

Salut à tutti. In questu articulu vi dicu perchè noi à Avito hà sceltu Kafka nove mesi fà è ciò chì hè. Aghju sparte unu di i casi d'usu - un broker di messagi. È infine, parlemu di quali vantaghji avemu avutu da l'usu di l'approcciu Kafka cum'è Service.
prublemu

Prima, un pocu cuntestu. Qualchì tempu fà avemu cuminciatu à alluntanassi da l'architettura monolitica, è avà Avito hà digià parechji centu di servizii diffirenti. Hanu i so repositori, a so pila di tecnulugia è sò rispunsevuli di a so parte di a logica cummerciale.
Unu di i prublemi cù un gran numaru di servizii hè a cumunicazione. U serviziu A spessu vole sapè l'infurmazioni chì hà u serviziu B. In questu casu, u serviziu A accede à u serviziu B per una API sincrona. U serviziu B vole sapè ciò chì passa cù i servizii D è D, è elli, à u turnu, anu interessatu à i servizii A è B. Quandu ci sò parechji servizii "curiosi", i ligami trà elli si trasformanu in un intricatu tangled.
À u listessu tempu, u serviziu A pò esse indisponibile in ogni mumentu. E chì deve fà u serviziu B è tutti l'altri servizii cunnessi à questu in questu casu? È se una catena di chjami sincroni sequenziali hè necessariu per compie una operazione cummerciale, a probabilità di fallimentu di l'operazione sana diventa ancu più altu (è più longa a catena, più altu hè).
Selezzione di tecnulugia

Va bè, i prublemi sò chjaru. Puderanu esse eliminati creendu un sistema di messageria centralizatu trà i servizii. Avà ognunu di i servizii solu bisognu di cunnosce circa stu sistema di messageria. Inoltre, u sistema stessu deve esse tolerante à i difetti è scalable horizontalmente, è ancu, in casu d'accidenti, accumule un buffer d'accessu per u prucessu sussegwente.
Selezziemu avà a tecnulugia nantu à quale sarà implementatu a spedizione di messagi. Per fà questu, avemu prima capisce ciò chì aspittemu da ellu:
- missaghji trà servizii ùn deve esse persu;
- i missaghji ponu esse duplicati;
- i missaghji ponu esse guardati è leghje à una prufundità di parechji ghjorni (buffer persistente);
- i servizii ponu abbonate à e dati chì anu interessatu;
- parechji servizii ponu leghje i stessi dati;
- i missaghji ponu cuntene una carica dettagliata è voluminosa (trasferimentu statale purtatu da l'avvenimentu);
- Calchì volta vi tocca à guarantisci l 'ordine di missaghji.
Era ancu criticu impurtante per noi di sceglie u sistema più scalabile è affidabile cù un altu throughput (almenu 100k missaghji di parechji kilobytes per seconda).
À questu puntu, avemu dettu addiu à RabbitMQ (difficile di mantene stabile à alta rps), PGQ da SkyTools (micca abbastanza veloce è ùn scala micca bè) è NSQ (micca persistente). Avemu aduprà tutte queste tecnulugii in a nostra cumpagnia, ma ùn sò micca adattati per u prublema chì si risolve.
In seguitu, avemu cuminciatu à guardà e tecnulugia chì eranu novi per noi - Apache Kafka, Apache Pulsar è NATS Streaming.
Pulsar hè statu u primu à esse scartatu. Avemu decisu chì Kafka è Pulsar sò suluzioni abbastanza simili. E malgradu u fattu chì Pulsar hè statu pruvatu da e grande cumpagnie, hè più novu è offre una latenza più bassa (in teoria), avemu decisu di lascià Kafka di sti dui cum'è u standard de facto per tali compiti. Probabilmente torneremu à Apache Pulsar in u futuru.
È avà sò rimasti dui candidati: NATS Streaming è Apache Kafka. Avemu studiatu e duie suluzioni in qualchì dettu, è tutti dui eranu adattati per u compitu. Ma à a fine, avemu avutu a paura di a giuventù relativa di NATS Streaming (è u fattu chì unu di i sviluppatori principali, Tyler Treat, hà decisu di lascià u prugettu è di inizià u so propiu - Liftbridge). À u listessu tempu, u modu di Clustering di NATS Streaming ùn hà micca furnitu a pussibilità di una forte scala horizontale (probabilmente questu ùn hè più un prublema dopu l'aghjunzione di u modu di partitioning in 2017).
Tuttavia, NATS Streaming hè una tecnulugia cool scritta in Go è supportata da a Cloud Native Computing Foundation. A cuntrariu di Apache Kafka, ùn hà micca bisognu di Zookeeper per travaglià (forse ), postu chì implementa RAFT internamente. À u listessu tempu, NATS Streaming hè più faciule d'amministrari. Ùn escludemu micca chì torneremu à sta tecnulugia in u futuru.
Eppuru, oghje u nostru vincitore hè Apache Kafka. In i nostri testi, hà dimustratu abbastanza veloce (più di un milione di messagi per seconda per leghje è scrive cù un voluminu di messagiu di 1 kilobyte), abbastanza affidabile, assai scalabile è pruvucatu da l'esperienza in a produzzione di grande imprese. Inoltre, Kafka sustene almenu parechje grandi cumpagnie cummerciale (avemu, per esempiu, aduprà a versione Confluent), è Kafka hà ancu un ecosistema sviluppatu.
Panoramica di Kafka
Prima di principià, mi piacerebbe ricumandemu immediatamente un libru eccellente - "Kafka: A Guida Definitiva" (Ci hè ancu una traduzzione russa, ma i termini sò un pocu sbalorditivi). Contene l'infurmazioni chì avete bisognu per acquistà una cunniscenza basica di Kafka è ancu un pocu più. A documentazione d'Apache è u blog di Confluent sò ancu scritti bè è faciuli di leghje.
Allora facemu una vista d'ochju di u funziunamentu di Kafka. A topologia basica di Kafka hè custituita da pruduttori, cunsumatori, broker è zookeeper.
Sede
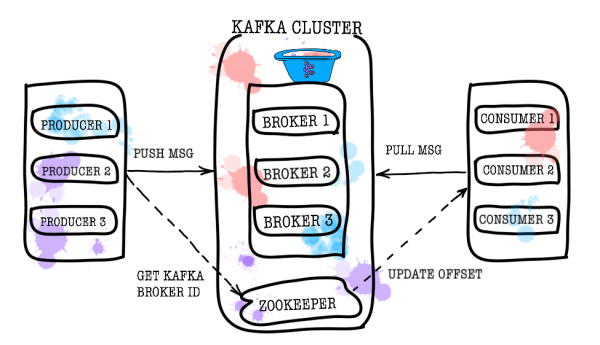
U broker hè rispunsevule per almacenà i vostri dati. Tutti i dati sò guardati in forma binaria, è u broker sapi pocu di ciò chì sò è ciò chì a so struttura hè.
Ogni tipu d'avvenimentu logicu hè generalmente situatu in u so propiu tema separatu. Per esempiu, l'avvenimentu di creà un annunziu pò falà in u tema item.created, è l'avvenimentu di u so cambiamentu pò fallu in item.changed. I temi ponu esse cunsiderati cum'è classificatori di avvenimenti. À u livellu di u tema, pudete stabilisce parametri di cunfigurazione cum'è:
- a quantità di dati almacenati è / o a so età (retention.bytes, retention.ms);
- fattore di redundanza di dati (fattore di replicazione);
- dimensione massima di un missaghju (max.message.bytes);
- u numeru minimu di repliche consistente à quale dati ponu esse scritti à un tema (min.insync.replicas);
- a capacità di realizà un failover in una replica lagging non sincrona cù una perdita potenziale di dati (unclean.leader.election.enable);
- è assai altri ().
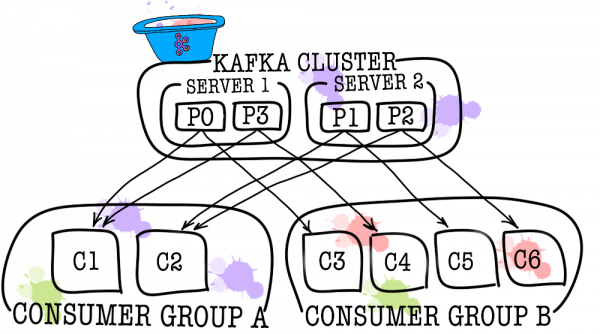
À u turnu, ogni tema hè divisu in una o più partizioni. Hè in i partiti chì l'avvenimenti finalmente cascanu. Se ci hè più di un broker in u cluster, allora e partizioni seranu distribuite uniformemente in tutti i brokers (in quantu pussibule), chì permetterà a carica di scrittura è lettura in un tema per esse scalatu in parechji brokers à una volta.
In u discu, i dati per ogni partizione sò almacenati in forma di schedarii di segmentu, per difettu uguali à un gigabyte (cuntrullatu da log.segment.bytes). Una funzione impurtante hè chì e dati sò sguassati da partizioni (quandu a retenzioni hè attivata) in segmenti (ùn pudete micca sguassà un avvenimentu da una partizione, pudete sguassà solu un segmentu sanu, è solu quellu inattivu).
zookeeper
Zookeeper agisce cum'è un magazinu di metadati è coordinatore. Hè quellu chì hè capaci di dì se i brokers sò vivi (pudete vede questu attraversu l'ochji di u zookeeper usendu zookeeper-shell cù u cumandimu). ls /brokers/ids), quale broker hè u cuntrollu (get /controller), se e partizioni sò in sincronizazione cù e so repliche (get /brokers/topics/topic_name/partitions/partition_number/state). Inoltre, hè à u zookeeper chì u pruduttore è u cunsumadore andaranu prima per sapè nantu à quale broker chì temi è partizioni sò almacenati. In i casi induve un fattore di replicazione più grande di 1 hè specificatu per un tema, u zookeeper indicà quali partizioni sò i capi (seranu scritti è leghje). In casu di fallimentu di u broker, l'infurmazioni nantu à e novi partizioni di capu seranu registrate in zookeeper (da a versione 1.1.0 in modu asincronu, ).
In e versioni più vechje di Kafka, u zookeeper era ancu rispunsevuli di almacenà offsets, ma avà sò guardati in un tema speciale. __consumer_offsets nantu à u broker (ancu se pudete ancu aduprà u zookeeper per questi scopi).
U modu più faciule per trasfurmà i vostri dati in una zucca hè di perde l'infurmazioni da u zookeeper. In un tali scenariu, serà assai difficiule di capisce ciò chì leghje è da induve.
Producer
Producer hè più spessu un serviziu chì scrive direttamente dati à Apache Kafka. U Produttore selezziunà un tema in quale guardà i so messagi di tema è principia à scrive l'infurmazioni. Per esempiu, u pruduttore puderia esse un serviziu di publicità. In questu casu, mandarà avvenimenti cum'è "annunziu creatu", "annunziu aghjurnatu", "annunziu eliminatu", etc. à temi tematichi. Ogni avvenimentu hè una coppia chjave-valore.
Per automaticamente, tutti l'avvenimenti sò distribuiti trà e partizioni tematiche usendu round-robin se a chjave ùn hè micca specificata (perde l'ordine), è attraversu MurmurHash (chjave) se a chjave hè presente (ordine in una partizione).
Hè da nutà subitu chì Kafka guarantisci l'ordine di l'avvenimenti solu in un batch. Ma in a realità questu hè spessu micca un prublema. Per esempiu, pudete esse sicuru d'aghjunghje tutti i cambiamenti à a listessa dichjarazione in una partizione (cusì priservendu l'ordine di sti cambiamenti in a dichjarazione). Pudete ancu mandà un numeru di sequenza in unu di i campi di l'avvenimentu.
Franchising
U cunsumadore hè rispunsevule per piglià e dati da Apache Kafka. Se turnemu à l'esempiu sopra, u cunsumadore puderia esse un serviziu di moderazione. Stu serviziu serà sottumessu à u tema di u serviziu di publicità, è quandu un novu annunziu appare, u riceverà è analizà per u rispettu di alcune pulitiche specificate.
Apache Kafka ricorda ciò chì l'avvenimenti recenti hà ricevutu u cunsumadore (un tema di serviziu hè utilizatu per questu __consumer__offsets), assicurendu cusì chì, se a lettura hè successu, u cunsumadore ùn riceve micca u stessu missaghju duie volte. Tuttavia, se utilizate l'opzione enable.auto.commit = true è delegate cumplettamente u travagliu di seguità a pusizione di u cunsumadore in u tema à Kafka, pudete . In u codice di pruduzzione, a maiò spessu a pusizione di u cunsumadore hè cuntrullata manualmente (u sviluppatore cuntrolla u mumentu quandu l'impegnu di l'avvenimentu di lettura deve esse).
In i casi induve un cunsumadore ùn hè micca abbastanza (per esempiu, u flussu di novi avvenimenti hè assai grande), pudete aghjunghje parechji più cunsumatori liendu inseme in un gruppu di cunsumatori. Un gruppu di cunsumatori hè lògicu esattamente u listessu cum'è un cunsumadore, ma cù dati distribuiti trà i membri di u gruppu. Questu permette à ogni participante di piglià a so parte di i missaghji, scalendu cusì a velocità di lettura.
Risultati di test

Ùn scriveraghju micca assai testu esplicativu quì, solu sparteraghju i risultati ottenuti. A prova hè stata realizata nantu à e macchine fisiche 3 (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit/s Net), i brokers è u zookeeper sò stati implementati in lxc.
Test di rendiment
Durante a prova, i risultati seguenti sò stati ottenuti.
- A vitezza di arregistramentu missaghji 1KB simultaneamente da 9 pruduttori hè 1300000 avvenimenti per seconda.
- A vitezza di leghje 1KB missaghji simultaneamente da i cunsumatori 9 hè 1500000 avvenimenti per seconda.
Test di tolleranza à i difetti
Durante a prova, i seguenti risultati sò stati ottenuti (3 brokers, 3 zookeepers).
- A terminazione anormale di unu di i brokers ùn pruvucarà micca chì u cluster si ferma o diventa indisponibile. U travagliu cuntinueghja cum'è normale, ma i brokers restanti anu una carica di travagliu pesante.
- A terminazione anormale di dui brokers in u casu di un cluster di trè brokers è min.isr = 2 porta à u cluster ùn hè micca dispunibule per scrive, ma accessibile per leghje. Se min.isr = 1, u cluster cuntinueghja esse dispunibule sia per a lettura sia per a scrittura. Tuttavia, stu modu cuntradisci u requisitu di alta sicurità di dati.
- Un arrestu anormale di unu di i servitori di Zookeeper ùn pruvucarà micca chì u cluster si ferma o diventa indisponibile. U travagliu cuntinueghja cum'è normale.
- Un arrestu anormale di dui servitori Zookeeper face chì u cluster ùn sia micca dispunibule finu à chì almenu unu di i servitori Zookeeper hè restauratu. Questa dichjarazione hè vera per un cluster Zookeeper di 3 servitori. In u risultatu, dopu a ricerca, hè statu decisu di aumentà u cluster Zookeeper à i servitori 5 per aumentà a toleranza di difetti.
Kafka cum'è serviziu

Semu cunvinti chì Kafka hè una tecnulugia excelente chì ci permette di risolve u compitu assignatu à noi (implementazione di un broker di messagi). In ogni casu, avemu decisu di pruibisce i servizii di accede direttamente à Kafka è chjusu in cima cù un serviziu di bus di dati. Perchè avemu fattu questu? In fatti, ci sò uni pochi di motivi.
Data-bus hà ripresu tutti i travaglii ligati à l'integrazione cù Kafka (implementazione è cunfigurazione di i cunsumatori è di i pruduttori, monitoraghju, alerting, logging, scaling, etc.). Cusì, l'integrazione cù u broker di messagi hè simplice quant'è pussibule.
Data-bus hà permessu di astrazione da una lingua specifica o biblioteca per travaglià cù Kafka.
Data-bus hà permessu à altri servizii di astrazione di a capa di almacenamento. Forsi à un certu puntu cambieremu Kafka à Pulsar, è nimu hà da nutà nunda (tutti i servizii cunnosci solu di l'API di dati-bus).
Data-bus hà pigliatu a validazione di i schemi di l'avvenimenti.
L'autenticazione hè implementata cù data-bus.
Sottu a copertura di dati-bus, pudemu aghjurnà in silenziu e versioni di Kafka senza tempi di inattività, gestione cintrali cunfigurazioni di pruduttori, cunsumatori, brokers, etc.
Data-bus ci hà permessu di aghjunghje e funziunalità chì avemu bisognu chì ùn sò micca in Kafka (cum'è temi di auditing, monitoring anomalies in u cluster, creazione DLQ, etc.).
Data-bus permette di implementà u failover centralmente per tutti i servizii.
À u mumentu, per cumincià à mandà l'avvenimenti à u broker di messagi, basta à cunnette una piccula biblioteca à u vostru codice di serviziu. Questu hè tuttu. Avete a capacità di scrive, leghje è scala cù una linea di codice. Tutta l'implementazione hè oculata da voi, cù solu uni pochi di manichi di dimensione di batch chì spuntanu. Sottu u cappucciu, u serviziu di bus di dati aumenta u numeru necessariu di pruduttori è cunsumatori in Kubernetes è li furnisce a cunfigurazione necessaria, ma tuttu questu hè trasparente à u vostru serviziu.
Di sicuru, ùn ci hè micca una bala d'argentu, è questu approcciu hà e so limitazioni.
- Data-bus deve esse supportatu in-house, in uppusizione à e biblioteche di terzu.
- Data-bus aumenta u nùmeru di interazzione trà i servizii è u broker di messagi, chì si traduce in un rendimentu più bassu cumparatu à Bare Kafka.
- Micca tuttu pò esse oculatu da i servizii cusì facilmente; ùn vulemu micca duplicà a funziunalità di KSQL o Kafka Streams in data-bus, cusì qualchì volta avemu da permette à i servizii per andà direttamente.
In u nostru casu, i prufessiunali anu più di i contra, è a decisione di copre u broker di messagiu cù un serviziu separatu hè stata ghjustificata. Duranti l'annu di funziunamentu ùn avemu micca avutu micca accidenti o prublemi gravi.
PS Grazie à a mo fidanzata, Ekaterina Obalyaeva, per l'imaghjini freschi per questu articulu. Se li piacia, ci sò più illustrazioni à vene.
Source: www.habr.com
