

Cuntinuemu a serie di articuli dedicati à u studiu di modi pocu cunnisciuti per migliurà u rendiment di e dumande PostgreSQL "apparente simplici":
Ùn pensate micca chì ùn mi piace micca tantu JOIN ... :)
Ma spessu senza ellu, a dumanda risulta esse significativamente più produtiva chè cun ella. Allora oghje avemu da pruvà sbarazzarsi di JOIN intensivi di risorse - utilizendu un dizziunariu.

Partendu da PostgreSQL 12, alcune di e situazioni descritte quì sottu ponu esse riprodutte in modu leggermente diversu per via di . Stu cumpurtamentu pò esse rimbursatu specificendu a chjave
MATERIALIZED.
Un saccu di "fatti" in un vocabulariu limitatu
Pigliemu un compitu d'applicazione assai reale - avemu bisognu di vede una lista o compiti attivi cù i mittenti:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
In u mondu astrattu, l'autori di u travagliu deve esse distribuitu uniformemente trà tutti l'impiegati di a nostra urganizazione, ma in realità I travaglii venenu, in regula, da un numeru abbastanza limitatu di persone - "da a gestione" à a ghjerarchia o "da i subcontractors" da i dipartimenti vicini (analisti, disegnatori, marketing, ...).
Accettamu chì in a nostra urganizazione di 1000 persone, solu l'autori 20 (di solitu ancu menu) stabiliscenu compiti per ogni esecutore specificu è per accelerà a dumanda "tradiziunale".
Generatore di script
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
Mostramu l'ultimi 100 compiti per un esecutore specificu:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 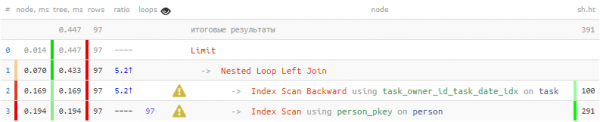
Questu hè chì 1/3 di u tempu tutale è 3/4 di lettura pagine di dati sò stati fatti solu per circà l'autore 100 volte - per ogni attività di output. Ma sapemu chì trà sti centinaie solu 20 sfarenti - Hè pussibule aduprà sta cunniscenza ?
hstore-dizziunariu
Aprovechemu per generà una chjave-valore "dizziunariu":
CREATE EXTENSION hstoreBasta à mette l'ID di l'autore è u so nome in u dizziunariu per pudè esse estratti cù sta chjave:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 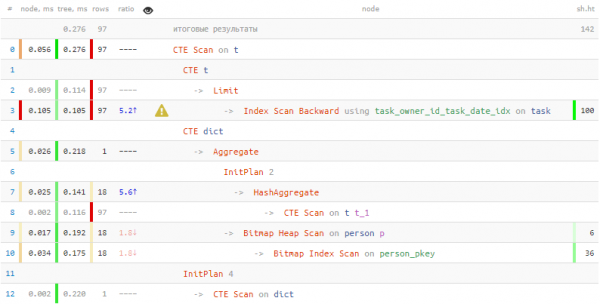
Spentu per ottene infurmazioni nantu à e persone 2 volte menu tempu è 7 volte menu dati leghje! In più di "vocabulary", ciò chì ci hà ancu aiutatu à ottene questi risultati era ricuperazione di record di massa da a tavula in una sola passata usendu = ANY(ARRAY(...)).
Entrie Table: Serializazione è Deserializazione
Ma chì si avemu bisognu di salvà micca solu un campu di testu, ma una entrata sana in u dizziunariu? In questu casu, a capacità di PostgreSQL ci aiuterà trattate una entrata di tavula cum'è un valore unicu:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;Fighjemu ciò chì passava quì:
- Avemu pigliatu p cum'è un alias à l'entrata di a tabella di persona sana è hà riunitu una serie di elli.
- issu a serie di registrazioni hè stata riformulata à un array di strings di testu (person[]::text[]) per mette in u dizziunariu hstore cum'è un array di valori.
- Quandu avemu ricevutu un record in relazione, noi tiratu da u dizziunariu da chjave cum'è una stringa di testu.
- Avemu bisognu di testu trasfurmà in un valore di tipu di tabella persona (per ogni tavula un tipu di u listessu nome hè creatu automaticamente).
- "Espandisce" u registru digitatu in culonni utilizendu
(...).*.
dizziunariu json
Ma un tali truccu cum'è avemu applicatu sopra ùn hà micca travagliatu s'ellu ùn ci hè micca un tipu di tavula currispondente per fà u "casting". Esattamente a listessa situazione si suscitarà, è si pruvemu à aduprà una fila CTE, micca una tavola "reale"..
In questu casu, ci aiuteranu :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; Semu devi esse nutatu chì quandu si descrizanu a struttura di destinazione, ùn pudemu micca liste tutti i campi di a stringa fonte, ma solu quelli chì avemu veramente bisognu. Se avemu una tavola "nativa", allora hè megliu aduprà a funzione json_populate_record.
Avemu sempre accede à u dizziunariu una volta, ma json-[de] i costi di serializazione sò abbastanza alti, dunque, hè ragiunate à aduprà stu mètudu solu in certi casi quandu u "onestu" CTE Scan si mostra peggiu.
Pruduzzione di prova
Dunque, avemu duie manere di serializà e dati in un dizziunariu - hstore/json_object. Inoltre, e matrici di chjavi è valori stessi ponu ancu esse generati in dui modi, cù cunversione interna o esterna in testu: array_agg(i::text) / array_agg(i)::text[].
Cuntrollamu l'efficacità di diversi tipi di serializazione cù un esempiu puramente sinteticu - serializza diversi numeri di chjave:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;Scrittura di valutazione: serializazione
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 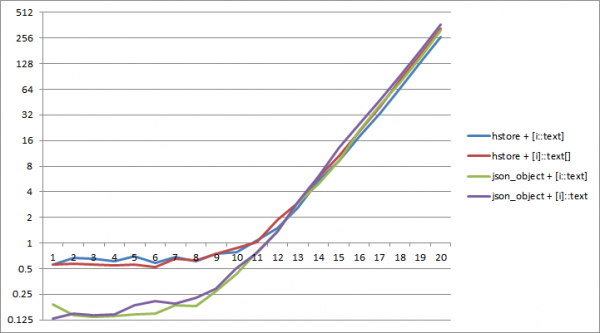
In PostgreSQL 11, finu à circa una dimensione di dizziunariu di 2^12 chjave A serializazione in json piglia menu tempu. In questu casu, u più efficace hè a cumminazzioni di json_object è cunversione di tipu "internu". array_agg(i::text).
Avà pruvemu à leghje u valore di ogni chjave 8 volte - dopu tuttu, se ùn accede micca à u dizziunariu, perchè hè necessariu?
Scrittura di valutazione : lettura da un dizziunariu
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 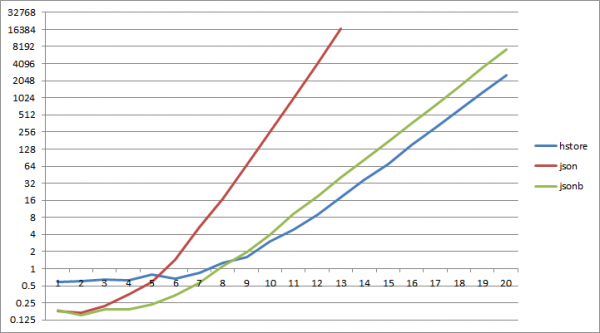
È... digià circa cù 2^6 chjave, a lettura da un dizziunariu json cumencia à perde parechje volte lettura da hstore, per jsonb u listessu succede à 2^9.
Conclusioni finali:
- s'ellu ci vole à fà UNISCITI cù parechji registri ripetuti - hè megliu aduprà "dizziunariu" di a tavula
- se u vostru dizziunariu hè aspittatu picculu è ùn leghje assai da ellu - pudete aduprà json [b]
- in tutti l'altri casi hstore + array_agg(i::text) serà più efficace
Source: www.habr.com
