


Fa male solu a prima volta!
Salut à tutti ! Cari amichi, in questu articulu vogliu sparte a mo sperienza di utilizà TensorRT, RetinaNet basatu annantu à u repository (questu hè un forchetta di a rapa ufficiale da , chì vi permetterà di cumincià à aduprà mudelli ottimizzati in a produzzione u più prestu pussibule). Scrolling through messages in i canali di a cumunità , Aghju incuntratu in dumande nantu à l'usu di TensorRT è e dumande sò soprattuttu ripetute, cusì aghju decisu di scrive cum'è cumpletu pussibule Una guida per utilizà l'inferenza rapida basata in TensorRT, RetinaNet, Unet è docker.
Descrizzione di u compitu
Pruponu di formulà u compitu in questu modu: avemu bisognu di etichettà u dataset, furmà a rete RetinaNet/Unet nantu à Pytorch 1.3+, cunvertisce i pesi ottenuti in ONNX, poi cunvertisceli in u mutore TensorRT è eseguisce tuttu in Docker, preferibilmente nantu à Ubuntu 18 è assai desiderabile nantu à l'architettura ARM (Jetson)*, minimizendu cusì u spiegamentu manuale di l'ambiente. U risultatu finale serà un container prontu micca solu per l'esportazione è a furmazione di RetinaNet/Unet, ma ancu per u sviluppu cumpletu è a furmazione di sistemi di classificazione è segmentazione, cù tuttu l'hardware necessariu.
Stage 1. Preparazione di l'ambienti
Hè impurtante di nutà quì chì recentemente aghju abbandunatu completamente l'usu è l'implementazione di almenu alcune biblioteche nantu à una macchina desktop, è ancu in devbox. L'unicu ciò chì avete da creà è installà hè un ambiente virtuale python è cuda 10.2 (pudete limità à un driver nvidia) da deb.
Supponemu chì avete un installatu appena Ubuntu 18. Installemu cuda 10.2 (deb). Ùn entreraghju micca in dettagli nantu à u prucessu d'installazione, a ducumentazione ufficiale hè abbastanza sufficiente.
Avà stallà docker, a guida d'installazione di docker pò esse facilmente truvata, quì hè un esempiu , a versione 19+ hè digià dispunibule - installate. Ebbè, ùn vi scurdate di fà pussibule aduprà docker senza sudo, serà più còmuda. Dopu chì tuttu hà travagliatu, facemu questu:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
È ùn avete mancu à guardà u repositoriu ufficiale .
Avà femu git clone .
Ci hè solu un pocu, per cumincià à aduprà docker cù una maghjina nvidia, avemu bisognu di registrà cù NGC Cloud è login. Andemu quì , registrate è dopu avè entratu in NGC Cloud, cliccate SETUP in l'angulu superiore manca di u screnu o seguite stu ligame . Cliccate "generate key". Vi ricumandemu di salvà, altrimenti a prossima volta chì u visitate, duverete generà di novu è, per quessa, implementà nantu à una nova vittura è ripetite sta operazione.
Facemu :
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
U nome d'utilizatore hè simplicemente copiatu. Ebbè, cunzidira l'ambiente dispiegatu!
Stage 2: Custruì u containeru docker
À a seconda tappa di u nostru travagliu, custruiremu docker è cunniscitemu cù i so interni.
Andemu à u cartulare radicali in relazione à u prughjettu di retina-esempii è eseguite
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Custruemu docker passendu l'utilizatore attuale in questu - questu hè assai utile se scrivite qualcosa à un VOLUME muntatu cù i diritti di l'utilizatore attuale, altrimenti serà root and pain.
Mentre docker hè custruitu, esaminemu u Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Cum'è pudete vede da u testu, pigliemu tutte e nostre biblioteche preferite, compilemu retinanet, aghjustemu alcuni strumenti basi per facilità di travagliu. Ubuntu è cunfigurà u servitore OpenSSH. A prima linea eredita l'imagine NVIDIA per a quale avemu creatu u login NGC Cloud è chì cuntene Pytorch1.3, TensorRT6.xxx, è un inseme d'altre biblioteche chì ci permettenu di cumpilà u codice surghjente CPP per u nostru detector.
Stage 3: Lanciamentu è Debugging di u Container Docker
Passemu à u casu principale di l'usu di u containeru è di l'ambiente di sviluppu prima, lanciamu nvidia docker. Facemu :
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestU cuntinuu hè avà accessibile via ssh @localhost. Dopu un lanciu successu, apre u prugettu in PyCharm. Dopu avemu apertu
Settings->Project Interpreter->Add->Ssh Interpreter mossa 1
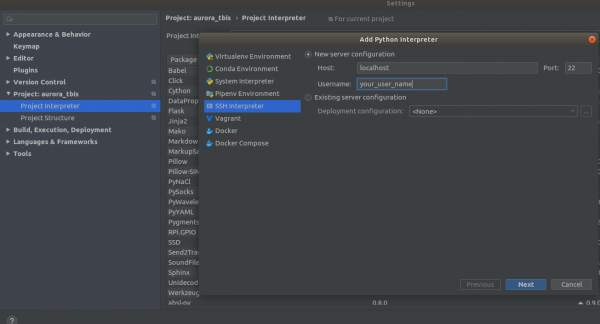
mossa 2
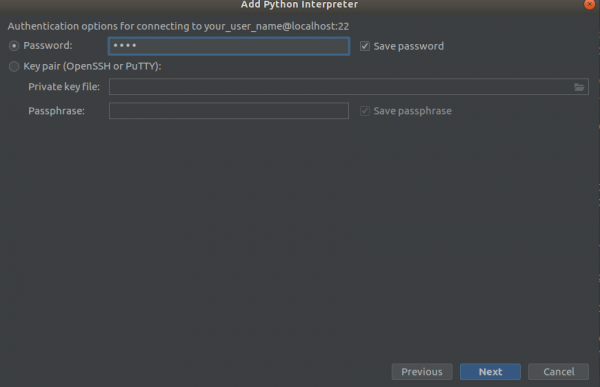
mossa 3
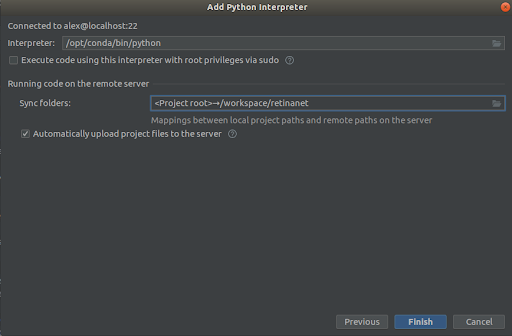
Selezziemu tuttu cum'è in i screenshots,
Interpreter -> /opt/conda/bin/python- questu serà ln in Python3.6 è
Sync folder -> /workspace/retinanetPrememu finitu, aspittemu l'indexazione, è questu hè, l'ambiente hè prontu per l'usu!
IMPORTANTE !!! Immediatamente dopu l'indexazione, tirate i schedarii compilati per Retinanet da docker. In u menù di cuntestu in a radica di u prughjettu, selezziunate l'elementu
Deployment->DownloadApparirà un schedariu è dui cartulare: build, retinanet.egg-info è _С.so
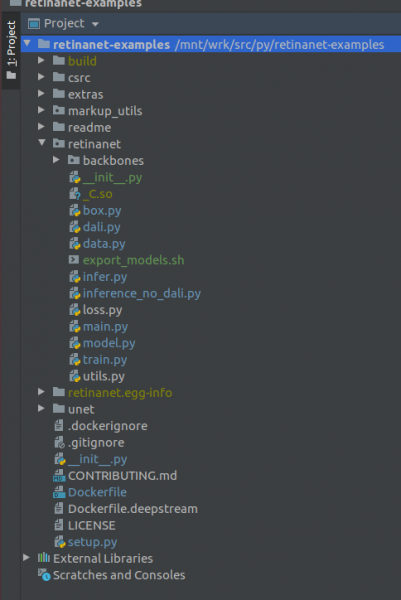
Se u vostru prughjettu pare cusì, allora l'ambiente vede tutti i schedarii necessarii è simu pronti per furmà RetinaNet.
Stage 4. Label i dati è furmà u detector
Per u marcatu aghju utilizatu principalmente - un strumentu piacevule è cunvene, recentemente una mansa di bug hè stata riparata è hè diventata significativamente megliu cumportatu.
Assumimu chì avete marcatu u dataset è scaricatu, ma ùn puderete micca mette immediatamente in u nostru RetinaNet, postu chì hè in u so propiu formatu è per questu avemu bisognu di cunvertisce in COCO. U strumentu di cunversione hè situatu in:
markup_utils/supervisly_to_coco.pyPer piacè nutate chì Category in u script hè un esempiu è avete bisognu di inserisce u vostru propiu (ùn ci hè bisognu di aghjunghje a categuria di fondo)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Per una certa ragione, l'autori di u repositoriu originale anu decisu chì ùn avete micca furmà nunda altru ch'è COCO / VOC per a deteczione, cusì anu da edità u schedariu fonte un pocu.
retinanet/dataset.pyAghjunghjendu i vostri aumenti preferiti quì è tagliate categurie cablate da COCO. Hè ancu pussibule di cultivà grandi spazii di deteczione, sè vo circate uggetti chjuchi in grandi ritratti, avete un picculu dataset =), è nunda ùn funziona, ma più nantu à questu un altru tempu.
In generale, u ciclu di u trenu hè ancu debule, inizialmente ùn hà micca salvatu i punti di cuntrollu, hà utilizatu un tipu di pianificatore terribili, etc. Ma avà tuttu ciò chì avete da fà hè di selezziunà a spina è eseguisce
/opt/conda/bin/python retinanet/main.pycù paràmetri:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
In a cunsola vi vede:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Per scopra tuttu u set di parametri, fighjate
retinanet/main.pyIn generale, sò standard per a deteczione, è anu una descrizzione. Cumincià a furmazione è aspettate i risultati. Un esempiu di inferenza pò esse vistu in:
retinanet/infer_example.pyo eseguite u cumandimu:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
U repositoriu hà digià Focal Loss è parechje backbones integrati, è hè ancu faciule d'incrustà u vostru propiu.
retinanet/backbones/*.pyIn u tavulu, l'autori dà alcune caratteristiche:
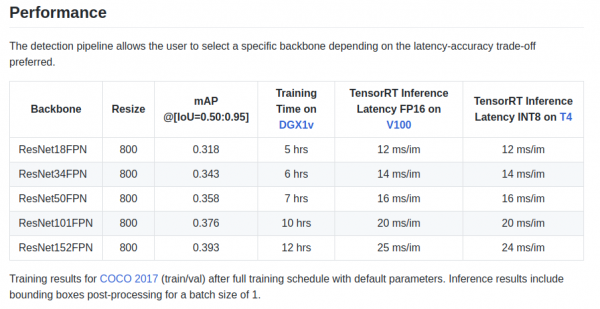
Ci hè ancu una spina ResNeXt50_32x4dFPN è ResNeXt101_32x8dFPN, presa da torchvision.
Spergu chì avete capitu un pocu di a deteczione, ma avete bisognu di leghje a documentazione ufficiale per quessa capisce i modi d'esportazione è di logging.
Stage 5. Export and inference of Unet models with Resnet encoder
Cum'è probabilmente avete nutatu, e librerie per a segmentazione sò state installate in u Dockerfile, è in particulare a maravigliosa lib . In u pacchettu unitet pudete truvà esempi di inferenza è esportazione di punti di cuntrollu di pytorch à u mutore TensorRT.
U prublema principali quandu si esportanu mudelli Unet-like da ONNX à TensoRT hè a necessità di stabilisce una dimensione Upsample fissa o aduprà ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Utilizendu sta trasfurmazioni, pudete fà questu automaticamente quandu esportate à ONNX, ma digià in a versione 7 di TensorRT stu prublema hè stata risolta, è avemu da aspittà un pocu.
cunchiusioni
Quandu aghju cuminciatu à aduprà docker, aghju avutu dubbitu nantu à a so prestazione per i mo compiti. Una di e mo unità hà attualmente assai trafficu di rete generatu da parechje camere.
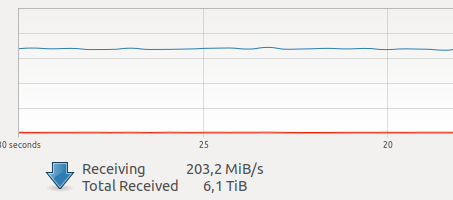
Diversi testi in Internet anu parlatu di un sopratuttu relativamente grande per l'interazzione di a rete è a registrazione in VOLUME, più u GIL scunnisciutu è terribili, è dapoi a catturazione di un quadru, u funziunamentu di u cunduttore è a trasmissione di u quadru nantu à a reta hè una operazione atomica in u modu. duru in tempu reale, i ritardi di a rete sò assai critichi per mè.
Ma tuttu hè andatu bè =)
PS Tuttu ciò chì resta hè di aghjunghje u vostru ciclu di trenu preferitu per a segmentazione è a produzzione!
Grazie
Grazie à a cumunità , senza ellu hè impussibile di sviluppà! Grazie tante , chì m'hà incuraghjitu à fà DL, per i so cunsiglii inestimabili è a prufessionalità estrema !
Aduprate mudelli ottimizzati in a produzzione!
 Aurorai, llc
Aurorai, llc
Source: www.habr.com
