


E rete neurali in a visione di l'informatica sò attivamente sviluppati, assai prublemi sò sempre luntanu da esse risolti. Per esse in tendenza in u vostru campu, seguite l'influenzatori in Twitter è leghje articuli pertinenti in arXiv.org. Ma avemu avutu l'uppurtunità di andà à a Cunferenza Internaziunale di Visione Informatica (ICCV) 2019. Quist'annu hè tenutu in Corea di u Sud. Avà vulemu sparte cù i lettori di Habr ciò chì avemu vistu è amparatu.
Ci era assai di noi quì da Yandex: i sviluppatori di vitture autoguidati, circadori, è quelli chì trattanu di i travaglii di CV in i servizii sò vinuti. Ma avà vulemu prisentà un puntu di vista un pocu subjectitivu di a nostra squadra - u Laboratoriu di Intelligenza Macchina (Yandex MILAB). L'altri picciotti probabilmente anu guardatu a cunferenza da u so angulu.
Chì faci u laboratoriu?Facemu prughjetti sperimentali ligati à a generazione d'imaghjini è di musica per scopi di divertimentu. Semu interessate in particulare in e rete neurali chì permettenu di cambià u cuntenutu da l'utilizatore (per i ritratti, sta attività hè chjamata manipulazione di l'imaghjini). u risultatu di u nostru travagliu da a cunferenza YaC 2019.
Ci sò parechje cunferenze scentifiche, ma spiccanu i primi, i cosiddetti cungressi A*, induve sò generalmente publicati articuli nantu à e tecnulugia più interessanti è impurtanti. Ùn ci hè micca una lista precisa di cunferenze A *, quì hè una lista apprussimata è incompleta: NeurIPS (antica NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. L'ultimi trè sò specializati in u tema CV.
ICCV in sguardu : affissi, tutoriali, attelli, stands
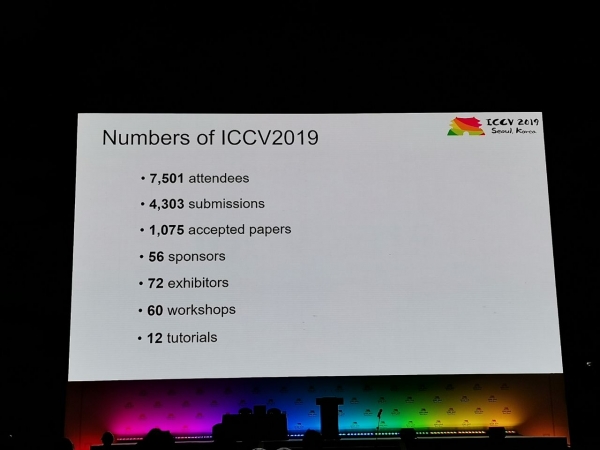
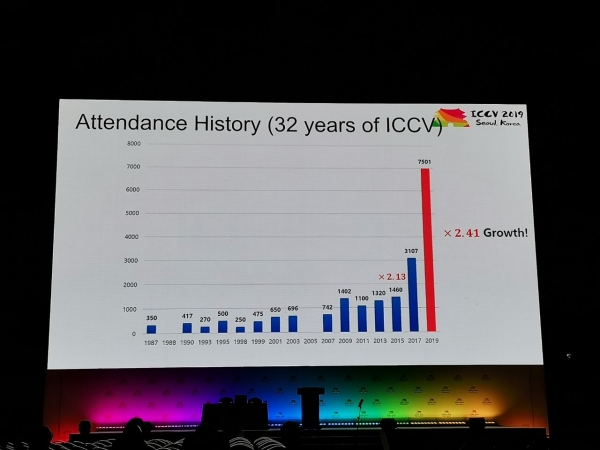
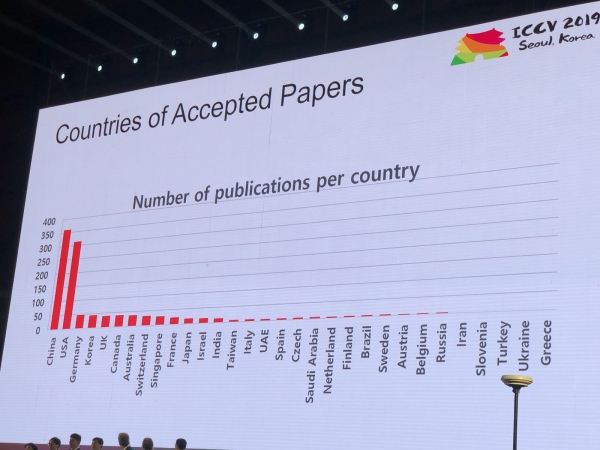
A cunferenza hà ricivutu 1075 documenti, ci sò stati 7500 participanti 103 persone sò venuti da Russia, ci eranu articuli di l'impiegati di Yandex, Skoltech, Samsung AI Center Moscow è Samara University. Quist'annu, micca assai circadori principali anu visitatu ICCV, ma, per esempiu, Alexey (Alyosha) Efros, chì sempre attrae assai persone:

Статистика 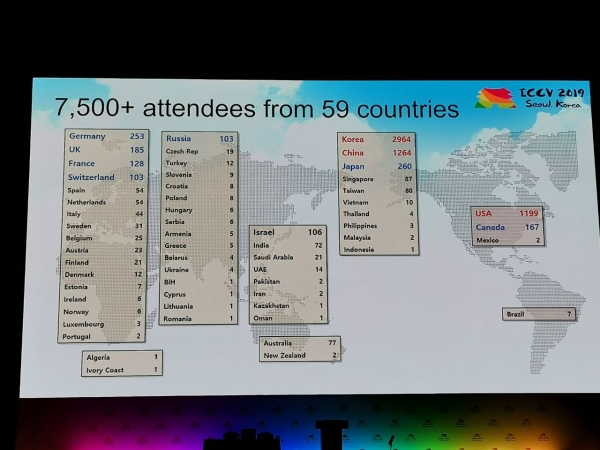

In tutte tali cunferenze, l'articuli sò presentati in forma di poster ( circa u furmatu), è i più boni sò ancu presentati in forma di brevi rapporti.
Eccu alcuni di l'opere da Russia 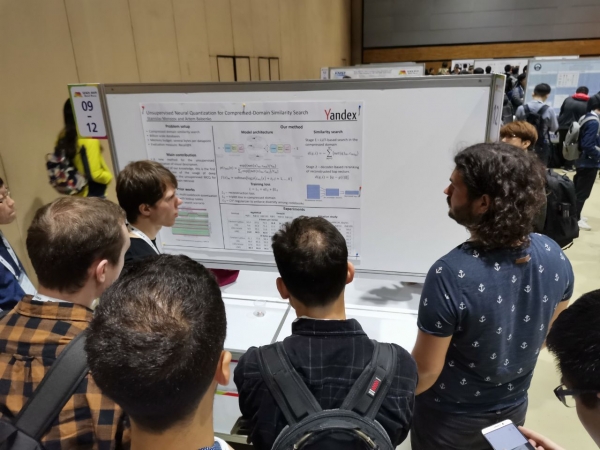


Cù i tutoriali pudete immergete in un sughjettu particulari chì ricorda una cunferenza in una università. Hè lettu da una persona, di solitu senza parlà di opere specifiche. Un esempiu di un bellu tutoriale ():

À l'attellu, à u cuntrariu, si parla d'articuli. Di solitu questi sò travaglii in qualchì tema strettu, storie da i capi di laboratori nantu à tutti l'ultimi travaglii di i studienti, o articuli chì ùn sò micca accettati à a cunferenza principale.
L'imprese di sponsori venenu à ICCV cù stands. Quist'annu, Google, Facebook, Amazon è parechje altre cumpagnie internaziunali sò ghjunti, è ancu un gran numaru di startups - coreanu è cinese. Ci era soprattuttu assai startups chì anu specializatu in l'etichettatura di dati. Ci sò spettaculi in i stand, pudete piglià merch è dumandà dumande. Per scopi di caccia, l'imprese patrocinatori anu partiti. Pudete mette in elli si cunvince i reclutatori chì site interessatu è chì pudete passà l'entrevista. Sè avete publicatu un articulu (o, in più, presentatu), cuminciatu o finite un PhD, questu hè un plus, ma qualchì volta pudete negocià à u stand facendu dumande interessanti à l'ingegneri di a cumpagnia.
Tendenze
A cunferenza permette di piglià un ochju à tuttu u campu di CV. Per u numeru di posters nantu à un tema particulari, pudete valutà quantu caldu u tema hè. Alcune cunclusioni suggerenu si basanu nantu à e parolle chjave:

Zero-shot, one-shot, little-shot, auto-survegliatu è semi-supervisatu: novi approcci à i travaglii longu studiati
A ghjente ampara à utilizà e dati in modu più efficace. Per esempiu, in hè pussibule di generà l'espressioni faciale di l'animali chì ùn eranu micca in u gruppu di furmazione (in appiecazione, furnisce parechji ritratti di riferimentu). L'idee di Deep Image Prior sò state sviluppate, è avà e rete GAN ponu esse furmatu nantu à una sola maghjina - parlemu quì sottu. . Pudete utilizà l'autosurveglianza per a pre-formazione (risolve un prublema per quale pudete sintetizà dati allineati, cum'è predichendu l'angolo di rotazione di una stampa) o amparà simultaneamente da dati etichettati è senza etichetta. In questu sensu, l'articulu pò esse cunsideratu a corona di a creazione . È quì hè u pre-furmazione nantu à ImageNet aiuta.

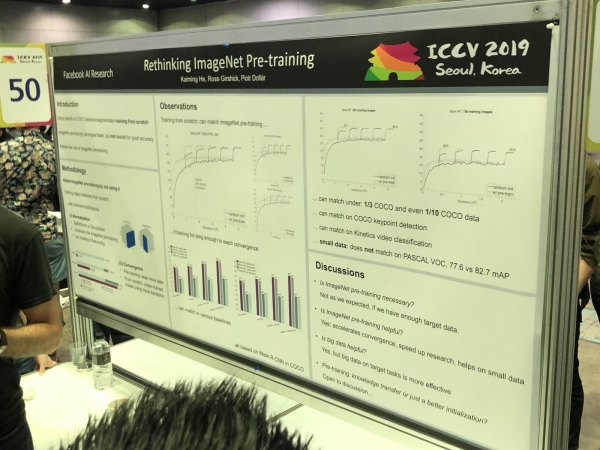
3D è 360 °
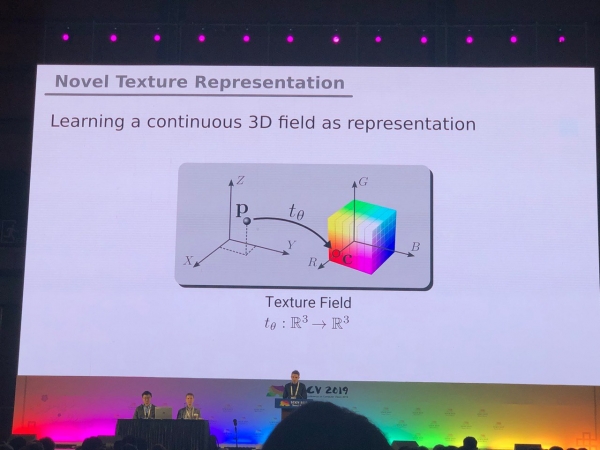
I prublemi chì sò stati risolti soprattuttu per e foto (segmentazione, rilevazione) necessitanu una ricerca supplementaria per mudelli 3D è video panoramichi. Avemu vistu parechji articuli nantu à cunvertisce RGB è RGB-D à 3D. Certi prublemi, cum'è l'estimazione di a pusizioni umana, ponu esse risolti più naturali passendu à mudelli 3D. Ma ùn ci hè ancu un cunsensu nantu à cumu esattamente rapprisintà mudelli XNUMXD - in forma di maglia, nuvola di punti, voxels o SDF. Eccu un'altra opzione:
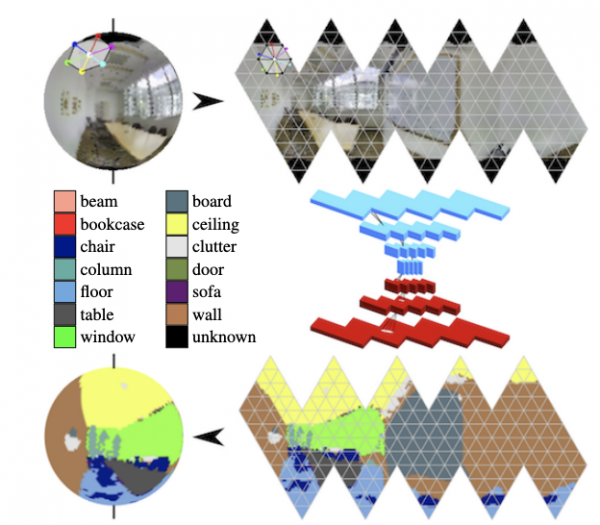
In i panorami, i cunvoluzioni nantu à a sfera si sviluppanu attivamente (vede. ) è cercate l'uggetti chjave in u quadru.
Rilevazione di pusizioni è predizione di u muvimentu umanu
Ci hè digià statu avanzatu in a rilevazione di pose in 2D - avà l'attenzione hè stata spostata versu u travagliu cù parechje camere è in 3D. Hè ancu pussibule, per esempiu, di detect un scheletru à traversu un muru per seguità i cambiamenti in u signale Wi-Fi chì passa per u corpu umanu.
Moltu travagliu hè statu fattu in u campu di a rilevazione di punti chjave di a manu. Nuvelli datasets sò apparsu, cumprese quelli basati in video di dialoghi trà duie persone - avà pudete predichendu i gesti di e mani da l'audio o u testu di una conversazione! U listessu prugressu hè statu fattu in i travaglii di seguimentu di l'ochji (estimazione di u sguardu).

Si pò ancu identificà un grande gruppu di travagli in relazione à a prediczione di u muvimentu umanu (per esempiu, o ). U compitu hè impurtante è, basatu annantu à cunversazione cù l'autori, hè più spessu usatu per analizà u cumpurtamentu di i pedoni in a guida autònoma.
Manipulazioni cù e persone in foto è video, cabine di prova virtuale
A tendenza principale hè di cambià l'imaghjini faciale secondu i paràmetri interpretabili. Idee: deepfake basatu annantu à una stampa, cambiante espressione basatu annantu à a resa faciale (), feedforward - cambià i paràmetri (per esempiu, ). I trasferimenti di stile sò passati da u titulu di u tema à l'applicazione di u travagliu. I camerini virtuali sò una storia diversa, quasi sempre travaglianu male; demo.


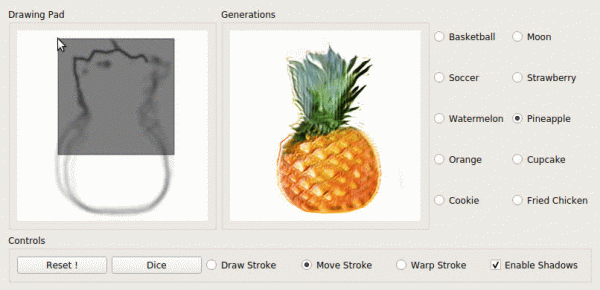
Generazione da schizzi / grafici
U sviluppu di l'idea "Lasciate chì a griglia generà qualcosa basata nantu à l'esperienza precedente" hè diventata un altru: "Mustremu a griglia quale opzione ci interessa".
permette di fà un inpaint guidatu: l'utilizatore pò finisce di pittura una parte di a faccia in l'area sguassata di a stampa è uttene una stampa restaurata secondu a finitura.
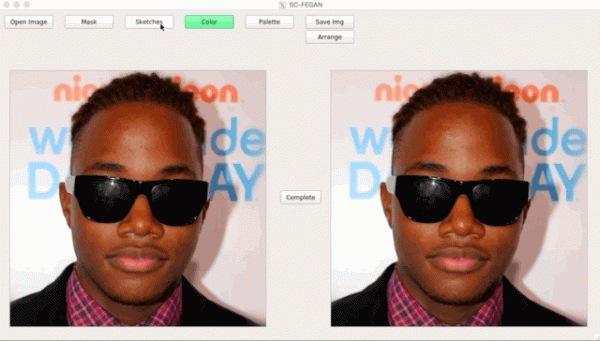
Unu di 25 articuli Adobe per ICCV combina dui GAN: unu cumpleta u sketch per l'utilizatore, l'altru genera una maghjina fotorealistica da u sketch ().
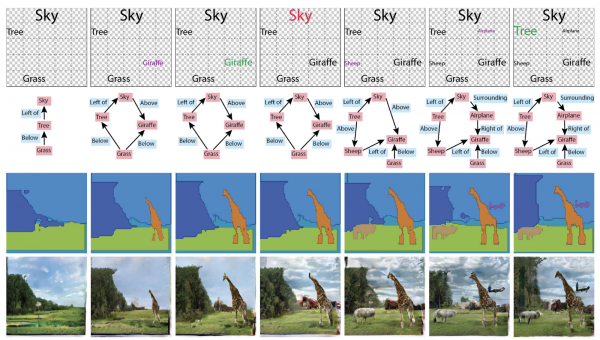
Nanzu, i grafici ùn eranu micca necessariu in a generazione di l'imaghjini, ma avà sò stati fatti un cuntainer di cunniscenze nantu à a scena. U premiu Best Paper Honorable Mentions basatu annantu à i risultati di l'ICCV hè statu ancu vintu da l'articulu . In generale, pudete aduprà in diverse manere: generà grafici da stampe, o imagine è testi da grafici.
Riidentificazione di persone è vitture, cuntendu a dimensione di a folla (!)
Parechji articuli sò dedicati à seguità e persone è à re-identificà e persone è e macchine. Ma ciò chì ci hà sorpresu era una mansa d'articuli nantu à a crowd counting, tutti da Cina.
Posters 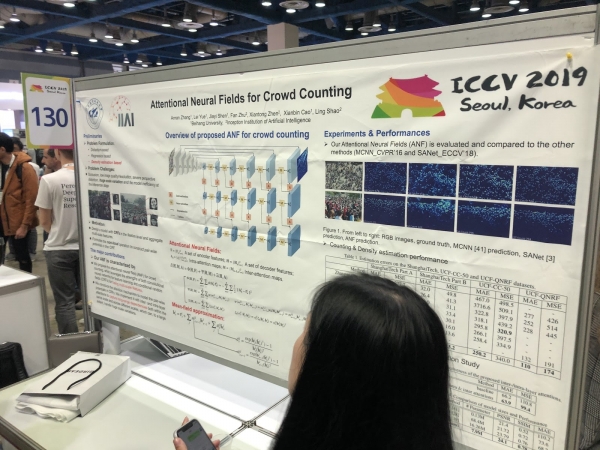
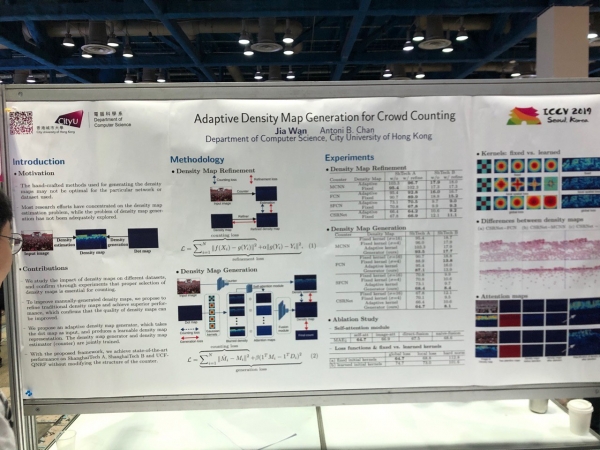
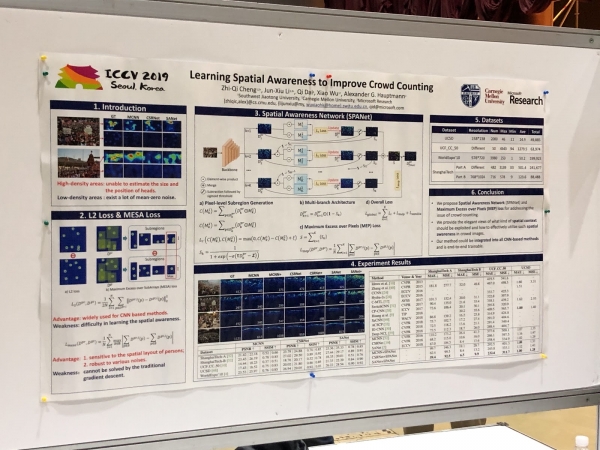


Ma Facebook, à u cuntrariu, anonimizeghja a foto. È face questu in una manera interessante: entrena a rete neurale per generà una faccia senza dettagli unichi - simili, ma micca cusì simili chì pò esse identificatu currettamente da i sistemi di ricunniscenza facciale.

Prutezzione contr'à attacchi avversari
Cù u sviluppu di l'applicazioni di visione di l'informatica in u mondu reale (in vitture autoguidati, in a ricunniscenza faciale), a quistione di l'affidabilità di tali sistemi si sviluppa sempre più. Per usà cumplettamente CV, avete bisognu à esse sicuru chì u sistema hè resistente à l'attacchi avversarii - per quessa, ùn ci era micca menu articuli nantu à a prutezzione contru à elli cà l'attacchi stessi. Ci hè statu assai travagliu nantu à spiegà e previsioni di a rete (mappa di salienza) è a misurazione di a fiducia in u risultatu.
I travaglii cumminati
In a maiò parte di i travaglii cù un scopu, e pussibulità di migliurà a qualità sò praticamente esaurite una di e novi direzzione per più cresce a qualità hè di insignà e rete neurali per risolve parechji prublemi simili simultaneamente. Esempii:
- predizione d'azzione + predizione di flussu otticu,
- presentazione video + presentazione in lingua (),
- .
Ci sò ancu articuli nantu à a segmentazione, a determinazione di posa è a re-identificazione di l'animali!

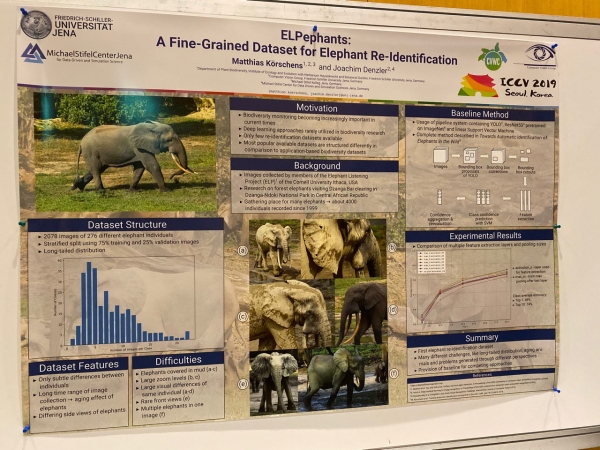
Highlights
Quasi tutti l'articuli eranu cunnisciuti in anticipu, u testu era dispunibule nantu à arXiv.org. Per quessa, a presentazione di tali opere cum'è Everybody Dance Now, FUNIT, Image2StyleGAN pari piuttostu strana - queste sò opere assai utili, ma micca novi. Sembra chì u prucessu classicu di publicazioni scientifiche si sguassate quì - a scienza si move troppu rapidamente.
Hè assai difficiuli di determinà i migliori travaglii - ci sò assai di elli, i sughjetti sò diffirenti. Parechji articuli ricevuti .
Vulemu mette in risaltu i travaglii chì sò interessanti da u puntu di vista di a manipulazione di l'imaghjini, postu chì questu hè u nostru tema. Ci sò stati assai freschi è interessanti per noi (ùn pretendemu micca di esse ughjettivi).
SinGAN (premiu di u megliu carta) è InGAN
SinGAN: , , .
InGAN: , , .
Sviluppu di l'idea Deep Image Priore da Dmitry Ulyanov, Andrea Vedaldi è Victor Lempitsky. Invece di furmà un GAN nantu à un dataset, e rete amparanu da frammenti di a listessa stampa per ricurdà e statistiche in questu. A rete furmata permette di edità è animate e foto (SinGAN) o generà novi imaghjini di ogni dimensione da e texture di l'imaghjini originale, priservendu a struttura lucale (InGAN).
SinGAN:

InGAN:

Videndu ciò chì un GAN ùn pò micca generà
.
E rete neurali chì generanu l'imaghjini spessu piglianu un vettore di rumore aleatoriu cum'è input. In una reta furmata, assai vettori di input formanu un spaziu, picculi movimenti longu chì portanu à picculi cambiamenti in a stampa. Utilizendu l'ottimisazione, pudete risolve u prublema inversu: truvate un vettore di input adattatu per una stampa da u mondu reale. L'autore mostra chì ùn hè guasi mai pussibule di truvà una stampa cumplettamente cumpleta in una rete neurale. Certi ogetti in a stampa ùn sò micca generati (apparentemente per via di a grande variabilità di questi ogetti).
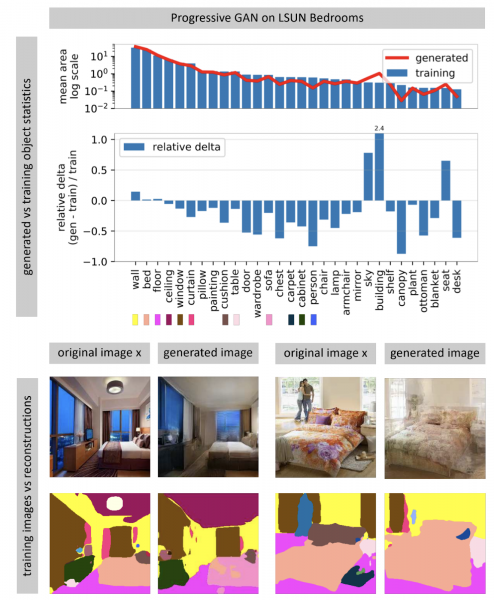
L'autore hypothesizes chì GAN ùn copre micca tuttu u spaziu di l'imaghjini, ma solu qualchi subset, stuffed with holes, like fromage. Quandu pruvemu di truvà e foto di u mondu reale in questu, sempre falleremu, perchè GAN ùn genera micca sempre e foto veri. E sferenze trà l'imaghjini veri è generati ponu esse superati solu cambiendu i pesi di a reta, vale à dì, per rinfurzà per una foto specifica.

Quandu a reta hè addestrata in più per una foto specifica, pudete pruvà diverse manipulazioni cù questa imagine. In l'esempiu sottu, una finestra hè stata aghjunta à a foto, è a rete hà ancu generatu riflessioni nantu à l'unità di cucina. Questu significa chì a reta, ancu dopu una furmazione supplementaria per a fotografia, ùn hà micca persu a capacità di vede a cunnessione trà l'uggetti in a scena.

GANalyze: Versu Definizioni Visuali di Proprietà Cognitive Image
, .
Utilizendu l'approcciu di stu travagliu, pudete visualizà è analizà ciò chì a rete neurale hà amparatu. L'autori pruponi di furmà GAN per creà ritratti per quale a reta generarà previsioni specifiche. L'articulu hà utilizatu parechje rete cum'è esempi, cumpresu MemNet, chì predice a memorabilità di foto. Hè risultatu chì per una memorabilità megliu, l'ughjettu in a foto deve:
- esse più vicinu à u centru
- avè una forma più tonda o quadrata è una struttura simplice,
- esse nantu à un fondo uniforme,
- cuntene ochji espressivi (almenu per i ritratti di cani),
- esse più brillanti, più saturati, in certi casi, più rossi.

Liquid Warping GAN: Un quadru unificatu per l'imitazione di u muvimentu umanu, u trasferimentu di l'aspettu è a sintesi di vista novella
, , .
Pipeline per generà ritratti di persone una foto à volta. L'autori mostranu esempi di successu di trasferimentu di u muvimentu di una persona à l'altru, trasferimentu di vestiti trà e persone è generà novi anguli di una persona - tuttu da una fotografia. A cuntrariu di i travaglii precedenti, quì ùn avemu micca usatu punti chjave in 2D (pose), ma una maglia 3D di u corpu (pose + forma) per creà cundizioni. L'autori anu capitu ancu cumu trasfiriri l'infurmazioni da l'imaghjini uriginale à a generata (Liquid Warping Block). I risultati pareanu decentu, ma a risoluzione di l'imaghjini resultanti hè solu 256x256. Per paragunà, vid2vid, chì hè apparsu un annu fà, hè capaci di generà in una risoluzione di 2048x1024, ma esige quant'è 10 minuti di registrazione video cum'è dataset.

FSGAN: Subject Agnostic Face Swapping and Reenactment
, .
À u principiu, pare chì ùn ci hè nunda inusual: un deepfake cù una qualità più o menu normale. Ma u principale realizazione di u travagliu hè a sustituzione di facci da una stampa. A cuntrariu di i travaglii precedenti, a furmazione era necessaria in parechje ritratti di una persona specifica. U pipeline hè diventatu cumbersome (reenactment and segmentation, view interpolation, inpainting, blending) è cù assai pirate tecnichi, ma u risultatu vale a pena.

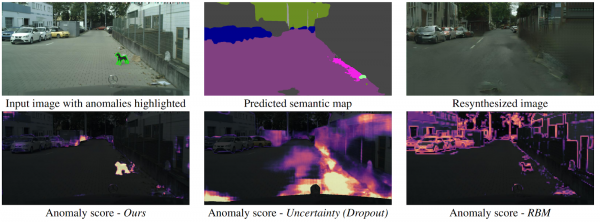
Detecting the Unexpected via Image Resynthesis
.
Cumu pò un drone capisce chì un ughjettu hè apparsu di colpu davanti à ellu chì ùn cascà in alcuna classa di segmentazione semantica? Ci sò parechji metudi, ma l'autori prupone un algoritmu novu intuitivu chì travaglia megliu cà i so predecessori. A segmentazione semantica hè prevista da l'immagine stradale di input. Hè alimentatu cum'è input à u GAN (pix2pixHD), chì prova di restaurà l'imaghjini originale solu da a mappa semantica. L'anomalii chì ùn cascà micca in alcunu di i segmenti differiscenu significativamente in l'output è l'imaghjini generati. E trè imagine (uriginale, segmentazione è ricustruita) sò allora alimentate in una altra reta chì predice anomalie. U dataset per questu hè statu generatu da u famosu Cityscapes dataset, cambiendu aleatoriamente e classi nantu à a segmentazione semantica. Curiosamente, in questu locu, un cane chì si trova à mezu à a strada, ma segmentatu currettamente (chì significa chì ci hè una classa per questu), ùn hè micca una anomalia, postu chì u sistema hà sappiutu ricunnosce.
cunchiusioni
Prima di a cunferenza, hè impurtante sapè quale sò i vostri interessi scientifichi, quali presentazioni vulete assistisce, è cun quale parlà. Allora tuttu serà assai più pruduttivu.
ICCV hè, prima di tuttu, networking. Avete capitu chì ci sò istituti superiori è dipartimenti scientifichi superiori, cuminciate à capisce questu, cunnosce a ghjente. È pudete leghje articuli nantu à arXiv - è per via, hè assai bellu chì ùn avete micca bisognu di andà in ogni locu per acquistà a cunniscenza.
Inoltre, à a cunferenza pudete immerse in fondu in temi chì ùn sò micca vicinu à voi è vede e tendenze. Ebbè, scrivite una lista di articuli per leghje. Sè vo site un studiente, questu hè l'uppurtunità di scuntrà un prufessore potenziale, sè vo site da l'industria, allora cù un novu patronu, è se una cumpagnia, allora per vede.
Arrugà si à ! Questu hè un prughjettu persunale: u conducemu inseme . Avemu postu tutti l'opere chì ci sò piaciuti durante a cunferenza quì : .
Source: www.habr.com
