


SRE (Site Reliability Engineering) er en tilgang til at sikre tilgængeligheden af webprojekter. Det betragtes som en ramme for DevOps og taler om, hvordan man opnår succes med at anvende DevOps-praksis. Oversættelse i denne artikel bøger fra Google. Jeg udarbejdede selv denne oversættelse og stolede på min egen erfaring med at forstå overvågningsprocesser. I telegramkanalen и Jeg udgav også en oversættelse af kapitel 6 i samme bog om serviceniveaumål.
Oversættelse af kat. God fornøjelse med at læse!
Det er umuligt at administrere en service, hvis der ikke er en forståelse af, hvilke indikatorer der rent faktisk betyder noget, og hvordan man måler og evaluerer dem. Til dette formål definerer og leverer vi et vist serviceniveau til vores brugere, uanset om de bruger en af vores interne API'er eller et offentligt produkt.
Vi bruger vores intuition, erfaring og forståelse af brugernes ønske om at forstå Service Level Indicators (SLI'er), Service Level Objectives (SLO'er) og Service Level Agreements (SLA'er). Disse dimensioner beskriver de vigtigste målinger, som vi ønsker at overvåge, og som vi vil reagere på, hvis vi ikke kan levere den forventede servicekvalitet. I sidste ende hjælper valget af de rigtige målinger med at guide de rigtige handlinger, hvis noget går galt, og giver også SRE-teamet tillid til tjenestens sundhed.
Dette kapitel beskriver den tilgang, vi bruger til at bekæmpe problemerne med metrisk modellering, metrisk udvælgelse og metrisk analyse. Det meste af forklaringen vil være uden eksempler, så vi vil bruge Shakespeare-tjenesten beskrevet i dens implementeringseksempel (søg efter Shakespeares værker) til at illustrere hovedpunkterne.
Serviceniveau terminologi
Mange læsere er sandsynligvis bekendt med begrebet SLA, men begreberne SLI og SLO fortjener en omhyggelig definition, fordi begrebet SLA generelt er overbelastet og har en række betydninger afhængigt af konteksten. For klarhedens skyld ønsker vi at adskille disse værdier.
Indikatorer
SLI er en serviceniveauindikator - et nøje defineret kvantitativt mål for et aspekt af det leverede serviceniveau.
For de fleste tjenester anses nøgle-SLI for at være anmodningsforsinkelse - hvor lang tid det tager at returnere et svar på en anmodning. Andre almindelige SLI'er omfatter fejlfrekvens, ofte udtrykt som en brøkdel af alle modtagne anmodninger, og systemgennemstrømning, normalt målt i anmodninger pr. sekund. Målinger er ofte aggregerede: rådata indsamles først og konverteres derefter til en ændringshastighed, middelværdi eller percentil.
Ideelt set måler SLI direkte serviceniveauet af interesse, men nogle gange er kun en relateret metrik tilgængelig for måling, fordi den originale er svær at opnå eller fortolke. For eksempel er latenstid på klientsiden ofte en mere passende metrik, men der er tidspunkter, hvor latens kun kan måles på serveren.
En anden type SLI, der er vigtig for SRE'er, er tilgængelighed eller den del af tiden, hvor en tjeneste kan bruges. Ofte defineret som antallet af vellykkede anmodninger, nogle gange kaldet udbytte. (Lifetime, sandsynligheden for, at data vil blive opbevaret i en længere periode, er også vigtig for datalagringssystemer.) Selvom 100 % tilgængelighed ikke er mulig, er tilgængelighed tæt på 100 % ofte opnåelig, tilgængelighedsværdier udtrykt som antallet af "ni" af tilgængelighedsprocenten. For eksempel kan 99 % og 99,999 % tilgængelighed mærkes som "2 niere" og "5 niere". Google Compute Engines nuværende erklærede tilgængelighedsmål er "tre en halv ni" eller 99,95 %.
mål
En SLO er et serviceniveaumål: en målværdi eller et værdiområde for et serviceniveau, der måles af SLI. En normal værdi for SLO er "SLI ≤ Target" eller "Lower Limit ≤ SLI ≤ Upper Limit". For eksempel kan vi beslutte, at vi vil returnere Shakespeare-søgeresultater "hurtigt" ved at indstille SLO til en gennemsnitlig latenstid for søgeforespørgsler på mindre end 100 millisekunder.
At vælge den rigtige SLO er en kompleks proces. For det første kan du ikke altid vælge en bestemt værdi. For eksterne indkommende HTTP-anmodninger til din tjeneste bestemmes Query Per Second (QPS)-metrikken primært af dine brugeres ønske om at besøge din tjeneste, og du kan ikke indstille en SLO for dette.
På den anden side kan du sige, at du ønsker, at den gennemsnitlige latens for hver anmodning skal være mindre end 100 millisekunder. At sætte et sådant mål kan tvinge dig til at skrive din frontend med lav latenstid eller købe udstyr, der giver en sådan latency. (100 millisekunder er naturligvis et vilkårligt tal, men det er bedre at have endnu lavere latency-tal. Der er beviser, der tyder på, at hurtige hastigheder er bedre end langsomme hastigheder, og at latens i behandlingen af brugeranmodninger over bestemte værdier faktisk tvinger folk til at holde sig væk fra din tjeneste.)
Igen er dette mere tvetydigt, end det kan se ud ved første øjekast: du bør ikke helt udelukke QPS fra beregningen. Faktum er, at QPS og latency er stærkt relateret til hinanden: højere QPS fører ofte til højere latenser, og tjenester oplever normalt et kraftigt fald i ydeevnen, når de når en vis belastningstærskel.
Valg og udgivelse af en SLO sætter brugernes forventninger til, hvordan tjenesten vil fungere. Denne strategi kan reducere ubegrundede klager mod tjenesteejeren, såsom langsom ydeevne. Uden et eksplicit SLO skaber brugerne ofte deres egne forventninger om ønsket ydeevne, hvilket måske ikke har noget at gøre med meningerne fra de personer, der designer og administrerer tjenesten. Denne situation kan føre til oppustede forventninger fra tjenesten, når brugere fejlagtigt tror, at tjenesten vil være mere tilgængelig, end den faktisk er, og forårsage mistillid, når brugere mener, at systemet er mindre pålideligt, end det faktisk er.
Aftaler
En serviceniveauaftale er en eksplicit eller implicit kontrakt med dine brugere, der inkluderer konsekvenserne af at opfylde (eller ikke opfylde) de SLO'er, de indeholder. Konsekvenser er nemmest at genkende, når de er økonomiske – en rabat eller en bøde – men de kan antage andre former. En nem måde at tale om forskellen mellem SLO'er og SLA'er er at spørge "hvad sker der, hvis SLO'erne ikke opfyldes?" Hvis der ikke er klare konsekvenser, ser du næsten helt sikkert på en SLO.
SRE er typisk ikke involveret i at oprette SLA'er, fordi SLA'er er tæt knyttet til forretnings- og produktbeslutninger. SRE er dog involveret i at hjælpe med at afbøde konsekvenserne af fejlslagne SLO'er. De kan også hjælpe med at bestemme SLI: Det er klart, at der skal være en objektiv måde at måle SLO på i aftalen, ellers vil der være uenighed.
Google Søgning er et eksempel på en vigtig tjeneste, der ikke har en offentlig SLA: Vi ønsker, at alle skal bruge Søgning så effektivt som muligt, men vi har ikke underskrevet en kontrakt med verden. Der er dog stadig konsekvenser, hvis søgning ikke er tilgængelig - utilgængelighed resulterer i et fald i vores omdømme samt reducerede annonceindtægter. Mange andre Google-tjenester, såsom Google for Work, har eksplicitte serviceniveauaftaler med brugere. Uanset om en bestemt tjeneste har en SLA, er det vigtigt at definere SLI og SLO og bruge dem til at administrere tjenesten.
Så meget teori - nu til oplevelse.
Indikatorer i praksis
I betragtning af, at vi har konkluderet, at det er vigtigt at vælge passende metrics til at måle serviceniveauet, hvordan ved du nu, hvilke metrics, der betyder noget for en tjeneste eller et system?
Hvad bekymrer dig og dine brugere om?
Du behøver ikke at bruge alle målinger som en SLI, som du kan spore i et overvågningssystem; At forstå, hvad brugerne ønsker fra et system, vil hjælpe dig med at vælge flere metrics. At vælge for mange indikatorer gør det svært at fokusere på vigtige indikatorer, mens valg af et lille antal kan efterlade store bidder af dit system uden opsyn. Vi bruger typisk flere nøgleindikatorer til at evaluere og forstå et systems sundhed.
Tjenester kan generelt opdeles i flere dele i form af SLI, der er relevante for dem:
- Tilpassede front-end-systemer, såsom søgegrænseflader til Shakespeare-tjenesten fra vores eksempel. De skal være tilgængelige, ikke have forsinkelser og have tilstrækkelig båndbredde. Derfor kan der stilles spørgsmål: kan vi svare på anmodningen? Hvor lang tid tog det at besvare anmodningen? Hvor mange anmodninger kan behandles?
- Opbevaringssystemer. De værdsætter lav responsforsinkelse, tilgængelighed og holdbarhed. Relaterede spørgsmål: Hvor lang tid tager det at læse eller skrive data? Kan vi få adgang til dataene efter anmodning? Er dataene tilgængelige, når vi har brug for dem? Se Kapitel 26 Dataintegritet: Det du læser er det du skriver for en detaljeret diskussion af disse spørgsmål.
- Big data-systemer såsom databehandlingspipelines er afhængige af gennemløb og forespørgselsbehandlingsforsinkelse. Relaterede spørgsmål: Hvor meget data behandles? Hvor lang tid tager det for data at rejse fra modtagelse af en anmodning til afgivelse af et svar? (Nogle dele af systemet kan også have forsinkelser i visse faser.)
Indsamling af indikatorer
Mange serviceniveauindikatorer indsamles mest naturligt på serversiden ved hjælp af et overvågningssystem som Borgmon (se nedenfor). ) eller Prometheus, eller blot periodisk analysere logfilerne for HTTP-svar med en status på 500. Nogle systemer bør dog udstyres med indsamling af klient-side metrics, da manglen på klient-side overvågning kan føre til, at man går glip af en række problemer, der påvirker brugerne, men som ikke påvirker server-side metrics. For eksempel kan fokus på backend-svar-latensen i vores Shakespeare-søgetest-applikation resultere i latency på brugersiden på grund af JavaScript-problemer: i dette tilfælde er måling af, hvor lang tid det tager browseren at behandle siden, en bedre metrik.
Aggregation
For enkelhedens skyld og brugervenligheden samler vi ofte rå målinger. Dette skal gøres omhyggeligt.
Nogle målinger virker enkle, som anmodninger per sekund, men selv denne tilsyneladende ligetil måling samler implicit data over tid. Modtages målingen specifikt én gang i sekundet, eller er målingen beregnet i gennemsnit over antallet af anmodninger i minuttet? Sidstnævnte mulighed kan skjule et meget højere øjeblikkeligt antal forespørgsler, der kun varer et par sekunder. Overvej et system, der betjener 200 anmodninger i sekundet med lige tal og 0 resten af tiden. En konstant i form af en gennemsnitsværdi på 100 anmodninger i sekundet og to gange den øjeblikkelige belastning er ikke det samme. På samme måde kan gennemsnitsberegning af forespørgselsforsinkelser virke attraktivt, men det skjuler en vigtig detalje: Det er muligt, at de fleste forespørgsler vil være hurtige, men der vil være mange forespørgsler, der er langsomme.
De fleste indikatorer ses bedre som fordelinger frem for gennemsnit. For eksempel, for SLI latency, vil nogle anmodninger blive behandlet hurtigt, mens nogle altid vil tage længere tid, nogle gange meget længere. Et simpelt gennemsnit kan skjule disse lange forsinkelser. Figuren viser et eksempel: Selvom en typisk anmodning tager cirka 50 ms at blive serveret, er 5 % af anmodningerne 20 gange langsommere! Overvågning og alarmering baseret kun på gennemsnitlig latenstid viser ikke ændringer i adfærd i løbet af dagen, når der faktisk er mærkbare ændringer i behandlingstiden for nogle anmodninger (øverste linje).
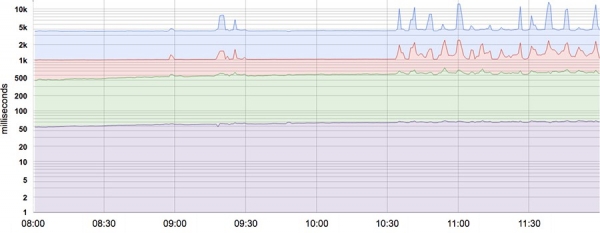
Systemlatens på 50, 85, 95 og 99 percentiler. Y-aksen er i logaritmisk format.
Brug af percentiler til indikatorer giver dig mulighed for at se fordelingens form og dens karakteristika: et højt percentilniveau, såsom 99 eller 99,9, viser den dårligste værdi, mens 50 percentilen (også kendt som medianen) viser den hyppigste tilstand af metrikken. Jo større spredning af responstid, jo flere langvarige anmodninger påvirker brugeroplevelsen. Effekten forstærkes under høj belastning og ved tilstedeværelse af køer. Brugeroplevelsesundersøgelser har vist, at folk generelt foretrækker et langsommere system med høj responstidsvarians, så nogle SRE-teams fokuserer kun på høje percentilscores, på det grundlag, at hvis metrikkens adfærd ved 99,9 percentilen er god, vil de fleste brugere ikke opleve problemer.
Bemærkning om statistiske fejl
Vi foretrækker generelt at arbejde med percentiler frem for middelværdien (aritmetisk middelværdi) af et sæt værdier. Dette giver os mulighed for at overveje mere spredte værdier, som ofte har væsentligt anderledes (og mere interessante) egenskaber end gennemsnittet. På grund af computersystemernes kunstige karakter er metriske værdier ofte skæve, således at ingen anmodning kan modtage et svar på mindre end 0 ms, og en timeout på 1000 ms betyder, at der ikke kan være vellykkede svar med værdier, der er større end timeout. Som et resultat kan vi ikke acceptere, at middelværdien og medianen kan være ens eller tæt på hinanden!
Uden forudgående test, og medmindre visse standardantagelser og tilnærmelser holder, er vi forsigtige med ikke at konkludere, at vores data er normalt distribueret. Hvis distributionen ikke er som forventet, kan automatiseringsprocessen, der løser problemet (når den f.eks. ser afvigere, genstarter serveren med høje anmodningsbehandlingsforsinkelser) gøre det for ofte eller ikke ofte nok (begge dele er ikke særlig gode).
Standardiser indikatorer
Vi anbefaler at standardisere de generelle karakteristika for SLI, så du ikke behøver at spekulere i dem hver gang. Enhver funktion, der opfylder standardmønstre, kan udelukkes fra specifikationen for en individuel SLI, for eksempel:
- Aggregeringsintervaller: "gennemsnit over 1 minut"
- Aggregeringsområder: "Alle opgaver i klyngen"
- Hvor ofte måles der: "Hvert 10. sekund"
- Hvilke anmodninger er inkluderet: "HTTP GET fra black box-overvågningsjob"
- Sådan opnås dataene: "Takket være vores overvågning målt på serveren"
- Dataadgangsforsinkelse: "Tid til sidste byte"
For at spare indsats skal du oprette et sæt genanvendelige SLI-skabeloner for hver fælles metrik; de gør det også lettere for alle at forstå, hvad en bestemt SLI betyder.
Mål i praksis
Start med at tænke over (eller finde ud af!), hvad dine brugere interesserer sig for, ikke hvad du kan måle. Det er ofte svært eller umuligt at måle, hvad dine brugere interesserer sig for, så du ender med at komme tættere på deres behov. Men hvis du bare starter med det, der er nemt at måle, ender du med mindre nyttige SLO'er. Som følge heraf har vi nogle gange oplevet, at det i første omgang at identificere ønskede mål og derefter arbejde med specifikke indikatorer fungerer bedre end at vælge indikatorer og derefter nå målene.
Definer dine mål
For maksimal klarhed bør det defineres, hvordan SLO'er måles, og under hvilke betingelser de er gyldige. For eksempel kunne vi sige følgende (den anden linje er den samme som den første, men bruger SLI-standardindstillingerne):
- 99 % (i gennemsnit over 1 minut) af Get RPC-opkald vil gennemføre på mindre end 100 ms (målt på tværs af alle backend-servere).
- 99 % af Get RPC-opkald afsluttes på mindre end 100 ms.
Hvis formen på præstationskurverne er vigtig, kan du angive flere SLO'er:
- 90 % af Få RPC-opkald gennemført på mindre end 1 ms.
- 99 % af Få RPC-opkald gennemført på mindre end 10 ms.
- 99.9% Få RPC-kald udført på under 100 ms.
Hvis dine brugere genererer heterogene arbejdsbelastninger: massebehandling (hvor gennemløb er vigtigt) og interaktiv behandling (hvor latens er vigtig), kan det være umagen værd at definere separate mål for hver belastningsklasse:
- 95 % af kundernes anmodninger kræver gennemløb. Indstil antallet af udførte RPC-kald <1 s.
- 99 % af kunderne bekymrer sig om latensen. Indstil antallet af RPC-opkald med trafik <1 KB og kører <10 ms.
Det er urealistisk og uønsket at insistere på, at SLO'er vil blive opfyldt 100 % af tiden: Dette kan reducere tempoet i at introducere ny funktionalitet og implementering og kræve dyre løsninger. I stedet er det bedre at tillade et fejlbudget - procentdelen af systemets nedetid tilladt - og overvåge denne værdi dagligt eller ugentligt. Den øverste ledelse ønsker måske månedlige eller kvartalsvise evalueringer. (Fejlbudgettet er simpelthen en SLO til sammenligning med en anden SLO.)
Procentdelen af SLO-overtrædelser kan sammenlignes med fejlbudgettet (se kapitel 3 og pkt ), med forskelsværdien brugt som input til processen, der bestemmer, hvornår nye udgivelser skal implementeres.
Valg af målværdier
Valg af planlægningsværdier (SLO'er) er ikke en rent teknisk aktivitet på grund af produkt- og forretningsinteresser, der skal afspejles i de valgte SLI'er, SLO'er (og muligvis SLA'er). Ligeledes kan det være nødvendigt at udveksle oplysninger vedrørende spørgsmål relateret til bemanding, time to market, tilgængelighed af udstyr og finansiering. SRE bør være en del af denne samtale og hjælpe med at forstå risici og levedygtighed ved forskellige muligheder. Vi har stillet et par spørgsmål, der kan være med til at sikre en mere produktiv diskussion:
Vælg ikke et mål baseret på den aktuelle præstation.
Selvom det er vigtigt at forstå et systems styrker og begrænsninger, kan tilpasning af målinger uden begrundelse blokere dig for at vedligeholde systemet: det vil kræve heroiske anstrengelser for at nå mål, der ikke kan nås uden væsentlig redesign.
Hold det enkelt
Komplekse SLI-beregninger kan skjule ændringer i systemets ydeevne og gøre det sværere at finde årsagen til problemet.
Undgå absolutter
Selvom det er fristende at have et system, der kan håndtere en uendeligt voksende belastning uden at øge latens, er dette krav urealistisk. Et system, der nærmer sig sådanne idealer, vil sandsynligvis kræve en masse tid at designe og bygge, vil være dyrt at betjene og vil være for godt til forventningerne hos brugere, der ville gøre med noget mindre.
Brug så få SLO'er som muligt
Vælg et tilstrækkeligt antal SLO'er for at sikre god dækning af systemattributter. Beskyt de SLO'er, du vælger: Hvis du aldrig kan vinde et argument om prioriteter ved at angive en specifik SLO, er det nok ikke værd at overveje det SLO. Det er dog ikke alle systemattributter, der er tilgængelige for SLO'er: det er svært at beregne niveauet af brugerglæde ved at bruge SLO'er.
Gå ikke efter perfektion
Du kan altid forfine definitionerne og målene for SLO'er over tid, efterhånden som du lærer mere om systemets adfærd under belastning. Det er bedre at starte med et flydende mål, som du vil forfine over tid, end at vælge et alt for strengt mål, der skal slappes af, når du finder det uopnåeligt.
SLO'er kan og bør være en central drivkraft i at prioritere arbejde for SRE'er og produktudviklere, fordi de afspejler en bekymring for brugerne. En god SLO er et nyttigt håndhævelsesværktøj for et udviklingsteam. Men en dårligt designet SLO kan føre til spildarbejde, hvis teamet gør en heroisk indsats for at opnå en alt for aggressiv SLO, eller et dårligt produkt, hvis SLO er for lav. SLO er en kraftfuld løftestang, brug den med omtanke.
Styr dine målinger
SLI og SLO er nøgleelementer, der bruges til at styre systemer:
- Overvåg og mål SLI-systemer.
- Sammenlign SLI med SLO og beslut om handling er nødvendig.
- Hvis handling er påkrævet, skal du finde ud af, hvad der skal ske for at nå målet.
- Fuldfør denne handling.
For eksempel, hvis trin 2 viser, at anmodningsforsinkelsen stiger og vil bryde SLO'en om et par timer, hvis der ikke gøres noget, kan trin 3 involvere at teste hypotesen om, at serverne er CPU-bundne, og tilføjelse af flere servere vil fordele belastningen. Uden en SLO ville du ikke vide, om (eller hvornår) du skulle handle.
Indstil SLO - så vil brugernes forventninger blive sat
Udgivelse af en SLO angiver brugernes forventninger til systemets adfærd. Brugere (og potentielle brugere) ønsker ofte at vide, hvad de kan forvente af en tjeneste for at forstå, om den er egnet til brug. For eksempel vil folk, der ønsker at bruge et fotodelingswebsted, måske undgå at bruge en tjeneste, der lover lang levetid og lave omkostninger i bytte for lidt mindre tilgængelighed, selvom den samme tjeneste kan være ideel til et arkivregistreringssystem.
For at sætte realistiske forventninger til dine brugere, brug en eller begge af følgende taktikker:
- Oprethold en sikkerhedsmargin. Brug en strengere intern SLO end hvad der annonceres for brugerne. Dette vil give dig mulighed for at reagere på problemer, før de bliver synlige udadtil. SLO-bufferen giver dig også mulighed for at have en sikkerhedsmargin, når du installerer udgivelser, der påvirker systemets ydeevne og sikrer, at systemet er nemt at vedligeholde uden at skulle frustrere brugerne med nedetid.
- Overgå ikke brugernes forventninger. Brugere er baseret på, hvad du tilbyder, ikke hvad du siger. Hvis den faktiske ydeevne af din tjeneste er meget bedre end den angivne SLO, vil brugerne stole på den aktuelle ydeevne. Du kan undgå overafhængighed ved bevidst at lukke systemet ned eller begrænse ydeevnen under lette belastninger.
At forstå, hvor godt et system lever op til forventningerne, hjælper med at beslutte, om der skal investeres i at fremskynde systemet og gøre det mere tilgængeligt og robust. Alternativt, hvis en tjeneste yder for godt, bør noget personaletid bruges på andre prioriteter, såsom at betale teknisk gæld, tilføje nye funktioner eller introducere nye produkter.
Aftaler i praksis
Oprettelse af en SLA kræver, at forretnings- og juridiske teams definerer konsekvenserne og sanktionerne for at overtræde den. SRE's rolle er at hjælpe dem med at forstå de sandsynlige udfordringer ved at opfylde SLO'erne i SLA'en. De fleste af anbefalingerne til oprettelse af SLO'er gælder også for SLA'er. Det er klogt at være konservativ i det, du lover brugerne, for jo mere du har, jo sværere er det at ændre eller fjerne SLA'er, der virker urimelige eller svære at opfylde.
Tak fordi du læste oversættelsen til slutningen. Abonner på min telegramkanal om overvågning и .
Kilde: www.habr.com
