


SRE (Site Reliability Engineering) on tapa tehdä verkkoprojekteista saavutettavia. Sitä pidetään DevOpsin viitekehyksenä ja se kertoo kuinka onnistua DevOps-käytäntöjen soveltamisessa. Tämä artikkeli käännetään kirjat Googlelta. Tein tämän käännöksen itse ja luotin omaan kokemukseeni seurantaprosessien ymmärtämisessä. Telegram-kanavalla и Julkaisin myös käännöksen saman kirjan palvelutason tavoitteita käsittelevästä luvusta 6.
Käännös kissalta. Nauti lukemisesta!
Palvelun johtaminen on mahdotonta, jos ei ole ymmärrystä siitä, millä indikaattoreilla oikeasti on merkitystä ja miten niitä mitataan ja arvioidaan. Tätä varten määritämme ja tarjoamme käyttäjillemme tietyn tason palvelua riippumatta siitä, käyttävätkö he jotakin sisäistä API-rajapintaamme vai julkista tuotetta.
Käytämme intuitiota, kokemusta ja ymmärrystä käyttäjien halusta ymmärtää palvelutason indikaattoreita (SLI), palvelutason tavoitteita (SLO) ja palvelutasosopimuksia (SLA). Nämä mitat kuvaavat tärkeimpiä mittareita, joita haluamme seurata ja joihin reagoimme, jos emme pysty tarjoamaan odotettua palvelun laatua. Viime kädessä oikeiden mittareiden valitseminen auttaa ohjaamaan oikeita toimia, jos jokin menee pieleen, ja antaa myös SRE-tiimille luottamusta palvelun kuntoon.
Tässä luvussa kuvataan lähestymistapa, jota käytämme metrisen mallintamisen, metrijärjestelmän valinnan ja metrijärjestelmän analyysin ongelmien torjumiseksi. Suurin osa selityksistä tulee olemaan ilman esimerkkejä, joten käytämme pääkohtien havainnollistamiseen sen toteutusesimerkissä kuvattua Shakespeare-palvelua (haku Shakespearen teoksia).
Palvelutason terminologia
Monet lukijat tuntevat todennäköisesti SLA:n käsitteen, mutta termit SLI ja SLO ansaitsevat huolellisen määrittelyn, koska yleensä termi SLA on ylikuormitettu ja sillä on useita merkityksiä kontekstista riippuen. Selvyyden vuoksi haluamme erottaa nämä arvot toisistaan.
Indikaattorit
SLI on palvelutason indikaattori – tarkasti määritelty määrällinen mitta yhdestä tarjotun palvelun tason näkökulmasta.
Useimmissa palveluissa SLI-avain katsotaan pyyntöviiveeksi – kuinka kauan kestää vastauksen palauttamiseen pyyntöön. Muita yleisiä SLI:itä ovat virheprosentti, joka ilmaistaan usein murto-osana kaikista vastaanotetuista pyynnöistä, ja järjestelmän suorituskyky, joka mitataan yleensä pyyntöinä sekunnissa. Mittaukset ovat usein aggregoituja: raakadata kerätään ensin ja muunnetaan sitten muutosnopeudeksi, keskiarvoksi tai prosenttipisteeksi.
Ihannetapauksessa SLI mittaa suoraan kiinnostavaa palvelutasoa, mutta joskus mittaukseen on käytettävissä vain siihen liittyvä mittari, koska alkuperäistä on vaikea saada tai tulkita. Esimerkiksi asiakaspuolen viive on usein sopivampi mittari, mutta joskus viivettä voidaan mitata vain palvelimella.
Toinen SLI:n tyyppi, joka on tärkeä SRE:lle, on saatavuus tai aika, jonka aikana palvelua voidaan käyttää. Määritetään usein onnistuneiden pyyntöjen määräksi, jota joskus kutsutaan tuotoksi. (Elinikä – todennäköisyys, että tietoja säilytetään pitkiä aikoja – on myös tärkeää tiedontallennusjärjestelmille.) Vaikka 100 %:n saatavuus ei ole mahdollista, lähes 100 %:n saatavuus on usein saavutettavissa; käytettävyysarvot ilmaistaan "yhdeksän" » saatavuusprosentti. Esimerkiksi 99 % ja 99,999 % saatavuus voidaan merkitä "2 yhdeksän" ja "5 yhdeksän". Google Compute Enginen tämänhetkinen ilmoitettu saatavuustavoite on "kolme ja puoli yhdeksän" eli 99,95 %.
tavoitteet
SLO on palvelutason tavoite: SLI:n mittaama tavoitearvo tai arvoalue palvelutasolle. Normaali arvo SLO:lle on “SLI ≤ Tavoite” tai “Alaraja ≤ SLI ≤ Yläraja”. Saatamme esimerkiksi päättää, että palautamme Shakespearen hakutulokset "nopeasti" asettamalla SLO:n keskimääräiseksi hakukyselyn viiveeksi, joka on alle 100 millisekuntia.
Oikean SLO:n valinta on monimutkainen prosessi. Ensinnäkin et voi aina valita tiettyä arvoa. Palveluusi saapuvien ulkoisten HTTP-pyyntöjen osalta Query Per Second (QPS) -mittari määräytyy ensisijaisesti käyttäjien halun vierailla palvelussasi, etkä voi asettaa SLO:ta sille.
Toisaalta voit sanoa, että haluat kunkin pyynnön keskimääräisen latenssin olevan alle 100 millisekuntia. Tällaisen tavoitteen asettaminen saattaa pakottaa sinut kirjoittamaan käyttöliittymäsi alhaisella viiveellä tai ostamaan laitteita, jotka tarjoavat tällaisen viiveen. (100 millisekuntia on tietysti mielivaltainen luku, mutta on parempi, että viiveluvut ovat vielä pienemmät. On näyttöä siitä, että nopeat nopeudet ovat parempia kuin hitaat ja että tiettyjä arvoja suurempi viive käyttäjien pyyntöjen käsittelyssä pakottaa ihmiset pysymään poissa palvelustasi.)
Tämä on jälleen epäselvämpi kuin miltä ensi silmäyksellä näyttää: sinun ei pitäisi sulkea QPS:ää kokonaan pois laskelmasta. Tosiasia on, että QPS ja latenssi liittyvät vahvasti toisiinsa: korkeampi QPS johtaa usein korkeampiin latenssiaikoihin, ja palveluiden suorituskyky heikkenee yleensä jyrkästi, kun ne saavuttavat tietyn kuormitusrajan.
SLO:n valitseminen ja julkaiseminen asettaa käyttäjien odotuksia palvelun toimivuudesta. Tämä strategia voi vähentää perusteettomia valituksia palvelun omistajaa kohtaan, kuten hidasta suorituskykyä. Ilman selkeää SLO:ta käyttäjät luovat usein omat odotuksensa halutusta suorituskyvystä, joilla ei välttämättä ole mitään tekemistä palvelua suunnittelevien ja hallinnoivien ihmisten mielipiteiden kanssa. Tämä tilanne voi johtaa liioiteltuihin odotuksiin palvelun suhteen, kun käyttäjät virheellisesti uskovat, että palvelu on saatavilla paremmin kuin se todellisuudessa on, ja aiheuttaa epäluottamusta, kun käyttäjät uskovat järjestelmän olevan vähemmän luotettava kuin se todellisuudessa on.
Sopimukset
Palvelutasosopimus on eksplisiittinen tai epäsuora sopimus käyttäjiesi kanssa, joka sisältää sen sisältämien SLO-ehtojen täyttämisen (tai noudattamatta jättämisen) seuraukset. Seuraukset tunnistetaan helpoimmin, kun ne ovat taloudellisia – alennus tai sakko – mutta ne voivat olla myös muita muotoja. Helppo tapa puhua SLO-sopimusten ja SLA-sopimusten eroista on kysyä "mitä tapahtuu, jos SLO-sopimuksia ei täytetä?" Jos selkeitä seurauksia ei ole, katsot lähes varmasti SLO:ta.
SRE ei yleensä osallistu palvelusopimusten luomiseen, koska palvelutasosopimukset liittyvät läheisesti liiketoiminta- ja tuotepäätöksiin. SRE on kuitenkin mukana auttamassa lieventämään epäonnistuneiden SLO:iden seurauksia. Ne voivat myös auttaa määrittämään SLI:n: On selvää, että sopimuksessa on oltava objektiivinen tapa mitata SLO-arvoa, muuten syntyy erimielisyyksiä.
Google-haku on esimerkki tärkeästä palvelusta, jolla ei ole julkista palvelusopimusta: haluamme kaikkien käyttävän hakua mahdollisimman tehokkaasti, mutta emme ole allekirjoittaneet sopimusta maailman kanssa. Siitä huolimatta, että haku ei ole käytettävissä, on seurauksia – epäkäytettävyys johtaa maineemme heikkenemiseen sekä mainostulojen vähenemiseen. Monilla muilla Googlen palveluilla, kuten Google for Workilla, on nimenomaiset palvelutasosopimukset käyttäjien kanssa. Riippumatta siitä, onko tietyllä palvelulla SLA-sopimus, on tärkeää määritellä SLI ja SLO ja käyttää niitä palvelun hallintaan.
Niin paljon teoriaa - nyt kokemaan.
Indikaattorit käytännössä
Koska olemme tulleet siihen tulokseen, että palvelutason mittaamiseen on tärkeää valita sopivat mittarit, mistä tiedät nyt, mitkä mittarit ovat tärkeitä palvelulle tai järjestelmälle?
Mistä sinä ja käyttäjäsi välität?
Sinun ei tarvitse käyttää kaikkia mittareita SLI:nä, jota voit seurata valvontajärjestelmässä. Kun ymmärrät, mitä käyttäjät haluavat järjestelmältä, voit valita useita mittareita. Liian monen indikaattorin valitseminen vaikeuttaa keskittymistä tärkeisiin indikaattoreihin, kun taas pienen määrän valitseminen voi jättää suuret osat järjestelmästäsi ilman valvontaa. Käytämme yleensä useita avainindikaattoreita arvioidaksemme ja ymmärtääksemme järjestelmän kuntoa.
Palvelut voidaan yleensä jakaa useisiin niitä koskeviin SLI-osiin:
- Mukautetut käyttöliittymäjärjestelmät, kuten esimerkkimme Shakespeare-palvelun hakurajapinnat. Niiden on oltava käytettävissä, niissä ei saa olla viiveitä ja niillä on oltava riittävä kaistanleveys. Vastaavasti voidaan esittää kysymyksiä: voimmeko vastata pyyntöön? Kuinka kauan pyyntöön vastaaminen kesti? Kuinka monta pyyntöä voidaan käsitellä?
- Varastointijärjestelmät. He arvostavat alhaista vasteviivettä, saatavuutta ja kestävyyttä. Aiheeseen liittyviä kysymyksiä: Kuinka kauan tietojen lukeminen tai kirjoittaminen kestää? Voimmeko päästä käsiksi tietoihin pyynnöstä? Onko tietoja saatavilla silloin, kun tarvitsemme sitä? Katso luku 26 Tietojen eheys: Mitä luet on mitä kirjoitat saadaksesi yksityiskohtaista keskustelua näistä ongelmista.
- Suuret datajärjestelmät, kuten tietojenkäsittelyputket, riippuvat suorituskyvystä ja kyselyn käsittelyn viiveestä. Aiheeseen liittyviä kysymyksiä: Kuinka paljon dataa käsitellään? Kuinka kauan tietojen kulkeminen pyynnön vastaanottamisesta vastauksen antamiseen kestää? (Joissakin järjestelmän osissa voi myös olla viiveitä tietyissä vaiheissa.)
Indikaattorien kokoelma
Monet palvelutason indikaattorit kerätään luonnollisimmin palvelinpuolelta käyttämällä valvontajärjestelmää, kuten Borgmon (katso alla). ) tai Prometheus, tai yksinkertaisesti ajoittain analysoimalla lokit ja tunnistamalla HTTP-vastaukset, joiden tila on 500. Jotkin järjestelmät tulisi kuitenkin varustaa asiakaspuolen mittareiden keräämisellä, koska asiakaspuolen valvonnan puute voi johtaa useiden ongelmien puuttumiseen. käyttäjiä, mutta ne eivät vaikuta palvelinpuolen mittareihin. Esimerkiksi Shakespeare-hakutestisovelluksemme taustavastausviiveeseen keskittyminen voi johtaa käyttäjäpuolen latenssiin JavaScript-ongelmien vuoksi: tässä tapauksessa parempi mittari on mitata, kuinka kauan selaimelta kuluu sivun käsittelyyn.
Aggregointi
Yksinkertaisuuden ja käytön helpottamiseksi yhdistämme usein raakamittaukset. Tämä on tehtävä huolellisesti.
Jotkut mittarit vaikuttavat yksinkertaisilta, kuten pyynnöt sekunnissa, mutta tämäkin näennäisesti suoraviivainen mittaus kokoaa implisiittisesti tietoja ajan mittaan. Vastaanotetaanko mittaus nimenomaan kerran sekunnissa vai lasketaanko mittauksen keskiarvo pyyntöjen määrästä minuutissa? Jälkimmäinen vaihtoehto voi piilottaa paljon suuremman hetkellisen määrän pyyntöjä, jotka kestävät vain muutaman sekunnin. Harkitse järjestelmää, joka palvelee 200 pyyntöä sekunnissa parillisilla luvuilla ja 0 muun ajan. Vakio, joka on 100 pyyntöä sekunnissa keskimäärin ja kaksinkertainen hetkellinen kuormitus, eivät ole sama asia. Vastaavasti kyselyn viiveiden keskiarvo voi vaikuttaa houkuttelevalta, mutta se kätkee tärkeän yksityiskohdan: on mahdollista, että useimmat kyselyt ovat nopeita, mutta monet kyselyt ovat hitaita.
Useimmat indikaattorit nähdään paremmin jakaumina kuin keskiarvoina. Esimerkiksi SLI-viiveen osalta jotkin pyynnöt käsitellään nopeasti, kun taas toiset vievät aina kauemmin, joskus paljon kauemmin. Yksinkertainen keskiarvo voi piilottaa nämä pitkät viiveet. Kuvassa on esimerkki: vaikka tyypillinen pyyntö kestää noin 50 ms, 5 % pyynnöistä on 20 kertaa hitaampaa! Pelkästään keskimääräiseen latenssiin perustuva valvonta ja hälytykset eivät näytä muutoksia käyttäytymisessä päivän aikana, vaikka itse asiassa joidenkin pyyntöjen käsittelyajassa on havaittavia muutoksia (ylärivi).
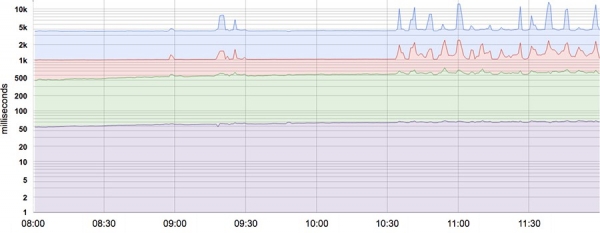
50, 85, 95 ja 99 prosenttipisteen järjestelmän latenssi. Y-akseli on logaritmisessa muodossa.
Käyttämällä prosenttipisteitä indikaattoreihin voit nähdä jakauman muodon ja sen ominaisuudet: korkea prosenttipiste, kuten 99 tai 99,9, näyttää huonoimman arvon, kun taas 50 prosenttipiste (tunnetaan myös mediaanina) näyttää yleisimmän tilan jakauman tilan. mittari. Mitä suurempi vasteajan hajonta, sitä enemmän pitkäaikaiset pyynnöt vaikuttavat käyttökokemukseen. Vaikutus tehostuu suurella kuormituksella ja jonoissa. Käyttäjäkokemustutkimukset ovat osoittaneet, että ihmiset suosivat yleensä hitaampaa järjestelmää, jossa on suuri vasteajan varianssi, joten jotkut SRE-tiimit keskittyvät vain korkeisiin prosenttipisteisiin sillä perusteella, että jos mittarin käyttäytyminen 99,9 prosenttipisteellä on hyvä, useimmat käyttäjät eivät kohtaa ongelmia. .
Huomautus tilastovirheistä
Käytämme yleensä mieluummin prosenttipisteitä kuin arvojoukon keskiarvoa (aritmeettista keskiarvoa). Tämä antaa meille mahdollisuuden tarkastella hajautetumpia arvoja, joilla on usein huomattavasti erilaisia (ja mielenkiintoisempia) ominaisuuksia kuin keskimäärin. Tietojenkäsittelyjärjestelmien keinotekoisen luonteen vuoksi metriset arvot ovat usein vääristyneitä, esimerkiksi yksikään pyyntö ei voi saada vastausta alle 0 ms:ssa ja 1000 ms:n aikakatkaisu tarkoittaa, että suuremmilla arvoilla ei voi olla onnistuneita vastauksia. kuin aikakatkaisu. Tämän seurauksena emme voi hyväksyä sitä, että keskiarvo ja mediaani voivat olla samat tai lähellä toisiaan!
Ilman ennakkotestausta ja elleivät tietyt vakiooletukset ja likiarvot pidä paikkaansa, olemme varovaisia, ettemme päättele, että tietomme jakautuvat normaalisti. Jos jakelu ei ole odotetulla tavalla, ongelman korjaava automaatioprosessi (esimerkiksi kun se näkee poikkeavia, se käynnistää palvelimen uudelleen korkeilla pyyntöjen käsittelyviiveillä) saattaa tehdä sen liian usein tai liian vähän (molemmat eivät ole Oikein hyvä).
Standardoi indikaattorit
Suosittelemme SLI:n yleisten ominaisuuksien standardointia, jotta sinun ei tarvitse spekuloida niitä joka kerta. Mikä tahansa ominaisuus, joka täyttää vakiomallit, voidaan jättää yksittäisen SLI:n määrittelyn ulkopuolelle, esimerkiksi:
- Kokoamisvälit: "keskiarvoisesti yli 1 minuutti"
- Kokoonpanoalueet: "Kaikki tehtävät klusterissa"
- Kuinka usein mittaukset suoritetaan: "10 sekunnin välein"
- Mitä pyyntöjä sisältyy: "HTTP GET from black box monitoring jobs"
- Miten tiedot saadaan: "Palvelimella mitatun valvontamme ansiosta"
- Tietojen käyttöviive: "Aika viimeiseen tavuun"
Säästä vaivaa luomalla joukko uudelleenkäytettäviä SLI-malleja kullekin yleiselle mittarille. ne myös helpottavat kaikkien ymmärtämistä, mitä tietty SLI tarkoittaa.
Tavoitteet käytännössä
Aloita ajattelemalla (tai ottamalla selvää!), mistä käyttäjillesi on kysymys, ei siitä, mitä voit mitata. Usein se, mistä käyttäjiäsi välittää, on vaikeaa tai mahdotonta mitata, joten pääset lähemmäs heidän tarpeitaan. Jos kuitenkin aloitat siitä, mikä on helppo mitata, päädyt vähemmän hyödyllisiin SLO:ihin. Tämän seurauksena olemme joskus havainneet, että haluttujen tavoitteiden tunnistaminen ja sitten työskentely tiettyjen indikaattoreiden kanssa toimii paremmin kuin indikaattoreiden valitseminen ja sitten tavoitteiden saavuttaminen.
Määrittele tavoitteet
Selvyyden vuoksi on määriteltävä, miten SLO:t mitataan ja millä ehdoilla ne ovat voimassa. Voisimme sanoa esimerkiksi seuraavan (toinen rivi on sama kuin ensimmäinen, mutta käyttää SLI-oletusasetuksia):
- 99 % (keskimäärin yli 1 minuutin) Get RPC -puheluista valmistuu alle 100 ms:ssa (kaikkien taustapalvelimien osalta mitattuna).
- 99 % Get RPC -puheluista valmistuu alle 100 ms:ssa.
Jos suorituskykykäyrien muoto on tärkeä, voit määrittää useita SLO:ita:
- 90 % Get RPC -puheluista suoritetaan alle 1 ms:ssa.
- 99 % Get RPC -puheluista suoritetaan alle 10 ms:ssa.
- 99.9% Saat RPC-kutsujen suoritettua alle 100 ms:ssa.
Jos käyttäjäsi luovat heterogeenisiä työkuormia: joukkokäsittelyä (jolle suoritusteho on tärkeää) ja interaktiivista käsittelyä (jolle viive on tärkeä), voi olla syytä määrittää erilliset tavoitteet kullekin kuormitusluokalle:
- 95 % asiakkaiden pyynnöistä vaatii läpimenoa. Aseta suoritettujen RPC-kutsujen määrä <1 s.
- 99 % asiakkaista välittää latenssista. Aseta niiden RPC-puheluiden määrä, joiden liikenne on <1 kt ja käynnissä <10 ms.
On epärealistista ja ei-toivottavaa vaatia, että SLO:t täytetään 100 % ajasta: tämä voi hidastaa uusien toimintojen käyttöönottoa ja käyttöönottoa ja edellyttää kalliita ratkaisuja. Sen sijaan on parempi sallia virhebudjetti - järjestelmän sallitun käyttökatkon prosenttiosuus - ja seurata tätä arvoa päivittäin tai viikoittain. Ylin johto saattaa haluta kuukausittaiset tai neljännesvuosittaiset arvioinnit. (Virhebudjetti on yksinkertaisesti SLO vertailua varten toiseen SLO:hen.)
SLO-rikkomusten prosenttiosuutta voidaan verrata virhebudjettiin (katso luku 3 ja kohta ), erotusarvoa käytetään syötteenä prosessiin, joka päättää, milloin uudet julkaisut otetaan käyttöön.
Tavoitearvojen valinta
Suunnitteluarvojen (SLO) valitseminen ei ole puhtaasti teknistä toimintaa, koska tuote- ja liiketoimintaintressit on otettava huomioon valituissa SLI:issä, SLO:issa (ja mahdollisesti SLA:issa). Samoin saatetaan joutua vaihtamaan tietoja henkilöstöön, markkinoilletuloaikaan, laitteiden saatavuuteen ja rahoitukseen liittyvistä asioista. SRE:n tulisi olla osa tätä keskustelua ja auttaa ymmärtämään eri vaihtoehtojen riskejä ja kannattavuutta. Olemme keksineet muutaman kysymyksen, jotka voivat auttaa varmistamaan tuottavamman keskustelun:
Älä valitse tavoitetta nykyisen suorituskyvyn perusteella.
Vaikka järjestelmän vahvuuksien ja rajojen ymmärtäminen on tärkeää, mittareiden mukauttaminen ilman perusteluja voi estää sinua ylläpitämästä järjestelmää: se vaatii sankarillisia ponnistuksia tavoitteiden saavuttamiseksi, joita ei voida saavuttaa ilman merkittävää uudelleensuunnittelua.
Ole yksinkertainen
Monimutkaiset SLI-laskelmat voivat piilottaa järjestelmän suorituskyvyn muutokset ja vaikeuttaa ongelman syyn löytämistä.
Vältä ehdottomia
Vaikka on houkuttelevaa saada järjestelmä, joka pystyy käsittelemään loputtomasti kasvavaa kuormaa lisäämättä latenssia, tämä vaatimus on epärealistinen. Järjestelmä, joka lähestyy tällaisia ihanteita, vaatii todennäköisesti paljon aikaa suunnitteluun ja rakentamiseen, on kallis käyttää ja on liian hyvä niiden käyttäjien odotuksiin, jotka tekisivät vähemmällä.
Käytä mahdollisimman vähän SLO:ta
Valitse riittävä määrä SLO:ita varmistaaksesi järjestelmämääritteiden hyvän kattavuuden. Suojaa valitsemiasi SLO:ita: Jos et koskaan voi voittaa kiistaa prioriteeteista määrittämällä tietyn SLO:n, tätä SLO:ta ei todennäköisesti kannata harkita. Kaikkia järjestelmän attribuutteja ei kuitenkaan voida soveltaa SLO:ihin: käyttäjän ilon tasoa on vaikea laskea SLO:iden avulla.
Älä tavoittele täydellisyyttä
Voit aina tarkentaa SLO:iden määritelmiä ja tavoitteita ajan myötä, kun opit lisää järjestelmän käyttäytymisestä kuormituksen alaisena. On parempi aloittaa kelluvalla tavoitteella, jota tarkennat ajan myötä, kuin valita liian tiukka tavoite, jota on rentouduttava, kun sitä ei voida saavuttaa.
SLO:t voivat ja niiden pitäisi olla avaintekijä SRE:n ja tuotekehittäjien työn priorisoinnissa, koska ne ovat käyttäjien huolenaihe. Hyvä SLO on hyödyllinen täytäntöönpanotyökalu kehitystiimille. Mutta huonosti suunniteltu SLO voi johtaa turhaan työhön, jos tiimi tekee sankarillisia ponnisteluja saavuttaakseen liian aggressiivisen SLO:n, tai huonoon tuotteeseen, jos SLO on liian alhainen. SLO on tehokas vipu, käytä sitä viisaasti.
Hallitse mittauksiasi
SLI ja SLO ovat avainelementtejä, joita käytetään järjestelmien hallintaan:
- Valvo ja mittaa SLI-järjestelmiä.
- Vertaa SLI:tä SLO:han ja päätä, tarvitaanko toimia.
- Jos tarvitaan toimia, selvitä, mitä on tapahduttava tavoitteen saavuttamiseksi.
- Suorita tämä toiminto loppuun.
Jos esimerkiksi vaihe 2 osoittaa, että pyyntö on aikakatkaistu ja katkaisee SLO:n muutamassa tunnissa, jos mitään ei tehdä, vaihe 3 saattaa sisältää sen hypoteesin testaamisen, että palvelimet ovat CPU-sidottuja ja lisäämällä palvelimia jaetaan kuormitus. Ilman SLO:ta et tietäisi, pitäisikö (tai milloin) ryhtyä toimiin.
Aseta SLO - sitten käyttäjien odotukset asetetaan
SLO:n julkaiseminen asettaa käyttäjien odotukset järjestelmän toiminnalle. Käyttäjät (ja potentiaaliset käyttäjät) haluavat usein tietää, mitä palvelulta voi odottaa ymmärtääkseen, soveltuuko se käytettäväksi. Ihmiset, jotka haluavat käyttää valokuvienjakosivustoa, saattavat esimerkiksi haluta välttää käyttämästä palvelua, joka lupaa pitkäikäisyyttä ja alhaisia kustannuksia vastineeksi hieman alhaisemmasta saatavuudesta, vaikka sama palvelu voisi olla ihanteellinen arkiston hallintajärjestelmään.
Voit asettaa käyttäjillesi realistisia odotuksia käyttämällä jompaakumpaa tai molempia seuraavista taktiikoista:
- Säilytä turvamarginaali. Käytä tiukempaa sisäistä SLO:ta kuin mitä käyttäjille mainostetaan. Tämä antaa sinulle mahdollisuuden reagoida ongelmiin ennen kuin ne näkyvät ulkoisesti. SLO-puskuri mahdollistaa myös turvamarginaalin, kun asennat julkaisuja, jotka vaikuttavat järjestelmän suorituskykyyn ja varmistavat, että järjestelmää on helppo ylläpitää ilman, että käyttäjiä tarvitsee turhauttaa seisokkeilla.
- Älä ylitä käyttäjien odotuksia. Käyttäjät perustuvat siihen, mitä tarjoat, eivät siihen, mitä sanot. Jos palvelusi todellinen suorituskyky on paljon parempi kuin ilmoitettu SLO, käyttäjät luottavat nykyiseen suorituskykyyn. Voit välttää liiallisen riippuvuuden sammuttamalla järjestelmän tarkoituksella tai rajoittamalla suorituskykyä kevyissä kuormissa.
Ymmärtäminen, kuinka hyvin järjestelmä vastaa odotuksia, auttaa päättämään, kannattaako investoida järjestelmän nopeuttamiseen ja helpottamaan sen saatavuutta ja joustavuutta. Vaihtoehtoisesti, jos palvelu toimii liian hyvin, osa henkilöstön ajasta tulisi käyttää muihin prioriteetteihin, kuten teknisten velkojen maksamiseen, uusien ominaisuuksien lisäämiseen tai uusien tuotteiden esittelyyn.
Sopimukset käytännössä
Palvelutasosopimuksen luominen edellyttää, että yritys- ja lakitiimit määrittelevät sen rikkomisen seuraukset ja rangaistukset. SRE:n tehtävänä on auttaa heitä ymmärtämään todennäköisiä haasteita SLA:n sisältämien SLO:iden täyttämisessä. Useimmat SLO-sopimusten luomista koskevat suositukset koskevat myös SLA-sopimuksia. On viisasta olla konservatiivinen käyttäjille luvattaessa, koska mitä enemmän sinulla on, sitä vaikeampaa on muuttaa tai poistaa SLA-sopimuksia, jotka vaikuttavat kohtuuttomalta tai vaikealta saavuttaa.
Kiitos, että luit käännöksen loppuun. Tilaa telegram-kanavani valvonnasta и .
Lähde: will.com
