

Elkenien praat oer de prosessen fan ûntwikkeling en testen, training fan personiel, tanimmende motivaasje, mar dizze prosessen binne net genôch as in minút fan tsjinstferliening enoarme bedragen kostje. Wat te dwaan as jo finansjele transaksjes útfiere ûnder in strikte SLA? Hoe kinne jo de betrouberens en fouttolerânsje fan jo systemen ferheegje, ûntwikkeling en testen út 'e fergeliking nimme?

De folgjende HighLoad++ konferinsje wurdt hâlden op 6 en 7 april 2020 yn Sint Petersburg. Details en kaartsjes foar . 9. novimber, 18:00. HighLoad++ Moskou 2018, Delhi + Kolkata hall. Theses en .
Evgeniy Kuzovlev (hjirnei - EK): - Freonen, hallo! Myn namme is Kuzovlev Evgeniy. Ik kom fan it bedriuw EcommPay, in spesifike divyzje is EcommPay IT, de IT-divyzje fan 'e groep bedriuwen. En hjoed sille wy prate oer downtimes - oer hoe't se se kinne foarkomme, oer hoe't se har gefolgen kinne minimalisearje as it net kin wurde foarkommen. It ûnderwerp wurdt as folget oanjûn: "Wat te dwaan as in minút fan downtime kostet $ 100"? Foarútsjen binne ús sifers te fergelykjen.
Wat docht EkommPay IT?
Wa binne wy? Wêrom stean ik hjir foar dy? Wêrom haw ik it rjocht om jo hjir wat te fertellen? En wat sille wy hjir yn mear detail prate?
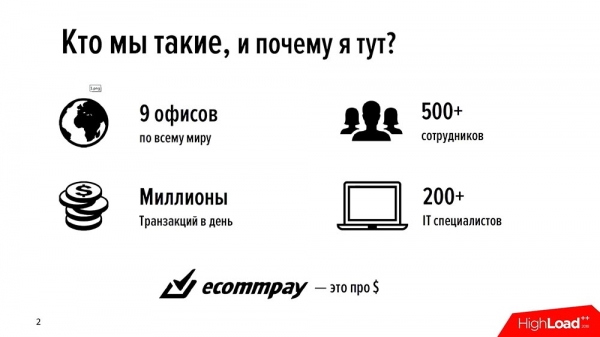
EcommPay-groep fan bedriuwen is in ynternasjonale oankeaper. Wy ferwurkje betellingen oer de hiele wrâld - yn Ruslân, Europa, Súdeast-Aazje (oer de hiele wrâld). Wy hawwe 9 kantoaren, 500 meiwurkers yn totaal, en likernôch in bytsje minder as de helte fan harren binne IT-spesjalisten. Alles wat wy dogge, alles wêrfan wy jild fertsjinje, hawwe wy sels dien.
Wy skreau al ús produkten (en wy hawwe nochal in protte fan harren - yn ús line fan grutte IT produkten wy hawwe oer 16 ferskillende komponinten) sels; Wy skriuwe ússels, wy ûntwikkelje ússels. En op it stuit fiere wy sawat in miljoen transaksjes deis út (miljoenen is wierskynlik de goeie manier om it te sizzen). Wy binne in frij jong bedriuw - wy binne noch mar seis jier âld.
6 jier lyn wie it sa'n opstart doe't de jonges mei it bedriuw kamen. Se waarden ferienige troch in idee (der wie neat oars as in idee), en wy rûnen. Lykas elke startup rûnen wy flugger ... Foar ús wie snelheid wichtiger as kwaliteit.
Op in stuit binne wy stilhâlden: wy realisearren ús dat wy op ien of oare manier net mear mei dy snelheid en mei dy kwaliteit libje koene en wy moasten ús earst rjochtsje op kwaliteit. Op dit stuit hawwe wy besletten om in nij platfoarm te skriuwen dat korrekt, skalberber en betrouber wêze soe. Se begon dit platfoarm te skriuwen (se begon te ynvestearjen, ûntwikkeljen ûntwikkeling, testen), mar op in stuit realisearre se dat ûntwikkeling en testen ús net tastean om in nij nivo fan tsjinstkwaliteit te berikken.
Jo meitsje in nij produkt, jo sette it yn produksje, mar dochs sil der earne wat mis gean. En hjoed sille wy prate oer hoe't jo in nij kwaliteitsnivo kinne berikke (hoe't wy it dien hawwe, oer ús ûnderfining), ûntjouwing en testen út 'e fergeliking nimme; wy sille prate oer wat beskikber is foar operaasje - wat operaasje sels kin dwaan, wat it kin biede oan testen om de kwaliteit te beynfloedzjen.
Downtimes. Geboaden fan operaasje.
Altyd de wichtichste hoekstien, wêr't wy hjoed eins oer sille prate is downtime. In ferskriklik wurd. As wy downtime hawwe, is alles min foar ús. Wy rinne om it te ferheegjen, de admins hâlde de tsjinner - God ferbiede dat it net falt, lykas se sizze yn dat ferske. Dit is wêr't wy hjoed oer prate.

Doe't wy ús oanpak begûnen te feroarjen, foarmen wy 4 geboaden. Ik haw se presintearre op 'e dia's:
Dizze geboaden binne frij ienfâldich:

- Identifisearje it probleem fluch.
- Krij it noch flugger kwyt.
- Help begripe de reden (letter, foar ûntwikkelders).
- En standardisearje oanpak.
Ik soe jo oandacht freegje wolle op punt nr. 2. Wy meitsje it probleem kwyt, lossen it net op. Beslút is sekundêr. Foar ús is it primêre ding dat de brûker is beskerme fan dit probleem. It sil bestean yn guon isolearre omjouwing, mar dizze omjouwing sil hawwe gjin kontakt mei it. Eins sille wy dizze fjouwer groepen problemen trochgean (guon yn mear detail, guon yn minder detail), ik sil jo fertelle wat wy brûke, hokker relevante ûnderfining wy hawwe yn oplossingen.
Troubleshooting: wannear barre se en wat te dwaan?
Mar wy sille út 'e oarder begjinne, wy sille begjinne mei punt 2 - hoe fluch it probleem kwyt te reitsjen? D'r is in probleem - wy moatte it reparearje. "Wat moatte wy hjirmei dwaan?" - de wichtichste fraach. En doe't wy begon te tinken oer hoe't wy it probleem kinne oplosse, hawwe wy foar ússels wat easken ûntwikkele dy't probleemoplossing moat folgje.

Om dizze easken te formulearjen, hawwe wy besletten om ússels de fraach te freegjen: "Wannear hawwe wy problemen"? En problemen, sa die bliken, komme yn fjouwer gefallen foar:

- Hardware flater.
- Eksterne tsjinsten mislearre.
- It feroarjen fan de softwareferzje (deselde ynset).
- Eksplosive lading groei.
Wy sille net prate oer de earste twa. In hardwarefout kin frij ienfâldich wurde oplost: jo moatte alles duplikearje. As dit binne skiven, de skiven moatte wurde gearstald yn RAID, as dit is in tsjinner, de tsjinner moat wurde duplicated as jo in netwurk ynfrastruktuer, jo moatte leverje in twadde kopy fan it netwurk ynfrastruktuer, dat is, jo nimme it en; duplicate it. En as der wat mislearret, skeakelje jo oer op reservestroom. It is lestich om hjir wat mear te sizzen.
De twadde is it mislearjen fan eksterne tsjinsten. Foar de measte is it systeem hielendal gjin probleem, mar net foar ús. Om't wy betellingen ferwurkje, binne wy in aggregator dy't stiet tusken de brûker (dy't syn kaartgegevens ynfiert) en banken, betellingssystemen (Visa, MasterCard, Mira, ensfh.). Us eksterne tsjinsten (betelsystemen, banken) hawwe de neiging om te mislearjen. Noch wy noch jo (as jo sokke tsjinsten hawwe) kinne dit beynfloedzje.
Wat te dwaan dan? D'r binne hjir twa opsjes. Earst, as jo kinne, moatte jo dizze tsjinst op ien of oare manier duplisearje. Bygelyks, as wy kinne, ferpleatse wy ferkear fan de iene tsjinst nei de oare: kaarten waarden bygelyks ferwurke fia Sberbank, Sberbank hat problemen - wy ferpleatse ferkear [betingsten] nei Raiffeisen. It twadde ding dat wy kinne dwaan is om it mislearjen fan eksterne tsjinsten heul fluch te merken, en dêrom sille wy prate oer antwurdsnelheid yn it folgjende diel fan it rapport.
Yn feite, fan dizze fjouwer, kinne wy spesifyk beynfloedzje de feroaring fan software ferzjes - nimme aksjes dy't sil liede ta in ferbettering fan de situaasje yn 'e kontekst fan ynset en yn' e kontekst fan eksplosive groei yn lading. Eins hawwe wy dat dien. Hjir, wer, in lytse notysje ...
Fan dizze fjouwer problemen wurde ferskate fuortendaliks oplost as jo in wolk hawwe. As jo yn 'e Microsoft Azhur, Ozone-wolken binne, of ús wolken brûke, fan Yandex of Mail, dan wurdt op syn minst in hardwarefout har probleem en alles wurdt daliks goed foar jo yn' e kontekst fan in hardwarefout.
Wy binne in bytsje ûnkonvinsjonele bedriuw. Hjir praat elkenien oer "Kubernets", oer wolken - wy hawwe noch "Kubernets" noch wolken. Mar wy hawwe rekken fan hardware yn in protte data sintra, en wy binne twongen om te libjen op dizze hardware, wy binne twongen om te wêzen ferantwurdlik foar it allegear. Dêrom sille wy prate yn dit ferbân. Dus, oer de problemen. De earste twa waarden út de heakjes helle.
It feroarjen fan de software ferzje. Bases
Us ûntwikkelders hawwe gjin tagong ta produksje. Wêrom is dat? It is gewoan dat wy PCI DSS-sertifisearre binne, en ús ûntwikkelders hawwe gewoan net it rjocht om yn it "produkt" te kommen. Dat is it, punt. Heulendal. Dêrom einiget ûntwikkelingsferantwurdlikens krekt op it momint dat ûntwikkeling de bou foar frijlitting yntsjinnet.

Us twadde basis dy't wy hawwe, dy't ús ek in protte helpt, is it ûntbrekken fan unike net-dokumintearre kennis. Ik hoopje dat it foar jo itselde is. Want as dit net it gefal is, sille jo problemen hawwe. Der sille problemen ûntstean as dizze unike, net-dokumintearre kennis net op it krekte momint op it goede plak oanwêzich is. Litte wy sizze dat jo ien persoan hawwe dy't wit hoe't jo in spesifike komponint ynsette - de persoan is der net, hy is op fakânsje of siik - dat is it, jo hawwe problemen.
En de tredde basis dêr't wy binne kommen. Wy kamen ta it troch pine, bloed, triennen - wy kamen ta de konklúzje dat elk fan ús builds flaters befettet, sels as it flaterfrij is. Wy hawwe dit foar ússels besletten: as wy wat ynsette, as wy wat yn produksje rôlje, hawwe wy in build mei flaters. Wy hawwe de easken foarme dêr't ús systeem oan moat foldwaan.
Easken foar it feroarjen fan de softwareferzje
Der binne trije easken:

- Wy moatte de ynset fluch weromdraaie.
- Wy moatte de ynfloed fan in mislearre ynset minimalisearje.
- En wy moatte parallel ynsette kinne.
Krekt yn dy folchoarder! Wêrom? Om't, earst fan alle, by it ynsetten fan in nije ferzje, snelheid is net wichtich, mar it is wichtich foar jo, as der wat mis giet, fluch werom te rôljen en minimale ynfloed te hawwen. Mar as jo in set ferzjes yn produksje hawwe, wêrfoar it docht bliken dat d'r in flater is (út it blau wie d'r gjin ynset, mar d'r is in flater) - de snelheid fan folgjende ynset is wichtich foar jo. Wat hawwe wy dien om oan dizze easken te foldwaan? Wy hawwe taflecht ta de folgjende metoade:
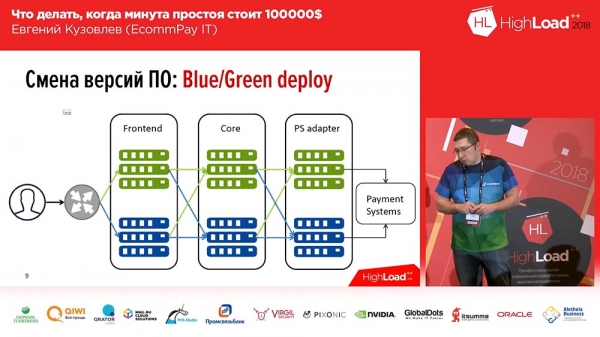
It is frij goed bekend, wy hawwe it noait útfûn - dit is Blau / Grien ynset. Wat is it? Jo moatte in kopy hawwe foar elke groep servers wêrop jo applikaasjes binne ynstalleare. It eksimplaar is "waarm": der stiet gjin ferkear op, mar dit ferkear kin op elk momint nei dit eksimplaar stjoerd wurde. Dit eksimplaar befettet de foarige ferzje. En op it momint fan ynset rôlje jo de koade út nei in ynaktive kopy. Dan wikselje jo in diel fan it ferkear (of alles) nei de nije ferzje. Dus, om de ferkearsstream fan 'e âlde ferzje nei de nije te feroarjen, moatte jo mar ien aksje dwaan: jo moatte de balancer yn' e streamôfwert feroarje, de rjochting feroarje - fan de iene streamop nei de oare. Dit is heul handich en lost it probleem op fan fluch wikseljen en rappe weromdraaien.Hjir is de oplossing foar de twadde fraach minimalisearjen: jo kinne mar in diel fan jo ferkear stjoere nei in nije line, nei in rigel mei in nije koade (lit it wêze, bygelyks, 2%). En dizze 2% binne net 100%! As jo 100% fan jo ferkear ferlern hawwe troch in mislearre ynset, dat is eng as jo 2% fan jo ferkear ferlern hawwe, dat is ûnnoflik, mar it is net eng. Boppedat sille brûkers dit nei alle gedachten net iens fernimme, om't yn guon gefallen (net yn allegear) deselde brûker, troch op F5 te drukken, nei in oare, wurkjende ferzje brocht wurde.
Blau / Grien ynset. Routing
Lykwols, net alles is sa ienfâldich "Blauwe / Grien ynsette" ... Al ús komponinten kinne wurde ferdield yn trije groepen:
- dit is de frontend (betellingssiden dy't ús kliïnten sjogge);
- ferwurkjen kearn;
- adapter foar wurkjen mei betelling systemen (banken, MasterCard, Visa ...).
En der is in nuânse hjir - de nuânse leit yn de routing tusken de rigels. As jo gewoan 100% fan it ferkear oerskeakelje, hawwe jo dizze problemen net. Mar as jo 2% wolle wikselje, begjinne jo fragen te stellen: "Hoe dit te dwaan?" De ienfâldichste ding is rjocht foarút: jo kinne ynstelle Round Robin yn nginx troch willekeurige kar, en do hast 2% nei lofts, 98% nei rjochts. Mar dit is net altyd geskikt.
Bygelyks, yn ús gefal, in brûker ynteraksje mei it systeem mei mear dan ien fersyk. Dit is normaal: 2, 3, 4, 5 fersiken - jo systemen kinne itselde wêze. En as it foar jo wichtich is dat alle oanfragen fan de brûker op deselde rigel komme dêr't it earste fersyk op kaam, of (twadde punt) komme alle oanfragen fan de brûker nei de nije rigel nei de oerstap (hy koe earder begjinne te wurkjen mei de systeem, foar de switch), - dan is dizze willekeurige ferdieling net geskikt foar jo. Dan binne d'r de folgjende opsjes:
De earste opsje, de ienfâldichste, is basearre op de basisparameters fan 'e kliïnt (IP Hash). Jo hawwe in IP, en jo diele it fan rjochts nei lofts troch IP-adres. Dan sil it twadde gefal dat ik beskreaun foar jo wurkje, doe't de ynset barde, koe de brûker al mei jo systeem begjinne te wurkjen, en fanôf it momint fan ynset sille alle oanfragen nei in nije line gean (nei deselde, bygelyks).As dit om ien of oare reden net by jo past en jo fersiken moatte stjoere nei de line wêr't it earste, earste fersyk fan de brûker kaam, dan hawwe jo twa opsjes ...
Earste opsje: jo kinne betelle nginx + keapje. D'r is in Sticky-sesjemeganisme, dy't, op it earste fersyk fan 'e brûker, in sesje oan 'e brûker tawize en it oan ien of oare streamop bynt. Alle folgjende brûkersoanfragen binnen de sesjelibben wurde stjoerd nei deselde streamop wêr't de sesje waard pleatst.Dit paste ús net om't wy al gewoane nginx hiene. Oerskeakelje nei nginx + is net dat it djoer is, it is gewoan dat it wat pynlik foar ús wie en net heul rjocht. "Sticks Sessions", bygelyks, wurke net foar ús om de ienfâldige reden dat "Sticks Sessions" gjin routing tastean basearre op "Of-of". Dêr kinne jo oanjaan wat wy "Sticks Sessions" dogge, bygelyks troch IP-adres of troch IP-adres en koekjes of troch postparameter, mar "Of-of" is dêr komplisearre.
Dêrom kamen wy by de fjirde opsje. Wy namen nginx op steroïden (dit is iepenresty) - dit is deselde nginx, dy't ek it opnimmen fan lêste skripts stipet. Jo kinne skriuwe in lêste skript, jou it in "iepen rest", en dit lêste skript wurdt útfierd as de brûker fersyk komt.
En wy skreau, yn feite, sa'n skript, set ússels "openresti" en yn dit skript wy sortearje troch 6 ferskillende parameters troch gearhing "Of". Ofhinklik fan 'e oanwêzigens fan ien of oare parameter, wy witte dat de brûker kaam op ien of oare side, ien of oare line.
Blau / Grien ynset. Foardielen en neidielen
Fansels wie it wierskynlik mooglik om it wat ienfâldiger te meitsjen (brûk deselde "Sticky Sessions"), mar wy hawwe ek sa'n nuânse dat net allinich de brûker mei ús ynteraksje binnen it ramt fan ien ferwurking fan ien transaksje ... Mar betelling systemen ek ynteraksje mei ús: Neidat wy ferwurkje de transaksje (troch it stjoeren fan in fersyk oan it betelling systeem), wy krije in coolback.
En lit ús sizze, as wy binnen ús circuit it IP-adres fan 'e brûker kinne trochstjoere yn alle oanfragen en brûkers ferdielen op basis fan it IP-adres, dan sille wy itselde "Visa" net fertelle: "Dude, wy binne sa'n retro-bedriuw, wy lykje om ynternasjonaal te wêzen (op 'e webside en yn Ruslân) ... Jou ús asjebleaft it IP-adres fan 'e brûker yn in ekstra fjild, jo protokol is standerdisearre"! It is dúdlik dat se it net iens wurde sille.
Dêrom, dit wurke net foar ús - wy diene iepenresty. Dêrtroch krigen wy mei routing sa'n ding:Blau / Grien ynset hat, neffens, de foardielen dy't ik neamde en neidielen.
Der binne twa neidielen:
- jo moatte lestich falle mei routing;
- de twadde wichtichste neidiel is de kosten.
Jo moatte twa kear safolle tsjinners, jo moatte twa kear safolle operasjonele boarnen, jo moatte besteegje twa kear safolle muoite te behâlden dizze hiele bistetún.
Trouwens, ûnder de foardielen is d'r noch ien ding dat ik net earder haw neamd: jo hawwe in reserve yn gefal fan ladinggroei. As jo in eksplosive groei yn 'e lading hawwe, hawwe jo in grut oantal brûkers, dan befetsje jo gewoan de twadde rigel yn' e 50 oan 50-distribúsje - en jo hawwe fuortendaliks x2-tsjinners yn jo kluster oant jo it probleem oplosse fan mear tsjinners.
Hoe kinne jo in rappe ynset meitsje?
Wy prate oer hoe't jo it probleem fan minimalisearjen en rappe weromdraaie kinne oplosse, mar de fraach bliuwt: "Hoe fluch ynsette?"
It is hjir koart en ienfâldich.- Jo moatte in CD-systeem hawwe (Continuous Delivery) - jo kinne net sûnder it libje. As jo ien server hawwe, kinne jo manuell ynsette. Wy hawwe sa'n ien en in heal tûzen tsjinners en ien en in heal tûzen hânfetten, fansels - wy kinne in ôfdieling plantsje fan 'e grutte fan dizze keamer gewoan om yn te setten.
- Ynset moat parallel wêze. As jo ynset sekwinsjele is, dan is alles min. Ien server is normaal, jo sille de hiele dei ien en in heal tûzen servers ynsette.
- Nochris, foar fersnelling is dit wierskynlik net mear nedich. Tidens ynset wurdt it projekt meastentiids boud. Jo hawwe in webprojekt, d'r is in front-end diel (jo dogge dêr in webpakket, jo kompilearje npm - soksawat), en dit proses is yn prinsipe koart - 5 minuten, mar dizze 5 minuten kinne kritysk wêze. Dêrom dogge wy dat bygelyks net: wy hawwe dizze 5 minuten fuorthelle, wy sette artefakten yn.
Wat is in artefakt? In artefakt is in gearstalde build wêryn alle gearstallingsdielen al foltôge binne. Wy bewarje dit artefakt yn 'e artefakt opslach. Op in stuit brûkten wy twa sokke opslach - it wie Nexus en no jFrog Artifactory Wy brûkten earst "Nexus" om't wy dizze oanpak begon te oefenjen yn java-applikaasjes (it paste it goed). Dan sette se wat fan de yn PHP skreaune applikaasjes der yn; en "Nexus" wie net mear geskikt, en dêrom wy keas jFrog Artefactory, dat kin artifactorize hast alles. Wy binne sels op it punt kommen dat wy yn dit artefaktrepository ús eigen binêre pakketten opslaan dy't wy sammelje foar servers.
Eksplosive lading groei
Wy hawwe it oer it feroarjen fan de softwareferzje. It folgjende ding dat wy hawwe is in eksplosive ferheging fan lading. Hjir bedoel ik wierskynlik mei eksplosive groei fan 'e lading net hielendal it goede ding ...
Wy hawwe in nij systeem skreaun - it is servicerjochte, modieus, prachtich, oeral arbeiders, oeral wachtrige, oeral asynchrony. En yn sokke systemen kinne gegevens troch ferskate streamen streame. Foar de earste transaksje kin de 1e, 3e, 10e arbeider brûkt wurde, foar de twadde transaksje - de 2e, 4e, 5e. En hjoed, litte wy sizze, yn 'e moarn hawwe jo in gegevensstream dy't de earste trije arbeiders brûkt, en yn' e jûn feroaret it dramatysk, en alles brûkt de oare trije arbeiders.
En hjir docht bliken dat jo de arbeiders op ien of oare manier moatte skaalje, jo moatte jo tsjinsten op ien of oare manier skaalje, mar tagelyk foarkommen fan resource-bloat.
Wy hawwe ús easken definiearre. Dizze easken binne frij simpel: dat der Service ûntdekking, parameterization - alles is standert foar it bouwen fan sokke scalable systemen, útsein ien punt - boarne ôfskriuwing. Wy seine dat wy binne net ree om te amortisearje middels sadat de tsjinners ferwaarmje de loft. Wy namen "Konsul", wy namen "Nomad", dy't ús arbeiders beheart.Wêrom is dit in probleem foar ús? Litte wy in bytsje weromgean. Wy hawwe no sa'n 70 betellingssystemen efter ús. Moarns giet ferkear troch Sberbank, dan foel Sberbank bygelyks, en wy wikselje it nei in oar betellingssysteem. Wy hienen 100 arbeiders foar Sberbank, en dêrnei moatte wy 100 arbeiders skerp ferheegje foar in oar betellingssysteem. En it is winsklik dat dit alles bart sûnder minsklike dielname. Want as der minsklike partisipaasje is, dan moat der 24/7 in yngenieur sitte, dy't dat allinnich dwaan moat, want sokke mislearrings, as der 70 systemen efter jo steane, komme geregeld foar.
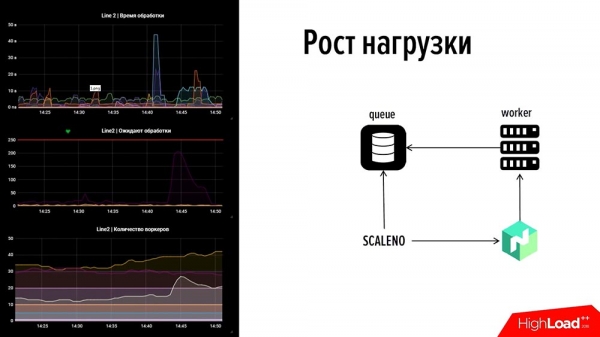
Dêrom seagen wy nei Nomad, dy't in iepen IP hat, en skreau ús eigen ding, Scale-Nomad - ScaleNo, dy't sawat it folgjende docht: it kontrolearret de groei fan 'e wachtrige en ferminderet of fergruttet it oantal arbeiders ôfhinklik fan de dynamyk fan de wachtrige. Doe't wy it diene, tochten wy: "Miskien kinne wy it iepenje?" Doe seagen se har oan - se wie sa ienfâldich as twa kopeken.
Oant no hawwe wy it net iepen boarnen, mar as jo ynienen nei it rapport, nei't jo realisearje dat jo soks nedich binne, it nedich binne, myn kontakten binne yn 'e lêste dia - skriuw my asjebleaft. As der minimaal 3-5 minsken binne, sponsorje wy it.
Hoe't it wurket? Litte wy ris sjen! Foarútsjen: oan de linkerkant is d'r in stik fan ús tafersjoch: dit is ien rigel, boppe is de tiid fan it ferwurkjen fan eveneminten, yn 'e midden is it oantal transaksjes, oan' e ûnderkant is it oantal arbeiders.As jo sjogge, is d'r in glitch yn dizze foto. Op 'e boppeste kaart stoarte ien fan' e charts yn 45 sekonden - ien fan 'e betellingssystemen gie del. Fuortendaliks waard ferkear yn 2 minuten brocht en de wachtrige begon te groeien op in oar betellingssysteem, wêr't gjin arbeiders wiene (wy brûkten gjin boarnen - krekt oarsom, wy hawwe de boarne korrekt ôfset). Wy woenen net ferwaarmje - d'r wie in minimaal oantal, sawat 5-10 arbeiders, mar se koenen net omgean.
De lêste grafyk toant in "bult", wat krekt betsjut dat "Skaleno" ferdûbele dit bedrach. En doe, doe't de grafyk in bytsje sakke, fermindere hy it in bytsje - it oantal arbeiders waard automatysk feroare. Dat is hoe't dit ding wurket. Wy hawwe it oer punt nûmer 2 - "Hoe kinne jo fluch kwytreitsje fan redenen."
Monitoring. Hoe kinne jo it probleem fluch identifisearje?
No is it earste punt "Hoe kinne jo it probleem fluch identifisearje?" Monitoring! Wy moatte bepaalde dingen fluch begripe. Hokker dingen moatte wy fluch begripe?
Trije dingen!- Wy moatte de prestaasjes fan ús eigen middels fluch begripe en begripe.
- Wy moatte flaters fluch begripe en de prestaasjes kontrolearje fan systemen dy't bûten ús binne.
- It tredde punt is it identifisearjen fan logyske flaters. Dit is as it systeem foar jo wurket, alles is normaal neffens alle yndikatoaren, mar der giet wat mis.
Ik sil jo hjir wierskynlik neat sizze dat cool is. Ik sil Captain Obvious wêze. Wy sochten wat der op 'e merk stie. Wy hawwe in "leuke bistetún". Dit is it soarte bistetún dat wy no hawwe:
Wy brûke Zabbix om hardware te kontrolearjen, om de wichtichste yndikatoaren fan servers te kontrolearjen. Wy brûke Okmeter foar databases. Wy brûke "Grafana" en "Prometheus" foar alle oare yndikatoaren dy't net passe by de earste twa, guon mei "Grafana" en "Prometheus", en guon mei "Grafana" mei "Influx" en Telegraf.In jier lyn woene wy New Relic brûke. Cool ding, it kin alles dwaan. Mar safolle as se alles kin, is se sa djoer. Doe't wy groeiden ta in folume fan 1,5 tûzen servers, kaam in ferkeaper nei ús en sei: "Litte wy in oerienkomst slute foar takom jier." Wy seagen nei de priis en seine nee, dat sille wy net dwaan. No litte wy New Relic ferlitte, wy hawwe sawat 15 servers oerbleaun ûnder it tafersjoch fan New Relic. De priis blykte absolút wyld te wêzen.
En d'r is ien ark dat wy sels ymplementearre hawwe - dit is Debugger. Earst neamden wy it "Bagger", mar doe kaam in learaar Ingelsk foarby, lake wyld en neamde it "Debagger." Wat is it? Dit is in ark dat yn feite yn 15-30 sekonden op elke komponint, lykas in "swarte doaze" fan it systeem, tests útfiert op 'e totale prestaasjes fan' e komponint.
As der bygelyks in eksterne side is (betellingsside), iepenet hy dy gewoan en sjocht nei hoe't it der útsjen moat. As dit ferwurket, stjoert hy in test "transaksje" en soarget derfoar dat dizze "transaksje" komt. As dit is in ferbining mei betelling systemen, wy fjoer in test fersyk accordingly, dêr't wy kinne, en sjen dat alles is goed mei ús.
Hokker yndikatoaren binne wichtich foar tafersjoch?
Wat kontrolearje wy benammen? Hokker yndikatoaren binne wichtich foar ús?
- Responstiid / RPS op fronten is in heul wichtige yndikator. Hy antwurdet daliks dat der wat mis is mei dy.
- It oantal ferwurke berjochten yn alle wachtrijen.
- Oantal arbeiders.
- Basis korrektheidsmetriken.
It lêste punt is "bedriuw", "bedriuw" metrysk. As jo itselde ding wolle kontrolearje, moatte jo ien of twa metriken definiearje dy't de wichtichste yndikatoaren foar jo binne. Us metrik is trochput (dit is de ferhâlding fan it oantal suksesfolle transaksjes nei de totale transaksjestream). As der wat feroaret yn it ynterval fan 5-10-15 minuten, betsjut it dat wy problemen hawwe (as it radikaal feroaret).
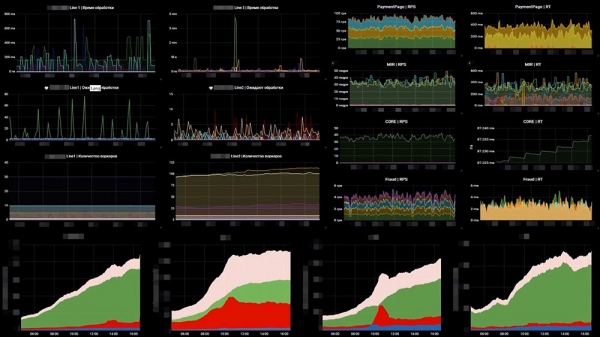
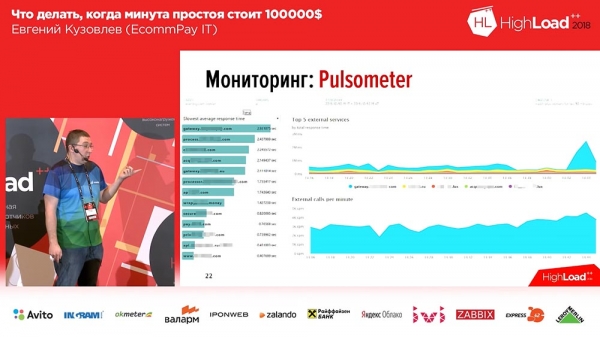
Hoe it der foar ús útsjocht is in foarbyld fan ien fan ús buorden:
Oan de linkerkant binne d'r 6 grafiken, dit is neffens de rigels - it oantal arbeiders en it oantal berjochten yn 'e wachtrige. Oan de rjochterkant - RPS, RTS. Hjirûnder is deselde "saaklike" metrik. En yn 'e "saaklike" metryske kinne wy fuortendaliks sjen dat der wat mis gie yn 'e twa middelste grafiken ... Dit is gewoan in oar systeem dat efter ús stiet dat fallen is.It twadde ding dat wy moasten dwaan wie de fal fan eksterne betellingssystemen kontrolearje. Hjir namen wy OpenTracing - in meganisme, standert, paradigma wêrmei jo ferdield systemen kinne trace; en it waard in bytsje feroare. It standert OpenTracing-paradigma seit dat wy in spoar bouwe foar elk yndividueel fersyk. Wy hienen dit net nedich, en wy ferpakt it yn in gearfetting, aggregaasjetrace. Wy hawwe in ark makke wêrmei wy de snelheid fan 'e systemen efter ús kinne folgje.
De grafyk lit ús sjen dat ien fan 'e betellingssystemen yn 3 sekonden begon te reagearjen - wy hawwe problemen. Boppedat sil dit ding reagearje as problemen begjinne, mei in ynterval fan 20-30 sekonden.En de tredde klasse fan tafersjochflaters dy't bestean is logyske tafersjoch.
Om earlik te wêzen, wist ik net wat ik op dizze slide tekenje moast, want wy sochten al lang op 'e merke nei eat dat by ús past. Wy fûnen neat, dus wy moasten it sels dwaan.
Wat bedoel ik mei logyske tafersjoch? No, stel jo foar: jo meitsje josels in systeem (bygelyks in Tinder-kloon); do makkest it, lansearre it. Súksesfolle manager Vasya Pupkin sette it op syn telefoan, sjocht dêr in famke, liket har ... en sa giet net nei it famke - sa giet nei de befeiligingswacht Mikhalych út itselde saaklike sintrum. De manager giet nei ûnderen en freget him dan ôf: "Wêrom glimket dizze befeiliger Mikhalych sa noflik nei him?"Yn sokke situaasjes... Foar ús klinkt dizze situaasje wat oars, om't (ik skreau) dit in reputaasjeferlies is dat yndirekt liedt ta finansjele ferliezen. Us situaasje is it tsjinoerstelde: wy meie lije direkte finansjele ferliezen - bygelyks, as wy útfierd in transaksje as suksesfol, mar it wie net slagge (of oarsom). Ik moast myn eigen ark skriuwe dat it oantal suksesfolle transaksjes oer tiid folget mei saaklike yndikatoaren. Net fûn neat op 'e merk! Dit is krekt it idee dat ik oerbringe woe. Der is neat op 'e merk te lossen dit soarte fan probleem.
Dit gie oer hoe't jo it probleem fluch identifisearje kinne.
Hoe te bepalen de redenen foar ynset
De tredde groep problemen dy't wy oplosse, is neidat wy hawwe identifisearre it probleem, neidat wy hawwe get rid of it, it soe wêze goed om te begripen de reden foar ûntwikkeling, foar testen, en dwaan wat oer it. Dêrom moatte wy ûndersykje, wy moatte de logs ferheegje.
As wy it hawwe oer logs (de wichtichste reden is logs), is it grutste part fan ús logs yn ELK Stack - hast elkenien hat itselde. Foar guon is it miskien net yn ELK, mar as jo logs yn gigabytes skriuwe, dan komme jo ier of letter by ELK. Wy skriuwe se yn terabytes.
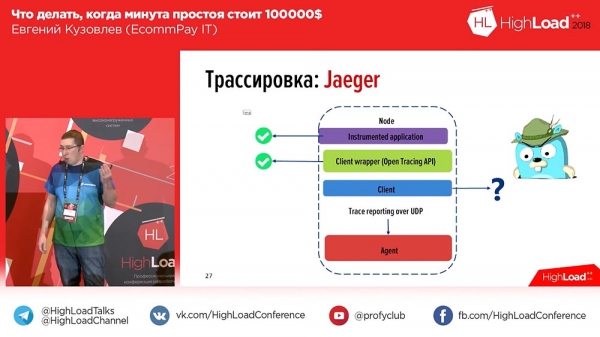
Der is in probleem hjir. Wy hawwe it reparearre, de flater korrizjearre foar de brûker, begon te graven wat d'r wie, klommen yn Kibana, fierden dêr de transaksje-id yn en krigen sa'n fuotkleed (sjokt in protte). En hielendal neat is dúdlik yn dit fuotkleed. Wêrom? Ja, want it is net dúdlik hokker part by hokker wurknimmer heart, hokker part by hokker ûnderdiel heart. En op dat stuit realisearren wy dat wy tracing nedich wiene - deselde OpenTracing dêr't ik oer praat.Wy tochten dit in jier lyn, rjochte ús oandacht op 'e merk, en d'r wiene twa ark - "Zipkin" en "Jaeger". "Jager" is eins sa'n ideologyske erfgenamt, in ideologyske opfolger fan "Zipkin". Alles is goed yn Zipkin, útsein dat it net wit hoe te aggregearjen, it wit net hoe't logs yn 'e trace kinne opnimme, allinich tiidspoar. En "Jager" stipe dit.
Wy seagen nei "Jager": jo kinne applikaasjes ynstrumintearje, jo kinne skriuwe yn Api (de Api-standert foar PHP op dat stuit wie lykwols net goedkard - dit wie in jier lyn, mar no is it al goedkard), mar dêr wie perfoarst gjin klant. "Okee," tochten wy, en skreau ús eigen klant. Wat hawwe wy krigen? Dit is sawat hoe't it derút sjocht:
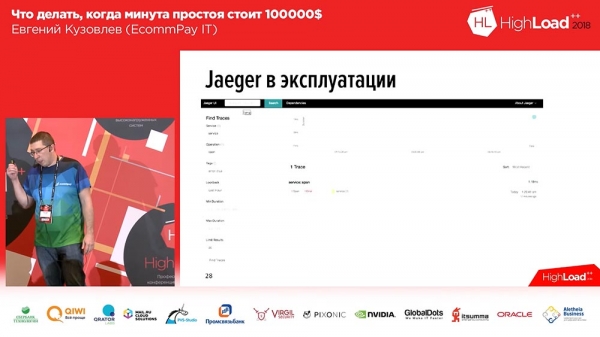
Yn Jaeger wurde spans makke foar elk berjocht. Dat is, as in brûker it systeem iepenet, sjocht hy ien of twa blokken foar elke ynkommende fersyk (1-2-3 - it oantal ynkommende oanfragen fan 'e brûker, it oantal blokken). Om it makliker te meitsjen foar brûkers, hawwe wy tags tafoege oan de logs en tiidspoaren. Dêrom sil ús applikaasje yn gefal fan in flater it log markearje mei de passende flatertag. Jo kinne filterje op Flatertag en allinich spans dy't dit blok befetsje mei in flater sille werjûn wurde. Dit is hoe't it derút sjocht as wy de span útwreidzje:
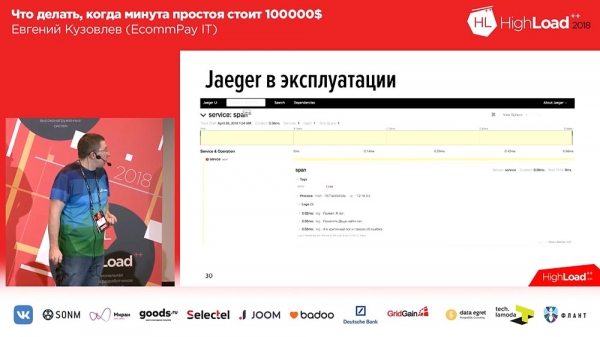
Binnen de span is der in set fan spoaren. Yn dit gefal binne dit trije testspoaren, en it tredde spoar fertelt ús dat der in flater bard is. Tagelyk sjogge wy hjir in tiidspoar: wy hawwe in tiidskaal boppe, en wy sjogge op hokker tiid ynterval dit of dat log waard opnommen.Dêrtroch gong it goed mei ús. Wy hawwe ús eigen útwreiding skreaun en wy hawwe it iepen boarne. As jo wolle wurkje mei tracing, as jo wolle wurkje mei "Jager" yn PHP, d'r is ús tafoeging, wolkom om te brûken, sa't se sizze:
Wy hawwe dizze tafoeging - it is in klant foar de OpenTracing Api, it is makke as php-útwreiding, dat is, jo moatte it sammelje en ynstallearje op it systeem. In jier lyn wie der neat oars. No binne d'r oare kliïnten dy't as komponinten binne. Hjir is it oan jo: of jo pompe de komponinten út mei in komponist, of jo brûke útwreiding oant jo.Corporate noarmen
Wy hawwe it oer de trije geboaden. It fjirde gebod is om oanpak te standardisearjen. Wêr giet dit oer? It giet hjiroer:
Wêrom is it wurd "bedriuw" hjir? Net om't wy in grut of burokratysk bedriuw binne, nee! Ik woe hjir it wurd "bedriuw" brûke yn 'e kontekst dat elk bedriuw, elk produkt syn eigen noarmen moatte hawwe, ynklusyf jo. Hokker noarmen hawwe wy?- Wy hawwe ynsetregels. Wy ferhúzje nergens sûnder him, wy kinne net. Wy sette sa'n 60 kear yn 'e wike yn, dat is, wy sette hast konstant yn. Tagelyk hawwe wy bygelyks yn de ynsetregeling in taboe op ynset op freed - yn prinsipe sette wy net yn.
- Wy easkje dokumintaasje. Net ien nij ûnderdiel komt yn produksje as der gjin dokumintaasje foar is, ek al is it berne ûnder de pinne fan ús RnD-spesjalisten. Wy fereaskje fan har ynset ynstruksjes, in tafersjochkaart en in rûge beskriuwing (goed, lykas programmeurs kinne skriuwe) fan hoe't dizze komponint wurket, hoe't jo it kinne oplosse.
- Wy losse net de oarsaak fan it probleem op, mar it probleem - wat ik al sei. It is wichtich foar ús om de brûker te beskermjen tsjin problemen.
- Wy hawwe fergunningen. Bygelyks, wy beskôgje it gjin downtime as wy binnen twa minuten 2% fan ferkear ferlern hawwe. Dit is yn prinsipe net opnommen yn ús statistiken. As it mear yn persintaazje of tydlik is, telle wy al.
- En wy skriuwe altyd postmortems. Wat der ek mei ús bart, elke situaasje dêr't immen yn 'e produksje abnormaal gedraacht, sil wurde wjerspegele yn' e post-mortem. In postmortem is in dokumint wêryn jo skriuwe wat jo bard is, in detaillearre timing, wat jo dien hawwe om it te korrigearjen en (dit is in ferplichte blokje!) wat jo sille dwaan om foar te kommen dat dit yn 'e takomst bart. Dit is ferplichte en nedich foar folgjende analyze.
Wat wurdt beskôge as downtime?
Wat hat dit alles laat ta?Dit late ta it feit dat (wy hiene bepaalde problemen mei stabiliteit, dit paste net by kliïnten of ús) yn 'e ôfrûne 6 moannen wie ús stabiliteitsindikator 99,97. Wy kinne sizze dat dit net folle is. Ja, wy hawwe wat om nei te stribjen. Fan dizze yndikator is sawat de helte de stabiliteit, as it wie, net fan ús, mar fan ús webapplikaasje-firewall, dy't foar ús stiet en wurdt brûkt as tsjinst, mar kliïnten dogge dit net oer.
Wy learden nachts sliepe. Úteinlik! Seis moanne lyn koenen wy net. En op dizze notysje mei de resultaten wol ik ien notysje meitsje. Justerjûn wie der in prachtich ferslach oer it bestjoeringssysteem foar in kearnreaktor. As de minsken dy't dit systeem skreaunen my kinne hearre, ferjit dan asjebleaft wat ik sei oer "2% is gjin downtime." Foar jo is 2% downtime, sels as foar twa minuten!
Da's alles! Jo fragen.
Oer balancers en databankmigraasje
Fraach út it publyk (hjirnei – B): – Goeie jûn. Tige tank foar sa'n admin ferslach! In koarte fraach oer jo balancers. Jo hawwe neamd dat jo in WAF hawwe, dat is, sa't ik it begryp, jo brûke in soarte fan eksterne balancer ...
EK: - Nee, wy brûke ús tsjinsten as in balancer. Yn dit gefal is WAF eksklusyf in DDoS-beskermingsark foar ús.
Yn: - Kinne jo in pear wurden sizze oer balancers?
EK: - Lykas ik al sei, dit is in groep servers yn openresty. Wy hawwe no 5 reservegroepen dy't eksklusyf reagearje ... dat is, in server dy't eksklusyf iepenresty rint, it proxearret allinich ferkear. Dêrom, om te begripen hoefolle wy hâlde: wy hawwe no in reguliere ferkearsstream fan ferskate hûndert megabits. Se dogge it, se fiele har goed, se spanne har net iens yn.
Yn: - Ek in ienfâldige fraach. Hjir is Blau / Grien ynset. Wat dogge jo bygelyks mei databankmigraasjes?
EK: - Goeie fraach! Sjoch, yn Blau / Grien ynset hawwe wy aparte wachtrigen foar elke rigel. Dat is, as wy it hawwe oer evenemintewachtrigen dy't wurde oerdroegen fan arbeider nei arbeider, binne d'r aparte wachtrigen foar de blauwe line en foar de griene line. As wy it oer de databank sels hawwe, dan hawwe wy it mei opsetsin beheind safolle as wy koenen, alles praktysk ferpleatst yn wachtrijen yn 'e databank bewarje wy allinich in stapel fan transaksjes. En ús transaksjestapel is itselde foar alle rigels. Mei de databank yn dit ferbân: wy diele it net yn blau en grien, om't beide ferzjes fan 'e koade moatte witte wat der bart mei de transaksje.
Freonen, ik haw ek in lytse priis om jo oan te moedigjen - in boek. En ik moat it bekroand wurde foar de bêste fraach.
Yn: - Hallo. Tank foar it ferslach. De fraach is dit. Jo kontrolearje betellingen, jo kontrolearje de tsjinsten wêrmei jo kommunisearje ... Mar hoe kontrolearje jo dat in persoan op ien of oare manier nei jo betellingsside kaam, in betelling makke en it projekt him mei jild ynskreaun hat? Dat is, hoe kontrolearje jo dat de marchant beskikber is en jo callback hat akseptearre?
EK: - "Keapman" foar ús yn dit gefal is krekt deselde eksterne tsjinst as de betelling systeem. Wy kontrolearje de antwurdsnelheid fan 'e keapman.
Oer databank fersifering
Yn: - Hallo. Ik haw in bytsje relatearre fraach. Jo hawwe PCI DSS gefoelige gegevens. Ik woe witte hoe't jo PAN's opslaan yn wachtrigen wêryn jo moatte oerdrage? Brûke jo fersifering? En dit liedt ta de twadde fraach: neffens PCI DSS is it nedich om de databank periodyk opnij te fersiferjen yn gefal fan feroaringen (ûntslach fan behearders, ensfh.) - wat bart der mei tagonklikens yn dit gefal?
EK: - Prachtige fraach! As earste bewarje wy PAN's net yn wachtrigen. Wy hawwe net it rjocht om PAN oeral yn iepen foarm op te slaan, yn prinsipe, dus wy brûke in spesjale tsjinst (wy neame it "Kademon") - dit is in tsjinst dy't mar ien ding docht: it ûntfangt in berjocht as ynfier en stjoert út in fersifere berjocht. En wy bewarje alles mei dit fersifere berjocht. Dêrtroch is ús kaailange minder dan in kilobyte, sadat dit serieus en betrouber is.Yn: – Binne jo no 2 kilobytes nedich?
EK: – It liket juster juster 256... No, wêr oars?!
Dêrtroch is dit de earste. En twad, de oplossing dy't bestiet, it stipet de proseduere foar opnij fersifering - d'r binne twa pearen "keks" (kaaien), dy't "decks" jouwe dy't fersiferje (kaai binne de kaaien, dek binne derivatives fan 'e kaaien dy't fersiferje) . En as de proseduere is inisjearre (it bart regelmjittich, fan 3 moannen oant ± guon), download wy in nij pear "cakes", en wy fersiferje de gegevens opnij. Wy hawwe aparte tsjinsten dy't alle gegevens ripje en op in nije manier fersiferje; De gegevens wurde opslein neist de identifier fan 'e kaai wêrmei't se fersifere binne. Sa gau as wy de gegevens fersiferje mei nije kaaien, wiskje wy de âlde kaai.
Soms moatte betellingen mei de hân makke wurde ...
Yn: - Dat is, as in weromjefte is oankaam foar guon operaasje, sille jo it noch ûntsiferje mei de âlde kaai?
EK: - Ja.
Yn: – Dan noch ien lytse fraach. As in soarte fan mislearring, fal of ynsidint foarkomt, is it nedich om de transaksje mei de hân troch te drukken. Der is sa'n situaasje.
EK: - Ja somtiden.
Yn: - Wêr krije jo dizze gegevens wei? Of geane jo sels nei dizze opslach?
EK: - Nee, no, fansels, wy hawwe in soarte fan back-office systeem dat befettet in ynterface foar ús stipe. As wy net witte yn hokker status de transaksje is (bygelyks oant it betellingssysteem mei in time-out antwurde), witte wy net a priori, dat is, wy jouwe de definitive status allinich mei folslein fertrouwen. Yn dit gefal jouwe wy de transaksje ta in spesjale status foar hânmjittich ferwurkjen. Moarns, de oare deis, sa gau as stipe ynformaasje krijt dat sokke en sokke transaksjes yn it betellingssysteem bliuwe, ferwurkje se se manuell yn dizze ynterface.
Yn: - Ik haw in pear fragen. Ien fan har is de fuortsetting fan 'e PCI DSS-sône: hoe registrearje jo har circuit? Dizze fraach is om't de ûntwikkelder alles yn 'e logs koe hawwe pleatst! Twadde fraach: hoe rôlje jo hotfixes út? It brûken fan hânfetten yn 'e databank is ien opsje, mar d'r kinne fergese hot-fixes wêze - wat is de proseduere dêr? En de tredde fraach is wierskynlik relatearre oan RTO, RPO. Jo beskikberens wie 99,97, hast fjouwer njoggenen, mar sa't ik it begryp, hawwe jo in twadde datasintrum, in tredde datasintrum en in fyfde datasintrum ... Hoe syngronisearje se, replikearje se, en al it oare?EK: - Litte wy begjinne mei de earste. Wie de earste fraach oer logs? As wy logs skriuwe, hawwe wy in laach dy't alle gefoelige gegevens maskearret. Se sjocht nei it masker en nei de ekstra fjilden. Dêrtroch komme ús logs út mei al maskere gegevens en in PCI DSS-sirkwy. Dit is ien fan 'e reguliere taken tawiisd oan' e testôfdieling. Se binne ferplichte om elke taak te kontrolearjen, ynklusyf de logs dy't se skriuwe, en dit is ien fan 'e reguliere taken by koadebeoardielingen, om te kontrolearjen dat de ûntwikkelder net wat opskreaun hat. Dêropfolgjende kontrôles wurde sa'n ien kear yn 'e wike geregeld troch de ôfdieling ynformaasjefeiligens útfierd: logs foar de lêste dei wurde selektyf nommen en se wurde troch in spesjale scanner-analyzer fan testservers útfierd om alles te kontrolearjen.
Oer hot-fixes. Dit is opnommen yn ús ynsetregels. Wy hawwe in aparte klausule oer hotfixes. Wy leauwe dat wy hotfixes rûn de klok ynsette as wy it nedich binne. Sadree't de ferzje is gearstald, sa gau as it wurdt útfierd, sa gau as wy hawwe in artefakt, wy hawwe in systeembehearder op plicht op in oprop fan stipe, en hy ynset it op it momint dat it nedich is.Oer "fjouwer njoggenen". It figuer dat wy no hawwe is wirklik berikt, en wy hawwe der nei stribbe yn in oar datasintrum. No hawwe wy in twadde datasintrum, en wy begjinne te rûte tusken har, en it probleem fan cross-data center replikaasje is wirklik in net-triviale fraach. Wy besochten it op ien kear op te lossen mei ferskate middels: wy besochten deselde "Tarantula" te brûken - it slagge ús net, sil ik jo daliks fertelle. Dêrom hawwe wy de "sens" mei de hân besteld. Yn feite, elke applikaasje yn ús systeem rint de nedige "feroarje - dien" syngronisaasje tusken datasintra asynchronous.
Yn: - As jo in twadde krigen hawwe, wêrom hawwe jo dan net in tredde krigen? Want gjinien hat noch split-brain...
EK: - Mar wy hawwe gjin Split Brain. Troch it feit dat elke applikaasje wurdt oandreaun troch in multimaster, makket it ús net út op hokker sintrum it fersyk kaam. Wy binne klear foar it feit dat as ien fan ús data sintra mislearret (wy fertrouwe op dit) en yn 'e midden fan in brûker fersyk skeakelt nei de twadde data sintrum, wy binne ree om te ferliezen dizze brûker, yndie; mar dit sille ienheden wêze, absolute ienheden.
Yn: - Goejûn. Tank foar it ferslach. Jo hawwe it oer jo debugger, dy't guon testtransaksjes yn produksje útfiert. Mar fertel ús oer test transaksjes! Hoe djip giet it?
EK: - It giet troch de folsleine syklus fan 'e hiele komponint. Foar in komponint is der gjin ferskil tusken in test transaksje en in produksje. Mar út in logysk eachpunt is dit gewoan in apart projekt yn it systeem, wêrop allinich testtransaksjes wurde útfierd.
Yn: - Wêr snijsto it ôf? Hjir stjoerde Core...
EK: - Wy binne efter "Kor" yn dit gefal foar testtransaksjes ... Wy hawwe sa'n ding as routing: "Kor" wit nei hokker betellingssysteem te stjoeren - wy stjoere nei in falsk betellingssysteem, dat gewoan in http-sinjaal jout en da's alles.
Yn: - Fertel my asjebleaft, wie jo applikaasje skreaun yn ien enoarme monolith, of hawwe jo it yn guon tsjinsten of sels mikrotsjinsten besunige?
EK: - Wy hawwe gjin monolith, fansels, wy hawwe in tsjinst-rjochte applikaasje. Wy grapke dat ús tsjinst is makke fan monoliten - se binne echt frij grut. It is lestich om it mikrotsjinsten te neamen, mar dit binne tsjinsten wêryn arbeiders fan ferdielde masines wurkje.
As de tsjinst op 'e tsjinner kompromitteare is ...
Yn: - Dan haw ik de folgjende fraach. Sels as it in monolyt wie, hawwe jo noch sein dat jo in protte fan dizze direkte tsjinners hawwe, se ferwurkje allegear yn prinsipe gegevens, en de fraach is: "Yn it gefal fan in kompromis fan ien fan 'e direkte tsjinners as in applikaasje, elke yndividuele keppeling , hawwe se in soarte fan tagong kontrôle? Wa fan harren kin wat dwaan? Wa moat ik kontakt opnimme foar hokker ynformaasje?
EK: - Ja, seker. De feiligenseasken binne frij serieus. As earste hawwe wy iepen gegevensbewegingen, en de havens binne allinich dejingen wêrmei't wy ferkearsbeweging fan tefoaren ferwachtsje. As in komponint kommunisearret mei de databank (sizze, mei Muskul) fia 5-4-3-2, sil allinnich 5-4-3-2 iepen wêze foar it, en oare havens en oare ferkearsrjochtingen sille net beskikber wêze. Derneist moatte jo begripe dat yn ús produksje sa'n 10 ferskillende feiligensloops binne. En sels as de applikaasje op ien of oare manier kompromittearre wie, God ferbean, sil de oanfaller gjin tagong krije ta de tsjinnerbehearkonsole, om't dit in oare netwurkfeiligenssône is.Yn: - En yn dizze kontekst is wat my nijsgjirriger is dat jo bepaalde kontrakten hawwe mei tsjinsten - wat se kinne dwaan, troch hokker "aksjes" se kinne kontakt opnimme ... En yn in normale stream freegje guon spesifike tsjinsten wat rige, in list fan "aksjes" oan de oare. Se lykje net te kearen nei oaren yn in normale situaasje, en se hawwe oare gebieten fan ferantwurdlikens. As ien fan har is kompromittearre, sil it dan de "aksjes" fan dy tsjinst kinne fersteure?
EK: - Ik begryp it. As yn in normale situaasje mei in oare tsjinner kommunikaasje wie tastien, dan ja. Neffens de SLA kontrakt, wy net tafersjoch op dat jo allinne tastien de earste 3 "aksjes", en jo binne net tastien de 4 "aksjes". Dit is nei alle gedachten oerstallich foar ús, om't wy hawwe al in 4-nivo beskerming systeem, yn prinsipe, foar circuits. Wy ferdigenje ússels leaver mei de kontoeren, as op it nivo fan 'e binnenkant.
Hoe Visa, MasterCard en Sberbank wurkje
Yn: - Ik wol in punt dúdlik meitsje oer it wikseljen fan in brûker fan it iene datasintrum nei it oare. Sa fier as ik wit, operearje Visa en MasterCard mei help fan de 8583 binêre syngroane protokol, en der binne mixen dêr. En ik woe witte, no bedoele wy it wikseljen - is it direkt "Visa" en "MasterCard" of foar betellingssystemen, foardat jo ferwurkje?
EK: - Dit is foar de mingen. Us mixen lizze yn itselde datasintrum.
Yn: – Hasto rûchwei ien oanslutingspunt?
EK: - "Visa" en "MasterCard" - ja. Gewoan om't Visa en MasterCard frij serieuze ynvestearrings yn ynfrastruktuer fereaskje om aparte kontrakten te sluten om bygelyks in twadde pear mixen te krijen. Se binne reservearre binnen ien datasintrum, mar as, God ferbiede, ús datasintrum, wêr't mixen binne foar ferbining mei Visa en MasterCard, stjert, dan sille wy in ferbining hawwe mei Visa en MasterCard ferlern ...
Yn: - Hoe kinne se reservearre wurde? Ik wit dat Visa lit mar ien ferbining yn prinsipe!
EK: – Se leverje de apparatuer sels. Yn alle gefallen hawwe wy apparatuer krigen dy't fan binnen folslein oerstallich is.
Yn: – Dus de stand is fan harren Connects Orange?..
EK: - Ja.
Yn: - Mar hoe sit it mei dizze saak: as jo datasintrum ferdwynt, hoe kinne jo it dan fierder brûke? Of hâldt it ferkear gewoan op?
EK: - Nee. Yn dit gefal sille wy it ferkear gewoan oerskeakelje nei in oar kanaal, dat, fansels, djoerder sil wêze foar ús en djoerder foar ús kliïnten. Mar it ferkear sil net gean troch ús direkte ferbining mei Visa, MasterCard, mar troch de betingst Sberbank (tige oerdreaun).
Ik ferûntskuldigje my wyld as ik Sberbank meiwurkers misledige. Mar neffens ús statistiken, ûnder de Russyske banken falt Sberbank it meast. Der giet gjin moanne foarby sûnder dat der wat ôffalt by Sberbank.

Guon advertinsjes 🙂
Tankewol foar it bliuwen by ús. Hâld jo fan ús artikels? Wolle jo mear ynteressante ynhâld sjen? Stypje ús troch in bestelling te pleatsen of oan te befeljen oan freonen, , in unike analoog fan servers op yngongsnivo, dy't troch ús foar jo útfûn is: (beskikber mei RAID1 en RAID10, oant 24 kearnen en oant 40GB DDR4).
Dell R730xd 2 kear goedkeaper yn Equinix Tier IV data sintrum yn Amsterdam? Allinne hjir yn Nederlân! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - fan $99! Lêze oer



















Boarne: www.habr.com
