

prehistoarje
D'r binne automaten fan ús eigen ûntwerp. Binnen de Raspberry Pi en wat bedrading op in apart boerd. In munt akseptearder, in rekken akseptor, in bank terminal binne ferbûn ... Alles wurdt regele troch in sels skreaun programma. De hiele wurkskiednis wurdt skreaun nei in log op in flash-drive (MicroSD), dy't dan fia it ynternet (mei in USB-modem) oerbrocht wurdt nei de tsjinner, wêr't it wurdt opslein yn in databank. Ferkeapynformaasje wurdt laden yn 1c, d'r is ek in ienfâldige webynterface foar tafersjoch, ensfh.
Dat is, it tydskrift is essensjeel - foar boekhâlding (ynkomsten, ferkeap, ensfh.), Tafersjoch (alle soarten mislearrings en oare oermacht omstannichheden); Dit, men soe sizze, is alle ynformaasje dy't wy hawwe oer dizze masine.
probleem
Flash-driven litte harsels sjen as heul ûnbetroubere apparaten. Se mislearje mei oergeunstige regelmaat. Dit liedt ta sawol masine-downtime as (as om ien of oare reden it log net online koe wurde oerdroegen) ta gegevensferlies.
Dit is net de earste ûnderfining fan it brûken fan flash drives, foardat dit wie in oar projekt mei mear as hûndert apparaten, dêr't it tydskrift waard opslein op USB flash drives, d'r wiene ek problemen mei betrouberens, soms it tal fan dyjingen dy't mislearre yn in moanne wie yn de tsientallen. Wy besochten ferskate flash-driven, ynklusyf merken mei SLC-ûnthâld, en guon modellen binne betrouberer as oaren, mar it ferfangen fan flash-driven hat it probleem net radikaal oplost.
Wês opsichtich! Longread! As jo net ynteressearre binne yn "wêrom", mar allinich yn "hoe", kinne jo direkt gean artikels.
beslút
It earste ding dat yn 't sin komt is: ferlitte MicroSD, ynstallearje bygelyks in SSD en bootje derút. Teoretysk mooglik, wierskynlik, mar relatyf djoer, en net sa betrouber (in USB-SATA-adapter wurdt tafoege; flaterstatistiken foar budzjet-SSD's binne ek net bemoedigjend).
USB HDD liket ek net as in bysûnder oantreklike oplossing.
Dêrom, wy kamen ta dizze opsje: lit booting út MicroSD, mar brûk se yn read-allinne modus, en bewarje de operaasje log (en oare ynformaasje unyk foar in bepaald stik hardware - serial number, sensor kalibraasjes, ensfh) earne oars .
It ûnderwerp fan allinich lês FS foar frambozen is al binnen en bûten studearre, ik sil net yngean op ymplemintaasjedetails yn dit artikel (mar as der belangstelling is, skriuw ik miskien in mini-artikel oer dit ûnderwerp). It ienige punt dat ik wol opmerke is dat sawol út persoanlike ûnderfining as út resinsjes fan dyjingen dy't it al hawwe ymplementearre, d'r in winst is yn betrouberens. Ja, it is ûnmooglik om folslein kwyt te reitsjen fan storingen, mar it is hiel mooglik om har frekwinsje signifikant te ferminderjen. En de kaarten wurde ferienige, dat makket ferfanging folle makliker foar tsjinst personiel.
Hardware
Der wie gjin bysûndere twifel oer de kar fan ûnthâld type - NOR Flash.
Arguminten:
- ienfâldige ferbining (meast faaks de SPI-bus, dy't jo al ûnderfining hawwe mei it brûken, dus gjin hardwareproblemen binne foarsjoen);
- ridlike priis;
- standert bestjoeringsprotokol (ymplemintaasje is al yn 'e kernel) Linux, as jo wolle, kinne jo in tredde partij nimme, dy't ek oanwêzich binne, of sels jo eigen skriuwe, gelokkich is alles ienfâldich);
- betrouberens en boarne:
út in typysk datasheet: gegevens wurde opslein foar 20 jier, 100000 wiske syklusen foar elk blok;
út boarnen fan tredden: ekstreem lege BER, postulearret gjin ferlet fan flaterkorreksje koades (guon wurken beskôgje ECC foar NOR, mar normaal betsjutte se noch altyd MLC NOR; dit bart ek).
Lit ús skatte de easken foar folume en boarne.
Ik wol graach dat de gegevens garandearre wurde foar ferskate dagen opslein. Dit is nedich om yn gefal fan kommunikaasjeproblemen de ferkeapskiednis net ferlern te gean. Wy sille rjochtsje op 5 dagen, yn dizze perioade (ek rekken hâldend mei wykeinen en feestdagen) it probleem kin wurde oplost.
Wy sammelje op it stuit sawat 100kb logs per dei (3-4 tûzen ynstjoerings), mar stadichoan groeit dit sifer - it detail nimt ta, nije eveneminten wurde tafoege. Plus, soms binne der bursts (guon sensor begjint spamming mei falske positiven, bygelyks). Wy sille foar 10 tûzen records elk 100 bytes berekkenje - megabytes per dei.
Yn totaal komt 5MB oan skjinne (goed komprimearre) gegevens út. Mear oan harren (rûge skatting) 1MB oan tsjinst gegevens.
Dat is, wy hawwe in 8MB-chip nedich as wy gjin kompresje brûke, of 4MB as wy it brûke. Hiel realistyske sifers foar dit soarte fan ûnthâld.
Wat de boarne oanbelanget: as wy fan plan binne dat it heule ûnthâld net mear as ien kear elke 5 dagen herskreaun wurdt, dan krije wy oer 10 jier tsjinst minder dan tûzen herskriuwsyklusen.
Lit my herinnerje jo dat de fabrikant belooft hûndert tûzen.
In bytsje oer NOR vs NAND
Tsjintwurdich is NAND-ûnthâld fansels folle populêrder, mar ik soe it net brûke foar dit projekt: NAND, yn tsjinstelling ta NOR, fereasket needsaaklikerwize it brûken fan flaterkorreksjekoades, in tabel mei minne blokken, ensfh., En ek de skonken fan NAND chips meastal folle mear.
De neidielen fan NOR omfetsje:
- lyts folume (en dus hege priis per megabyte);
- lege kommunikaasje snelheid (foar it grutste part fanwege it feit dat in serial ynterface wurdt brûkt, meastal SPI of I2C);
- stadich wiskjen (ôfhinklik fan 'e blokgrutte duorret it fan in fraksje fan in sekonde oant ferskate sekonden).
It liket derop dat der neat kritysk foar ús is, dus wy geane troch.
As de details ynteressant binne, is it mikrocircuit selektearre (dit is lykwols ûnbelangryk, d'r binne in protte analogen op 'e merke dy't kompatibel binne yn pinout en kommandosysteem; sels as wy in mikrokring fan in oare fabrikant en / of in oare grutte wolle ynstallearje, sil alles wurkje sûnder de feroaring te feroarjen koade).
Ik brûk dejinge dy't yn 'e kernel ynboud is Linux Bestjoerder, op Raspberry Pi, tanksij de stipe foar apparaatbeam-overlays, is alles hiel ienfâldich - jo moatte de kompilearre overlay yn /boot/overlays pleatse en /boot/config.txt in bytsje oanpasse.
Foarbyld dts file
Om earlik te wêzen, ik bin der net wis fan dat it is skreaun sûnder flaters, mar it wurket.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};En in oare rigel yn config.txt
dtoverlay=at25:spimaxfrequency=50000000Ik sil de beskriuwing fan it ferbinen fan de chip nei de Raspberry Pi weglitte. Oan 'e iene kant bin ik gjin ekspert yn elektroanika, oan' e oare kant is alles hjir banaal sels foar my: it mikrocircuit hat mar 8 skonken, wêrfan wy grûn, krêft, SPI (CS, SI, SO, SCK nedich binne) ); de nivo's binne itselde as dy fan 'e Raspberry Pi, gjin ekstra bedrading is nedich - ferbine gewoan de oanjûne 6 pins.
Probleemintwurding
Lykas gewoanlik giet de probleemstelling troch ferskate iteraasjes, en it liket my ta dat it tiid is foar de folgjende. Litte wy dus stopje, gearstelle wat al skreaun is en de details dúdlik meitsje dy't yn it skaad bliuwe.
Dat, wy hawwe besletten dat it log sil wurde opslein yn SPI NOR Flash.
Wat is NOR Flash foar dyjingen dy't it net witte?
Dit is net-flechtich ûnthâld wêrmei jo trije operaasjes kinne dwaan:
- Lêzing:
De meast foarkommende lêzing: wy stjoere it adres oer en lêze safolle bytes as wy nedich binne; - Opnimme:
It skriuwen nei NOR flash liket in gewoane, mar it hat ien eigenaardichheid: jo kinne allinich 1 nei 0 feroarje, mar net oarsom. As wy bygelyks 0x55 yn in ûnthâldsel hiene, dan sil nei it skriuwen fan 0x0f dêr al 0x05 opslein wurde (sjoch tabel krekt hjirûnder); - Wiskje:
Fansels moatte wy de tsjinoerstelde operaasje dwaan kinne - feroarje fan 0 nei 1, dit is krekt wêr't de wiskje operaasje foar is. Oars as de earste twa, wurket it net mei bytes, mar mei blokken (it minimale wisblok yn 'e selektearre chip is 4kb). Wiskje ferneatiget it hiele blok en is de ienige manier om te feroarjen 0 oan 1. Dêrom, as jo wurkje mei flash ûnthâld, moatte jo faaks gegevensstruktueren ôfstimme op 'e wiskje blokgrins.
Opname yn NOR Flash:
Binêre gegevens
It wie
01010101
Opnommen
00001111
Is wurden
00000101
It log sels stiet foar in sekwinsje fan records fan fariabele lingte. De typyske lingte fan in record is sa'n 30 bytes (hoewol't records dy't ferskate kilobytes lang binne soms foarkomme). Yn dit gefal wurkje wy gewoan mei har as in set bytes, mar, as jo ynteressearre binne, wurdt CBOR brûkt yn 'e records
Neist it log moatte wy wat "ynstellings" ynformaasje opslaan, sawol bywurke as net: in bepaalde apparaat-ID, sensorkalibraasjes, in flagge "apparaat is tydlik útskeakele", ensfh.
Dizze ynformaasje is in set fan kaai-wearde records, ek opslein yn CBOR. Wy hawwe net in soad fan dizze ynformaasje (in pear kilobytes op syn meast), en it wurdt bywurke selden.
Yn it folgjende sille wy it kontekst neame.
As wy ûnthâlde wêr't dit artikel begon, is it heul wichtich om betroubere gegevensopslach te garandearjen en, as it mooglik is, trochgeande operaasje sels yn gefal fan hardwarefouten / datakorrupsje.
Hokker boarnen fan problemen kinne wurde beskôge?
- Útskeakelje tidens skriuw-/wisoperaasjes. Dit is fan 'e kategory fan "d'r is gjin trúk tsjin koevoet."
Ynformaasje fan op stackexchange: as de macht is útskeakele by it wurkjen mei flash, beide wiskjen (ynsteld op 1) en skriuwen (ynsteld op 0) liede ta ûndefiniearre gedrach: gegevens kinne wurde skreaun, foar in part skreaun (sizze, wy hawwe oerdroegen 10 bytes / 80 bits , mar noch net allinnich 45 bits kinne wurde skreaun), it is ek mooglik dat guon fan 'e bits sille wêze yn in "tusken" steat (lêzen kin produsearje sawol 0 en 1); - Flaters yn it flash ûnthâld sels.
BER, hoewol tige leech, kin net gelyk wêze oan nul; - Bus flaters
Gegevens oerbrocht fia SPI binne op gjin inkelde manier beskerme; sawol inkele bitflaters as syngronisaasjeflaters kinne foarkomme - ferlies of ynfoegje fan bits (wat liedt ta massive gegevensferfoarming); - Oare flaters / glitches
Flaters yn 'e koade, Raspberry glitches, alien ynterferinsje ...
Ik haw de easken formulearre, wêrfan it ferfoljen nei myn miening nedich is om betrouberens te garandearjen:
- records moatte fuortendaliks yn it flash-ûnthâld gean, fertrage skriuwingen wurde net beskôge; - as in flater optreedt, moat dy sa betiid mooglik ûntdutsen en ferwurke wurde; - it systeem moat, as it mooglik is, herstelle fan flaters.
(in foarbyld út it libben "hoe't it net moat", dat ik tink dat elkenien tsjinkaam is: nei in needreboot is it bestânsysteem "brutsen" en it bestjoeringssysteem bootet net)
Ideeën, oanpakken, refleksjes
Doe't ik begon te tinken oer dit probleem, flitsen in protte ideeën troch myn holle, bygelyks:
- brûk gegevens kompresje;
- brûk tûke gegevensstruktueren, bygelyks, bewarje recordkoppen apart fan 'e records sels, sadat as der in flater is yn elke record, kinne jo de rest sûnder problemen lêze;
- brûk bitfjilden om it foltôgjen fan opname te kontrolearjen as de macht útskeakele is;
- bewarje checksums foar alles;
- brûk wat soarte fan lûd-resistant kodearring.
Guon fan dizze ideeën waarden brûkt, wylst oaren besletten waarden ferlitten te wurden. Litte wy yn oarder gean.
Gegevenskompresje
De foarfallen sels dy't wy opnimme yn it tydskrift binne frij ferlykber en repeterber ("goaie in munt fan 5 roebel", "drukte op de knop foar it jaan fan feroaring", ...). Dêrom moat kompresje frij effektyf wêze.
De kompresje-overhead is ûnbelangryk (ús prosessor is frij krêftich, sels de earste Pi hie ien kearn mei in frekwinsje fan 700 MHz, hjoeddeistige modellen hawwe ferskate kearnen mei in frekwinsje fan mear as in gigahertz), de wikselkoers mei de opslach is leech (ferskate megabytes per sekonde), de grutte fan 'e records is lyts. Yn 't algemien, as kompresje in ynfloed hat op prestaasjes, sil it allinich posityf wêze. (absoluut net kritysk, gewoan sizze)Plus, wy hawwe gjin echte ynbêde, mar in gewoane. Linux — dus de ymplemintaasje moat net folle muoite fereaskje (it is genôch om gewoan de bibleteek te keppeljen en in pear funksjes dêrfan te brûken).
In stik fan it log waard nommen fan in wurkjend apparaat (1.7 MB, 70 tûzen yngongen) en earst kontrolearre foar komprimerberens mei gzip, lz4, lzop, bzip2, xz, zstd beskikber op 'e kompjûter.
- gzip, xz, zstd lieten ferlykbere resultaten sjen (40Kb).
Ik wie ferrast dat de modieuze xz him hjir op it nivo fan gzip of zstd sjen liet; - lzip mei standertynstellingen joech wat minder resultaten;
- lz4 en lzop lieten net heul goede resultaten sjen (150Kb);
- bzip2 liet in ferrassend goed resultaat sjen (18Kb).
Dat, de gegevens wurde hiel goed komprimearre.
Dus (as wy gjin fatale gebreken fine) sil der kompresje wêze! Gewoan om't mear gegevens kinne passe op deselde flash drive.
Lit ús tinke oer de neidielen.
Earste probleem: wy hawwe al ôfpraat dat elk plaat fuortdaliks nei flits gean moat. Typysk sammelet de argivator gegevens fan 'e ynfierstream oant it beslút dat it tiid is om te skriuwen yn it wykein. Wy moatte fuortendaliks ûntfange in komprimearre blok fan gegevens en bewarje it yn net-flechtich ûnthâld.
Ik sjoch trije manieren:
- Komprimearje elk rekord mei help fan wurdboekkompresje ynstee fan de hjirboppe besprutsen algoritmen.
It is in folslein wurkjende opsje, mar ik fyn it net leuk. Om in min of mear fatsoenlik nivo fan kompresje te garandearjen, moat it wurdboek "op maat" wurde oan spesifike gegevens; elke feroaring sil liede ta it kompresjenivo katastrofysk falt. Ja, it probleem kin wurde oplost troch it meitsjen fan in nije ferzje fan it wurdboek, mar dit is in kopke - wy sille moatte opslaan alle ferzjes fan it wurdboek; yn elke yngong moatte wy oanjaan mei hokker ferzje fan it wurdboek it komprimearre is... - Komprimearje elk rekord mei "klassike" algoritmen, mar ûnôfhinklik fan 'e oaren.
De kompresje-algoritmen dy't wurde beskôge binne net ûntwurpen om te wurkjen mei records fan dizze grutte (tsientallen bytes), de kompresjeferhâlding sil dúdlik minder wêze as 1 (dat is, it fergrutsjen fan it gegevensvolumint ynstee fan komprimearjen); - Doch FLUSH nei eltse opname.
In protte kompresjebiblioteken hawwe stipe foar FLUSH. Dit is in kommando (of in parameter foar de kompresjeproseduere), by ûntfangst wêrfan de archiver in komprimearre stream foarmet, sadat it kin wurde brûkt om te herstellen allegear net-komprimearre gegevens dy't al ûntfongen binne. Sa'n analoogsyncyn triemsystemen ofcommityn sql.
Wat wichtich is, is dat folgjende kompresje-operaasjes it opboude wurdboek kinne brûke en de kompresjeferhâlding sil net safolle lije as yn 'e foarige ferzje.
Ik tink dat it fanselssprekkend is dat ik de tredde opsje keas, lit ús it yn mear detail besjen.
Fûn oer FLUSH yn zlib.
Ik die in knibbeltest basearre op it artikel, naam 70 tûzen logyngongen fan in echt apparaat, mei in sidegrutte fan 60Kb (wy komme letter werom op sidegrutte) ûntfongen:
Roald gegevens
Kompresje gzip -9 (gjin FLUSH)
zlib mei Z_PARTIAL_FLUSH
zlib mei Z_SYNC_FLUSH
Volume, KB
1692
40
352
604
Op it earste each is de priis bydroegen troch FLUSH te heech, mar yn 'e realiteit hawwe wy in bytsje kar - of net om hielendal te komprimearjen, of om te komprimearjen (en heul effektyf) mei FLUSH. Wy moatte net ferjitte dat wy 70 tûzen records hawwe, de oerstalligens yntrodusearre troch Z_PARTIAL_FLUSH is mar 4-5 bytes per record. En de kompresjeferhâlding die bliken hast 5: 1 te wêzen, dat is mear as in poerbêst resultaat.
It kin komme as in ferrassing, mar Z_SYNC_FLUSH is eins in effisjinter manier om FLUSH te dwaan
By it brûken fan Z_SYNC_FLUSH sille de lêste 4 bytes fan elke yngong altyd 0x00, 0x00, 0xff, 0xff wêze. En as wy se kenne, dan hoege wy se net te bewarjen, dus de definitive grutte is mar 324Kb.
It artikel dêr't ik nei keppele hat in útlis:
In nij type 0 blok mei lege ynhâld wurdt taheakke.
In blok type 0 mei lege ynhâld bestiet út:
- de trije-bit blok koptekst;
- 0 oant 7 bits gelyk oan nul, om byte-ôfstimming te berikken;
- de fjouwer-byte folchoarder 00 00 FF FF.
Sa't jo maklik sjen kinne, binne yn it lêste blok foar dizze 4 bytes fan 3 oant 10 nul bits. De praktyk hat lykwols sjen litten dat der eins op syn minst 10 nul bits binne.
It docht bliken dat sokke koarte blokken gegevens meastal (altyd?) wurde kodearre mei in blok fan type 1 (fêst blok), dat needsaaklik einiget mei 7 nul bits, wêrtroch in totaal fan 10-17 garandearre nul bits (en de rest sil wêze nul mei in kâns fan likernôch 50%).
Dat, op testgegevens, is d'r yn 100% fan 'e gefallen ien nul byte foar 0x00, 0x00, 0xff, 0xff, en yn mear as in tredde fan' e gefallen binne d'r twa nul bytes (miskien is it feit dat ik binary CBOR brûke, en by it brûken fan tekst JSON, blokken fan type 2 - dynamysk blok soene faker wêze, respektivelik, blokken sûnder ekstra nul bytes foardat 0x00, 0x00, 0xff, 0xff wurde tsjinkaam).
Yn totaal, mei de beskikbere testgegevens, is it mooglik om te passen yn minder dan 250Kb oan komprimearre gegevens.
Jo kinne wat mear besparje troch bitjonglerjen te dwaan: foar no negearje wy de oanwêzigens fan in pear nul bits oan 'e ein fan it blok, in pear bits oan it begjin fan it blok feroarje ek net ...
Mar doe naam ik in sterke wil om te stopjen, oars koe ik yn dit tempo myn eigen archiver ûntwikkelje.
Yn totaal krige ik fan myn testgegevens 3-4 bytes per skriuw, de kompresjeferhâlding die bliken mear as 6: 1 te wêzen. Ik sil earlik wêze: sa'n resultaat hie ik net ferwachte; neffens my is alles better as 2:1 al in resultaat dat it brûken fan kompresje rjochtfeardiget.
Alles is goed, mar zlib (deflate) is noch altyd in argaysk, goed fertsjinne en wat âlderwetske kompresjealgoritme. It gewoane feit dat de lêste 32Kb fan 'e net-komprimeare gegevensstream wurdt brûkt as in wurdboek sjocht der hjoed frjemd út (dat is, as guon gegevensblok tige ferlykber is mei wat wie yn' e ynfierstream 40Kb lyn, dan sil it opnij begjinne te argivearjen, en sil net ferwize nei in earder foarkommen). Yn modieuze moderne argiven wurdt de wurdboekgrutte faaks mjitten yn megabytes yn stee fan kilobytes.
Sa geane wy troch mei ús ministúdzje fan argivarissen.
Dêrnei testen wy bzip2 (ûnthâld, sûnder FLUSH toande it in fantastyske kompresjeferhâlding fan hast 100: 1). Spitigernôch die it heul min mei FLUSH; de grutte fan 'e komprimearre gegevens die bliken grutter te wêzen dan de net-komprimeare gegevens.
Myn oannames oer de redenen foar it mislearjen
Libbz2 biedt mar ien flush-opsje, dy't it wurdboek liket te wiskjen (analooch oan Z_FULL_FLUSH yn zlib); der is gjin sprake fan in effektive kompresje nei dit.
En de lêste te testen wie zstd. Ofhinklik fan 'e parameters komprimearret it op it nivo fan gzip, mar folle flugger, of better as gzip.
Och, mei FLUSH die it net heul goed: de grutte fan 'e komprimearre gegevens wie sawat 700Kb.
Я op 'e github-side fan it projekt krige ik in antwurd dat jo moatte rekkenje op maksimaal 10 bytes oan tsjinstgegevens foar elk blok mei komprimearre gegevens, wat ticht by de resultaten is krigen; d'r is gjin manier om deflate yn te heljen.
Ik besleat om op dit punt te stopjen yn myn eksperiminten mei argiven (lit my jo herinnerje dat xz, lzip, lzo, lz4 harsels net sjen litte sels op it teststadium sûnder FLUSH, en ik haw net mear eksoatyske kompresjealgoritmen beskôge).
Litte wy weromgean nei argyfproblemen.
De twadde (lykas se sizze yn oarder, net yn wearde) probleem is dat de komprimearre gegevens is in inkele stream, dêr't hieltyd ferwizings nei foarige seksjes. Dus, as in seksje fan komprimearre gegevens skansearre is, ferlieze wy net allinich it assosjearre blok fan net-komprimeare gegevens, mar ek alle folgjende.
D'r is in oanpak om dit probleem op te lossen:
- Foarkom dat it probleem opkomt - foegje redundans ta oan de komprimearre gegevens, wêrtroch jo flaters kinne identifisearje en korrigearje; dêr sille wy letter oer prate;
- Minimalisearje gefolgen as in probleem optreedt
Wy hawwe earder al sein dat jo elk gegevensblok selsstannich komprimearje kinne, en it probleem sil ferdwine troch himsels (skea oan 'e gegevens fan ien blok sil allinich foar dit blok liede ta it ferlies fan gegevens). Dit is lykwols in ekstreem gefal wêryn gegevenskompresje net effektyf sil wêze. It tsjinoerstelde ekstreem: brûk alle 4MB fan ús chip as ien argyf, wat ús poerbêste kompresje sil jaan, mar katastrofale gefolgen yn gefal fan datakorrupsje.
Ja, in kompromis is nedich yn termen fan betrouberens. Mar wy moatte betinke dat wy ûntwikkelje in gegevens opslach formaat foar net-flechtich ûnthâld mei ekstreem lege BER en in ferklearre gegevens opslach perioade fan 20 jier.
Tidens de eksperiminten ûntduts ik dat mear of minder merkbere ferliezen yn it kompresjenivo begjinne op blokken fan komprimearre gegevens minder dan 10 KB yn grutte.
It waard earder neamd dat it brûkte ûnthâld wurdt paged; Ik sjoch gjin reden wêrom't de korrespondinsje "ien side - ien blok mei komprimearre gegevens" net soe wurde brûkt.
Dat is, de minimale ridlike sidegrutte is 16Kb (mei in reserve foar tsjinstynformaasje). Sa'n lytse sidegrutte set lykwols wichtige beheiningen op foar de maksimale recordgrutte.
Hoewol't ik noch net ferwachtsje records grutter as in pear kilobytes yn komprimearre foarm, Ik besletten in gebrûk 32Kb siden (foar in totaal fan 128 siden per chip).
Summary:
- Wy bewarje gegevens komprimearre mei zlib (deflate);
- Foar elke yngong sette wy Z_SYNC_FLUSH;
- Foar elke komprimearre record trimme wy de efterste bytes (bgl 0x00, 0x00, 0xff, 0xff); yn de koptekst jouwe wy oan hoefolle bytes wy ôfsnien hawwe;
- Wy bewarje gegevens yn 32Kb siden; der is in inkele stream fan komprimearre gegevens binnen de side; Op elke side begjinne wy wer mei kompresje.
En, foardat ik mei kompresje einigje, wol ik jo omtinken freegje foar it feit dat wy mar in pear bytes oan komprimearre gegevens per record hawwe, dus it is ekstreem wichtich om de tsjinstynformaasje net op te blazen, elke byte telt hjir.
Gegevenskoppen opslaan
Sûnt wy hawwe records fan fariabele lingte, wy moatte ien of oare wize bepale de pleatsing / grinzen fan records.
Ik ken trije oanpak:
- Alle records wurde opslein yn in trochgeande stream, earst is der in record header mei dêryn de lingte, en dan it record sels.
Yn dizze belichaming kinne sawol kopteksten as gegevens fan fariabele lingte wêze.
Yn wêzen krije wy in inkeld keppele list dy't de hiele tiid brûkt wurdt; - Kopteksten en de records sels wurde opslein yn aparte streamen.
Troch it brûken fan kopteksten fan konstante lingte soargje wy derfoar dat skea oan ien koptekst gjin ynfloed hat op de oaren.
In ferlykbere oanpak wurdt brûkt, bygelyks, yn in protte triem systemen; - Records wurde opslein yn in trochgeande stream, de rekordgrins wurdt bepaald troch in bepaalde marker (in karakter/sekwinsje fan karakters dy't ferbean is binnen gegevensblokken). As d'r in marker yn it rekord is, dan ferfange wy it mei wat sekwinsje (ûntkommen).
In ferlykbere oanpak wurdt brûkt, bygelyks, yn it PPP-protokol.
Ik sil yllustrearje.
Option 1:

Alles is hjir hiel ienfâldich: wittende de lingte fan it rekôr, kinne wy it adres fan de folgjende koptekst berekkenje. Sa geane wy troch de kopteksten oant wy in gebiet tsjinkomme fol mei 0xff (frij gebiet) of it ein fan de side.
Option 2:

Troch de fariabele recordlingte kinne wy net fan tefoaren sizze hoefolle records (en dus kopteksten) wy per side nedich hawwe. Jo kinne de kopteksten en de gegevens sels ferspriede oer ferskate siden, mar ik leaver in oare oanpak: wy pleatse sawol de kopteksten as de gegevens op ien side, mar de kopteksten (fan konstante grutte) komme fan it begjin fan 'e side, en de gegevens (fan fariabele lingte) komt fan 'e ein. Sadree't se "treffe" (der is net genôch frije romte foar in nije yngong), beskôgje wy dizze side folslein.
Option 3:

D'r is gjin ferlet om de lingte of oare ynformaasje op te slaan oer de lokaasje fan 'e gegevens yn' e koptekst; markers dy't de grinzen fan 'e records oanjaan binne genôch. De gegevens moatte lykwols ferwurke wurde by it skriuwen/lêzen.
Ik soe 0xff brûke as marker (dy't de side foltôget nei it wiskjen), dus it frije gebiet sil perfoarst net as gegevens behannele wurde.
Fergeliking tabel:
Option 1
Option 2
Option 3
Flater tolerânsje
-
+
+
Kompakte
+
-
+
Kompleksiteit fan ymplemintaasje
*
**
**
Opsje 1 hat in fatale flater: as ien fan 'e kopteksten is skansearre, wurdt de hiele folgjende ketting ferneatige. De oerbleaune opsjes tastean jo te herstellen guon gegevens sels yn it gefal fan massive skea.
Mar hjir is it passend om te ûnthâlden dat wy besletten hawwe om de gegevens yn in komprimearre foarm op te slaan, en dus ferlieze wy alle gegevens op 'e side nei in "brutsen" rekord, dus ek al is d'r in minus yn' e tabel, wy dogge it net dêr rekken mei hâlde.
Kompaktens:
- yn 'e earste opsje moatte wy allinich de lingte yn' e koptekst opslaan; as wy heule getallen fan fariabele lingte brûke, dan kinne wy yn 'e measte gefallen mei ien byte komme;
- yn 'e twadde opsje moatte wy it begjinadres en de lingte opslaan; it rekord moat in konstante grutte wêze, ik skatte 4 bytes per rekord (twa bytes foar de offset, en twa bytes foar de lingte);
- de tredde opsje hat mar ien karakter nedich om it begjin fan 'e opname oan te jaan, plus de opname sels sil tanimme mei 1-2% troch shielding. Yn it algemien, likernôch pariteit mei de earste opsje.
Yn it earstoan beskôge ik de twadde opsje as de wichtichste (en skreau sels de ymplemintaasje). Ik haw it allinich ferlitten doe't ik úteinlik besleat kompresje te brûken.
Miskien ienris sil ik noch in ferlykbere opsje brûke. As ik bygelyks te krijen ha mei gegevensopslach foar in skip dat reizget tusken Ierde en Mars, sille d'r folslein oare easken wêze foar betrouberens, kosmyske strieling, ...
Wat de tredde opsje oangiet: ik joech it twa stjerren foar de swierrichheid fan ymplemintaasje gewoan om't ik net leuk fyn om te rommeljen mei skerming, de lingte yn it proses te feroarjen, ensfh. Ja, miskien bin ik beoardiele, mar ik sil de koade moatte skriuwe - wêrom twinge josels om iets te dwaan dat jo net leuk fine.
Summary: Wy kieze de opslachopsje yn 'e foarm fan keatlingen "koptekst mei lingte - gegevens fan fariabele lingte" fanwegen effisjinsje en maklike ymplemintaasje.
Bitfjilden brûke om it sukses fan skriuwoperaasjes te kontrolearjen
Ik wit no net mear wêr't ik it idee krige, mar it sjocht der sa út:
Foar elke yngong jouwe wy ferskate bits ta om flaggen op te slaan.
As wy sein earder, nei wiskjen alle bits fol mei 1s, en wy kinne feroarje 1 oan 0, mar net oarsom. Dus foar "de flagge is net ynsteld" brûke wy 1, foar "de flagge is ynsteld" brûke wy 0.
Hjir is hoe't it pleatsen fan in record mei fariabele lingte yn flash der útsjen kin:
- Stel de flagge "lingte opname is begûn";
- Record de lingte;
- Stel de flagge "data opname is begûn" yn;
- Wy registrearje de gegevens;
- Stel de flagge "opname einige" yn.
Dêrneist sille wy hawwe in "flater barde" flagge, foar in totaal fan 4 bit flaggen.
Yn dit gefal hawwe wy twa stabile steaten "1111" - opname is net begon en "1000" - opname wie suksesfol; yn it gefal fan in ûnferwachte ûnderbrekking fan it opnameproses, krije wy tuskensteaten, dy't wy dan kinne ûntdekke en ferwurkje.
De oanpak is nijsgjirrich, mar it beskermet allinich tsjin hommelse stroomûnderbrekken en ferlykbere flaters, wat, fansels, wichtich is, mar dit is fier fan de ienige (of sels de wichtichste) reden foar mooglike mislearrings.
Summary: Litte wy fierder gean op syk nei in goede oplossing.
Checksums
Checksums meitsje it ek mooglik om der wis fan te wêzen (mei ridlike kâns) dat wy krekt lêze wat skreaun wurde moast. En, yn tsjinstelling ta de hjirboppe besprutsen bitfjilden, wurkje se altyd.
As wy de list mei potinsjele boarnen fan problemen beskôgje dy't wy hjirboppe besprutsen, dan kin de kontrôlesum in flater werkenne, nettsjinsteande syn oarsprong (útsein, miskien, foar kweade aliens - se kinne de kontrôlesum ek fermeitsje).
Dus as ús doel is om te kontrolearjen dat de gegevens yntakt binne, binne kontrôlesummen in geweldich idee.
De kar fan it algoritme foar it berekkenjen fan 'e kontrôlesum hat gjin fragen oproppen - CRC. Oan 'e iene kant meitsje wiskundige eigenskippen it mooglik om bepaalde soarten flaters 100% te fangen; oan 'e oare kant, op willekeurige gegevens toant dit algoritme normaal de kâns op botsingen net folle grutter dan de teoretyske limyt  . It is miskien net it fluchste algoritme, en it is ek net altyd it minimum yn termen fan it oantal botsingen, mar it hat in heul wichtige kwaliteit: yn 'e testen dy't ik tsjinkaam, wiene der gjin patroanen wêryn't it dúdlik mislearre. Stabiliteit is de wichtichste kwaliteit yn dit gefal.
. It is miskien net it fluchste algoritme, en it is ek net altyd it minimum yn termen fan it oantal botsingen, mar it hat in heul wichtige kwaliteit: yn 'e testen dy't ik tsjinkaam, wiene der gjin patroanen wêryn't it dúdlik mislearre. Stabiliteit is de wichtichste kwaliteit yn dit gefal.
Foarbyld fan volumetryske stúdzje: , (keppelings nei narod.ru, sorry).
De taak om in kontrôlesum te selektearjen is lykwols net kompleet; CRC is in hiele famylje fan kontrôlesummen. Jo moatte beslute oer de lingte, en dan kieze in polynoom.
Kieze fan 'e kontrôlesumlange is net sa ienfâldich in fraach as it liket op it earste each.
Lit my yllustrearje:
Lit ús de kâns hawwe fan in flater yn elke byte  en in ideale kontrôlesum, lit ús it gemiddelde oantal flaters per miljoen records berekkenje:
en in ideale kontrôlesum, lit ús it gemiddelde oantal flaters per miljoen records berekkenje:
Data, byte
Checksum, byte
Net ûntdutsen flaters
Falske flaterdeteksjes
Totaal falske positives
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
It liket derop dat alles ienfâldich is - ôfhinklik fan 'e lingte fan' e gegevens dy't wurde beskerme, kies de lingte fan 'e kontrôlesum mei in minimum fan ferkearde positives - en de trúk is yn 'e tas.
Der ûntstiet lykwols in probleem mei koarte kontrôlesummen: hoewol se goed binne yn it ûntdekken fan inkele bitflaters, kinne se mei in frij hege kâns folslein willekeurige gegevens as korrekt akseptearje. Der stie al in artikel oer Habré dy't beskreau .
Dêrom, om in willekeurige kontrôlesum oerienkomst hast ûnmooglik te meitsjen, moatte jo kontrôlesummen brûke dy't 32 bits of langer binne. (foar lingten grutter dan 64 bits wurde kryptografyske hashfunksjes typysk brûkt).
Nettsjinsteande it feit dat ik earder skreau dat wy mei alle middels romte moatte besparje, sille wy noch in 32-bit kontrôlesum brûke (16 bits binne net genôch, de kâns op in botsing is mear as 0.01%; en 24 bits, lykas se sizze, binne noch hjir noch dêr).
Hjir kin in beswier opkomme: hawwe wy by it kiezen fan kompresje elke byte bewarre om no 4 bytes tagelyk te jaan? Soe it net better wêze om gjin kontrôlesum net te komprimearjen of ta te foegjen? Fansels net, gjin kompresje betsjut net, dat wy net nedich yntegriteit kontrôle.
By it kiezen fan in polynoom sille wy it tsjil net opnij útfine, mar de no populêre CRC-32C nimme.
Dizze koade detektearret 6-bit flaters op pakketten oant 22 bytes (miskien it meast foarkommende gefal foar ús), 4-bit flaters op pakketten oant 655 bytes (ek in gewoan gefal foar ús), 2 of in ûneven oantal bitflaters op pakketten fan elke ridlike lingte.
As immen is ynteressearre yn de details
oer CRC.
op - miskien de liedende CRC-spesjalist op 'e planeet.
В is , dat jout wat better parameters foar de pakket lingtematen dy't relevant foar ús, mar ik net beskôgje it ferskil wichtich, en ik wie befoege genôch te kiezen oanpaste koade ynstee fan de standert en goed ûndersocht.
Ek, om't ús gegevens komprimearre binne, ûntstiet de fraach: moatte wy de kontrôlesum fan komprimearre of net-komprimeare gegevens berekkenje?
Arguminten foar it berekkenjen fan de kontrôlesum fan net-komprimearre gegevens:
- Wy moatte úteinlik de feiligens fan gegevensopslach kontrolearje - dus kontrolearje wy it direkt (tagelyk wurde mooglike flaters yn 'e ymplemintaasje fan kompresje / dekompresje, skea feroarsake troch brutsen ûnthâld, ensfh.);
- De deflate algoritme yn zlib hat in frij folwoeksen ymplemintaasje en soe net falle mei "krûm" ynfiergegevens; boppedat is it faaks yn steat om selsstannich flaters yn 'e ynfierstream te ûntdekken, wêrtroch't de algemiene kâns om in flater net te ûntdekken te ferminderjen (in test útfierd mei it omkearjen fan ien bit yn in koarte record, zlib ûntdekte in flater yn sawat in tredde fan 'e gefallen).
Arguminten tsjin it berekkenjen fan de kontrôlesum fan net-komprimearre gegevens:
- CRC is "op maat" spesifyk foar de pear bit flaters dy't karakteristyk foar flash ûnthâld (in bytsje flater yn in komprimearre stream kin feroarsaakje in massale feroaring yn de útfier stream, dêr't, suver teoretysk, kinne wy "fange" in botsing);
- Ik hâld net echt fan it idee om potinsjeel brutsen gegevens troch te jaan oan de dekomprimerer, hoe't er reagearje sil.
Yn dit projekt haw ik besletten om ôf te wijken fan 'e algemien akseptearre praktyk fan it bewarjen fan in kontrôlesum fan net-komprimeare gegevens.
Summary: Wy brûke CRC-32C, wy berekkenje de kontrôlesum fan 'e gegevens yn' e foarm wêryn't se skreaun binne om te flitsen (nei kompresje).
Redundânsje
It brûken fan oerstallige kodearring elimineert, fansels, gjin gegevensferlies, lykwols kin it signifikant (faak troch in protte oarders fan grutte) de kâns op ûnherstelbere gegevensferlies ferminderje.
Wy kinne ferskate soarten oerstalligens brûke om flaters te korrigearjen.
Hamming-koades kinne inkele bitflaters korrigearje, Reed-Solomon-karakterkoades, meardere kopyen fan gegevens kombineare mei kontrôlesummen, of kodearrings lykas RAID-6 kinne helpe om gegevens te herstellen, sels yn it gefal fan massive korrupsje.
Yn it earstoan wie ik ynsette foar it wiidferspraat gebrûk fan flaterbestindige kodearring, mar doe realisearre ik dat wy earst in idee moatte hawwe fan hokker flaters wy ússels wolle beskermje, en dan kodearring kieze.
Wy hawwe earder sein dat flaters sa gau mooglik oppakt wurde moatte. Op hokker punten kinne wy tsjinkomme flaters?
- Unfoltôge opname (om ien of oare reden op it momint fan opnimmen wie de macht útskeakele, de Raspberry beferzen, ...)
Och, yn it gefal fan sa'n flater bliuwt alles oer ûnjildige records te negearjen en de gegevens ferlern te beskôgjen; - Skriuwflaters (om ien of oare reden wie wat skreaun yn it flashûnthâld net wat skreaun wie)
Wy kinne fuortendaliks detect sokke flaters as wy dogge in test lêzen fuortendaliks nei opname; - ferfoarming fan gegevens yn it ûnthâld tidens opslach;
- Lêsflaters
Om it te korrigearjen, as de kontrôlesum net oerienkomt, is it genôch om it lêzen ferskate kearen te werheljen.
Dat is, allinich flaters fan it tredde type (spontane korrupsje fan gegevens by opslach) kinne net korrizjearre wurde sûnder flaterbestindige kodearring. It liket derop dat sokke flaters noch heul ûnwierskynlik binne.
Summary: it waard besletten om oerstallige kodearring te ferlitten, mar as de operaasje de flater fan dit beslút toant, gean dan werom nei it beskôgjen fan it probleem (mei al opboude statistiken oer mislearrings, wêrtroch't jo it optimale type kodearring kinne kieze).
Прочее
Fansels lit it formaat fan it artikel ús net elk stikje yn it formaat rjochtfeardigje (en myn krêft is al oprûn), dus ik gean koart oer guon punten dy't net earder oanrekke binne.
- Der waard besletten om alle siden "lykweardich" te meitsjen
Dat is, d'r sille gjin spesjale siden mei metadata, aparte diskusjes, ensfh.
Dit soarget foar sels slijtage op 'e siden, gjin inkeld punt fan mislearring, en ik fyn it gewoan leuk; - It is ymperatyf om ferzje fan it formaat te leverjen.
In opmaak sûnder in ferzjenûmer yn 'e koptekst is kwea!
It is genôch om in fjild mei in bepaald Magic Number (hântekening) ta te foegjen oan 'e sidekop, dy't de ferzje fan it brûkte formaat oanjout (Ik tink net dat d'r yn 'e praktyk sels in tsiental fan sille wêze); - Brûk in koptekst fan fariabele lingte foar records (wêrfan d'r in protte binne), besykje it yn 'e measte gefallen 1 byte lang te meitsjen;
- Om de lingte fan 'e koptekst en de lingte fan it ôfsnien diel fan' e komprimearre record te kodearjen, brûke binêre koades mei fariabele lingte.
In protte holpen Huffman koades. Yn mar in pear minuten wiene wy by steat om te selektearjen de fereaske fariabele lingte koades.
Beskriuwing fan gegevens opslach formaat
Byte oarder
Fjilden grutter dan ien byte wurde opslein yn big-endian opmaak (netwurk byte folchoarder), dat is, 0x1234 wurdt skreaun as 0x12, 0x34.
Paginaasje
Alle flash ûnthâld is ferdield yn siden fan gelikense grutte.
De standert sidegrutte is 32Kb, mar net mear as 1/4 fan 'e totale grutte fan' e ûnthâldchip (foar in 4MB-chip wurde 128 siden krigen).
Elke side bewarret gegevens ûnôfhinklik fan 'e oaren (dat is, gegevens op ien side ferwize gjin gegevens op in oare side).
Alle siden binne nûmere yn natuerlike folchoarder (yn oprinnende folchoarder fan adressen), begjinnend mei nûmer 0 (side nul begjint by adres 0, de earste side begjint by 32Kb, de twadde side begjint by 64Kb, ensfh.)
It ûnthâld chip wurdt brûkt as in cyclic buffer (ring buffer), dat is, earst skriuwen giet nei side nûmer 0, dan nûmer 1, ..., as wy folje de lêste side, in nije syklus begjint en opname giet troch fan side nul .
Binnen de side

Oan it begjin fan 'e side wurdt in 4-byte sidekoptekst opslein, dan in koptekstkontrôlesum (CRC-32C), dan wurde records opslein yn it "header, data, checksum"-formaat.
De sidetitel (smoarch grien yn it diagram) bestiet út:
- twa-byte Magic Number fjild (ek in teken fan de opmaak ferzje)
foar de aktuele ferzje fan it formaat wurdt it berekkene as0xed00 ⊕ номер страницы; - twa-byte teller "Side ferzje" (ûnthâld herskriuwe syklus number).
Ynstjoerings op 'e side wurde opslein yn komprimearre foarm (it deflate-algoritme wurdt brûkt). Alle records op ien side wurde komprimearre yn ien tried (in mienskiplik wurdboek wurdt brûkt), en op elke nije side begjint kompresje op 'e nij. Dat is, om elk record te dekomprimearjen, binne alle eardere records fan dizze side (en allinich dizze) fereaske.
Elts rekord wurdt komprimearre mei de Z_SYNC_FLUSH flagge, en oan 'e ein fan' e komprimearre stream sil wêze 4 bytes 0x00, 0x00, 0xff, 0xff, mooglik foarôfgien troch ien of twa mear nul bytes.
Wy ferwiderje dizze sekwinsje (4, 5 of 6 bytes lang) by it skriuwen nei flash ûnthâld.
De recordkoptekst is 1, 2 of 3 bytes opslaan:
- ien bit (T) oanjout it type record: 0 - kontekst, 1 - log;
- in fjild mei fariabele lingte (S) fan 1 oant 7 bits, definiearret de lingte fan 'e koptekst en de "sturt" dy't moatte wurde tafoege oan it rekôr foar dekompresje;
- rekord lingte (L).
S wearde tabel:
S
Header lingte, bytes
Ferwiderje op skriuwen, byte
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Ik besocht te yllustrearjen, ik wit net hoe dúdlik it bliek:
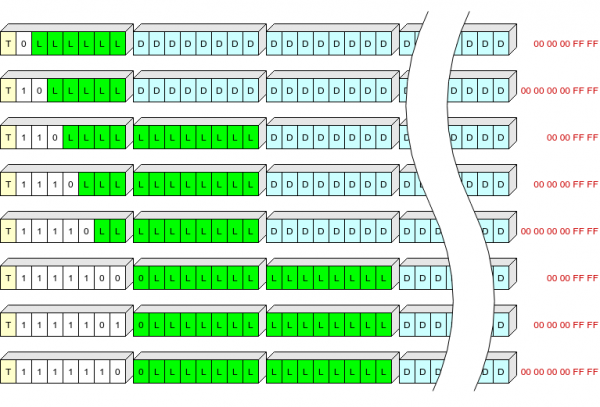
Giel jout hjir it T-fjild oan, wyt it S-fjild, grien L (de lingte fan 'e komprimearre gegevens yn bytes), blau de komprimearre gegevens, read de lêste bytes fan 'e komprimearre gegevens dy't net skreaun binne nei flashgeheugen.
Sa kinne wy rekordkoppen fan 'e meast foarkommende lingte (oant 63+5 bytes yn komprimearre foarm) yn ien byte skriuwe.
Nei elke rekord wurdt in CRC-32C-kontrôlesum opslein, wêryn de omkearde wearde fan 'e foarige kontrôlesum wurdt brûkt as de begjinwearde (init).
CRC hat de eigenskip fan "duration", de folgjende formule wurket (plus of minus bit inversion yn it proses):  .
.
Dat is, yn feite, wy berekkenje de CRC fan alle foarige bytes fan kopteksten en gegevens op dizze side.
Direkt nei de kontrôlesum is de koptekst fan it folgjende record.
De koptekst is sa ûntwurpen dat syn earste byte altyd oars is fan 0x00 en 0xff (as wy ynstee fan de earste byte fan de koptekst 0xff tsjinkomme, dan betsjut dit dat dit in net brûkt gebiet is; 0x00 sinjalearret in flater).
Foarbyld Algoritmen
Lêzen út Flash Memory
Elke lêzing komt mei in kontrôlesum.
As de kontrôlesum net oerienkomt, wurdt it lêzen ferskate kearen werhelle yn 'e hoop om de juste gegevens te lêzen.
(dat makket sin, Linux Slaat gjin lêzingen fan NOR Flash yn 'e cache, ferifiearre)
Skriuw nei flash ûnthâld
Wy registrearje de gegevens.
Litte wy se lêze.
As de lêzen gegevens net oerienkomme mei de skreaune gegevens, wy folje it gebiet mei nullen en sinjalearje in flater.
It tarieden fan in nij microcircuit foar operaasje
Foar inisjalisaasje wurdt in koptekst mei ferzje 1 skreaun nei de earste (of leaver nul) side.
Dêrnei wurdt de earste kontekst nei dizze side skreaun (befettet de UUID fan 'e masine en standertynstellingen).
Dat is it, it flash-ûnthâld is klear foar gebrûk.
It laden fan de masine
By it laden wurde de earste 8 bytes fan elke side (koptekst + CRC) lêzen, siden mei in ûnbekend Magic Number of in ferkearde CRC wurde negearre.
Fan 'e "korrekte" siden wurde siden mei de maksimale ferzje selektearre, en dêr wurdt de side mei it heechste nûmer fan helle.
It earste rekord wurdt lêzen, de krektens fan 'e CRC en de oanwêzigens fan' e "kontekst" flagge wurde kontrolearre. As alles goed is, wurdt dizze side as aktueel beskôge. As net, rôlje wy werom nei de foarige oant wy in "live" side fine.
en op 'e fûn side lêze wy alle records, dejingen dy't wy brûke mei de "kontekst" flagge.
Bewarje it zlib-wurdboek (it sil nedich wêze om ta te foegjen oan dizze side).
Dat is it, de ynlaad is foltôge, de kontekst is restaurearre, jo kinne wurkje.
It tafoegjen fan in Journal Entry
Wy komprimearje it record mei it juste wurdboek, spesifisearje Z_SYNC_FLUSH Wy sjogge oft it komprimearre record past op de aktuele side.
As it net past (of der wiene CRC flaters op 'e side), begjinne in nije side (sjoch hjirûnder).
Wy skriuwe it rekord en CRC op. As der in flater optreedt, begjin dan in nije side.
Nije side
Wy selektearje in fergese side mei it minimale oantal (wy beskôgje in fergese side as in side mei in ferkearde kontrôlesum yn 'e koptekst of mei in ferzje dy't minder is as de hjoeddeiske). As d'r gjin sokke siden binne, selektearje dan de side mei it minimale oantal fan dyjingen dy't in ferzje hawwe dy't gelyk is oan de hjoeddeiske.
Wy wiskje de selektearre side. Wy kontrolearje de ynhâld mei 0xff. As der wat mis is, nim dan de folgjende fergese side, ensfh.
Wy skriuwe in koptekst op 'e wiske side, de earste yngong is de hjoeddeistige tastân fan' e kontekst, de folgjende is de ûnskreaune log-yngong (as d'r ien is).
Opmaak tapasberens
Yn myn miening die bliken dat it in goed formaat is foar it bewarjen fan mear of minder kompresjearbere ynformaasjestreamen (plain text, JSON, MessagePack, CBOR, mooglik protobuf) yn NOR Flash.
Fansels is it formaat "op maat" foar SLC NOR Flash.
It moat net brûkt wurde mei hege BER media lykas NAND of MLC NOR (is sa'n ûnthâld sels te keap te keap? Ik haw it allinnich sjoen yn wurken oer korreksjekoades).
Boppedat moat it net brûkt wurde mei apparaten dy't har eigen FTL hawwe: USB flash, SD, MicroSD, ensfh (foar sa'n ûnthâld haw ik in opmaak makke mei in sidegrutte fan 512 bytes, in hantekening oan it begjin fan elke side en unike rekordnûmers - soms wie it mooglik om alle gegevens werom te heljen fan in "glitched" flash-drive troch ienfâldige opienfolgjende lêzing).
Ofhinklik fan 'e taken kin it formaat brûkt wurde sûnder feroaringen op flash-skiven fan 128Kbit (16Kb) nei 1Gbit (128MB). As jo wolle, kinne jo it brûke op gruttere chips, mar jo moatte wierskynlik de sidegrutte oanpasse (Mar hjir ûntstiet de fraach fan ekonomyske helberens al; de priis foar NOR Flash mei grutte folume is net bemoedigend).
As immen it formaat ynteressant fynt en it yn in iepen projekt wol brûke, skriuw dan, ik sil besykje de tiid te finen, de koade te poetsen en it op github te pleatsen.
konklúzje
Sa't jo sjen kinne, úteinlik die it formaat ienfâldich te wêzen en sels saai.
It is lestich om de evolúsje fan myn eachpunt yn in artikel te reflektearjen, mar leau my: ynearsten woe ik wat ferfine, ûnferwoastbere meitsje, dat sels in nukleêre eksploazje yn 'e buert kin oerlibje. Lykwols, de reden (hoopje ik) noch wûn en stadichoan ferskowen prioriteiten nei ienfâld en kompaktheid.
Kin it wêze dat ik ferkeard wie? Ja, wiswier. It kin wol bliken, bygelyks, dat wy kocht in partij fan lege kwaliteit microcircuits. Of om ien of oare reden sil de apparatuer net foldwaan oan betrouberensferwachtingen.
Haw ik in plan foar dit? Ik tink dat jo nei it lêzen fan it artikel gjin twifel hawwe dat d'r in plan is. En net iens allinnich.
Op in wat serieuze noat waard it formaat ûntwikkele sawol as in wurkopsje en as in "proefballon".
Op it stuit wurket alles op tafel goed, letterlik de oare deis wurdt de oplossing ynset (sawat) op hûnderten apparaten, lit ús sjen wat der bart yn "combat" operaasje (gelokkich, ik hoopje dat it formaat kinne jo betrouber ûntdekke mislearrings; sadat jo sammelje folsleine statistiken). Oer in pear moanne kinne konklúzjes lutsen wurde (en as jo pech hawwe, noch earder).
As, basearre op de resultaten fan gebrûk, serieuze problemen wurde ûntdutsen en ferbetteringen binne nedich, dan sil ik der grif oer skriuwe.
Literatuer
Ik woe net in lange saaie list meitsje fan brûkte wurken; elkenien hat ommers Google.
Hjir besleat ik in list mei befiningen te litten dy't my benammen ynteressant like, mar stadichoan migrearren se direkt yn 'e tekst fan it artikel, en ien item bleau op' e list:
- Utility fan de skriuwer zlib. Kin dúdlik werjaan de ynhâld fan deflate / zlib / gzip argiven. As jo te krijen hawwe mei de ynterne struktuer fan it deflate (of gzip) formaat, advisearje ik it tige oan.
Boarne: www.habr.com
