

Ynlieding
 "Jo moatte sa hurd rinne as jo kinne gewoan om op it plak te bliuwen,
"Jo moatte sa hurd rinne as jo kinne gewoan om op it plak te bliuwen,
en om earne te kommen, moatte jo op syn minst twa kear sa hurd rinne!”
(c) Alice yn Wûnderlân
In skoft lyn waard my frege om in lêzing te jaan analysts ús bedriuw op it ûnderwerp fan it ûntwerpen fan gegevensmodellen, om't wy lang op projekten sitte (soms foar ferskate jierren) ferlieze wy út it each op wat der om ús hinne bart yn 'e wrâld fan IT-technologyen. Yn ús bedriuw (it bart gewoan) brûke in protte projekten gjin NoSQL-databases (teminsten foar no), dat ik haw yn myn lêzing apart wat omtinken jûn oan har mei it foarbyld fan HBase en besocht de presintaasje fan it materiaal nei dy te oriïntearjen dy't se nea brûkt hawwe, hawwe wurke. Benammen yllustrearre ik guon fan 'e funksjes fan gegevensmodelûntwerp mei in foarbyld dat ik ferskate jierren lyn lies . By it analysearjen fan foarbylden fergelike ik ferskate opsjes foar it oplossen fan itselde probleem om de haadideeën better oan it publyk oer te bringen.
Koartlyn, "út neat te dwaan," stelde ik mysels de fraach (it lange maaie-wykein yn karantine is hjir foaral befoarderlik foar), hoefolle sille teoretyske berekkeningen oerienkomme mei de praktyk? Eins is dit hoe't it idee foar dit artikel is berne. In ûntwikkelder dy't al ferskate dagen mei NoSQL wurket kin der neat nijs fan leare (en kin dêrom de helte fan it artikel daliks oerslaan). Mar foar analystsFoar dyjingen dy't noch net nau gearwurke hawwe mei NoSQL, tink ik dat it nuttich wêze sil foar it krijen fan in basisbegryp fan 'e funksjes fan it ûntwerpen fan gegevensmodellen foar HBase.
Foarbyld analyze
Nei myn miening, foardat jo NoSQL-databases begjinne te brûken, moatte jo goed neitinke en de foar- en neidielen weagje. Faak kin it probleem nei alle gedachten wurde oplost mei tradisjonele relational DBMSs. Dêrom is it better om NoSQL net te brûken sûnder wichtige redenen. As jo nettsjinsteande besletten hawwe in NoSQL-database te brûken, dan moatte jo der rekken mei hâlde dat de ûntwerpbenaderingen hjir wat oars binne. Benammen guon fan harren kinne ûngewoan wêze foar dyjingen dy't earder allinich mei relasjonele DBMS's behannele hawwe (neffens myn observaasjes). Dat, yn 'e "relasjonele" wrâld, begjinne wy meastentiids mei it modellearjen fan it probleemdomein, en allinich dan, as it nedich is, it model denormalisearje. Yn NoSQL wy moatte fuortendaliks rekken hâlde mei de ferwachte senario's foar it wurkjen mei gegevens en ynearsten denormalisearje de gegevens. Derneist binne d'r in oantal oare ferskillen, dy't hjirûnder besprutsen wurde.
Lit ús beskôgje de folgjende "syntetyske" probleem, dêr't wy sille fierder te wurkjen:
It is needsaaklik om in opslachstruktuer te ûntwerpen foar de list mei freonen fan brûkers fan in abstrakt sosjale netwurk. Om te ferienfâldigjen, sille wy oannimme dat al ús ferbiningen binne rjochte (lykas op Instagram, net Linkedin). De struktuer moat jo effektyf meitsje kinne:
- Beantwurdzje de fraach oft brûker A brûker B lêst (lêspatroan)
- Taheakjen/ferwiderjen fan ferbiningen tastean yn gefal fan abonnemint/ôfskriuwing fan brûker A fan brûker B (sjabloan foar gegevensferoaring)
Fansels binne d'r in protte opsjes foar it oplossen fan it probleem. Yn in reguliere relaasjedatabank soene wy nei alle gedachten gewoan in tabel fan relaasjes meitsje (mooglik typearre as wy bygelyks in brûkersgroep moatte opslaan: famylje, wurk, ensfh., dy't dizze "freon") omfettet), en om te optimalisearjen tagong snelheid soe tafoegje yndeksen / partitioning. Meast wierskynlik soe de finale tafel der sa útsjen:
brûker_id
freon_id
Vasya
Petya
Vasya
Olya
hjirnei, foar dúdlikens en better begryp, Ik sil oanjaan nammen ynstee fan IDs
Yn it gefal fan HBase witte wy dat:
- effisjint sykjen dat net resultearret yn in folsleine tabel scan is mooglik eksklusyf troch kaai
- yn feite, dêrom is it skriuwen fan SQL-fragen nei sokke databases dy't in protte bekend binne in min idee; technysk kinne jo fansels in SQL-fraach stjoere mei Joins en oare logika nei HBase fan deselde Impala, mar hoe effektyf sil it wêze ...
Dêrom wurde wy twongen om de brûkers-ID as kaai te brûken. En myn earste gedachte oer it ûnderwerp "wêr en hoe kinne jo ID's fan freonen opslaan?" miskien in idee om se op te slaan yn kolommen. Dizze meast foar de hân lizzende en "naïve" opsje sil der sa útsjen (litte wy it neame Opsje 1 (standert)foar fierdere referinsje):
RowKey
Sprekkers
Vasya
1: pyk
2: oly
3: dasj
Petya
1: masj
2: wyz
Hjir komt elke rigel oerien mei ien netwurk brûker. De kolommen hawwe nammen: 1, 2, ... - neffens it oantal freonen, en de ID's fan freonen wurde opslein yn 'e kolommen. It is wichtich om te notearjen dat elke rige in oar oantal kolommen sil hawwe. Yn it foarbyld yn 'e boppesteande figuer hat ien rige trije kolommen (1, 2 en 3), en de twadde hat mar twa (1 en 2) - hjir hawwe wy sels twa HBase-eigenskippen brûkt dy't relationele databases net hawwe:
- de mooglikheid om de gearstalling fan kolommen dynamysk te feroarjen (in freon taheakje -> in kolom taheakje, in freon fuortsmite -> in kolom wiskje)
- ferskillende rigen kinne hawwe ferskillende kolom komposysjes
Litte wy ús struktuer kontrolearje foar neilibjen fan de easken fan 'e taak:
- Lêzen fan gegevens: om te begripen oft Vasya is ynskreaun op Olya, sille wy moatte subtractearje de hiele line troch de kaai RowKey = "Vasya" en sortearje troch de kolomwearden oant wy Olya yn har "treffe". Of iterearje troch de wearden fan alle kolommen, "net moetsje" Olya en werom it antwurd False;
- Gegevens bewurkje: in freon tafoegje: foar in soartgelikense taak moatte wy ek ôfrekkenje de hiele line mei de kaai RowKey = "Vasya" om it totale oantal fan syn freonen te tellen. Wy hawwe dit totale oantal freonen nedich om it nûmer fan 'e kolom te bepalen wêryn't wy de ID fan 'e nije freon moatte opskriuwe.
- Gegevens feroarje: in freon wiskje:
- Need te subtract de hiele line troch de kaai RowKey = "Vasya" en sortearje troch de kolommen om dejinge te finen wêryn de te wiskjen freon is opnommen;
- Folgjende, nei it wiskjen fan in freon, moatte wy alle gegevens yn ien kolom "ferpleatse" om gjin "gaten" yn har nûmering te krijen.
Litte wy no evaluearje hoe produktyf dizze algoritmen, dy't wy moatte ymplementearje oan 'e kant fan' e "betingsten tapassing", sille wêze, mei . Litte wy de grutte fan ús hypotetysk sosjale netwurk oantsjutte as n. Dan is it maksimum oantal freonen dat ien brûker kin hawwe (n-1). Wy kinne dit (-1) fierder negearje foar ús doelen, om't it yn it ramt fan it brûken fan O-symboalen ûnbelangryk is.
- Lêzen fan gegevens: it is nedich om de hiele line ôf te lûken en troch al syn kolommen yn 'e limyt te iterearjen. Dit betsjut dat de boppeste skatting fan kosten sawat O(n) sil wêze
- Gegevens bewurkje: in freon tafoegje: om it oantal freonen te bepalen, moatte jo troch alle kolommen fan 'e rige iterearje, en dan in nije kolom ynfoegje => O(n)
- Gegevens feroarje: in freon wiskje:
- Fergelykber mei tafoegjen - jo moatte troch alle kolommen yn 'e limyt gean => O(n)
- Nei it fuortheljen fan de kolommen moatte wy se "ferpleatse". As jo dizze "head-on" ymplementearje, dan sille jo yn 'e limyt oant (n-1) operaasjes nedich wêze. Mar hjir en fierder yn it praktyske diel sille wy in oare oanpak brûke, dy't in "pseudo-shift" sil ymplementearje foar in fêst oantal operaasjes - dat is, dêr sil konstante tiid oan bestege wurde, nettsjinsteande n. Dizze konstante tiid (O(2) om krekt te wêzen) kin ferwaarleazge wurde yn ferliking mei O(n). De oanpak wurdt yllustrearre yn 'e ôfbylding hjirûnder: wy kopiearje gewoan de gegevens fan 'e "lêste" kolom nei dejinge wêrfan wy gegevens wiskje wolle, en wiskje dan de lêste kolom:

Yn totaal krigen wy yn alle senario's in asymptotyske berekkeningskompleksiteit fan O(n).
Jo hawwe nei alle gedachten al opfallen dat wy hast altyd moatte lêze de hiele rige út de databank, en yn twa gefallen fan trije, gewoan te gean troch alle kolommen en berekkenje it totale oantal freonen. Dêrom, as in besykjen om te optimalisearjen, kinne jo in kolom "telling" tafoegje, dy't it totale oantal freonen fan elke netwurkbrûker opslacht. Yn dit gefal, wy kinne net lêze de hiele rige te berekkenjen it totale oantal freonen, mar lêze mar ien "count" kolom. It wichtichste is net te ferjitten om "telle" te aktualisearjen by it manipulearjen fan gegevens. Dat. wy wurde ferbettere Opsje 2 (telling):
RowKey
Sprekkers
Vasya
1: pyk
2: oly
3: dasj
oant: 3
Petya
1: masj
2: wyz
oant: 2
Yn ferliking mei de earste opsje:
- Lêzen fan gegevens: om in antwurd te krijen op 'e fraach "Lês Vasya Olya?" neat is feroare => O(n)
- Gegevens bewurkje: in freon tafoegje: Wy hawwe it ynfoegjen fan in nije freon ferienfâldige, om't wy no de heule rigel net hoege te lêzen en oer syn kolommen te iterearjen, mar kinne allinich de wearde krije fan 'e kolom "telling", ensfh. bepale fuortendaliks it kolomnûmer om in nije freon yn te foegjen. Dit liedt ta in reduksje fan berekkeningskompleksiteit nei O(1)
- Gegevens feroarje: in freon wiskje: By it wiskjen fan in freon kinne wy dizze kolom ek brûke om it oantal I / O-operaasjes te ferminderjen as de gegevens ien sel nei lofts "feroarje". Mar de needsaak om troch de kolommen te iterearjen om dejinge te finen dy't wiske moat, bliuwt noch, dus => O(n)
- Oan 'e oare kant, no by it bywurkjen fan gegevens moatte wy elke kear de kolom "telling" bywurkje, mar dit duorret konstante tiid, wat kin wurde ferwaarleazge yn it ramt fan O-symboalen
Yn 't algemien liket opsje 2 in bytsje optimaler, mar it is mear as "evolúsje ynstee fan revolúsje." Om in "revolúsje" te meitsjen sille wy nedich wêze Opsje 3 (kol).
Litte wy alles "op syn kop" keare: wy sille tawize kolom namme brûkers ID! Wat yn de kolom sels skreaun wurdt, is foar ús net mear wichtich, lit it it nûmer 1 wêze (yn 't algemien kinne dêr nuttige dingen opslein wurde, bygelyks de groep "famylje/freonen/etc."). Dizze oanpak kin de ûnfoarbereide "leek" ferrasse dy't gjin eardere ûnderfining hat mei it wurkjen mei NoSQL-databases, mar it is krekt dizze oanpak wêrmei jo it potensjeel fan HBase yn dizze taak folle effektiver kinne brûke:
RowKey
Sprekkers
Vasya
Pyt: 1
olya: 1
dasj: 1
Petya
Masha: 1
Waske: 1
Hjir krije wy ferskate foardielen tagelyk. Om se te begripen, litte wy de nije struktuer analysearje en de berekkeningskompleksiteit skatte:
- Lêzen fan gegevens: om de fraach te beantwurdzjen oft Vasya is ynskreaun op Olya, is it genôch om ien kolom "Olya" te lêzen: as it d'r is, dan is it antwurd Wier, as net - False => O(1)
- Gegevens bewurkje: in freon tafoegje: In freon tafoegje: gewoan in nije kolom taheakje "Friend ID" => O(1)
- Gegevens feroarje: in freon wiskje: fuortsmite gewoan de Friend ID kolom => O(1)
Sa't jo sjen kinne, is in wichtich foardiel fan dit opslachmodel dat wy yn alle senario's dy't wy nedich binne, operearje mei mar ien kolom, it foarkommen fan it lêzen fan 'e hiele rige út' e databank en boppedat, enumerearje alle kolommen fan dizze rige. Dêr koene we ophâlde, mar...
Jo kinne fernuverje en in bytsje fierder gean op it paad fan it optimalisearjen fan prestaasjes en it ferminderjen fan I / O-operaasjes by tagong ta de databank. Wat as wy opslein de folsleine relaasje ynformaasje direkt yn de rige kaai sels? Dat is, meitsje de kaai gearstalde lykas userID.friendID? Yn dit gefal hoege wy de kolommen fan 'e rigel net iens te lêzen (Opsje 4 (rige)):
RowKey
Sprekkers
Vasya.Petya
Pyt: 1
Vasya.Olya
olya: 1
Vasya.Dasha
dasj: 1
Petya.Masha
Masha: 1
Petya.Vasya
Waske: 1
Fansels sil de beoardieling fan alle senario's foar gegevensmanipulaasje yn sa'n struktuer, lykas yn 'e foarige ferzje, O (1) wêze. It ferskil mei opsje 3 sil allinich wêze yn 'e effisjinsje fan I / O-operaasjes yn' e database.
No, de lêste "bôge". It is maklik om te sjen dat yn opsje 4 de rigekaai in fariabele lingte sil hawwe, dy't mooglik de prestaasjes beynfloedzje (hjir betinke wy dat HBase gegevens bewarret as in set fan bytes en rigen yn tabellen wurde sorteare op kaai). Plus wy hawwe in separator dy't miskien moatte wurde behannele yn guon senario's. Om dizze ynfloed te eliminearjen, kinne jo hashes brûke fan userID en friendID, en om't beide hashes in konstante lingte sille hawwe, kinne jo se gewoan keppelje, sûnder in separator. Dan sille de gegevens yn 'e tabel der sa útsjen (Opsje 5 (hash)):
RowKey
Sprekkers
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Pyt: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
olya: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
dasj: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Masha: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Waske: 1
Fansels sil de algoritmyske kompleksiteit fan wurkjen mei sa'n struktuer yn 'e senario's dy't wy beskôgje itselde wêze as dy fan opsje 4 - dat is O(1).
Litte wy yn totaal al ús rûzingen fan berekkeningskompleksiteit gearfetsje yn ien tabel:
In freon tafoegje
Kontrolearje op in freon
It fuortsmiten fan in freon
Opsje 1 (standert)
O (n)
O (n)
O (n)
Opsje 2 (tel)
O (1)
O (n)
O (n)
Opsje 3 (kolom)
O (1)
O (1)
O (1)
Opsje 4 (rige)
O (1)
O (1)
O (1)
Opsje 5 (hash)
O (1)
O (1)
O (1)
Sa't jo sjen kinne, lykje opsjes 3-5 de meast foarkar te wêzen en teoretysk soargje foar de útfiering fan alle needsaaklike senario's foar gegevensmanipulaasje yn konstante tiid. Yn 'e betingsten fan ús taak is d'r gjin eksplisite eask om in list te krijen fan alle freonen fan' e brûker, mar yn echte projektaktiviteiten soe it goed wêze foar ús, as goede analisten, om "antisipearje" dat sa'n taak kin ûntstean en "spried in strie." Dêrom binne myn sympatyen oan 'e kant fan opsje 3. Mar it is heul wierskynlik dat yn in echte projekt dit fersyk al op oare middels koe wurde oplost, dus sûnder in algemiene fisy fan it heule probleem is it better net te meitsjen definitive konklúzjes.
Tarieding fan it eksperimint
Ik wol de boppesteande teoretyske arguminten yn 'e praktyk testje - dit wie it doel fan it idee dat oer it lange wykein ûntstie. Om dit te dwaan, is it nedich om de wurksnelheid fan ús "betingsten applikaasje" te evaluearjen yn alle beskreaune senario's foar it brûken fan de databank, en ek de ferheging yn dizze tiid mei tanimmende grutte fan it sosjale netwurk (n). De doelparameter dy't ús ynteresseart en dy't wy sille mjitte tidens it eksperimint is de tiid bestege troch de "betingsten applikaasje" om ien "saaklike operaasje" út te fieren. Mei "saaklike transaksje" bedoele wy ien fan 'e folgjende:
- Ien nije freon tafoegje
- Kontrolearje oft brûker A in freon is fan brûker B
- Ien freon fuortsmite
Sa, rekken hâldend mei de easken sketste yn de earste ferklearring, it ferifikaasje senario ferskynt as folget:
- Data opname. Willekeurich generearje in earste netwurk fan grutte n. Om tichter by de "echte wrâld" te kommen, is it oantal freonen dat elke brûker hat ek in willekeurige fariabele. Meitsje de tiid wêryn't ús "betingsten applikaasje" alle oanmakke gegevens skriuwt nei HBase. Diel dan de resultearjende tiid troch it totale oantal tafoege freonen - dit is hoe't wy de gemiddelde tiid krije foar ien "saaklike operaasje"
- Lêzen fan gegevens. Meitsje foar elke brûker in list mei "persoanlikheden" wêrfoar jo in antwurd moatte krije oft de brûker op har ynskreaun is of net. De lingte fan 'e list = sawat it oantal freonen fan' e brûker, en foar de helte fan 'e kontrolearre freonen moat it antwurd "Ja" wêze, en foar de oare helte - "Nee". De kontrôle wurdt útfierd yn sa'n folchoarder dat de antwurden "Ja" en "Nee" ôfwikselje (dat is, yn elk twadde gefal moatte wy troch alle kolommen fan 'e line gean foar opsjes 1 en 2). De totale screeningtiid wurdt dan dield troch it oantal testen freonen om de gemiddelde screeningtiid per ûnderwerp te krijen.
- It wiskjen fan gegevens. Fuortsmite alle freonen fan de brûker. Boppedat is de wiskje folchoarder willekeurich (dat is, wy "shuffle" de orizjinele list brûkt foar it opnimmen fan de gegevens). De totale kontrôletiid wurdt dan dield troch it oantal freonen fuorthelle om de gemiddelde tiid per kontrôle te krijen.
De senario's moatte wurde útfierd foar elk fan 'e 5 gegevensmodel-opsjes en foar ferskate grutte fan it sosjale netwurk om te sjen hoe't de tiid feroaret as it groeit. Binnen ien n moatte ferbinings yn it netwurk en de list fan brûkers te kontrolearjen, fansels, wêze itselde foar alle 5 opsjes.
Foar in better begryp, hjirûnder is in foarbyld fan oanmakke gegevens foar n = 5. De skreaune "generator" produsearret trije ID wurdboeken as útfier:
- de earste is foar ynfoegje
- de twadde is foar kontrôle
- tredde - foar wiskjen
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Sa't jo sjen kinne, binne alle ID's grutter dan 10 yn it wurdboek foar kontrôle krekt dyjingen dy't grif it antwurd False sille jaan. It ynfoegje, kontrolearje en wiskjen fan "freonen" wurdt útfierd krekt yn 'e folchoarder spesifisearre yn it wurdboek.
It eksperimint waard útfierd op in laptop dy't oan it rinnen wie Windows 10, wêrby't HBase yn ien Docker-kontener rûn, en Python mei Jupyter Notebook yn in oare. Docker krige 2 CPU-kearnen en 2 GB RAM tawiisd. Alle logika, ynklusyf de simulaasje fan 'e "dummy-applikaasje" en it ramt foar it generearjen fan testgegevens en it mjitten fan tiid, waarden skreaun yn Python. De bibleteek , om hashes (MD5) te berekkenjen foar opsje 5 - hashlib
Mei it rekkenjen fan de komputerkrêft fan in bepaalde laptop, waard in lansearring foar n = 10, 30, ... eksperiminteel selektearre. 170 - doe't de totale operaasje tiid fan de folsleine test syklus (alle senario foar alle opsjes foar alle n) wie noch mear of minder ridlik en fit tidens ien tee partij (gemiddeld 15 minuten).
Hjir is it nedich om in opmerking te meitsjen dat wy yn dit eksperimint net primêr absolute prestaasjesifers evaluearje. Sels in relative ferliking fan ferskate twa opsjes kin net folslein korrekt wêze. No binne wy ynteressearre yn 'e aard fan' e feroaring yn 'e tiid ôfhinklik fan n, om't de boppesteande konfiguraasje fan' e "teststand" yn 'e rekken is, is it heul lestich om tiidskattingen "ferwiderje" te krijen fan' e ynfloed fan willekeurige en oare faktoaren ( en sa'n taak waard net ynsteld).
Eksperimint resultaat
De earste test is hoe't de tiid bestege oan it ynfoljen fan 'e freonenlist feroaret. It resultaat is yn 'e grafyk hjirûnder.
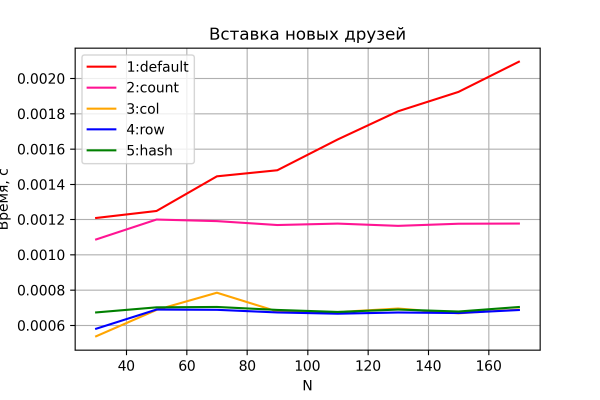
Opsjes 3-5, lykas ferwachte, litte in hast konstante "saaklike transaksje" tiid sjen, dy't net ôfhinklik is fan 'e groei fan' e netwurkgrutte en in net te ûnderskieden ferskil yn prestaasjes.
Opsje 2 toant ek konstante, mar wat slimmer prestaasjes, hast krekt 2 kear relatyf oan opsjes 3-5. En dit kin net oars as bliid wêze, om't it korrelearret mei teory - yn dizze ferzje is it oantal I/O-operaasjes nei/fan HBase krekt 2 kear grutter. Dit kin tsjinje as yndirekt bewiis dat ús testbank, yn prinsipe, in goede krektens leveret.
Opsje 1 blykt ek, lykas ferwachte, de stadichste te wêzen en toant in lineêre ferheging fan 'e tiid bestege oan it tafoegjen fan inoar oan' e grutte fan it netwurk.
Litte wy no sjen nei de resultaten fan 'e twadde test.
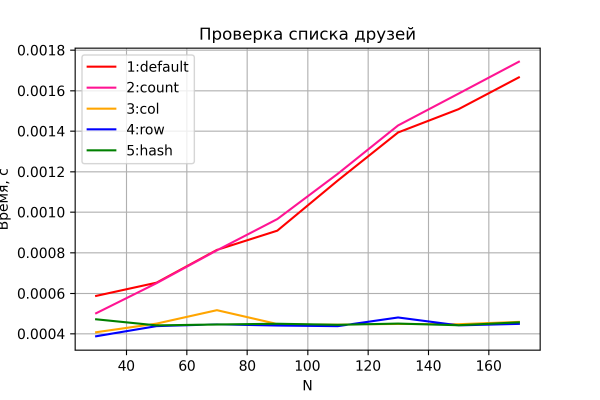
Opsjes 3-5 wer gedrage as ferwachte - konstante tiid, ûnôfhinklik fan de grutte fan it netwurk. Opsjes 1 en 2 demonstrearje in lineêre ferheging yn 'e tiid as de netwurkgrutte nimt ta en ferlykbere prestaasjes. Boppedat blykt opsje 2 wat stadiger te wêzen - blykber troch de needsaak om de ekstra kolom "telling" te korrizearjen en te ferwurkjen, dy't mear opfallend wurdt as n groeit. Mar ik sil my noch wol ôfhâlde fan konklúzjes te lûken, om't de krektens fan dizze ferliking relatyf leech is. Dêrneist binne dizze ferhâldingen (hokker opsje, 1 of 2, flugger) feroare fan run nei run (wylst it aard fan 'e ôfhinklikens behâlde en "hals en nekke gean").
No, de lêste grafyk is it resultaat fan testen foar ferwidering.
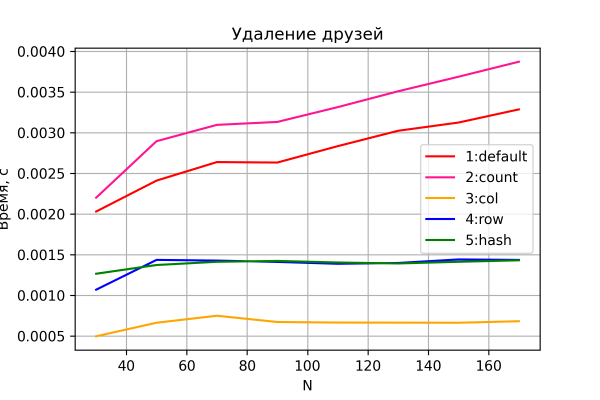
Nochris, gjin ferrassingen hjir. Opsjes 3-5 fiere ferwidering yn konstante tiid.
Boppedat, nijsgjirrich, opsjes 4 en 5, yn tsjinstelling ta de foarige senario, toant merkber wat slimmer prestaasje as opsje 3. Blykber, de rige wiskje operaasje is djoerder as de kolom wiskjen operaasje, dat is oer it algemien logysk.
Opsjes 1 en 2, lykas ferwachte, litte in lineêre ferheging yn 'e tiid sjen. Tagelyk is opsje 2 konsekwint stadiger as opsje 1 - troch de ekstra I/O-operaasje om de telkolom te "behâlden".
Algemiene konklúzjes fan it eksperimint:
- Opsjes 3-5 bewize gruttere effisjinsje as se profitearje fan HBase; Boppedat, harren prestaasjes ferskille relatyf oan elkoar troch in konstante en is net ôfhinklik fan de grutte fan it netwurk.
- It ferskil tusken opsjes 4 en 5 waard net opnommen. Mar dit betsjut net dat opsje 5 net brûkt wurde moat. It is wierskynlik dat it brûkte eksperimintele senario, rekken hâldend mei de prestaasjeskenmerken fan 'e testbank, it net liet ûntdekke.
- De aard fan 'e ferheging fan' e tiid dy't nedich is om "saaklike operaasjes" út te fieren mei gegevens befêstige algemien de earder krigen teoretyske berekkeningen foar alle opsjes.
Epilogue
Dizze rûge eksperiminten moatte net as absolute wierheid nommen wurde. Der binne in protte faktoaren dy't net yn rekken brocht binne en de resultaten ferfoarme hawwe (dizze fluktuaasjes binne foaral sichtber yn 'e grafyken foar lytse netwurkgruttes). Bygelyks, de snelheid fan thrift, dy't brûkt wurdt troch happybase, it folume en de ymplemintaasjemetoade fan 'e logika dy't ik yn Python skreau (ik kin net beweare dat de koade optimaal skreaun is of effektyf gebrûk makke hat fan alle komponinten), mooglik HBase-cachingfunksjes, en eftergrûnaktiviteit. Windows 10 Op myn laptop, ensfh. Oer it algemien kin konkludearre wurde dat alle teoretyske oannames eksperiminteel bewiisd jildich binne. Of teminsten, it wie net mooglik om se te wjerlizzen mei sa'n frontale oanfal.
Ta beslút, oanbefellings foar elkenien dy't krekt begjint te ûntwerpen gegevensmodellen yn HBase: abstrakt út eardere ûnderfining wurkjen mei relaasje databases en ûnthâlde de "geboaden":
- By it ûntwerpen geane wy út fan 'e taak en patroanen fan gegevensmanipulaasje, en net fan it domeinmodel
- Effisjinte tagong (sûnder folsleine tabel scan) - allinne troch kaai
- Denormalisaasje
- Ferskillende rigen kinne ferskate kolommen befetsje
- Dynamyske komposysje fan sprekkers
Boarne: www.habr.com
