


It haaddoel fan Patroni is om hege beskikberens foar PostgreSQL te leverjen. Mar Patroni is gewoan in sjabloan, net in klear ark (wat yn 't algemien is wat de dokumintaasje seit). Op it earste each, nei't jo Patroni yn it testlabor hawwe konfigureare, kinne jo sjen wat in prachtich ark it is en hoe maklik it ús besykjen om it kluster te ferneatigjen omgiet. Yn de praktyk bart yn in produksjeomjouwing lykwols net altyd alles sa moai en elegant as yn in testlab.

Ik sil dy wat oer mysels fertelle. Ik begon as systeembehearder. Hat wurke by webûntwikkeling. Ik wurkje sûnt 2014 by Data Egret. It bedriuw is dwaande mei advys op it mêd fan Postgres. En wy tsjinje Postgres spesifyk, en wy wurkje alle dagen mei Postgres, dus wy hawwe in ferskaat oan operasjonele saakkundigens.
En oan 'e ein fan 2018 begûnen wy Patroni stadichoan te brûken. En wat spesifike ûnderfining is sammele. Wy hawwe it op ien of oare manier diagnostearre, ôfstimd en kamen ta ús bêste praktiken. En yn dit rapport sil ik it oer har hawwe.
Neist Postgres fyn ik it moai LinuxIk hâld derfan om dermei te knutseljen en te ferkennen, en ik hâld fan it bouwen fan kernels. Ik hâld fan firtualisaasje, konteners, Docker en Kubernetes. Ik bin ynteressearre yn dit alles, om't myn âlde beheargewoanten my ynhelje. Ik hâld fan knutseljen mei monitoring. Ik hâld ek fan Postgres-relatearre dingen dy't relatearre binne oan admin, lykas replikaasje en reservekopyen. En yn myn frije tiid skriuw ik yn Go. Ik bin gjin software-yngenieur, ik skriuw gewoan foar mysels yn Go. En ik genietsje derfan.

- Ik tink dat in protte fan jimme witte dat Postgres gjin HA (hege beskikberens) út it fak hat. Om HA te krijen, moatte jo wat ynsette, konfigurearje, ynsette en it krije.
- D'r binne ferskate ark en Patroni is ien fan har, dy't HA frij cool en heul goed oplost. Mar troch it alles yn in testlaboratoarium te setten en it út te fieren, kinne wy sjogge dat it allegear wurket, wy kinne guon problemen reprodusearje, sjen hoe't Patroni har tsjinnet. En wy sille sjen dat it allegear goed wurket.
- Mar yn 'e praktyk troffen wy ferskate problemen. En ik sil prate oer dizze problemen.
- Ik sil jo fertelle hoe't wy it diagnostearre hawwe, wat wy oanpast hawwe - oft it ús holp of net holp.

- Ik sil jo net fertelle hoe't jo Patroni ynstallearje, om't jo it op it ynternet kinne googleje, jo kinne nei de konfiguraasjebestannen sjen om te begripen hoe't it allegear begjint en hoe't it is ynsteld. Jo kinne de diagrammen en arsjitektueren begripe troch ynformaasje oer it te finen op it ynternet.
- Ik sil net prate oer de ûnderfiningen fan oaren. Ik sil allinich prate oer de problemen dy't wy tsjinkamen.
- En ik sil net prate oer problemen dy't bûten Patroni en PostgreSQL binne. As der bygelyks problemen binne yn ferbân mei lykwicht as ús kluster ynstoarte, sil ik der net oer prate.

En in lytse disclaimer foardat wy begjinne mei ús rapport.
Al dizze problemen dy't wy tsjinkamen, wy hienen se yn 'e earste 6-7-8 moannen fan operaasje. Yn 'e rin fan' e tiid kamen wy ta ús eigen ynterne best practices. En ús problemen ferdwûnen. Dêrom is it rapport sa'n seis moanne lyn yntsjinne, doe't it my allegear fris yn 'e holle siet en ik it allegear perfekt yn 'e gaten hie.
By it opstellen fan it rapport haw ik al âlde postmortales ophelle en nei de logs sjoen. En guon fan 'e details binne miskien fergetten, of guon fan' e details binne miskien net folslein ûndersocht tidens de analyze fan 'e problemen, dus op guon punten kin it lykje dat de problemen net folslein beskôge binne, of d'r is in soarte fan gebrek oan ynformaasje. En dêrom freegje ik jo om my te ferjaan foar dit momint.

Wat is Patroni?
- Dit is in sjabloan foar it bouwen fan HA. Dat stiet yn de dokumintaasje. En út myn eachpunt is dit in heul korrekte opheldering. Patroni is gjin sulveren kûgel dy't al jo problemen sil oplosse, d.w.s. jo moatte in poging dwaan om it te begjinnen te wurkjen en nuttich te wêzen.
- Dit is in agent tsjinst dat is ynstallearre op elke tsjinst mei in databank, en dat is in soarte fan init systeem foar jo Postgres. It begjint Postgres, stopt it, start it opnij, feroaret de konfiguraasje en feroaret de topology fan jo kluster.
- Dêrom, om de steat fan it kluster op te slaan, syn hjoeddeistige fertsjintwurdiging, hoe't it derút sjocht, is in soarte fan opslach nedich. En út dit eachpunt, Patroni naam it paad fan it bewarjen fan steat yn in ekstern systeem. It is in ferspraat konfiguraasje opslach systeem. Dit kin Etcd, Consul, ZooKeeper, of kubernetes Etcd wêze, dus ien fan dizze opsjes.
- En ien fan 'e funksjes fan Patroni is dat jo de autofileover út' e doaze krije, pas nei it ynstellen fan it. As wy Repmgr nimme foar ferliking, is de filer dêr opnommen. Mei Repmgr krije wy oerstap, mar as wy autofileover wolle, dan moat it fierder konfigureare wurde. Patroni hat al in autofileover út 'e doaze.
- En der binne noch folle oare dingen. Bygelyks, it behâld fan konfiguraasjes, it tafoegjen fan nije replika's, backups, ensfh Mar dit is bûten it berik fan it rapport, ik sil der net oer prate.

En in lyts resultaat is dat de haadtaak fan Patroni is om in autofileover goed en betrouber te dwaan, sadat ús kluster operasjoneel bliuwt en de applikaasje gjin feroaringen yn 'e klustertopology merkt.

Mar as wy Patroni begjinne te brûken, wurdt ús systeem in bytsje komplekser. As wy earder Postgres hiene, dan krije wy by it brûken fan Patroni Patroni sels, wy krije DCS, wêr't de steat wurdt opslein. En it moat allegear op ien of oare manier wurkje. Dêrom, wat kin brekke?
Mei brekke:
- Postgres kin brekke. It kin in master wêze as in replika, ien fan har kin mislearje.
- De Patroni sels kin brekke.
- De DCS, dêr't de steat wurdt opslein, kin brekke.
- En it netwurk kin brekke.
Ik sil al dizze punten yn it rapport beskôgje.

Ik sil saken beskôgje as se komplekser wurde, net út it eachpunt dat in saak in protte komponinten omfettet. En út it eachpunt fan subjektive gefoelens, dizze saak wie kompleks foar my, it wie dreech te disassemble ... en oarsom, guon saak wie licht en maklik te disassemble.

En it earste gefal is it ienfâldichste. Dit is it gefal as wy in databankkluster namen en ús DCS-opslach op itselde kluster ynset. Dit is de meast foarkommende flater. Dit is in flater yn it bouwen fan arsjitektueren, dus it kombinearjen fan ferskate komponinten op ien plak.
Dat, in filer barde, litte wy útfine wat der bard is.

En hjir binne wy ynteressearre yn wannear't de filer barde. Dat is, wy binne ynteressearre yn dit momint yn 'e tiid doe't de steat fan' e kluster feroare.
Mar de filer is net altyd instantaneous, dat wol sizze dat it net nimme in bepaalde ienheid fan tiid, it kin slepe op. It kin lang duorje.
Dêrom hat it in begjintiid en in eintiid, d.w.s. it is in trochgeand barren. En wy ferdiele alle eveneminten yn trije yntervallen: wy hawwe tiid foar de filer, tidens de filer en nei de filer. Dat is, wy beskôgje alle eveneminten yn dizze tiidline.

En earst fan alle, doe't in filer barde, wy sykje nei de reden, wat barde, wat feroarsake wat late ta de filer.
As wy nei de logs sjogge, binne dit de klassike Patroni-logs. Yn har fertelt hy ús dat de tsjinner in master wurden is, en de rol fan 'e master is oergien nei dit knooppunt. It is hjir markearre.

Folgjende, wy moatte begripe wêrom't de filer barde, dat wol sizze wat barrens barde dy't feroarsake de master rol te ferpleatsen fan de iene knooppunt nei in oare. En yn dit gefal is alles ienfâldich. Wy hawwe in flater ynteraksje mei it opslachsysteem. De master realisearre dat hy net mei DCS wurkje koe, d.w.s. der wie wat probleem mei ynteraksje. En hy seit dat er gjin master mear wêze kin en nimt ôf. Dizze line "degradearre sels" seit krekt dat.

As wy sjogge nei de foarfallen dy't foarôfgien de filer, kinne wy sjen dêr de hiel redenen dy't tsjinne as in probleem foar de fuortsetting fan 'e master syn wurk.
As wy nei de Patroni-logs sjogge, sille wy sjen dat wy in protte flaters en timeouts hawwe, d.w.s. de Patroni-agint kin net mei DCS wurkje. Yn dit gefal is dit de Consul-agint, wêrmei kommunikaasje plakfynt op haven 8500.
It probleem hjir is dat Patroni en de databank op deselde host rinne. Consul-tsjinners rûnen ek op deselde host. Troch in lading op 'e tsjinner te meitsjen, hawwe wy problemen makke foar servers Konsul. Se koenen net normaal kommunisearje.

Nei ferrin fan tiid, doe't de lading sakke, koe ús Patroni wer mei aginten kommunisearje. It normale wurk is wer begûn. En deselde Pgdb-2-tsjinner waard wer de master. Dat is, der wie in lytse flip, wêrmei't it knooppunt syn machten as master opjoech, en dêrnei wer oernaam, dat wol, alles kaam werom sa't it wie.

En dit kin wurde beskôge as in falsk posityf, of it kin wurde beskôge dat Patroni die alles goed. Dat is, hy besefte dat hy de steat fan 'e kluster net behâlde koe en syn autoriteit fuorthelle.
En hjir is it probleem ûntstien troch it feit dat de Consul-tsjinners lizze op deselde apparatuer as de databases. Dêrtroch is elke lading: of it no de lading is op skiven as prosessoren, it hat ek ynfloed op ynteraksje mei it Consul-kluster.

En wy besletten dat dit net tegearre libje soe, wy hawwe in apart kluster tawiisd foar konsul. En Patroni wurke al mei in aparte Konsul, d.w.s. der wie in apart Postgres-kluster, in apart Konsul-kluster. Dit is in basisynstruksje oer hoe't jo al dizze dingen skiede en hâlde kinne, sadat se net tegearre libje.
As alternatyf kinne jo de parameters ttl, loop_wait, retry_timeout oanpasse, d.w.s. besykje dizze koarte termyn loadpieken te oerlibjen troch dizze parameters te ferheegjen. Mar dit is net de meast geskikte opsje, om't dizze lading lang duorje kin. En wy sille gewoan oer dizze grinzen fan dizze parameters gean. En dat kin net echt helpe.
It earste probleem, lykas jo begripe, is ienfâldich. Wy namen de DCS en sette it tegearre mei de basis, en wy krigen in probleem.

It twadde probleem is gelyk oan it earste. It is fergelykber yn dat wy wer problemen hawwe mei ynteraksje mei it DCS-systeem.

As wy nei de logs sjogge, sille wy sjen dat wy wer in kommunikaasjeflater hawwe. En Patroni seit dat ik kin net ynteraksje mei DCS, dus de hjoeddeiske master giet yn replika modus.
De âlde master wurdt in replika, hjir wurket Patroni sa't it moat. It rint pg_rewind om it transaksjelogboek werom te draaien en dan te ferbinen mei de nije master, en dan de nije master yn te heljen. Hjir wurket Patroni sa't it moat.

Hjir moatte wy fine it plak dat foarôfgien de filer, dat wol sizze dy flaters dy't feroarsake de filer te foarkommen. En yn dit ferbân binne Patroni-logs frij handich om mei te wurkjen. Hy skriuwt deselde berjochten mei bepaalde yntervallen. En as wy begjinne te scrollen troch dizze logs fluch, dan sille sjen út de logs dat de logs binne feroare, dat betsjut dat guon problemen binne begûn. Wy komme gau werom nei dit plak en sjogge wat der bart.
En yn in normale situaasje sjogge de logs der sa út. De eigner fan it slot wurdt kontrolearre. En as de eigner, bygelyks, feroaret, dan kinne guon eveneminten foarkomme wêrop Patroni reagearje moat. Mar yn dit gefal binne wy goed. Wy sykje it plak dêr't de flaters begûnen.

En nei it rôljen nei it punt wêr't flaters begon te ferskinen, sjogge wy dat wy in autofileover hawwe. En om't ús flaters relatearre wiene oan ynteraksje mei DCS en yn ús gefal wy Consul brûkten, sjogge wy ek nei de Consul-logs om te sjen wat der barde.
Nei't wy de tiid fan 'e filer en de tiid yn' e konsul-logboeken sawat fergelike hawwe, sjogge wy dat ús buorlju yn 'e konsul-kluster begon te twifeljen oan it bestean fan oare leden fan 'e konsul-kluster.

En as jo sjogge nei de logs fan oare Consul-aginten, kinne jo ek sjen dat der in soarte fan netwurk ynstoarten bart. En alle leden fan it Konsul-kluster twivelje oan elkoars bestean. En dit wie de ympuls foar de filer.
As jo sjogge nei wat der bard foar dizze flaters, kinne jo sjen dat der allerhanne flaters, Bygelyks, deadline, RPC foel, d.w.s. der is dúdlik wat probleem yn de ynteraksje fan Consul kluster leden mei elkoar.

It ienfâldichste antwurd is om it netwurk te reparearjen. Mar steand op it poadium, it is maklik foar my om dit te sizzen. Mar omstannichheden binne sa dat de klant it net altyd kin betelje om it netwurk te reparearjen. Hy kin yn 'e DC wenje en kin net de mooglikheid hawwe om it netwurk te reparearjen of de apparatuer te beynfloedzjen. En dêrom binne guon oare opsjes nedich.

Der binne opsjes:
- De ienfâldichste opsje, dy't neffens my skreaun is, sels yn 'e dokumintaasje, is om Consul-kontrôles út te skeakeljen, d.w.s. gewoan in lege array trochjaan. En wy fertelle de Consul-agint om gjin kontrôles te brûken. Troch dizze kontrôles kinne wy negearje dizze netwurk stoarmen en net inisjearje in filer.
- In oare opsje is om raft_multiplier dûbel te kontrolearjen. Dit is in parameter fan de Consul-tsjinner sels. Standert is it ynsteld op 5. Dizze wearde wurdt oanrikkemandearre neffens de dokumintaasje foar staging omjouwings. Yn essinsje hat dit ynfloed op de frekwinsje fan berjochtútwikseling tusken leden fan it Consul-netwurk. Yn essinsje hat dizze parameter ynfloed op de snelheid fan offisjele kommunikaasje tusken leden fan it Consul-kluster. En foar produksje is it al oan te rieden om it te ferminderjen sadat knopen faker berjochten útwikselje.
- In oare opsje dy't wy begon te brûken wie om de prioriteit fan Consul-prosessen te ferheegjen ûnder oare prosessen foar de prosesplanner fan it bestjoeringssysteem. D'r is sa'n parameter "moai", it bepaalt gewoan de prioriteit fan prosessen dy't rekken holden wurdt troch de OS-planner by planning. Wy ek redusearre de moaie wearde foar Consul aginten, i.e. ferhege de prioriteit sadat it bestjoeringssysteem Consul-prosessen mear tiid jout om te wurkjen en har koade út te fieren. Yn ús gefal hat dit ús probleem oplost.
- In oare opsje is om Consul net te brûken. Ik haw in freon dy't in grutte foarstanner fan Etcd. En hy en ik rûzje regelmjittich wat better is Etcd of Consul. Mar yn termen fan wat better is, hy en ik binne it oer it algemien iens dat Consul in agent hat dy't op elke knooppunt mei in database moat rinne. Dat is, de ynteraksje fan Patroni mei it Consul-kluster komt troch dizze agint. En dizze agint wurdt in flessehals. As der wat mei de agint bart, dan kin Patroni net mear mei it Consul-kluster wurkje. En dit is in probleem. D'r is gjin agent yn it Etcd-plan. Patroni kin direkt wurkje mei in list fan Etcd tsjinners en al kommunisearje mei harren. Yn dit ferbân, as jo Etcd brûke yn jo bedriuw, dan sil Etcd wierskynlik in bettere kar wêze dan Consul. Mar mei ús klanten binne wy altyd beheind troch wat de klant hat keazen en brûkt. En foar it grutste part, al ús kliïnten hawwe Consul.
- En it lêste punt is om de parameterwearden opnij te besjen. Wy kinne dizze parameters heger ferheegje yn 'e hope dat ús koarte termyn netwurkproblemen koart sille wêze en net binnen it berik fan dizze parameters falle. Op dizze manier kinne wy de agressiviteit fan Patroni ferminderje om in autofileover út te fieren as der netwurkproblemen ûntsteane.
Ik tink dat in protte dy't Patroni brûke binne bekend mei dit kommando.
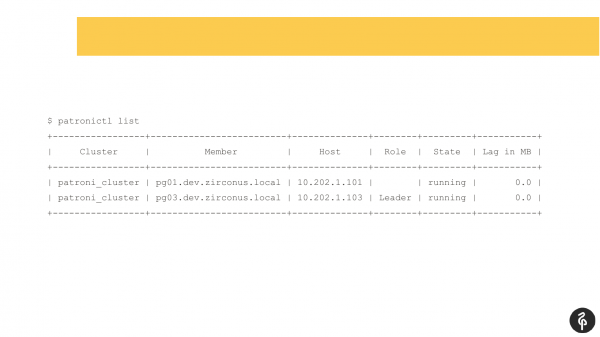
Dit kommando lit de aktuele tastân fan it kluster sjen. En op it earste each kin dizze foto normaal lykje. Wy hawwe in master, wy hawwe in replika, d'r is gjin replikaasjefertraging. Mar dizze foto is normaal oant wy witte dat dit kluster trije knopen moat hawwe, net twa.

Dêrtroch barde in autofileover. En nei dizze autofileover ferdwûn ús replika. Wy moatte útfine wêrom't se ferdwûn en har werom bringe, har weromsette. En wy geane wer nei de logs en sjoch nei wêrom't de autofileover barde.

Yn dit gefal waard de twadde replika de master. Alles is goed hjir.

En wy moatte sjen nei de replika dy't fallen is en net yn 'e kluster is. Wy iepenje de Patroni-logs en sjogge dat wy in probleem hiene by it pg_rewind-poadium by it ferbinen mei it kluster. Om te ferbinen mei it kluster, moatte jo it transaksjelogboek weromdraaie, it fereaske transaksjelog fan 'e master oanfreegje en it brûke om de master yn te heljen.
Yn dit gefal hawwe wy gjin transaksjelog en kin de replika net begjinne. Dêrtroch stopje wy Postgres mei in flater. En dêrom is it net yn 'e kluster.

Wy moatte begripe wêrom't it net yn 'e kluster is en wêrom't d'r gjin logs wiene. Wy geane nei de nije master en sjogge wat it yn har logs hat. It docht bliken dat doe't pg_rewind dien wie, in kontrôle barde. En guon fan 'e âlde transaksje logs waarden gewoan omneamd. Doe't de âlde master besocht te ferbinen mei de nije master en freegje dizze logs, se wiene al omneamd, se gewoan net bestean.

Ik fergelike tiidstempels doe't dizze barrens barde. En dêr is it ferskil letterlik 150 millisekonden, dus yn 369 millisekonden wie it kontrôlepunt foltôge, de WAL-segminten waarden omneamd. En letterlik op 517, 150 millisekonden letter, begon werom te spoelen op 'e âlde replika. Dat is, letterlik 150 millisekonden wie genôch foar ús om te foarkommen dat de replika ferbine en wurket.

Wat binne de opsjes?
Wy brûkten ynearsten replikaasje slots. Wy tochten it wie goed. Hoewol't yn 'e earste faze fan operaasje wy útskeakele de slots. It like ús dat as de slots sammele in protte WAL segminten, wy meie falle de master. Hy sil falle. Wy lije in skoft sûnder slots . En wy realisearre dat wy nedich slots , wy werom de slots .
Mar der is in probleem hjir dat doe't de master ferhuzet nei in replika, it wisket slots en, tegearre mei de slots, wiskje WAL segminten. En om dit probleem te eliminearjen, hawwe wy besletten om de parameter wal_keep_segments te ferheegjen. It is standert op 8 segminten. Wy hawwe it opbrocht nei 1 en seagen hoefolle frije romte wy hiene. En wy skonken 000 gigabytes oan wal_keep_segments. Dat is, by it wikseljen hawwe wy altyd in reserve fan 16 gigabyte oan transaksje logs op alle knopen.
En plus - dit is ek relevant foar ûnderhâldstaken op lange termyn. Litte wy sizze dat wy ien fan 'e replika's moatte bywurkje. En wy wolle it útsette. Wy moatte de software bywurkje, miskien it bestjoeringssysteem, wat oars. En as wy in replika útsette, wurdt it slot foar dy replika ek fuortsmiten. En as wy lytse wal_keep_segments brûke, dan as der in lange ôfwêzigens fan in replika is, sille de transaksjelogs ferlern gean. Wy sille ophelje in replika, it sil freegje dy transaksje logs dêr't it stoppe, mar se meie net op 'e master. En de replika sil ek net kinne ferbine. Dêrom hâlde wy in grutte foarried oan tydskriften.

Wy hawwe in produksjebasis. Dêr wurkje al projekten.
Der is in file bard. Wy gongen yn en seagen - alles is yn oarder, de replika's binne op it plak, d'r is gjin replikaasjefertraging. D'r binne ek gjin flaters yn 'e logs, alles is yn oarder.
It produktteam seit dat it liket dat der wat gegevens wêze moatte, mar wy sjogge it fan ien boarne, mar wy sjogge it net yn 'e databank. En wy moatte begripe wat der bard mei harren.

It is dúdlik dat pg_rewind se wiske hat. Wy realisearre dit daliks, mar gongen om te sjen wat der barde.

Yn 'e logboeken kinne wy altyd fine wannear't de filer barde, wa't de master waard, en wy kinne bepale wa't de âlde master wie en wannear't hy in replika woe wurde, d.w.s. wy hawwe dizze logs nedich om it folume fan transaksjelogs te finen dat wie ferlern.
Us âlde master is wer opstarten. En Patroni waard registrearre yn 'e autostart. Patroni lansearre. Hy begon doe Postgres. Mear krekter, foardat Postgres begon en foardat it in replika makke, lansearre Patroni it pg_rewind-proses. Dêrtroch wist hy guon fan 'e transaksjelogboeken, downloadde nije en ferbûn. Hjir die Patroni in geweldige baan, dat is, sa't it moat. Us kluster is restaurearre. Wy hiene 3 knopen, nei de filer wiene d'r 3 knopen - alles wie cool.

Wy hawwe wat gegevens ferlern. En wy moatte begripe hoefolle wy hawwe ferlern. Wy binne op syk nei krekt it momint dat wy hiene in rewind. Wy kinne dit fine út dizze sjoernaalposten. rewind begûn, die wat dêr en einige.

Wy moatte de posysje fine yn it transaksjelogboek wêr't de âlde master stoppe. Yn dit gefal is it dit merk. En wy moatte in twadde markearje, dus de ôfstân wêrmei't de âlde master ferskilt fan 'e nije.
Wy nimme de gewoane pg_wal_lsn_diff en fergelykje dizze twa tekens. En yn dit gefal krije wy 17 megabytes. Oft dit in protte of in bytsje is, beslút elkenien foar himsels. Want foar guon is 17 megabytes net folle, foar oaren is it in protte en net akseptabel. Hjir beslút elkenien foar himsels yndividueel yn oerienstimming mei de behoeften fan it bedriuw.

Mar wat hawwe wy sels útfûn?
As earste moatte wy sels beslute - hawwe wy altyd Patroni autostart nedich nei in systeem opnij starte? Faker komt it foar dat wy nei de âld master gean moatte, sjen hoe fier er gien is. Ynspektearje miskien de segminten fan it transaksjelogboek, sjoch wat der is. En begryp oft wy dizze gegevens kinne ferlieze of oft wy de âlde master yn standalone modus moatte útfiere om dizze gegevens op te heljen.
En pas nei dit moatte wy beslute oft wy dizze gegevens kinne ferwiderje of wy kinne it weromsette, dizze knooppunt ferbine as in replika oan ús kluster.
Derneist is d'r in parameter "maximum_lag_on_failover". Standert, as myn ûnthâld my goed tsjinnet, hat dizze parameter in wearde fan 1 megabyte.
Hoe wurket hy? As ús replika efter is mei 1 megabyte oan gegevens yn 'e replikaasjefertraging, dan nimt dizze replika net mei oan' e ferkiezings. En as der ynienen in filer foarkomt, sjocht Patroni nei hokker replika's efterbliuwe. As se efter in grut oantal transaksje logs binne, kinne se gjin master wurde. Dit is in heul goede feiligensfunksje dy't foarkomt dat jo in protte gegevens ferlieze.
Mar d'r is in probleem dat de replikaasjefertraging yn it Patroni- en DCS-kluster op in bepaald ynterval wurdt bywurke. Ik tink dat 30 sekonden de standert ttl-wearde is.
Dêrnjonken kin d'r in situaasje wêze wêr't de replikaasjefertraging foar replika's yn DCS itselde is, mar yn feite kin d'r in folslein oare efterstân wêze of d'r kin hielendal gjin lag wêze, dus dit ding is net realtime. En it reflektearret net altyd it echte byld. En it is net wurdich om der fancy logika op te meitsjen.
En it risiko fan ferlies bliuwt altyd. En yn it slimste gefal is der ien formule, en yn it gemiddelde gefal is der in oare formule. Dat is, as wy de ymplemintaasje fan Patroni planne en skatte hoefolle gegevens wy kinne ferlieze, moatte wy fertrouwe op dizze formules en sawat yntinke hoefolle gegevens wy kinne ferlieze.
En der is goed nijs. As de âlde master foarôf gien is, kin er troch guon eftergrûnprosessen troch gean. Dat is, d'r wie in soarte fan autovacuum, it skreau de gegevens en bewarre it yn it transaksjelogboek. En wy kinne dizze gegevens maklik negearje en ferlieze. Der is gjin probleem mei dit.

En dit is wat de logs lykje as maximum_lag_on_failover is ynsteld en in fileover optreedt, en jo moatte selektearje in nije master. De replika beoardielet himsels as net by steat om mei te dwaan oan de ferkiezings. En se wegeret mei te dwaan oan 'e race foar liederskip. En se wachtet op in nije master dy't selektearre wurdt, sadat se dan mei him ferbine kin. Dit is in ekstra maatregel tsjin gegevensferlies.

Hjir skreau ús produktteam dat har produkt problemen ûnderfynt by it wurkjen mei Postgres. Tagelyk kinne jo gjin tagong krije ta de master sels, om't it net tagonklik is fia SSH. En autofileover bart ek net.
Dizze host waard twongen ta in reboot. Troch de trochstart kaam der in autofileover, hoewol it ek mooglik wie om in hânmjittich autofileover te dwaan, sa't ik no begryp. En nei de herstart geane wy om te sjen wat wy hiene mei de hjoeddeiske master.
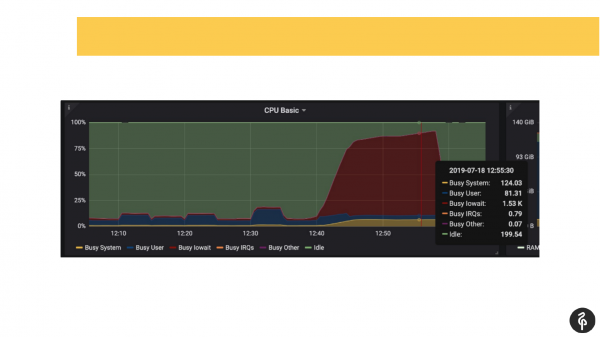
Tagelyk wisten wy fan tefoaren dat wy problemen hiene mei de skiven, d.w.s. wy wisten al fan tafersjoch wêr't te graven en wat te sykjen.

Wy kamen yn it postgres log en begûnen te sjen nei wat der barde. Wy seagen commits dy't ien, twa of trije sekonden duorre, wat hielendal net normaal is. Wy seagen dat ús autovacuum in heul lange en frjemde tiid duorre om op te starten. En wy seagen tydlike triemmen op 'e skiif. Dat is, dit binne allegear yndikatoaren fan problemen mei skiven.

Wy seagen yn it systeem dmesg (nukleêre berjochtlog). En wy seagen dat wy hiene problemen mei ien fan de skiven. De skiif subsysteem wie in software Raid. Wy seagen op /proc/mdstat en seagen dat wy ien skiif misten. Dat is, der is in Raid fan 8 skiven, wy misse ien. As jo de slide goed sjogge, kinne jo yn 'e útfier sjen dat wy dêr gjin sde hawwe. Us skiif, relatyf sjoen, foel út. Dit feroarsake skiifproblemen, en applikaasjes ûnderfûnen ek problemen by it wurkjen mei it Postgres-kluster.

En yn dit gefal soe Patroni ús op gjin inkelde manier helpe, om't Patroni net de taak hat om de steat fan 'e tsjinner te kontrolearjen, de steat fan' e skiif. En wy moatte sokke situaasjes kontrolearje mei eksterne tafersjoch. Wy hawwe operasjonele skyfmonitoring tafoege oan eksterne tafersjoch.
En d'r wie dizze gedachte - koe fekânsje- of watchdog-software ús helpe? Wy tochten dat it net wierskynlik wie dat hy ús yn dit gefal holpen hie, om't Patroni yn 'e problemen trochgie mei it DCS-kluster en seach gjin probleem. Dat is, út it eachpunt fan DCS en Patroni, alles wie goed mei it kluster, hoewol't yn feite der wiene problemen mei de skiif, der wiene problemen mei de beskikberens fan de databank.
Yn myn miening is dit ien fan 'e nuverste problemen dy't ik in heul lange tiid ûndersocht, in protte logboeken opnij lêzen, dermei tintele en it in klustersimulator neamde.

It probleem wie dat de âlde master net in normale replika wurde koe, d.w.s. Patroni lansearre it, Patroni liet sjen dat dizze knooppunt wie oanwêzich as in replika, mar tagelyk wie it net in normale replika. No sille jo sjen wêrom. Ik hold dit fan it analysearjen fan dat probleem.

En wêr begûn it allegear? It begûn, lykas yn it foarige probleem, mei schijfremmen. Wy hiene commits ien sekonde op in tiid, twa op in tiid.

D'r wiene ferbiningsbrekken, d.w.s. kliïnten waarden loskeppele.

Der wiene blokkades fan ferskillende earnst.

En sadwaande is it skiifsubsysteem net heul responsyf.

En it meast mysterieuze ding foar my is it direkte shutdown-fersyk dat oankaam. Postgres hat trije shutdown-modi:
- It is sierlik as wy wachtsje op alle kliïnten om de ferbining op har eigen te ferbrekken.
- D'r is fluch, as wy kliïnten twinge om de ferbining te ferbrekken, om't wy sille ôfslute.
- En daliks. Yn dit gefal fertelt direkt kliïnten net iens om ôf te sluten, it slút gewoan ôf sûnder warskôging. En it bestjoeringssysteem stjoert in RST-berjocht nei alle kliïnten (TCP-berjocht dat de ferbining is ûnderbrutsen en de kliïnt hat neat mear te fangen).
Wa stjoerde dit sinjaal? Eftergrûn Postgres-prosessen stjoere sokke sinjalen net nei elkoar, d.w.s. dit is in kill-9. Se stjoere dit net nei inoar, se reagearje hjir allinnich op, dus dit is in needherstart fan Postgres. Ik wit net wa't him stjoerd hat.
Ik seach nei it "lêste" kommando en ik seach ien persoan dy't ek by ús oanmelde by dizze tsjinner, mar ik wie ferlegen om in fraach te stellen. Miskien wie it kill -9. Ik soe kill -9 yn 'e logs sjen, om't ... Postgres seit dat it akseptearre kill -9, mar ik seach it net yn 'e logs.

As ik fierder seach, seach ik dat Patroni in lange tiid net yn it log skreau - 54 sekonden. En as jo de twa tiidstempels fergelykje, wiene d'r sawat 54 sekonden gjin berjochten.
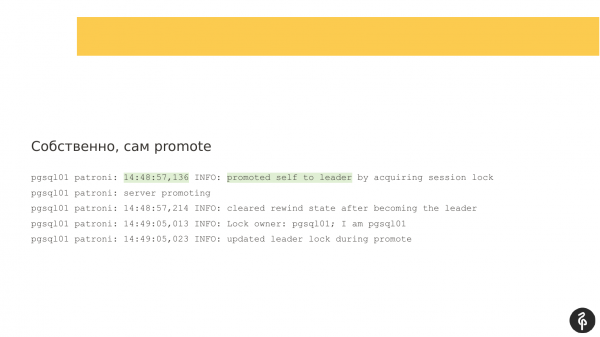
En yn dizze tiid barde in autofileover. Patroni wurke hjir wer geweldich. Us âlde master wie net beskikber, der barde der wat mei him. En de ferkiezing fan in nije master begûn. Alles slagge hjir goed. Us pgsql01 is ús nije lieder wurden.

Wy hawwe in replika dy't in master wurden is. En der is in twadde replika. En der wiene problemen mei de twadde opmerking. Se besocht te rekonfigurearjen. As ik it begryp, besocht se recovery.conf te feroarjen, Postgres opnij starte en ferbine mei de nije master. Se sms't elke 10 sekonden dat se besykje, mar se slagget net.

En tidens dizze besykjen komt der in sinjaal foar fuortendaliks ôfsluten by de âlde master. De master begjint opnij. En ek herstel stopt omdat de âlde master giet yn reboot. Dat is, de replika kin der net mei ferbine, om't it yn shutdown-modus is.

Op in stuit wurke it, mar replikaasje begon net.
De ienige hypoteze dy't ik haw is dat recovery.conf it adres fan 'e âlde master befette. En doe't der in nije master ferskynde, besocht de twadde replika noch te ferbinen mei de âlde master.
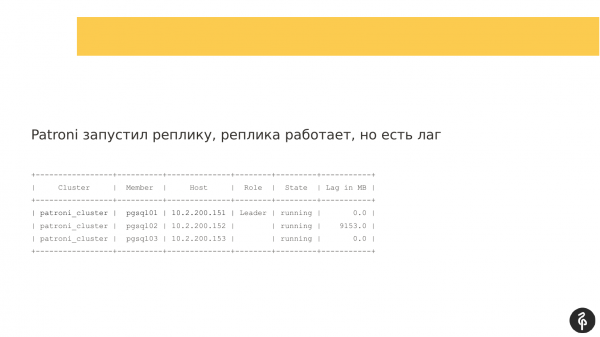
Doe't Patroni begon op 'e twadde replika, begon it knooppunt, mar koe net ferbine fia replikaasje. En der ûntstie in replikaasjefertraging, dy't der sa útseach. Dat is, alle trije knooppunten wiene yn plak, mar de twadde knoop wie efter.
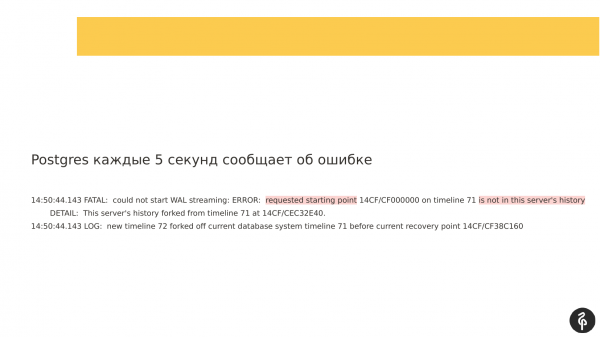
Tagelyk, as jo sjogge nei de logs dy't waarden skreaun, kinne jo sjen dat replikaasje koe net begjinne omdat de transaksje logs wiene oars. En de transaksje logs dy't de wizard biedt, dy't yn recovery.conf steane, binne gewoan net geskikt foar ús hjoeddeistige knooppunt.

En hjir haw ik in flater makke. Ik moast komme sjen wat der yn recovery.conf wie om myn hypoteze te testen dat wy ferbine mei de ferkearde master. Mar ik siet it doe krekt út en it foel net yn my op, of ik seach dat de replika efterbliuwt en opnij oanfolle wurde soe, d.w.s. ik ha it op ien of oare manier achteleas útwurke. Dit wie myn jamb.

Nei 30 minuten kaam de admin, d.w.s. ik haw Patroni opnij starte op 'e replika. Ik hie it al opjûn, ik tocht dat it wol wer opfolle wurde moast. En ik tocht, ik sil Patroni opnij starte, miskien komt der wat goeds út. Herstel begûn. En de basis sels iepene, it wie klear om ferbinings te akseptearjen.
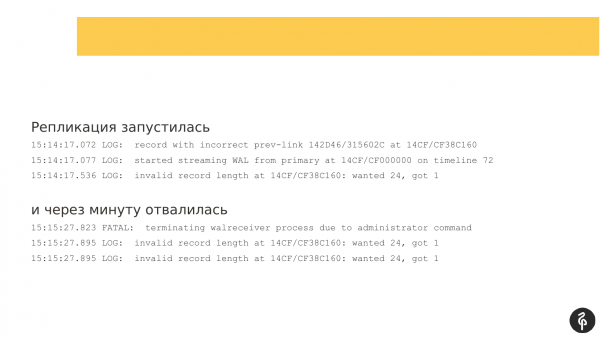
Replikaasje is begûn. Mar in minút letter stoarte it mei in flater dat transaksjelogboeken der net geskikt foar wiene.

Ik tocht dat ik opnij begjinne soe. Ik haw Patroni opnij starte, en ik haw Postgres net opnij starte, mar Patroni opnij starte yn 'e hope dat it de databank magysk starte.

Replikaasje begon opnij, mar de notysjes yn it transaksjelogboek wiene oars, se wiene net itselde as dy yn 'e foarige besykjen om te begjinnen. Replikaasje is wer stoppe. En it berjocht wie wat oars. En it wie net bysûnder ynformatyf foar my.

En dan komt it my op - wat as ik Postgres opnij starte, op dit stuit meitsje ik in kontrôlepunt op 'e hjoeddeistige master om it punt yn' e transaksjelog in bytsje foarút te ferpleatsen, sadat it herstel fan in oar momint begjint? Plus we hiene noch WAL reserves dêr.

Ik haw Patroni opnij starte, in pear kontrôlepunten makke op 'e master, in pear opnij starte punten op' e replika doe't it iepene. En it holp. Ik tocht lang en hurd oer wêrom't it holp en hoe't it wurke. En de replika begon. En replikaasje mislearre net mear.

Dit probleem is foar my ien fan 'e mysterieuzer, dêr't ik noch oer bin oer wat der eins barde.
Wat binne de konklúzjes hjir? Patroni kin wurkje lykas bedoeld en sûnder flaters. Mar tagelyk is dit gjin 100% garânsje dat alles goed is mei ús. De replika kin begjinne, mar it kin wêze yn in semy-wurkjende steat, en de applikaasje kin net wurkje mei sa'n replika, omdat der sil wêze âlde gegevens dêr.
En nei fileover moatte wy altyd kontrolearje dat alles goed is mei it kluster, d.w.s. wy hawwe it fereaske oantal replika's en d'r is gjin replikaasjelag.
En as wy dizze problemen beskôgje, sil ik oanbefellings formulearje. Ik besocht se te kombinearjen yn twa dia's. Wierskynlik koene alle ferhalen yn twa dia's kombinearre wurde en allinich ferteld wurde.

As jo Patroni brûke, moatte jo tafersjoch hawwe. Jo moatte altyd witte wannear't in autofileover barde, want as jo net witte dat jo in autofileover hawwe, binne jo net yn kontrôle oer it kluster. En dat is slim.
Nei elke filer moatte wy it kluster altyd mei de hân kontrolearje. Wy moatte derfoar soargje dat wy altyd in aktueel oantal replika's hawwe, d'r is gjin replikaasjefertraging, en d'r binne gjin flaters yn 'e logs yn ferbân mei streamende replikaasje, Patroni, of it DCS-systeem.
Automatisearring kin mei súkses wurkje, Patroni is in heul goed ark. It kin wurkje, mar it sil it kluster net nei de winske steat bringe. En as wy it net witte, dan krije wy problemen.
En Patroni is gjin sulveren kûgel. Wy moatte noch in begryp hawwe fan hoe't Postgres wurket, hoe't replikaasje wurket en hoe't Patroni wurket mei Postgres en hoe't kommunikaasje tusken knooppunten wurdt berikt. Dit is nedich om problemen mei jo hannen op te lossen.

Hoe benaderje ik it probleem fan diagnoaze? It barde sa dat wy wurkje mei ferskate kliïnten en gjinien hat in ELK-stapel, en wy moatte de logs begripe troch 6 konsoles en 2 ljeppers te iepenjen. Yn ien ljepper binne d'r Patroni-logs foar elke knooppunt, yn 'e oare ljepper binne d'r Consul-logs, of Postgres-logs as nedich. It is heul lestich om te diagnostearjen.
Hokker oanpak haw ik ûntwikkele? Earst sjoch ik altyd as de filer oankaam. En foar my is dit in soarte fan wetterskieding. Ik sjoch wat der barde foar de filer, tidens de filer en nei de filer. De fileover hat twa tekens: dit is de start- en eintiid.
Dêrnei sjoch ik yn 'e logs nei de barrens foar de filer, dy't de filer foarôfgien, d.w.s. ik sykje de redenen wêrom't de filer barde.
En dit jout in byld fan begryp wat der bard is en wat der yn 'e takomst dien wurde kin om foar te kommen dat sokke omstannichheden foarkomme (en dêrtroch komt der gjin fileover).
En wêr sjogge wy meastentiids? Ik sjoch:
- Earst nei de Patroni logs.
- Dêrnei sjoch ik nei de Postgres-logs of de DCS-logs, ôfhinklik fan wat fûn is yn 'e Patroni-logs.
- En de systeemlogboeken jouwe ek soms in begryp fan wat de filer feroarsake hat.

Hoe fiel ik my oer Patroni? Ik fiel my tige goed oer Patroni. Neffens my is dit it bêste dat der hjoed is. Ik wit in protte oare produkten. Dit binne Stolon, Repmgr, Pg_auto_failover, PAF. 4 ark. Ik haw se allegearre besocht. Ik mocht Patroni it meast.
As se my freegje: "Rebear ik Patroni oan?" Ik sil sizze ja, want ik hâld fan Patroni. En ik tink dat ik leard hoe't it koekje.
As jo ynteressearre binne om te sjen hokker oare problemen d'r binne mei Patroni, neist de problemen dy't ik útsprutsen, kinne jo altyd nei de side gean op GitHub. Der binne in protte ferskillende ferhalen en in protte nijsgjirrige problemen wurde dêr besprutsen. En as gefolch waarden guon bugs yntrodusearre en oplost, d.w.s. dit is in nijsgjirrich lêzen.
Der binne nijsgjirrige ferhalen oer minsken dy't harsels yn 'e foet sjitte. Hiel ynformatyf. Jo lêze en begripe dat jo dit net hoege te dwaan. Ik tikke mysels.
En ik soe graach sizze in grutte tank oan it bedriuw Zalando foar it ûntwikkeljen fan dit projekt, nammentlik Alexander Kukushkin en Alexey Klyukin. Alexey Klyukin is ien fan 'e co-auteurs hy wurket net mear by Zalando, mar dit binne twa minsken dy't begûn te wurkjen mei dit produkt.
En ik tink dat Patroni in heul cool ding is. Ik bin bliid dat se bestiet, it is nijsgjirrich om by har te wêzen. En in protte tank oan alle meiwurkers dy't patches skriuwe oan Patroni. Ik hoopje dat Patroni mei leeftyd folwoeksener, koeler en bekwamer wurdt. It is al effisjint, mar ik hoopje dat it noch better wurdt. Dus as jo fan plan binne om Patroni yn jo hûs te brûken, eangje dan net. Dit is in goede oplossing, it kin wurde ymplementearre en brûkt.
Da's alles. As jo fragen hawwe, freegje dan asjebleaft.

Jo fragen
Tank foar it ferslach! As jo der nei de filer noch hiel foarsichtich sjen moatte, wêrom hawwe wy dan in automatyske filer nedich?
Want it is in nij ding. Wy wurkje noch mar in jier mei har. Better om it feilich te spyljen. Wy wolle ynkomme en sjen dat alles echt wurke sa't it moat. Dit is it nivo fan mistrouwen foar folwoeksenen - it is better om dûbel te kontrolearjen en te sjen.
Wy kamen bygelyks fannemoarn binnen en seagen, krekt?
Net yn 'e moarn, wy meastal komme út oer autofileover hast fuortendaliks. Wy ûntfange notifikaasjes, wy sjogge dat in autofileover bard is. Wy geane der hast daliks yn en sjogge. Mar al dizze kontrôles moatte op it tafersjochnivo brocht wurde. As jo tagong krije ta Patroni fia de REST API, is d'r skiednis. Mei help fan skiednis, kinne jo sjen nei de tiid stimpels doe't it bestân waard ynladen. Op grûn dêrfan kin tafersjoch dien wurde. Jo kinne de skiednis besjen om te sjen hoefolle eveneminten d'r wiene. As wy mear eveneminten hawwe, betsjut dit dat in autofileover bard is. Jo kinne gean en sjen. Of ús tafersjochautomatisaasje kontrolearre dat wy alle replika's yn plak hawwe, d'r is gjin efterstân en alles is goed.
Tankewol!
Tige tank foar in geweldich ferhaal! As wy it DCS-kluster earne fier fuort fan it Postgres-kluster ferpleatst hawwe, moat dit kluster dan ek periodyk betsjinne wurde? Wat binne de bêste praktiken yn dat guon dielen fan it DCS-kluster moatte wurde útskeakele, wat moat dien wurde mei harren, ensfh? Hoe libbet dizze hiele struktuer? En hoe te dwaan dizze dingen?
Foar ien bedriuw wie it nedich om in probleemmatrix te meitsjen fan wat bart as ien of mear komponinten mislearje. Mei help fan dizze matrix geane wy sequentieel troch alle komponinten en bouwe senario's yn gefal fan mislearring fan dizze komponinten. Dêrtroch kinne jo foar elk mislearre senario in aksjeplan hawwe foar herstel. En yn it gefal fan DCS komt dit as ûnderdiel fan 'e standertynfrastruktuer. En de admin beheart it, en wy fertrouwe al op de admins dy't it beheare en op syn fermogen om it te reparearjen yn gefal fan rampen. As der hielendal gjin DCS is, dan sette wy it yn, mar wy kontrolearje it net spesjaal, om't wy net ferantwurdlik binne foar de ynfrastruktuer, mar wy jouwe oanbefellings oer hoe en wat te kontrolearjen.
Dat is, haw ik goed begrepen dat ik Patroni moat útskeakelje, de filer útskeakelje, alles útskeakelje foardat ik wat mei de hosts dwaan?
It hinget ôf fan hoefolle knopen wy hawwe yn 'e DCS-kluster. As d'r in protte knooppunten binne en as wy mar ien fan 'e knooppunten (replika) útskeakelje, dan wurdt it quorum yn it kluster bewarre. En Patroni bliuwt operasjoneel. En neat wurdt trigger. As wy wat komplekse operaasjes hawwe dy't mear knopen beynfloedzje, wêrfan it ûntbrekken it kworum kin ferneatigje, dan ja, miskien is it sinfol om Patroni te stopjen. It hat in oerienkommende kommando - patronictl pause, patronictl resume. Wy pauze it gewoan, en de autofileover wurket op dit stuit net. Wy dogge ûnderhâld oan de DCS kluster, dan fuortsmite de pauze en fierder mei it libben.
Tige tank!
Tige tank foar it ferslach! Hoe fielt it produktteam oer it ferliezen fan gegevens?
Produkt teams net jouwe in damn, mar team leads binne soargen.
Hokker garânsjes binne der?
It is hiel dreech mei garânsjes. Alexander Kukushkin hat in rapport "Hoe kinne jo RPO en RTO berekkenje", dus hersteltiid en hoefolle gegevens wy kinne ferlieze. Ik tink dat wy dizze dia's moatte fine en studearje. Foar safier't ik my herinner, binne d'r spesifike stappen oer hoe't jo dizze dingen kinne berekkenje. Hoefolle transaksjes kinne wy ferlieze, hoefolle gegevens kinne wy ferlieze. As opsje kinne wy syngroane replikaasje brûke op it Patroni-nivo, mar dit is in dûbelsnijd swurd: wy hawwe gegevensbetrouberens of ferlieze snelheid. D'r is syngroane replikaasje, mar it garandearret ek gjin 100% beskerming tsjin gegevensferlies.
Alexey, tank foar it prachtige rapport! Elke ûnderfining mei it brûken fan Patroni foar beskerming op nul nivo? Dat is, yn kombinaasje mei syngroane standby? Dit is de earste fraach. En de twadde fraach. Jo hawwe ferskate oplossings brûkt. Wy brûkten Repmgr, mar sûnder in autofileover en binne no fan plan om in autofileover te ferbinen. En wy beskôgje Patroni as in alternative oplossing. Wat kinne jo sizze binne de foardielen yn ferliking mei Repmgr?
De earste fraach gie oer syngroane replika's. Nimmen brûkt hjir syngroane replikaasje, om't elkenien bang is (Ferskate kliïnten brûke it al, se hawwe hielendal gjin prestaasjesproblemen opmurken - Speaker's Note). Mar wy hawwe in regel foar ússels ûntwikkele dat yn in syngroane replikaasjekluster op syn minst trije knooppunten moatte wêze, want as wy twa knooppunten hawwe en as de master of replika mislearret, dan skeakelt Patroni dizze knooppunt nei Standalone modus sadat de applikaasje trochgiet nei wurk. Yn dit gefal is d'r in risiko fan gegevensferlies.
Wat de twadde fraach oanbelanget, hawwe wy Repmgr brûkt en dogge it noch foar guon kliïnten om histoaryske redenen. Wat kinne wy sizze? Yn Patroni komt autofileover út it fak yn Repmgr, autofileover komt as in ekstra funksje dy't ynskeakele wurde moat. Wy moatte Repmgr-daemon op elke node útfiere en dan kinne wy de autofileover konfigurearje.
Repmgr kontrolearret oft Postgres-knooppunten libje. Repmgr prosessen kontrolearje it bestean fan elkoar, dit is net in hiel effisjinte oanpak omdat D'r kinne komplekse gefallen wêze fan netwurkisolaasje wêryn in grut Repmgr-kluster yn ferskate lytse kin brekke en trochgean mei wurkjen. Ik haw Repmgr in lange tiid net folge, miskien is dit reparearre ... of miskien net. Mar it oerdragen fan ynformaasje oer de steat fan it kluster nei DCS, lykas Stolon en Patroni dogge, is de meast libbensfetbere opsje.
Alexey, ik haw in fraach dy't lamme kin wêze. Yn ien fan 'e earste foarbylden hawwe jo DCS ferpleatst fan' e lokale masine nei in knooppunt op ôfstân. Wy begripe dat it netwurk is in ding dat hat syn eigen skaaimerken it libbet op syn eigen. En wat bart der as om ien of oare reden it DCS-kluster net beskikber wurdt? Ik sil de redenen net sizze, der kinne in protte fan wêze: fan 'e kromme hannen fan netwurkers oant echte problemen.
Ik haw it net sein lûdop, mar de DCS kluster moat ek v wêze skuld-tolerant, betsjut dat it hat in ûneven oantal knopen foar in kworum. Wat bart der as it DCS-kluster net beskikber wurdt of in kworum kin net berikt wurde, dus in soarte fan netwurksplit of knooppuntfal? Yn dit gefal giet it Patroni-kluster yn allinich lêsmodus. It Patroni-kluster kin de steat fan it kluster net bepale en wat te dwaan. It kin net kontakt DCS en bewarje de nije kluster steat dêr, sadat it hiele kluster giet yn allinnich-lêzen modus. En wachtet of op hânmjittich yntervinsje fan 'e operator of foar herstel fan DCS.
Rûchwei wurdt DCS foar ús in like wichtige tsjinst as de databank sels?
Ja Ja. Yn in protte moderne bedriuwen is Service Discovery in yntegraal diel fan 'e ynfrastruktuer. It wurdt ymplementearre noch foardat d'r sels in database yn 'e ynfrastruktuer wie. Relatyf sprutsen hawwe wy de ynfrastruktuer lansearre, ynset nei de DC, en wy hawwe fuortendaliks Service Discovery. As dit Consul is, dan kin DNS derop boud wurde. As dit Etcd is, dan kin der in diel wêze fan it Kubernetes-kluster wêryn al it oare ynset wurdt. It liket my dat Service Discovery al in yntegraal ûnderdiel is fan moderne ynfrastruktuer. En se tinke der folle earder oer as databases.
Tankewol!
Boarne: www.habr.com
