

Yn dit artikel sil ik prate oer hoe't it projekt wêr't ik oan wurkje is feroare fan in grutte monolith yn in set fan mikrotsjinsten.
It projekt begûn syn skiednis frij lang lyn, begjin 2000. De earste ferzjes waarden skreaun yn Visual Basic 6. Yn 'e rin fan' e tiid waard dúdlik dat ûntwikkeling yn dizze taal yn 'e takomst dreech te stypjen wêze soe, om't de IDE en de taal sels binne min ûntwikkele. Oan 'e ein fan' e jierren 2000 waard besletten om te wikseljen nei de mear kânsrike C #. De nije ferzje waard skreaun yn parallel mei de revyzje fan 'e âlde, stadichoan waard mear en mear koade skreaun yn .NET. Backend yn C # wie yn earste ynstânsje rjochte op in tsjinst arsjitektuer, mar tidens ûntwikkeling waarden mienskiplike biblioteken mei logika brûkt, en tsjinsten waarden lansearre yn ien proses. It resultaat wie in applikaasje dy't wy in "tsjinstmonolith" neamden.
Ien fan 'e pear foardielen fan dizze kombinaasje wie de mooglikheid fan tsjinsten om elkoar te skiljen fia in eksterne API. D'r wiene dúdlike betingsten foar de oergong nei in krekter tsjinst, en yn 'e takomst, microservice-arsjitektuer.
Wy binne om 2015 hinne begûn mei ús wurk oan ûntbining. Wy hawwe noch gjin ideale steat berikt - der binne noch dielen fan in grut projekt dy't amper monolyten neamd wurde kinne, mar se lykje ek net op mikrotsjinsten. Dochs is foarútgong signifikant.
Ik sil der oer prate yn it artikel.
Ynhâld
Arsjitektuer en problemen fan 'e besteande oplossing
Yn it earstoan seach de arsjitektuer sa út: de UI is in aparte applikaasje, it monolityske diel is skreaun yn Visual Basic 6, de .NET-applikaasje is in set fan relatearre tsjinsten dy't wurkje mei in frij grutte databank.
Neidielen fan 'e foarige oplossing
Single punt fan mislearring
Wy hiene ien punt fan mislearring: de .NET-applikaasje rûn yn ien proses. As in module mislearre, mislearre de heule applikaasje en moast opnij starte wurde. Sûnt wy automatisearje in grut oantal prosessen foar ferskillende brûkers, fanwege in mislearring yn ien fan harren, elkenien koe net wurkje foar in skoft. En yn gefal fan in softwareflater holp sels backup net.
Wachtrige fan ferbetterings
Dit nadeel is earder organisatoarysk. Us applikaasje hat in protte klanten, en se wolle allegear sa gau mooglik ferbetterje. Earder wie it ûnmooglik om dit parallel te dwaan, en alle klanten stiene yn 'e rige. Dit proses wie negatyf foar bedriuwen om't se bewize moasten dat har taak weardefol wie. En it ûntwikkelteam hat tiid bestege oan it organisearjen fan dizze wachtrige. Dit koste in protte tiid en muoite, en it produkt koe úteinlik net sa fluch feroarje as se wolle.
Suboptimaal gebrûk fan boarnen
By it hostjen fan tsjinsten yn ien proses, hawwe wy de konfiguraasje altyd folslein kopieare fan tsjinner nei tsjinner. Wy woenen de meast swier beladen tsjinsten apart pleatse om gjin boarnen te fergrieme en fleksibeler kontrôle te krijen oer ús ynsetskema.
It is lestich om moderne technologyen út te fieren
In probleem bekend foar alle ûntwikkelders: d'r is in winsk om moderne technologyen yn it projekt yn te fieren, mar d'r is gjin kâns. Mei in grutte monolithyske oplossing feroaret elke fernijing fan 'e hjoeddeistige bibleteek, om de oergong nei in nije net te hawwen, in nochal net-triviale taak. It duorret lang om de ploechlieder te bewizen dat dit mear bonussen bringe sil as fergriemde senuwen.
Swierrichheid útjaan feroarings
Dit wie it meast serieuze probleem - wy lieten elke twa moannen releases frij.
Elke release feroare yn in echte ramp foar de bank, nettsjinsteande de testen en ynspanningen fan 'e ûntwikkelders. It bedriuw begriep dat oan it begjin fan 'e wike wat fan syn funksjonaliteit net soe wurkje. En de ûntwikkelders begrepen dat der in wike fan serieuze ynsidinten op harren wachte.
Elkenien hie in winsk om de situaasje te feroarjen.
Ferwachtingen fan mikrotsjinsten
Útjefte fan komponinten as klear. Levering fan komponinten as klear troch de oplossing te ûntbinen en ferskate prosessen te skieden.
Lytse produktteams. Dit is wichtich om't in grut team wurke oan de âlde monolith wie lestich te behearjen. Sa'n ploech waard twongen om te wurkjen neffens in strang proses, mar se woene mear kreativiteit en selsstannigens. Allinnich lytse teams koene dit betelje.
Isolaasje fan tsjinsten yn aparte prosessen. Ideaallik soe ik it graach isolearje yn konteners, mar in grut oantal tsjinsten skreaun yn it .NET Framework rinne allinich ûnder WindowsTsjinsten basearre op .NET Core ferskine no, mar d'r binne noch mar in pear fan.
Ynset fleksibiliteit. Wy wolle tsjinsten kombinearje lykas wy it nedich binne, en net sa't de koade it twingt.
Gebrûk fan nije technologyen. Dit is ynteressant foar elke programmeur.
Transysjeproblemen
Fansels, as it maklik wie om in monolyt yn mikrotsjinsten te brekken, soe d'r net nedich wêze om der oer te praten op konferinsjes en artikels te skriuwen. D'r binne in protte falkûlen yn dit proses; Ik sil de wichtichste beskriuwe dy't ús hinderen.
It earste probleem typysk foar de measte monoliten: gearhing fan saaklike logika. As wy in monolyt skriuwe, wolle wy ús klassen opnij brûke om gjin ûnnedige koade te skriuwen. En by it ferpleatsen nei mikrotsjinsten wurdt dit in probleem: alle koade is frij strak keppele, en it is lestich om de tsjinsten te skieden.
Op it momint fan it begjin fan it wurk hie it repository mear dan 500 projekten en mear dan 700 tûzen rigels koade. Dit is nochal in grut beslút en twadde probleem. It wie net mooglik om it gewoan te nimmen en te ferdielen yn mikrotsjinsten.
Tredde probleem - gebrek oan needsaaklike ynfrastruktuer. Yn feite kopiearje wy de boarnekoade manuell nei de servers.
Hoe kinne jo fan monolith nei mikrotsjinsten ferpleatse
Foarsjenning Microservices
As earste hawwe wy fuortendaliks foar ússels bepaald dat de skieding fan mikrotsjinsten in iteratyf proses is. Wy wiene altyd ferplichte om bedriuwsproblemen parallel te ûntwikkeljen. Hoe't wy dit technysk útfiere, is al ús probleem. Dêrom hawwe wy ús taret op in iteratyf proses. It sil gjin oare manier wurkje as jo in grutte applikaasje hawwe en it is yn earste ynstânsje net ree om te wurde herskreaun.
Hokker metoaden brûke wy om mikrotsjinsten te isolearjen?
De earste manier - ferpleatse besteande modules as tsjinsten. Wat dit oanbelanget hienen wy gelok: d'r wiene al registrearre tsjinsten dy't wurken mei it WCF-protokol. Se waarden ferdield yn aparte gearkomsten. Wy hawwe se apart porteare, in lytse launcher tafoege oan elke build. It is skreaun mei de prachtige Topshelf-bibleteek, wêrmei jo de applikaasje kinne útfiere sawol as tsjinst as as konsole. Dit is handich foar debuggen, om't gjin ekstra projekten nedich binne yn 'e oplossing.
De tsjinsten wiene ferbûn neffens saaklike logika, om't se mienskiplike gearkomsten brûkten en wurken mei in mienskiplike databank. Se koene amper neamd wurde mikrotsjinsten yn har suvere foarm. Wy koene dizze tsjinsten lykwols apart leverje, yn ferskate prosessen. Dit allinnich makke it mooglik om te ferminderjen harren ynfloed op elkoar, it ferminderjen fan it probleem mei parallelle ûntwikkeling en ien punt fan mislearring.
Gearstalling mei de host is mar ien rigel fan koade yn de Program klasse. Wy ferburgen wurk mei Topshelf yn in helpklasse.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
De twadde manier om mikrotsjinsten te allocearjen is: meitsje se om nije problemen op te lossen. As tagelyk de monolith net groeit, is dit al poerbêst, dat betsjut dat wy yn 'e goede rjochting geane. Om nije problemen op te lossen, hawwe wy besocht om aparte tsjinsten te meitsjen. As d'r sa'n kâns wie, dan makken wy mear "kanonike" tsjinsten dy't har eigen datamodel folslein beheare, in aparte databank.
Wy, lykas in protte, binne begon mei tsjinsten foar ferifikaasje en autorisaasje. Se binne perfekt foar dit. Se binne ûnôfhinklik, as regel, se hawwe in apart gegevens model. Se sels net ynteraksje mei de monolith, mar it draait om harren te lossen guon problemen. Mei it brûken fan dizze tsjinsten kinne jo de oergong nei in nije arsjitektuer begjinne, de ynfrastruktuer op har debugje, guon oanpakken probearje yn ferbân mei netwurkbiblioteken, ensfh. Wy hawwe gjin teams yn ús organisaasje dy't gjin autentikaasjetsjinst kinne oanmeitsje.
De tredde manier om mikrotsjinsten te allocearjenDe iene dy't wy brûke is in bytsje spesifyk foar ús. Dit is it fuortheljen fan saaklike logika fan 'e UI-laach. Us haad UI-applikaasje is buroblêd; it, lykas de backend, is skreaun yn C#. De ûntwikkelders makken periodyk flaters en brochten dielen fan logika oer nei de UI dy't yn 'e efterkant bestien moatten hawwe en wurde opnij brûkt.
As jo nei in echt foarbyld sjogge fan 'e koade fan it UI-diel, kinne jo sjen dat de measte fan dizze oplossing echte saaklike logika befettet dy't nuttich is yn oare prosessen, net allinich foar it bouwen fan it UI-formulier.
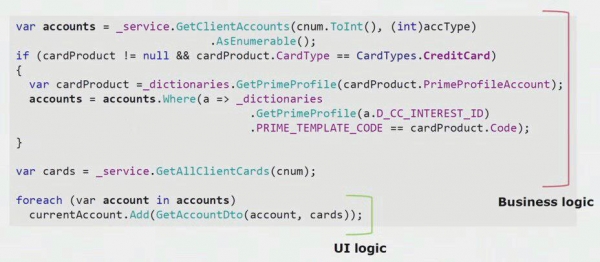
De echte UI-logika is der allinich yn 'e lêste pear rigels. Wy hawwe it oerbrocht nei de tsjinner sadat it opnij brûkt wurde koe, wêrtroch de UI fermindere en de juste arsjitektuer berikke.
De fjirde en wichtichste manier om mikrotsjinsten te isolearjen, Dat makket it mooglik om de monolith te ferminderjen, is it fuortheljen fan besteande tsjinsten mei ferwurking. As wy besteande modules útnimme lykas is, is it resultaat net altyd nei de smaak fan 'e ûntwikkelders, en it bedriuwsproses kin ferâldere wurden wurden sûnt de funksjonaliteit is makke. Mei refactoring kinne wy in nij bedriuwsproses stypje, om't bedriuweasken konstant feroarje. Wy kinne de boarnekoade ferbetterje, bekende defekten ferwiderje en in better gegevensmodel meitsje. D'r binne in protte foardielen sammele.
It skieden fan tsjinsten fan ferwurking is ûnskiedber ferbûn mei it konsept fan beheinde kontekst. Dit is in konsept fan Domain Driven Design. It betsjut in seksje fan it domeinmodel wêryn alle termen fan ien taal unyk definieare binne. Litte wy as foarbyld de kontekst fan fersekering en rekkens sjen. Wy hawwe in monolithic applikaasje, en wy moatte wurkje mei de rekken yn fersekering. Wy ferwachtsje dat de ûntwikkelder in besteande Account-klasse sil fine yn in oare gearkomste, ferwize it fan 'e Insurance-klasse, en wy sille wurkkoade hawwe. It DRY-prinsipe sil wurde respektearre, de taak sil rapper dien wurde troch besteande koade te brûken.
Dêrtroch docht bliken dat de konteksten fan rekkens en fersekering ferbûn binne. As nije easken ûntsteane, sil dizze koppeling ynterferearje mei ûntwikkeling, wêrtroch de kompleksiteit fan al komplekse saaklike logika sil tanimme. Om dit probleem op te lossen, moatte jo de grinzen fine tusken konteksten yn 'e koade en har oertredings fuortsmite. Bygelyks, yn 'e fersekeringskontekst is it heul mooglik dat in 20-sifers akkountnûmer fan' e Sintrale Bank en de datum dat it akkount iepene is genôch wêze.
Om dizze beheine konteksten fan elkoar te skieden en it proses te begjinnen fan it skieden fan mikrotsjinsten fan in monolityske oplossing, brûkten wy in oanpak lykas it meitsjen fan eksterne API's binnen de applikaasje. As wy wisten dat guon module in mikrotsjinst wurde soe, op ien of oare manier feroare yn it proses, dan makken wy fuortendaliks oproppen nei de logika dy't heart by in oare beheinde kontekst fia eksterne oproppen. Bygelyks fia REST of WCF.
Wy stevich besletten dat wy soene net mije koade dat soe fereaskje ferspraat transaksjes. Yn ús gefal, it die bliken frij maklik te folgjen dizze regel. Wy hawwe noch gjin situaasjes tsjinkaam wêr't strikt ferdielde transaksjes echt nedich binne - de definitive gearhing tusken modules is genôch genôch.
Litte wy nei in spesifyk foarbyld sjen. Wy hawwe it konsept fan in orkestrator - in pipeline dy't de entiteit fan 'e "applikaasje" ferwurket. Hy makket op syn beurt in klant, in akkount en in bankkaart. As de klant en it akkount mei súkses oanmakke wurde, mar it oanmeitsjen fan de kaart mislearret, ferpleatst de applikaasje net nei de status "suksesfol" en bliuwt yn 'e status "kaart net oanmakke". Yn 'e takomst sil eftergrûnaktiviteit it ophelje en ôfmeitsje. It systeem is al in skoft yn in steat fan inkonsistinsje, mar wy binne oer it algemien tefreden oer dit.
As der in situaasje ûntstiet as it nedich is om konsekwint in diel fan 'e gegevens te bewarjen, sille wy nei alle gedachten gean foar konsolidaasje fan' e tsjinst om it yn ien proses te ferwurkjen.
Litte wy nei in foarbyld sjen fan it tawizen fan in mikrotsjinst. Hoe kinne jo it relatyf feilich nei produksje bringe? Yn dit foarbyld hawwe wy in apart diel fan it systeem - in leantsjinstmodule, ien fan 'e koade-seksjes wêrfan wy mikroservice wolle meitsje.
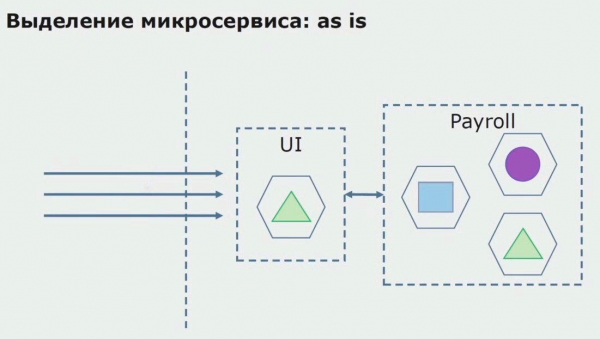
As earste meitsje wy in mikrotsjinst troch de koade te herskriuwen. Wy ferbetterje guon aspekten dêr't wy net bliid mei wiene. Wy implementearje nije saaklike easken fan 'e klant. Wy foegje in API Gateway ta oan de ferbining tusken de UI en de backend, dy't sil foarsjen oprop trochstjoere.
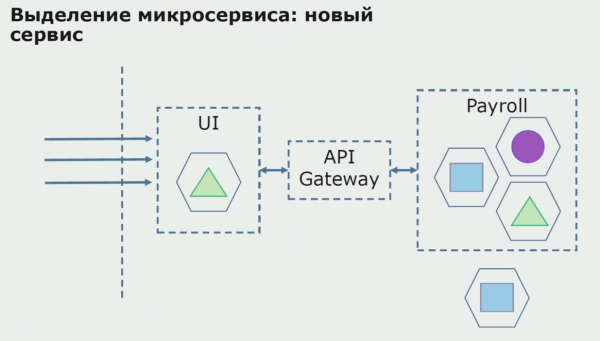
Folgjende, wy frij dizze konfiguraasje yn wurking, mar yn in pilot steat. De measte fan ús brûkers wurkje noch mei âlde saaklike prosessen. Foar nije brûkers ûntwikkelje wy in nije ferzje fan 'e monolityske applikaasje dy't dit proses net mear befettet. Yn essinsje hawwe wy in kombinaasje fan in monolith en in mikroservice dy't wurket as pilot.
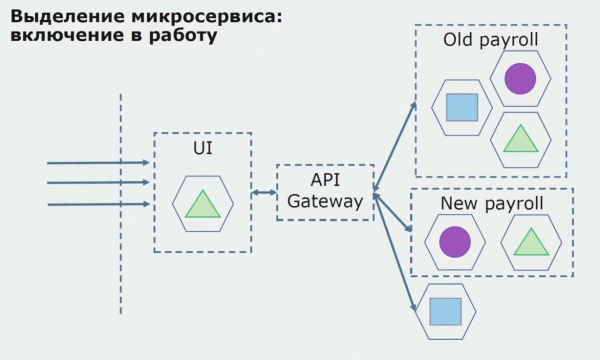
Mei in suksesfolle pilot, wy begripe dat de nije konfiguraasje is yndie wurkber, kinne wy fuortsmite de âlde monolith út de fergeliking en lit de nije konfiguraasje yn plak fan de âlde oplossing.
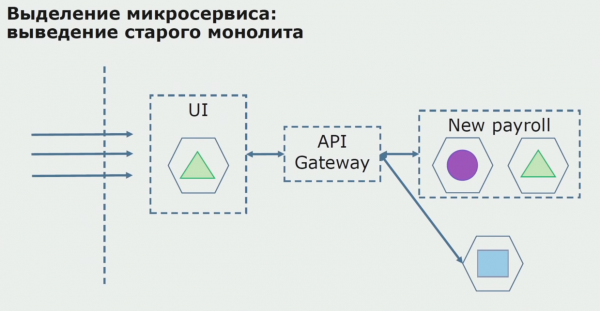
Yn totaal brûke wy hast alle besteande metoaden foar it splitsen fan de boarnekoade fan in monolith. Allegear kinne wy de grutte fan dielen fan 'e applikaasje ferminderje en se oersette nei nije bibleteken, wêrtroch't bettere boarnekoade wurdt.
Wurkje mei de databank
De databank kin slimmer wurde ferdield as de boarnekoade, om't it net allinich it aktuele skema befettet, mar ek sammele histoaryske gegevens.
Us databank, lykas in protte oaren, hie in oar wichtich nadeel - syn enoarme grutte. Dizze databank is ûntwurpen neffens de yngewikkelde saaklike logika fan in monolith, en relaasjes sammele tusken de tabellen fan ferskate begrinzge konteksten.
Yn ús gefal, om alle problemen (grutte databank, in protte ferbiningen, soms ûndúdlike grinzen tusken tabellen), ûntstie in probleem dat foarkomt yn in protte grutte projekten: it brûken fan it dielde databanksjabloan. Gegevens waarden nommen út tabellen troch werjefte, troch replikaasje, en ferstjoerd nei oare systemen dêr't dizze replikaasje wie nedich. Dêrtroch koene wy de tabellen net yn in apart skema ferpleatse om't se aktyf waarden brûkt.
Deselde ferdieling yn beheinde konteksten yn 'e koade helpt ús by skieding. It jout ús normaal in aardich goed idee fan hoe't wy de gegevens op databasenivo ôfbrekke. Wy begripe hokker tabellen hearre ta ien begrinzge kontekst en hokker ta in oar.
Wy brûkten twa globale metoaden fan databank partitioning: partitioning fan besteande tabellen en partitioning mei ferwurking.
It splitsen fan besteande tabellen is in goede metoade om te brûken as de gegevensstruktuer goed is, foldocht oan saaklike easken, en elkenien is der bliid mei. Yn dit gefal kinne wy besteande tabellen skiede yn in apart skema.
In ôfdieling mei ferwurking is nedich as it bedriuwsmodel sterk feroare is, en de tabellen ús hielendal net mear foldwaan.
Splitting besteande tabellen. Wy moatte bepale wat wy sille skiede. Sûnder dizze kennis sil neat wurkje, en hjir sil de skieding fan beheinde konteksten yn 'e koade ús helpe. As regel, as jo de grinzen fan konteksten yn 'e boarnekoade kinne begripe, wurdt it dúdlik hokker tabellen moatte wurde opnommen yn' e list foar de ôfdieling.
Litte wy ús foarstelle dat wy in oplossing hawwe wêryn twa monolithmodules ynteraksje mei ien database. Wy moatte derfoar soargje dat mar ien module ynteraksje mei de seksje fan skieden tabellen, en de oare begjint te ynteraksje mei it fia de API. Om te begjinnen is it genôch dat allinich opname wurdt útfierd fia de API. Dit is in needsaaklike betingst foar ús om te praten oer de ûnôfhinklikens fan mikrotsjinsten. Lêzeferbiningen kinne bliuwe salang't der gjin grut probleem is.
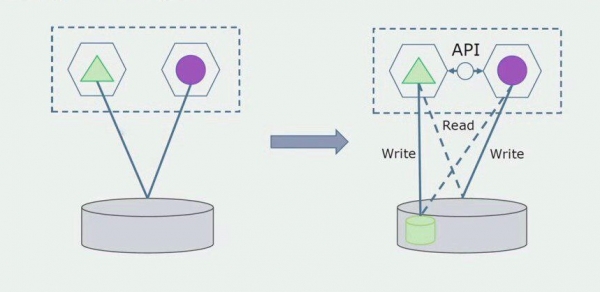
De folgjende stap is dat wy de seksje koade kinne skiede dy't wurket mei skieden tabellen, mei of sûnder ferwurking, yn in aparte mikroservice en it útfiere yn in apart proses, in kontener. Dit sil in aparte tsjinst wêze mei in ferbining mei de monolitedatabase en dy tabellen dy't der net direkt mei relatearje. De monolyt is noch altyd ynteraksje foar it lêzen mei it útnimbere diel.
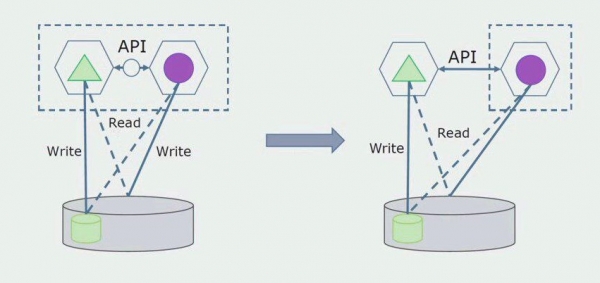
Letter sille wy dizze ferbining fuortsmite, dat is, it lêzen fan gegevens fan in monolityske applikaasje fan skieden tabellen wurdt ek oerbrocht nei de API.
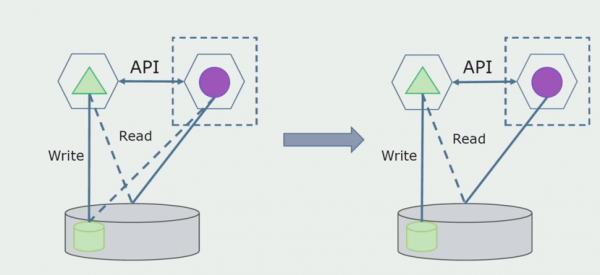
Dêrnei sille wy út 'e algemiene databank de tabellen selektearje wêrmei allinich de nije mikroservice wurket. Wy kinne de tabellen ferpleatse nei in apart skema of sels nei in aparte fysike databank. D'r is noch altyd in lêsferbining tusken de mikrotsjinst en de monolith-database, mar d'r is neat om soargen te meitsjen, yn dizze konfiguraasje kin it nochal lang libje.
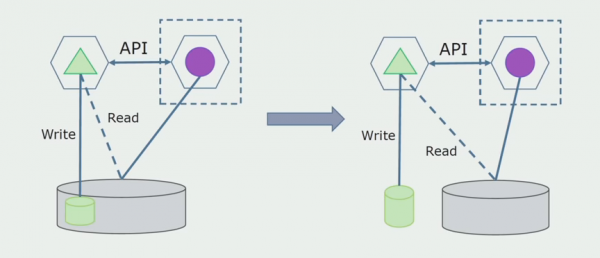
De lêste stap is om alle ferbiningen folslein te ferwiderjen. Yn dit gefal moatte wy miskien gegevens fan 'e haaddatabase migrearje. Soms wolle wy wat gegevens of mappen opnij brûke fan eksterne systemen yn ferskate databases. Dit bart ús periodyk.
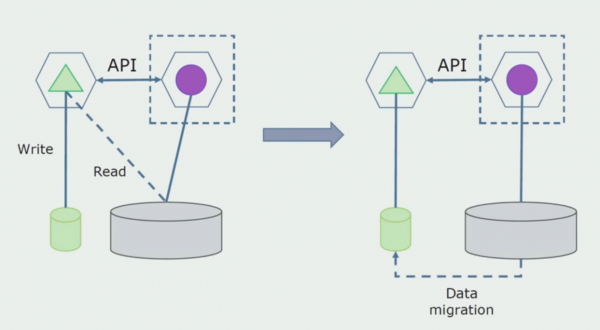
Ferwurkjen ôfdieling. Dizze metoade is tige ferlykber mei de earste, allinich yn omkearde folchoarder. Wy allocearje fuortendaliks in nije databank en in nije mikroservice dy't ynteraksje mei de monolith fia in API. Mar tagelyk bliuwt d'r in set fan databasetabellen dy't wy yn 'e takomst wiskje wolle. Wy hawwe it net mear nedich; wy hawwe it ferfongen yn it nije model.
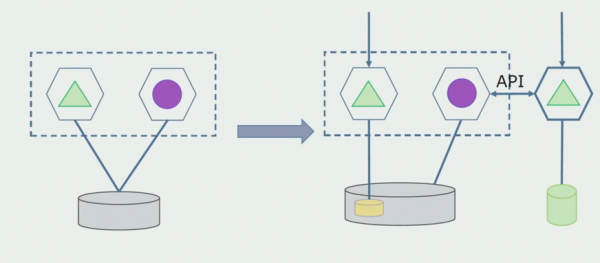
Om dit skema te wurkjen sille wy wierskynlik in oergongsperioade nedich wêze.
Der binne dan twa mooglike oanpakken.
De earste: wy duplisearje alle gegevens yn 'e nije en âlde databases. Yn dit gefal hawwe wy gegevensredundânsje en kinne syngronisaasjeproblemen ûntstean. Mar wy kinne nimme twa ferskillende kliïnten. Ien sil wurkje mei de nije ferzje, de oare mei de âlde.
De twadde: wy ferdiele de gegevens neffens guon saaklike kritearia. Bygelyks, wy hiene 5 produkten yn it systeem dy't waarden opslein yn de âlde databank. Wy pleatse de sechsde binnen de nije saaklike taak yn in nije databank. Mar wy sille in API Gateway nedich wêze dy't dizze gegevens sil syngronisearje en de kliïnt sjen litte wêr't en wat te krijen.
Beide oanpakken wurkje, kieze ôfhinklik fan 'e situaasje.
Nei't wy wis binne dat alles wurket, kin it diel fan 'e monolit dat wurket mei âlde databankstruktueren wurde útskeakele.
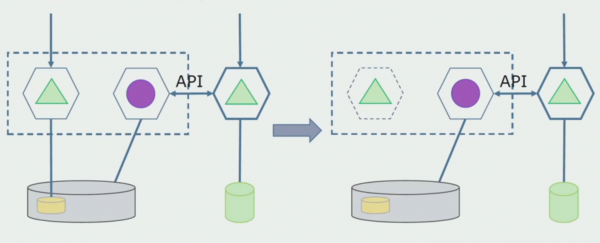
De lêste stap is om de âlde gegevensstruktueren te ferwiderjen.
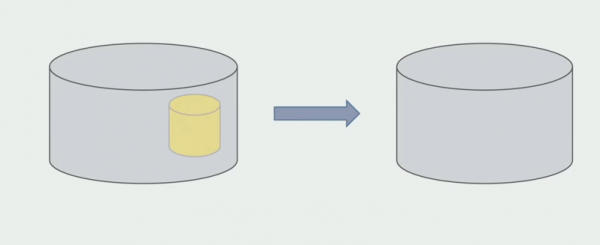
Om gearfetsje kinne wy sizze dat wy problemen hawwe mei de databank: it is lestich om mei te wurkjen yn ferliking mei de boarnekoade, it is dreger om te dielen, mar it kin en moat dien wurde. Wy hawwe wat manieren fûn wêrmei't wy dit frij feilich kinne dwaan, mar it is noch makliker om flaters te meitsjen mei gegevens as mei boarnekoade.
Wurkje mei boarne koade
Dit is hoe't it boarnekoadediagram der útseach doe't wy it monolityske projekt begon te analysearjen.
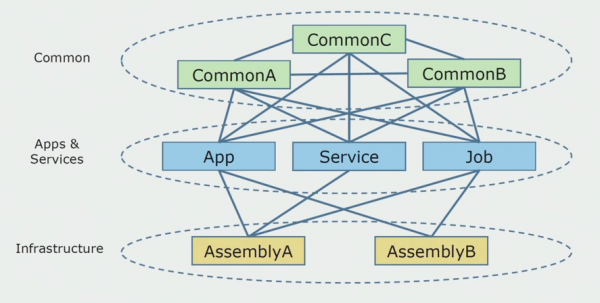
It kin rûchwei ferdield wurde yn trije lagen. Dit is in laach fan lansearre modules, plugins, tsjinsten en yndividuele aktiviteiten. Yn feite wiene dit yngongspunten binnen in monolityske oplossing. Allegear waarden strak ôfsletten mei in mienskiplike laach. It hie saaklike logika dat de tsjinsten dielde en in protte ferbiningen. Elke tsjinst en plugin brûkt oant 10 of mear mienskiplike gearkomsten, ôfhinklik fan har grutte en it gewisse fan 'e ûntwikkelders.
Wy wiene gelok te hawwen ynfrastruktuer biblioteken dy't koe wurde brûkt apart.
Soms ûntstie der in situaasje as guon mienskiplike objekten eins net ta dizze laach hearden, mar ynfrastruktuerbiblioteken wiene. Dit waard oplost troch omneaming.
De grutste soarch wie beheinde konteksten. It barde dat 3-4 konteksten waarden mingd yn ien Common gearkomste en brûkten inoar binnen deselde saaklike funksjes. It wie nedich om te begripen wêr't dit koe wurde ferdield en lâns hokker grinzen, en wat te dwaan neist mei it yn kaart bringen fan dizze divyzje yn boarnekoade-assemblies.
Wy hawwe formulearre ferskate regels foar de koade splitting proses.
De earste: Wy woene gjin saaklike logika mear diele tusken tsjinsten, aktiviteiten en plugins. Wy woenen bedriuwslogika ûnôfhinklik meitsje binnen mikrotsjinsten. Mikrotsjinsten, oan 'e oare kant, wurde ideaal beskôge as tsjinsten dy't folslein ûnôfhinklik besteane. Ik leau dat dizze oanpak is wat wasteful, en it is dreech om te berikken, omdat bygelyks tsjinsten yn C # sil yn alle gefallen wurde ferbûn troch in standert bibleteek. Us systeem is skreaun yn C #; wy hawwe noch gjin oare technologyen brûkt. Dêrom hawwe wy besletten dat wy it betelje kinne om mienskiplike technyske gearkomsten te brûken. It wichtichste is dat se gjin fragminten fan saaklike logika befetsje. As jo in gemak-wrapper hawwe oer de ORM dy't jo brûke, dan is it kopiearjen fan tsjinst nei tsjinst heul djoer.
Us team is in fan fan domein-oandreaune ûntwerp, dus sipel-arsjitektuer wie in geweldige fit foar ús. De basis fan ús tsjinsten is net de gegevenstagongslaach, mar in gearstalling mei domeinlogika, dy't allinich saaklike logika befettet en gjin ferbiningen hat mei de ynfrastruktuer. Tagelyk kinne wy de domeinmontage selsstannich wizigje om problemen op te lossen yn ferbân mei kaders.
Op dit stadium hawwe wy ús earste serieuze probleem tsjinkaam. De tsjinst moast ferwize nei ien domeingearkomste, wy woenen de logika ûnôfhinklik meitsje, en it DRY-prinsipe hindere ús hjir tige. De ûntwikkelders woenen klassen fan oanbuorjende gearkomsten opnij brûke om duplikaasje te foarkommen, en as gefolch begonen domeinen opnij te keppeljen. Wy analysearren de resultaten en besletten dat miskien it probleem ek leit yn it gebiet fan it boarnekoade-opslachapparaat. Wy hienen in grut repository mei alle boarnekoade. De oplossing foar it hiele projekt wie heul lestich om te sammeljen op in lokale masine. Dêrom waarden aparte lytse oplossings makke foar dielen fan it projekt, en gjinien ferbea in tafoeging fan guon mienskiplike of domeingearkomsten oan har en opnij brûke. It ienige ark dat ús dit net koe dwaan wie koadebeoardieling. Mar soms mislearre it ek.
Doe begûnen wy te ferhúzjen nei in model mei aparte repositories. Bedriuwslogika streamt net mear fan tsjinst nei tsjinst, domeinen binne wirklik ûnôfhinklik wurden. Bûnte konteksten wurde dúdliker stipe. Hoe brûke wy ynfrastruktuerbiblioteken opnij? Wy skieden se yn in aparte repository, en sette se dan yn Nuget-pakketten, dy't wy yn Artifactory sette. By elke feroaring fynt gearstalling en publikaasje automatysk.
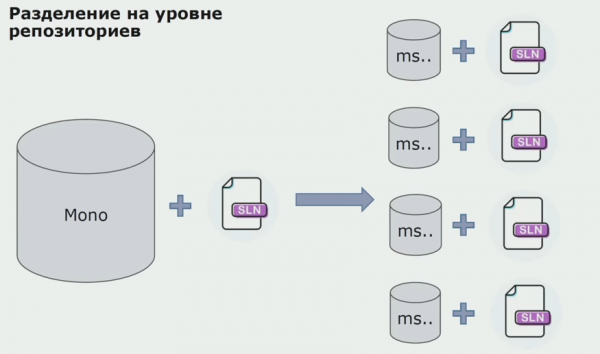
Us tsjinsten begon te ferwizen nei ynterne ynfrastruktuerpakketten op deselde manier as eksterne. Wy downloade eksterne biblioteken fan Nuget. Om te wurkjen mei Artifactory, wêr't wy dizze pakketten pleatsten, brûkten wy twa pakketbehearders. Yn lytse repositories hawwe wy ek Nuget brûkt. Yn repositories mei meardere tsjinsten, wy brûkten Paket, dat jout mear ferzje gearhing tusken modules.
Sadwaande, troch te wurkjen oan 'e boarnekoade, de arsjitektuer in bytsje te feroarjen en de repositories te skieden, meitsje wy ús tsjinsten selsstanniger.
Ynfrastruktuer problemen
De measte fan 'e neidielen foar it ferpleatsen nei mikrotsjinsten binne ynfrastruktuer relatearre. Jo sille automatisearre ynset nedich wêze, jo sille nije biblioteken nedich wêze om de ynfrastruktuer út te fieren.
Hânlieding ynstallaasje yn omjouwings
Yn earste ynstânsje hawwe wy de oplossing foar omjouwings mei de hân ynstalleare. Om dit proses te automatisearjen, hawwe wy in CI / CD-pipeline makke. Wy hawwe keazen foar it trochgeande leveringsproses, om't trochgeande ynset noch net akseptabel is foar ús út it eachpunt fan saaklike prosessen. Dêrom wurdt it ferstjoeren foar operaasje útfierd mei in knop, en foar testen - automatysk.
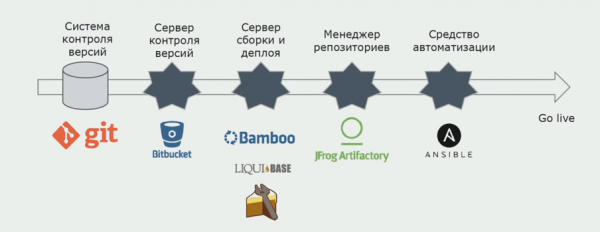
Wy brûke Atlassian, Bitbucket foar boarnekoade opslach en Bamboo foar it bouwen. Wy graach skriuwe build skripts yn Cake omdat it is itselde as C #. Ready-makke pakketten komme nei Artifactory, en Ansible komt automatysk nei de testservers, wêrnei't se daliks testen kinne.
Separate logging
Op in stuit wie ien fan 'e ideeën fan' e monolit om dielde logging te leverjen. Wy moatte ek begripe wat te dwaan mei de yndividuele logs dy't op 'e skiven binne. Us logs wurde skreaun nei tekstbestannen. Wy besletten in gebrûk in standert ELK stack. Wy hawwe net direkt fia de providers nei ELK skreaun, mar besletten dat wy de tekstlogboeken wizigje soene en de trace-ID dêryn skriuwe as in identifier, en de tsjinstnamme taheakje, sadat dizze logs letter kinne wurde parseard.
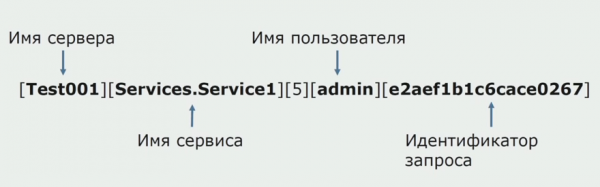
Mei Filebeat kinne wy ús logs sammelje fan servers, transformearje se dan, brûk Kibana om fragen yn 'e brûkersynterface te bouwen, en sjoch hoe't de oprop tusken tsjinsten rûtearre is. Trace-ID's binne hjirfoar tige nuttich.
Testen en debuggen relatearre tsjinsten
Yn earste ynstânsje hawwe wy net folslein begrepen hoe't wy de tsjinsten dy't wurde ûntwikkele kinne debuggen. Alles wie ienfâldich mei de monolith; wy rûnen it op in lokale masine. Earst besochten se itselde te dwaan mei mikrotsjinsten, mar soms om ien mikrotsjinst folslein te starten moatte jo ferskate oaren starte, en dit is ûngemaklik. Wy realisearre dat wy moatte ferhúzje nei in model wêr't wy op 'e lokale masine allinich de tsjinst of tsjinsten litte dy't wy wolle debuggen. De oerbleaune tsjinsten wurde brûkt fan servers dy't oerienkomme mei de konfiguraasje mei prod. Nei it debuggen, by it testen, wurde foar elke taak allinich de feroare tsjinsten útjûn oan de testtsjinner. Sa wurdt de oplossing hifke yn 'e foarm wêryn't it yn 'e takomst yn produksje sil ferskine.
D'r binne servers dy't allinich produksjeferzjes fan tsjinsten útfiere. Dizze servers binne nedich yn gefal fan ynsidinten, om levering te kontrolearjen foar ynset en foar ynterne training.
Wy hawwe in automatisearre testproses tafoege mei de populêre Specflow-bibleteek. Tests rinne automatysk mei NUnit fuort nei ynset fan Ansible. As de taakdekking folslein automatysk is, dan is d'r gjin ferlet fan hânmjittich testen. Hoewol soms ekstra hânmjittich testen is noch fereaske. Wy brûke tags yn Jira om te bepalen hokker tests moatte wurde útfierd foar in spesifyk probleem.
Derneist is de needsaak foar loadtesten tanommen; earder waard it allinich yn seldsume gefallen útfierd. Wy brûke JMeter om tests út te fieren, InfluxDB om se op te slaan, en Grafana om prosesgrafiken te bouwen.
Wat hawwe wy berikt?
Earst hawwe wy it konsept fan "frijlitting" kwyt. Fuort binne de twa-moanne meunsterlike releases doe't dizze kolossus waard ynset yn in produksje omjouwing, tydlik fersteure saaklike prosessen. No sette wy tsjinsten yn gemiddeld elke 1,5 dagen yn, groepearje se om't se nei goedkarring yn wurking gean.
D'r binne gjin fatale flaters yn ús systeem. As wy in mikrotsjinst mei in brek frijlitte, dan sil de funksjonaliteit dy't dêrmei ferbûn is brutsen wurde, en alle oare funksjonaliteit sil net beynfloede wurde. Dit ferbetteret de brûkersûnderfining gâns.
Wy kinne it ynsetpatroan kontrolearje. Jo kinne groepen fan tsjinsten apart selektearje fan 'e rest fan' e oplossing, as it nedich is.
Derneist hawwe wy it probleem signifikant fermindere mei in grutte wachtrige fan ferbetterings. Wy hawwe no aparte produktteams dy't selsstannich wurkje mei guon fan 'e tsjinsten. It Scrum-proses past hjir al goed. In spesifyk team kin in aparte produkteigner hawwe dy't har taken tawize.
Gearfetting
- Mikrotsjinsten binne goed geskikt foar it ûntbinen fan komplekse systemen. Yn it proses begjinne wy te begripen wat yn ús systeem is, wat beheinde konteksten binne, wêr't har grinzen lizze. Hjirmei kinne jo ferbetteringen korrekt fersprieden ûnder modules en koade-ferwarring foarkomme.
- Mikrotsjinsten jouwe organisatoaryske foardielen. Se wurde faak allinich as arsjitektuer sprutsen, mar elke arsjitektuer is nedich om saaklike behoeften op te lossen, en net op himsels. Dêrom kinne wy sizze dat mikrotsjinsten goed geskikt binne foar it oplossen fan problemen yn lytse teams, jûn dat Scrum no heul populêr is.
- Skieding is in iteratyf proses. Jo kinne gjin applikaasje nimme en it gewoan ferdiele yn mikrotsjinsten. It resultaat produkt is net wierskynlik funksjoneel te wêzen. By it tawizen fan mikrotsjinsten is it foardielich om de besteande erfenis te herskriuwen, dat is, it omsette yn koade dy't wy leuk fine en better foldocht oan bedriuwsbehoeften yn termen fan funksjonaliteit en snelheid.
In lytse warskôging: De kosten fan it ferpleatsen nei mikrotsjinsten binne frij signifikant. It duorre lang om it ynfrastruktuerprobleem allinich op te lossen. Dus as jo in lytse applikaasje hawwe dy't gjin spesifike skaalfergrutting fereasket, útsein as jo in grut oantal klanten hawwe dy't konkurrearje om de oandacht en tiid fan jo team, dan binne mikrotsjinsten miskien net wat jo hjoed nedich binne. It is frij djoer. As jo it proses begjinne mei mikrotsjinsten, dan sille de kosten yn 't earstoan heger wêze as as jo itselde projekt begjinne mei de ûntwikkeling fan in monolith.
PS In mear emosjoneel ferhaal (en as foar jo persoanlik) - neffens .
Hjir is de folsleine ferzje fan it rapport.
Boarne: www.habr.com
