


Netflix is de lieder yn 'e ynternettelevyzjemerk - it bedriuw dat dit segmint makke en aktyf ûntwikkelet. Netflix is net allinich bekend om syn wiidweidige katalogus fan films en tv-searjes te krijen fan hast elke hoeke fan 'e planeet en elk apparaat mei in display, mar ek om syn betroubere ynfrastruktuer en unike yngenieurkultuer.
In dúdlik foarbyld fan 'e Netflix-oanpak foar it ûntwikkeljen en stypjen fan komplekse systemen waard presintearre op DevOops 2019 - Direkteur fan ûntwikkeling by Netflix. Studearre oan 'e Fakulteit fan Computational Mathematics and Mathematics fan' e Nizhny Novgorod State University. Lobachevsky, Sergey ien fan 'e earste yngenieurs yn Open Connect - CDN team by Netflix. Hy boude systemen foar it kontrolearjen en analysearjen fan fideogegevens, lansearre in populêre tsjinst foar it beoardieljen fan snelheid fan ynternetferbining FAST.com, en hat de lêste jierren wurke oan it optimalisearjen fan ynternetfersiken sadat de Netflix-applikaasje sa rap mooglik wurket foar brûkers.
It rapport krige de bêste resinsjes fan konferinsje dielnimmers, en wy hawwe taret in tekst ferzje foar dy.

Yn syn rapport spruts Sergei yn detail
- oer wat beynfloedet de fertraging fan ynternetoanfragen tusken de kliïnt en tsjinner;
- hoe te ferminderjen dizze fertraging;
- hoe te ûntwerpen, ûnderhâlden en tafersjoch op flater-tolerante systemen;
- hoe te berikken resultaten yn in koarte tiid, en mei minimale risiko foar it bedriuw;
- hoe't jo resultaten analysearje en learje fan flaters.
Antwurden op dizze fragen binne net allinich nedich troch dyjingen dy't wurkje yn grutte bedriuwen.
De presinteare prinsipes en techniken moatte bekend en praktisearre wurde troch elkenien dy't ynternetprodukten ûntwikkelet en stipet.
Folgjende is de fertelling út it perspektyf fan de sprekker.
It belang fan ynternet snelheid
De snelheid fan ynternetoanfragen is direkt relatearre oan bedriuw. Beskôgje de winkelyndustry: Amazon yn 2009 dat in fertraging fan 100ms resultearret yn in ferlies fan 1% fan ferkeap.
D'r binne hieltyd mear mobile apparaten, folge troch mobile siden en applikaasjes. As jo side langer duorret dan 3 sekonden om te laden, ferlieze jo sawat de helte fan jo brûkers. MEI Google hâldt rekken mei de laden snelheid fan jo side yn sykresultaten: hoe flugger de side, hoe heger syn posysje yn Google.
Ferbiningssnelheid is ek wichtich yn finansjele ynstellingen wêr't latency kritysk is. Yn 2015, Hibernia Networks in kabel fan $ 400 miljoen tusken New York en Londen om de latency tusken de stêden mei 6ms te ferminderjen. Stel jo $ 66 miljoen foar foar 1 ms fan latencyreduksje!
Neffens , ferbiningssnelheden boppe 5 Mbit / s hawwe net mear direkte ynfloed op de laden snelheid fan in typyske webside. D'r is lykwols in lineêre relaasje tusken ferbiningslatinsje en side-laden snelheid:
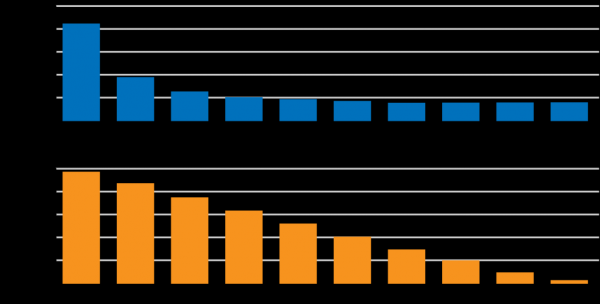
Netflix is lykwols gjin typysk produkt. De ynfloed fan latency en snelheid op 'e brûker is in aktyf gebiet fan analyse en ûntwikkeling. D'r is applikaasje-laden en ynhâldseleksje dy't ôfhinklik binne fan latency, mar laden fan statyske eleminten en streaming binne ek ôfhinklik fan ferbiningssnelheid. Analyse en optimalisearjen fan de kaaifaktoaren dy't de brûkersûnderfining beynfloedzje is in aktyf gebiet fan ûntwikkeling foar ferskate teams by Netflix. Ien fan 'e doelen is om de latency fan oanfragen tusken Netflix-apparaten en de wolkynfrastruktuer te ferminderjen.
Yn it rapport sille wy spesifyk rjochtsje op it ferminderjen fan latency mei it foarbyld fan 'e Netflix-ynfrastruktuer. Litte wy út in praktysk eachpunt beskôgje hoe't jo de prosessen fan ûntwerp, ûntwikkeling en eksploitaasje fan komplekse ferdielde systemen kinne benaderje en tiid besteegje oan ynnovaasje en resultaten, yn stee fan diagnoaze fan operasjonele problemen en storingen.
Binnen Netflix
Tûzenen ferskillende apparaten stypje Netflix-apps. Se wurde ûntwikkele troch fjouwer ferskillende teams, dy't elk aparte kliïntferzjes meitsje foar Android, iOS, TV en webbrowsers. Wy wurkje ek hurd om de brûkersûnderfining te ferbetterjen en te personalisearjen, en fiere hûnderten A/B-tests parallel út.
Personalisaasje wurdt stipe troch hûnderten mikrotsjinsten yn 'e AWS-wolk, dy't personaliseare brûkersgegevens, query-ferstjoering, telemetry, Big Data en kodearring leverje. Ferkearfisualisaasje sjocht der sa út:
Links is it yngongspunt, en dan wurdt it ferkear ferdield oer ferskate hûnderten mikrotsjinsten dy't wurde stipe troch ferskate backend-teams.
In oare wichtige komponint fan ús ynfrastruktuer is de Open Connect CDN, dy't statyske ynhâld leveret oan 'e ein brûker - fideo's, ôfbyldings, kliïntkoade, ensfh. De CDN leit op oanpaste servers (OCA - Open Connect Appliance). Binnen binne d'r arrays fan SSD- en HDD-skiven mei optimalisearre FreeBSD, mei NGINX en in set tsjinsten. Wy ûntwerpe en optimalisearje hardware- en softwarekomponinten sadat sa'n CDN-tsjinner safolle mooglik gegevens nei brûkers stjoere kin.
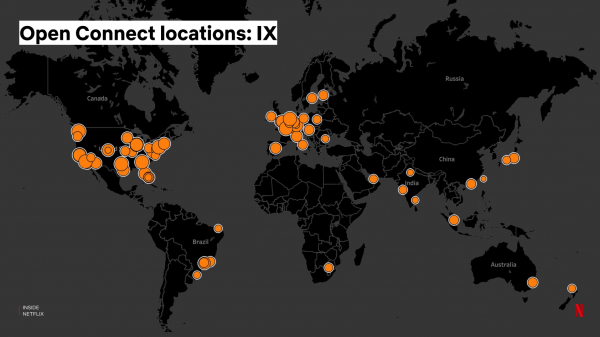
De "muorre" fan dizze servers op it ynternetferkearútwikselpunt (Internet eXchange - IX) sjocht der sa út:

Ynternetútwikseling jout de mooglikheid foar ynternettsjinstferlieners en ynhâldproviders om "ferbine" mei elkoar om mear direkt gegevens op it ynternet te wikseljen. D'r binne sawat 70-80 Internet Exchange-punten om 'e wrâld wêr't ús servers binne ynstalleare, en wy ynstallearje en ûnderhâlde se selsstannich:
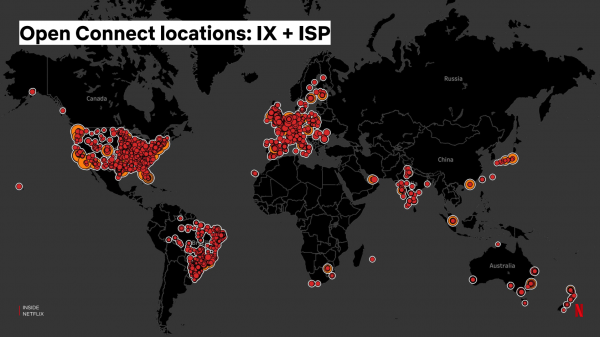
Derneist leverje wy servers direkt oan ynternetproviders, dy't se yn har netwurk ynstallearje, en ferbetterje de lokalisaasje fan Netflix-ferkear en de kwaliteit fan streaming foar brûkers:
In set AWS-tsjinsten is ferantwurdlik foar it ferstjoeren fan fideo-oanfragen fan kliïnten nei CDN-tsjinners, en ek it konfigurearjen fan de servers sels - bywurkjen fan ynhâld, programmakoade, ynstellings, ensfh. Foar de lêste hawwe wy ek in eftergrûnnetwurk boud dat servers yn Internet Exchange-punten ferbynt mei AWS. It eftergrûnnetwurk is in wrâldwide netwurk fan glêstriedkabels en routers dy't wy kinne ûntwerpe en konfigurearje op basis fan ús behoeften.
By , ús CDN-ynfrastruktuer leveret sawat ⅛ fan it ynternetferkear fan 'e wrâld yn spitstiden en ⅓ fan it ferkear yn Noard-Amearika, wêr't Netflix it langst west hat. Yndrukwekkende sifers, mar foar my is ien fan 'e meast geweldige prestaasjes dat it hiele CDN-systeem wurdt ûntwikkele en ûnderhâlden troch in team fan minder dan 150 minsken.
Yn it earstoan waard de CDN-ynfrastruktuer ûntworpen om fideogegevens te leverjen. Yn 'e rin fan' e tiid realisearren wy lykwols dat wy it ek kinne brûke om dynamyske oanfragen fan kliïnten yn 'e AWS-wolk te optimalisearjen.
Oer ynternetfersnelling
Tsjintwurdich hat Netflix 3 AWS-regio's, en de latency fan oanfragen nei de wolk sil ôfhingje fan hoe fier de klant fan 'e tichtstbye regio is. Tagelyk hawwe wy in protte CDN-tsjinners dy't wurde brûkt om statyske ynhâld te leverjen. Is d'r ien manier om dit ramt te brûken om dynamyske fragen te fersnellen? Spitigernôch is it lykwols ûnmooglik om dizze oanfragen te cache - API's binne personaliseare en elk resultaat is unyk.
Litte wy in proxy meitsje op 'e CDN-tsjinner en begjinne ferkear dêrtroch te ferstjoeren. Sil it flugger wêze?
Materiel
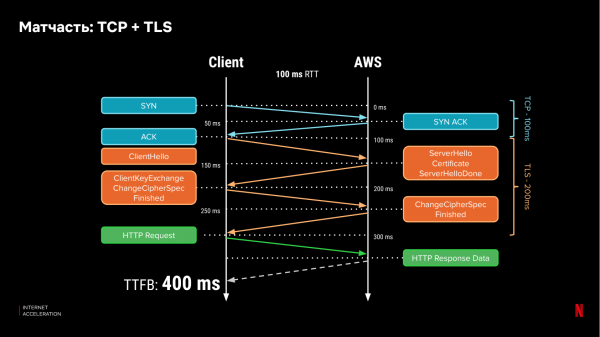
Lit ús ûnthâlde hoe't netwurkprotokollen wurkje. Tsjintwurdich brûkt it measte ferkear op it ynternet HTTPs, wat ôfhinklik is fan 'e legere laachprotokollen TCP en TLS. Om in kliïnt te ferbinen mei de tsjinner, docht it in handshake, en om in feilige ferbining te meitsjen, moat de kliïnt trije kear berjochten útwikselje mei de tsjinner en op syn minst noch ien kear om gegevens oer te bringen. Mei in latency per rûnreis (RTT) fan 100 ms, soe it ús 400 ms duorje om it earste bit gegevens te ûntfangen:
As wy de sertifikaten op 'e CDN-tsjinner pleatse, dan kin de handshake-tiid tusken de kliïnt en de server gâns fermindere wurde as de CDN tichterby is. Litte wy oannimme dat de latency nei de CDN-tsjinner 30ms is. Dan sil it 220 ms duorje om it earste bit te ûntfangen:
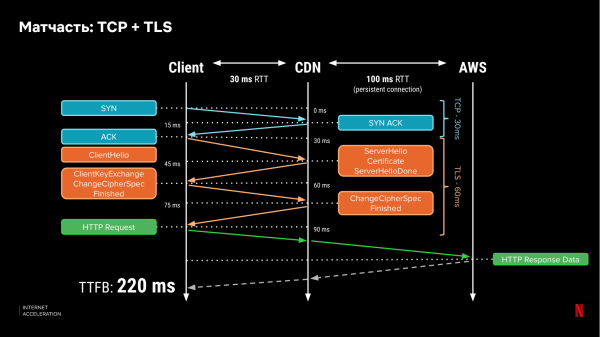
Mar de foardielen einigje dêr net. Sadree't in ferbining is ta stân kommen, fergruttet TCP it congestie-finster (it hoemannichte ynformaasje dy't it parallel oer dy ferbining kin ferstjoere). As in gegevenspakket ferlern giet, ferminderje klassike ymplemintaasjes fan it TCP-protokol (lykas TCP New Reno) it iepen "finster" mei de helte. De groei fan it congestiefenster, en de snelheid fan har herstel fan ferlies hinget wer ôf fan 'e fertraging (RTT) nei de tsjinner. As dizze ferbining allinich sa fier giet as de CDN-tsjinner, sil dit herstel rapper wêze. Tagelyk is pakketferlies in standert ferskynsel, benammen foar draadloze netwurken.
Ynternetbânbreedte kin wurde fermindere, benammen yn spitstiden, troch ferkear fan brûkers, dat kin liede ta files. D'r is lykwols gjin manier op it ynternet om foarrang te jaan oan guon oanfragen boppe oaren. Jou bygelyks prioriteit oan lytse en latency-gefoelige oanfragen oer "swiere" gegevensstreamen dy't it netwurk lade. Lykwols, yn ús gefal, mei ús eigen rêchbonke netwurk kinne wy dit dwaan op in diel fan it fersykpaad - tusken de CDN en de wolk, en wy kinne it folslein konfigurearje. Jo kinne der wis fan dat lytse en latency-gefoelige pakketten wurde prioriteit, en grutte gegevens streamt giet in bytsje letter. Hoe tichter de CDN by de klant is, hoe grutter de effisjinsje.
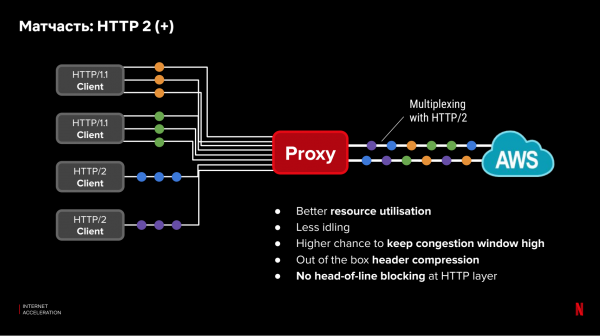
Applikaasjenivo-protokollen (OSI-nivo 7) hawwe ek ynfloed op latency. Nije protokollen lykas HTTP/2 optimalisearje de prestaasjes fan parallelle oanfragen. Wy hawwe lykwols Netflix-kliïnten mei âldere apparaten dy't de nije protokollen net stypje. Net alle kliïnten kinne wurde bywurke of optimaal ynsteld. Tagelyk, tusken de CDN-proxy en de wolk is d'r folsleine kontrôle en de mooglikheid om nije, optimale protokollen en ynstellingen te brûken. It ineffektive diel mei âlde protokollen sil allinich wurkje tusken de kliïnt en de CDN-tsjinner. Boppedat kinne wy multiplex-oanfragen meitsje op in al fêststelde ferbining tusken de CDN en de wolk, it ferbetterjen fan ferbiningsgebrûk op it TCP-nivo:
Wy mjitte
Nettsjinsteande it feit dat de teory ferbetteringen belooft, ha wy net fuortendaliks om it systeem yn produksje te lansearjen. Ynstee dêrfan moatte wy earst bewize dat it idee yn 'e praktyk sil wurkje. Om dit te dwaan moatte jo ferskate fragen beantwurdzje:
- Speed: sil in proxy flugger wêze?
- Reliabiliteit: Sil it faker brekke?
- Swierrichheid: hoe yntegrearje mei applikaasjes?
- kosten fan: Hoefolle kostet it om ekstra ynfrastruktuer yn te setten?
Lit ús yn detail beskôgje ús oanpak foar it beoardieljen fan it earste punt. De rest wurdt op deselde wize behannele.
Om de snelheid fan oanfragen te analysearjen, wolle wy gegevens krije foar alle brûkers, sûnder in protte tiid te besteegjen oan ûntwikkeling en sûnder produksje te brekken. D'r binne ferskate oanpak foar dit:
- RUM, of passive fersyk mjitting. Wy mjitte de útfieringstiid fan aktuele oanfragen fan brûkers en soargje foar folsleine brûkersdekking. It neidiel is dat it sinjaal is net hiel stabyl troch in protte faktoaren, Bygelyks, fanwege ferskillende fersyk maten, ferwurkjen tiid op de tsjinner en client. Derneist kinne jo gjin nije konfiguraasje testen sûnder effekt yn produksje.
- Laboratoarium tests. Spesjale servers en ynfrastruktuer dy't kliïnten simulearje. Mei har help fiere wy de nedige tests út. Op dizze manier krije wy folsleine kontrôle oer de mjitresultaten en in dúdlik sinjaal. Mar d'r is gjin folsleine dekking fan apparaten en brûkerslokaasjes (benammen mei in wrâldwide tsjinst en stipe foar tûzenen apparaatmodellen).
Hoe kinne jo de foardielen fan beide metoaden kombinearje?
Us team hat in oplossing fûn. Wy hawwe in lyts stikje koade skreaun - in foarbyld - dat wy yn ús applikaasje boud hawwe. Probes tastean ús te dwaan folslein kontrolearre netwurk tests fan ús apparaten. It wurket sa:
- Koart nei it laden fan de applikaasje en it foltôgjen fan de earste aktiviteit, rinne wy ús probes.
- De kliïnt makket in fersyk oan de tsjinner en krijt in "resept" foar de test. It resept is in list mei URL's dêr't in HTTP(s) fersyk oan dien wurde moat. Derneist konfigurearret it resept oanfraachparameters: fertragingen tusken oanfragen, hoemannichte oanfrege gegevens, HTTP(s)-headers, ensfh. Tagelyk kinne wy ferskate ferskillende resepten parallel testen - by it oanfreegjen fan in konfiguraasje, bepale wy willekeurich hokker resept te útjaan.
- De starttiid fan de sonde wurdt selektearre om net yn konflikt te kommen mei it aktive gebrûk fan netwurkboarnen op 'e kliïnt. Yn essinsje wurdt de tiid selektearre as de klant net aktyf is.
- Nei it ûntfangen fan it resept makket de kliïnt oanfragen oan elk fan 'e URL's, parallel. It fersyk oan elk fan 'e adressen kin wurde werhelle - de saneamde. "pulses". Op de earste puls mjitte wy hoe lang it duorre om in ferbining te meitsjen en gegevens te downloaden. Op de twadde puls mjitte wy de tiid dy't it nimt om gegevens te laden oer in al fêststelde ferbining. Foar de tredde kinne wy in fertraging ynstelle en de snelheid mjitte foar it oprjochtsjen fan in opnij ferbining, ensfh.
Tidens de test mjitte wy alle parameters dy't it apparaat kin krije:
- DNS-oanfraachtiid;
- TCP ferbining setup tiid;
- TLS ferbining opset tiid;
- tiid fan ûntfangst fan de earste byte fan gegevens;
- totale laden tiid;
- status resultaat koade.
- Nei't alle pulsen binne foltôge, laadt it stekproef alle mjittingen foar analyse.
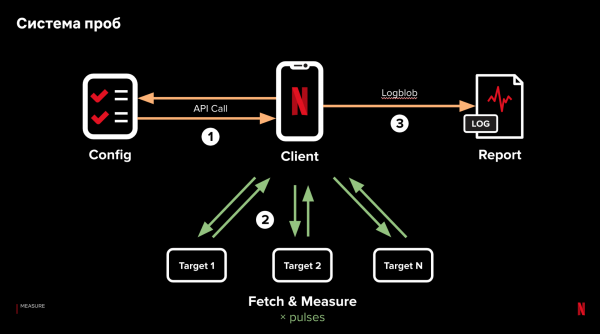
De kaaipunten binne minimale ôfhinklikens fan logika op 'e kliïnt, gegevensferwurking op' e tsjinner en it mjitten fan parallelle oanfragen. Sa kinne wy de ynfloed fan ferskate faktoaren isolearje en testen dy't ynfloed hawwe op query-prestaasjes, fariearje se binnen ien resept, en resultaten krije fan echte kliïnten.
Dizze ynfrastruktuer hat bewiisd nuttich foar mear dan allinich analyse fan queryprestaasjes. Op it stuit hawwe wy 14 aktive resepten, mear dan 6000 samples per sekonde, ûntfange gegevens út alle hoeken fan 'e ierde en folsleine apparaat dekking. As Netflix in ferlykbere tsjinst kocht fan in tredde partij, soe it miljoenen dollars yn 't jier kostje, mei folle minder dekking.
Testteory yn 'e praktyk: prototype
Mei sa'n systeem kinne wy de effektiviteit fan CDN-proxy's evaluearje op fersyk latency. No moatte jo:
- meitsje in proxy prototype;
- pleats it prototype op in CDN;
- bepale hoe't jo kliïnten rjochtsje nei in proxy op in spesifike CDN-tsjinner;
- Fergelykje prestaasjes mei oanfragen yn AWS sûnder proxy.
De taak is om de effektiviteit fan 'e foarstelde oplossing sa gau mooglik te evaluearjen. Wy hawwe Go keazen om it prototype te ymplementearjen fanwegen de beskikberens fan goede netwurkbiblioteken. Op elke CDN-tsjinner hawwe wy de prototype-proxy ynstalleare as in statyske binêr om ôfhinklikens te minimalisearjen en yntegraasje te ferienfâldigjen. Yn 'e inisjele ymplemintaasje brûkten wy safolle mooglik standertkomponinten en lytse oanpassingen foar pooling fan HTTP / 2-ferbining en multiplexing oanfreegje.
Om lykwicht te meitsjen tusken AWS-regio's, brûkten wy in geografyske DNS-database, deselde dy't brûkt waard om kliïnten te balansearjen. Om in CDN-tsjinner foar de kliïnt te selektearjen, brûke wy TCP Anycast foar servers yn Internet Exchange (IX). Yn dizze opsje brûke wy ien IP-adres foar alle CDN-tsjinners, en de kliïnt wurdt rjochte op de CDN-tsjinner mei it minste oantal IP-hops. Yn CDN-tsjinners ynstalleare troch ynternetproviders (ISP's), hawwe wy gjin kontrôle oer de router om TCP Anycast te konfigurearjen, dus wy brûke , dy't klanten rjochtet nei ynternetproviders foar fideostreaming.
Dat, wy hawwe trije soarten oanfraachpaden: nei de wolk fia it iepen ynternet, fia in CDN-tsjinner yn IX, of fia in CDN-tsjinner by in ynternetprovider. Us doel is om te begripen hokker manier better is, en wat is it foardiel fan in proxy, yn ferliking mei hoe't oanfragen nei produksje wurde stjoerd. Om dit te dwaan, brûke wy it folgjende samplingsysteem:
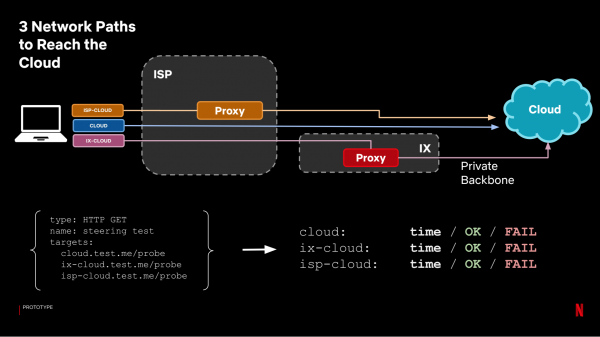
Elk fan 'e paden wurdt in apart doel, en wy sjogge nei de tiid dy't wy krigen. Foar analyse kombinearje wy de proxy-resultaten yn ien groep (selektearje de bêste tiid tusken IX- en ISP-proxies), en fergelykje se mei de tiid fan oanfragen nei de wolk sûnder proxy:
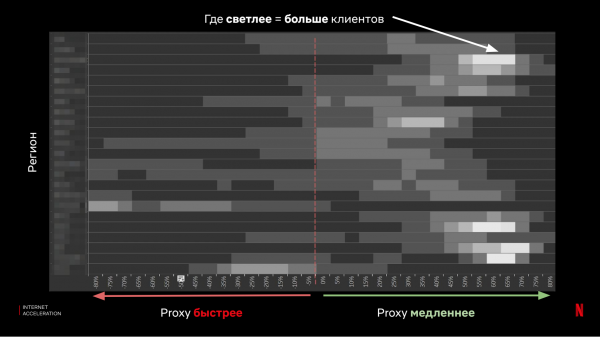
Sa't jo sjen kinne, wiene de resultaten mingd - yn 'e measte gefallen jout de proxy in goede snelheid, mar d'r binne ek in foldwaande oantal kliïnten foar wa't de situaasje signifikant fergriemt.
As gefolch hawwe wy ferskate wichtige dingen dien:
- Wy beoardielje de ferwachte prestaasjes fan oanfragen fan kliïnten nei de wolk fia in CDN-proxy.
- Wy krigen gegevens fan echte kliïnten, fan alle soarten apparaten.
- Wy realisearre dat de teory wie net 100% befêstige en it earste oanbod mei in CDN proxy soe net wurkje foar ús.
- Wy namen gjin risiko's - wy hawwe produksjekonfiguraasjes foar kliïnten net feroare.
- Der wie neat stikken.
Prototype 2.0
Dus, werom nei it tekenboerd en werhelje it proses wer.
It idee is dat yn stee fan in 100% proxy te brûken, sille wy it fluchste paad foar elke kliïnt bepale, en wy sille dêr fersiken stjoere - dat is, wy sille dwaan wat hjit client steering.
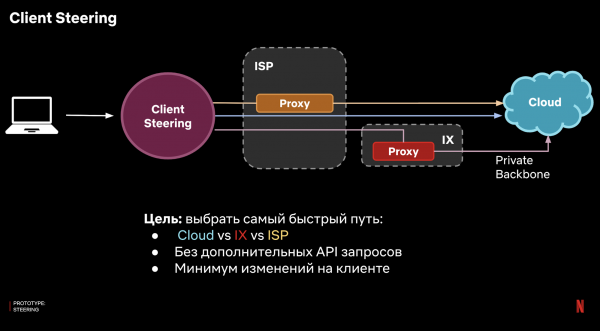
Hoe kinne jo dit útfiere? Wy kinne gjin logika brûke oan 'e serverkant, om't ... It doel is om te ferbinen mei dizze tsjinner. D'r moat ien of oare manier wêze om dit op 'e kliïnt te dwaan. En ideaal, doch dit mei in minimum bedrach fan komplekse logika, om it probleem fan yntegraasje net op te lossen mei in grut oantal kliïntplatfoarms.
It antwurd is om DNS te brûken. Yn ús gefal hawwe wy ús eigen DNS-ynfrastruktuer, en wy kinne in domeinsône ynstelle wêrfoar ús servers autoritêr sille wêze. It wurket sa:
- De kliïnt makket in fersyk oan de DNS-tsjinner mei in host, bygelyks api.netflix.xom.
- It fersyk komt by ús DNS-tsjinner
- De DNS-tsjinner wit hokker paad it rapste is foar dizze kliïnt en jout it oerienkommende IP-adres út.
De oplossing hat in ekstra kompleksiteit: autoritêre DNS-providers sjogge it IP-adres fan 'e kliïnt net en kinne allinich it IP-adres lêze fan' e rekursive resolver dy't de kliïnt brûkt.
As resultaat moat ús autoritêre resolver in beslút nimme net foar in yndividuele kliïnt, mar foar in groep kliïnten basearre op 'e rekursive resolver.
Om op te lossen, brûke wy deselde samples, aggregearje de mjittingsresultaten fan kliïnten foar elk fan 'e rekursive resolvers en beslute wêr't dizze groep fan har te stjoeren - in proxy fia IX mei TCP Anycast, fia in ISP-proxy, of direkt nei de wolk.
Wy krije it folgjende systeem:
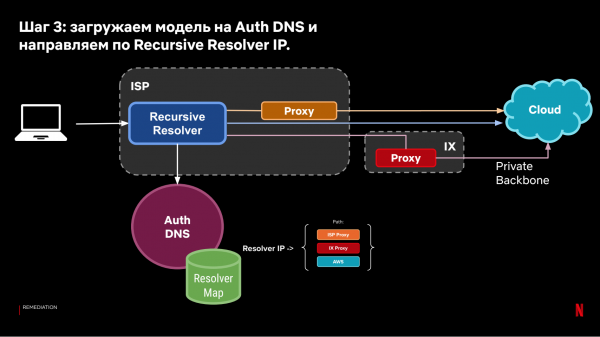
It resultearjende DNS-steeringmodel lit jo kliïnten rjochtsje op basis fan histoaryske observaasjes fan 'e snelheid fan ferbiningen fan kliïnten nei de wolk.
Nochris is de fraach hoe effektyf sil dizze oanpak wurkje? Om te beantwurdzjen brûke wy wer ús probesysteem. Dêrom konfigurearje wy de presintatorkonfiguraasje, wêrby't ien fan 'e doelen de rjochting folget fan DNS-steering, de oare giet direkt nei de wolk (aktuele produksje).
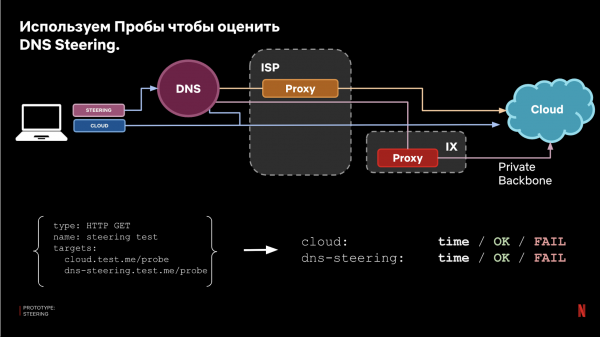
As resultaat fergelykje wy de resultaten en krije in beoardieling fan 'e effektiviteit:
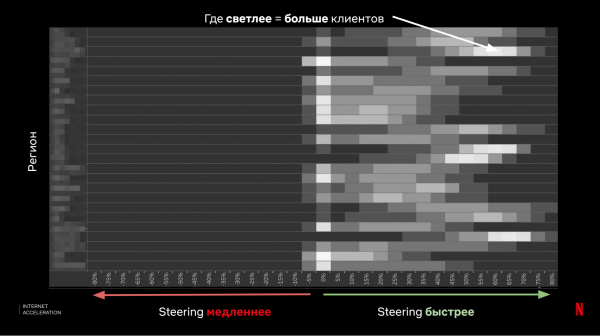
As gefolch hawwe wy ferskate wichtige dingen leard:
- Wy beoardielje de ferwachte prestaasjes fan oanfragen fan kliïnten nei de wolk mei DNS Steering.
- Wy krigen gegevens fan echte kliïnten, fan alle soarten apparaten.
- De effektiviteit fan it foarstelde idee is bewiisd.
- Wy namen gjin risiko's - wy hawwe produksjekonfiguraasjes foar kliïnten net feroare.
- Der wie neat stikken.
No oer it lestige diel - wy lansearje it yn produksje
It maklike diel is no foarby - d'r is in wurkjend prototype. No is it hurde diel in oplossing lansearje foar al it ferkear fan Netflix, ynset op 150 miljoen brûkers, tûzenen apparaten, hûnderten mikrotsjinsten, en in hieltyd feroarjend produkt en ynfrastruktuer. Netflix-tsjinners ûntfange miljoenen oanfragen per sekonde, en it is maklik om de tsjinst te brekken mei achtleaze aksje. Tagelyk wolle wy dynamysk ferkear troch tûzenen CDN-tsjinners op it ynternet ferpleatse, wêr't wat feroaret en brekt konstant en op it meast ûnopportune momint.
En mei dit alles hat it team 3 yngenieurs ferantwurdlik foar de ûntwikkeling, ynset en folsleine stipe fan it systeem.
Dêrom sille wy trochgean te praten oer rêstige en sûne sliep.
Hoe kinne jo ûntwikkeling trochgean en net al jo tiid besteegje oan stipe? Us oanpak is basearre op 3 prinsipes:
- Wy ferminderje de potinsjele skaal fan breakdowns (blast radius).
- Wy binne tariede op ferrassingen - wy ferwachtsje dat der wat sil brekke, nettsjinsteande testen en persoanlike ûnderfining.
- Graceful degradation - as iets net goed wurket, moat it automatysk reparearre wurde, sels as net op 'e meast effisjinte manier.
It die bliken dat yn ús gefal, mei dizze oanpak fan it probleem, kinne wy fine in ienfâldige en effektive oplossing en gâns ferienfâldigjen systeem stipe. Wy realisearre dat wy koenen tafoegje in lyts stikje koade oan de kliïnt en monitor foar netwurk fersyk flaters feroarsake troch ferbining problemen. Yn gefal fan netwurkflaters meitsje wy in fallback direkt nei de wolk. Dizze oplossing fereasket gjin signifikante ynset foar kliïntteams, mar ferminderet it risiko fan ûnferwachte flaters en ferrassingen foar ús sterk.
Fansels, nettsjinsteande de fallback, folgje wy dochs in dúdlike dissipline by ûntwikkeling:
- Sample test.
- A / B-testen of Kanaryske.
- Progressive útrol.
Mei samples is de oanpak beskreaun - feroarings wurde earst hifke mei in oanpast resept.
Foar kanaryske testen moatte wy ferlykbere pearen servers krije wêrop wy kinne fergelykje hoe't it systeem wurket foar en nei de feroarings. Om dit te dwaan, fan ús protte CDN-siden, selektearje wy pearen servers dy't fergelykber ferkear ûntfange:
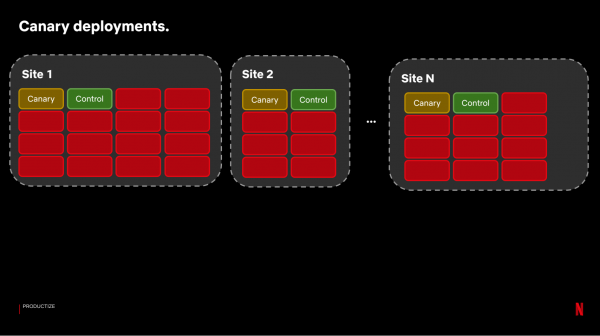
Dan ynstallearje wy de build mei de wizigingen op 'e Kanaryske tsjinner. Om de resultaten te evaluearjen, rinne wy in systeem dat sawat 100-150 metriken fergeliket mei in stekproef fan kontrôleservers:
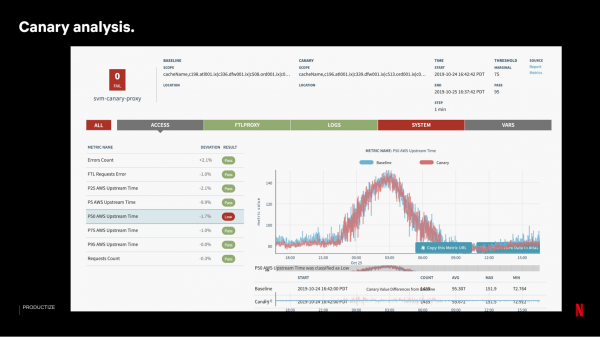
As Kanaryske testen suksesfol is, dan litte wy it stadichoan frijlitte, yn weagen. Wy aktualisearje gjin servers op elke side tagelyk - it ferliezen fan in heule side fanwege problemen hat in wichtiger ynfloed op 'e tsjinst foar brûkers dan it ferliezen fan itselde oantal servers op ferskate lokaasjes.
Yn 't algemien hinget de effektiviteit en feiligens fan dizze oanpak ôf fan' e kwantiteit en kwaliteit fan 'e sammele metriken. Foar ús query-fersnellingssysteem sammelje wy metriken fan alle mooglike komponinten:
- fan kliïnten - oantal sesjes en oanfragen, fallback tariven;
- proxy - statistiken oer it oantal en tiid fan oanfragen;
- DNS - oantal en resultaten fan oanfragen;
- wolkrâne - oantal en tiid foar it ferwurkjen fan oanfragen yn 'e wolk.
Dit alles wurdt sammele yn ien pipeline, en, ôfhinklik fan 'e behoeften, beslute wy hokker metriken te stjoeren nei real-time analytics, en hokker nei Elasticsearch of Big Data foar mear detaillearre diagnostyk.
Wy kontrolearje

Yn ús gefal meitsje wy feroaringen op it krityske paad fan oanfragen tusken de kliïnt en de tsjinner. Tagelyk is it oantal ferskillende komponinten op 'e kliïnt, op' e server, en op 'e wei troch it ynternet enoarm. Feroarings op 'e kliïnt en server komme konstant - tidens it wurk fan tsientallen teams en natuerlike feroaringen yn it ekosysteem. Wy binne yn 'e midden - by it diagnostisearjen fan problemen is d'r in goede kâns dat wy belutsen wurde. Dêrom moatte wy dúdlik begripe hoe't jo metriken definiearje, sammelje en analysearje om problemen fluch te isolearjen.
Idealiter folsleine tagong ta alle soarten metriken en filters yn realtime. Mar d'r binne in protte metriken, dus de fraach fan kosten ûntstiet. Yn ús gefal skiede wy metriken en ûntwikkelingsark as folget:

Om problemen te ûntdekken en te triage brûke wy ús eigen iepen-boarne real-time systeem и - foar fisualisaasje. It bewarret aggregearre metriken yn it ûnthâld, is betrouber en yntegreart mei it warskôgingssysteem. Foar lokalisaasje en diagnostyk hawwe wy tagong ta logs fan Elasticsearch en Kibana. Foar statistyske analyze en modellering brûke wy grutte gegevens en fisualisaasje yn Tableau.
It liket derop dat dizze oanpak heul lestich is om mei te wurkjen. Troch metriken en ark hiërargysk te organisearjen, kinne wy lykwols in probleem fluch analysearje, it type probleem bepale en dan yn detaillearre metriken boarje. Yn 't algemien besteegje wy sawat 1-2 minuten om de boarne fan' e ôfbraak te identifisearjen. Dêrnei wurkje wy mei in spesifyk team oan diagnostyk - fan tsientallen minuten oant ferskate oeren.
Sels as de diagnoaze gau dien wurdt, wolle wy net dat dit faak bart. Ideal sille wy allinich in krityske warskôging krije as d'r in signifikante ynfloed is op 'e tsjinst. Foar ús query-fersnellingssysteem hawwe wy mar 2 warskôgings dy't sille warskôgje:
- Client Fallback persintaazje - beoardieling fan klant gedrach;
- persintaazje Probe flaters - stabiliteit gegevens fan netwurk komponinten.
Dizze krityske warskôgings kontrolearje oft it systeem wurket foar de mearderheid fan brûkers. Wy sjogge nei hoefolle kliïnten fallback brûkten as se net yn steat wiene om fersnelling fan fersyk te krijen. Wy gemiddeld minder dan 1 krityske warskôging per wike, ek al binne d'r in ton feroarings yn it systeem. Wêrom is dit genôch foar ús?
- D'r is in klantfallback as ús proxy net wurket.
- Der is in automatysk stjoersysteem dat reagearret op problemen.
Mear details oer de lêste. Us proefsysteem, en it systeem foar it automatysk bepalen fan it optimale paad foar oanfragen fan 'e kliïnt nei de wolk, kinne ús automatysk omgean mei guon problemen.
Litte wy weromgean nei ús foarbyldkonfiguraasje en 3 paadkategoryen. Neist laden tiid, kinne wy sjen op it feit fan levering sels. As it net mooglik wie om de gegevens te laden, dan kinne wy troch de resultaten op ferskate paden te sjen, bepale wêr't en wat bruts, en oft wy it automatysk kinne reparearje troch it fersykpaad te feroarjen.
foarbylden:
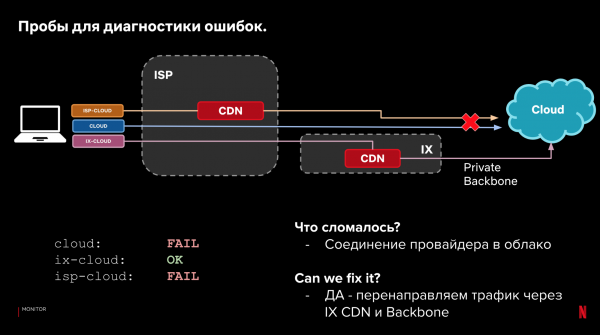
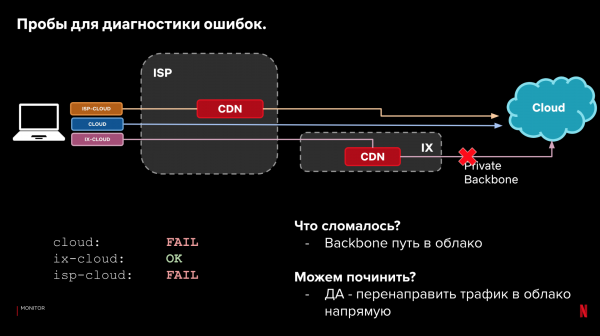
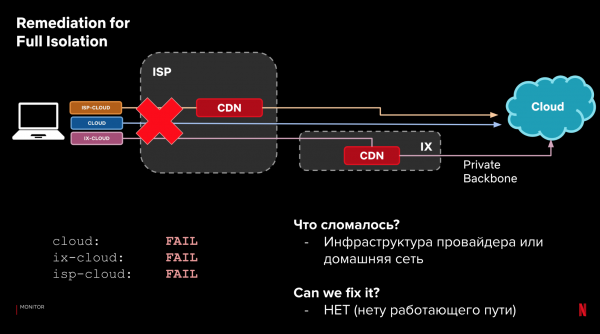
Dit proses kin automatisearre wurde. Meitsje it yn it stjoersysteem. En lear it om te reagearjen op prestaasjes en betrouberensproblemen. As der wat begjint te brekken, reagearje dan as d'r in bettere opsje is. Tagelyk is in direkte reaksje net kritysk, troch fallback op kliïnten.
Sa kinne de prinsipes fan systeemstipe as folgjend formulearre wurde:
- it ferminderjen fan de skaal fan breakdowns;
- sammeljen fan metriken;
- Wy reparearje automatysk storingen as wy kinne;
- as it net kin, melde wy jo;
- Wy wurkje oan dashboards en triage-ark foar rappe reaksje.
Lessen leard
It nimt net folle tiid om in prototype te skriuwen. Yn ús gefal wie it nei 4 moannen klear. Dêrmei krigen wy nije metriken, en 10 moannen nei it begjin fan ûntwikkeling krigen wy it earste produksjeferkear. Doe begon it ferfeelsume en heul lestige wurk: stadichoan produktisearje en skaal it systeem, migrearje it haadferkear en lear fan flaters. Dit effektive proses sil lykwols net lineêr wêze - nettsjinsteande alle ynspanningen kin alles net foarsizze. It is folle effektiver om fluch iterearje en reagearje op nije gegevens.
Op grûn fan ús ûnderfining kinne wy it folgjende oanbefelje:
- Fertrou jo yntuysje net.
Us yntuysje mislearre ús konstant, nettsjinsteande de grutte ûnderfining fan ús teamleden. Wy hawwe bygelyks de ferwachte fersnelling ferkeard foarsein troch it brûken fan in CDN-proxy, as it gedrach fan TCP Anycast.
- Krij gegevens fan produksje.
It is wichtich om sa rap mooglik tagong te krijen ta op syn minst in lyts bedrach fan produksjegegevens. It is hast ûnmooglik om it oantal unike gefallen, konfiguraasjes en ynstellingen te krijen yn laboratoariumbetingsten. Snelle tagong ta de resultaten sil jo fluch leare oer potensjele problemen en se yn 'e systeemarsjitektuer rekken hâlde.
- Folgje net advys en resultaten fan oaren - sammelje jo eigen gegevens.
Folgje de prinsipes foar it sammeljen en analysearjen fan gegevens, mar akseptearje net blyn de resultaten en útspraken fan oaren. Allinich kinne jo krekt witte wat wurket foar jo brûkers. Jo systemen en jo klanten kinne signifikant ferskille fan oare bedriuwen. Gelokkich binne analyse-ark no beskikber en maklik te brûken. De resultaten dy't jo krije binne miskien net wat Netflix, Facebook, Akamai en oare bedriuwen beweare. Yn ús gefal ferskilt de prestaasjes fan TLS, HTTP2 of statistiken oer DNS-oanfragen fan 'e resultaten fan Facebook, Uber, Akamai - om't wy ferskate apparaten, kliïnten en gegevensstreamen hawwe.
- Folgje moadetrends net unnedich en evaluearje de effektiviteit.
Begjin ienfâldich. It is better om in ienfâldich wurksysteem yn koarte tiid te meitsjen dan in enoarme tiid te besteegjen oan it ûntwikkeljen fan komponinten dy't jo net nedich binne. Los taken en problemen op dy't wichtich binne op basis fan jo mjittingen en resultaten.
- Meitsje jo klear foar nije applikaasjes.
Krekt sa't it lestich is om alle problemen te foarsizzen, is it lestich om de foardielen en tapassingen fan tefoaren te foarsizzen. Nim in oanwizing fan startups - har fermogen om oan te passen oan klantbetingsten. Yn jo gefal kinne jo nije problemen en har oplossingen ûntdekke. Yn ús projekt sette wy in doel om fersyk latency te ferminderjen. Tidens de analyze en diskusjes realisearren wy lykwols dat wy ek proxy-tsjinners kinne brûke:
- om ferkear oer AWS-regio's te balansearjen en kosten te ferminderjen;
- om CDN-stabiliteit te modellearjen;
- om DNS te konfigurearjen;
- om TLS/TCP te konfigurearjen.
konklúzje
Yn it rapport beskreau ik hoe't Netflix it probleem oplost fan it fersnellen fan ynternetoanfragen tusken kliïnten en de wolk. Hoe't wy sammelje gegevens mei help fan in sampling systeem op kliïnten, en brûk de sammele histoaryske gegevens foar in route produksje fersiken fan kliïnten fia de fluchste paad op it ynternet. Hoe't wy de prinsipes fan netwurkprotokollen, ús CDN-ynfrastruktuer, rêchbonkenetwurk, en DNS-tsjinners brûke om dizze taak te berikken.
Us oplossing is lykwols gewoan in foarbyld fan hoe't wy by Netflix sa'n systeem hawwe ymplementearre. Wat wurke foar ús. It tapaste diel fan myn rapport foar jo is de begjinsels fan ûntwikkeling en stipe dy't wy folgje en goede resultaten berikke.
Us oplossing foar it probleem past miskien net by jo. De teory en ûntwerpprinsipes bliuwe lykwols, sels as jo gjin eigen CDN-ynfrastruktuer hawwe, of as it signifikant ferskilt fan ús.
It belang fan 'e snelheid fan saaklike oanfragen bliuwt ek wichtich. En sels foar in ienfâldige tsjinst moatte jo in kar meitsje: tusken wolkproviders, serverlokaasje, CDN- en DNS-providers. Jo kar sil ynfloed hawwe op de effektiviteit fan ynternetfragen foar jo klanten. En it is wichtich foar jo om dizze ynfloed te mjitten en te begripen.
Begjin mei ienfâldige oplossingen, soarch oer hoe't jo it produkt feroarje. Learje as jo gean en ferbetterje it systeem basearre op gegevens fan jo klanten, jo ynfrastruktuer en jo bedriuw. Tink oan de mooglikheid fan ûnferwachte flaters tidens it ûntwerpproses. En dan kinne jo jo ûntwikkelingsproses fersnelle, effisjinsje fan oplossing ferbetterje, ûnnedige stipelêsten foarkomme en rêstich sliepe.
Dit jier yn online formaat. Jo kinne fragen stelle oan ien fan 'e heiten fan DevOps, John Willis sels!
Boarne: www.habr.com
