


ಒಂದೆರಡು ವರ್ಷಗಳ ಹಿಂದೆ ಕುಬರ್ನೆಟ್ಸ್ ಅಧಿಕೃತ GitHub ಬ್ಲಾಗ್ನಲ್ಲಿ. ಅಂದಿನಿಂದ, ಸೇವೆಗಳನ್ನು ನಿಯೋಜಿಸಲು ಇದು ಪ್ರಮಾಣಿತ ತಂತ್ರಜ್ಞಾನವಾಗಿದೆ. ಕುಬರ್ನೆಟ್ಸ್ ಈಗ ಆಂತರಿಕ ಮತ್ತು ಸಾರ್ವಜನಿಕ ಸೇವೆಗಳ ಗಮನಾರ್ಹ ಭಾಗವನ್ನು ನಿರ್ವಹಿಸುತ್ತಿದ್ದಾರೆ. ನಮ್ಮ ಕ್ಲಸ್ಟರ್ಗಳು ಬೆಳೆದಂತೆ ಮತ್ತು ಕಾರ್ಯಕ್ಷಮತೆಯ ಅಗತ್ಯತೆಗಳು ಹೆಚ್ಚು ಕಟ್ಟುನಿಟ್ಟಾಗುತ್ತಿದ್ದಂತೆ, ಕುಬರ್ನೆಟ್ಸ್ನಲ್ಲಿನ ಕೆಲವು ಸೇವೆಗಳು ವಿರಳವಾಗಿ ಲೇಟೆನ್ಸಿಯನ್ನು ಅನುಭವಿಸುತ್ತಿರುವುದನ್ನು ನಾವು ಗಮನಿಸಲು ಪ್ರಾರಂಭಿಸಿದ್ದೇವೆ ಅದನ್ನು ಅಪ್ಲಿಕೇಶನ್ನ ಲೋಡ್ನಿಂದ ವಿವರಿಸಲಾಗುವುದಿಲ್ಲ.
ಮೂಲಭೂತವಾಗಿ, ಅಪ್ಲಿಕೇಶನ್ಗಳು 100ms ಅಥವಾ ಅದಕ್ಕಿಂತ ಹೆಚ್ಚಿನ ಯಾದೃಚ್ಛಿಕ ನೆಟ್ವರ್ಕ್ ಲೇಟೆನ್ಸಿಯನ್ನು ಅನುಭವಿಸುತ್ತವೆ, ಇದು ಸಮಯ ಮೀರುವಿಕೆಗಳು ಅಥವಾ ಮರುಪ್ರಯತ್ನಗಳಿಗೆ ಕಾರಣವಾಗುತ್ತದೆ. ಸೇವೆಗಳು 100ms ಗಿಂತ ಹೆಚ್ಚು ವೇಗವಾಗಿ ವಿನಂತಿಗಳಿಗೆ ಪ್ರತಿಕ್ರಿಯಿಸಲು ಸಾಧ್ಯವಾಗುತ್ತದೆ ಎಂದು ನಿರೀಕ್ಷಿಸಲಾಗಿದೆ. ಆದರೆ ಸಂಪರ್ಕವು ತುಂಬಾ ಸಮಯ ತೆಗೆದುಕೊಂಡರೆ ಇದು ಅಸಾಧ್ಯ. ಪ್ರತ್ಯೇಕವಾಗಿ, ಮಿಲಿಸೆಕೆಂಡ್ಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಬೇಕಾದ ಅತ್ಯಂತ ವೇಗದ MySQL ಪ್ರಶ್ನೆಗಳನ್ನು ನಾವು ಗಮನಿಸಿದ್ದೇವೆ ಮತ್ತು MySQL ಮಿಲಿಸೆಕೆಂಡ್ಗಳಲ್ಲಿ ಪೂರ್ಣಗೊಂಡಿತು, ಆದರೆ ವಿನಂತಿಸುವ ಅಪ್ಲಿಕೇಶನ್ನ ದೃಷ್ಟಿಕೋನದಿಂದ, ಪ್ರತಿಕ್ರಿಯೆಯು 100 ms ಅಥವಾ ಹೆಚ್ಚಿನ ಸಮಯವನ್ನು ತೆಗೆದುಕೊಂಡಿತು.
ಕುಬರ್ನೆಟ್ಸ್ ಹೊರಗಿನಿಂದ ಕರೆ ಬಂದಿದ್ದರೂ ಸಹ, ಕುಬರ್ನೆಟ್ಸ್ ನೋಡ್ಗೆ ಸಂಪರ್ಕಿಸುವಾಗ ಮಾತ್ರ ಸಮಸ್ಯೆ ಸಂಭವಿಸಿದೆ ಎಂಬುದು ತಕ್ಷಣವೇ ಸ್ಪಷ್ಟವಾಯಿತು. ಸಮಸ್ಯೆಯನ್ನು ಪುನರುತ್ಪಾದಿಸಲು ಸುಲಭವಾದ ಮಾರ್ಗವೆಂದರೆ ಪರೀಕ್ಷೆ , ಇದು ಯಾವುದೇ ಆಂತರಿಕ ಹೋಸ್ಟ್ನಿಂದ ಚಲಿಸುತ್ತದೆ, ನಿರ್ದಿಷ್ಟ ಪೋರ್ಟ್ನಲ್ಲಿ ಕುಬರ್ನೆಟ್ಸ್ ಸೇವೆಯನ್ನು ಪರೀಕ್ಷಿಸುತ್ತದೆ ಮತ್ತು ಆಗಾಗ್ಗೆ ಹೆಚ್ಚಿನ ಸುಪ್ತತೆಯನ್ನು ನೋಂದಾಯಿಸುತ್ತದೆ. ಈ ಲೇಖನದಲ್ಲಿ, ಈ ಸಮಸ್ಯೆಯ ಕಾರಣವನ್ನು ನಾವು ಹೇಗೆ ಪತ್ತೆಹಚ್ಚಲು ಸಾಧ್ಯವಾಯಿತು ಎಂಬುದನ್ನು ನಾವು ನೋಡುತ್ತೇವೆ.
ವೈಫಲ್ಯಕ್ಕೆ ಕಾರಣವಾಗುವ ಸರಪಳಿಯಲ್ಲಿ ಅನಗತ್ಯ ಸಂಕೀರ್ಣತೆಯನ್ನು ತೆಗೆದುಹಾಕುವುದು
ಅದೇ ಉದಾಹರಣೆಯನ್ನು ಪುನರಾವರ್ತಿಸುವ ಮೂಲಕ, ನಾವು ಸಮಸ್ಯೆಯ ಗಮನವನ್ನು ಕಿರಿದಾಗಿಸಲು ಮತ್ತು ಸಂಕೀರ್ಣತೆಯ ಅನಗತ್ಯ ಪದರಗಳನ್ನು ತೆಗೆದುಹಾಕಲು ಬಯಸುತ್ತೇವೆ. ಆರಂಭದಲ್ಲಿ, ವೆಜಿಟಾ ಮತ್ತು ಕುಬರ್ನೆಟ್ಸ್ ಪಾಡ್ಗಳ ನಡುವಿನ ಹರಿವಿನಲ್ಲಿ ಹಲವು ಅಂಶಗಳಿದ್ದವು. ಆಳವಾದ ನೆಟ್ವರ್ಕ್ ಸಮಸ್ಯೆಯನ್ನು ಗುರುತಿಸಲು, ಅವುಗಳಲ್ಲಿ ಕೆಲವನ್ನು ನೀವು ತಳ್ಳಿಹಾಕಬೇಕಾಗುತ್ತದೆ.
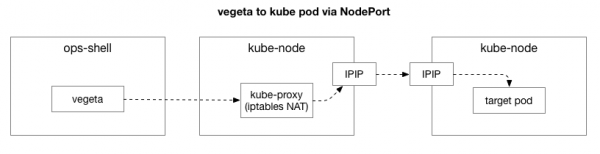
ಕ್ಲೈಂಟ್ (ವೆಜಿಟಾ) ಕ್ಲಸ್ಟರ್ನಲ್ಲಿನ ಯಾವುದೇ ನೋಡ್ನೊಂದಿಗೆ TCP ಸಂಪರ್ಕವನ್ನು ರಚಿಸುತ್ತದೆ. ಕುಬರ್ನೆಟ್ಸ್ ಓವರ್ಲೇ ನೆಟ್ವರ್ಕ್ ಆಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ (ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಡೇಟಾ ಸೆಂಟರ್ ನೆಟ್ವರ್ಕ್ನ ಮೇಲೆ) ಅದನ್ನು ಬಳಸುತ್ತದೆ , ಅಂದರೆ, ಇದು ಡೇಟಾ ಸೆಂಟರ್ನ IP ಪ್ಯಾಕೆಟ್ಗಳ ಒಳಗೆ ಓವರ್ಲೇ ನೆಟ್ವರ್ಕ್ನ IP ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಆವರಿಸುತ್ತದೆ. ಮೊದಲ ನೋಡ್ಗೆ ಸಂಪರ್ಕಿಸುವಾಗ, ನೆಟ್ವರ್ಕ್ ವಿಳಾಸ ಅನುವಾದವನ್ನು ನಿರ್ವಹಿಸಲಾಗುತ್ತದೆ (NAT) ಕುಬರ್ನೆಟ್ಸ್ ನೋಡ್ನ IP ವಿಳಾಸ ಮತ್ತು ಪೋರ್ಟ್ ಅನ್ನು ಓವರ್ಲೇ ನೆಟ್ವರ್ಕ್ನಲ್ಲಿರುವ IP ವಿಳಾಸ ಮತ್ತು ಪೋರ್ಟ್ಗೆ ಭಾಷಾಂತರಿಸಲು (ನಿರ್ದಿಷ್ಟವಾಗಿ, ಅಪ್ಲಿಕೇಶನ್ನೊಂದಿಗೆ ಪಾಡ್). ಒಳಬರುವ ಪ್ಯಾಕೆಟ್ಗಳಿಗಾಗಿ, ಕ್ರಿಯೆಗಳ ಹಿಮ್ಮುಖ ಅನುಕ್ರಮವನ್ನು ನಿರ್ವಹಿಸಲಾಗುತ್ತದೆ. ಇದು ಸಾಕಷ್ಟು ರಾಜ್ಯ ಮತ್ತು ಅನೇಕ ಅಂಶಗಳನ್ನು ಹೊಂದಿರುವ ಸಂಕೀರ್ಣ ವ್ಯವಸ್ಥೆಯಾಗಿದ್ದು, ಸೇವೆಗಳನ್ನು ನಿಯೋಜಿಸಿ ಮತ್ತು ಸ್ಥಳಾಂತರಿಸಿದಂತೆ ನಿರಂತರವಾಗಿ ನವೀಕರಿಸಲಾಗುತ್ತದೆ ಮತ್ತು ಬದಲಾಯಿಸಲಾಗುತ್ತದೆ.
ಉಪಯುಕ್ತತೆ tcpdump ವೆಜಿಟಾ ಪರೀಕ್ಷೆಯಲ್ಲಿ TCP ಹ್ಯಾಂಡ್ಶೇಕ್ ಸಮಯದಲ್ಲಿ ವಿಳಂಬವಾಗಿದೆ (SYN ಮತ್ತು SYN-ACK ನಡುವೆ). ಈ ಅನಗತ್ಯ ಸಂಕೀರ್ಣತೆಯನ್ನು ತೆಗೆದುಹಾಕಲು, ನೀವು ಬಳಸಬಹುದು hping3 SYN ಪ್ಯಾಕೆಟ್ಗಳೊಂದಿಗೆ ಸರಳವಾದ "ಪಿಂಗ್ಗಳು" ಗಾಗಿ. ಪ್ರತಿಕ್ರಿಯೆ ಪ್ಯಾಕೆಟ್ನಲ್ಲಿ ವಿಳಂಬವಿದೆಯೇ ಎಂದು ನಾವು ಪರಿಶೀಲಿಸುತ್ತೇವೆ ಮತ್ತು ನಂತರ ಸಂಪರ್ಕವನ್ನು ಮರುಹೊಂದಿಸಿ. ನಾವು 100ms ಗಿಂತ ಹೆಚ್ಚಿನ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಮಾತ್ರ ಸೇರಿಸಲು ಡೇಟಾವನ್ನು ಫಿಲ್ಟರ್ ಮಾಡಬಹುದು ಮತ್ತು Vegeta ನ ಪೂರ್ಣ ನೆಟ್ವರ್ಕ್ ಲೇಯರ್ 7 ಪರೀಕ್ಷೆಗಿಂತ ಸಮಸ್ಯೆಯನ್ನು ಪುನರುತ್ಪಾದಿಸಲು ಸುಲಭವಾದ ಮಾರ್ಗವನ್ನು ಪಡೆಯಬಹುದು. 30927ms ಮಧ್ಯಂತರದಲ್ಲಿ "ನೋಡ್ ಪೋರ್ಟ್" (10) ಸೇವೆಯಲ್ಲಿ TCP SYN/SYN-ACK ಅನ್ನು ಬಳಸುವ ಕುಬರ್ನೆಟ್ಸ್ ನೋಡ್ "ಪಿಂಗ್ಗಳು" ಇಲ್ಲಿವೆ, ನಿಧಾನವಾದ ಪ್ರತಿಕ್ರಿಯೆಗಳಿಂದ ಫಿಲ್ಟರ್ ಮಾಡಲಾಗಿದೆ:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=1485 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=127.1 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=1486 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=117.0 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=1487 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=106.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=1488 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=104.1 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=5024 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=109.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=59 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=30927 ಫ್ಲ್ಯಾಗ್ಗಳು=ಎಸ್ಎ ಸೆಕ್=5231 ಗೆಲುವು=29200 ಆರ್ಟಿಟಿ=109.2 ಎಂಎಸ್
ತಕ್ಷಣವೇ ಮೊದಲ ವೀಕ್ಷಣೆಯನ್ನು ಮಾಡಬಹುದು. ಅನುಕ್ರಮ ಸಂಖ್ಯೆಗಳು ಮತ್ತು ಸಮಯಗಳ ಮೂಲಕ ನಿರ್ಣಯಿಸುವುದು, ಇವು ಒಂದೇ ಬಾರಿ ದಟ್ಟಣೆಗಳಲ್ಲ ಎಂಬುದು ಸ್ಪಷ್ಟವಾಗುತ್ತದೆ. ವಿಳಂಬವು ಹೆಚ್ಚಾಗಿ ಸಂಗ್ರಹಗೊಳ್ಳುತ್ತದೆ ಮತ್ತು ಅಂತಿಮವಾಗಿ ಪ್ರಕ್ರಿಯೆಗೊಳ್ಳುತ್ತದೆ.
ಮುಂದೆ, ದಟ್ಟಣೆಯ ಸಂಭವದಲ್ಲಿ ಯಾವ ಘಟಕಗಳು ಭಾಗಿಯಾಗಿರಬಹುದು ಎಂಬುದನ್ನು ನಾವು ಕಂಡುಹಿಡಿಯಲು ಬಯಸುತ್ತೇವೆ. ಬಹುಶಃ ಇದು NAT ನಲ್ಲಿರುವ ನೂರಾರು iptables ನಿಯಮಗಳಲ್ಲಿ ಕೆಲವು? ಅಥವಾ ನೆಟ್ವರ್ಕ್ನಲ್ಲಿ IPIP ಟನೆಲಿಂಗ್ನಲ್ಲಿ ಯಾವುದೇ ಸಮಸ್ಯೆಗಳಿವೆಯೇ? ಇದನ್ನು ಪರಿಶೀಲಿಸಲು ಒಂದು ಮಾರ್ಗವೆಂದರೆ ಸಿಸ್ಟಮ್ನ ಪ್ರತಿ ಹಂತವನ್ನು ತೆಗೆದುಹಾಕುವ ಮೂಲಕ ಪರೀಕ್ಷಿಸುವುದು. ನೀವು NAT ಮತ್ತು ಫೈರ್ವಾಲ್ ಲಾಜಿಕ್ ಅನ್ನು ತೆಗೆದುಹಾಕಿದರೆ ಏನಾಗುತ್ತದೆ, IPIP ಭಾಗವನ್ನು ಮಾತ್ರ ಬಿಟ್ಟುಬಿಡುತ್ತದೆ:
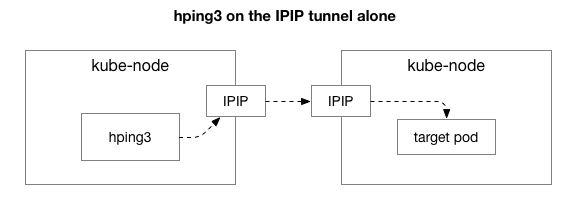
ಅದೃಷ್ಟವಶಾತ್, Linux ಯಂತ್ರವು ಒಂದೇ ನೆಟ್ವರ್ಕ್ನಲ್ಲಿದ್ದರೆ, IP ಓವರ್ಲೇ ಲೇಯರ್ ಅನ್ನು ನೇರವಾಗಿ ಸುಲಭವಾಗಿ ಪ್ರವೇಶಿಸಲು ನಿಮಗೆ ಅನುಮತಿಸುತ್ತದೆ:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
ಲೆನ್=40 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=0 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=7346 ವಿನ್=0 ಆರ್ಟಿಟಿ=127.3 ಎಂಎಸ್
ಲೆನ್=40 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=0 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=7347 ವಿನ್=0 ಆರ್ಟಿಟಿ=117.3 ಎಂಎಸ್
ಲೆನ್=40 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=0 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=7348 ವಿನ್=0 ಆರ್ಟಿಟಿ=107.2 ಎಂಎಸ್
ಫಲಿತಾಂಶಗಳ ಮೂಲಕ ನಿರ್ಣಯಿಸುವುದು, ಸಮಸ್ಯೆ ಇನ್ನೂ ಉಳಿದಿದೆ! ಇದು iptables ಮತ್ತು NAT ಅನ್ನು ಹೊರತುಪಡಿಸುತ್ತದೆ. ಹಾಗಾದರೆ ಸಮಸ್ಯೆ TCP ಆಗಿದೆಯೇ? ಸಾಮಾನ್ಯ ICMP ಪಿಂಗ್ ಹೇಗೆ ಹೋಗುತ್ತದೆ ಎಂದು ನೋಡೋಣ:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=42594 ಐಸಿಎಂಪಿ_ಸೆಕ್=104 ಆರ್ಟಿಟಿ=110.0 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=49448 ಐಸಿಎಂಪಿ_ಸೆಕ್=4022 ಆರ್ಟಿಟಿ=141.3 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=49449 ಐಸಿಎಂಪಿ_ಸೆಕ್=4023 ಆರ್ಟಿಟಿ=131.3 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=49450 ಐಸಿಎಂಪಿ_ಸೆಕ್=4024 ಆರ್ಟಿಟಿ=121.2 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=49451 ಐಸಿಎಂಪಿ_ಸೆಕ್=4025 ಆರ್ಟಿಟಿ=111.2 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=49452 ಐಸಿಎಂಪಿ_ಸೆಕ್=4026 ಆರ್ಟಿಟಿ=101.1 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=50023 ಐಸಿಎಂಪಿ_ಸೆಕ್=4343 ಆರ್ಟಿಟಿ=126.8 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=50024 ಐಸಿಎಂಪಿ_ಸೆಕ್=4344 ಆರ್ಟಿಟಿ=116.8 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=50025 ಐಸಿಎಂಪಿ_ಸೆಕ್=4345 ಆರ್ಟಿಟಿ=106.8 ಎಂಎಸ್
ಲೆನ್=28 ಐಪಿ=10.125.20.64 ಟಿಟಿಎಲ್=64 ಐಡಿ=59727 ಐಸಿಎಂಪಿ_ಸೆಕ್=9836 ಆರ್ಟಿಟಿ=106.1 ಎಂಎಸ್
ಸಮಸ್ಯೆ ದೂರವಾಗಿಲ್ಲ ಎಂದು ಫಲಿತಾಂಶಗಳು ತೋರಿಸುತ್ತವೆ. ಬಹುಶಃ ಇದು ಐಪಿಐಪಿ ಸುರಂಗವೇ? ಪರೀಕ್ಷೆಯನ್ನು ಮತ್ತಷ್ಟು ಸರಳಗೊಳಿಸೋಣ:
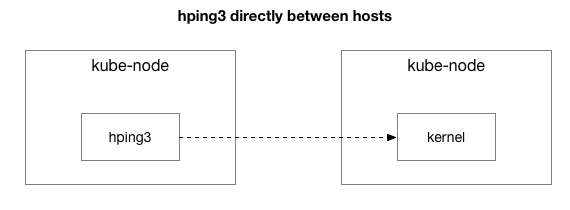
ಎಲ್ಲಾ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಈ ಎರಡು ಹೋಸ್ಟ್ಗಳ ನಡುವೆ ಕಳುಹಿಸಲಾಗಿದೆಯೇ?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=41127 ಐಸಿಎಂಪಿ_ಸೆಕ್=12564 ಆರ್ಟಿಟಿ=140.9 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=41128 ಐಸಿಎಂಪಿ_ಸೆಕ್=12565 ಆರ್ಟಿಟಿ=130.9 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=41129 ಐಸಿಎಂಪಿ_ಸೆಕ್=12566 ಆರ್ಟಿಟಿ=120.8 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=41130 ಐಸಿಎಂಪಿ_ಸೆಕ್=12567 ಆರ್ಟಿಟಿ=110.8 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=41131 ಐಸಿಎಂಪಿ_ಸೆಕ್=12568 ಆರ್ಟಿಟಿ=100.7 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=9062 ಐಸಿಎಂಪಿ_ಸೆಕ್=31443 ಆರ್ಟಿಟಿ=134.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=9063 ಐಸಿಎಂಪಿ_ಸೆಕ್=31444 ಆರ್ಟಿಟಿ=124.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=9064 ಐಸಿಎಂಪಿ_ಸೆಕ್=31445 ಆರ್ಟಿಟಿ=114.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಐಡಿ=9065 ಐಸಿಎಂಪಿ_ಸೆಕ್=31446 ಆರ್ಟಿಟಿ=104.2 ಎಂಎಸ್
ನಾವು ಪರಿಸ್ಥಿತಿಯನ್ನು ಎರಡು Kubernetes ನೋಡ್ಗಳಿಗೆ ಸರಳಗೊಳಿಸಿದ್ದೇವೆ, ಪರಸ್ಪರ ಯಾವುದೇ ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಕಳುಹಿಸುತ್ತೇವೆ, ICMP ಪಿಂಗ್ ಕೂಡ. ಟಾರ್ಗೆಟ್ ಹೋಸ್ಟ್ "ಕೆಟ್ಟ" (ಕೆಲವು ಇತರರಿಗಿಂತ ಕೆಟ್ಟದಾಗಿದೆ) ಆಗಿದ್ದರೆ ಅವರು ಇನ್ನೂ ಸುಪ್ತತೆಯನ್ನು ನೋಡುತ್ತಾರೆ.
ಈಗ ಕೊನೆಯ ಪ್ರಶ್ನೆ: ಕ್ಯೂಬ್-ನೋಡ್ ಸರ್ವರ್ಗಳಲ್ಲಿ ಮಾತ್ರ ವಿಳಂಬ ಏಕೆ ಸಂಭವಿಸುತ್ತದೆ? ಮತ್ತು kube-node ಕಳುಹಿಸುವವರು ಅಥವಾ ಸ್ವೀಕರಿಸುವವರಾಗಿದ್ದರೆ ಅದು ಸಂಭವಿಸುತ್ತದೆಯೇ? ಅದೃಷ್ಟವಶಾತ್, ಕುಬರ್ನೆಟ್ಸ್ನ ಹೊರಗಿನ ಹೋಸ್ಟ್ನಿಂದ ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಕಳುಹಿಸುವ ಮೂಲಕ ಇದನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುವುದು ತುಂಬಾ ಸುಲಭ, ಆದರೆ ಅದೇ "ತಿಳಿದಿರುವ ಕೆಟ್ಟ" ಸ್ವೀಕರಿಸುವವರೊಂದಿಗೆ. ನೀವು ನೋಡುವಂತೆ, ಸಮಸ್ಯೆ ಕಣ್ಮರೆಯಾಗಿಲ್ಲ:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=9876 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=312 ವಿನ್=0 ಆರ್ಟಿಟಿ=108.5 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=9876 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=5903 ವಿನ್=0 ಆರ್ಟಿಟಿ=119.4 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=9876 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=6227 ವಿನ್=0 ಆರ್ಟಿಟಿ=139.9 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.47.27 ಟಿಟಿಎಲ್=61 ಡಿಎಫ್ ಐಡಿ=0 ಸ್ಪೋರ್ಟ್=9876 ಫ್ಲ್ಯಾಗ್ಗಳು=ಆರ್ಎ ಸೆಕ್=7929 ವಿನ್=0 ಆರ್ಟಿಟಿ=131.2 ಎಂಎಸ್
ನಂತರ ನಾವು ಹಿಂದಿನ ಮೂಲ ಕ್ಯೂಬ್-ನೋಡ್ನಿಂದ ಬಾಹ್ಯ ಹೋಸ್ಟ್ಗೆ ಅದೇ ವಿನಂತಿಗಳನ್ನು ರನ್ ಮಾಡುತ್ತೇವೆ (ಇದು ಮೂಲ ಹೋಸ್ಟ್ ಅನ್ನು ಹೊರತುಪಡಿಸುತ್ತದೆ ಏಕೆಂದರೆ ಪಿಂಗ್ RX ಮತ್ತು TX ಘಟಕಗಳನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
ಲೇಟೆನ್ಸಿ ಪ್ಯಾಕೆಟ್ ಕ್ಯಾಪ್ಚರ್ಗಳನ್ನು ಪರಿಶೀಲಿಸುವ ಮೂಲಕ, ನಾವು ಕೆಲವು ಹೆಚ್ಚುವರಿ ಮಾಹಿತಿಯನ್ನು ಪಡೆದುಕೊಂಡಿದ್ದೇವೆ. ನಿರ್ದಿಷ್ಟವಾಗಿ ಹೇಳುವುದಾದರೆ, ಕಳುಹಿಸುವವರು (ಕೆಳಭಾಗ) ಈ ಸಮಯ ಮೀರುವಿಕೆಯನ್ನು ನೋಡುತ್ತಾರೆ, ಆದರೆ ಸ್ವೀಕರಿಸುವವರು (ಮೇಲ್ಭಾಗ) ನೋಡುವುದಿಲ್ಲ - ಡೆಲ್ಟಾ ಕಾಲಮ್ (ಸೆಕೆಂಡ್ಗಳಲ್ಲಿ):
ಹೆಚ್ಚುವರಿಯಾಗಿ, ನೀವು ಸ್ವೀಕರಿಸುವವರ ಬದಿಯಲ್ಲಿ TCP ಮತ್ತು ICMP ಪ್ಯಾಕೆಟ್ಗಳ ಕ್ರಮದಲ್ಲಿನ ವ್ಯತ್ಯಾಸವನ್ನು (ಅನುಕ್ರಮ ಸಂಖ್ಯೆಗಳ ಮೂಲಕ) ನೋಡಿದರೆ, ICMP ಪ್ಯಾಕೆಟ್ಗಳು ಯಾವಾಗಲೂ ಕಳುಹಿಸಲಾದ ಅದೇ ಅನುಕ್ರಮದಲ್ಲಿ ಬರುತ್ತವೆ, ಆದರೆ ವಿಭಿನ್ನ ಸಮಯದೊಂದಿಗೆ. ಅದೇ ಸಮಯದಲ್ಲಿ, TCP ಪ್ಯಾಕೆಟ್ಗಳು ಕೆಲವೊಮ್ಮೆ ಇಂಟರ್ಲೀವ್ ಆಗುತ್ತವೆ ಮತ್ತು ಅವುಗಳಲ್ಲಿ ಕೆಲವು ಸಿಲುಕಿಕೊಳ್ಳುತ್ತವೆ. ನಿರ್ದಿಷ್ಟವಾಗಿ ಹೇಳುವುದಾದರೆ, ನೀವು SYN ಪ್ಯಾಕೆಟ್ಗಳ ಪೋರ್ಟ್ಗಳನ್ನು ಪರಿಶೀಲಿಸಿದರೆ, ಅವು ಕಳುಹಿಸುವವರ ಬದಿಯಲ್ಲಿ ಕ್ರಮವಾಗಿರುತ್ತವೆ, ಆದರೆ ಸ್ವೀಕರಿಸುವವರ ಬದಿಯಲ್ಲಿಲ್ಲ.
ಹೇಗೆ ಎಂಬುದರಲ್ಲಿ ಸೂಕ್ಷ್ಮ ವ್ಯತ್ಯಾಸವಿದೆ ಆಧುನಿಕ ಸರ್ವರ್ಗಳು (ನಮ್ಮ ಡೇಟಾ ಕೇಂದ್ರದಲ್ಲಿರುವಂತೆ) TCP ಅಥವಾ ICMP ಹೊಂದಿರುವ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತವೆ. ಪ್ಯಾಕೆಟ್ ಬಂದಾಗ, ನೆಟ್ವರ್ಕ್ ಅಡಾಪ್ಟರ್ "ಪ್ರತಿ ಸಂಪರ್ಕಕ್ಕೆ ಹ್ಯಾಶ್ ಮಾಡುತ್ತದೆ", ಅಂದರೆ, ಇದು ಸಂಪರ್ಕಗಳನ್ನು ಸರತಿಯಲ್ಲಿ ಒಡೆಯಲು ಪ್ರಯತ್ನಿಸುತ್ತದೆ ಮತ್ತು ಪ್ರತಿ ಕ್ಯೂ ಅನ್ನು ಪ್ರತ್ಯೇಕ ಪ್ರೊಸೆಸರ್ ಕೋರ್ಗೆ ಕಳುಹಿಸುತ್ತದೆ. TCP ಗಾಗಿ, ಈ ಹ್ಯಾಶ್ ಮೂಲ ಮತ್ತು ಗಮ್ಯಸ್ಥಾನ IP ವಿಳಾಸ ಮತ್ತು ಪೋರ್ಟ್ ಎರಡನ್ನೂ ಒಳಗೊಂಡಿದೆ. ಬೇರೆ ರೀತಿಯಲ್ಲಿ ಹೇಳುವುದಾದರೆ, ಪ್ರತಿ ಸಂಪರ್ಕವನ್ನು ಹ್ಯಾಶ್ ಮಾಡಲಾಗಿದೆ (ಸಂಭಾವ್ಯವಾಗಿ) ವಿಭಿನ್ನವಾಗಿ. ICMP ಗಾಗಿ, ಯಾವುದೇ ಪೋರ್ಟ್ಗಳಿಲ್ಲದ ಕಾರಣ IP ವಿಳಾಸಗಳನ್ನು ಮಾತ್ರ ಹ್ಯಾಶ್ ಮಾಡಲಾಗಿದೆ.
ಮತ್ತೊಂದು ಹೊಸ ಅವಲೋಕನ: ಈ ಅವಧಿಯಲ್ಲಿ ನಾವು ಎರಡು ಹೋಸ್ಟ್ಗಳ ನಡುವಿನ ಎಲ್ಲಾ ಸಂವಹನಗಳಲ್ಲಿ ICMP ವಿಳಂಬಗಳನ್ನು ನೋಡುತ್ತೇವೆ, ಆದರೆ TCP ಮಾಡುವುದಿಲ್ಲ. ಕಾರಣವು RX ಕ್ಯೂ ಹ್ಯಾಶಿಂಗ್ಗೆ ಸಂಬಂಧಿಸಿದೆ ಎಂದು ಇದು ನಮಗೆ ಹೇಳುತ್ತದೆ: ದಟ್ಟಣೆಯು ಬಹುತೇಕ RX ಪ್ಯಾಕೆಟ್ಗಳ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿದೆಯೇ ಹೊರತು ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ಕಳುಹಿಸುವಲ್ಲಿ ಅಲ್ಲ.
ಸಂಭವನೀಯ ಕಾರಣಗಳ ಪಟ್ಟಿಯಿಂದ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಕಳುಹಿಸುವುದನ್ನು ಇದು ತೆಗೆದುಹಾಕುತ್ತದೆ. ಪ್ಯಾಕೆಟ್ ಸಂಸ್ಕರಣೆಯ ಸಮಸ್ಯೆಯು ಕೆಲವು ಕ್ಯೂಬ್-ನೋಡ್ ಸರ್ವರ್ಗಳಲ್ಲಿ ಸ್ವೀಕರಿಸುವ ಬದಿಯಲ್ಲಿದೆ ಎಂದು ನಮಗೆ ಈಗ ತಿಳಿದಿದೆ.
ಕರ್ನಲ್ನಲ್ಲಿ ಪ್ಯಾಕೆಟ್ ಸಂಸ್ಕರಣೆಯನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು Linux
ಕೆಲವು ಕ್ಯೂಬ್-ನೋಡ್ ಸರ್ವರ್ಗಳಲ್ಲಿ ರಿಸೀವರ್ನಲ್ಲಿ ಸಮಸ್ಯೆ ಏಕೆ ಸಂಭವಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು, ಕರ್ನಲ್ ಹೇಗೆ ಸಂಭವಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ನೋಡೋಣ Linux ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ.
ಸರಳವಾದ ಸಾಂಪ್ರದಾಯಿಕ ಅನುಷ್ಠಾನಕ್ಕೆ ಹಿಂತಿರುಗಿ, ನೆಟ್ವರ್ಕ್ ಕಾರ್ಡ್ ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಸ್ವೀಕರಿಸುತ್ತದೆ ಮತ್ತು ಕಳುಹಿಸುತ್ತದೆ ಕೋರ್ Linuxಪ್ರಕ್ರಿಯೆಗೊಳಿಸಬೇಕಾದ ಪ್ಯಾಕೆಟ್ ಇದೆ ಎಂದು. ಕರ್ನಲ್ ಇತರ ಕೆಲಸಗಳನ್ನು ನಿಲ್ಲಿಸುತ್ತದೆ, ಸಂದರ್ಭವನ್ನು ಅಡಚಣೆ ಹ್ಯಾಂಡ್ಲರ್ಗೆ ಬದಲಾಯಿಸುತ್ತದೆ, ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ನಂತರ ಪ್ರಸ್ತುತ ಕಾರ್ಯಗಳಿಗೆ ಹಿಂತಿರುಗುತ್ತದೆ.
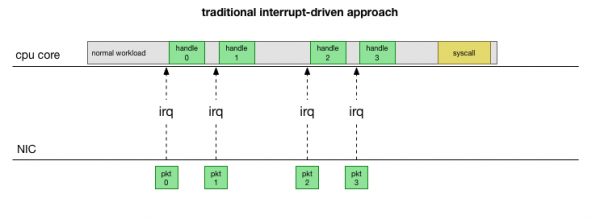
ಈ ಸಂದರ್ಭ ಸ್ವಿಚಿಂಗ್ ನಿಧಾನವಾಗಿದೆ: 10 ರ ದಶಕದಲ್ಲಿ 90Mbps ನೆಟ್ವರ್ಕ್ ಕಾರ್ಡ್ಗಳಲ್ಲಿ ಲೇಟೆನ್ಸಿ ಗಮನಿಸದೇ ಇರಬಹುದು, ಆದರೆ ಆಧುನಿಕ 10G ಕಾರ್ಡ್ಗಳಲ್ಲಿ ಸೆಕೆಂಡಿಗೆ 15 ಮಿಲಿಯನ್ ಪ್ಯಾಕೆಟ್ಗಳ ಗರಿಷ್ಠ ಥ್ರೋಪುಟ್ನೊಂದಿಗೆ, ಸಣ್ಣ ಎಂಟು-ಕೋರ್ ಸರ್ವರ್ನ ಪ್ರತಿ ಕೋರ್ಗೆ ಲಕ್ಷಾಂತರ ಅಡ್ಡಿಯಾಗಬಹುದು ಪ್ರತಿ ಸೆಕೆಂಡಿಗೆ ಬಾರಿ.
ಹಲವು ವರ್ಷಗಳ ಹಿಂದೆ, ನಿರಂತರವಾಗಿ ಅಡಚಣೆಗಳನ್ನು ನಿರ್ವಹಿಸುವುದನ್ನು ತಪ್ಪಿಸಲು Linux ಸೇರಿಸಲಾಗಿದೆ : ಹೆಚ್ಚಿನ ವೇಗದಲ್ಲಿ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಸುಧಾರಿಸಲು ಎಲ್ಲಾ ಆಧುನಿಕ ಚಾಲಕರು ಬಳಸುವ ನೆಟ್ವರ್ಕ್ API. ಕಡಿಮೆ ವೇಗದಲ್ಲಿ ಕರ್ನಲ್ ಇನ್ನೂ ಹಳೆಯ ರೀತಿಯಲ್ಲಿ ನೆಟ್ವರ್ಕ್ ಕಾರ್ಡ್ನಿಂದ ಅಡಚಣೆಗಳನ್ನು ಪಡೆಯುತ್ತದೆ. ಮಿತಿಯನ್ನು ಮೀರಿದ ಸಾಕಷ್ಟು ಪ್ಯಾಕೆಟ್ಗಳು ಒಮ್ಮೆ ಬಂದರೆ, ಕರ್ನಲ್ ಅಡಚಣೆಗಳನ್ನು ನಿಷ್ಕ್ರಿಯಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ಬದಲಿಗೆ ನೆಟ್ವರ್ಕ್ ಅಡಾಪ್ಟರ್ ಅನ್ನು ಪೋಲಿಂಗ್ ಮಾಡಲು ಪ್ರಾರಂಭಿಸುತ್ತದೆ ಮತ್ತು ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ತುಂಡುಗಳಾಗಿ ಎತ್ತಿಕೊಳ್ಳುತ್ತದೆ. ಸಂಸ್ಕರಣೆಯನ್ನು softirq ನಲ್ಲಿ ನಡೆಸಲಾಗುತ್ತದೆ, ಅಂದರೆ, in ಸಿಸ್ಟಮ್ ಕರೆಗಳು ಮತ್ತು ಹಾರ್ಡ್ವೇರ್ ಅಡಚಣೆಗಳ ನಂತರ, ಕರ್ನಲ್ (ಬಳಕೆದಾರರ ಜಾಗಕ್ಕೆ ವಿರುದ್ಧವಾಗಿ) ಈಗಾಗಲೇ ಚಾಲನೆಯಲ್ಲಿರುವಾಗ.
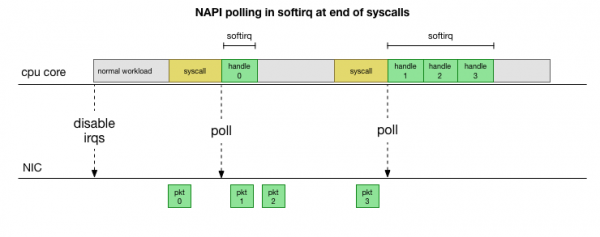
ಇದು ಹೆಚ್ಚು ವೇಗವಾಗಿರುತ್ತದೆ, ಆದರೆ ವಿಭಿನ್ನ ಸಮಸ್ಯೆಯನ್ನು ಉಂಟುಮಾಡುತ್ತದೆ. ಹಲವಾರು ಪ್ಯಾಕೆಟ್ಗಳಿದ್ದರೆ, ನೆಟ್ವರ್ಕ್ ಕಾರ್ಡ್ನಿಂದ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಲು ಸಾರ್ವಕಾಲಿಕ ಸಮಯವನ್ನು ಕಳೆಯಲಾಗುತ್ತದೆ ಮತ್ತು ಬಳಕೆದಾರರ ಸ್ಥಳ ಪ್ರಕ್ರಿಯೆಗಳು ಈ ಸಾಲುಗಳನ್ನು ನಿಜವಾಗಿ ಖಾಲಿ ಮಾಡಲು ಸಮಯ ಹೊಂದಿಲ್ಲ (ಟಿಸಿಪಿ ಸಂಪರ್ಕಗಳಿಂದ ಓದುವುದು, ಇತ್ಯಾದಿ.). ಅಂತಿಮವಾಗಿ ಸಾಲುಗಳು ತುಂಬುತ್ತವೆ ಮತ್ತು ನಾವು ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಬಿಡಲು ಪ್ರಾರಂಭಿಸುತ್ತೇವೆ. ಸಮತೋಲನವನ್ನು ಕಂಡುಹಿಡಿಯುವ ಪ್ರಯತ್ನದಲ್ಲಿ, softirq ಸಂದರ್ಭದಲ್ಲಿ ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಲಾದ ಗರಿಷ್ಠ ಸಂಖ್ಯೆಯ ಪ್ಯಾಕೆಟ್ಗಳಿಗೆ ಕರ್ನಲ್ ಬಜೆಟ್ ಅನ್ನು ಹೊಂದಿಸುತ್ತದೆ. ಈ ಬಜೆಟ್ ಮೀರಿದಾಗ, ಪ್ರತ್ಯೇಕ ಎಳೆಯನ್ನು ಜಾಗೃತಗೊಳಿಸಲಾಗುತ್ತದೆ ksoftirqd (ನೀವು ಅವುಗಳಲ್ಲಿ ಒಂದನ್ನು ನೋಡುತ್ತೀರಿ ps ಪ್ರತಿ ಕೋರ್) ಇದು ಸಾಮಾನ್ಯ ಸಿಸ್ಕಾಲ್/ಇಂಟರಪ್ಟ್ ಮಾರ್ಗದ ಹೊರಗೆ ಈ ಸಾಫ್ಟ್ಇರ್ಕ್ಗಳನ್ನು ನಿರ್ವಹಿಸುತ್ತದೆ. ಈ ಥ್ರೆಡ್ ಅನ್ನು ಪ್ರಮಾಣಿತ ಪ್ರಕ್ರಿಯೆ ಶೆಡ್ಯೂಲರ್ ಅನ್ನು ಬಳಸಿಕೊಂಡು ನಿಗದಿಪಡಿಸಲಾಗಿದೆ, ಇದು ಸಂಪನ್ಮೂಲಗಳನ್ನು ನ್ಯಾಯಯುತವಾಗಿ ನಿಯೋಜಿಸಲು ಪ್ರಯತ್ನಿಸುತ್ತದೆ.
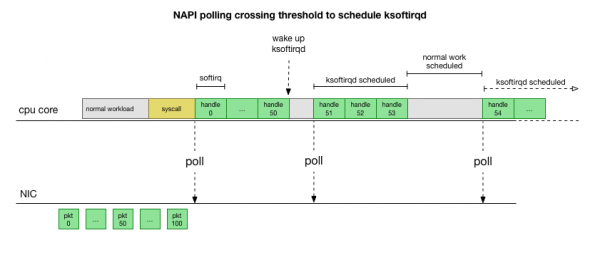
ಕರ್ನಲ್ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಹೇಗೆ ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಅಧ್ಯಯನ ಮಾಡಿದ ನಂತರ, ದಟ್ಟಣೆಯ ಒಂದು ನಿರ್ದಿಷ್ಟ ಸಾಧ್ಯತೆಯಿದೆ ಎಂದು ನೀವು ನೋಡಬಹುದು. softirq ಕರೆಗಳನ್ನು ಕಡಿಮೆ ಬಾರಿ ಸ್ವೀಕರಿಸಿದರೆ, ನೆಟ್ವರ್ಕ್ ಕಾರ್ಡ್ನಲ್ಲಿ RX ಕ್ಯೂನಲ್ಲಿ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಲು ಸ್ವಲ್ಪ ಸಮಯ ಕಾಯಬೇಕಾಗುತ್ತದೆ. ಇದು ಪ್ರೊಸೆಸರ್ ಕೋರ್ ಅನ್ನು ನಿರ್ಬಂಧಿಸುವ ಕೆಲವು ಕಾರ್ಯಗಳ ಕಾರಣದಿಂದಾಗಿರಬಹುದು ಅಥವಾ ಕೋರ್ ಸಾಫ್ಟ್ಇರ್ಕ್ ಅನ್ನು ಚಾಲನೆ ಮಾಡುವುದನ್ನು ತಡೆಯುತ್ತದೆ.
ಸಂಸ್ಕರಣೆಯನ್ನು ಕೋರ್ ಅಥವಾ ವಿಧಾನಕ್ಕೆ ಸಂಕುಚಿತಗೊಳಿಸುವುದು
Softirq ವಿಳಂಬಗಳು ಸದ್ಯಕ್ಕೆ ಕೇವಲ ಊಹೆಯಾಗಿದೆ. ಆದರೆ ಇದು ಅರ್ಥಪೂರ್ಣವಾಗಿದೆ, ಮತ್ತು ನಾವು ಇದೇ ರೀತಿಯದ್ದನ್ನು ನೋಡುತ್ತಿದ್ದೇವೆ ಎಂದು ನಮಗೆ ತಿಳಿದಿದೆ. ಆದ್ದರಿಂದ ಮುಂದಿನ ಹಂತವು ಈ ಸಿದ್ಧಾಂತವನ್ನು ದೃಢೀಕರಿಸುವುದು. ಮತ್ತು ಅದನ್ನು ದೃಢೀಕರಿಸಿದರೆ, ನಂತರ ವಿಳಂಬದ ಕಾರಣವನ್ನು ಕಂಡುಹಿಡಿಯಿರಿ.
ನಮ್ಮ ನಿಧಾನವಾದ ಪ್ಯಾಕೆಟ್ಗಳಿಗೆ ಹಿಂತಿರುಗೋಣ:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29574 ಐಸಿಎಂಪಿ_ಸೆಕ್=1954 ಆರ್ಟಿಟಿ=89.3 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29575 ಐಸಿಎಂಪಿ_ಸೆಕ್=1955 ಆರ್ಟಿಟಿ=79.2 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29576 ಐಸಿಎಂಪಿ_ಸೆಕ್=1956 ಆರ್ಟಿಟಿ=69.1 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29577 ಐಸಿಎಂಪಿ_ಸೆಕ್=1957 ಆರ್ಟಿಟಿ=59.1 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29790 ಐಸಿಎಂಪಿ_ಸೆಕ್=2070 ಆರ್ಟಿಟಿ=75.7 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29791 ಐಸಿಎಂಪಿ_ಸೆಕ್=2071 ಆರ್ಟಿಟಿ=65.6 ಎಂಎಸ್
ಲೆನ್=46 ಐಪಿ=172.16.53.32 ಟಿಟಿಎಲ್=61 ಐಡಿ=29792 ಐಸಿಎಂಪಿ_ಸೆಕ್=2072 ಆರ್ಟಿಟಿ=55.5 ಎಂಎಸ್
ಮೊದಲೇ ಚರ್ಚಿಸಿದಂತೆ, ಈ ICMP ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಒಂದೇ NIC RX ಕ್ಯೂಗೆ ಹ್ಯಾಶ್ ಮಾಡಲಾಗುತ್ತದೆ ಮತ್ತು ಒಂದೇ CPU ಕೋರ್ನಿಂದ ಸಂಸ್ಕರಿಸಲಾಗುತ್ತದೆ. ನಾವು ಕಾರ್ಯಾಚರಣೆಯನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು ಬಯಸಿದರೆ Linux, ಪ್ರಕ್ರಿಯೆಯನ್ನು ಪತ್ತೆಹಚ್ಚಲು ಈ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಎಲ್ಲಿ (ಯಾವ CPU ಕೋರ್ನಲ್ಲಿ) ಮತ್ತು ಹೇಗೆ (softirq, ksoftirqd) ಸಂಸ್ಕರಿಸಲಾಗುತ್ತದೆ ಎಂಬುದನ್ನು ತಿಳಿದುಕೊಳ್ಳುವುದು ಉಪಯುಕ್ತವಾಗಿದೆ.
ಈಗ ಕರ್ನಲ್ನ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ನೈಜ ಸಮಯದಲ್ಲಿ ಮೇಲ್ವಿಚಾರಣೆ ಮಾಡಲು ನಿಮಗೆ ಅನುಮತಿಸುವ ಪರಿಕರಗಳನ್ನು ಬಳಸುವ ಸಮಯ. Linuxಇಲ್ಲಿ ನಾವು ಬಳಸಿದ್ದೇವೆ . ಕರ್ನಲ್ನಲ್ಲಿ ಅನಿಯಂತ್ರಿತ ಕಾರ್ಯಗಳನ್ನು ಹುಕ್ ಮಾಡುವ ಮತ್ತು ಈವೆಂಟ್ಗಳನ್ನು ಬಳಕೆದಾರ-ಸ್ಪೇಸ್ ಪೈಥಾನ್ ಪ್ರೋಗ್ರಾಂಗೆ ಬಫರ್ ಮಾಡುವ ಸಣ್ಣ ಸಿ ಪ್ರೋಗ್ರಾಂಗಳನ್ನು ಬರೆಯಲು ಈ ಪರಿಕರಗಳ ಸೆಟ್ ನಿಮಗೆ ಅನುಮತಿಸುತ್ತದೆ ಮತ್ತು ಅದು ಅವುಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಬಹುದು ಮತ್ತು ಫಲಿತಾಂಶವನ್ನು ನಿಮಗೆ ಹಿಂತಿರುಗಿಸುತ್ತದೆ. ಕರ್ನಲ್ನಲ್ಲಿ ಅನಿಯಂತ್ರಿತ ಕಾರ್ಯಗಳನ್ನು ಹುಕ್ ಮಾಡುವುದು ಒಂದು ಸಂಕೀರ್ಣ ವಿಷಯವಾಗಿದೆ, ಆದರೆ ಉಪಯುಕ್ತತೆಯನ್ನು ಗರಿಷ್ಠ ಭದ್ರತೆಗಾಗಿ ವಿನ್ಯಾಸಗೊಳಿಸಲಾಗಿದೆ ಮತ್ತು ಪರೀಕ್ಷೆ ಅಥವಾ ಅಭಿವೃದ್ಧಿ ಪರಿಸರದಲ್ಲಿ ಸುಲಭವಾಗಿ ಪುನರುತ್ಪಾದಿಸಲಾಗದ ಉತ್ಪಾದನಾ ಸಮಸ್ಯೆಗಳನ್ನು ನಿಖರವಾಗಿ ಪತ್ತೆಹಚ್ಚಲು ವಿನ್ಯಾಸಗೊಳಿಸಲಾಗಿದೆ.
ಇಲ್ಲಿ ಯೋಜನೆ ಸರಳವಾಗಿದೆ: ಕರ್ನಲ್ ಈ ICMP ಪಿಂಗ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ ಎಂದು ನಮಗೆ ತಿಳಿದಿದೆ, ಆದ್ದರಿಂದ ನಾವು ಕರ್ನಲ್ ಕಾರ್ಯದ ಮೇಲೆ ಕೊಕ್ಕೆ ಹಾಕುತ್ತೇವೆ , ಇದು ಒಳಬರುವ ICMP ಪ್ರತಿಧ್ವನಿ ವಿನಂತಿ ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಸ್ವೀಕರಿಸುತ್ತದೆ ಮತ್ತು ICMP ಪ್ರತಿಧ್ವನಿ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಕಳುಹಿಸುವುದನ್ನು ಪ್ರಾರಂಭಿಸುತ್ತದೆ. icmp_seq ಸಂಖ್ಯೆಯನ್ನು ಹೆಚ್ಚಿಸುವ ಮೂಲಕ ನಾವು ಪ್ಯಾಕೆಟ್ ಅನ್ನು ಗುರುತಿಸಬಹುದು, ಅದು ತೋರಿಸುತ್ತದೆ hping3 ಮೇಲೆ.
ಕೋಡ್ ಸಂಕೀರ್ಣವಾಗಿ ಕಾಣುತ್ತದೆ, ಆದರೆ ಅದು ತೋರುವಷ್ಟು ಭಯಾನಕವಲ್ಲ. ಕಾರ್ಯ icmp_echo ತಿಳಿಸುತ್ತದೆ struct sk_buff *skb: ಇದು "ಪ್ರತಿಧ್ವನಿ ವಿನಂತಿ" ಹೊಂದಿರುವ ಪ್ಯಾಕೆಟ್ ಆಗಿದೆ. ನಾವು ಅದನ್ನು ಟ್ರ್ಯಾಕ್ ಮಾಡಬಹುದು, ಅನುಕ್ರಮವನ್ನು ಎಳೆಯಿರಿ echo.sequence (ಇದು ಹೋಲಿಸುತ್ತದೆ icmp_seq hping3 ಮೂಲಕ выше), ಮತ್ತು ಅದನ್ನು ಬಳಕೆದಾರರ ಜಾಗಕ್ಕೆ ಕಳುಹಿಸಿ. ಪ್ರಸ್ತುತ ಪ್ರಕ್ರಿಯೆಯ ಹೆಸರು/ಐಡಿಯನ್ನು ಸೆರೆಹಿಡಿಯಲು ಇದು ಅನುಕೂಲಕರವಾಗಿದೆ. ಕರ್ನಲ್ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುವಾಗ ನಾವು ನೇರವಾಗಿ ನೋಡುವ ಫಲಿತಾಂಶಗಳನ್ನು ಕೆಳಗೆ ನೀಡಲಾಗಿದೆ:
TGID PID ಪ್ರಕ್ರಿಯೆ ಹೆಸರು ICMP_seq 0 0 Swapper/11 770 0 0 Swapper/11 771 0 0 11 Swapper/772 0 0 11 Swapper/773 0 0 PRO11 774 20041 20086 775 ಸ್ವ್ಯಾಪರ್/ 0 0 11 776 ಸ್ವ್ಯಾಪರ್/0 0 11 777 ಸ್ಪೋಕ್ಸ್-ವರದಿ-ಗಳು 0
ಎಂಬುದನ್ನು ಇಲ್ಲಿ ಗಮನಿಸಬೇಕು softirq ಸಿಸ್ಟಮ್ ಕರೆಗಳನ್ನು ಮಾಡಿದ ಪ್ರಕ್ರಿಯೆಗಳು "ಪ್ರಕ್ರಿಯೆಗಳು" ಎಂದು ಗೋಚರಿಸುತ್ತವೆ, ಅದು ಕರ್ನಲ್ ಸಂದರ್ಭದಲ್ಲಿ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಸುರಕ್ಷಿತವಾಗಿ ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ.
ಈ ಉಪಕರಣದೊಂದಿಗೆ ನಾವು ನಿರ್ದಿಷ್ಟ ಪ್ರಕ್ರಿಯೆಗಳನ್ನು ನಿರ್ದಿಷ್ಟ ಪ್ಯಾಕೇಜ್ಗಳೊಂದಿಗೆ ಸಂಯೋಜಿಸಬಹುದು ಅದು ವಿಳಂಬವನ್ನು ತೋರಿಸುತ್ತದೆ hping3. ಅದನ್ನು ಸರಳಗೊಳಿಸೋಣ grep ಕೆಲವು ಮೌಲ್ಯಗಳಿಗಾಗಿ ಈ ಸೆರೆಹಿಡಿಯುವಿಕೆಯ ಮೇಲೆ icmp_seq. ಮೇಲಿನ icmp_seq ಮೌಲ್ಯಗಳಿಗೆ ಹೊಂದಿಕೆಯಾಗುವ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ನಾವು ಮೇಲೆ ಗಮನಿಸಿದ RTT ಜೊತೆಗೆ ಗುರುತಿಸಲಾಗಿದೆ (ಆವರಣದಲ್ಲಿ 50 ms ಗಿಂತ ಕಡಿಮೆ RTT ಮೌಲ್ಯಗಳಿಂದ ನಾವು ಫಿಲ್ಟರ್ ಮಾಡಿದ ಪ್ಯಾಕೆಟ್ಗಳಿಗೆ ನಿರೀಕ್ಷಿತ RTT ಮೌಲ್ಯಗಳು):
TGID PID ಪ್ರಕ್ರಿಯೆ ಹೆಸರು ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 ksoftirqd/1952 76 ** 76/ms 11 1953 99 ksoftirq d/76 76 ** 11ms 1954 89 ksoftirqd/ 76 76 ** 11ms 1955 79 ksoftirqd/76 76 ** 11ms 1956 69 ksoftirqd/76 76 ** (11ms) 1957 59 ksoftirqd/76 76 ** (11ms) 1958 49 76 ksoftir qd/ 76 11 ** (1959ms) 39 76 ksoftirqd/76 11 ** (1960ms) -- 29 76 cadvisor 76 11 1961 cadvisor 19 76 76 11 ftirqd/1962 9 ** 10137ms 10436 2068 ksoftirqd/ 10137 10436 ** 2069ms 76 76 ksoftirqd/11 2070 ** (75ms) 76 76 ksoftirqd/11 2071 ** (65ms) 76 76 ksoftirqd/11 * 2072 * 55* * (76 ಮಿ ) 76 11 ksoftirqd/2073 45 ** (76ms)
ಫಲಿತಾಂಶಗಳು ನಮಗೆ ಹಲವಾರು ವಿಷಯಗಳನ್ನು ಹೇಳುತ್ತವೆ. ಮೊದಲನೆಯದಾಗಿ, ಈ ಎಲ್ಲಾ ಪ್ಯಾಕೇಜುಗಳನ್ನು ಸಂದರ್ಭಕ್ಕೆ ಅನುಗುಣವಾಗಿ ಸಂಸ್ಕರಿಸಲಾಗುತ್ತದೆ ksoftirqd/11. ಇದರರ್ಥ ಈ ನಿರ್ದಿಷ್ಟ ಜೋಡಿ ಯಂತ್ರಗಳಿಗೆ, ICMP ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಸ್ವೀಕರಿಸುವ ತುದಿಯಲ್ಲಿ ಕೋರ್ 11 ಗೆ ಹ್ಯಾಶ್ ಮಾಡಲಾಗಿದೆ. ಜ್ಯಾಮ್ ಇದ್ದಾಗಲೆಲ್ಲಾ, ಸಿಸ್ಟಮ್ ಕರೆಯ ಸಂದರ್ಭದಲ್ಲಿ ಸಂಸ್ಕರಿಸಿದ ಪ್ಯಾಕೆಟ್ಗಳು ಇರುವುದನ್ನು ನಾವು ನೋಡುತ್ತೇವೆ cadvisor... ನಂತರ ksoftirqd ಕಾರ್ಯವನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ ಮತ್ತು ಸಂಗ್ರಹವಾದ ಸರತಿಯನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ: ನಿಖರವಾಗಿ ನಂತರ ಸಂಗ್ರಹವಾದ ಪ್ಯಾಕೆಟ್ಗಳ ಸಂಖ್ಯೆ cadvisor.
ಇದು ಯಾವಾಗಲೂ ಕೆಲಸ ಮಾಡುವ ಮೊದಲು ತಕ್ಷಣವೇ cadvisor, ಸಮಸ್ಯೆಯಲ್ಲಿ ಅವನ ಪಾಲ್ಗೊಳ್ಳುವಿಕೆಯನ್ನು ಸೂಚಿಸುತ್ತದೆ. ವಿಪರ್ಯಾಸವೆಂದರೆ, ಉದ್ದೇಶ - ಈ ಕಾರ್ಯಕ್ಷಮತೆಯ ಸಮಸ್ಯೆಯನ್ನು ಉಂಟುಮಾಡುವ ಬದಲು "ಸಂಪನ್ಮೂಲ ಬಳಕೆ ಮತ್ತು ಚಾಲನೆಯಲ್ಲಿರುವ ಕಂಟೈನರ್ಗಳ ಕಾರ್ಯಕ್ಷಮತೆಯ ಗುಣಲಕ್ಷಣಗಳನ್ನು ವಿಶ್ಲೇಷಿಸಿ".
ಕಂಟೇನರ್ಗಳ ಇತರ ಅಂಶಗಳಂತೆ, ಇವೆಲ್ಲವೂ ಹೆಚ್ಚು ಸುಧಾರಿತ ಸಾಧನಗಳಾಗಿವೆ ಮತ್ತು ಕೆಲವು ಅನಿರೀಕ್ಷಿತ ಸಂದರ್ಭಗಳಲ್ಲಿ ಕಾರ್ಯಕ್ಷಮತೆಯ ಸಮಸ್ಯೆಗಳನ್ನು ಅನುಭವಿಸಲು ನಿರೀಕ್ಷಿಸಬಹುದು.
ಪ್ಯಾಕೆಟ್ ಸರದಿಯನ್ನು ನಿಧಾನಗೊಳಿಸಲು ಕ್ಯಾಡ್ವೈಸರ್ ಏನು ಮಾಡುತ್ತದೆ?
ಈಗ ನಮಗೆ ಕ್ರ್ಯಾಶ್ ಹೇಗೆ ಸಂಭವಿಸುತ್ತದೆ, ಯಾವ ಪ್ರಕ್ರಿಯೆಯು ಅದಕ್ಕೆ ಕಾರಣವಾಗುತ್ತಿದೆ ಮತ್ತು ಯಾವ CPU ಮೇಲೆ ಎಂಬುದರ ಬಗ್ಗೆ ಉತ್ತಮ ತಿಳುವಳಿಕೆ ಇದೆ. ಹಾರ್ಡ್ ಲಾಕ್ನಿಂದಾಗಿ, ಕರ್ನಲ್ Linux ಸಮಯಕ್ಕೆ ಸರಿಯಾಗಿ ಯೋಜನೆ ಮಾಡಲು ಸಮಯವಿಲ್ಲ. ksoftirqd. ಮತ್ತು ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಸನ್ನಿವೇಶದಲ್ಲಿ ಸಂಸ್ಕರಿಸಲಾಗುತ್ತದೆ ಎಂದು ನಾವು ನೋಡುತ್ತೇವೆ cadvisor. ಎಂದು ಭಾವಿಸುವುದು ತಾರ್ಕಿಕವಾಗಿದೆ cadvisor ನಿಧಾನವಾದ ಸಿಸ್ಕಾಲ್ ಅನ್ನು ಪ್ರಾರಂಭಿಸುತ್ತದೆ, ಅದರ ನಂತರ ಆ ಸಮಯದಲ್ಲಿ ಸಂಗ್ರಹವಾದ ಎಲ್ಲಾ ಪ್ಯಾಕೆಟ್ಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಲಾಗುತ್ತದೆ:
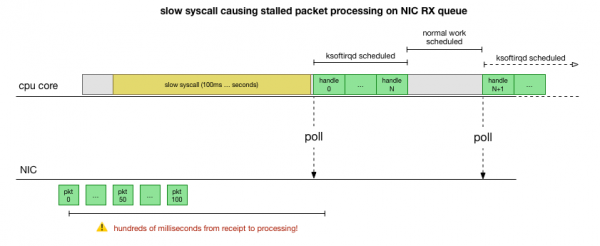
ಇದು ಒಂದು ಸಿದ್ಧಾಂತ, ಆದರೆ ಅದನ್ನು ಹೇಗೆ ಪರೀಕ್ಷಿಸುವುದು? ನಾವು ಏನು ಮಾಡಬಹುದು ಈ ಪ್ರಕ್ರಿಯೆಯ ಉದ್ದಕ್ಕೂ CPU ಕೋರ್ ಅನ್ನು ಪತ್ತೆಹಚ್ಚುವುದು, ಪ್ಯಾಕೆಟ್ಗಳ ಸಂಖ್ಯೆಯು ಬಜೆಟ್ ಮತ್ತು ksoftirqd ಎಂದು ಕರೆಯಲ್ಪಡುವ ಬಿಂದುವನ್ನು ಕಂಡುಹಿಡಿಯುವುದು, ಮತ್ತು ಆ ಬಿಂದುವಿನ ಮೊದಲು CPU ಕೋರ್ನಲ್ಲಿ ನಿಖರವಾಗಿ ಏನನ್ನು ಚಾಲನೆ ಮಾಡುತ್ತಿದೆ ಎಂಬುದನ್ನು ನೋಡಲು ಸ್ವಲ್ಪ ಮುಂದೆ ನೋಡಿ. . ಇದು ಪ್ರತಿ ಕೆಲವು ಮಿಲಿಸೆಕೆಂಡ್ಗಳಿಗೆ CPU ಅನ್ನು ಎಕ್ಸ್-ರೇ ಮಾಡುವಂತಿದೆ. ಇದು ಈ ರೀತಿ ಕಾಣುತ್ತದೆ:
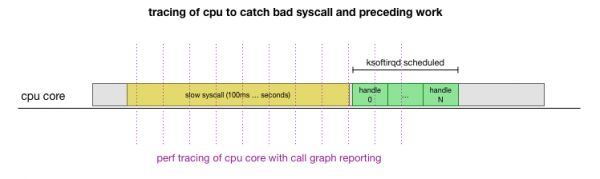
ಅನುಕೂಲಕರವಾಗಿ, ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಸಾಧನಗಳೊಂದಿಗೆ ಇದೆಲ್ಲವನ್ನೂ ಮಾಡಬಹುದು. ಉದಾಹರಣೆಗೆ, ನಿರ್ದಿಷ್ಟ ಆವರ್ತನದಲ್ಲಿ ನಿರ್ದಿಷ್ಟ CPU ಕೋರ್ ಅನ್ನು ಪರಿಶೀಲಿಸುತ್ತದೆ ಮತ್ತು ಬಳಕೆದಾರ ಸ್ಥಳ ಮತ್ತು ಕರ್ನಲ್ ಎರಡನ್ನೂ ಒಳಗೊಂಡಂತೆ ಚಾಲನೆಯಲ್ಲಿರುವ ವ್ಯವಸ್ಥೆಯ ಕರೆ ಗ್ರಾಫ್ ಅನ್ನು ರಚಿಸಬಹುದು. Linuxನೀವು ಈ ದಾಖಲೆಯನ್ನು ತೆಗೆದುಕೊಂಡು ಪ್ರೋಗ್ರಾಂನ ಸಣ್ಣ ಫೋರ್ಕ್ ಬಳಸಿ ಅದನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಬಹುದು. ಬ್ರೆಂಡನ್ ಗ್ರೆಗ್ನಿಂದ, ಇದು ಸ್ಟಾಕ್ ಟ್ರೇಸ್ನ ಕ್ರಮವನ್ನು ಸಂರಕ್ಷಿಸುತ್ತದೆ. ನಾವು ಪ್ರತಿ 1 ಎಂಎಸ್ಗೆ ಏಕ-ಸಾಲಿನ ಸ್ಟಾಕ್ ಟ್ರೇಸ್ಗಳನ್ನು ಉಳಿಸಬಹುದು, ತದನಂತರ ಟ್ರೇಸ್ ಹಿಟ್ ಮಾಡುವ ಮೊದಲು ಮಾದರಿಯನ್ನು 100 ಮಿಲಿಸೆಕೆಂಡುಗಳನ್ನು ಹೈಲೈಟ್ ಮಾಡಬಹುದು ಮತ್ತು ಉಳಿಸಬಹುದು ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
ಫಲಿತಾಂಶಗಳು ಇಲ್ಲಿವೆ:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
ಇಲ್ಲಿ ಬಹಳಷ್ಟು ವಿಷಯಗಳಿವೆ, ಆದರೆ ಮುಖ್ಯ ವಿಷಯವೆಂದರೆ ICMP ಟ್ರೇಸರ್ನಲ್ಲಿ ನಾವು ಮೊದಲು ನೋಡಿದ "ksoftirqd ಮೊದಲು ಕ್ಯಾಡ್ವೈಸರ್" ಮಾದರಿಯನ್ನು ನಾವು ಕಂಡುಕೊಳ್ಳುತ್ತೇವೆ. ಅದರ ಅರ್ಥವೇನು?
ಪ್ರತಿಯೊಂದು ಸಾಲು ಒಂದು ನಿರ್ದಿಷ್ಟ ಸಮಯದಲ್ಲಿ CPU ಟ್ರೇಸ್ ಆಗಿದೆ. ಒಂದು ಸಾಲಿನ ಮೇಲಿನ ಸ್ಟಾಕ್ನ ಪ್ರತಿ ಕರೆಯನ್ನು ಅರ್ಧವಿರಾಮ ಚಿಹ್ನೆಯಿಂದ ಬೇರ್ಪಡಿಸಲಾಗುತ್ತದೆ. ಸಾಲುಗಳ ಮಧ್ಯದಲ್ಲಿ ಸಿಸ್ಕಾಲ್ ಅನ್ನು ಕರೆಯುವುದನ್ನು ನಾವು ನೋಡುತ್ತೇವೆ: read(): .... ;do_syscall_64;sys_read; .... ಆದ್ದರಿಂದ ಕ್ಯಾಡ್ವೈಸರ್ ಸಿಸ್ಟಮ್ ಕರೆಯಲ್ಲಿ ಸಾಕಷ್ಟು ಸಮಯವನ್ನು ಕಳೆಯುತ್ತಾರೆ read()ಕಾರ್ಯಗಳಿಗೆ ಸಂಬಂಧಿಸಿದೆ mem_cgroup_* (ಕರೆ ಸ್ಟಾಕ್ನ ಮೇಲ್ಭಾಗ/ಸಾಲಿನ ಅಂತ್ಯ).
ನಿಖರವಾಗಿ ಏನು ಓದಲಾಗುತ್ತಿದೆ ಎಂಬುದನ್ನು ಕರೆ ಟ್ರೇಸ್ನಲ್ಲಿ ನೋಡಲು ಅನಾನುಕೂಲವಾಗಿದೆ, ಆದ್ದರಿಂದ ನಾವು ಓಡೋಣ strace ಮತ್ತು ಕ್ಯಾಡ್ವೈಸರ್ ಏನು ಮಾಡುತ್ತದೆ ಎಂಬುದನ್ನು ನೋಡೋಣ ಮತ್ತು 100 ms ಗಿಂತ ಹೆಚ್ಚಿನ ಸಿಸ್ಟಮ್ ಕರೆಗಳನ್ನು ಕಂಡುಹಿಡಿಯೋಣ:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
ನೀವು ನಿರೀಕ್ಷಿಸಿದಂತೆ, ನಾವು ಇಲ್ಲಿ ನಿಧಾನ ಕರೆಗಳನ್ನು ನೋಡುತ್ತೇವೆ read(). ಓದುವ ಕಾರ್ಯಾಚರಣೆಗಳು ಮತ್ತು ಸಂದರ್ಭದ ವಿಷಯಗಳಿಂದ mem_cgroup ಈ ಸವಾಲುಗಳು ಸ್ಪಷ್ಟವಾಗಿದೆ read() ಫೈಲ್ ಅನ್ನು ಉಲ್ಲೇಖಿಸಿ memory.stat, ಇದು ಮೆಮೊರಿ ಬಳಕೆ ಮತ್ತು cgroup ಮಿತಿಗಳನ್ನು ತೋರಿಸುತ್ತದೆ (ಡಾಕರ್ನ ಸಂಪನ್ಮೂಲ ಪ್ರತ್ಯೇಕ ತಂತ್ರಜ್ಞಾನ). ಧಾರಕಗಳಿಗೆ ಸಂಪನ್ಮೂಲ ಬಳಕೆಯ ಮಾಹಿತಿಯನ್ನು ಪಡೆಯಲು ಕ್ಯಾಡ್ವೈಸರ್ ಉಪಕರಣವು ಈ ಫೈಲ್ ಅನ್ನು ಪ್ರಶ್ನಿಸುತ್ತದೆ. ಇದು ಕರ್ನಲ್ ಅಥವಾ ಕ್ಯಾಡ್ವೈಸರ್ ಏನಾದರೂ ಅನಿರೀಕ್ಷಿತವಾಗಿ ಮಾಡುತ್ತಿದೆಯೇ ಎಂದು ಪರಿಶೀಲಿಸೋಣ:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
ನಿಜವಾದ 0m0.153ಸೆ
ಬಳಕೆದಾರ 0m0.000s
ಸಿಸ್ 0m0.152s
ಥಿಯೋಜುಲಿಯೆನ್ @ ಕ್ಯೂಬ್-ನೋಡ್-ಬ್ಯಾಡ್ ~ $
ಈಗ ನಾವು ದೋಷವನ್ನು ಪುನರುತ್ಪಾದಿಸಬಹುದು ಮತ್ತು ಕರ್ನಲ್ ಅನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಬಹುದು Linux ರೋಗಶಾಸ್ತ್ರವನ್ನು ಎದುರಿಸುತ್ತದೆ.
ಓದುವ ಕಾರ್ಯಾಚರಣೆ ಏಕೆ ನಿಧಾನವಾಗಿದೆ?
ಈ ಹಂತದಲ್ಲಿ, ಇದೇ ರೀತಿಯ ಸಮಸ್ಯೆಗಳ ಕುರಿತು ಇತರ ಬಳಕೆದಾರರ ಸಂದೇಶಗಳನ್ನು ಕಂಡುಹಿಡಿಯುವುದು ತುಂಬಾ ಸುಲಭ. ಅದು ಬದಲಾದಂತೆ, ಕ್ಯಾಡ್ವೈಸರ್ ಟ್ರ್ಯಾಕರ್ನಲ್ಲಿ ಈ ದೋಷವನ್ನು ವರದಿ ಮಾಡಲಾಗಿದೆ , ನೆಟ್ವರ್ಕ್ ಸ್ಟಾಕ್ನಲ್ಲಿ ಸುಪ್ತತೆಯು ಯಾದೃಚ್ಛಿಕವಾಗಿ ಪ್ರತಿಫಲಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಯಾರೂ ಗಮನಿಸಲಿಲ್ಲ. ಕ್ಯಾಡ್ವೈಸರ್ ನಿರೀಕ್ಷಿಸಿದ್ದಕ್ಕಿಂತ ಹೆಚ್ಚು CPU ಸಮಯವನ್ನು ಸೇವಿಸುತ್ತಿದೆ ಎಂದು ಗಮನಿಸಲಾಗಿದೆ, ಆದರೆ ಇದಕ್ಕೆ ಹೆಚ್ಚಿನ ಪ್ರಾಮುಖ್ಯತೆಯನ್ನು ನೀಡಲಾಗಿಲ್ಲ, ಏಕೆಂದರೆ ನಮ್ಮ ಸರ್ವರ್ಗಳು ಬಹಳಷ್ಟು CPU ಸಂಪನ್ಮೂಲಗಳನ್ನು ಹೊಂದಿರುವುದರಿಂದ ಸಮಸ್ಯೆಯನ್ನು ಎಚ್ಚರಿಕೆಯಿಂದ ಅಧ್ಯಯನ ಮಾಡಲಾಗಿಲ್ಲ.
ಸಮಸ್ಯೆಯೆಂದರೆ ಸಿಗ್ರೂಪ್ಗಳು ನೇಮ್ಸ್ಪೇಸ್ನಲ್ಲಿ (ಕಂಟೇನರ್) ಮೆಮೊರಿ ಬಳಕೆಯನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುತ್ತವೆ. ಈ cgroup ನಲ್ಲಿನ ಎಲ್ಲಾ ಪ್ರಕ್ರಿಯೆಗಳು ನಿರ್ಗಮಿಸಿದಾಗ, ಡಾಕರ್ ಮೆಮೊರಿ cgroup ಅನ್ನು ಬಿಡುಗಡೆ ಮಾಡುತ್ತದೆ. ಆದಾಗ್ಯೂ, "ಮೆಮೊರಿ" ಕೇವಲ ಪ್ರಕ್ರಿಯೆ ಸ್ಮರಣೆಯಲ್ಲ. ಪ್ರಕ್ರಿಯೆಯ ಮೆಮೊರಿಯು ಇನ್ನು ಮುಂದೆ ಬಳಸಲ್ಪಡದಿದ್ದರೂ, ಕರ್ನಲ್ ಇನ್ನೂ ಕ್ಯಾಶ್ ಮಾಡಲಾದ ವಿಷಯಗಳನ್ನು ನಿಯೋಜಿಸುತ್ತದೆ, ಉದಾಹರಣೆಗೆ ಡೆಂಟ್ರೀಸ್ ಮತ್ತು ಐನೋಡ್ಗಳು (ಡೈರೆಕ್ಟರಿ ಮತ್ತು ಫೈಲ್ ಮೆಟಾಡೇಟಾ), ಇವುಗಳನ್ನು ಮೆಮೊರಿ cgroup ನಲ್ಲಿ ಸಂಗ್ರಹಿಸಲಾಗುತ್ತದೆ. ಸಮಸ್ಯೆಯ ವಿವರಣೆಯಿಂದ:
zombie cgroups: ಯಾವುದೇ ಪ್ರಕ್ರಿಯೆಗಳನ್ನು ಹೊಂದಿರದ ಮತ್ತು ಅಳಿಸಲಾದ, ಆದರೆ ಇನ್ನೂ ಮೆಮೊರಿಯನ್ನು ನಿಯೋಜಿಸಲಾದ cgroups (ನನ್ನ ಸಂದರ್ಭದಲ್ಲಿ, ಡೆಂಟ್ರಿ ಕ್ಯಾಶ್ನಿಂದ, ಆದರೆ ಅದನ್ನು ಪುಟ ಸಂಗ್ರಹ ಅಥವಾ tmpfs ನಿಂದ ಕೂಡ ಹಂಚಬಹುದು).
cgroup ಅನ್ನು ಮುಕ್ತಗೊಳಿಸುವಾಗ ಸಂಗ್ರಹದಲ್ಲಿರುವ ಎಲ್ಲಾ ಪುಟಗಳ ಕರ್ನಲ್ನ ಪರಿಶೀಲನೆಯು ತುಂಬಾ ನಿಧಾನವಾಗಿರಬಹುದು, ಆದ್ದರಿಂದ ಸೋಮಾರಿಯಾದ ಪ್ರಕ್ರಿಯೆಯನ್ನು ಆಯ್ಕೆಮಾಡಲಾಗುತ್ತದೆ: ಈ ಪುಟಗಳನ್ನು ಮತ್ತೆ ವಿನಂತಿಸುವವರೆಗೆ ಕಾಯಿರಿ, ತದನಂತರ ಅಂತಿಮವಾಗಿ ಮೆಮೊರಿ ಅಗತ್ಯವಿರುವಾಗ cgroup ಅನ್ನು ತೆರವುಗೊಳಿಸಿ. ಇಲ್ಲಿಯವರೆಗೆ, ಅಂಕಿಅಂಶಗಳನ್ನು ಸಂಗ್ರಹಿಸುವಾಗ cgroup ಅನ್ನು ಇನ್ನೂ ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳಲಾಗುತ್ತದೆ.
ಕಾರ್ಯಕ್ಷಮತೆಯ ದೃಷ್ಟಿಕೋನದಿಂದ, ಅವರು ಕಾರ್ಯಕ್ಷಮತೆಗಾಗಿ ಸ್ಮರಣೆಯನ್ನು ತ್ಯಾಗ ಮಾಡಿದರು: ಕೆಲವು ಸಂಗ್ರಹವಾದ ಸ್ಮರಣೆಯನ್ನು ಬಿಟ್ಟು ಆರಂಭಿಕ ಶುದ್ಧೀಕರಣವನ್ನು ವೇಗಗೊಳಿಸುತ್ತಾರೆ. ಇದು ಚೆನ್ನಾಗಿದೆ. ಕರ್ನಲ್ ಕ್ಯಾಶ್ ಮಾಡಲಾದ ಮೆಮೊರಿಯ ಕೊನೆಯದನ್ನು ಬಳಸಿದಾಗ, cgroup ಅನ್ನು ಅಂತಿಮವಾಗಿ ತೆರವುಗೊಳಿಸಲಾಗುತ್ತದೆ, ಆದ್ದರಿಂದ ಇದನ್ನು "ಸೋರಿಕೆ" ಎಂದು ಕರೆಯಲಾಗುವುದಿಲ್ಲ. ದುರದೃಷ್ಟವಶಾತ್, ಹುಡುಕಾಟ ಕಾರ್ಯವಿಧಾನದ ನಿರ್ದಿಷ್ಟ ಅನುಷ್ಠಾನ memory.stat ಈ ಕರ್ನಲ್ ಆವೃತ್ತಿಯಲ್ಲಿ (4.9), ನಮ್ಮ ಸರ್ವರ್ಗಳಲ್ಲಿನ ದೊಡ್ಡ ಪ್ರಮಾಣದ ಮೆಮೊರಿಯೊಂದಿಗೆ ಸಂಯೋಜಿಸಲ್ಪಟ್ಟಿದೆ, ಅಂದರೆ ಇತ್ತೀಚಿನ ಕ್ಯಾಶ್ ಮಾಡಿದ ಡೇಟಾವನ್ನು ಮರುಸ್ಥಾಪಿಸಲು ಮತ್ತು cgroup zombies ಅನ್ನು ತೆರವುಗೊಳಿಸಲು ಇದು ಹೆಚ್ಚು ಸಮಯ ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ.
ನಮ್ಮ ಕೆಲವು ನೋಡ್ಗಳು ತುಂಬಾ ಸಿಗ್ರೂಪ್ ಸೋಮಾರಿಗಳನ್ನು ಹೊಂದಿದ್ದು, ಓದುವಿಕೆ ಮತ್ತು ಸುಪ್ತತೆಯು ಸೆಕೆಂಡ್ ಅನ್ನು ಮೀರಿದೆ ಎಂದು ಅದು ತಿರುಗುತ್ತದೆ.
ಕ್ಯಾಡ್ವೈಸರ್ ಸಮಸ್ಯೆಗೆ ಪರಿಹಾರವೆಂದರೆ ಸಿಸ್ಟಮ್ನಾದ್ಯಂತ ಡೆಂಟ್ರೀಸ್/ಇನೋಡ್ಗಳ ಸಂಗ್ರಹಗಳನ್ನು ತಕ್ಷಣವೇ ಮುಕ್ತಗೊಳಿಸುವುದು, ಇದು ಹೋಸ್ಟ್ನಲ್ಲಿ ಓದುವ ಲೇಟೆನ್ಸಿ ಮತ್ತು ನೆಟ್ವರ್ಕ್ ಲೇಟೆನ್ಸಿಯನ್ನು ತಕ್ಷಣವೇ ತೆಗೆದುಹಾಕುತ್ತದೆ, ಏಕೆಂದರೆ ಸಂಗ್ರಹವನ್ನು ತೆರವುಗೊಳಿಸುವುದರಿಂದ ಕ್ಯಾಶ್ ಮಾಡಿದ ಜೊಂಬಿ ಸಿಗ್ರೂಪ್ ಪುಟಗಳು ಆನ್ ಆಗುತ್ತದೆ ಮತ್ತು ಅವುಗಳನ್ನು ಸಹ ಮುಕ್ತಗೊಳಿಸುತ್ತದೆ. ಇದು ಪರಿಹಾರವಲ್ಲ, ಆದರೆ ಇದು ಸಮಸ್ಯೆಯ ಕಾರಣವನ್ನು ಖಚಿತಪಡಿಸುತ್ತದೆ.
ಹೊಸ ಕರ್ನಲ್ ಆವೃತ್ತಿಗಳಲ್ಲಿ (4.19+) ಕರೆ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಸುಧಾರಿಸಲಾಗಿದೆ ಎಂದು ಅದು ಬದಲಾಯಿತು memory.stat, ಆದ್ದರಿಂದ ಈ ಕರ್ನಲ್ಗೆ ಬದಲಾಯಿಸುವುದರಿಂದ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸಲಾಗಿದೆ. ಅದೇ ಸಮಯದಲ್ಲಿ, ಕುಬರ್ನೆಟ್ಸ್ ಕ್ಲಸ್ಟರ್ಗಳಲ್ಲಿ ಸಮಸ್ಯಾತ್ಮಕ ನೋಡ್ಗಳನ್ನು ಪತ್ತೆಹಚ್ಚಲು, ಅವುಗಳನ್ನು ಆಕರ್ಷಕವಾಗಿ ಡ್ರೈನ್ ಮಾಡಲು ಮತ್ತು ಅವುಗಳನ್ನು ರೀಬೂಟ್ ಮಾಡಲು ನಾವು ಉಪಕರಣಗಳನ್ನು ಹೊಂದಿದ್ದೇವೆ. ನಾವು ಎಲ್ಲಾ ಕ್ಲಸ್ಟರ್ಗಳನ್ನು ಬಾಚಿಕೊಂಡಿದ್ದೇವೆ, ಸಾಕಷ್ಟು ಹೆಚ್ಚಿನ ಲೇಟೆನ್ಸಿ ಹೊಂದಿರುವ ನೋಡ್ಗಳನ್ನು ಕಂಡುಕೊಂಡಿದ್ದೇವೆ ಮತ್ತು ಅವುಗಳನ್ನು ರೀಬೂಟ್ ಮಾಡಿದ್ದೇವೆ. ಉಳಿದಿರುವ ಸರ್ವರ್ಗಳಲ್ಲಿ OS ಅನ್ನು ನವೀಕರಿಸಲು ಇದು ನಮಗೆ ಸಮಯವನ್ನು ನೀಡಿದೆ.
ಸಾರಾಂಶ
ಈ ದೋಷವು ನೂರಾರು ಮಿಲಿಸೆಕೆಂಡ್ಗಳಿಗೆ RX NIC ಕ್ಯೂ ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುವಿಕೆಯನ್ನು ನಿಲ್ಲಿಸಿದ ಕಾರಣ, ಇದು ಏಕಕಾಲದಲ್ಲಿ ಕಿರು ಸಂಪರ್ಕಗಳಲ್ಲಿ ಹೆಚ್ಚಿನ ಸುಪ್ತತೆ ಮತ್ತು MySQL ವಿನಂತಿಗಳು ಮತ್ತು ಪ್ರತಿಕ್ರಿಯೆ ಪ್ಯಾಕೆಟ್ಗಳ ನಡುವಿನ ಮಧ್ಯ-ಸಂಪರ್ಕ ಲೇಟೆನ್ಸಿ ಎರಡನ್ನೂ ಉಂಟುಮಾಡುತ್ತದೆ.
ಕುಬರ್ನೆಟ್ಸ್ನಂತಹ ಅತ್ಯಂತ ಮೂಲಭೂತ ವ್ಯವಸ್ಥೆಗಳ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು ಮತ್ತು ನಿರ್ವಹಿಸುವುದು, ಅವುಗಳ ಆಧಾರದ ಮೇಲೆ ಎಲ್ಲಾ ಸೇವೆಗಳ ವಿಶ್ವಾಸಾರ್ಹತೆ ಮತ್ತು ವೇಗಕ್ಕೆ ನಿರ್ಣಾಯಕವಾಗಿದೆ. ಕುಬರ್ನೆಟ್ಸ್ ಕಾರ್ಯಕ್ಷಮತೆ ಸುಧಾರಣೆಗಳಿಂದ ನೀವು ರನ್ ಮಾಡುವ ಪ್ರತಿಯೊಂದು ಸಿಸ್ಟಮ್ ಪ್ರಯೋಜನಗಳನ್ನು ಪಡೆಯುತ್ತದೆ.
ಮೂಲ: www.habr.com
