

Salve, Habr! Hodie systema aedificabimus quod Apache Kafka nuntius fluminum processit utentes Spark Streaming et scribentes eventus processus ad AWS RDS nubecularum datorum.
Fingamus aliquem institutum fidem nobis praebere negotium processus "in musca" per omnes ramos eius ineuntes. Hoc fieri potest ad prompte computandi apertam monetam positionem pro aerario, limitibus vel proventuum oeconomicorum pro transactionibus, etc.
Quomodo hanc causam efficiendi sine magicis et magicis carminibus adhibitis - sub inciso legitur! Perge!

introduction
Utique, dispensando magnam copiam notitiarum realium temporis, amplas praebet opportunitates utendi in systematis hodiernis. Una ex maxime popularibus coniunctio haec est tandem Apache Kafka et Spark Streaming, ubi Kafka rivum advenientis nuntius facit, et scintillae processuum harum fasciculorum dato tempore interiecto.
Ad tolerantiam vitiorum augendam adhibitis, checks utemur. Cum hac mechanismo, cum scintillae Streaming machinae notitias amissas recuperare debet, solum ad ultimum LAPIS reverti ac calculos inde repetere necesse est.
Architectura systematis enucleatae
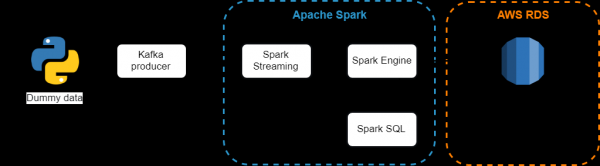
Components usus est:
- est distributa nuntius ratiocinandi-subscribe ratio. Apta tabitudo nuntiorum et online tam offline. Ad damna notificata impediendam, nuntii Kafka in disco reponuntur et intra botrum repplicantur. Systema Kafka aedificatum est in vertice synchronisationi zooKeeper;
- - Scintilla pars est processus effusis data. Scintilla Streaming modulus fabricatur architecturae parvae batch utens, ubi notitia amnis interpretatur continua serie rerum parvarum fasciculorum. Scintilla Streaming notitias e diversis fontibus accipit et in parvas sarcinas componit. Novae fasciculi certis intervallis creantur. Ineunte cuiusque temporis spatio, novus fasciculus creatur, et quaelibet notitia eo intervallo recepta in fasciculum comprehenditur. In fine intervalli, incrementum fasciculus sistit. Magnitudo intervalli per modulum inter- jectum appellatur ;
- - processus relationis coniungit cum scintilla programmandi functionis. Data constructa significat notitia quae schema habet, id est, unum campum pro omnibus monumentis. Scintilla SQL subsidia initus ex variis fontibus structuris data et, propter schematismi promptitudinem, potest efficaciter recuperare solum debitas tabularum regiones, et etiam praebet DataFrame APIs;
- est relativum insumptuosus nubilus innixus relationis datorum, servitium interretialem quae simplices habeat, operandi et scalas, et immediate ab Amazonio administratur.
Installing et currit Kafka servo
Antequam Kafka directe utatur, debes fac tibi Javam, quia... JVM adhibetur ad opus;
sudo apt-get update
sudo apt-get install default-jre
java -version
Novam usorem cum Kafka opus faciamus:
sudo useradd kafka -m
sudo passwd kafka
sudo adduser kafka sudo
Deinceps distributionem ex officiali Apache Kafka website accipe:
wget -P /YOUR_PATH "http://apache-mirror.rbc.ru/pub/apache/kafka/2.2.0/kafka_2.12-2.2.0.tgz"EXIMO downloaded archivo:
tar -xvzf /YOUR_PATH/kafka_2.12-2.2.0.tgz
ln -s /YOUR_PATH/kafka_2.12-2.2.0 kafka
Proximum est libitum. Ita res est, quod occasus defectus non te permittit ut omnes facultates Apache Kafka plene utantur. Exempli causa, delere thema, categoriam, catervam ad quam epistulae divulgari possunt. Ad hoc mutandum, configurationem limamus:
vim ~/kafka/config/server.propertiesAdde sequenti usque ad finem tabella:
delete.topic.enable = truePriusquam a servo Kafka incipias, debes servo ZooKeeper incipere, scripto auxiliario utemur quod cum distributione Kafka venit:
Cd ~/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
Postquam ZooKeeper feliciter incepit, Kafka server in separato termino detrudit:
bin/kafka-server-start.sh config/server.propertiesNovum topicum nomine transactionis creare faciamus:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic transactionFaciamus ut thema cum requisitis partitionibus et replicationibus creatum sit:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 
Desideremus momenta probationis producentis et consumpti pro themate novo creato. Plus details quomodo probare potes mittere nuntios accipientesque in documentis officialibus scriptae sunt. . Bene movemur ad scribendum effectorem in Pythone KafkaProducer API utentem.
producentis scripturam
Faciens temere notitias generabit - 100 nuntios omnes secundos. Per temere data intelligimus glossarium tribus agris constans:
- genere - nomen institutionis crediti punctum venditionis;
- Monetæ - transaction monetæ;
- Aliquam - re tantum. Quantitas numerus positivus erit si sit emptio monetae apud Argentariam, et numerus negativus si venditio est.
Codex ad producentis hoc spectat:
from numpy.random import choice, randint
def get_random_value():
new_dict = {}
branch_list = ['Kazan', 'SPB', 'Novosibirsk', 'Surgut']
currency_list = ['RUB', 'USD', 'EUR', 'GBP']
new_dict['branch'] = choice(branch_list)
new_dict['currency'] = choice(currency_list)
new_dict['amount'] = randint(-100, 100)
return new_dict
Deinde, methodo mittendo utens, nuntium mittimus ad ministratorem, ad thema, quod opus est, in forma JSON:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:dumps(x).encode('utf-8'),
compression_type='gzip')
my_topic = 'transaction'
data = get_random_value()
try:
future = producer.send(topic = my_topic, value = data)
record_metadata = future.get(timeout=10)
print('--> The message has been sent to a topic:
{}, partition: {}, offset: {}'
.format(record_metadata.topic,
record_metadata.partition,
record_metadata.offset ))
except Exception as e:
print('--> It seems an Error occurred: {}'.format(e))
finally:
producer.flush()
Quando scriptum currit, epistulas sequentes in termino recipimus:
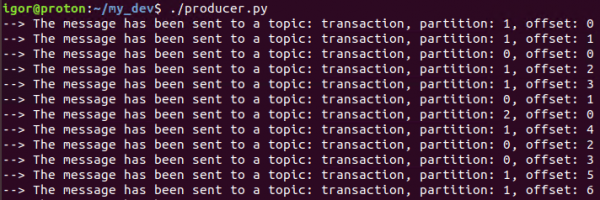
Hoc significat omnia opera sicut voluimus - producens generare et nuntios mittere ad rem quae opus est.
Proximus gradus est scintillam installare et hunc nuntium fluentum procedere.
Apache installing scintilla
Apache Spark est universalis et summus perficientur botrum computandi suggestum.
Scintilla meliores facit quam populares exsecutiones MapReduce exemplar, dum latius rationes computationis sustinent, inclusas interrogationes interactivas et processus amnis. Celeritas munus magni ponderis agit cum magnas copiarum notitiarum dispensando, cum celeritas illa permittit ut sine minuta vel hora exspectatione interactive laboras. One of Spark's Maximas vires, quae tam celeriter efficit, facultas est in- calculis memoriam praestare.
Hoc compage in Scala scriptum est, ut primum illud instituas necesse est;
sudo apt-get install scalaDownload Scintilla distributio ex rutrum:
wget "http://mirror.linux-ia64.org/apache/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz"Archivum Unpack:
sudo tar xvf spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz -C /usr/local/sparkAdde viam scintillae ad fasciculi vercundus:
vim ~/.bashrcSequentes lineas per editorem adde:
SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
Curre imperium infra post mutationes bashrc;
source ~/.bashrcdisponas AWS PostgreSQL
Reliquum est ad explicandum datorum, in quod notitias processitales ex rivulis onerabimus. Hac AWS RDS utemur servitio.
Ite ad AWS consolandum -> AWS RDS -> Databases -> database:
Lego PostgreSQL ac preme Next:

Quod Hoc exemplum in educational causa tantum est, ut libero servo "ad minimum" (liberum Tier);
Deinde ricinum in Libero Tier trunco ponimus, et postea sponte exhibebimus instantiam t2.micro classis -, licet debilis, liberam et ad negotium nostrum satis idoneam;
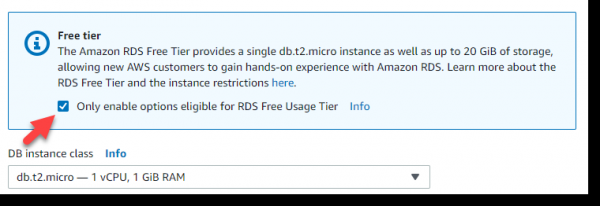
Proxima magnae res veniunt: nomen exempli datorum, nomen domini utentis et tesserae eius. Exempli gratia: myHabrTest, dominus usor; habr, password: habr12345 and click on the Next button:
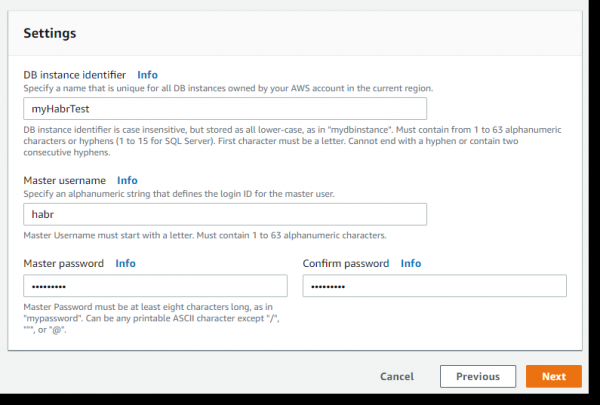
In altera pagina parametri sunt responsabiles pro accessibilitate servientis database nostri ab extra (Publicum accessibilitatem) et portum promptitudinis:
Novum occasum pro societate securitatis VPC creemus, quae externam accessum ad serverni datorum per portum 5432 dabunt (PostgreSQL).
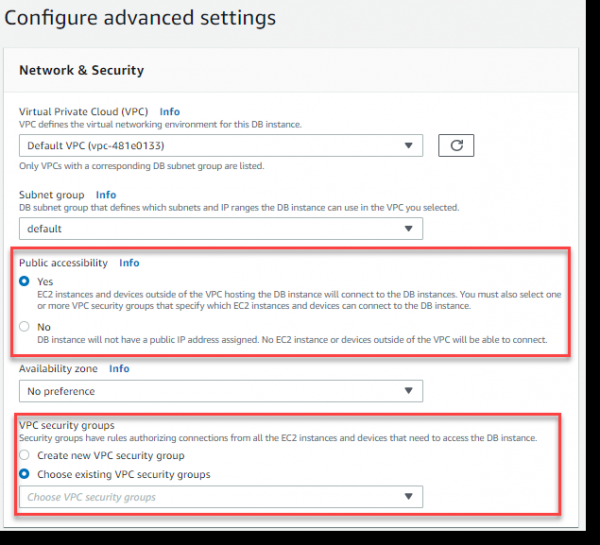
Eamus ad AWS consolandum in fenestra pasco separato ad VPC Dashboard -> Securitatis Sodalitates -> Securitatem coetus crea sectionem:

Nomen pro sodalitate Securitatis - PostgreSQL, descriptione, indicamus quae VPC hic coetus coniungi debet cum globulo crea et preme:

Imple regulas Inbound pro portu 5432 pro coetu recenti creato, ut in imagine infra ostendetur. Portum manually exprimere non potes, sed eligere PostgreSQL ex Typus gutta-down indicem.
Proprie valor ::/0 significat facultatem adveniendi negotiationis ministratori ex toto orbe terrarum, quod canonice non omnino verum est, sed exemplum analysi, accessu hoc uti permittamus:
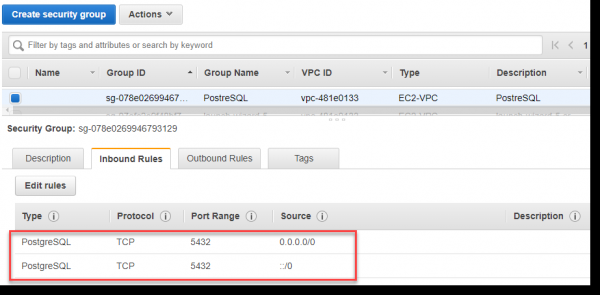
Redimus ad paginam pasco, ubi "configurare occasus provectus" aperta et elige in sectione securitatis in VPC circulorum -> elige coetus securitatem VPC existentes -> PostgreSQL:
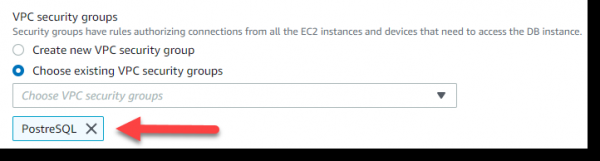
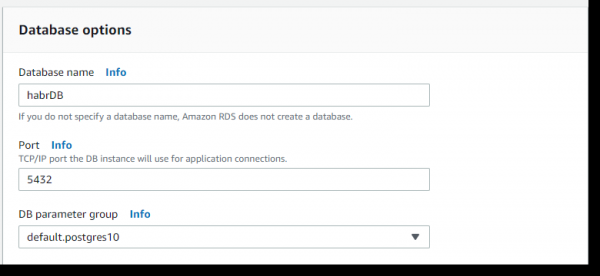
Dein in optionibus Database -> Nomen Database -> nomen pone - habrDB.
Reliquas parametros relinquere possumus, excepto inactivare tergum (tergum retentionis periodi - 0 dierum), vigilantia et euismod Insights, per defaltam. Click in puga pyga database crea:
Post tracto
Ultimus scaena explicatio operis scintillae erit, quae notitias novas e Kafka singulis duobus secundis procedet et proventum datorum intrabit.
Sicut supra dictum est, checkpoints sunt nucleus mechanismus in SparkStreaming qui conformari debet ad tolerantiam culpae praestandam. checks punctis utemur et, si ratio deficit, scintillae Streaming moduli tantum opus est ad ultimum LAPIS redire et ex eo calculos resumere ad datam amissam recuperandam.
Reprehensio possit praebere indicem in culpa toleranti, certae rationi fasciculi (ut HDFS, S3, etc.) in qua notitia LAPIS reponenda est. Hoc fit utens, verbi gratia:
streamingContext.checkpoint(checkpointDirectory)In exemplo nostro sequenti utemur accessu, nempe, si check punctumDirectorium existit, contextus e notitia LAPIS recreabitur. Si directorium non est (i.e. primum supplicium), tunc munusToCreateContext appellatur ad novum contextum creandum et DStreams configurandum:
from pyspark.streaming import StreamingContext
context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
DirectStream rem crearemus ad coniungere cum themate "transactionis" utendi methodum bibliothecae KafkaUtils createDirectStream:
from pyspark.streaming.kafka import KafkaUtils
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 2)
broker_list = 'localhost:9092'
topic = 'transaction'
directKafkaStream = KafkaUtils.createDirectStream(ssc,
[topic],
{"metadata.broker.list": broker_list})
Parsing advenientis notitia in forma JSON:
rowRdd = rdd.map(lambda w: Row(branch=w['branch'],
currency=w['currency'],
amount=w['amount']))
testDataFrame = spark.createDataFrame(rowRdd)
testDataFrame.createOrReplaceTempView("treasury_stream")
Scintilla SQL utendo, simplicem copulationem facimus et eventum in console exhibemus:
select
from_unixtime(unix_timestamp()) as curr_time,
t.branch as branch_name,
t.currency as currency_code,
sum(amount) as batch_value
from treasury_stream t
group by
t.branch,
t.currency
Questus est textus interrogationis et currit per Scintillam SQL:
sql_query = get_sql_query()
testResultDataFrame = spark.sql(sql_query)
testResultDataFrame.show(n=5)
Et tunc servamus datam aggregatam inde in tabulam in AWS RDS. Ut proventus aggregationis ad mensam database, scribe methodo obiecti DataFrame utemur;
testResultDataFrame.write
.format("jdbc")
.mode("append")
.option("driver", 'org.postgresql.Driver')
.option("url","jdbc:postgresql://myhabrtest.ciny8bykwxeg.us-east-1.rds.amazonaws.com:5432/habrDB")
.option("dbtable", "transaction_flow")
.option("user", "habr")
.option("password", "habr12345")
.save()
Pauca verba de nexum constituendo ad AWS RDS. Usorem et tesseram creavimus pro eo in "explicando AWS PostgreSQL" gradum. Endpoint uti debes sicut URL server datorum, qui in sectione securitatis & Connectivity ostenditur:
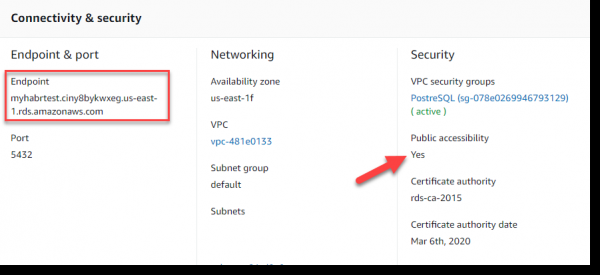
Ut scintillam et Kafka recte iungas, officium debes per submittere artificio utendo. scintilla amne-kafka-0-8_2.11. Accedit, artificio etiam utemur ad commercium cum datorum PostgreSQL, ea per --packages transferemus.
Ad scriptionis flexibilitatem, etiam input parametri nomen ponemus nuntii servi et locum unde notitia accipere volumus.
Tempus itaque est mittere ac deprimere rationem functionis;
spark-submit
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2,
org.postgresql:postgresql:9.4.1207
spark_job.py localhost:9092 transaction
Omnia elaborata! Ut videre potes in tabula infra, dum applicatio currit, novae aggregationis eventus sunt output omnes 2 secundis, quia intervallum ad secundas 2 secundas constituimus cum obiectum StreamingContext creavimus:
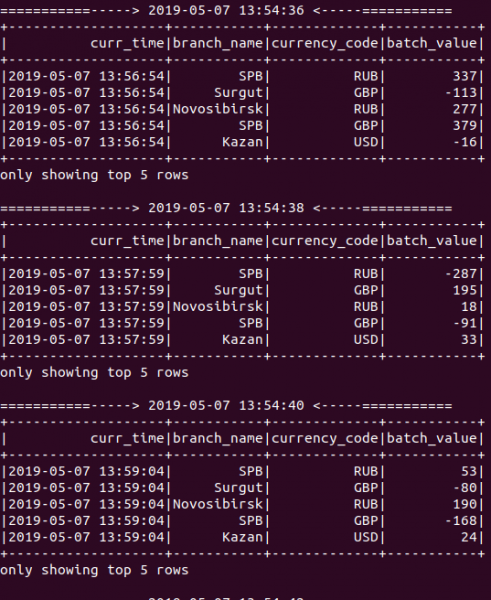
Deinde simplicem interrogationem datorum ut reprimantur praesentia monumentorum in mensa transaction_flow:
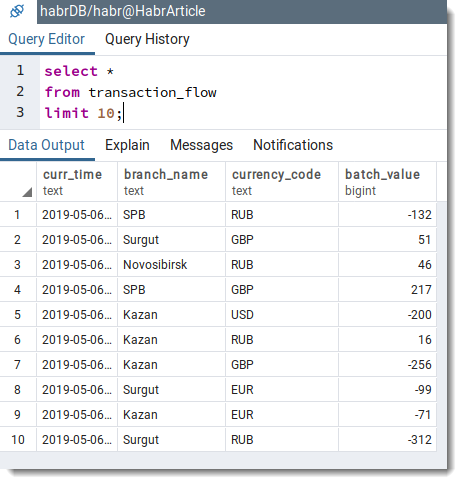
conclusio,
Articulus hic exemplum spectavit processus amnis informationis utendi Spark Streaming in conjunctione cum Apache Kafka et PostgreSQL. Cum ex variis fontibus auctum notitiarum, difficile est aestimare vim practicam Spark Streaming ad diffluentes et reales applicationes creandas.
Potes invenire plenam source codice in repositio at .
Laetus sum de hoc articulo disputare, tuas commentarios exspecto, et etiam spero criticam structuram ab omnibus curantibus legentibus.
Utinam fortuna!
. Initio destinatum est uti database locali PostgreSQL, sed amorem meum AWS datum, decrevi datorum nubem movere. In sequenti articulo de hoc argumento docebo quomodo totam systema, de quibus supra in AWS, utentibus AWS Kinesis et AWS EMR, docebo. Sequere nuntium!
Source: www.habr.com
")