

Moien, Habr! Haut wäerte mir e System bauen deen Apache Kafka Message Streams mat Spark Streaming veraarbecht an d'Veraarbechtungsresultater an d'AWS RDS Cloud Datebank schreiwen.
Loosst eis virstellen datt eng bestëmmte Kreditinstitut eis d'Aufgab setzt fir erakommen Transaktiounen "op der Flucht" iwwer all seng Filialen ze veraarbecht. Dëst kann fir den Zweck gemaach ginn fir eng oppe Währungspositioun fir de Schatzkammer, Limiten oder finanziell Resultater fir Transaktiounen, etc.
Wéi Dir dëse Fall ouni d'Benotzung vu Magie a Magie Zauber ëmsetzen - liest ënner dem Schnëtt! Gitt!

Aféierung
Natierlech gëtt d'Veraarbechtung vun enger grousser Quantitéit un Daten an Echtzäit vill Méiglechkeeten fir an modernen Systemer ze benotzen. Eng vun de populäerste Kombinatioune fir dëst ass den Tandem vun Apache Kafka a Spark Streaming, wou Kafka e Stroum vun erakommen Message Päckchen erstellt, a Spark Streaming dës Päckchen zu engem bestëmmten Zäitintervall veraarbecht.
Fir d'Feeltoleranz vun der Applikatioun ze erhéijen, benotze mir Kontrollpunkte. Mat dësem Mechanismus, wann de Spark Streaming-Motor verluer Donnéeën muss recuperéieren, brauch se nëmmen zréck op de leschte Kontrollpunkt ze goen an d'Berechnungen vun do unzefänken.
Architektur vum entwéckelte System
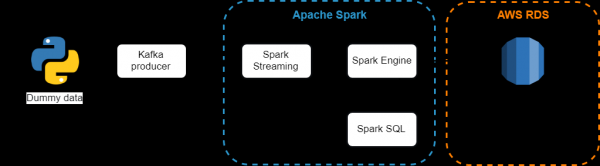
Benotzt Komponenten:
- ass e verdeelt publizéiert-abonnéieren Messagerie System. Gëeegent fir souwuel offline an online Message Konsum. Fir Datenverloscht ze vermeiden, ginn Kafka Messagen op Disk gespäichert a replizéiert am Cluster. De Kafka System gëtt uewen um ZooKeeper Synchroniséierungsservice gebaut;
- - Spark Komponent fir Streaming Daten ze veraarbecht. De Spark Streaming Modul gëtt mat enger Mikro-Batcharchitektur gebaut, wou den Datestroum als eng kontinuéierlech Sequenz vu klengen Datepäck interpretéiert gëtt. Spark Streaming hëlt Daten aus verschiddene Quellen a kombinéiert se a kleng Packagen. Nei Packagen ginn a reegelméissegen Intervalle erstallt. Um Ufank vun all Zäitintervall gëtt en neie Paket erstallt, an all Daten, déi während deem Intervall kritt goufen, sinn am Paket abegraff. Um Enn vum Intervall stoppt de Paketwachstum. D'Gréisst vum Intervall gëtt vun engem Parameter festgeluegt, deen de Batchintervall genannt gëtt;
- - kombinéiert relational Veraarbechtung mat Spark funktionell Programméierung. Strukturéiert Donnéeën bedeit Daten déi e Schema hunn, dat heescht eng eenzeg Rei vu Felder fir all records. Spark SQL ënnerstëtzt Input aus enger Rei vu strukturéierten Datequellen an, dank der Disponibilitéit vun Schemainformatioun, kann et effizient nëmmen déi erfuerderlech Felder vun records recuperéieren, a bitt och DataFrame APIs;
- ass eng relativ preiswerte Cloud-baséiert relational Datebank, Webservice déi d'Setup, d'Operatioun an d'Skaléierung vereinfacht, an direkt vun Amazon verwalt gëtt.
Installéieren a lafen de Kafka Server
Ier Dir Kafka direkt benotzt, musst Dir sécher sinn datt Dir Java hutt, well ... JVM gëtt fir Aarbecht benotzt:
sudo apt-get update
sudo apt-get install default-jre
java -version
Loosst eis en neie Benotzer erstellen fir mat Kafka ze schaffen:
sudo useradd kafka -m
sudo passwd kafka
sudo adduser kafka sudo
Als nächst luet d'Verdeelung vun der offizieller Apache Kafka Websäit erof:
wget -P /YOUR_PATH "http://apache-mirror.rbc.ru/pub/apache/kafka/2.2.0/kafka_2.12-2.2.0.tgz"Auspackt den erofgelueden Archiv:
tar -xvzf /YOUR_PATH/kafka_2.12-2.2.0.tgz
ln -s /YOUR_PATH/kafka_2.12-2.2.0 kafka
De nächste Schrëtt ass fakultativ. D'Tatsaach ass datt d'Standardastellungen Iech net erlaben all d'Features vum Apache Kafka voll ze benotzen. Zum Beispill, läscht en Thema, Kategorie, Grupp op déi Messagen publizéiert kënne ginn. Fir dëst z'änneren, loosst eis d'Konfiguratiounsdatei änneren:
vim ~/kafka/config/server.propertiesFüügt déi folgend um Enn vun der Datei:
delete.topic.enable = trueIer Dir de Kafka Server ufänkt, musst Dir den ZooKeeper Server starten; mir benotze den Hilfsskript dat mat der Kafka Verdeelung kënnt:
Cd ~/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
Nodeems ZooKeeper erfollegräich ugefaang huet, starten de Kafka Server an engem separaten Terminal:
bin/kafka-server-start.sh config/server.propertiesLoosst eis en neit Thema erstellen mam Numm Transaktioun:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic transactionLoosst eis sécher sinn datt en Thema mat der erfuerderter Unzuel u Partitionen a Replikatioun erstallt gouf:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 
Loosst eis d'Momenter verpassen fir de Produzent a Konsument fir dat neit Thema ze testen. Méi Detailer iwwer wéi Dir d'Schécken an d'Empfang vun Messagen testen kënnt sinn an der offizieller Dokumentatioun geschriwwen - . Gutt, mir fuere weider fir e Produzent am Python ze schreiwen mat der KafkaProducer API.
Produzent schreiwen
De Produzent generéiert zoufälleg Donnéeën - 100 Messagen all Sekonn. Mat zoufälleg Donnéeën menge mir e Wierderbuch, deen aus dräi Felder besteet:
- Branch - Numm vum Verkafspunkt vun der Kredittinstitut;
- Währung - Transaktioun Währung;
- Betrag - Transaktioun Betrag. De Betrag wäert eng positiv Zuel sinn wann et e Kaf vun Währung vun der Bank ass, an eng negativ Zuel wann et e Verkaf ass.
De Code fir de Produzent gesäit esou aus:
from numpy.random import choice, randint
def get_random_value():
new_dict = {}
branch_list = ['Kazan', 'SPB', 'Novosibirsk', 'Surgut']
currency_list = ['RUB', 'USD', 'EUR', 'GBP']
new_dict['branch'] = choice(branch_list)
new_dict['currency'] = choice(currency_list)
new_dict['amount'] = randint(-100, 100)
return new_dict
Als nächst, mat der Schéckmethod, schécken mir e Message un de Server, op dat Thema dat mir brauchen, am JSON Format:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:dumps(x).encode('utf-8'),
compression_type='gzip')
my_topic = 'transaction'
data = get_random_value()
try:
future = producer.send(topic = my_topic, value = data)
record_metadata = future.get(timeout=10)
print('--> The message has been sent to a topic:
{}, partition: {}, offset: {}'
.format(record_metadata.topic,
record_metadata.partition,
record_metadata.offset ))
except Exception as e:
print('--> It seems an Error occurred: {}'.format(e))
finally:
producer.flush()
Wann Dir de Skript leeft, kréie mir déi folgend Messagen am Terminal:
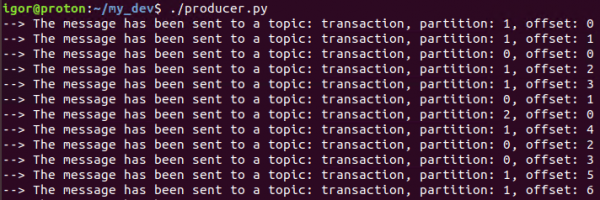
Dëst bedeit datt alles funktionnéiert wéi mir wollten - de Produzent generéiert a schéckt Messagen op dat Thema dat mir brauchen.
De nächste Schrëtt ass Spark z'installéieren an dëse Message Stream ze veraarbecht.
Installéiert Apache Spark
Apache Spark ass eng universell an héich performant Cluster Computing Plattform.
Spark leeft besser wéi populär Implementatioune vum MapReduce Modell wärend eng méi breet Palette vu Berechnungstypen ënnerstëtzt, dorënner interaktiv Ufroen a Streamveraarbechtung. Geschwindegkeet spillt eng wichteg Roll wann Dir grouss Quantitéiten un Daten veraarbecht, well et ass Geschwindegkeet déi Iech erlaabt interaktiv ze schaffen ouni Minutten oder Stonnen ze waarden. Eng vun de gréisste Stäerkten vum Spark, déi et sou séier mécht, ass seng Fäegkeet fir In-Memory Berechnungen auszeféieren.
Dëse Kader ass a Scala geschriwwen, also musst Dir et als éischt installéieren:
sudo apt-get install scalaLuet d'Spark Verdeelung vun der offizieller Websäit erof:
wget "http://mirror.linux-ia64.org/apache/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz"Auspacken den Archiv:
sudo tar xvf spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz -C /usr/local/sparkFüügt de Wee op Spark an d'Bash Datei:
vim ~/.bashrcFüügt déi folgend Zeilen duerch den Editor:
SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
Fëllt de Kommando hei drënner nodeems Dir Ännerungen op bashrc gemaach hutt:
source ~/.bashrcDeploy AWS PostgreSQL
Alles wat bleift ass d'Datebank z'installéieren an déi mir déi veraarbecht Informatioun aus de Streamen eropluede. Fir dëst wäerte mir den AWS RDS Service benotzen.
Gitt op d'AWS Konsole -> AWS RDS -> Datenbanken -> Datebank erstellen:
Wielt PostgreSQL a klickt Next:

Well Dëst Beispill ass nëmme fir pädagogesch Zwecker; mir wäerten e gratis Server "minimum" benotzen (Free Tier):
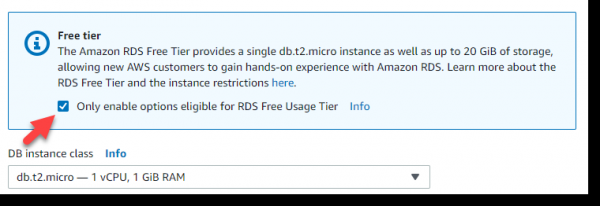
Als nächst setzen mir e Kräiz an de Free Tier Block, an duerno wäerte mir automatesch eng Instanz vun der Klass t2.micro ugebuede ginn - obwuel et schwaach ass, ass et gratis a ganz gëeegent fir eis Aufgab:
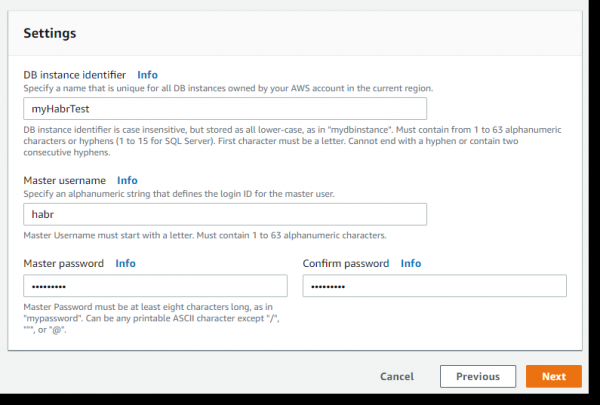
Als nächst kommen ganz wichteg Saachen: den Numm vun der Datebankinstanz, den Numm vum Master Benotzer a säi Passwuert. Loosst eis d'Instanz nennen: myHabrTest, Master Benotzer: habr, Passwuert: habr12345 a klickt op de nächste Knäppchen:
Op der nächster Säit sinn Parameteren verantwortlech fir d'Accessibilitéit vun eisem Datebankserver vu baussen (Ëffentlech Accessibilitéit) a Port Disponibilitéit:
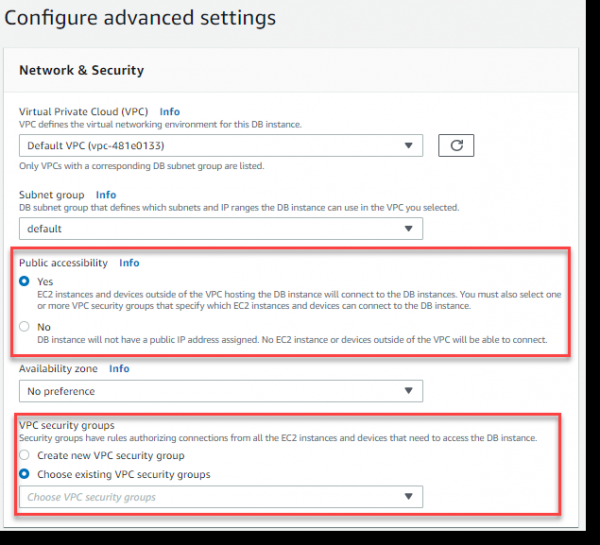
Loosst eis en neien Astellung fir de VPC Sécherheetsgrupp erstellen, deen den externen Zougang zu eisem Datebankserver iwwer Port 5432 (PostgreSQL) erlaabt.
Loosst eis op d'AWS Konsole an enger separater Browserfenster op de VPC Dashboard goen -> Sécherheetsgruppen -> Sécherheetsgrupp erstellen:

Mir setzen den Numm fir d'Sécherheetsgrupp - PostgreSQL, eng Beschreiwung, gitt un wéi eng VPC dës Grupp soll verbonne sinn a klickt op de Knäppchen Erstellen:

Fëllt d'Inbound Regele fir den Hafen 5432 fir déi nei erstallt Grupp aus, wéi am Bild hei drënner. Dir kënnt den Hafen net manuell spezifizéieren, awer wielt PostgreSQL aus der Dropdown-Lëscht Typ.
Streng geschwat bedeit de Wäert ::/0 d'Disponibilitéit vum erakommende Traffic op de Server aus der ganzer Welt, wat kanonesch net ganz richteg ass, awer fir d'Beispill ze analyséieren, loosst eis dës Approche benotzen:
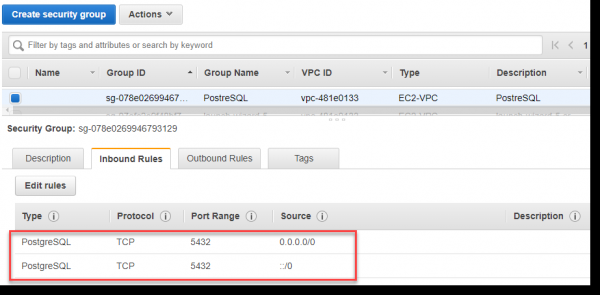
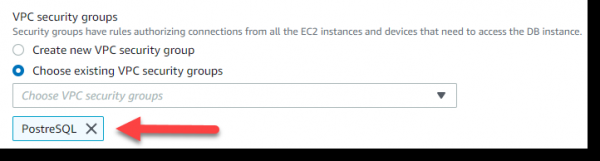
Mir ginn zréck op d'Browser Säit, wou mir "Fortgeschratt Astellungen konfiguréieren" opmaachen a wielt an der VPC Sécherheetsgruppen Sektioun -> Wielt existent VPC Sécherheetsgruppen -> PostgreSQL:
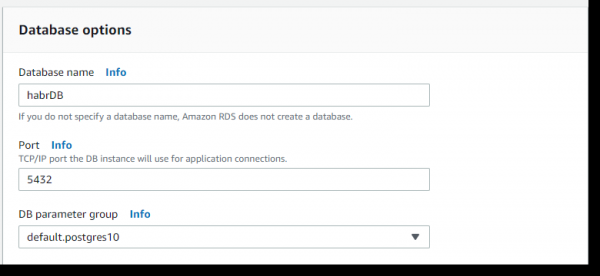
Als nächst, an den Datebank Optiounen -> Datebank Numm -> den Numm setzen - habrDB.
Mir kënnen déi verbleiwen Parameteren verloossen, mat Ausnam vum Desaktivéiere vum Backup (Backup-Retentiounsperiod - 0 Deeg), Iwwerwaachung a Performance Insights, par défaut. Klickt op de Knäppchen Schafen Datebank:
Thread Handler
Déi lescht Etapp ass d'Entwécklung vun engem Spark Job, deen all zwou Sekonnen nei Daten aus Kafka veraarbecht an d'Resultat an d'Datebank aginn.
Wéi uewen ernimmt, sinn Checkpoints e Kärmechanismus am SparkStreaming dee muss konfiguréiert ginn fir Feeler Toleranz ze garantéieren. Mir wäerte Kontrollpunkte benotzen an, wann d'Prozedur klappt, brauch de Spark Streaming Modul nëmmen op de leschte Kontrollpunkt zréckzekommen an d'Berechnungen dovunner erëmzefannen fir déi verluerene Donnéeën ze recuperéieren.
Checkpointing kann aktivéiert ginn andeems Dir e Verzeechnes op engem Feeler-tolerante, zouverléissege Dateiesystem (wéi HDFS, S3, etc.) setzt, an deem d'Kontrollpunktinformatioun gespäichert gëtt. Dëst gëtt gemaach mat, zum Beispill:
streamingContext.checkpoint(checkpointDirectory)An eisem Beispill wäerte mir déi folgend Approche benotzen, nämlech, wann CheckpointDirectory existéiert, da gëtt de Kontext vun de Checkpointdaten erstallt. Wann de Verzeichnis net existéiert (dh fir d'éischte Kéier ausgefouert), da gëtt functionToCreateContext opgeruff fir en neie Kontext ze kreéieren an DStreams ze konfiguréieren:
from pyspark.streaming import StreamingContext
context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
Mir kreéieren en DirectStream Objet fir mam "Transaktioun" Thema ze verbannen mat der createDirectStream Method vun der KafkaUtils Bibliothéik:
from pyspark.streaming.kafka import KafkaUtils
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 2)
broker_list = 'localhost:9092'
topic = 'transaction'
directKafkaStream = KafkaUtils.createDirectStream(ssc,
[topic],
{"metadata.broker.list": broker_list})
Parsing vun erakommen Daten am JSON Format:
rowRdd = rdd.map(lambda w: Row(branch=w['branch'],
currency=w['currency'],
amount=w['amount']))
testDataFrame = spark.createDataFrame(rowRdd)
testDataFrame.createOrReplaceTempView("treasury_stream")
Mat Spark SQL maache mir eng einfach Gruppéierung a weisen d'Resultat an der Konsole:
select
from_unixtime(unix_timestamp()) as curr_time,
t.branch as branch_name,
t.currency as currency_code,
sum(amount) as batch_value
from treasury_stream t
group by
t.branch,
t.currency
Den Ufrotext kréien an duerch Spark SQL lafen:
sql_query = get_sql_query()
testResultDataFrame = spark.sql(sql_query)
testResultDataFrame.show(n=5)
An da späichere mir déi resultéierend aggregéiert Donnéeën an eng Tabell an AWS RDS. Fir d'Aggregatiounsresultater op eng Datebank Tabelle ze späicheren, benotze mir d'Schreifmethod vum DataFrame Objet:
testResultDataFrame.write
.format("jdbc")
.mode("append")
.option("driver", 'org.postgresql.Driver')
.option("url","jdbc:postgresql://myhabrtest.ciny8bykwxeg.us-east-1.rds.amazonaws.com:5432/habrDB")
.option("dbtable", "transaction_flow")
.option("user", "habr")
.option("password", "habr12345")
.save()
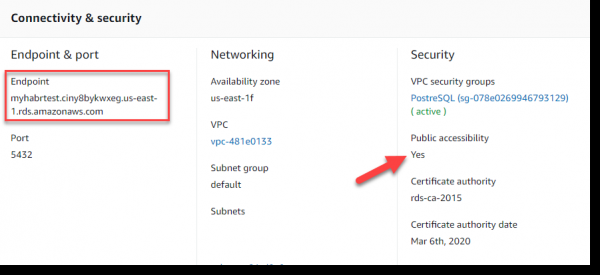
E puer Wierder iwwer d'Opstelle vun enger Verbindung mat AWS RDS. Mir hunn de Benotzer a Passwuert dofir erstallt am Schrëtt "Deploying AWS PostgreSQL". Dir sollt Endpoint als Datebankserver URL benotzen, déi an der Konnektivitéit & Sécherheet Sektioun ugewise gëtt:
Fir Spark a Kafka richteg ze verbannen, sollt Dir d'Aarbecht iwwer smark-submit mam Artefakt lafen spark-streaming-kafka-0-8_2.11. Zousätzlech benotze mir och en Artefakt fir mat der PostgreSQL Datebank ze interagéieren; mir transferéieren se iwwer --Packages.
Fir d'Flexibilitéit vum Skript wäerte mir och als Inputparameter den Numm vum Message Server an d'Thema enthalen, aus deem mir Daten kréien wëllen.
Also, et ass Zäit fir d'Funktionalitéit vum System ze starten an ze kontrolléieren:
spark-submit
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2,
org.postgresql:postgresql:9.4.1207
spark_job.py localhost:9092 transaction
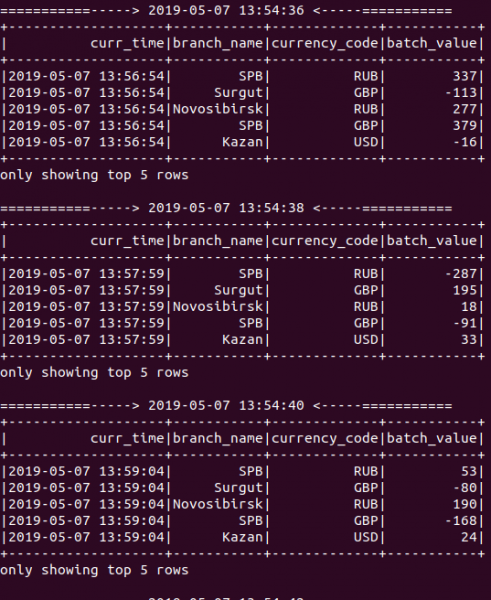
Alles huet geklappt! Wéi Dir op der Foto hei ënnen gesitt, wärend d'Applikatioun leeft, ginn nei Aggregatiounsresultater all 2 Sekonnen erausginn, well mir de Batchintervall op 2 Sekonnen setzen wa mir den StreamingContext Objet erstallt hunn:
Als nächst maache mir eng einfach Ufro un d'Datebank fir d'Präsenz vun de Rekorder an der Tabell ze kontrolléieren Transaktiounsfloss:
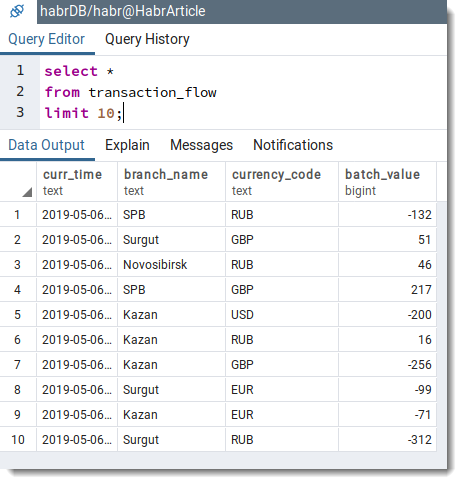
Konklusioun
Dësen Artikel huet e Beispill vun der Streamveraarbechtung vun Informatioun gekuckt mat Spark Streaming a Verbindung mat Apache Kafka a PostgreSQL. Mat dem Wuesstum vun Daten aus verschiddene Quellen ass et schwéier de praktesche Wäert vum Spark Streaming ze iwwerschätzen fir Streaming an Echtzäit Uwendungen ze kreéieren.
Dir fannt de komplette Quellcode a mengem Repository op .
Ech si frou dësen Artikel ze diskutéieren, ech freeën eis op Är Kommentaren, an ech hoffen och op konstruktiv Kritik vun all suergfälteg Lieser.
Ech wënschen Iech Erfolleg!
. Am Ufank war et geplangt eng lokal PostgreSQL Datebank ze benotzen, awer wéinst menger Léift fir AWS hunn ech decidéiert d'Datebank an d'Wollek ze réckelen. Am nächsten Artikel iwwer dëst Thema wäert ech weisen wéi een de ganze System hei uewen beschriwwen an AWS implementéiert mat AWS Kinesis an AWS EMR. Follegt d'Neiegkeeten!
Source: will.com
