


Et deet just déi éischte Kéier wéi!
Moien alleguer! Léif Frënn, an dësem Artikel wëll ech meng Erfahrung mat TensorRT ze deelen, RetinaNet baséiert op dem Repository (dëst ass eng Gabel vun der offizieller Rüben aus , wat Iech erlaabt Iech optimiséiert Modeller an der Produktioun sou séier wéi méiglech ze benotzen). Scrollen duerch Messagen a Gemeinschaftskanäl , Ech lafen op Froen iwwer d'Benotzung vun TensorRT an d'Froen widderhuelen meeschtens, also hunn ech beschloss ze schreiwen esou komplett wéi méiglech E Guide fir séier Inferenz ze benotzen baséiert op TensorRT, RetinaNet, Unet an Docker.
Aufgab Beschreiwung
Ech proposéieren, d'Aufgab op dës Manéier ze formuléieren: mir mussen den Datesaz beschrëften, den RetinaNet/Unet-Netz op Pytorch 1.3+ trainéieren, déi kritt Gewiichter an ONNX konvertéieren, dann an den TensorRT-Motor konvertéieren an dat Ganzt an Docker ausféieren, am léifsten op ... Ubuntu 18 an héich wënschenswäert op der ARM (Jetson)* Architektur, wouduerch d'manuell Asaz vun der Ëmfeld miniméiert gëtt. D'Ennresultat wäert e Container sinn, deen net nëmme fir den Export an d'Training vu RetinaNet/Unet prett ass, mä och fir eng vollwäerteg Entwécklung an Training vu Klassifikatiouns- a Segmentéierungssystemer, mat all der néideger Hardware.
Etapp 1. Virbereedung vun der Ëmwelt
Et ass wichteg hei ze notéieren datt ech viru kuerzem d'Benotzung an d'Deployment vun op d'mannst e puer Bibliothéiken op enger Desktop Maschinn komplett opginn hunn, souwéi op Devbox. Dat eenzegt wat Dir musst erstellen an installéieren ass Python virtuell Ëmfeld an cuda 10.2 (Dir kënnt Iech op ee nvidia Chauffer limitéieren) vun deb.
Loosst eis dovun ausgoen, datt Dir eng frësch installéiert hutt Ubuntu 18. Loosst eis cuda 10.2 (deb) installéieren. Ech ginn net am Detail op den Installatiounsprozess an, déi offiziell Dokumentatioun ass ganz duer.
Loosst eis den Docker installéieren, den Docker Installatiounsguide kann einfach fonnt ginn, hei ass e Beispill , Versioun 19+ ass scho verfügbar - installéiere se. Gutt, vergiesst net et méiglech ze maachen Docker ouni Sudo ze benotzen, et wäert méi praktesch sinn. Nodeems alles geschafft huet, maache mir dat:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
An Dir musst net emol den offiziellen Repository kucken .
Loosst eis elo Git Klonen maachen .
Et ass just e bësse lénks, fir Docker mat engem nvidia Bild ze benotzen, musse mir eis mat NGC Cloud registréieren an aloggen. Loosst eis heihinner goen , registréiert an nodeems mir an NGC Cloud kommen, klickt op SETUP an der ieweschter lénkser Ecke vum Écran oder befollegt dëse Link . Klickt op "Schlëssel generéieren". Ech recommandéieren et ze späicheren, soss musst Dir déi nächst Kéier wann Dir et besicht, et erëm generéieren an deementspriechend op en neien Auto ofsetzen an dës Operatioun widderhuelen.
Loosst eis maachen:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Benotzernumm gëtt einfach kopéiert. Gutt, betruecht d'Ëmwelt ofgesat!
Etapp 2: Bau vum Docker Container
Op der zweeter Etapp vun eiser Aarbecht wäerte mir Docker bauen a mat hiren Internen kennenzeléieren.
Loosst eis an de Root Dossier a Relatioun mam Netzhaut-Beispiller Projet goen an ausféieren
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Mir bauen Docker andeems Dir den aktuelle Benotzer an et passéiert - dëst ass ganz nëtzlech wann Dir eppes op e montéierte VOLUME schreift mat de Rechter vum aktuelle Benotzer, soss wäert et root a Péng sinn.
Wärend den Docker baut, loosst eis den Dockerfile ënnersichen:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Wéi Dir aus dem Text gesitt, huelen mir all eis Liiblingsbibliothéiken, kompilléiere Retinanet, fügen e puer Basis-Tools derbäi fir d'Aarbecht méi einfach ze maachen. Ubuntu an den OpenSSH Server konfiguréieren. Déi éischt Zeil ierft den NVIDIA Image, fir deen mir den NGC Cloud Login erstallt hunn an deen Pytorch1.3, TensorRT6.xxx an eng ganz Rëtsch aner Bibliothéiken enthält, déi et eis erlaben, de CPP Quellcode fir eisen Detektor ze kompiléieren.
Stage 3: Den Docker Container starten an Debugging
Loosst eis op den Haaptfall goen fir de Container an d'Entwécklungsëmfeld ze benotzen; als éischt, loosst eis den nvidia Docker starten. Loosst eis maachen:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestDe Container ass elo iwwer ssh zougänglech @localhost. Nom erfollegräiche Start, öffnen de Projet am PyCharm. Als nächst maache mer op
Settings->Project Interpreter->Add->Ssh Interpreter Schrëtt 1
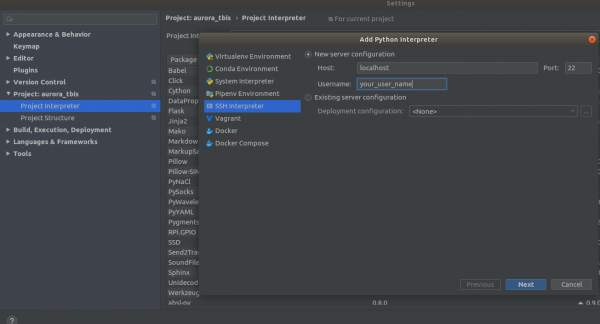
Schrëtt 2
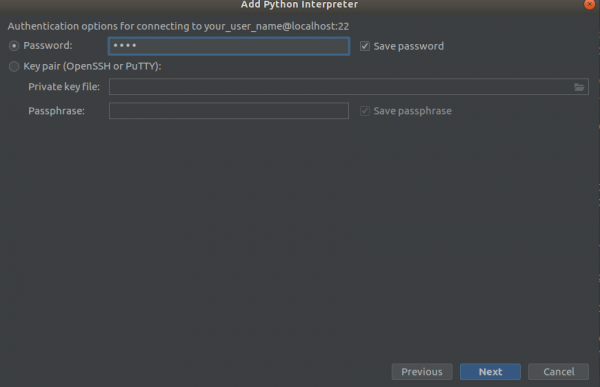
Schrëtt 3
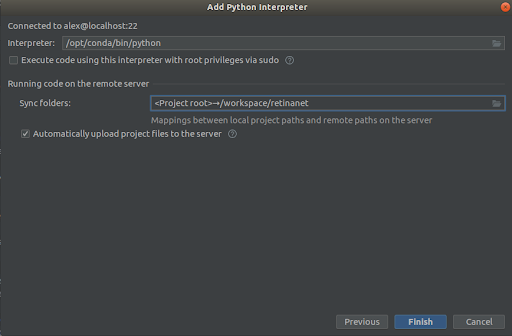
Mir wielt alles wéi an de Screenshots,
Interpreter -> /opt/conda/bin/python- dëst wäert ln am Python3.6 an
Sync folder -> /workspace/retinanetMir drécken op Finish, waarden op Indexéierung, an dat ass et, d'Ëmwelt ass prett fir ze benotzen!
WICHTEG!!! Direkt no der Indexéierung, zitt déi kompiléiert Dateie fir Retinanet vum Docker. Am Kontextmenü an der Projektroot, wielt den Artikel
Deployment->DownloadEng Datei an zwee Ordner erschéngen: build, retinanet.egg-info an _С.so
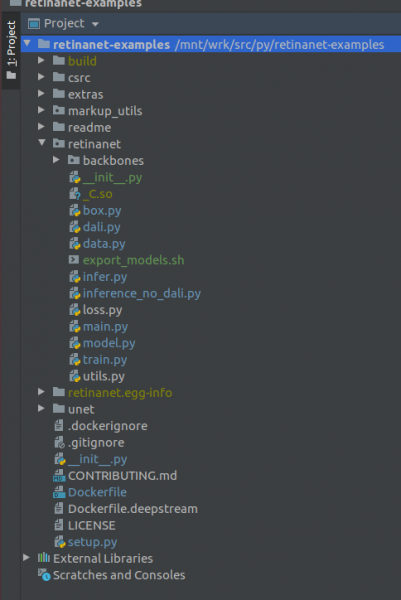
Wann Äre Projet esou ausgesäit, da gesäit d'Ëmwelt all déi néideg Dateien a mir si prett fir RetinaNet ze trainéieren.
Etapp 4. Label d'Donnéeën an trainéiert den Detektor
Fir Markup benotzen ech haaptsächlech - en agreabelt a praktescht Tool, viru kuerzem sinn eng Rëtsch Bugs fixéiert an et ass wesentlech besser behuelen.
Loosst eis unhuelen datt Dir d'Datebank markéiert hutt an erofgelueden hutt, awer Dir kënnt et net direkt an eise RetinaNet setzen, well et a sengem eegene Format ass a fir dëst musse mir et op COCO konvertéieren. D'Konversiounstool ass an:
markup_utils/supervisly_to_coco.pyNotéiert w.e.g. datt d'Kategorie am Skript e Beispill ass an Dir musst Är eege setzen (et ass net néideg d'Hannergrondkategorie bäizefügen)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Aus e puer Grënn hunn d'Auteuren vum urspréngleche Repository decidéiert datt Dir näischt anescht wéi COCO/VOC fir d'Detektioun trainéiert, also hu se d'Quelldatei e bëssen z'änneren
retinanet/dataset.pyAndeems Dir Är Liiblingsvergréisserungen hei bäidréit a schneide hard-wired Kategorien aus COCO aus. Et ass och méiglech grouss Detektiounsberäicher ze cropéieren, wann Dir kleng Objeten a grousse Biller sicht, hutt Dir e klengen Dataset =), an näischt funktionnéiert, awer méi doriwwer eng aner Kéier.
Am Allgemengen ass d'Zuchschleife och schwaach, am Ufank huet et keng Kontrollpunkte gespuert, et huet eng Aart vu schreckleche Scheduler benotzt, asw. Awer elo alles wat Dir maache musst ass de Backbone auswielen an auszeféieren
/opt/conda/bin/python retinanet/main.pymat Parameteren:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
An der Konsole gesitt Dir:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Fir de ganze Set vu Parameteren ze entdecken, kuckt
retinanet/main.pyAm Allgemengen, si Standard fir Detectioun, a si hunn eng Beschreiwung. Start den Training a waart op d'Resultater. E Beispill vun Inferenz ka gesi ginn an:
retinanet/infer_example.pyoder lafen de Kommando:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
De Repository huet scho Focal Loss a verschidde Backbones agebaut, an et ass och einfach Ären eegenen z'integréieren
retinanet/backbones/*.pyAn der Tabell ginn d'Auteuren e puer Charakteristiken:
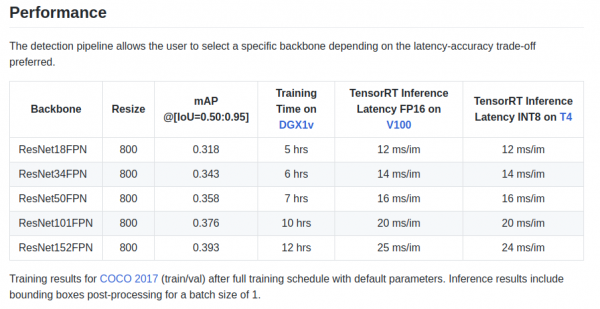
Et gëtt och e Réckgrat ResNeXt50_32x4dFPN an ResNeXt101_32x8dFPN, aus Torchvision geholl.
Ech hoffen Dir hutt d'Detektioun e bëssen erausfonnt, awer Dir sollt definitiv déi offiziell Dokumentatioun liesen fir datt verstoen Export- a Logmodus.
Etapp 5. Export an Inferenz vun Unet Modeller mat Resnet encoder
Wéi Dir wahrscheinlech gemierkt hutt, goufen d'Bibliothéike fir Segmentatioun an der Dockerfile installéiert, a besonnesch déi wonnerbar Librairie. . Am unitet Package kënnt Dir Beispiller vun Inferenz an Export vu Pytorch Checkpoints op den TensorRT Motor fannen.
Den Haaptproblem beim Export vun Unet-ähnleche Modeller vun ONNX op TensoRT ass d'Notzung fir eng fix Upsample Gréisst ze setzen oder ConvTranspose2D ze benotzen:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Mat dëser Transformatioun kënnt Dir dëst automatesch maachen wann Dir op ONNX exportéiert, awer schonn an der Versioun 7 vun TensorRT gouf dëse Problem geléist, a mir musse zimmlech waarden.
Konklusioun
Wéi ech ugefaang hunn Docker ze benotzen, hat ech Zweifel iwwer seng Leeschtung fir meng Aufgaben. Eng vun mengen Unitéiten huet de Moment zimlech vill Netzverkéier generéiert vu verschiddene Kameraen.
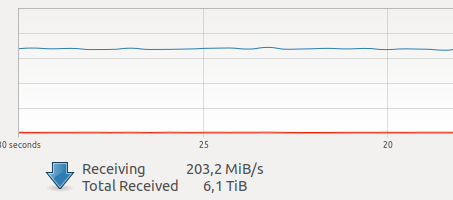
Verschidde Tester um Internet hunn e relativ groussen Overhead fir Netzwierkinteraktioun an Opnam op VOLUME uginn, plus déi onbekannt a schrecklech GIL, a well e Frame erfaasst, de Chauffer bedreiwen an de Frame iwwer d'Netz iwwerdroen ass eng atomar Operatioun am Modus schwéier Echtzäit, Reseau Verspéidungen si ganz kritesch fir mech.
Mee alles ass ok geklappt =)
PS Alles wat bleift ass Äre Liiblingszuchschleife fir Segmentéierung a Produktioun ze addéieren!
Merci
Merci der Gemeng , ouni et ass onméiglech ze entwéckelen! Villmols merci , deen mech encouragéiert huet DL ze maachen, fir seng onschätzbar Berodung an extrem Professionalitéit!
Benotzt optimiséiert Modeller an der Produktioun!
 Aurorai, LLC
Aurorai, LLC
Source: will.com
