

Dës Notiz wäert interessant sinn fir déi, déi d'Tabulardatenveraarbechtungsbibliothéik fir R benotzen - data.table, a kënne frou sinn d'Flexibilitéit vu senger Benotzung a verschiddene Beispiller ze gesinn.
Inspiréiert vun engem gudde Beispill , an hoffen datt Dir säin Artikel scho gelies hutt, proposéieren ech méi déif Richtung Code Optimiséierung a Leeschtung baséiert op data.tabell.
Aféierung: Wou kommen daten.Table hier?
Et ass am beschten fir d'Bibliothéik e bësse vu wäitem ze kennenzeléieren, nämlech mat den Datestrukturen, aus deenen den Data.Table-Objet (nodréiglech DT bezeechent) kritt.
Array
Code
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Eng esou Struktur ass eng Array (?base::array). Wéi an anere Sproochen sinn Arrays hei multidimensional. Wéi och ëmmer, déi interessant Saach ass datt zum Beispill eng zweedimensional Array ufänkt Eegeschafte vun der Matrixklass ze ierwen (?base::matrix), an eng eendimensional Array, déi och wichteg ass, ierft net vun engem Vektor (?base::vektor).
Et sollt verstane ginn datt d'Zort vun Daten an all Objet enthale soll mat der Funktioun gepréift ginn base :: typeof, déi d'intern Typbeschreiwung no R Internal - den allgemenge Protokoll vun der Sprooch, déi mam Original ass C.
En anere Kommando fir d'Klass vun engem Objet ze bestëmmen ass Basis :: Klass, am Fall vu Vektoren, gëtt de Vektortyp zréck (et ënnerscheet sech am Numm vum internen, awer erlaabt Iech och d'Datentyp ze verstoen).
Lëscht
Vun engem zweedimensionalen Array, och bekannt als Matrix, kënnt Dir op d'Lëscht goen (?Basis :: Lëscht).
Code
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Verschidde Saachen geschéien op eemol:
- Déi zweet Dimensioun vun der Matrix fällt zesummen, dat heescht, mir kréien souwuel eng Lëscht wéi och e Vektor zur selwechter Zäit.
- D'Lëscht ierft also vun dëse Klassen. Et muss am Kapp behalen ginn datt e Lëschtelement engem (scalar) Wäert vun enger Zell vun der Array Matrix entsprécht.
Well eng Lëscht och e Vektor ass, kënnen e puer Vektorfunktiounen op se applizéiert ginn.
Dateframe
Dir kënnt vun enger Lëscht, Matrix oder Vektor an en Dateframe goen (?base::data.frame).
Code
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Wat ass interessant doriwwer: den Dateframe ierft aus der Lëscht! Dataframe Kolonnen sinn Lëschtzellen. Dëst wäert méi spéit wichteg sinn wa mir Funktiounen op Lëschten applizéiert benotzen.
data.tabell
Get DT (?data.table::data.table) kann aus dateframe, Lëscht, Vektor oder Matrix. Zum Beispill, wéi dëst (op der Plaz).
Code
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Et ass nëtzlech datt, wéi en Dataframe, en DT d'Eegeschafte vun enger Lëscht ierft.
DT an Erënnerung
Am Géigesaz zu all aner Objeten an der R Basis, ginn DTs duerch Referenz weiderginn. Wann Dir musst eng Kopie op eng nei Erënnerung Beräich maachen, Dir braucht eng Funktioun data.table :: kopéieren oder Dir musst eng Auswiel aus dem alen Objet maachen.
Code
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Dëst schléisst d'Aféierung. DT ass eng Fortsetzung vun der Entwécklung vun Datestrukturen am R, déi haaptsächlech geschitt wéinst der Expansioun an der Beschleunigung vun Operatiounen, déi op Objekter vun der Dataframe Klass ausgefouert ginn. Zur selwechter Zäit ass d'Ierfschaft vun anere Primitiv bewahrt.
E puer Beispiller fir d'Benotzung vun data.table Eegeschaften
Wéi eng Lëscht ...
Iteréieren iwwer d'Reihen vun engem Dataframe oder DT ass keng gutt Iddi, well de Loopcode an der Sprooch R vill méi lues C, awer et ass ganz méiglech duerch d'Säulen ze schloen, déi normalerweis vill méi kleng sinn. Gitt duerch d'Kolonn, erënnert un datt all Kolonn en Element vun enger Lëscht ass, normalerweis e Vektor. An Operatiounen op Vecteure si gutt vektoriséiert an de Basisfunktiounen vun der Sprooch. Dir kënnt och Selektiounsbedreiwer benotzen, déi allgemeng fir Lëschten a Vecteure sinn: `[[`, `$`.
Code
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vectorization
Wann et néideg ass duerch d'Linnen vun engem groussen DT ze goen, wier déi bescht Léisung eng Funktioun mat Vektoriséierung ze schreiwen. Awer wann dëst net funktionnéiert, da sollt Dir drun erënneren datt den Zyklus innerhalb DT ass ëmmer méi séier wéi de Zyklus R, well et opgefouert gëtt C.
Loosst eis et op e gréissere Beispill mat 100K Reihen probéieren. Mir extrahéieren den éischte Bréif aus de Wierder, déi an der Vektorkolonne abegraff sinn w.
aktualiséiert
Code
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Éischt lafen Iteratioun iwwer Reihen:
Eenheet: Millisekonnen
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fix = T))[1]), vun = 1:nrow(dt)] } 439.6217
lq Mëttelméisseg uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Déi zweet Laf, wou Vektoriséierung geschitt andeems d'Lëscht an eng Matrix ëmgewandelt gëtt an Elementer op der Slice mam Index 1 huelen (déi lescht ass d'Vektoriséierung selwer). Korrektur: Vektoriséierung um Funktiounsniveau strsplit, deen e Vektor als Input akzeptéiere kann. Et stellt sech eraus datt d'Prozedur fir eng Lëscht an eng Matrix ze maachen ass vill méi schwéier wéi d'Vektoriséierung selwer, awer an dësem Fall ass et vill méi séier wéi déi net-vektoriséiert Versioun.
Eenheet: Millisekonnen
expr min lq heeschen Median uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Beschleunegung duerch Median an 3 Mol.
Déi drëtt Course, wou d'Transformatiounsschema an d'Matrix geännert gouf.
Eenheet: Millisekonnen
expr min lq heeschen Median uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Beschleunegung duerch Median an 13 Mol.
Dir musst mat dëser Matière experimentéieren, wat méi, wat besser et wäert sinn.
En anert Beispill mat Vektoriséierung, wou et och Text gëtt, awer et ass no bei realen Bedéngungen: verschidde Längt vu Wierder, aner Zuel vu Wierder. Dir musst déi éischt 3 Wierder kréien. Esou:
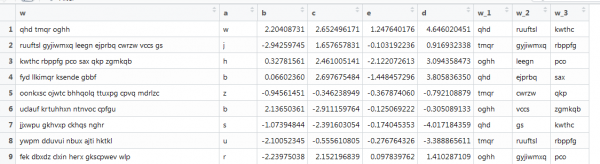
Hei funktionnéiert déi viregt Funktioun net, well d'Vektore vu verschiddene Längt sinn, a mir setzen d'Matrixgréisst. Loosst eis dat nei maachen andeems Dir um Internet gräift.
Code
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Eenheet: Millisekonnen
expr min lq heeschen Median
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fix = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
De Skript leeft mat enger Duerchschnëttsgeschwindegkeet vun 1 Sekonn. Net schlecht.
Verbonne mat enger Kette ...
Dir kënnt mat DT Objete mat Ketten schaffen. Et gesäit aus wéi d'Bracket Syntax no riets befestegt, am Wesentlechen Zocker.
Code
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Fléisst duerch d'Päifen ...
Déiselwecht Operatioune kënnen iwwer Piping gemaach ginn, et gesäit ähnlech aus, awer ass funktionell méi räich, well Dir all Methode benotze kënnt, net nëmmen DT. Loosst eis logistesch Regressiounskoeffizienten fir eis synthetesch Daten mat enger Zuel vu Filtere op DT ofleeden.
Code
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistiken, Maschinn Léieren a méi bannent DT
Dir kënnt Lambda Funktiounen benotzen, awer heiansdo ass et besser se separat ze kreéieren, déi ganz Datenanalyse Pipeline ze schreiwen, a virugoen - si schaffen am DT. D'Beispill ass beräichert mat all den uewe genannten Features, plus e puer nëtzlech Saachen aus dem DT Arsenal (wéi zum Beispill Zougang zum DT selwer am DT iwwer e Link, heiansdo net sequenziell agebaut, awer sou datt et ass).
Code
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
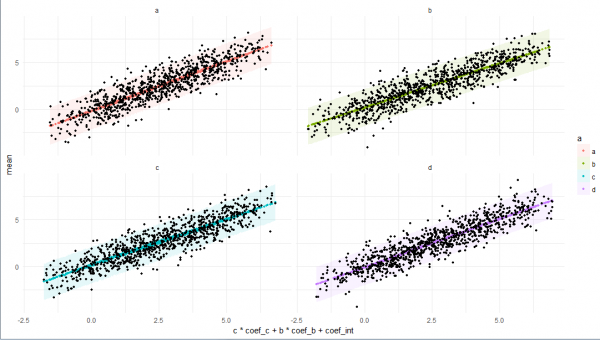
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Konklusioun
Ech hoffen, datt ech konnt e komplett, awer, natierlech, net komplett, Bild vun esou engem Objet wéi Data.table ze schafen, ugefaange vu sengen Eegeschafte verbonne mat Ierfschaft aus R Klassen a mat hiren eegene Fonctiounen an Ëmwelt aus tidyverse Elementer ophalen. . Ech hoffen dat hëlleft Iech fir dës Bibliothéik besser ze léieren an ze benotzen fir ze schaffen an Ënnerhalung.
Merci!
Voll Code
Code
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Source: will.com
