


Энэ нь зөвхөн анх удаа өвдөж байна!
Сайн уу! Эрхэм найзууд аа, энэ нийтлэлд би агуулах дээр суурилсан TensorRT, RetinaNet ашиглах туршлагаа хуваалцахыг хүсч байна. (энэ нь албан ёсны манжингийн сэрээ юм , энэ нь оновчтой загваруудыг үйлдвэрлэлд аль болох хурдан ашиглаж эхлэх боломжийг олгоно). Олон нийтийн сувгууд дахь мессежүүдийг гүйлгэж байна , Би TensorRT ашиглах талаар асуултуудтай тулгарч байгаа бөгөөд асуултууд ихэвчлэн давтагдаж байгаа тул бичихээр шийдсэн аль болох бүрэн гүйцэд TensorRT, RetinaNet, Unet болон docker дээр суурилсан хурдан дүгнэлтийг ашиглах гарын авлага.
Даалгаврын тодорхойлолт
Би даалгаврыг дараах байдлаар томъёолохыг санал болгож байна: бид өгөгдлийн багцыг шошголж, RetinaNet/Unet сүлжээг Pytorch 1.3+ дээр сургаж, олж авсан жинг ONNX болгон хөрвүүлж, дараа нь тэдгээрийг TensorRT хөдөлгүүр рүү хөрвүүлж, бүх зүйлийг Docker дээр, болж өгвөл дээр ажиллуулах хэрэгтэй. Ubuntu 18 бөгөөд ARM (Jetson)* архитектур дээр маш их хүсүүштэй бөгөөд ингэснээр орчныг гараар байршуулахыг багасгадаг. Эцсийн үр дүн нь зөвхөн RetinaNet/Unet-ийг экспортлох, сургахад төдийгүй ангилал, сегментчиллийн системийг бүрэн хөгжүүлэх, сургахад шаардлагатай бүх техник хангамжтай бэлэн контейнер байх болно.
Үе шат 1. Байгаль орчныг бэлтгэх
Саяхан би ширээний компьютер, түүнчлэн devbox дээр зарим номын санг ашиглах, байршуулахаас бүрэн татгалзсан гэдгийг энд тэмдэглэх нь чухал юм. Таны үүсгэж суулгах цорын ганц зүйл бол python виртуал орчин болон deb-ээс cuda 10.2 (та нэг nvidia драйвераар өөрийгөө хязгаарлаж болно) юм.
Та шинээр суулгасан гэж бодъё Ubuntu 18. cuda 10.2 (deb)-г суулгацгаая. Би суулгах процессын талаар дэлгэрэнгүй ярихгүй, албан ёсны баримт бичиг хангалттай.
Одоо docker суулгацгаая, docker суулгах гарын авлагыг хялбархан олох боломжтой, энд жишээ байна , 19+ хувилбар аль хэдийн бэлэн болсон - үүнийг суулгана уу. За, docker-ийг sudoгүйгээр ашиглах боломжтой болгохоо бүү мартаарай, энэ нь илүү тохиромжтой байх болно. Бүх зүйл дууссаны дараа бид үүнийг хийдэг:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Мөн та албан ёсны агуулахыг үзэх шаардлагагүй .
Одоо git clone хийцгээе .
Жаахан үлдлээ, nvidia дүрс бүхий docker ашиглаж эхлэхийн тулд бид NGC Cloud-т бүртгүүлж, нэвтрэх шаардлагатай болно. Энд явцгаая , бүртгүүлээд NGC Cloud-д орсны дараа дэлгэцийн зүүн дээд буланд байрлах SETUP дээр дарах эсвэл энэ холбоосыг дагана уу. . "Түлхүүр үүсгэх" дээр дарна уу. Би үүнийг хадгалахыг зөвлөж байна, эс тэгвээс та дараагийн удаад зочлохдоо үүнийг дахин үүсгэж, үүний дагуу шинэ машин дээр байрлуулж, энэ үйлдлийг давтах шаардлагатай болно.
Хийцгээе:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Хэрэглэгчийн нэрийг зүгээр л хуулсан. За, байршуулсан орчныг анхаарч үзээрэй!
2-р шат: Докерын савыг барих
Ажлынхаа 2-р шатанд бид докер барьж, түүний дотоод байдалтай танилцах болно.
Retina-examples төсөлтэй холбоотой root хавтас руу орж ажиллуулъя
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Бид докерыг одоогийн хэрэглэгч рүү шилжүүлэх замаар бүтээдэг - хэрэв та одоогийн хэрэглэгчийн эрхээр холбогдсон VOLUME-д ямар нэгэн зүйл бичвэл энэ нь маш хэрэгтэй бөгөөд эс тэгвээс энэ нь үндэс болон өвдөлт болно.
Докер бүтээж байх хооронд Dockerfile-ийг шалгая:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Текстээс харахад бид дуртай бүх номын сангуудаа авч, retinanet-ийг эмхэтгэж, ажиллахад хялбар болгохын тулд зарим үндсэн хэрэгслүүдийг оруулсан болно. Ubuntu мөн OpenSSH серверийг тохируулах. Эхний мөр нь бидний NGC Cloud нэвтрэлтийг үүсгэсэн NVIDIA зургийг өвлөн авдаг бөгөөд энэ нь бидэнд илрүүлэгчийнхээ CPP эх кодыг эмхэтгэх боломжийг олгодог Pytorch1.3, TensorRT6.xxx болон бусад олон сангуудыг агуулдаг.
3-р үе шат: Докерын контейнерыг ажиллуулж, дибаг хийх
Контейнер болон хөгжүүлэлтийн орчинг ашиглах үндсэн тохиолдол руу шилжиж эхлээд nvidia docker-ийг ажиллуулъя; Хийцгээе:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestУг контейнерт одоо ssh-ээр хандах боломжтой @localhost. Амжилттай эхлүүлсний дараа төслийг PyCharm дээр нээнэ үү. Дараа нь бид нээнэ
Settings->Project Interpreter->Add->Ssh Interpreter 1 алхам
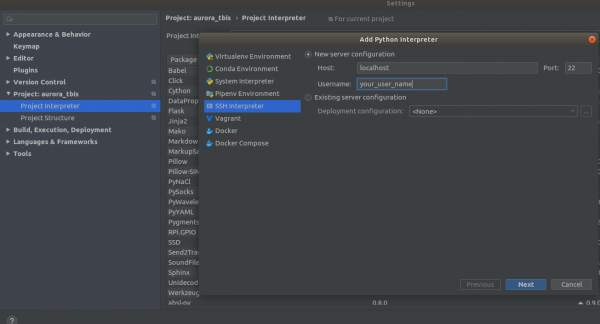
2 алхам
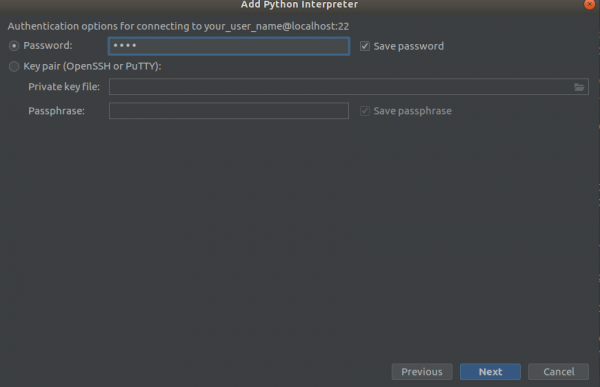
3 алхам
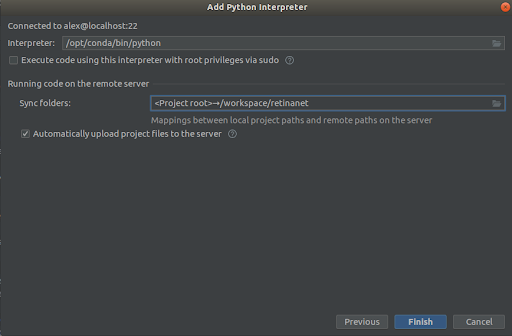
Бид дэлгэцийн агшин дээрх шиг бүгдийг сонгоно.
Interpreter -> /opt/conda/bin/python- энэ нь Python3.6 дээр ln байх болно
Sync folder -> /workspace/retinanetБид дуусгах товчийг дарж, индексжүүлэхийг хүлээнэ үү, тэгээд л орчин ашиглахад бэлэн боллоо!
ЧУХАЛ!!! Индексжүүлсний дараа тэр даруй Retinanet-д зориулж хөрвүүлсэн файлуудыг докероос татаж аваарай. Төслийн үндэс дэх контекст цэснээс тухайн зүйлийг сонгоно уу
Deployment->DownloadНэг файл, хоёр хавтас гарч ирнэ: build, retinanet.egg-info болон _С.so
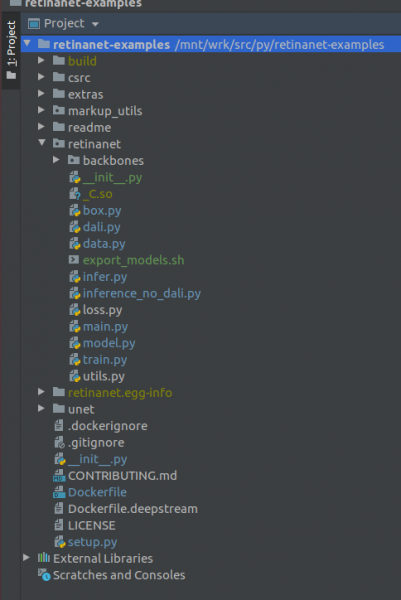
Хэрэв таны төсөл иймэрхүү харагдаж байвал орчин нь шаардлагатай бүх файлуудыг хардаг бөгөөд бид RetinaNet-ийг сургахад бэлэн байна.
Үе шат 4. Өгөгдлийг шошгож, илрүүлэгчийг сурга
Тэмдэглэгээний хувьд би голчлон ашигладаг - тааламжтай, тохиромжтой хэрэгсэл, саяхан олон тооны алдаануудыг засч, илүү боловсронгуй болсон.
Та өгөгдлийн багцыг тэмдэглээд татаж авсан гэж бодъё, гэхдээ та үүнийг манай RetinaNet-д шууд оруулах боломжгүй, учир нь энэ нь өөрийн гэсэн форматтай тул бид үүнийг COCO болгон хөрвүүлэх хэрэгтэй. Хөрвүүлэх хэрэгсэл нь дараах хэсэгт байрладаг:
markup_utils/supervisly_to_coco.pyСкрипт дэх Ангилал нь жишээ бөгөөд та өөрөө оруулах шаардлагатай гэдгийг анхаарна уу (арын ангилал нэмэх шаардлагагүй)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Зарим шалтгааны улмаас анхны репозиторын зохиогчид таныг илрүүлэхийн тулд COCO/VOC-ээс өөр зүйл сургахгүй гэж шийдсэн тул эх файлыг бага зэрэг засварлах шаардлагатай болсон.
retinanet/dataset.pyӨөрийн дуртай нэмэлтүүдийг энд нэмснээр мөн COCO-аас хатуу утастай категорийг хайчилж ав. Мөн том илрүүлэлтийн талбайг тайрах боломжтой, хэрвээ та том зураг дээр жижиг объект хайж байгаа бол танд жижиг өгөгдлийн багц байгаа =), юу ч ажиллахгүй, гэхдээ өөр нэг удаа.
Ерөнхийдөө галт тэрэгний гогцоо бас сул, эхэндээ хяналтын цэгүүдийг хэмнээгүй, ямар нэгэн аймшигтай хуваарь ашигладаг байсан гэх мэт. Харин одоо нуруугаа сонгоод гүйцэтгэх л үлдлээ
/opt/conda/bin/python retinanet/main.pyпараметрүүдтэй:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
Консол дээр та дараахь зүйлийг харах болно.
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Бүхэл бүтэн параметрүүдийг судлахын тулд харна уу
retinanet/main.pyЕрөнхийдөө тэдгээр нь илрүүлэх стандарт бөгөөд тэдгээр нь тайлбартай байдаг. Сургалтыг эхлүүлж, үр дүнг хүлээнэ үү. Дүгнэлтийн жишээг дараахь байдлаар харж болно.
retinanet/infer_example.pyэсвэл тушаалыг ажиллуулна уу:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
Хадгалах газар аль хэдийн Фокусын алдагдал болон хэд хэдэн тулгуур системтэй бөгөөд үүнийг өөрөө суулгахад хялбар байдаг.
retinanet/backbones/*.pyХүснэгтэнд зохиогчид зарим шинж чанарыг өгдөг.
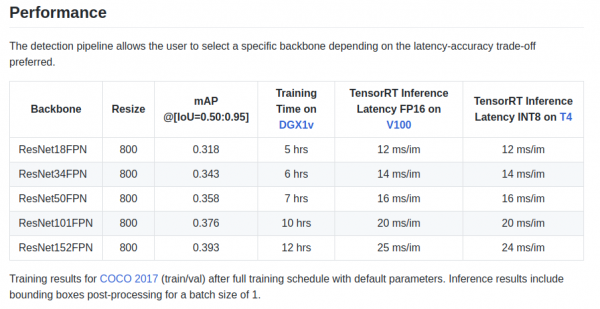
Мөн torchvision-ээс авсан ResNeXt50_32x4dFPN болон ResNeXt101_32x8dFPN-ийн үндсэн суурь байдаг.
Та илрүүлэлтийг бага зэрэг ойлгосон гэж найдаж байна, гэхдээ та албан ёсны баримт бичгийг заавал унших хэрэгтэй экспорт болон бүртгэлийн горимуудыг ойлгох.
Үе шат 5. Resnet кодлогчтой Unet загваруудыг экспортлох, дүгнэлт хийх
Докер файлд сегментчлэх сангууд, ялангуяа гайхалтай lib-д суулгагдсаныг та анзаарсан байх. . Unite багцаас та pytorch хяналтын цэгүүдийг TensorRT хөдөлгүүрт гаргах, экспортлох жишээг олж болно.
Unet-тэй төстэй загваруудыг ONNX-ээс TensoRT руу экспортлоход тулгардаг гол асуудал бол тогтмол дээжийн хэмжээг тохируулах эсвэл ConvTranspose2D-г ашиглах хэрэгцээ юм.
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Энэхүү хувиргалтыг ашигласнаар та үүнийг ONNX руу экспортлохдоо автоматаар хийх боломжтой, гэхдээ TensorRT-ийн 7-р хувилбар дээр энэ асуудал шийдэгдсэн тул бид бага зэрэг хүлээх хэрэгтэй болно.
дүгнэлт
Би докерыг ашиглаж эхлэхэд түүний даалгаврын гүйцэтгэлд эргэлзэж байсан. Миний нэг нэгж одоогоор хэд хэдэн камераар үүсгэсэн сүлжээний ачаалал ихтэй байна.
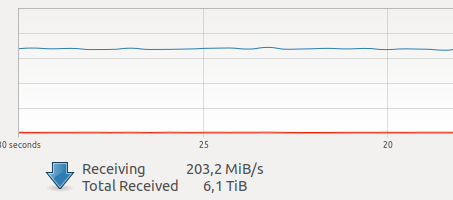
Интернэт дэх янз бүрийн туршилтууд нь VOLUME дээр сүлжээний харилцан үйлчлэл, бичлэг хийхэд харьцангуй их зардал, үл мэдэгдэх, аймшигтай GIL-ийн талаар ярьсан бөгөөд фрэймийг барьж авснаас хойш драйверийг ажиллуулж, сүлжээгээр хүрээ дамжуулах нь атомын горимд ажилладаг. хэцүү бодит цаг, сүлжээний саатал нь миний хувьд маш чухал юм.
Гэхдээ бүх зүйл сайхан болсон =)
Жич Үлдсэн зүйл бол сегментчлэл, үйлдвэрлэлд дуртай галт тэрэгний гогцоо нэмэх явдал юм!
Баярлалаа
Хамт олондоо баярлалаа , үүнгүйгээр хөгжих боломжгүй юм! Маш их баярлалаа Үнэлж баршгүй зөвлөгөө, мэргэжлийн өндөр ур чадварын төлөө намайг DL хийхийг урамшуулсан!
Үйлдвэрлэлд оновчтой загваруудыг ашигла!
 Аврорай, ХХК
Аврорай, ХХК
Эх сурвалж: www.habr.com
