

वेळोवेळी, कळांच्या संचाद्वारे संबंधित डेटा शोधण्याचे काम उद्भवते, जोपर्यंत आपण आवश्यक असलेल्या एकूण नोंदींची संख्या गाठत नाही तोपर्यंत.
सर्वात "वास्तविक" उदाहरण म्हणजे निष्कर्ष काढणे २० सर्वात जुनी कामे, सूचीबद्ध कर्मचाऱ्यांच्या यादीत (उदाहरणार्थ, एकाच विभागात). कार्यक्षेत्रांचा थोडक्यात सारांश असलेल्या विविध व्यवस्थापन डॅशबोर्डसाठी, बहुतेकदा समान थीम आवश्यक असते.

या लेखात, आपण PostgreSQL मध्ये या समस्येवर "भोळे" उपाय लागू करण्याचा विचार करू, जो "अधिक स्मार्ट" आणि अतिशय जटिल अल्गोरिथम आहे. सापडलेल्या डेटावर आधारित एक्झिट कंडिशनसह SQL मध्ये "लूप"., जे सामान्य विकासासाठी आणि इतर तत्सम प्रकरणांमध्ये वापरण्यासाठी उपयुक्त ठरू शकते.
चला एक चाचणी डेटा सेट घेऊया क्रमवारी लावलेल्या मूल्यांशी जुळताना आउटपुट रेकॉर्ड एका वेळेपासून दुसऱ्या वेळी "उडी मारण्यापासून" रोखण्यासाठी, चला प्राथमिक की जोडून विषय निर्देशांक वाढवूया.हे ताबडतोब ते अद्वितीय बनवेल आणि स्पष्ट क्रमवारीची हमी देईल:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;ते जसे वाटते तसे लिहिले आहे.
प्रथम, विनंतीची सर्वात सोपी आवृत्ती रेखाटूया, कलाकारांचे आयडी पास करूया. :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
हे थोडे दुःखद आहे - आम्ही फक्त २० रेकॉर्ड ऑर्डर केले आणि इंडेक्स स्कॅनने ते आम्हाला परत केले. ९६० ओळी, जे नंतर क्रमवारी लावावे लागले... चला कमी वाचण्याचा प्रयत्न करूया.
अननेस्ट + अॅरे
आपल्याला मदत करणारा पहिला विचार म्हणजे आपल्याला गरज आहे का फक्त २० क्रमवारी लावली रेकॉर्ड, नंतर ते वाचण्यासाठी पुरेसे आहे प्रत्येकासाठी एकाच क्रमाने २० पेक्षा जास्त नाही. की. सुदैवाने, योग्य निर्देशांक (मालक_आयडी, कार्य_तारीख, आयडी) आमच्याकडे आहे.
चला काढण्याची आणि "स्तंभांमध्ये उलगडण्याची" समान यंत्रणा वापरूया. इंटिग्रल टेबल एंट्री, जसे की . आपण फंक्शन वापरून अॅरेमध्ये फोल्डिंग देखील लागू करू. ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 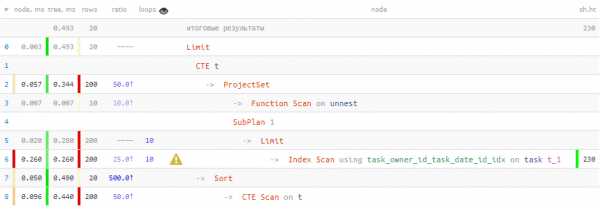
अरे, ते तर खूपच चांगले आहे! ४०% जलद आणि ४.५ पट कमी डेटा मला ते वाचावे लागले.
CTE द्वारे टेबल रेकॉर्डचे भौतिकीकरणमी तुमचे लक्ष या वस्तुस्थितीकडे वेधू इच्छितो की काही बाबतीत सबक्वेरीमध्ये रेकॉर्ड फील्ड शोधल्यानंतर, ते CTE मध्ये "रॅपिंग" न करता लगेच त्यावर काम करण्याचा प्रयत्न केल्यास, InitPlan चे "गुणाकार" या समान फील्डच्या संख्येच्या प्रमाणात:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
तोच रेकॉर्ड ४ वेळा "शोधला" गेला... PostgreSQL ११ पर्यंत, हे वर्तन नियमितपणे आढळत होते आणि त्यावर उपाय म्हणजे ते CTE मध्ये "रॅप" करणे, जे या आवृत्त्यांमध्ये ऑप्टिमायझरसाठी एक परिपूर्ण मर्यादा आहे.
रिकर्सिव्ह अॅक्युम्युलेटर
मागील आवृत्तीत, आपण एकूण वाचले ९६० ओळी आवश्यक असलेल्या २० साठी. आता ९६० नाही, तर त्याहूनही कमी - हे शक्य आहे का?
आपल्याला आवश्यक असलेले ज्ञान वापरण्याचा प्रयत्न करूया एकूण 20 रेकॉर्ड. म्हणजेच, आपण आवश्यक संख्येपर्यंत पोहोचेपर्यंतच डेटा रीडिंगची पुनरावृत्ती करू.
पायरी १: सुरुवातीची यादी
अर्थात, आमची २० रेकॉर्डची "लक्ष्य" यादी आमच्या मालक_आयडी की पैकी एकाच्या "पहिल्या" रेकॉर्डने सुरू झाली पाहिजे. तर, प्रथम त्या शोधूया प्रत्येक किल्लीसाठी "पहिले" आणि ते यादीत जोडा, आपल्याला हव्या त्या क्रमाने क्रमवारी लावा - (कार्य_तारीख, आयडी).
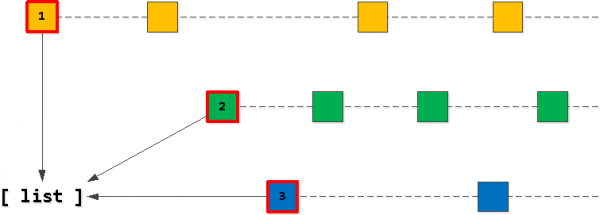
पायरी २: "पुढील" नोंदी शोधा
आता जर आपण आपल्या यादीतील पहिली नोंद घेतली आणि सुरुवात केली तर निर्देशांकात आणखी "पाय" टाका मालक_आयडी की जतन करून, सापडलेले सर्व रेकॉर्ड परिणामी निवडीतील अगदी पुढील रेकॉर्ड असतील. अर्थात, फक्त जोपर्यंत आपण लागू केलेली की ओलांडत नाही तोपर्यंत यादीतील दुसरी नोंद.
जर असे दिसून आले की आपण दुसरी नोंद "क्रॉस" केली, तर पहिल्याऐवजी शेवटची वाचलेली नोंद यादीत जोडावी. (त्याच मालकाच्या_आयडीसह), त्यानंतर आम्ही यादी पुन्हा क्रमवारी लावतो.
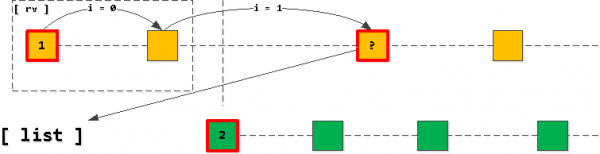
म्हणजेच, आपल्याला नेहमीच असे आढळते की यादीमध्ये प्रत्येक कीसाठी एकापेक्षा जास्त नोंदी नाहीत (जर नोंदी संपल्या आणि आपण त्या "क्रॉस" केल्या नाहीत, तर पहिली नोंद यादीतून गायब होईल आणि काहीही जोडले जाणार नाही), आणि ते नेहमी क्रमवारी लावलेले अॅप्लिकेशन की (टास्क_डेट, आयडी) च्या चढत्या क्रमाने.
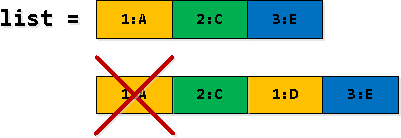
पायरी ३: रेकॉर्ड फिल्टर करा आणि विस्तृत करा
आमच्या रिकर्सिव्ह निवडीच्या काही ओळींमध्ये, काही नोंदी rv डुप्लिकेट नोंदी - आपल्याला प्रथम "यादीतील दुसऱ्या नोंदीची सीमा ओलांडणे" सारख्या नोंदी आढळतात आणि नंतर त्या यादीतील पहिल्या नोंदी म्हणून बदलतात. म्हणून, पहिली घटना फिल्टर करणे आवश्यक आहे.
भयानक शेवटचा प्रश्न
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 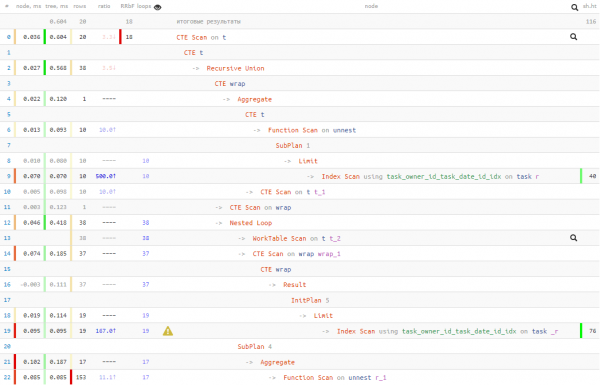
तर आपण अंमलबजावणी वेळेच्या २०% साठी ५०% डेटा रीडचा व्यापार केलाम्हणजेच, जर तुम्हाला असे मानण्याचे कारण असेल की वाचन मंद असू शकते (उदाहरणार्थ, डेटा बहुतेकदा कॅशेमध्ये नसतो आणि डिस्कवरून पुनर्प्राप्त करावा लागतो), तर ही पद्धत वाचनावरील तुमचा अवलंबित्व कमी करू शकते.
काहीही असो, "भोळ्या" पहिल्या पर्यायापेक्षा अंमलबजावणीचा वेळ चांगला होता. पण या तीन पर्यायांपैकी कोणता पर्याय वापरायचा हे तुमच्यावर अवलंबून आहे.
स्त्रोत: www.habr.com
