

Pada Februari-Mac 2019, satu pertandingan telah diadakan untuk menentukan kedudukan suapan rangkaian sosial , di mana pasukan kami mendapat tempat pertama. Dalam artikel saya akan bercakap tentang penganjuran pertandingan, kaedah yang kami cuba, dan tetapan catboost untuk latihan mengenai data besar.

SNA Hackathon
Ini adalah kali ketiga hackathon di bawah nama ini diadakan. Ia dianjurkan oleh rangkaian sosial ok.ru, masing-masing, tugas dan data berkaitan secara langsung dengan rangkaian sosial ini.
SNA (analisis rangkaian sosial) dalam kes ini lebih tepat difahami bukan sebagai analisis graf sosial, sebaliknya sebagai analisis rangkaian sosial.
- Pada tahun 2014, tugasnya adalah untuk meramalkan bilangan suka yang akan diterima oleh siaran.
- Pada tahun 2016 - tugas VVZ (mungkin anda sudah biasa), lebih dekat dengan analisis graf sosial.
- Pada tahun 2019, kedudukan suapan pengguna berdasarkan kemungkinan pengguna akan menyukai siaran tersebut.
Saya tidak boleh mengatakan tentang 2014, tetapi pada 2016 dan 2019, sebagai tambahan kepada kebolehan analisis data, kemahiran dalam bekerja dengan data besar juga diperlukan. Saya fikir ia adalah gabungan pembelajaran mesin dan masalah pemprosesan data besar yang menarik saya ke pertandingan ini, dan pengalaman saya dalam bidang ini membantu saya menang.
mlbootcamp
Pada tahun 2019, pertandingan itu dianjurkan di platform .
Pertandingan ini bermula secara dalam talian pada 7 Februari dan terdiri daripada 3 tugasan. Sesiapa sahaja boleh mendaftar di tapak, muat turun dan muatkan kereta anda selama beberapa jam. Pada penghujung peringkat dalam talian pada 15 Mac, 15 teratas setiap acara lompat pertunjukan telah dijemput ke pejabat Mail.ru untuk peringkat luar talian, yang berlangsung dari 30 Mac hingga 1 April.
Petugas
Data sumber menyediakan ID pengguna (userId) dan ID siaran (objectId). Jika pengguna ditunjukkan siaran, maka data tersebut mengandungi baris yang mengandungi userId, objectId, reaksi pengguna terhadap siaran ini (maklum balas) dan satu set pelbagai ciri atau pautan ke gambar dan teks.
| ID Pengguna | objectId | id pemilik | maklum balas | imej |
|---|---|---|---|---|
| 3555 | 22 | 5677 | [suka, diklik] | [cincang1] |
| 12842 | 55 | 32144 | [tidak suka] | [hash2, hash3] |
| 13145 | 35 | 5677 | [diklik, dikongsi] | [cincang2] |
Set data ujian mengandungi struktur yang serupa, tetapi medan maklum balas tiada. Tugasnya adalah untuk meramalkan kehadiran reaksi 'suka' dalam medan maklum balas.
Fail penyerahan mempunyai struktur berikut:
| ID Pengguna | Senarai Isih[objectId] |
|---|---|
| 123 | 78,13,54,22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Metrik ialah purata ROC AUC untuk pengguna.
Penerangan yang lebih terperinci tentang data boleh didapati di. Anda juga boleh memuat turun data di sana, termasuk ujian dan gambar.
Pentas dalam talian
Pada peringkat atas talian, tugasan dibahagikan kepada 3 bahagian
- — termasuk semua ciri kecuali imej dan teks;
- — termasuk hanya maklumat tentang imej;
- — termasuk maklumat hanya tentang teks.
Peringkat luar talian
Pada peringkat luar talian, data termasuk semua ciri, manakala teks dan imej adalah jarang. Terdapat 1,5 kali lebih banyak baris dalam set data, yang mana sudah terdapat banyak.
Penyelesaian masalah
Memandangkan saya membuat CV di tempat kerja, saya memulakan perjalanan saya dalam pertandingan ini dengan tugasan "Imej". Data yang diberikan ialah userId, objectId, ownerId (kumpulan tempat siaran diterbitkan), cap masa untuk membuat dan memaparkan siaran dan, sudah tentu, imej untuk siaran ini.
Selepas menjana beberapa ciri berdasarkan cap masa, idea seterusnya adalah untuk mengambil lapisan kedua terakhir neuron yang telah dilatih pada imagenet dan menghantar benam ini untuk meningkatkan.
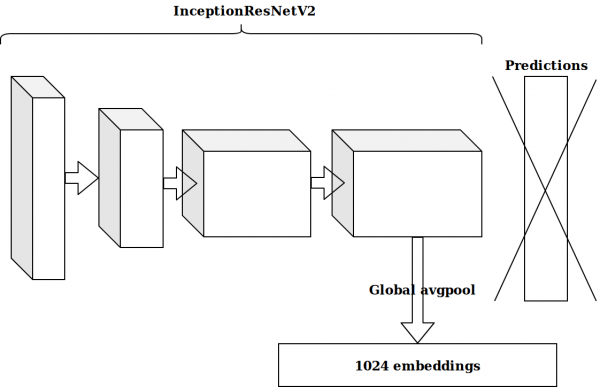
Hasilnya tidak mengagumkan. Pembenaman daripada neuron imagenet tidak relevan, saya fikir, saya perlu membuat pengekod automatik saya sendiri.
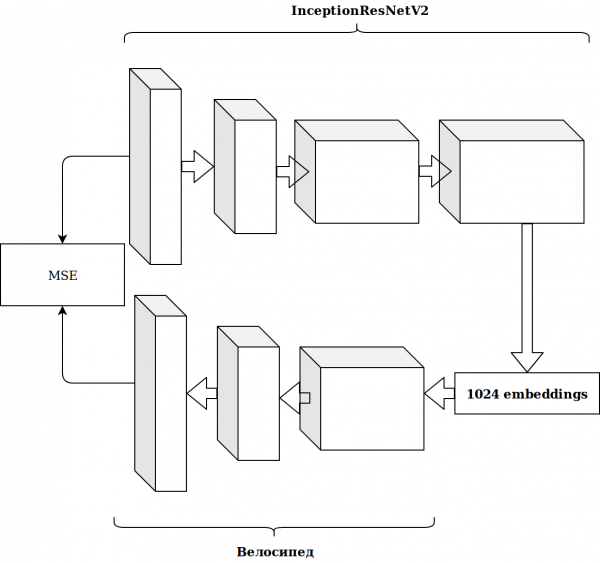
Ia mengambil banyak masa dan hasilnya tidak bertambah baik.
Penjanaan ciri
Bekerja dengan imej memerlukan banyak masa, jadi saya memutuskan untuk melakukan sesuatu yang lebih mudah.
Seperti yang anda boleh lihat dengan segera, terdapat beberapa ciri kategori dalam set data, dan untuk tidak terlalu mengganggu, saya hanya mengambil catboost. Penyelesaiannya sangat baik, tanpa sebarang tetapan saya segera sampai ke baris pertama papan pendahulu.
Terdapat banyak data dan ia dibentangkan dalam format parket, jadi tanpa berfikir dua kali, saya mengambil skala dan mula menulis segala-galanya dalam percikan api.
Ciri paling mudah yang memberikan lebih banyak pertumbuhan daripada pembenaman imej:
- berapa kali objectId, userId dan ownerId muncul dalam data (harus dikaitkan dengan populariti);
- berapa banyak siaran yang telah dilihat oleh userId daripada ownerId (harus dikaitkan dengan minat pengguna dalam kumpulan);
- bilangan userId unik yang melihat siaran daripada ownerId (mencerminkan saiz khalayak kumpulan).
Daripada cap masa adalah mungkin untuk mendapatkan masa hari di mana pengguna menonton suapan (pagi/petang/petang/malam). Dengan menggabungkan kategori ini, anda boleh terus menjana ciri:
- berapa kali userId log masuk pada waktu petang;
- pada pukul berapa siaran ini paling kerap ditunjukkan (objectId) dan sebagainya.
Semua ini menambah baik metrik secara beransur-ansur. Tetapi saiz set data latihan ialah kira-kira 20M rekod, jadi penambahan ciri sangat melambatkan latihan.
Saya telah memikirkan semula pendekatan saya untuk menggunakan data. Walaupun data bergantung pada masa, saya tidak melihat sebarang kebocoran maklumat yang jelas "pada masa hadapan", namun, untuk berjaga-jaga, saya memecahkannya seperti ini:
Set latihan yang diberikan kepada kami (Februari dan 2 minggu Mac) dibahagikan kepada 2 bahagian.
Model ini dilatih pada data dari N hari terakhir. Pengagregatan yang diterangkan di atas dibina pada semua data, termasuk ujian. Pada masa yang sama, data telah muncul di mana ia mungkin untuk membina pelbagai pengekodan pembolehubah sasaran. Pendekatan yang paling mudah ialah menggunakan semula kod yang sudah mencipta ciri baharu, dan hanya menyuapkannya data yang tidak akan dilatih dan disasarkan = 1.
Oleh itu, kami mendapat ciri yang serupa:
- Berapa kali userId telah melihat siaran dalam group ownerId;
- Berapa kali userId menyukai siaran dalam group ownerId;
- Peratusan siaran yang userId suka daripada ownerId.
Iaitu, ternyata min pengekodan sasaran pada sebahagian daripada set data untuk pelbagai kombinasi ciri kategori. Pada dasarnya, catboost juga membina pengekodan sasaran dan dari sudut pandangan ini tidak ada faedah, tetapi, sebagai contoh, adalah mungkin untuk mengira bilangan pengguna unik yang menyukai siaran dalam kumpulan ini. Pada masa yang sama, matlamat utama telah dicapai - set data saya telah dikurangkan beberapa kali, dan adalah mungkin untuk terus menjana ciri.
Walaupun catboost boleh membina pengekodan hanya berdasarkan reaksi yang disukai, maklum balas mempunyai reaksi lain: dikongsi semula, tidak suka, tidak suka, diklik, diabaikan, pengekodan yang boleh dilakukan secara manual. Saya mengira semula semua jenis agregat dan menghapuskan ciri dengan kepentingan yang rendah supaya tidak mengembang set data.
Pada masa itu saya berada di tempat pertama dengan margin yang luas. Satu-satunya perkara yang mengelirukan ialah pembenaman imej hampir tidak menunjukkan pertumbuhan. Idea datang untuk memberikan segala-galanya untuk catboost. Kami mengelompokkan imej Kmeans dan mendapatkan imej ciri kategorikal baharu.
Berikut ialah beberapa kelas selepas penapisan manual dan penggabungan kelompok yang diperoleh daripada KMeans.
Berdasarkan imageCat yang kami hasilkan:
- Ciri kategori baharu:
- ImageCat manakah yang paling kerap dilihat oleh userId;
- ImageCat manakah yang paling kerap menunjukkan ownerId;
- ImageCat manakah yang paling kerap disukai oleh userId;
- Pelbagai kaunter:
- Berapa banyak imageCat unik melihat userId;
- Kira-kira 15 ciri serupa serta pengekodan sasaran seperti yang diterangkan di atas.
Teks
Keputusan dalam pertandingan imej sesuai dengan saya dan saya memutuskan untuk mencuba teks. Saya tidak banyak bekerja dengan teks sebelum ini dan, bodohnya, saya membunuh hari itu di tf-idf dan svd. Kemudian saya melihat garis dasar dengan doc2vec, yang melakukan apa yang saya perlukan. Setelah melaraskan sedikit parameter doc2vec, saya mendapat pembenaman teks.
Dan kemudian saya hanya menggunakan semula kod untuk imej, di mana saya menggantikan benam imej dengan benam teks. Hasilnya, saya mendapat tempat ke-2 dalam pertandingan teks.
Sistem kerjasama
Terdapat satu pertandingan lagi yang saya belum lagi "mencucuk" dengan kayu, dan berdasarkan AUC pada papan pendahulu, keputusan pertandingan tertentu ini sepatutnya mempunyai kesan yang paling besar di peringkat luar talian.
Saya mengambil semua ciri yang terdapat dalam data sumber, yang dipilih secara kategori dan mengira agregat yang sama seperti untuk imej, kecuali untuk ciri berdasarkan imej itu sendiri. Hanya meletakkan ini dalam catboost telah membawa saya ke tempat ke-2.
Langkah pertama pengoptimuman catboost
Satu tempat pertama dan dua kedua menggembirakan saya, tetapi ada pemahaman bahawa saya tidak melakukan sesuatu yang istimewa, yang bermakna saya boleh mengharapkan kehilangan kedudukan.
Tugas pertandingan adalah untuk meletakkan jawatan dalam pengguna, dan selama ini saya menyelesaikan masalah klasifikasi, iaitu, mengoptimumkan metrik yang salah.
Izinkan saya memberi anda contoh mudah:
| ID Pengguna | objectId | ramalan | kebenaran tanah |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
Mari kita buat penyusunan semula kecil
| ID Pengguna | objectId | ramalan | kebenaran tanah |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
Kami mendapat keputusan berikut:
| Model | AUC | Pengguna1 AUC | Pengguna2 AUC | bermakna AUC |
|---|---|---|---|---|
| Pilihan 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Pilihan 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Seperti yang anda lihat, meningkatkan metrik AUC keseluruhan tidak bermakna meningkatkan purata metrik AUC dalam pengguna.
Catboost Dari kotak itu. Saya membaca tentang metrik kedudukan, apabila menggunakan catboost dan tetapkan YetiRankPairwise untuk berlatih semalaman. Hasilnya tidak mengagumkan. Memutuskan bahawa saya kurang latihan, saya menukar fungsi ralat kepada QueryRMSE, yang, berdasarkan dokumentasi catboost, menumpu lebih cepat. Akhirnya, saya mendapat keputusan yang sama seperti semasa latihan untuk klasifikasi, tetapi ensemble kedua-dua model ini memberikan peningkatan yang baik, yang membawa saya ke tempat pertama dalam ketiga-tiga pertandingan.
5 minit sebelum penutupan peringkat dalam talian pertandingan "Sistem Kerjasama", Sergey Shalnov memindahkan saya ke tempat kedua. Kami berjalan ke laluan yang lebih jauh bersama-sama.
Bersedia untuk peringkat luar talian
Kami dijamin kemenangan di peringkat dalam talian dengan kad video RTX 2080 TI, tetapi hadiah utama 300 rubel dan, kemungkinan besar, walaupun tempat pertama yang terakhir memaksa kami bekerja selama 000 minggu ini.
Ternyata, Sergey juga menggunakan catboost. Kami bertukar idea dan ciri, dan saya belajar tentangnya yang mengandungi jawapan kepada banyak soalan saya, dan juga soalan yang saya belum ada pada masa itu.
Melihat laporan membawa saya kepada idea bahawa kita perlu mengembalikan semua parameter kepada nilai lalai, dan melakukan tetapan dengan berhati-hati dan hanya selepas membetulkan satu set ciri. Kini satu latihan mengambil masa kira-kira 15 jam, tetapi satu model berjaya memperoleh kelajuan yang lebih baik daripada yang diperoleh dalam ensemble dengan ranking.
Penjanaan ciri
Dalam pertandingan Sistem Kolaboratif, sejumlah besar ciri dinilai sebagai penting untuk model. Sebagai contoh, auditweights_spark_svd - tanda yang paling penting, tetapi tidak ada maklumat tentang maksudnya. Saya fikir adalah berbaloi untuk mengira pelbagai agregat berdasarkan ciri penting. Contohnya, purata auditweights_spark_svd mengikut pengguna, mengikut kumpulan, mengikut objek. Perkara yang sama boleh dikira menggunakan data yang tiada latihan dilakukan dan sasaran = 1, iaitu purata auditweights_spark_svd oleh pengguna dengan objek yang dia suka. Tanda-tanda penting selain auditweights_spark_svd, terdapat beberapa. Berikut adalah sebahagian daripada mereka:
- auditweightsCtrGender
- auditweightsCtrHigh
- penggunaOwnerCounterCreateLikes
Sebagai contoh, purata auditweightsCtrGender menurut userId ia ternyata menjadi ciri penting, sama seperti nilai purata penggunaOwnerCounterCreateLikes oleh userId+ownerId. Ini sepatutnya membuat anda berfikir bahawa anda perlu memahami maksud medan.
Juga ciri-ciri penting ialah auditweightsLikesCount и auditweightsShowsCount. Membahagikan satu dengan yang lain, ciri yang lebih penting diperolehi.
Kebocoran data
Persaingan dan pemodelan pengeluaran adalah tugas yang sangat berbeza. Apabila menyediakan data, amat sukar untuk mengambil kira semua butiran dan tidak menyampaikan beberapa maklumat yang tidak remeh tentang pembolehubah sasaran dalam ujian. Jika kami mencipta penyelesaian pengeluaran, kami akan cuba mengelak daripada menggunakan kebocoran data semasa melatih model. Tetapi jika kita ingin memenangi pertandingan, maka kebocoran data adalah ciri terbaik.
Setelah mengkaji data, anda boleh melihatnya mengikut nilai objectId auditweightsLikesCount и auditweightsShowsCount perubahan, yang bermaksud nisbah nilai maksimum ciri ini akan mencerminkan penukaran pasca jauh lebih baik daripada nisbah pada masa paparan.
Kebocoran pertama yang kami temui ialah auditweightsLikesCountMax/auditweightsShowsCountMax.
Tetapi bagaimana jika kita melihat data dengan lebih teliti? Mari isi mengikut tarikh tayangan dan dapatkan:
| objectId | ID Pengguna | auditweightsShowsCount | auditweightsLikesCount | sasaran (disukai) |
|---|---|---|---|---|
| 1 | 1 | 12 | 3 | mungkin tidak |
| 1 | 2 | 15 | 3 | mungkin ya |
| 1 | 3 | 16 | 4 |
Sungguh memeranjatkan apabila saya menemui contoh pertama sebegitu dan ternyata ramalan saya tidak menjadi kenyataan. Tetapi, dengan mengambil kira hakikat bahawa nilai maksimum ciri-ciri ini dalam objek memberikan peningkatan, kami tidak malas dan memutuskan untuk mencari auditweightsShowsCountNext и auditweightsLikesCountNext, iaitu, nilai-nilai pada masa yang akan datang. Dengan menambah ciri
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) kami membuat lompatan tajam dengan pantas.
Kebocoran yang serupa boleh digunakan dengan mencari nilai berikut untuk penggunaOwnerCounterCreateLikes dalam userId+ownerId dan, sebagai contoh, auditweightsCtrGender dalam objectId+userGender. Kami menemui 6 medan serupa dengan kebocoran dan mengekstrak sebanyak mungkin maklumat daripadanya.
Pada masa itu, kami telah memerah sebanyak mungkin maklumat daripada ciri kolaboratif, tetapi tidak kembali kepada pertandingan imej dan teks. Saya mempunyai idea yang bagus untuk menyemak: berapa banyak yang diberikan ciri secara langsung berdasarkan imej atau teks dalam pertandingan yang berkaitan?
Tiada kebocoran dalam pertandingan imej dan teks, tetapi pada masa itu saya telah mengembalikan parameter catboost lalai, membersihkan kod dan menambah beberapa ciri. Jumlahnya ialah:
| keputusan | tidak lama lagi |
|---|---|
| Maksimum dengan imej | 0.6411 |
| Maksimum tiada imej | 0.6297 |
| Keputusan tempat kedua | 0.6295 |
| keputusan | tidak lama lagi |
|---|---|
| Maksimum dengan teks | 0.666 |
| Maksimum tanpa teks | 0.660 |
| Keputusan tempat kedua | 0.656 |
| keputusan | tidak lama lagi |
|---|---|
| Maksimum dalam kerjasama | 0.745 |
| Keputusan tempat kedua | 0.723 |
Ia menjadi jelas bahawa kami tidak mungkin dapat memerah banyak daripada teks dan imej, dan selepas mencuba beberapa idea yang paling menarik, kami berhenti bekerja dengan mereka.
Penjanaan ciri selanjutnya dalam sistem kerjasama tidak memberikan peningkatan, dan kami memulakan kedudukan. Pada peringkat dalam talian, ensemble klasifikasi dan ranking memberi saya peningkatan kecil, ternyata kerana saya kurang melatih klasifikasi. Tiada satu pun daripada fungsi ralat, termasuk YetiRanlPairwise, menghasilkan hampir hasil yang LogLoss lakukan (0,745 lwn. 0,725). Masih ada harapan untuk QueryCrossEntropy, yang tidak dapat dilancarkan.
Peringkat luar talian
Pada peringkat luar talian, struktur data kekal sama, tetapi terdapat perubahan kecil:
- id pengguna pengecam, objectId, ownerId telah diubah rawak;
- beberapa tanda telah dikeluarkan dan beberapa telah dinamakan semula;
- data telah meningkat lebih kurang 1,5 kali ganda.
Sebagai tambahan kepada kesukaran yang disenaraikan, terdapat satu tambahan besar: pasukan telah diperuntukkan pelayan besar dengan RTX 2080TI. Saya sudah lama menikmati htop.
Terdapat hanya satu idea - untuk menghasilkan semula apa yang sudah wujud. Selepas menghabiskan beberapa jam menyediakan persekitaran pada pelayan, kami secara beransur-ansur mula mengesahkan bahawa hasilnya boleh dihasilkan semula. Masalah utama yang kami hadapi ialah peningkatan jumlah data. Kami memutuskan untuk mengurangkan sedikit beban dan menetapkan parameter catboost ctr_complexity=1. Ini mengurangkan kelajuan sedikit, tetapi model saya mula berfungsi, hasilnya bagus - 0,733. Sergey, tidak seperti saya, tidak membahagikan data kepada 2 bahagian dan melatih semua data, walaupun ini memberikan hasil terbaik di peringkat dalam talian, di peringkat luar talian terdapat banyak kesukaran. Jika kami mengambil semua ciri yang kami hasilkan dan cuba memasukkannya ke dalam catboost, maka tiada apa yang akan berfungsi di peringkat dalam talian. Sergey melakukan pengoptimuman jenis, contohnya, menukar jenis float64 kepada float32. Anda boleh mendapatkan maklumat tentang pengoptimuman memori dalam panda. Akibatnya, Sergey melatih CPU menggunakan semua data dan mendapat kira-kira 0,735.
Keputusan ini sudah cukup untuk menang, tetapi kami menyembunyikan kelajuan sebenar kami dan tidak dapat memastikan bahawa pasukan lain tidak melakukan perkara yang sama.
Berjuang hingga akhir
Penalaan Catboost
Penyelesaian kami telah diterbitkan semula sepenuhnya, kami menambah ciri data teks dan imej, jadi yang tinggal hanyalah untuk menala parameter catboost. Sergey berlatih pada CPU dengan sebilangan kecil lelaran, dan saya berlatih pada CPU dengan ctr_complexity=1. Tinggal satu hari lagi dan jika anda hanya menambah lelaran atau meningkatkan ctr_complexity, maka pada waktu pagi anda boleh mendapatkan kelajuan yang lebih baik dan berjalan sepanjang hari.
Pada peringkat luar talian, kelajuan boleh disembunyikan dengan mudah dengan hanya memilih bukan penyelesaian terbaik di tapak. Kami menjangkakan perubahan drastik dalam papan pendahulu pada minit terakhir sebelum penyerahan ditutup dan memutuskan untuk tidak berhenti.
Daripada video Anna, saya belajar bahawa untuk meningkatkan kualiti model, sebaiknya pilih parameter berikut:
- kadar_pembelajaran — Nilai lalai dikira berdasarkan saiz set data. Meningkatkan kadar_pembelajaran memerlukan peningkatan bilangan lelaran.
- l2_daun_reg — Pekali penyelarasan, nilai lalai 3, sebaik-baiknya pilih daripada 2 hingga 30. Penurunan nilai membawa kepada peningkatan overfit.
- suhu_bekas — menambah rawak kepada berat objek dalam sampel. Nilai lalai ialah 1, di mana pemberat diambil daripada taburan eksponen. Menurunkan nilai membawa kepada peningkatan overfit.
- rawak_kekuatan — Mempengaruhi pilihan pemisahan pada lelaran tertentu. Lebih tinggi rawak_strength, lebih tinggi peluang pemisahan kepentingan rendah dipilih. Pada setiap lelaran berikutnya, rawak berkurangan. Menurunkan nilai membawa kepada peningkatan overfit.
Parameter lain mempunyai kesan yang lebih kecil pada hasil akhir, jadi saya tidak cuba memilihnya. Satu lelaran latihan pada set data GPU saya dengan ctr_complexity=1 mengambil masa 20 minit dan parameter yang dipilih pada set data yang dikurangkan sedikit berbeza daripada parameter optimum pada set data penuh. Pada akhirnya, saya melakukan kira-kira 30 lelaran pada 10% data, dan kemudian kira-kira 10 lagi lelaran pada semua data. Ternyata seperti ini:
- kadar_pembelajaran Saya meningkat sebanyak 40% daripada lalai;
- l2_daun_reg meninggalkannya sama;
- suhu_bekas и rawak_kekuatan dikurangkan kepada 0,8.
Kita boleh membuat kesimpulan bahawa model itu kurang terlatih dengan parameter lalai.
Saya sangat terkejut apabila saya melihat keputusan di papan pendahulu:
| Model | model 1 | model 2 | model 3 | ensemble |
|---|---|---|---|---|
| Tanpa penalaan | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| Dengan penalaan | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
Saya membuat kesimpulan sendiri bahawa jika aplikasi pantas model tidak diperlukan, maka lebih baik untuk menggantikan pemilihan parameter dengan ensemble beberapa model menggunakan parameter yang tidak dioptimumkan.
Sergey sedang mengoptimumkan saiz set data untuk menjalankannya pada GPU. Pilihan paling mudah ialah memotong sebahagian daripada data, tetapi ini boleh dilakukan dalam beberapa cara:
- keluarkan data tertua secara beransur-ansur (bermula bulan Februari) sehingga set data mula dimuatkan ke dalam ingatan;
- keluarkan ciri dengan kepentingan yang paling rendah;
- alih keluar userId yang hanya terdapat satu entri;
- tinggalkan hanya userId yang dalam ujian.
Dan akhirnya, buat ensemble daripada semua pilihan.
Kumpulan terakhir
Menjelang lewat petang hari terakhir, kami telah membentangkan ensemble model kami yang menghasilkan 0,742. Semalaman saya melancarkan model saya dengan ctr_complexity=2 dan bukannya 30 minit ia dilatih selama 5 jam. Hanya pada pukul 4 pagi ia dikira, dan saya membuat ensembel terakhir, yang memberikan 0,7433 pada papan pendahulu awam.
Oleh kerana pendekatan yang berbeza untuk menyelesaikan masalah, ramalan kami tidak berkorelasi kuat, yang memberikan peningkatan yang baik dalam ensembel. Untuk mendapatkan ensemble yang baik, lebih baik menggunakan ramalan model mentah ramalan(prediction_type='RawFormulaVal') dan tetapkan scale_pos_weight=neg_count/pos_count.
Di laman web anda boleh lihat .
Penyelesaian lain
Banyak pasukan mengikuti kanun algoritma sistem pengesyor. Saya, bukan pakar dalam bidang ini, tidak boleh menilai mereka, tetapi saya ingat 2 penyelesaian yang menarik.
- . Nikolay, sebagai pekerja Mail.ru, tidak memohon hadiah, jadi matlamatnya bukan untuk mencapai kelajuan maksimum, tetapi untuk mendapatkan penyelesaian yang mudah berskala.
- Keputusan pasukan pemenang Hadiah Juri berdasarkan , dibenarkan untuk pengelompokan imej yang sangat baik tanpa kerja manual.
Kesimpulan
Apa yang paling melekat dalam ingatan saya:
- Jika terdapat ciri kategori dalam data, dan anda tahu cara melakukan pengekodan sasaran dengan betul, adalah lebih baik untuk mencuba catboost.
- Jika anda menyertai pertandingan, anda tidak seharusnya membuang masa memilih parameter selain daripada kadar_pembelajaran dan lelaran. Penyelesaian yang lebih pantas ialah membuat ensemble beberapa model.
- Penggalak boleh belajar pada GPU. Catboost boleh belajar dengan cepat pada GPU, tetapi ia memakan banyak memori.
- Semasa pembangunan dan ujian idea, adalah lebih baik untuk menetapkan rsm kecil~=0.2 (CPU sahaja) dan ctr_complexity=1.
- Tidak seperti pasukan lain, ensemble model kami memberikan peningkatan yang besar. Kami hanya bertukar idea dan menulis dalam bahasa yang berbeza. Kami mempunyai pendekatan yang berbeza untuk memisahkan data dan, saya fikir, masing-masing mempunyai pepijatnya sendiri.
- Tidak jelas mengapa pengoptimuman kedudukan menunjukkan prestasi yang lebih buruk daripada pengoptimuman klasifikasi.
- Saya memperoleh sedikit pengalaman bekerja dengan teks dan pemahaman tentang cara sistem pengesyor dibuat.

Terima kasih kepada penganjur atas emosi, ilmu dan hadiah yang diterima.
Sumber: www.habr.com
