


دا یو افسانه ده چې د سرور هارډویر په ساحه کې خورا عام دی. په عمل کې، د ډیرو شیانو لپاره د هایپر کنورډ حلونه (کله چې هرڅه په یو کې وي) ته اړتیا ده. په تاریخي توګه، لومړی جوړښتونه د ایمیزون او ګوګل لخوا د دوی خدماتو لپاره رامینځته شوي. بیا مفکوره دا وه چې د ورته نوډونو څخه د کمپیوټر فارم جوړ کړي، چې هر یو یې خپل ډیسکونه لري. دا ټول د ځینې سیسټم جوړونکي سافټویر (هایپروایزر) لخوا متحد شوي او په مجازی ماشینونو ویشل شوي. اصلي هدف د یو نوډ خدمت کولو لپاره لږترلږه هڅې او د اندازه کولو پرمهال لږترلږه ستونزې دي: یوازې د ورته سرورونو څخه بل زره یا دوه وپیرئ او نږدې یې وصل کړئ. په عمل کې، دا جلا قضیې دي، او ډیری وختونه موږ د کوچنیو نوډونو او یو څه مختلف جوړښت په اړه خبرې کوو.
مګر پلس ورته پاتې دی - د اندازه کولو او مدیریت نه منلو وړ اسانتیا. نیمګړتیا دا ده چې مختلف دندې په مختلف ډول سرچینې مصرفوي، او په ځینو ځایونو کې به ډیری محلي ډیسکونه وي، په نورو کې به لږ RAM وي، او داسې نور، دا د مختلفو کارونو لپاره، د سرچینو کارول به کم شي.
دا معلومه شوه چې تاسو د تنظیم کولو اسانتیا لپاره 10-15٪ ډیر تادیه کوئ. دا هغه څه دي چې په سرلیک کې افسانه راپورته کړه. موږ ډیر وخت په دې لټه کې تیر کړ چې ټیکنالوژي به په ښه توګه پلي شي، او موږ یې وموندل. حقیقت دا دی چې سیسکو د خپل ذخیره کولو سیسټمونه نه درلودل، مګر دوی د بشپړ سرور بازار غوښتونکي دي. او دوی سیسکو هایپرفلیکس جوړ کړ - په نوډونو کې د محلي ذخیره کولو حل.
او دا ناڅاپه د بیک اپ ډیټا مرکزونو (د ناورین بیا رغونه) لپاره خورا ښه حل وګرځید. زه به تاسو ته ووایم چې ولې او څنګه. او زه به تاسو ته د کلستر ازموینې وښیم.
چیرته چې اړتیا وي
Hyperconvergence دا دی:
- د کمپیوټر نوډونو ته د ډیسکونو لیږدول.
- د مجازی کولو فرعي سیسټم سره د ذخیره کولو فرعي سیسټم بشپړ ادغام.
- د شبکې فرعي سیسټم سره لیږد / ادغام.
دا ترکیب تاسو ته اجازه درکوي د ډیری ذخیره کولو سیسټم ځانګړتیاوې د مجازی کولو په کچه او ټول د یوې کنټرول کړکۍ څخه پلي کړئ.
زموږ په شرکت کې، د بې کاره ډیټا مرکزونو ډیزاین کولو پروژې خورا په تقاضا کې دي، او د هایپر کنورګډ حل ډیری وختونه د بکس څخه بهر د نقل کولو اختیارونو (تر میټروکلستر پورې) له امله غوره کیږي.
د بیک اپ ډیټا مرکزونو په حالت کې ، موږ معمولا د ښار په بل اړخ کې یا په بل ښار کې په بشپړ ډول په سایټ کې د لرې پرتو تاسیساتو په اړه خبرې کوو. دا تاسو ته اجازه درکوي د اصلي معلوماتو مرکز د جزوي یا بشپړې ناکامۍ په صورت کې مهم سیسټمونه بحال کړئ. د پلور ډاټا په دوامداره توګه هلته نقل کیږي، او دا نقل کیدای شي د غوښتنلیک په کچه یا د بلاک وسیلې (ذخیرې) په کچه وي.
له همدې امله ، اوس به زه د سیسټم ډیزاین او ازموینو په اړه وغږیږم ، او بیا به د سپما ډیټا سره د یو څو ریښتیني ژوند غوښتنلیک سناریوګانو په اړه وغږیږم.
ازموینې
زموږ مثال څلور سرورونه لري، چې هر یو یې د 10 GB 960 SSD ډرایو لري. د کیچ لیکلو عملیاتو او د خدمت مجازی ماشین ذخیره کولو لپاره وقف شوی ډیسک شتون لري. د حل لاره پخپله څلورمه نسخه ده. لومړی په ریښتیا خام دی (د بیاکتنې په واسطه قضاوت کول) ، دوهم لندبل دی ، دریم لا دمخه خورا مستحکم دی ، او دا د عامو خلکو لپاره د بیټا ازموینې پای ته رسیدو وروسته خوشې کیدلی شي. د ازموینې پرمهال ما کومه ستونزه ونه لیده، هرڅه د ساعت په څیر کار کوي.
په v4 کې بدلونونهد کیګونو یوه ډله سمه شوې ده.
په پیل کې، پلیټ فارم کولی شي یوازې د VMware ESXi هایپروایزر سره کار وکړي او د لږ شمیر نوډونو ملاتړ وکړي. همچنان ، د ګمارلو پروسه تل په بریالیتوب سره پای ته نه وه رسیدلې ، ځینې مرحلې باید بیا پیل شي ، د زړو نسخو تازه کولو کې ستونزې شتون درلود ، په GUI کې ډاټا تل په سمه توګه نه ښودل شوې (که څه هم زه لاهم د فعالیت ګرافونو ښودلو څخه خوښ نه یم )، ځینې وختونه د مجازی کولو سره په انٹرفیس کې ستونزې رامینځته کیږي.
اوس د ماشومتوب ټولې ستونزې حل شوي، HyperFlex کولی شي دواړه ESXi او Hyper-V اداره کړي، او دا ممکنه ده چې:
- د پراخ شوي کلستر جوړول.
- له دوه څخه تر څلورو نوډونو (موږ یوازې سرورونه اخلو) د فابریک انټرنیټ کارولو پرته د دفترونو لپاره د کلستر جوړول.
- د بهرني ذخیره کولو سیسټمونو سره د کار کولو وړتیا.
- د کانټینرونو او کبرنیټ لپاره ملاتړ.
- د شتون زونونو رامینځته کول.
- د VMware SRM سره یوځای کول که چیرې جوړ شوی فعالیت د قناعت وړ نه وي.
جوړښت د خپلو اصلي سیالانو د حلونو څخه ډیر توپیر نلري؛ دوی بایسکل نه دی جوړ کړی. دا ټول د VMware یا Hyper-V مجازی کولو پلیټ فارم کې پرمخ ځي. هارډویر د ملکیت سیسکو UCS سرورونو کې کوربه شوی دی. دلته هغه څوک شتون لري چې د لومړني تنظیم کولو نسبي پیچلتیا لپاره پلیټ فارم څخه کرکه لري ، ډیری بټنونه ، د ټیمپلیټونو او انحصارونو غیر معمولي سیسټم ، مګر داسې کسان هم شتون لري چې زین یې زده کړی ، له نظره الهام اخیستی او نور نه غواړي. د نورو سرورونو سره کار کولو لپاره.
موږ به د VMware حل په پام کې ونیسو، ځکه چې حل په اصل کې د دې لپاره رامینځته شوی او ډیر فعالیت لري؛ Hyper-V د لارې په اوږدو کې اضافه شوی ترڅو د سیالیو سره پاتې شي او د بازار توقعات پوره کړي.
د ډیسکونو څخه ډک د سرورونو کلستر شتون لري. د ډیټا ذخیره کولو لپاره ډیسکونه شتون لري (SSD یا HDD - ستاسو د خوند او اړتیاو مطابق) ، د کیچ کولو لپاره یو SSD ډیسک شتون لري. کله چې ډیټا سټور ته ډیټا لیکئ ، ډاټا د کیشینګ پرت کې خوندي کیږي (وقف شوي SSD ډیسک او د VM خدمت رام). په موازي ډول، د معلوماتو یو بلاک په کلستر کې نوډونو ته لیږل کیږي (د نوډونو شمیر د کلستر د نقل کولو فکتور پورې اړه لري). د بریالي ثبت کولو په اړه د ټولو نوډونو څخه تایید وروسته، د ثبت کولو تایید هایپروایزر او بیا VM ته لیږل کیږي. ثبت شوي معلومات په شالید کې د ذخیره کولو ډیسکونو ته نقل شوي ، کمپریس شوي او لیکل شوي. په ورته وخت کې ، یو لوی بلاک تل د ذخیره کولو ډیسکونو ته لیکل کیږي او په ترتیب سره ، کوم چې د ذخیره کولو ډیسکونو بار کموي.
ډیپلیکیشن او کمپریشن تل فعال وي او غیر فعال نشي. ډاټا په مستقیم ډول د ذخیره کولو ډیسکونو یا د رام کیچ څخه لوستل کیږي. که د هایبرډ ترتیب کارول کیږي، لوستل هم په SSD کې ساتل کیږي.
ډاټا د مجازی ماشین اوسني موقعیت سره تړلې ندي او د نوډونو ترمنځ په مساوي ډول ویشل شوي. دا طریقه تاسو ته اجازه درکوي چې ټول ډیسکونه او د شبکې انټرنیټونه په مساوي ډول پورته کړئ. یو ښکاره نیمګړتیا شتون لري: موږ نشو کولی د لوستلو ځنډ د امکان تر حده کم کړو، ځکه چې په ځایی توګه د معلوماتو شتون هیڅ تضمین شتون نلري. مګر زه باور لرم چې دا د ترلاسه شویو ګټو په پرتله لږه قرباني ده. سربیره پردې ، د شبکې ځنډونه داسې ارزښتونو ته رسیدلي چې دوی په عملي ډول په عمومي پایله اغیزه نه کوي.
یو ځانګړی خدمت VM سیسکو هایپر فلیکس ډیټا پلیټ فارم کنټرولر ، کوم چې په هر ذخیره نوډ کې رامینځته شوی ، د ډیسک فرعي سیسټم ټول عملیات منطق لپاره مسؤل دی. زموږ په خدمت کې د VM ترتیب کې، اته vCPUs او 72 GB رام تخصیص شوی، کوم چې دومره لږ ندی. اجازه راکړئ تاسو ته یادونه وکړم چې کوربه پخپله 28 فزیکي کورونه او 512 GB رام لري.
خدمت VM مستقیم د SAS کنټرولر VM ته لیږلو سره فزیکي ډیسکونو ته لاسرسی لري. د هایپروایسر سره اړیکه د ځانګړي ماډل IOVisor له لارې پیښیږي ، کوم چې د I/O عملیات مداخله کوي ، او د داسې اجنټ په کارولو سره چې تاسو ته اجازه درکوي د هایپروایسر API ته کمانډونه واستوي. اجنټ د HyperFlex سنیپ شاټونو او کلونونو سره د کار کولو مسؤلیت لري.
د ډیسک سرچینې په هایپروایزر کې د NFS یا SMB شریکانو په توګه نصب شوي (د هایپروایزر ډول پورې اړه لري، اټکل وکړئ چې کوم یو چیرته دی). او د هوډ لاندې ، دا د توزیع شوي فایل سیسټم دی چې تاسو ته اجازه درکوي د بالغ بشپړ ذخیره کولو سیسټمونو ځانګړتیاوې اضافه کړئ: د پتلي حجم تخصیص ، کمپریشن او ډیپلیکیشن ، د ریډیریټ-آن-رایټ ټیکنالوژۍ په کارولو سره سنیپ شاټونه ، همغږي / غیر متناسب نقل.
خدمت VM د HyperFlex فرعي سیسټم WEB مدیریت انٹرفیس ته لاسرسی چمتو کوي. د vCenter سره ادغام شتون لري، او ډیری ورځني کارونه له دې څخه ترسره کیدی شي، مګر ډیټاسټورونه، د بیلګې په توګه، د جلا ویب کیم څخه د قطع کولو لپاره خورا اسانه دي که تاسو دمخه ګړندي HTML5 انٹرفیس ته تللي وي، یا د بشپړ فلش پیرودونکي کاروئ. د بشپړ ادغام سره. د خدماتو ویب کیم کې تاسو کولی شئ د سیسټم فعالیت او تفصيلي حالت وګورئ.
په کلستر کې یو بل ډول نوډ شتون لري - کمپیوټري نوډونه. دا د جوړ شوي ډیسکونو پرته ریک یا بلیډ سرورونه کیدی شي. دا سرورونه کولی شي VMs پرمخ بوځي چې ډاټا د ډیسکونو سره په سرورونو کې زیرمه شوي. د معلوماتو د لاسرسي له نظره، د نوډونو ډولونو ترمنځ هیڅ توپیر شتون نلري، ځکه چې جوړښت د معلوماتو فزیکي موقعیت څخه خلاصول شامل دي. د ذخیره کولو نوډونو لپاره د کمپیوټري نوډونو اعظمي تناسب 2: 1 دی.
د کمپیوټ نوډونو کارول انعطاف زیاتوي کله چې د کلستر سرچینو اندازه کول: موږ اړتیا نلرو د ډیسکونو سره اضافي نوډونه واخلو که چیرې موږ یوازې CPU/RAM ته اړتیا ولرو. سربیره پردې ، موږ کولی شو د تیغ پنجره اضافه کړو او د سرورونو ریک ځای په ځای کولو کې خوندي کړو.
د پایلې په توګه، موږ د لاندې ځانګړتیاو سره یو هایپر کنورډ پلیټ فارم لرو:
- په یو کلستر کې تر 64 نوډونو پورې (تر 32 ذخیره کولو نوډونو پورې).
- په یوه کلستر کې د نوډونو لږترلږه شمیره درې ده (دوه د Edge کلستر لپاره).
- د ډیټا بې ځایه کیدو میکانیزم: د عکس العمل فکتور 2 او 3 سره عکس العمل.
- د میټرو کلستر.
- د بل هایپر فلیکس کلستر ته د اسینکرونوس VM نقل کول.
- د لرې پرتو معلوماتو مرکز ته د VMs بدلولو آرکیسټریشن.
- اصلي عکسونه د ریډیریټ پر لیکلو ټیکنالوژۍ په کارولو سره.
- تر 1 PB پورې د کارونې وړ ځای د نقل کولو فکتور 3 کې او پرته له تکرار څخه. موږ د نقل کولو فکتور 2 په پام کې نه نیسو، ځکه چې دا د جدي پلور لپاره اختیار ندی.
بل لوی پلس د مدیریت او ګمارلو اسانتیا ده. د UCS سرورونو تنظیم کولو ټولې پیچلتیاوې د سیسکو انجینرانو لخوا چمتو شوي ځانګړي VM لخوا په پام کې نیول کیږي.
د ازموینې بنچ ترتیب:
- 2 x Cisco UCS Fabric Interconnect 6248UP د مدیریت کلستر او د شبکې اجزاو په توګه (48 بندرونه په ایترنیټ 10G/FC 16G حالت کې فعالیت کوي).
- څلور سیسکو UCS HXAF240 M4 سرورونه.
د سرور ځانګړتیاوې:
سی پی یو
2 x Intel® Xeon® E5-2690 v4
مؤقتي حافظه
16 x 32GB DDR4-2400-MHz RDIMM/PC4-19200/دوه اړخیزه درجه/x4/1.2v
شبکه
UCSC-MLOM-CSC-02 (VIC 1227). 2 10G ایترنیټ بندرونه
ذخیره HBA
د سیسکو 12G ماډلر SAS د کنټرولر له لارې تیریږي
د ذخیره کولو ډیسکونه
1 x SSD Intel S3520 120 GB، 1 x SSD Samsung MZ-IES800D، 10 x SSD Samsung PM863a 960 GB
د ترتیب کولو نور اختیارونهد ټاکل شوي هارډویر سربیره، لاندې اختیارونه اوس مهال شتون لري:
- HXAF240c M5.
- یو یا دوه CPUs د انټیل سلور 4110 څخه تر انټیل پلاټینم I8260Y پورې. دوهم نسل شتون لري.
- د 24 حافظې سلاټونه، د 16 GB RDIMM 2600 څخه تر 128 GB LRDIMM 2933 پورې پټې.
- له 6 څخه تر 23 ډیټا ډیسکونو پورې ، یو کیشینګ ډیسک ، یو سیسټم ډیسک او یو بوټ ډیسک.
د ظرفیت ډرایو
- HX-SD960G61X-EV 960GB 2.5 انچ تصدۍ ارزښت 6G SATA SSD (1X برداشت) SAS 960 GB.
- HX-SD38T61X-EV 3.8TB 2.5 انچ انٹرپرائز ارزښت 6G SATA SSD (1X برداشت) SAS 3.8 TB.
- کیشینګ ډرایو
- HX-NVMEXPB-I375 375GB 2.5 انچ Intel Optane Drive، Extreme Perf & Endurance.
- HX-NVMEHW-H1600* 1.6TB 2.5 انچه Ent. Perf. NVMe SSD (3X برداشت) NVMe 1.6 TB.
- HX-SD400G12TX-EP 400GB 2.5 انچه Ent. Perf. 12G SAS SSD (10X برداشت) SAS 400 GB.
- HX-SD800GBENK9** 800GB 2.5 انچه Ent. Perf. 12G SAS SED SSD (10X برداشت) SAS 800 GB.
- HX-SD16T123X-EP 1.6TB 2.5 انچ تصدۍ فعالیت 12G SAS SSD (3X برداشت).
سیسټم/لاګ ډرایو
- HX-SD240GM1X-EV 240GB 2.5 انچ تصدۍ ارزښت 6G SATA SSD (د لوړولو ته اړتیا لري).
د بوټ ډرایو
- HX-M2-240GB 240GB SATA M.2 SSD SATA 240GB.
د 40G، 25G یا 10G ایترنیټ بندرونو له لارې شبکې سره وصل شئ.
FI کیدای شي HX-FI-6332 (40G)، HX-FI-6332-16UP (40G)، HX-FI-6454 (40G/100G) وي.
پخپله ازموینه
د ډیسک فرعي سیسټم ازموینې لپاره ، ما د HCIBench 2.2.1 کارولی. دا یو وړیا افادیت دی چې تاسو ته اجازه درکوي د ډیری مجازی ماشینونو څخه د بار رامینځته کول اتومات کړئ. بار پخپله د معمول fio لخوا رامینځته کیږي.
زموږ کلستر څلور نوډونه لري، د نقل کولو فکتور 3، ټول ډیسکونه فلش دي.
د ازموینې لپاره ، ما څلور ډیټاسټورونه او اته مجازی ماشینونه رامینځته کړل. د لیکلو ازموینې لپاره، داسې انګیرل کیږي چې د کیشینګ ډیسک ډک نه وي.
د ازموینې پایلې په لاندې ډول دي:
100٪ لوستل 100٪ تصادفي
0٪ لوستل 100٪ تصادفي
بلاک/قطار ژوروالی
128
256
512
1024
2048
128
256
512
1024
2048
4K
0,59 ms 213804 IOPS
0,84 ms 303540 IOPS
1,36ms 374348 IOPS
2.47 ms 414116 IOPS
4,86ms 420180 IOPS
2,22 ms 57408 IOPS
3,09 ms 82744 IOPS
5,02 ms 101824 IPOS
8,75 ms 116912 IOPS
17,2 ms 118592 IOPS
8K
0,67 ms 188416 IOPS
0,93 ms 273280 IOPS
1,7 ms 299932 IOPS
2,72 ms 376,484 IOPS
5,47 ms 373,176 IOPS
3,1 ms 41148 IOPS
4,7 ms 54396 IOPS
7,09 ms 72192 IOPS
12,77 ms 80132 IOPS
16K
0,77 ms 164116 IOPS
1,12 ms 228328 IOPS
1,9 ms 268140 IOPS
3,96 ms 258480 IOPS
3,8 ms 33640 IOPS
6,97 ms 36696 IOPS
11,35 ms 45060 IOPS
32K
1,07 ms 119292 IOPS
1,79 ms 142888 IOPS
3,56 ms 143760 IOPS
7,17 ms 17810 IOPS
11,96 ms 21396 IOPS
64K
1,84 ms 69440 IOPS
3,6 ms 71008 IOPS
7,26 ms 70404 IOPS
11,37 ms 11248 IOPS
بولډ هغه ارزښتونو ته اشاره کوي چې وروسته یې په تولید کې زیاتوالی نه راځي، ځینې وختونه حتی تخریب هم لیدل کیږي. دا د دې حقیقت له امله دی چې موږ د شبکې / کنټرولر / ډیسکونو فعالیت محدود یو.
- په ترتیب سره لوستل 4432 MB/s.
- په ترتیب سره لیکل 804 MB/s.
- که یو کنټرولر ناکام شي (د مجازی ماشین یا کوربه ناکامي)، د فعالیت کمښت دوه چنده کیږي.
- که چیرې د ذخیره کولو ډیسک ناکام شي، د کمښت 1/3 دی. د ډیسک بیا رغونه د هر کنټرولر سرچینې 5٪ اخلي.
په یو کوچني بلاک کې ، موږ د کنټرولر (مجازی ماشین) فعالیت لخوا محدود یو ، د دې CPU په 100٪ بار شوی ، او کله چې بلاک ډیریږي ، موږ د پورټ بینډ ویت لخوا محدود یو. 10 Gbps د آل فلش سیسټم احتمالي خلاصولو لپاره کافي ندي. له بده مرغه، د چمتو شوي ډیمو سټینډ پیرامیټونه موږ ته اجازه نه راکوي چې په 40 Gbit/s کې عملیات ازموینه وکړو.
د ازموینو او د معمارۍ مطالعې څخه زما په تاثیر کې ، د الګوریتم له امله چې د ټولو کوربه توبونو ترمینځ ډیټا ځای په ځای کوي ، موږ د توزیع وړ ، د وړاندوینې وړ فعالیت ترلاسه کوو ، مګر دا د لوستلو پرمهال یو محدودیت هم دی ، ځکه چې دا به ممکن وي چې د ځایی ډیسکونو څخه ډیر څه وباسئ ، دلته کیدای شي ډیر ګټور شبکه خوندي کړي، د بیلګې په توګه، FI په 40 Gbit/s کې شتون لري.
همچنان ، د کیچ کولو او نقل کولو لپاره یو ډیسک ممکن یو محدودیت وي؛ په حقیقت کې ، پدې ټیسټ بیډ کې موږ کولی شو څلور SSD ډیسکونو ته ولیکو. دا به خورا ښه وي چې د کیشینګ ډرایو شمیر زیاتولو توان ولرئ او توپیر وګورئ.
ریښتینی کارول
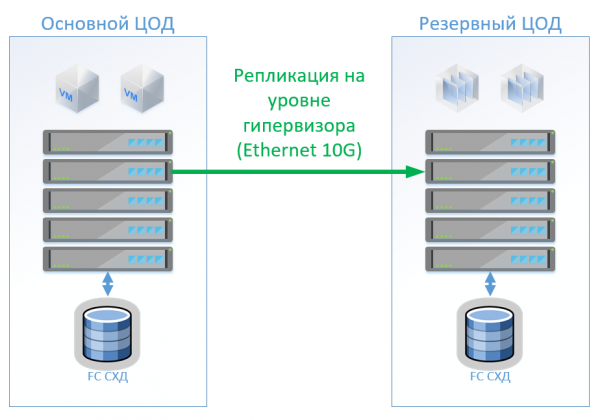
د بیک اپ ډیټا مرکز تنظیم کولو لپاره ، تاسو کولی شئ دوه لارې وکاروئ (موږ په لیرې سایټ کې د بیک اپ ساتلو په اړه فکر نه کوو):
- فعال - غیر فعال. ټول غوښتنلیکونه د اصلي معلوماتو مرکز کې کوربه شوي دي. نقل کول همغږي یا غیر متناسب دي. که د معلوماتو اصلي مرکز ناکام شي، موږ اړتیا لرو چې بیک اپ فعال کړو. دا په لاسي ډول ترسره کیدی شي / سکریپټونه / آرکیسټریشن غوښتنلیکونه. دلته به موږ د نقل کولو فریکونسۍ سره مطابقت لرونکی RPO ترلاسه کړو ، او RTO د مدیر عکس العمل او مهارتونو او د سویچ کولو پلان د پراختیا / ډیبګ کولو کیفیت پورې اړه لري.
- فعال-فعال. په دې حالت کې، یوازې همغږي تکرار شتون لري؛ د معلوماتو مرکزونو شتون د دریم سایټ کې په کلکه موقعیت لري د کورم / ثالث لخوا ټاکل کیږي. RPO = 0، او RTO کولی شي 0 ته ورسیږي (که غوښتنلیک اجازه ورکړي) یا په مجازی کلستر کې د نوډ د ناکامۍ وخت سره مساوي وي. د مجازی کولو په کچه، یو پراخ شوی (میټرو) کلستر جوړ شوی چې فعال فعال ذخیره ته اړتیا لري.
معمولا موږ ګورو چې پیرودونکو دمخه د اصلي معلوماتو مرکز کې د کلاسیک ذخیره کولو سیسټم سره جوړښت پلي کړی ، نو موږ د نقل لپاره بل ډیزاین کوو. لکه څنګه چې ما یادونه وکړه، سیسکو هایپر فلیکس د غیر متناسب نقل او پراخه مجازی کلستر جوړولو وړاندیز کوي. په ورته وخت کې، موږ د میډرینج کچې وقف شوي ذخیره کولو سیسټم ته اړتیا نلرو او په دوه ذخیره کولو سیسټمونو کې د ګران نقل افعال او فعال - فعال ډیټا لاسرسي سره.
سناریو 1: موږ د لومړني او بیک اپ ډیټا مرکزونه لرو، په VMware vSphere کې د مجازی کولو پلیټ فارم. ټول تولیدي سیسټمونه په اصلي ډیټا مرکز کې موقعیت لري، او د مجازی ماشینونو نقل کول د هایپروایسر په کچه ترسره کیږي، دا به د بیک اپ ډیټا مرکز کې د VMs د فعال ساتلو مخه ونیسي. موږ د جوړ شوي وسیلو په کارولو سره ډیټابیسونه او ځانګړي غوښتنلیکونه نقل کوو او VMs فعال ساتو. که د اصلي معلوماتو مرکز ناکام شي، موږ د بیک اپ ډیټا مرکز کې سیسټمونه پیل کوو. موږ باور لرو چې موږ شاوخوا 100 مجازی ماشینونه لرو. پداسې حال کې چې د لومړني ډیټا مرکز فعال دی، د سټینډ بای ډیټا مرکز کولی شي د ازموینې چاپیریال او نور سیسټمونه پرمخ بوځي چې د لومړني ډیټا مرکز بدلیدو په صورت کې وتړل شي. دا هم امکان لري چې موږ دوه اړخیزه نقل وکاروو. د هارډویر له نظره، هیڅ شی به بدلون ومومي.
د کلاسیک جوړښت په حالت کې، موږ به په هر ډیټا مرکز کې د فایبر چینل له لارې د لاسرسي سره د هایبرډ ذخیره کولو سیسټم نصب کړو، ټیرنګ، ډیپلیکیشن او کمپریشن (مګر آنلاین نه)، د هر سایټ لپاره 8 سرورونه، 2 د فایبر چینل سویچونه او 10G ایترنیټ. په کلاسیک معمارۍ کې د نقل کولو او بدلولو مدیریت لپاره ، موږ کولی شو د VMware اوزار (تکلیف + SRM) یا د دریمې ډلې وسیلې وکاروو ، کوم چې به یو څه ارزانه او ځینې وختونه ډیر اسانه وي.
انځور انځور ښیي.
کله چې د سیسکو هایپر فلیکس کاروئ ، لاندې جوړښت ترلاسه کیږي:
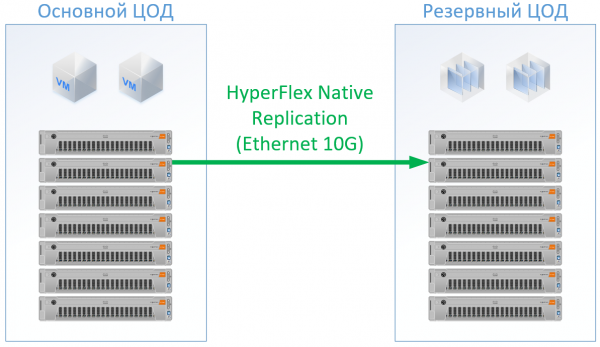
د HyperFlex لپاره، ما د لوی CPU/RAM سرچینو سره سرورونه کارولي، ځکه چې ... ځینې سرچینې به د HyperFlex کنټرولر VM ته لاړ شي؛ د CPU او حافظې په شرایطو کې، ما حتی د HyperFlex ترتیب یو څه بیا تنظیم کړی ترڅو د سیسکو سره لوبې ونه کړي او د پاتې VMs لپاره سرچینې تضمین کړي. مګر موږ کولی شو د فایبر چینل سویچونه پریږدو، او موږ به د هر سرور لپاره ایترنیټ بندرونو ته اړتیا ونلرو؛ سیمه ایز ترافیک په FI کې بدل شوی.
پایله د هر ډیټا مرکز لپاره لاندې ترتیب و:
سرورونه
8 x 1U سرور (384 GB رام، 2 x Intel Gold 6132، FC HBA)
8 x HX240C-M5L (512 GB رام، 2 x Intel Gold 6150، 3,2 GB SSD، 10 x 6 TB NL-SAS)
SHD
د FC فرنټ-اینډ سره د هایبرډ ذخیره کولو سیسټم (20TB SSD، 130 TB NL-SAS)
-
LAN
2 x ایترنیټ سویچ 10G 12 بندرونه
-
سینټ
2 x FC سویچ 32/16Gb 24 بندرونه
2 ایکس سیسکو UCS FI 6332
جوازونه
VMware Ent Plus
د VM سویچنګ نقل او/یا آرکیسټریشن
VMware Ent Plus
ما د هایپرفلیکس لپاره د نقل سافټویر جوازونه ندي چمتو کړي ، ځکه چې دا زموږ لپاره د بکس څخه بهر شتون لري.
د کلاسیک معمارۍ لپاره ، ما یو پلورونکی غوره کړ چې ځان یې د لوړ کیفیت او ارزانه تولید کونکي په توګه رامینځته کړی. د دواړو اختیارونو لپاره ، ما د ځانګړي حل لپاره معیاري تخفیف پلي کړ ، او په پایله کې ما ریښتیني نرخونه ترلاسه کړل.
د سیسکو هایپر فلیکس حل 13٪ ارزانه وګرځید.
سناریو 2: د دوو فعالو معلوماتو مرکزونو جوړول. پدې سناریو کې ، موږ په VMware کې پراخه کلستر ډیزاین کوو.
کلاسیک جوړښت د مجازی کولو سرورونو څخه جوړ دی، یو SAN (FC پروتوکول) او دوه ذخیره سیسټمونه چې کولی شي د دوی تر منځ پراخ شوي حجم ته لوستل او لیکل شي. د ذخیره کولو په هر سیسټم کې موږ د ذخیره کولو لپاره ګټور ظرفیت لرو.
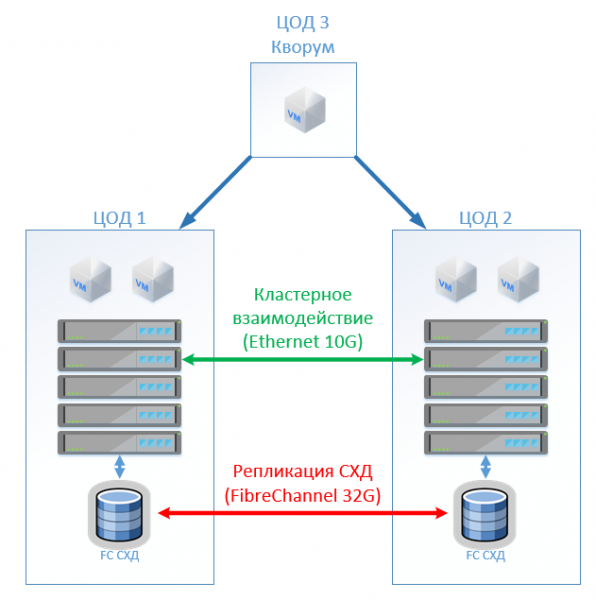
په HyperFlex کې موږ په ساده ډول په دواړو سایټونو کې د ورته شمیر نوډونو سره د سټیچ کلستر جوړوو. په دې حالت کې، د 2+2 د نقل کولو فکتور کارول کیږي.
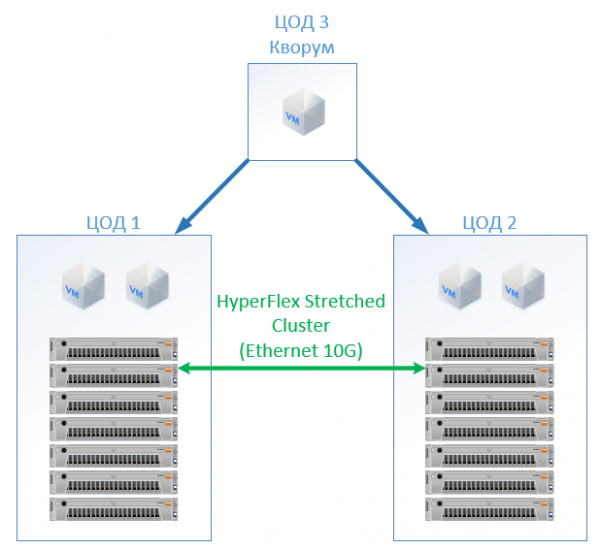
پایله یې لاندې ترتیب دی:
کلاسیک معمارۍ
HyperFlex
سرورونه
16 x 1U سرور (384 GB رام، 2 x Intel Gold 6132، FC HBA، 2 x 10G NIC)
16 x HX240C-M5L (512 GB رام، 2 x Intel Gold 6132، 1,6 TB NVMe، 12 x 3,8 TB SSD، VIC 1387)
SHD
2 x آل فلش ذخیره کولو سیسټمونه (150 TB SSD)
-
LAN
4 x ایترنیټ سویچ 10G 24 بندرونه
-
سینټ
4 x FC سویچ 32/16Gb 24 بندرونه
4 ایکس سیسکو UCS FI 6332
جوازونه
VMware Ent Plus
VMware Ent Plus
په ټولو محاسبو کې، ما د شبکې زیربنا، د معلوماتو مرکز لګښتونه، او نور په پام کې ندي نیولي: دوی به د کلاسیک جوړښت او د هایپر فلیکس حل لپاره یو شان وي.
د لګښت په شرایطو کې، HyperFlex 5٪ ډیر ګران و. دلته د یادولو وړ ده چې د CPU/RAM سرچینو شرایطو کې ما د سیسکو لپاره سکیو درلوده ، ځکه چې په ترتیب کې ما د حافظې کنټرولر چینلونه په مساوي ډول ډک کړل. لګښت یو څه لوړ دی، مګر د اندازې په ترتیب سره نه، کوم چې په روښانه توګه په ګوته کوي چې هایپر کنورژنس ضروري نه دی چې "د شتمنو لپاره یوه لوبه" وي، مګر کولی شي د معلوماتو مرکز جوړولو لپاره د معیاري چلند سره سیالي وکړي. دا ممکن د هغو کسانو لپاره هم د علاقې وړ وي چې دمخه یې د سیسکو UCS سرورونه او د دوی لپاره ورته زیربناوې لري.
د ګټو په مینځ کې ، موږ د SAN او ذخیره کولو سیسټمونو اداره کولو لپاره د لګښتونو نشتوالی ترلاسه کوو ، آنلاین کمپریشن او ډیپلیکیشن ، د ملاتړ لپاره د ننوتلو یو واحد نقطه (مجازی کول ، سرورونه ، دوی د ذخیره کولو سیسټمونه هم دي) ، د ځای خوندي کول (مګر په ټولو سناریوګانو کې نه) ، عملیات ساده کول.
د ملاتړ لپاره، دلته تاسو دا د یو پلورونکي څخه ترلاسه کوئ - سیسکو. د سیسکو UCS سرورونو سره زما د تجربې قضاوت کول ، زه دا خوښوم؛ ما اړتیا نه درلوده چې دا په HyperFlex کې خلاص کړم ، هرڅه ورته کار کوي. انجینران سمدستي ځواب ورکوي او کولی شي نه یوازې عادي ستونزې حل کړي ، بلکه پیچلې څنډې قضیې هم. ځینې وختونه زه دوی ته د پوښتنو سره مخ کیږم: "ایا دا ممکنه ده چې دا کار وکړئ، دا یې وخورئ؟" یا "ما دلته یو څه ترتیب کړی، او دا نه غواړي کار وکړي. مرسته!" - دوی به په صبر سره هلته اړین لارښود ومومي او سم عملونه به په ګوته کړي؛ دوی به ځواب ورنکړي: "موږ یوازې د هارډویر ستونزې حل کوو."
مرجع
- زما برېښنالیک stGeneralov@croc.ru دی.
سرچینه: www.habr.com
