


عصري ویب د رسنیو له محتوا پرته په عملي توګه د تصور وړ نه دی: نږدې هره انا سمارټ فون لري، هرڅوک په ټولنیزو رسنیو کې دي، او د کار بندول د شرکتونو لپاره ګران دي. دلته د شرکت د کیسې یوه لنډه لیکنه ده. د دې په اړه چې څنګه هغې د هارډویر حل په کارولو سره د عکسونو تحویل تنظیم کړ، په پروسه کې یې د فعالیت کومې ستونزې سره مخ شوې، څه یې لامل شوي، او دا ستونزې څنګه د Nginx پر بنسټ د سافټویر حل په کارولو سره حل شوې، پداسې حال کې چې په ټولو کچو کې د غلطیو زغم ډاډمن کول (). د اولیګ د کیسې لیکوالانو څخه مننه ایفیمووا او الکسانډرا ډیمووا، چې په کنفرانس کې یې خپلې تجربې شریکې کړې .
راځئ چې د عکسونو د ذخیره کولو او کیش کولو څرنګوالي په اړه د یوې لنډې پیژندنې سره پیل وکړو. موږ د ذخیره کولو طبقه او د کیش کولو طبقه لرو. که موږ غواړو د لوړ هټ نرخ ترلاسه کړو او د ذخیره کولو بار کم کړو، نو دا زموږ لپاره مهمه ده چې د هر کارونکي عکس په یوه واحد کیش کولو سرور کې زیرمه کړو. که نه نو، موږ باید د هغو سرورونو شمیر سره مساوي ډیسکونه ځای په ځای کړو چې موږ یې لرو. زموږ د هټ کچه شاوخوا 99٪ ده، پدې معنی چې موږ په خپل ذخیره کې بار د 100 فکتور لخوا کموو. د دې ترلاسه کولو لپاره، 10 کاله دمخه، کله چې موږ دا ټول شی جوړاوه، موږ 50 سرورونه درلودل. په پایله کې، د دې عکسونو خدمت کولو لپاره، موږ په اصل کې د دې سرورونو لخوا خدمت شوي 50 بهرني ډومینونو ته اړتیا درلوده.
په طبیعي ډول، پوښتنه سمدلاسه راپورته شوه: که زموږ یو سرور ښکته شي او شتون ونلري، نو موږ به څومره ټرافیک له لاسه ورکړو؟ موږ هغه څه ته وکتل چې په بازار کې شتون لري او پریکړه مو وکړه چې هغه هارډویر واخلو چې زموږ ټولې ستونزې به حل کړي. موږ د F5-شبکې څخه یوه حل لاره غوره کړه (کوم چې په تصادفي ډول پدې وروستیو کې NGINX، Inc. ترلاسه کړی): BIG-IP سیمه ایز ټرافیک مدیر.

دا هارډویر (LTM) څه کوي؟ دا یو هارډویر روټر دی چې په خپلو بهرنیو بندرونو کې د هارډویر بې ځایه والی ترسره کوي او د شبکې ټوپولوژي او ځینې ترتیباتو پراساس ټرافیک روټ کوي، او د روغتیا چکونه ترسره کوي. دا زموږ لپاره مهمه وه چې دا هارډویر د پروګرام وړ وي. له همدې امله، موږ کولی شو د هغه منطق تشریح کړو چې څنګه د یو ځانګړي کارونکي لپاره عکسونه د یو ځانګړي کیش څخه وړاندې شوي. دا څه ډول ښکاري؟ د هارډویر یوه ټوټه شتون لري چې د یو واحد ډومین، یو واحد IP پتې له لارې انټرنیټ ته لاسرسی لري، د SSL آفلوډونه ترسره کوي، د HTTP غوښتنې پارس کوي، د IRule څخه د کیش شمیره غوره کوي ترڅو ټرافیک ته روټ کړي، او هلته یې روټ کړي. دا د روغتیا چکونه هم ترسره کوي، او که چیرې یو ماشین شتون ونلري، موږ دا تنظیم کړی ترڅو ټرافیک یو واحد بیک اپ سرور ته روټ کړي. البته، د ترتیب په برخه کې ځینې لنډیزونه شتون لري، مګر په ټولیز ډول، دا خورا ساده دی: موږ نقشه تعریف کوو، په شبکه کې زموږ د IP پتې ته یو شمیر ورکوو، مشخص کوو چې موږ به په 80 او 443 پورټونو کې اورو، مشخص کوو چې که سرور شتون ونلري، موږ باید ترافیک بیک اپ ته واړوو، پدې حالت کې، پورټ 35، او د دې جوړښت ماتولو لپاره د منطق یوه ډله تشریح کړو. یوازینۍ ستونزه دا وه چې هارډویر په Tcl کې پروګرام شوی و. که څوک حتی دا په یاد ولري ... دا د پروګرام کولو ژبې په پرتله یوازې د لیکلو ژبه ده:

موږ څه ترلاسه کړل؟ موږ داسې هارډویر ترلاسه کړ چې زموږ د زیربنا لوړه شتون تضمینوي، زموږ ټول ټرافیک روټ کوي، روغتیایی معاینات چمتو کوي، او په ساده ډول کار کوي. او دا د ډیر وخت راهیسې کار کوي: په تیرو لسو کلونو کې ورسره کومه ستونزه نه وه. د 2018 کال په پیل کې، موږ دمخه په هره ثانیه کې شاوخوا 80,000 عکسونه وړاندې کول. دا زموږ د دواړو معلوماتو مرکزونو څخه شاوخوا 80 ګیګابایټ ټرافیک دی.
خو…
د ۲۰۱۸ کال په پیل کې، موږ په خپلو ګرافونو کې یو څه بدمرغه ولیدل: د عکسونو رسولو وختونه په څرګنده توګه زیات شوي وو. او موږ نور له دې څخه راضي نه وو. ستونزه دا وه چې دا چلند یوازې د ترافیک په لوړ ساعتونو کې د پام وړ و - زموږ د شرکت لپاره، دا د یکشنبې له شپې څخه تر دوشنبې پورې دی. مګر پاتې وخت، سیسټم د معمول په څیر چلند کاوه، د خرابیدو نښې نښانې پرته.

سره له دې، ستونزه باید حل شي. موږ احتمالي خنډونه وپیژندل او د هغوی له منځه وړل یې پیل کړل. البته، لومړی او تر ټولو مهم، موږ بهرني اپ لینکونه پراخ کړل، د داخلي اپ لینکونو بشپړ تفتیش مو ترسره کړ، او ټول ممکنه خنډونه مو وپیژندل. مګر له دې څخه هیڅ یو یې کومه څرګنده پایله نه ده ورکړې؛ ستونزه دوام لري.
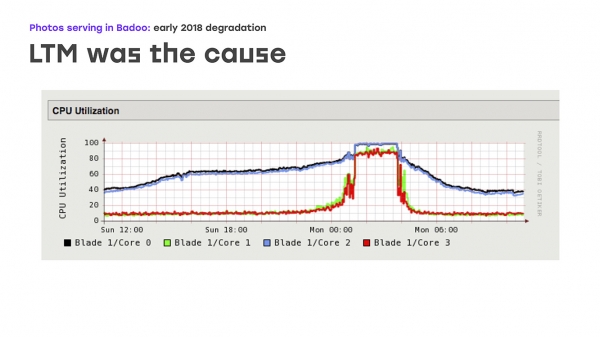
بله احتمالي ستونزه د عکسونو د کیشونو فعالیت و. موږ پریکړه وکړه چې شاید ستونزه هلته وي. نو، موږ فعالیت پراخ کړ - په عمده توګه د عکسونو کیشونو کې د شبکې پورټونه. مګر بیا، موږ هیڅ څرګند پرمختګ ونه لید. په پای کې، موږ پخپله د LTM فعالیت ته نږدې پاملرنه وکړه، او په ګرافونو کې یو نا امیده انځور ولید: د CPU کارول په اسانۍ سره پیل شول، مګر بیا ناڅاپه لوړ شو. په ورته وخت کې، LTM د اپ لینک روغتیا چکونو ته په مناسب ډول ځواب ورکول بند کړل او په ناڅاپي ډول یې غیر فعال کول پیل کړل، چې د فعالیت جدي تخریب لامل شو.
نو، موږ د ستونزې سرچینه او خنډ پیژندلی دی. اوس یوازې دا پاتې ده چې پریکړه وکړو چې څه وکړو.
لومړی، تر ټولو څرګند، هغه څه چې موږ یې کولی شو هغه دا وو چې په یو ډول د LTM پخپله عصري کړو. مګر پدې کې ځینې لنډیزونه شتون لري، ځکه چې دا هارډویر خورا ځانګړی دی؛ تاسو نشئ کولی یوازې نږدې سوپر مارکیټ ته لاړ شئ او دا واخلئ. دا یو جلا قرارداد دی، یو جلا جواز تړون دی، او دا به ډیر وخت ونیسي. دوهم انتخاب دا دی چې په خپلواکه توګه فکر پیل کړئ، زموږ د خپلو برخو په کارولو سره زموږ خپل حل رامینځته کړئ، په غوره توګه د خلاصې سرچینې سافټویر په کارولو سره. ټول هغه څه چې پاتې دي دا دي چې پریکړه وکړو چې موږ به د دې لپاره څه غوره کړو او څومره وخت به د دې ستونزې په حل کې مصرف کړو، ځکه چې کاروونکو کافي عکسونه نه ترلاسه کول. له همدې امله، دا ټول باید ډیر، ډیر ژر، په عملي توګه پرون ترسره شي.
څرنګه چې هدف دا و چې "د هغه هارډویر په کارولو سره چې موږ یې لرو ژر تر ژره یو څه ترسره کړو،" زموږ لومړی فکر دا و چې په ساده ډول د مخکینۍ برخې څخه ځینې لږ ځواکمن ماشینونه لرې کړو، Nginx نصب کړو، کوم چې موږ ورسره آرام یو، او هڅه وکړو چې ټول ورته منطق پلي کړو چې هارډویر مخکې اداره کړی و. نو، په اصل کې، موږ خپل هارډویر وساتو، څلور نور سرورونه نصب کړل، کوم چې موږ باید تنظیم کړو، او د دوی لپاره بهرني ډومینونه جوړ کړل، لکه څنګه چې موږ 10 کاله دمخه ترسره کړي وو ... که چیرې دا ماشینونه بند شي نو موږ د شتون په برخه کې یو څه زیان سره مخ شو، مګر موږ بیا هم د خپلو کاروونکو ستونزه په محلي توګه حل کوله.
په همدې اساس، منطق ورته پاتې دی: موږ Nginx نصب کوو، دا کولی شي د SSL آفلوډینګ ترسره کړي، موږ کولی شو په یو ډول د روټینګ منطق پروګرام کړو، په ترتیبونو کې روغتیا چکونه وکړو او په ساده ډول هغه منطق نقل کړو چې موږ مخکې درلود.
راځئ چې د ترتیب فایلونو لیکل پیل کړو. په لومړي سر کې، دا خورا ساده ښکاریده، مګر له بده مرغه، د هر کار لپاره لارښود موندل خورا ستونزمن دي. له همدې امله، موږ په ساده ډول د ګوګل کولو سپارښتنه نه کوو "څنګه د عکسونو لپاره Nginx تنظیم کړئ": دا غوره ده چې د رسمي اسنادو سره مشوره وکړئ، کوم چې به تاسو ته وښيي چې کوم ترتیبات بدل کړئ. په هرصورت، دا غوره ده چې ځانګړي پیرامیټونه پخپله غوره کړئ. له هغې وروسته، هرڅه ساده دي: موږ هغه سرورونه تشریح کوو چې موږ یې لرو، موږ سندونه تشریح کوو ... مګر ترټولو په زړه پورې برخه، په حقیقت کې، د روټینګ منطق پخپله دی.
په لومړي سر کې، موږ فکر کاوه چې موږ به په ساده ډول خپل موقعیت تشریح کړو، زموږ د عکس کیش شمیره به ورسره مل کړو، په لاسي ډول یا د جنراتور په مرسته، تشریح کړو چې موږ څومره اپسټریم ته اړتیا لرو، او په هر اپسټریم کې، هغه سرور مشخص کړو چې ټرافیک باید ورته لاړ شي، او همدارنګه د بیک اپ سرور که چیرې اصلي سرور شتون ونلري:

خو شاید که هرڅه دومره ساده وای، موږ به په ساده ډول کور ته تللي وای او هیڅ به نه وای. له بده مرغه، د Nginx د ډیفالټ ترتیباتو سره، کوم چې په حقیقت کې د ډیرو کلونو پراختیا په اوږدو کې بدل شوي وو او د دې کارونې قضیې سره سم ندي ... ترتیب داسې ښکاري: که چیرې یو اپ سټریم سرور د غوښتنې تېروتنه یا وخت پای ته ورسیږي، Nginx تل ټرافیک بل ته بدلوي. سربیره پردې، د لومړۍ ناکامۍ وروسته، سرور به هم د 10 ثانیو دننه وتړل شي، دواړه د غلطۍ او وخت پای ته رسیدو له امله - دا حتی د تنظیم وړ ندي. نو، که موږ د اپ سټریم لارښود کې د وخت پای اختیار لرې یا بیا تنظیم کړو، که څه هم Nginx به غوښتنه پروسس نه کړي او د یو ډول ناوړه غلطۍ سره به ځواب ووایی، سرور به لاهم بند شي.

د دې د مخنیوي لپاره، موږ دوه کارونه وکړل:
الف) نګینکس د دې کار په لاسي ډول کولو څخه منع شوی و - او له بده مرغه، د دې کولو یوازینۍ لار دا ده چې په ساده ډول د اعظمي ناکامۍ ترتیبات تنظیم کړئ.
ب) موږ په یاد ولرو چې په نورو پروژو کې موږ یو ماډل کاروو چې موږ ته اجازه راکوي چې د شالید روغتیا معاینات ترسره کړو. په همدې اساس، موږ د روغتیا معاینات په مکرر ډول ترسره کړل ترڅو د پیښې په صورت کې د ځنډ وخت لږترلږه وي.
له بده مرغه، دا ټول نه دي، ځکه چې په لفظي ډول د دې تنظیم لومړۍ دوه اونۍ وښودله چې د TCP روغتیا چک کول هم د اعتبار وړ ندي: د اپ سټریم سرور ممکن Nginx نه چلوي، یا Nginx ممکن په D-state کې روان وي، په دې حالت کې کرنل به اړیکه ومني، د روغتیا چک به تیر شي، مګر دا به کار ونکړي. نو موږ سمدلاسه دا د HTTP روغتیا چک سره بدل کړ، یو ځانګړی یې رامینځته کړ چې، که دا 200 بیرته راولي، نو هرڅه پدې سکریپټ کې کار کوي. اضافي منطق پلي کیدی شي - د مثال په توګه، د کیش کولو سرورونو په حالت کې، دا چیک کول چې د فایل سیسټم په سمه توګه نصب شوی:

موږ به له دې څخه خوښ یو، پرته له دې چې اوسني ترتیب په بشپړ ډول هغه څه تکرار کړي چې هارډویر یې کوي. مګر موږ غوښتل چې ښه کار وکړو. پخوا، موږ یو واحد بیک اپ سرور درلود، او دا شاید مثالی نه وي، ځکه چې که تاسو سل سرورونه ولرئ، نو که چیرې په یو وخت کې څو ټکرونه وي، نو یو واحد بیک اپ سرور د بار اداره کولو امکان نلري. نو موږ پریکړه وکړه چې په ټولو سرورونو کې بې ځایه والی وویشو: موږ په ساده ډول یو بل جلا اپ سټریم رامینځته کړ، ټول سرورونه یې د دوی د بار ظرفیت پراساس د ځانګړو پیرامیټرو سره اضافه کړل، او ورته روغتیا چکونه چې موږ یې مخکې درلودل اضافه کړل:

څرنګه چې د یو اپ سټریم دننه بل اپ سټریم ته لاسرسی ناممکن دی، موږ اړتیا درلوده چې دا داسې جوړ کړو چې که اصلي اپ سټریم، کوم چې د سم، اړین عکس کیش لیکلو لپاره کارول کیده، شتون ونلري، موږ به په ساده ډول د فال بیک لاسرسي لپاره error_page وکاروو، له هغه ځایه به موږ بیک اپ اپ سټریم ته لاسرسی ولرو:

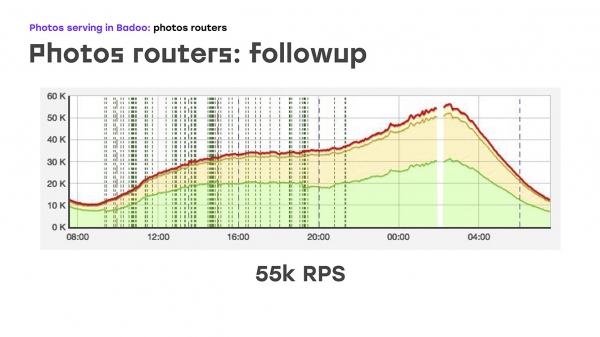
او په لفظي ډول د څلورو سرورونو په اضافه کولو سره، دا هغه څه دي چې موږ ترلاسه کړل: موږ د بار یوه برخه بدله کړه — دا له LTM څخه دې سرورونو ته افلوډ کړه. موږ هلته ورته منطق د معیاري هارډویر او سافټویر په کارولو سره پلي کړ. موږ سمدلاسه د پراخیدو بونس ترلاسه کړ ځکه چې موږ کولی شو په ساده ډول د اړتیا په صورت کې ډیری ځای په ځای کړو. یوازینۍ نیمګړتیا دا وه چې موږ د بهرني کاروونکو لپاره لوړ شتون له لاسه ورکړ. مګر په هغه وخت کې، موږ باید دا قرباني کړو ځکه چې موږ اړتیا درلوده چې ستونزه سمدلاسه حل کړو. نو، موږ د بار یوه برخه افلوډ کړه — په هغه وخت کې شاوخوا 40٪ — LTM ښه شو، او په لفظي توګه د ستونزې له پیل څخه دوه اونۍ وروسته، موږ په هره ثانیه کې 45 غوښتنې وړاندې کولې، چې له 55 څخه پورته وې. په اصل کې، موږ 20٪ وده وکړه — دا په څرګنده توګه هغه ټرافیک دی چې موږ یې کم خدمت کاوه. او له هغې وروسته، موږ د پاتې ستونزې د حل کولو په اړه فکر کول پیل کړل — د لوړ بهرني شتون ډاډمن کول.
موږ د هغه حل په اړه چې موږ به یې کاروو بحث کولو پرمهال یو لنډ وقفه واخیسته. د DNS، دودیز سکریپټونو، متحرک روټینګ پروتوکولونو په کارولو سره د اعتبار ډاډ ترلاسه کولو لپاره وړاندیزونه وو ... ډیری اختیارونه وو، مګر دا روښانه شوه چې د ریښتینې باوري عکس رسولو لپاره، موږ اړتیا لرو چې د هغې اداره کولو لپاره بل پرت معرفي کړو. موږ دې ماشینونو ته د عکس ډایرکټرانو نوم ورکړ. موږ د هغه سافټویر په توګه Keepalived غوره کړ چې موږ پرې تکیه کوله:

راځئ چې د هغه څه سره پیل وکړو چې کیپالیوډ پکې شامل دي. لومړی، د VRRP پروتوکول، چې په پراخه کچه د شبکې کاروونکو لپاره پیژندل شوی، د شبکې تجهیزاتو کې موقعیت لري، د بهرني IP پتې لپاره د غلطۍ زغم چمتو کوي چې مراجعین ورسره وصل کیږي. دوهمه برخه IPVS ده، د IP مجازی سرور، د عکس روټرونو ترمنځ د بار توازن لپاره او پدې کچه کې د غلطۍ زغم ډاډمن کولو لپاره. او دریم، د روغتیا چکونه.
راځئ چې د لومړۍ برخې سره پیل وکړو: VRRP—دا څنګه ښکاري؟ په badoocdn.com کې د DNS ننوتلو سره یو مجازی IP پته شتون لري، چې مراجعین ورسره وصل کیږي. په یو وخت کې، دا IP پته په یو واحد سرور کې شتون لري. د VRRP پروتوکول په کارولو سره د سرورونو ترمنځ د Keepalive پیکټونه لیږل کیږي، او که ماسټر له لید څخه ورک شي (د ریبوټ یا بل څه له امله)، د بیک اپ سرور په اتوماتيک ډول دا IP پته راوړي — هیڅ لاسي مداخلې ته اړتیا نشته. د ماسټر او بیک اپ سرورونو ترمنځ توپیر په عمده توګه په لومړیتوب کې دی: څومره چې لومړیتوب لوړ وي، د ماشین د ماسټر کیدو چانس ډیر وي. یوه ډیره لویه ګټه دا ده چې تاسو اړتیا نلرئ په سرور کې د IP پتې تنظیم کړئ؛ دوی په ساده ډول په ترتیب فایل کې تعریف کیدی شي. که چیرې دا IP پتې کوم دودیز روټینګ قواعدو ته اړتیا ولري، دا په مستقیم ډول په ترتیب فایل کې تعریف شوي، د VRRP پاکټ په څیر ورته ترکیب کاروي. تاسو به د کوم ناپیژندل شوي ځانګړتیاو سره مخ نه شئ.
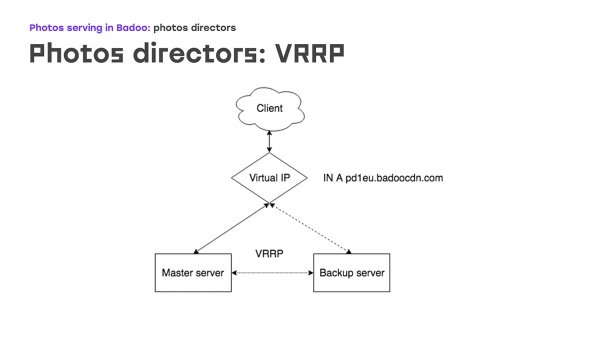
دا په عمل کې څنګه کار کوي؟ که چیرې یو سرور ناکام شي نو څه پیښیږي؟ هرڅومره ژر چې ماسټر ښکته شي، زموږ بیک اپ د اعلاناتو ترلاسه کول ودروي او په اتوماتيک ډول ماسټر کیږي. یو څه وخت وروسته، موږ ماسټر ترمیم کوو، بیا یې بیا پیل کوو، او Keepalived فعالوو — اعلانونه د بیک اپ په پرتله لوړ لومړیتوب سره راځي، او بیک اپ په اتوماتيک ډول بیرته راګرځي، د هغې IP پتې لرې کوي — هیڅ لاسي عمل ته اړتیا نشته.

نو، موږ د بهرني IP پتې د غلطۍ زغم ډاډمن کړی دی. بل ګام دا دی چې په یو ډول د بهرني IP پتې څخه د عکس روټرونو ته ټرافیک متوازن کړو، کوم چې بیا یې پای ته رسوي. د توازن پروتوکولونه خورا روښانه دي. دا یا یو ساده راؤنډ روبین دی یا یو څه ډیر پیچلي شیان لکه wrr، د لیست اتصال، او داسې نور. دا عموما په اسنادو کې تشریح شوی؛ پدې کې هیڅ ځانګړی شی نشته. د تحویلي میتود په اړه ... راځئ چې نږدې وګورو چې ولې موږ یو له دوی څخه غوره کړ. دا NAT، مستقیم روټینګ، او TUN دي. خبره دا ده چې موږ په پیل کې پلان درلود چې له سایټونو څخه 100 ګیګابایټ ټرافیک وړاندې کړو. دا پدې مانا ده چې تاسو به 10 ګیګابایټ کارتونو ته اړتیا ولرئ، سمه ده؟ په یوه سرور کې لس ګیګابایټ کارتونه - دا د هغه څه هاخوا دي چې موږ یې "معیاري تجهیزات" ګڼو. او بیا موږ په یاد ولرو چې موږ یوازې ټرافیک نه ورکوو؛ موږ عکسونه ورکوو.
په دې کې څه ځانګړی دی؟ — د راتلوونکي او وتلوونکي ټرافیک ترمنځ لوی توپیر شتون لري. راتلونکی ټرافیک خورا کوچنی دی، پداسې حال کې چې بهر ته تلونکی ټرافیک خورا لوی دی:
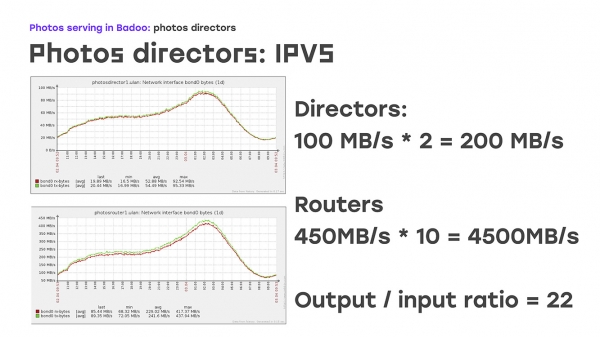
د دې ګرافونو په لیدلو سره، تاسو لیدلی شئ چې ډایرکټر اوس مهال په هره ثانیه کې شاوخوا 200 MB ترلاسه کوي؛ دا یوه عادي ورځ ده. موږ په هره ثانیه کې 4,500 MB بیرته لیږو، چې د نږدې 1/22 تناسب دی. دا روښانه ده چې د 22 کارګر سرورونو ته د وتلو ترافیک بشپړ ملاتړ کولو لپاره، موږ یوازې یو سرور ته اړتیا لرو چې دا اړیکه ومني. دا هغه ځای دی چې د مستقیم روټینګ الګوریتم راځي.
دا څنګه ښکاري؟ زموږ د عکس ډایرکټر زموږ د عکس روټرونو سره اړیکې د خپل میز سره سم لیږدوي. په هرصورت، د عکس روټرونه بیرته راستنیدونکي ټرافیک مستقیم انټرنیټ ته، مراجع ته لیږي؛ دا د عکس ډایرکټر له لارې بیرته نه تیریږي. پدې توګه، د لږترلږه ماشینونو سره، موږ د بشپړ غلطی زغم او بشپړ ترافیک جریان ډاډمن کوو. د ترتیب فایلونو کې، دا داسې ښکاري: موږ الګوریتم مشخص کوو - زموږ په قضیه کې، یو ساده RR - مستقیم روټینګ فعالوي، او بیا د ټولو اصلي سرورونو لیست پیل کوو چې موږ یې لرو، کوم چې دا ټرافیک به ټاکي. که موږ یو یا دوه نور سرورونه اضافه کړو، یا که اړتیا رامنځته شي، موږ په ساده ډول دا برخه د ترتیب فایل ته اضافه کوو او د هغې په اړه ډیره اندیښنه نه کوو. دا طریقه د اصلي سرورونو په اړخ کې، او همدارنګه د عکس روټر په اړخ کې خورا لږترلږه ترتیب ته اړتیا لري. دا ښه مستند شوی، او هیڅ زیانونه شتون نلري.
هغه څه چې په ځانګړي ډول ښه دي دا دي چې دا حل د محلي شبکې بشپړ بیاکتنې ته اړتیا نلري، کوم چې زموږ لپاره مهم و؛ موږ اړتیا درلوده چې دا په لږترلږه لګښت سره حل کړو. که تاسو وګورئ ، موږ به وګورو چې دا څنګه ښکاري. دلته موږ یو مجازی سرور لرو، په پورټ 443 کې اورو، اړیکې منو، ټول کاري سرورونه شمیرو، او موږ ګورو چې اړیکه لږ یا ډیر ورته ده. که موږ په ورته مجازی سرور کې احصایې وګورو، موږ راتلونکي پیکټونه، راتلونکي اړیکې ګورو، مګر په بشپړ ډول هیڅ بهر ته نه ځي. بهر ته تلونکي اړیکې مستقیم مراجع ته ځي. سمه ده، موږ اداره کړې چې دا غیر متوازن کړو. اوس، څه پیښیږي که زموږ د عکس روټرونو څخه یو ناکام شي؟ هارډویر هارډویر دی، بالاخره. دا کولی شي د کرنل ویره ته لاړ شي، دا ماتیدلی شي، د بریښنا رسولو سوځیدلی شي. هرڅه. دا هغه څه دي چې د روغتیا چکونه دي. دوی کولی شي د چک کولو په څیر ساده وي چې ایا پورټ خلاص دی، یا ډیر پیچلي، په شمول د دودیز سکریپټونو چې حتی د سوداګرۍ منطق به وګوري.
موږ په منځ کې یو ځای حل شوي یو: موږ یو ځانګړي ځای ته د HTTPS غوښتنه لرو، یو سکریپټ ویل کیږي، او که دا د 200 ځواب سره ځواب ووایی، موږ فرض کوو چې سرور سم دی، دا ژوندی دی، او موږ کولی شو دا په خوندي ډول فعال کړو.
دلته دا په عمل کې داسې ښکاري. راځئ چې فرض کړو چې یو سرور د ساتنې لپاره تړل شوی دی — د مثال په توګه، د BIOS تازه کول. په لاګونو کې سمدلاسه د وخت پای څرګندیږي. موږ لومړۍ کرښه ګورو. بیا، د دریو هڅو وروسته، دا د "ناکام" په توګه نښه کیږي، او سرور په ساده ډول له لیست څخه لرې کیږي.

بله ممکنه سناریو دا ده چې VS په صفر باندې تنظیم کړئ، مګر دا د عکسونو وړاندې کولو پرمهال ښه کار نه کوي. سرور راځي، Nginx پیل کیږي، د روغتیا معاینات سمدلاسه کشف کوي چې اړیکه بریالۍ ده، هرڅه سم دي، او سرور زموږ په لیست کې څرګندیږي، او بار په اتوماتيک ډول په هغې باندې پلي کیږي. د دندې پر مهال مدیر څخه هیڅ لاسي عمل ته اړتیا نشته. سرور د شپې بیا پیل کیږي — د څارنې څانګه موږ ته د دې په اړه زنګ نه وهي. دوی موږ ته خبر ورکوي چې دا پیښ شوی، او هرڅه سم دي.
نو، په خورا ساده ډول، د لږ شمیر سرورونو په کارولو سره، موږ د بهرني غلطی زغم ستونزه حل کړه.
دا د یادونې وړ ده چې دا ټول، البته، باید وڅارل شي. دا د یادونې وړ ده چې Keepalivede، د سافټویر د یوې خورا زړې برخې په توګه، د دې د څارنې لپاره ډیری لارې لري، پشمول د DBus، SMTP، او SNMP چکونو، او همدارنګه معیاري Zabbix له لارې. برسېره پردې، دا کولی شي په عملي توګه د هر کوچني شی لپاره بریښنالیکونه واستوي، او په ریښتیا سره، په یوه وخت کې موږ حتی د دې غیر فعالولو په اړه فکر وکړ ځکه چې دا د هر ټرافیک سویچ، هر پیل، هر IP پته، او داسې نورو لپاره ډیر بریښنالیکونه لیږي. البته، که تاسو ډیری سرورونه لرئ، تاسو کولی شئ د دې بریښنالیکونو سره ډوب شئ. موږ د معیاري میتودونو په کارولو سره د عکس روټرونو کې Nginx څارنه کوو، او د هارډویر څارنه لاهم شتون لري. موږ به، البته، دوه نور شیان وړاندیز وکړو: لومړی، د بهرني شتون روغتیا چکونه، ځکه چې حتی که هرڅه کار وکړي، کاروونکي ممکن د بهرني چمتو کونکو سره د ستونزو یا یو څه ډیر پیچلي شی له امله عکسونه ترلاسه نکړي. دا تل ارزښت لري چې په بل شبکه کې یو جلا ماشین وساتئ، لکه ایمیزون یا بل چیرې، چې کولی شي ستاسو سرورونه له بهر څخه پنګ کړي. دا د هغو کسانو لپاره چې د پیچلي ماشین زده کړې کې مهارت لري، یا ساده څارنه، یا د بې نظمۍ کشف کارولو ارزښت لري، لږترلږه د دې لپاره چې ایا غوښتنې کمې شوې یا په چټکۍ سره زیاتې شوې دي. دا هم ګټور کیدی شي.
لنډیز: موږ په اصل کې د هارډویر حل بدل کړ، کوم چې په یو وخت کې موږ نور نه راضي کوو، د یو ساده سیسټم سره چې ورته کار کوي، دا دی، دا د HTTPS ټرافیک پای ته رسولو او د اړین روغتیا چکونو سره وروسته سمارټ روټینګ چمتو کوي. موږ د دې سیسټم ثبات زیات کړی دی، پدې معنی چې موږ په هر پرت کې لوړ شتون ساتو. برسیره پردې، د بونس په توګه، موږ په هر پرت کې د پیمانه کولو اسانتیا ترلاسه کړې ځکه چې دا د معیاري سافټویر سره معیاري هارډویر دی، پدې معنی چې موږ خپل د ستونزو حل کول ساده کړي دي.
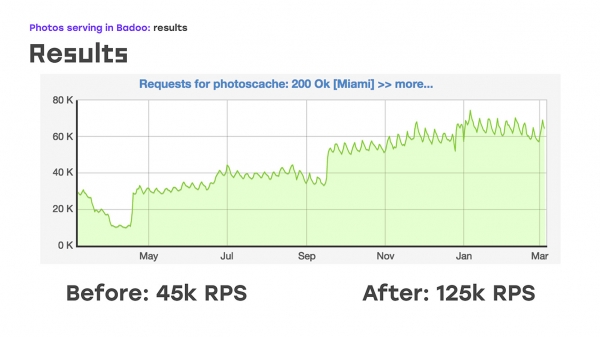
موږ په پای کې څه ترلاسه کړل؟ موږ د ۲۰۱۸ کال د جنوري د رخصتیو په جریان کې له یوې ستونزې سره مخ شو. په لومړیو شپږو میاشتو کې، پداسې حال کې چې موږ دا سیسټم پلي کاوه او د LTM څخه د ټولو ټرافیکونو د خلاصولو لپاره یې پراخول، موږ په یوه ډیټا مرکز کې ټرافیک له ۴۰ ګیګابایټ څخه ۶۰ ګیګابایټ ته لوړ کړ، او په ورته وخت کې، د ټول ۲۰۱۸ کال لپاره، موږ وکولی شو چې په هره ثانیه کې نږدې درې چنده ډیر عکسونه وړاندې کړو.
سرچینه: www.habr.com
