

هن آرٽيڪل ۾، مان ڳالهائيندس ته ڪيئن پروجيڪٽ جنهن تي آئون ڪم ڪري رهيو آهيان هڪ وڏي مانوليٿ کان مائڪرو سروسز جي هڪ سيٽ ۾ تبديل ٿي.
پروجيڪٽ پنهنجي تاريخ ڪافي وقت اڳ، 2000 جي شروعات ۾ شروع ڪئي هئي. پهريون نسخو Visual Basic 6 ۾ لکيو ويو هو. وقت گذرڻ سان، اهو واضح ٿي ويو ته مستقبل ۾ هن ٻولي جي ترقي کي سپورٽ ڪرڻ ڏکيو هوندو، ڇاڪاڻ ته IDE. ۽ ٻولي پاڻ خراب ترقي يافته آهن. 2000s جي آخر ۾، ان کي تبديل ڪرڻ جو فيصلو ڪيو ويو وڌيڪ پرجوش C#. نئون نسخو پراڻي نسخي سان متوازي لکيو ويو، آهستي آهستي وڌيڪ ۽ وڌيڪ ڪوڊ .NET ۾ لکيو ويو. C# ۾ پس منظر شروعاتي طور تي هڪ خدمت آرڪيٽيڪچر تي مرکوز هو، پر ترقي جي دوران، منطق سان گڏ عام لائبريريون استعمال ڪيون ويون، ۽ خدمتون هڪ واحد عمل ۾ شروع ڪيون ويون. نتيجو هڪ ايپليڪيشن هئي جنهن کي اسان سڏيو ويندو آهي "سروس مونولٿ."
هن ميلاپ جي چند فائدن مان هڪ هڪ ٻاهرين API ذريعي هڪ ٻئي کي ڪال ڪرڻ جي خدمتن جي صلاحيت هئي. وڌيڪ صحيح خدمت ڏانهن منتقلي لاءِ واضح شرطون هيون، ۽ مستقبل ۾، مائڪرو سروس فن تعمير.
اسان 2015 جي ڀرسان اسان جي ڪم کي ختم ڪرڻ تي شروع ڪيو. اسان اڃا تائين هڪ مثالي حالت تي پهچي نه سگهيا آهيون - اڃا تائين هڪ وڏي منصوبي جا حصا آهن جن کي شايد ئي monoliths سڏيو وڃي، پر اهي مائڪرو سروسز وانگر نظر نه ٿا اچن. تنهن هوندي به، ترقي اهم آهي.
مون کي مضمون ۾ ان جي باري ۾ ڳالهائي ويندي.
Contents
فن تعمير ۽ موجوده حل جي مسئلن
شروعات ۾، آرڪيٽيڪچر هن طرح نظر آيو: UI هڪ الڳ ايپليڪيشن آهي، monolithic حصو Visual Basic 6 ۾ لکيل آهي، .NET ايپليڪيشن لاڳاپيل خدمتن جو هڪ سيٽ آهي جيڪو ڪافي وڏي ڊيٽابيس سان ڪم ڪري ٿو.
پوئين حل جا نقصان
ناڪامي جو واحد نقطو
اسان وٽ ناڪامي جو ھڪڙو نقطو ھو: .NET ايپليڪيشن ھڪڙي ھڪڙي عمل ۾ ھليو. جيڪڏهن ڪو به ماڊل ناڪام ٿيو، سڄي ايپليڪيشن ناڪام ٿي ۽ ٻيهر شروع ڪيو وڃي. جيئن ته اسان مختلف استعمال ڪندڙن لاءِ وڏي تعداد ۾ عمل کي خودڪار ڪيو، انهن مان هڪ ۾ ناڪامي جي ڪري، هرڪو ڪجهه وقت لاءِ ڪم نه ڪري سگهيو. ۽ سافٽ ويئر جي غلطي جي صورت ۾، بيڪ اپ به مدد نه ڪئي.
سڌارن جي قطار
هي خرابي بلڪه تنظيمي آهي. اسان جي ائپليڪيشن ۾ ڪيترائي گراهڪ آهن، ۽ اهي سڀئي جلد کان جلد ان کي بهتر بڻائڻ چاهيندا آهن. اڳي، اهو متوازي ۾ اهو ڪرڻ ناممڪن هو، ۽ سڀئي گراهڪ قطار ۾ بيٺا هئا. اهو عمل ڪاروبار لاءِ منفي هو ڇاڪاڻ ته انهن کي ثابت ڪرڻو هو ته انهن جو ڪم قيمتي هو. ۽ ترقياتي ٽيم هن قطار کي منظم ڪرڻ ۾ وقت گذاريو. اهو تمام گهڻو وقت ۽ ڪوشش ورتي، ۽ پيداوار آخرڪار تبديل نه ٿي سگهيا جيترو جلدي انهن کي پسند ڪيو ها.
وسيلن جو ذيلي استعمال
جڏهن ميزباني ڪيل خدمتون هڪ واحد عمل ۾، اسان هميشه مڪمل طور تي سرور کان سرور تائين ترتيبن کي نقل ڪيو. اسان چاهيون ٿا ته سڀ کان وڌيڪ لوڊ ٿيل خدمتون الڳ الڳ رکون ته جيئن وسيلن کي ضايع نه ڪيو وڃي ۽ اسان جي ڊيپلائيمينٽ اسڪيم تي وڌيڪ لچڪدار ڪنٽرول حاصل ڪيو وڃي.
جديد ٽيڪنالاجي لاڳو ڪرڻ ڏکيو
ھڪڙو مسئلو سڀني ڊولپرز کان واقف آھي: ھڪڙي منصوبي ۾ جديد ٽيڪنالاجي متعارف ڪرائڻ جي خواهش آھي، پر ڪو موقعو نه آھي. هڪ وڏي monolithic حل سان، موجوده لائبريري جي ڪنهن به تازه ڪاري، هڪ نئين ڏانهن منتقلي جو ذڪر نه ڪرڻ، بلڪه غير معمولي ڪم ۾ بدلجي ٿو. ٽيم جي اڳواڻ کي ثابت ڪرڻ ۾ هڪ ڊگهو وقت لڳندو آهي ته اهو ضايع ٿيل اعصاب کان وڌيڪ بونس آڻيندو.
تبديليون جاري ڪرڻ ۾ مشڪلات
اهو سڀ کان وڌيڪ سنگين مسئلو هو - اسان هر ٻن مهينن ۾ رليز جاري ڪري رهيا هئاسين.
ڊولپرز جي جاچ ۽ ڪوششن جي باوجود، هر رليز بينڪ لاءِ حقيقي آفت ۾ تبديل ٿي وئي. ڪاروبار سمجهي ويو ته هفتي جي شروعات ۾ ان جي ڪجهه ڪارڪردگي ڪم نه ڪندي. ۽ ڊولپر سمجهي ٿو ته هڪ هفتي سنگين واقعن جو انتظار ڪري رهيا آهن.
هر ڪنهن جي دل ۾ حالت بدلائڻ جي خواهش هئي.
microservices مان اميدون
اجزاء جو مسئلو جڏهن تيار ٿي. اجزاء جي ترسيل جڏهن تيار ٿي حل کي ختم ڪندي ۽ مختلف عملن کي الڳ ڪري.
ننڍي پيداوار ٽيمون. اهو ضروري آهي ڇو ته پراڻي monolith تي ڪم ڪندڙ هڪ وڏي ٽيم جو انتظام ڪرڻ ڏکيو هو. اهڙي ٽيم کي سخت عمل جي مطابق ڪم ڪرڻ تي مجبور ڪيو ويو، پر اهي وڌيڪ تخليقيت ۽ آزادي چاهيندا هئا. صرف ننڍي ٽيمون هن کي برداشت ڪري سگهي ٿي.
الڳ الڳ عملن ۾ خدمتن کي الڳ ڪرڻ. مثالي طور تي، مان ان کي ڪنٽينرز ۾ الڳ ڪرڻ چاهيان ٿو، پر .NET فريم ورڪ ۾ لکيل وڏي تعداد ۾ خدمتون صرف هيٺ هلن ٿيون Windows.NET ڪور تي ٻڌل خدمتون هاڻي ظاهر ٿي رهيون آهن، پر اڃا تائين انهن مان ڪجهه گهٽ آهن.
لڳائڻ جي لچڪ. اسان چاهيون ٿا ته خدمتن کي گڏ ڪرڻ جي طريقي سان اسان کي ضرورت آهي، ۽ نه ته اهو طريقو جيڪو ڪوڊ ان کي مجبور ڪري ٿو.
جديد ٽيڪنالاجي جو استعمال. اهو ڪنهن به پروگرامر لاء دلچسپ آهي.
منتقلي مسئلا
يقينن، جيڪڏهن اهو آسان هو ته هڪ واحد کي مائڪرو سروسز ۾ ٽوڙڻ، ڪانفرنس ۾ ان بابت ڳالهائڻ ۽ آرٽيڪل لکڻ جي ڪا ضرورت ناهي. ھن عمل ۾ ڪيترائي نقص آھن؛ مان انھن کي بيان ڪندس جيڪي اسان کي روڪيو.
پهريون مسئلو اڪثر monoliths لاء عام: ڪاروباري منطق جو هم آهنگ. جڏهن اسان هڪ واحد لکندا آهيون، اسان چاهيون ٿا ته اسان جي ڪلاس کي ٻيهر استعمال ڪيو وڃي ته جيئن غير ضروري ڪوڊ نه لکجي. ۽ جڏهن microservices ڏانهن منتقل ٿئي ٿي، اهو هڪ مسئلو بڻجي ٿو: سڀ ڪوڊ ڪافي مضبوط طور تي ملائي وئي آهي، ۽ خدمتن کي الڳ ڪرڻ ڏکيو آهي.
ڪم جي شروعات جي وقت، مخزن ۾ 500 کان وڌيڪ منصوبا ۽ 700 هزار کان وڌيڪ ڪوڊ لائنون هيون. هي هڪ تمام وڏو فيصلو آهي ۽ ٻيو مسئلو. اهو ممڪن نه هو ته صرف ان کي وٺي ۽ ان کي microservices ۾ ورهايو.
ٽيون مسئلو - ضروري بنيادي ڍانچي جي کوٽ. حقيقت ۾، اسان دستي طور تي سرورز ڏانهن سورس ڪوڊ ڪاپي ڪري رهيا هئاسين.
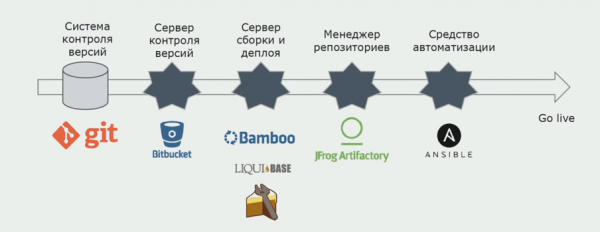
monolith کان microservices ڏانهن ڪيئن منتقل ڪجي
مائڪرو سروسز فراهم ڪرڻ
پهرين، اسان فوري طور تي پاڻ لاء طئي ڪيو ته مائڪرو سروسز جي علحدگي هڪ ٻيهر عمل آهي. اسان کي هميشه متوازي ۾ ڪاروباري مسئلن کي ترقي ڪرڻ جي ضرورت هئي. اسان ان کي ڪيئن لاڳو ڪنداسين ٽيڪنيڪل طور تي اسان جو مسئلو آهي. تنهن ڪري، اسان هڪ ٻيهر عمل لاء تيار ڪيو. اهو ڪنهن ٻئي طريقي سان ڪم نه ڪندو جيڪڏهن توهان وٽ وڏي ايپليڪيشن آهي ۽ اهو شروعاتي طور تي ٻيهر لکڻ لاءِ تيار ناهي.
Microservices کي الڳ ڪرڻ لاءِ اسان ڪھڙا طريقا استعمال ڪريون ٿا؟
پهرين رستو - موجوده ماڊلز کي خدمتن جي طور تي منتقل ڪريو. ان سلسلي ۾، اسان خوش قسمت هئاسين: اڳ ۾ ئي رجسٽرڊ خدمتون موجود آهن جيڪي WCF پروٽوڪول استعمال ڪندي ڪم ڪن ٿيون. انهن کي الڳ الڳ اسيمبلين ۾ ورهايو ويو. اسان انهن کي الڳ الڳ پورٽ ڪيو، هر تعمير ۾ هڪ ننڍڙو لانچر شامل ڪيو. اهو شاندار Topshelf لائبريري استعمال ڪندي لکيو ويو آهي، جيڪا توهان کي ايپليڪيشن کي هلائڻ جي اجازت ڏئي ٿي سروس ۽ ڪنسول جي طور تي. هي ڊيبگنگ لاءِ آسان آهي ڇو ته حل ۾ اضافي منصوبن جي ضرورت ناهي.
خدمتون ڪاروباري منطق جي مطابق ڳنڍيل هئا، ڇاڪاڻ ته اهي عام اسيمبليون استعمال ڪندا هئا ۽ هڪ عام ڊيٽابيس سان ڪم ڪيو. انهن کي پنهنجي خالص روپ ۾ شايد ئي microservices سڏيو وڃي. بهرحال، اسان اهي خدمتون الڳ الڳ، مختلف عملن ۾ مهيا ڪري سگهون ٿا. اهو اڪيلو اهو ممڪن بڻائي ٿو ته هڪ ٻئي تي انهن جي اثر کي گهٽائڻ، متوازي ترقي ۽ ناڪامي جي هڪ واحد نقطي سان مسئلو کي گهٽائڻ.
ميزبان سان اسيمبلي پروگرام ڪلاس ۾ ڪوڊ جي صرف هڪ لائن آهي. اسان هڪ معاون ڪلاس ۾ Topshelf سان ڪم لڪايو.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
microservices مختص ڪرڻ جو ٻيو طريقو آهي: نئين مسئلن کي حل ڪرڻ لاء ان کي ٺاهيو. جيڪڏهن هڪ ئي وقت ۾ monolith نه وڌو، اهو اڳ ۾ ئي شاندار آهي، جنهن جو مطلب آهي ته اسان صحيح طرف منتقل ڪري رهيا آهيون. نئين مسئلن کي حل ڪرڻ لاء، اسان الڳ خدمتون ٺاهڻ جي ڪوشش ڪئي. جيڪڏهن ڪو اهڙو موقعو هو، ته پوءِ اسان وڌيڪ ”ڪيننيڪل“ خدمتون ٺاهيون جيڪي مڪمل طور تي پنهنجي ڊيٽا ماڊل کي منظم ڪن، هڪ الڳ ڊيٽابيس.
اسان، گھڻن وانگر، تصديق ۽ اختيار جي خدمتن سان شروع ڪيو. اهي هن لاء ڀرپور آهن. اهي آزاد آهن، ضابطي جي طور تي، انهن وٽ هڪ الڳ ڊيٽا ماڊل آهي. اهي پاڻ کي monolith سان لهه وچڙ نه ڪندا آھن، رڳو انھن کي ڪجهه مسئلا حل ڪرڻ لاء موڙ. انهن خدمتن کي استعمال ڪندي، توهان هڪ نئين آرڪيٽيڪچر ڏانهن منتقلي شروع ڪري سگهو ٿا، انهن تي انفراسٽرڪچر کي ڊيبگ ڪري سگهو ٿا، نيٽ ورڪ لائبريرين سان لاڳاپيل ڪجهه طريقا آزمائي سگهو ٿا، وغيره. اسان وٽ اسان جي تنظيم ۾ ڪا به ٽيم ناهي جيڪا تصديق جي خدمت ٺاهي نه سگهي.
ٽيون طريقو microservices مختص ڪرڻ لاءجيڪو اسان استعمال ڪندا آهيون اهو اسان لاءِ ٿورڙو مخصوص آهي. هي UI پرت مان ڪاروباري منطق کي ختم ڪرڻ آهي. اسان جي مکيه UI ايپليڪيشن ڊيسڪ ٽاپ آهي، اهو، پس منظر وانگر، C# ۾ لکيل آهي. ڊولپر وقتي طور تي غلطيون ڪيون ۽ منطق جا حصا UI ڏانهن منتقل ڪيا جيڪي پس منظر ۾ موجود هجڻ گهرجن ۽ ٻيهر استعمال ڪيا وڃن.
جيڪڏهن توهان UI حصي جي ڪوڊ مان هڪ حقيقي مثال ڏسو ٿا، توهان ڏسي سگهو ٿا ته هن حل مان اڪثر حقيقي ڪاروباري منطق تي مشتمل آهي جيڪو ٻين عملن ۾ ڪارائتو آهي، نه صرف UI فارم ٺاهڻ لاءِ.
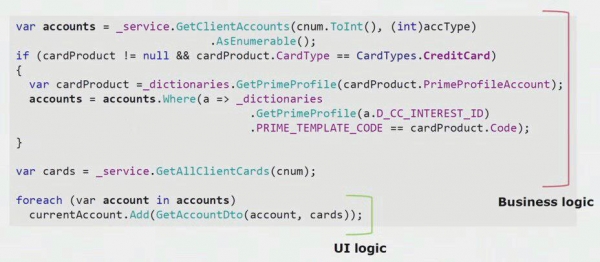
حقيقي UI منطق صرف آخري لائنن ۾ موجود آهي. اسان ان کي سرور ڏانهن منتقل ڪيو ته جيئن ان کي ٻيهر استعمال ڪري سگهجي، ان ڪري UI کي گهٽائي ۽ صحيح فن تعمير حاصل ڪري.
مائڪرو سروسز کي الڳ ڪرڻ جو چوٿون ۽ سڀ کان اهم طريقو، جيڪو اهو ممڪن بڻائي ٿو ته مونولٿ کي گهٽائڻ، پروسيسنگ سان موجوده خدمتن کي ختم ڪرڻ آهي. جڏهن اسان موجوده ماڊلز کي ائين ڪڍون ٿا، نتيجو هميشه ڊولپرز جي پسند جي مطابق ناهي، ۽ ڪاروباري عمل شايد پراڻي ٿي چڪو آهي جڏهن کان ڪارڪردگي ٺاهي وئي هئي. ريفيڪٽرنگ سان، اسان هڪ نئين ڪاروباري عمل جي حمايت ڪري سگهون ٿا ڇو ته ڪاروباري گهرجون مسلسل تبديل ٿي رهيا آهن. اسان سورس ڪوڊ کي بهتر ڪري سگھون ٿا، سڃاتل خرابين کي ختم ڪري سگھون ٿا، ۽ بھتر ڊيٽا ماڊل ٺاھي سگھون ٿا. اتي ڪيترائي فائدا حاصل ڪرڻ وارا آھن.
خدمتن کي پروسيسنگ کان الڳ ڪرڻ غير معمولي طور تي پابند ٿيل مفهوم جي تصور سان ڳنڍيل آهي. هي ڊومين ڊرائيو ڊيزائن مان هڪ تصور آهي. ان جو مطلب آھي ڊومين ماڊل جو ھڪڙو حصو جنھن ۾ ھڪڙي ٻوليءَ جا سڀ اصطلاح منفرد طور بيان ڪيل آھن. اچو ته مثال طور انشورنس ۽ بل جي حوالي سان ڏسو. اسان وٽ هڪ واحد درخواست آهي، ۽ اسان کي انشورنس ۾ اڪائونٽ سان ڪم ڪرڻ جي ضرورت آهي. اسان توقع ڪريون ٿا ته ڊولپر هڪ موجوده اڪائونٽ ڪلاس کي ٻئي اسيمبليءَ ۾ ڳولهي، ان کي انشورنس ڪلاس مان حوالي ڪري، ۽ اسان وٽ ڪم ڪندڙ ڪوڊ هوندو. DRY اصول جو احترام ڪيو ويندو، موجوده ڪوڊ استعمال ڪندي ڪم تيزيء سان ڪيو ويندو.
نتيجي طور، اهو ظاهر ٿئي ٿو ته اڪائونٽس ۽ انشورنس جا حوالا ڳنڍيل آهن. جيئن نئين گهرج اڀري ٿي، هي جوڙيل ترقي سان مداخلت ڪندو، اڳ ۾ ئي پيچيده ڪاروباري منطق جي پيچيدگي کي وڌائيندو. هن مسئلي کي حل ڪرڻ لاء، توهان کي ڪوڊ ۾ حوالن جي وچ ۾ حدون ڳولڻ ۽ انهن جي خلاف ورزي کي هٽائڻ جي ضرورت آهي. مثال طور، انشورنس جي حوالي سان، اهو بلڪل ممڪن آهي ته 20-عددي مرڪزي بئنڪ اڪائونٽ نمبر ۽ اڪائونٽ کولڻ جي تاريخ ڪافي هوندي.
انهن حد بندي ٿيل حوالن کي هڪ ٻئي کان الڳ ڪرڻ ۽ هڪ واحد حل کان مائڪرو سروسز کي الڳ ڪرڻ جي عمل کي شروع ڪرڻ لاءِ، اسان هڪ طريقو استعمال ڪيو جيئن ته ايپليڪيشن اندر خارجي APIs ٺاهڻ. جيڪڏهن اسان ڄاڻون ٿا ته ڪجهه ماڊل هڪ microservice ٿيڻ گهرجي، ڪنهن به طريقي سان پروسيس ۾ تبديل ٿيل، پوء اسان فوري طور تي ڪالون ڪيون آهن منطق کي جيڪو ٻاهرين ڪالن ذريعي ڪنهن ٻئي محدود حوالي سان تعلق رکي ٿو. مثال طور، REST يا WCF ذريعي.
اسان پڪ سان فيصلو ڪيو ته اسان ڪوڊ کان پاسو نه ڪنداسين جيڪو ورهايل ٽرانزيڪشن جي ضرورت هوندي. اسان جي حالت ۾، اهو نڪتو ته هن قاعدي جي پيروي ڪرڻ بلڪل آسان آهي. اسان اڃا تائين اهڙين حالتن جو سامنا نه ڪيو آهي جتي سخت ورهايل ٽرانزيڪشن واقعي گهربل آهن - ماڊلز جي وچ ۾ حتمي استحڪام ڪافي آهي.
اچو ته هڪ خاص مثال ڏسو. اسان وٽ هڪ آرڪيسٽرٽر جو تصور آهي - هڪ پائپ لائن جيڪا "ايپليڪيشن" جي اداري کي پروسيس ڪري ٿي. هو بدلي ۾ هڪ ڪلائنٽ، هڪ اڪائونٽ ۽ هڪ بينڪ ڪارڊ ٺاهي ٿو. جيڪڏهن ڪلائنٽ ۽ اڪائونٽ ڪاميابي سان ٺاهيا ويا آهن، پر ڪارڊ ٺاهي ناڪام ٿي، ايپليڪيشن "ڪامياب" اسٽيٽس ڏانهن منتقل نه ٿيندي ۽ "ڪارڊ نه ٺاهي وئي" جي حيثيت ۾ رهي ٿي. مستقبل ۾، پس منظر جي سرگرمي ان کي کڻندي ۽ ان کي ختم ڪندي. سسٽم ڪجهه وقت کان غير مطابقت جي حالت ۾ آهي، پر اسان عام طور تي ان سان مطمئن آهيون.
جيڪڏهن ڪا صورتحال پيدا ٿئي ٿي جڏهن ڊيٽا جو حصو مسلسل محفوظ ڪرڻ ضروري آهي، اسان گهڻو ڪري خدمت جي استحڪام لاءِ وينداسون ته جيئن ان کي هڪ عمل ۾ پروسيس ڪيو وڃي.
اچو ته هڪ microservice مختص ڪرڻ جو هڪ مثال ڏسو. توهان ان کي پيداوار ۾ نسبتا محفوظ ڪيئن آڻي سگهو ٿا؟ هن مثال ۾، اسان وٽ سسٽم جو هڪ الڳ حصو آهي - هڪ پگهار سروس ماڊل، ڪوڊ سيڪشن مان هڪ جنهن مان اسان مائڪرو سروس ٺاهڻ چاهيون ٿا.
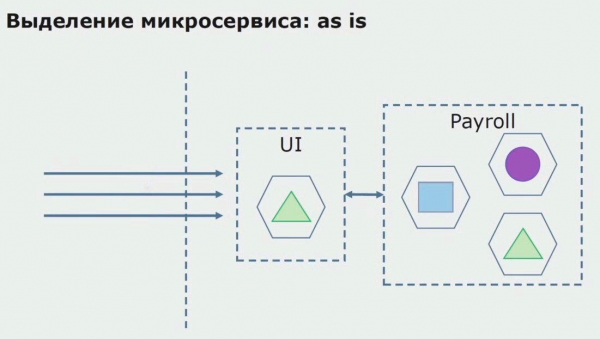
سڀ کان پهريان، اسان ڪوڊ کي ٻيهر لکڻ سان هڪ microservice ٺاهيندا آهيون. اسان ڪجهه پهلو کي بهتر ڪري رهيا آهيون جيڪي اسان سان خوش نه هئاسين. اسان ڪسٽمر کان نئين ڪاروباري گهرجن کي لاڳو ڪندا آهيون. اسان UI ۽ پس منظر جي وچ ۾ ڪنيڪشن لاءِ API گيٽ وي شامل ڪريون ٿا، جيڪو ڪال فارورڊنگ مهيا ڪندو.
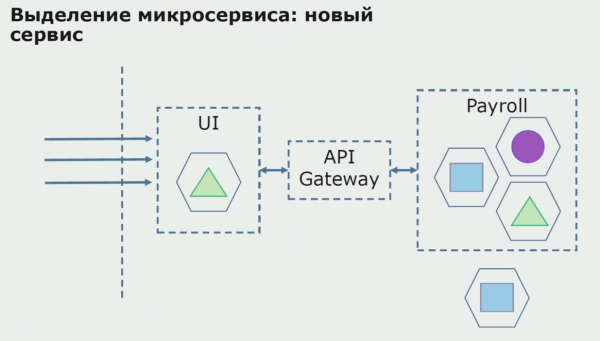
اڳيون، اسان هن تشڪيل کي آپريشن ۾ ڇڏي ڏيو، پر پائلٽ حالت ۾. اسان جا گهڻا صارف اڃا تائين پراڻي ڪاروباري عملن سان ڪم ڪن ٿا. نون استعمال ڪندڙن لاءِ، اسان ڊولپمينٽ ڪري رهيا آهيون هڪ نئين ورزن جو monolithic ائپليڪيشن جنهن ۾ هاڻي اهو عمل شامل ناهي. لازمي طور تي، اسان وٽ هڪ ميلاپ آهي هڪ monolith ۽ هڪ microservice جو هڪ پائلٽ طور ڪم ڪري رهيو آهي.
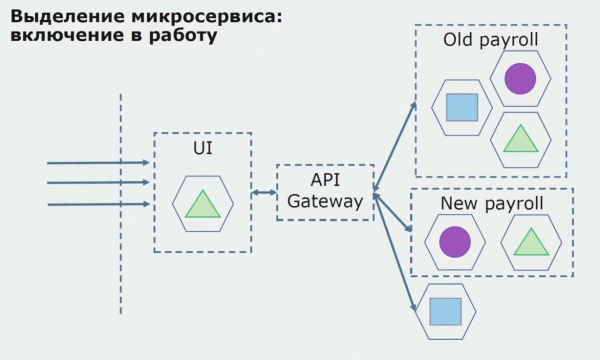
هڪ ڪامياب پائلٽ سان، اسان سمجهون ٿا ته نئين تشڪيل واقعي قابل عمل آهي، اسان مساوات مان پراڻي monolith کي هٽائي سگهون ٿا ۽ پراڻي حل جي جاء تي نئين ترتيب کي ڇڏي ڏيو.
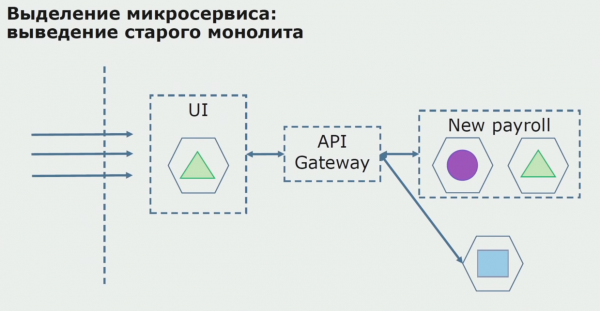
مجموعي طور تي، اسان تقريباً سڀ موجود طريقا استعمال ڪريون ٿا ورهائڻ لاءِ هڪ منبع جو سورس ڪوڊ. اهي سڀئي اسان کي ايپليڪيشن جي حصن جي سائيز کي گهٽائڻ ۽ انهن کي نئين لائبريرين ۾ ترجمو ڪرڻ جي اجازت ڏين ٿا، بهتر سورس ڪوڊ ٺاهڻ.
ڊيٽابيس سان ڪم ڪرڻ
ڊيٽابيس کي ماخذ ڪوڊ کان بدتر ورهائي سگهجي ٿو، ڇاڪاڻ ته اهو نه رڳو موجوده اسڪيما تي مشتمل آهي، پر گڏ ڪيل تاريخي ڊيٽا پڻ.
اسان جي ڊيٽابيس، ٻين ڪيترن ئي وانگر، هڪ ٻي اهم خرابي هئي - ان جي وڏي سائيز. هي ڊيٽابيس هڪ monolith جي پيچيده ڪاروباري منطق جي مطابق ٺاهيو ويو آهي، ۽ مختلف حدن جي مقصدن جي جدولن جي وچ ۾ لاڳاپا گڏ ڪيا ويا آهن.
اسان جي حالت ۾، سڀني مشڪلاتن کي مٿي ڪرڻ لاء (وڏي ڊيٽابيس، ڪيترائي ڪنيڪشن، ڪڏهن ڪڏهن جدولن جي وچ ۾ غير واضح حدون)، هڪ مسئلو پيدا ٿيو جيڪو ڪيترن ئي وڏن منصوبن ۾ ٿئي ٿو: گڏيل ڊيٽابيس ٽيمپليٽ جو استعمال. ڊيٽا جدولن مان ورتو ويو ڏسڻ جي ذريعي، نقل ذريعي، ۽ ٻين سسٽم ڏانهن موڪليو ويو جتي هن نقل جي ضرورت هئي. نتيجي طور، اسان جدولن کي الڳ اسڪيما ۾ منتقل نه ڪري سگھون ٿا ڇو ته اھي فعال طور تي استعمال ڪيا ويا آھن.
ڪوڊ ۾ محدود حوالن ۾ ساڳي تقسيم اسان کي الڳ ڪرڻ ۾ مدد ڪري ٿي. اهو عام طور تي اسان کي هڪ تمام سٺو خيال ڏئي ٿو ته اسان ڊيٽابيس جي سطح تي ڊيٽا کي ڪيئن ٽوڙيو. اسان سمجھون ٿا ته ڪھڙي جدولن جو تعلق ھڪڙي حد جي حوالي سان آھي ۽ ڪھڙو ٻئي سان.
اسان ڊيٽابيس ورهاڱي جا ٻه عالمي طريقا استعمال ڪيا: موجوده جدولن جي ورهاڱي ۽ پروسيسنگ سان ورهاڱي.
موجوده جدولن کي ورهائڻ هڪ سٺو طريقو آهي استعمال ڪرڻ لاءِ جيڪڏهن ڊيٽا جي جوڙجڪ سٺي آهي، ڪاروباري گهرجن کي پورو ڪري ٿي، ۽ هرڪو ان سان خوش آهي. انهي حالت ۾، اسان موجوده جدولن کي الڳ اسڪيما ۾ الڳ ڪري سگھون ٿا.
پروسيسنگ سان گڏ هڪ ڊپارٽمينٽ جي ضرورت آهي جڏهن ڪاروباري ماڊل تمام گهڻو تبديل ٿي چڪو آهي، ۽ ٽيبل هاڻي اسان کي مطمئن نه ڪندا آهن.
موجوده جدولن کي ورهائڻ. اسان کي اهو طئي ڪرڻو پوندو ته اسان ڇا الڳ ڪنداسين. هن علم کان سواء، ڪجھ به ڪم نه ڪندو، ۽ هتي ڪوڊ ۾ پابند ٿيل حوالن جي جدائي اسان جي مدد ڪندي. ضابطي جي طور تي، جيڪڏهن توهان سورس ڪوڊ ۾ حوالن جي حدن کي سمجهي سگهو ٿا، اهو واضح ٿئي ٿو ته ڪهڙيون جدولن کي ڊپارٽمينٽ جي فهرست ۾ شامل ڪيو وڃي.
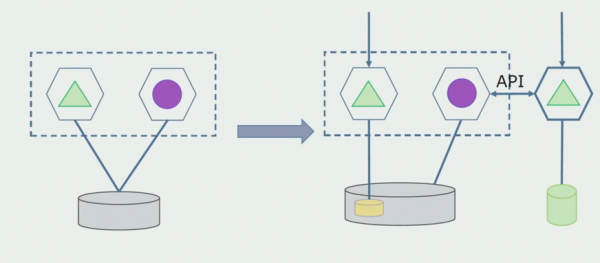
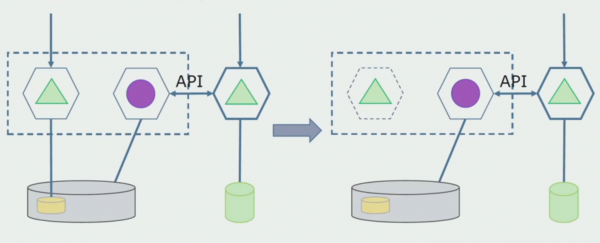
اچو ته تصور ڪريون ته اسان وٽ ھڪڙو حل آھي جنھن ۾ ٻه مونولٿ ماڊل ھڪڙي ڊيٽابيس سان رابطو ڪن ٿا. اسان کي پڪ ڪرڻ جي ضرورت آهي ته صرف هڪ ماڊل الڳ ٿيل جدولن جي حصي سان لهه وچڙ ۾ اچي ٿو، ۽ ٻيو ان سان رابطو ڪرڻ شروع ٿئي ٿو API ذريعي. شروع ڪرڻ سان، اهو ڪافي آهي ته صرف رڪارڊنگ API ذريعي ڪيو ويندو آهي. اهو اسان لاءِ ضروري شرط آهي ته مائڪرو سروسز جي آزادي بابت ڳالهائڻ لاءِ. پڙهائڻ جو لاڳاپو رهي سگهي ٿو جيستائين ڪو وڏو مسئلو ناهي.
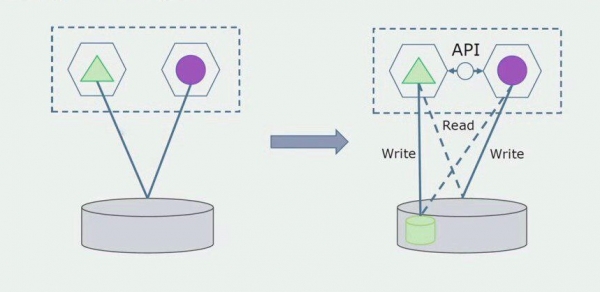
اڳيون قدم اهو آهي ته اسان ڪوڊ جي سيڪشن کي الڳ ڪري سگهون ٿا جيڪو ڪم ڪري ٿو الڳ جدولن سان، پروسيسنگ سان يا بغير، هڪ الڳ مائڪرو سروس ۾ ۽ ان کي هڪ الڳ پروسيس ۾ هلائي، هڪ ڪنٽينر. هي هڪ الڳ خدمت هوندي جنهن سان منولٿ ڊيٽابيس ۽ انهن جدولن جو تعلق سڌو سنئون ان سان نه هوندو. monolith اڃا به جدا ٿيڻ واري حصي سان پڙهڻ لاءِ رابطو ڪري ٿو.
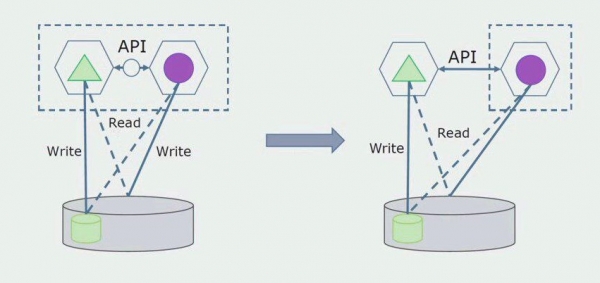
بعد ۾ اسان هن ڪنيڪشن کي هٽائي ڇڏينداسين، يعني، جدا جدا جدولن مان هڪ واحد ايپليڪيشن کان ڊيٽا پڙهڻ پڻ API ڏانهن منتقل ڪيو ويندو.
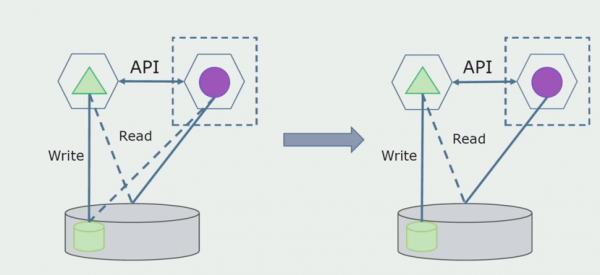
اڳيون، اسان عام ڊيٽابيس مان ٽيبل چونڊينداسين جن سان صرف نئين مائڪرو سروس ڪم ڪري ٿي. اسان جدولن کي الڳ اسڪيما يا ان کان به الڳ جسماني ڊيٽابيس ڏانھن منتقل ڪري سگھون ٿا. microservice ۽ monolith ڊيٽابيس جي وچ ۾ اڃا تائين هڪ پڙهڻ وارو رابطو آهي، پر پريشان ٿيڻ جي ڪا به ڳالهه ناهي، هن ترتيب ۾ اهو ڪافي وقت تائين رهي سگهي ٿو.
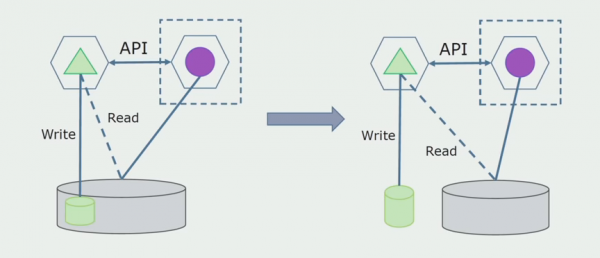
آخري قدم مڪمل طور تي سڀني ڪنيڪشن کي ختم ڪرڻ آهي. انهي حالت ۾، اسان کي شايد مکيه ڊيٽابيس مان ڊيٽا لڏڻ جي ضرورت پوندي. ڪڏهن ڪڏهن اسان چاهيون ٿا ٻيهر استعمال ڪرڻ چاهيون ٿا ڪجهه ڊيٽا يا ڊاريڪٽريون جيڪي خارجي سسٽم مان نقل ٿيل ڪيترن ئي ڊيٽابيس ۾. اهو اسان سان وقتي طور تي ٿئي ٿو.
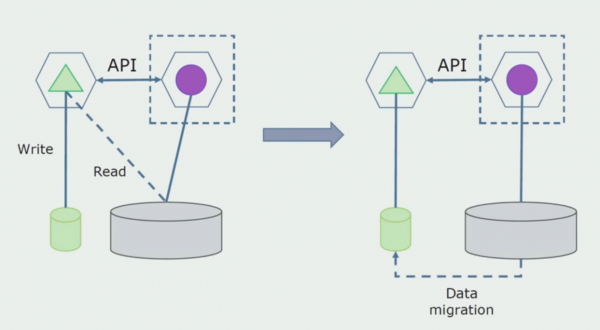
پروسيسنگ ڊپارٽمينٽ. اهو طريقو پهرين هڪ سان بلڪل ملندڙ جلندڙ آهي، صرف ريورس آرڊر ۾. اسان فوري طور تي هڪ نئون ڊيٽابيس ۽ هڪ نئون microservice مختص ڪيو آهي جيڪو هڪ API ذريعي مونولٿ سان رابطو ڪري ٿو. پر ساڳئي وقت، ڊيٽابيس جدولن جو هڪ سيٽ رهي ٿو جيڪو اسان مستقبل ۾ ختم ڪرڻ چاهيون ٿا. اسان کي هاڻي ان جي ضرورت ناهي؛ اسان ان کي نئين ماڊل ۾ تبديل ڪيو.
ھن اسڪيم کي ڪم ڪرڻ لاءِ، اسان کي امڪاني طور تي ھڪڙي منتقلي جي مدت جي ضرورت پوندي.
پوء اتي ٻه ممڪن طريقا آهن.
پهرين: اسان سڀني ڊيٽا کي نئين ۽ پراڻي ڊيٽابيس ۾ نقل ڪريون ٿا. انهي صورت ۾، اسان وٽ ڊيٽا بيڪار آهي ۽ هم وقت سازي جا مسئلا پيدا ٿي سگهن ٿا. پر اسان ٻه مختلف گراهڪ وٺي سگهون ٿا. هڪ نئين نسخي سان ڪم ڪندو، ٻيو پراڻي نسخ سان.
ٻيو: اسان ڊيٽا کي ورهايون ٿا ڪجھ ڪاروباري معيار مطابق. مثال طور، اسان وٽ سسٽم ۾ 5 پراڊڪٽس جيڪي پراڻي ڊيٽابيس ۾ ذخيرو ٿيل هئا. اسان ڇهين کي نئين ڪاروباري ڪم ۾ نئين ڊيٽابيس ۾ رکون ٿا. پر اسان کي هڪ API گيٽ وي جي ضرورت پوندي جيڪا هن ڊيٽا کي هم وقت سازي ڪندو ۽ ڪلائنٽ کي ڏيکاريندو ته ڪٿي ۽ ڇا حاصل ڪجي.
ٻئي طريقا ڪم ڪن ٿا، چونڊيو صورتحال تي منحصر ڪري ٿو.
ان کان پوءِ اسان کي پڪ ٿي ته سڀ ڪجھ ڪم ڪري ٿو، مونولٿ جو حصو جيڪو ڪم ڪري ٿو پراڻن ڊيٽابيس جي جوڙجڪ کي غير فعال ڪري سگھجي ٿو.
آخري قدم پراڻي ڊيٽا جي جوڙجڪ کي ختم ڪرڻ آهي.
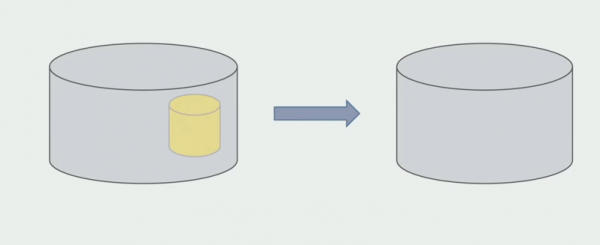
اختصار ڪرڻ لاء، اسان اهو چئي سگهون ٿا ته اسان وٽ ڊيٽابيس سان مسئلا آهن: ان سان ڪم ڪرڻ ڏکيو آهي ذريعو ڪوڊ جي مقابلي ۾، ان کي حصيداري ڪرڻ وڌيڪ ڏکيو آهي، پر اهو ٿي سگهي ٿو ۽ ٿيڻ گهرجي. اسان کي ڪجھ طريقا مليا آھن جيڪي اسان کي اھو ڪرڻ جي اجازت ڏين ٿا بلڪل محفوظ طور تي، پر اھو اڃا تائين آسان آھي ڊيٽا سان غلطيون ڪرڻ جي ڀيٽ ۾ سورس ڪوڊ سان.
سورس ڪوڊ سان ڪم ڪرڻ
اھو اھو آھي جيڪو سورس ڪوڊ ڊاگرام وانگر نظر آيو جڏھن اسان ھڪڙي ھڪڙي منصوبي جو تجزيو ڪرڻ شروع ڪيو.
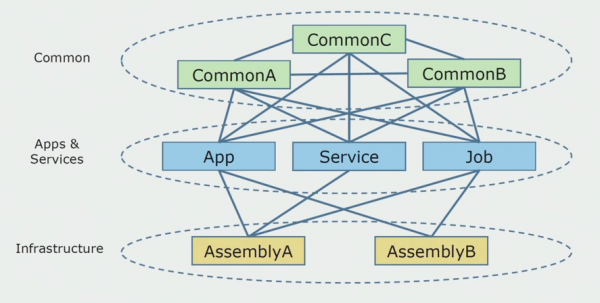
ان کي تقريبن ٽن حصن ۾ ورهائي سگهجي ٿو. هي لانچ ٿيل ماڊلز، پلگ ان، خدمتن ۽ انفرادي سرگرمين جو هڪ پرت آهي. حقيقت ۾، اهي هڪ واحد حل جي اندر داخل ٿيڻ جا نقطا هئا. انهن سڀني کي مضبوط طور تي هڪ عام پرت سان بند ڪيو ويو. اهو ڪاروباري منطق هو ته خدمتون حصيداري ڪيون ويون ۽ تمام گهڻا ڪنيڪشن. هر خدمت ۽ پلگ ان استعمال ٿيل 10 يا وڌيڪ عام اسيمبلين تائين، انهن جي سائيز ۽ ڊولپرز جي ضمير تي منحصر آهي.
اسان خوش قسمت هئاسين ته انفراسٽرڪچر لائبريريون آهن جيڪي الڳ الڳ استعمال ڪري سگهجن ٿيون.
ڪڏهن ڪڏهن اهڙي صورتحال پيدا ٿيندي آهي جڏهن ڪجهه عام شيون اصل ۾ هن پرت سان تعلق نه رکندا هئا، پر انفراسٽرڪچر لائبريريون هيون. اهو نالو تبديل ڪرڻ سان حل ڪيو ويو.
سڀ کان وڏي تشويش حد بندي جي حوالي سان هئي. اهو ٿيو ته 3-4 حوالن کي هڪ گڏيل اسيمبليءَ ۾ ملايو ويو ۽ هڪ ٻئي کي هڪ ئي ڪاروباري ڪمن ۾ استعمال ڪيو ويو. اهو سمجهڻ ضروري هو ته اهو ڪٿي ورهائي سگهجي ٿو ۽ ڪهڙي حدن سان، ۽ هن ڊويزن کي ماخذ ڪوڊ اسيمبلين ۾ ميپ ڪرڻ سان اڳتي ڇا ڪجي.
اسان ڪوڊ ورهائڻ واري عمل لاءِ ڪيترائي ضابطا ٺاهيا آهن.
پهرين: اسان هاڻي نه چاهيون ٿا ته ڪاروباري منطق خدمتن، سرگرمين ۽ پلگ ان جي وچ ۾ حصيداري ڪريو. اسان چاهيون ٿا ته ڪاروباري منطق کي مائڪرو سروسز جي اندر آزاد. Microservices، ٻئي طرف، مثالي طور تي سوچيا ويندا آهن جيئن خدمتون جيڪي مڪمل طور تي آزاد طور تي موجود آهن. مان سمجهان ٿو ته اهو طريقو ڪجهه فضول آهي، ۽ اهو حاصل ڪرڻ ڏکيو آهي، ڇاڪاڻ ته، مثال طور، C# ۾ خدمتون ڪنهن به صورت ۾ معياري لائبريري سان ڳنڍيل هوندا. اسان جو سسٽم C# ۾ لکيل آهي؛ اسان اڃا تائين ٻيون ٽيڪنالاجيون استعمال نه ڪيون آهن. تنهن ڪري، اسان فيصلو ڪيو ته اسان عام ٽيڪنيڪل اسيمبليون استعمال ڪرڻ جي متحمل ٿي سگهون ٿا. بنيادي شيء اها آهي ته اهي ڪاروباري منطق جي ڪنهن به ٽڪر تي مشتمل نه آهن. جيڪڏهن توهان وٽ او آر ايم تي هڪ سهولت ريپر آهي جنهن کي توهان استعمال ڪري رهيا آهيو، ته پوءِ ان کي نقل ڪرڻ هڪ خدمت کان خدمت تائين تمام مهانگو آهي.
اسان جي ٽيم ڊومين تي هلندڙ ڊيزائن جي مداح آهي، تنهنڪري پياز فن تعمير اسان لاءِ هڪ بهترين موزون هو. اسان جي خدمتن جو بنياد ڊيٽا جي رسائي واري پرت نه آهي، پر ڊومين منطق سان گڏ هڪ اسيمبلي، جنهن ۾ صرف ڪاروباري منطق شامل آهي ۽ انفراسٽرڪچر سان ڪو به تعلق ناهي. ساڳئي وقت، اسان فريم ورڪ سان لاڳاپيل مسئلن کي حل ڪرڻ لاء ڊومين اسيمبليء کي آزاديء سان تبديل ڪري سگهون ٿا.
هن مرحلي تي اسان کي اسان جي پهرين سنگين مسئلي جو سامنا ڪيو. خدمت کي ھڪڙي ڊومين اسيمبلي جو حوالو ڏيڻو پيو، اسان منطق کي آزاد بڻائڻ چاھيو ٿا، ۽ DRY اصول اسان کي ھتي تمام گھڻو متاثر ڪيو. ڊولپرز پاڙيسري اسيمبلين مان ڪلاس ٻيهر استعمال ڪرڻ چاهيندا هئا ته نقل کان بچڻ لاءِ، ۽ نتيجي طور، ڊومينز ٻيهر هڪٻئي سان ڳنڍڻ شروع ڪيا ويا. اسان نتيجن جو تجزيو ڪيو ۽ فيصلو ڪيو ته شايد مسئلو پڻ سورس ڪوڊ اسٽوريج ڊوائيس جي علائقي ۾ آهي. اسان وٽ ھڪڙو وڏو ذخيرو ھو جنھن ۾ سڀ سورس ڪوڊ ھو. سڄي منصوبي جو حل مقامي مشين تي گڏ ڪرڻ تمام ڏکيو هو. تنهن ڪري، پروجيڪٽ جي حصن لاء الڳ ننڍا حل ٺاهيا ويا، ۽ ڪنهن به انهن کي ڪجهه عام يا ڊومين اسيمبلي شامل ڪرڻ ۽ انهن کي ٻيهر استعمال ڪرڻ کان منع ڪئي. واحد اوزار جيڪو اسان کي ڪرڻ جي اجازت نه ڏني هئي ڪوڊ جو جائزو. پر ڪڏهن ڪڏهن اهو پڻ ناڪام ٿيو.
ان کان پوء اسان هڪ ماڊل ڏانهن منتقل ڪرڻ شروع ڪيو جدا جدا ذخيرو سان. ڪاروباري منطق هاڻي خدمت کان خدمت تائين نه وهندو آهي، ڊومينز واقعي آزاد ٿي چڪا آهن. پابند ٿيل حوالن کي وڌيڪ واضح طور تي سپورٽ ڪيو ويو آهي. اسان انفراسٽرڪچر لائبريرين کي ڪيئن ٻيهر استعمال ڪريون ٿا؟ اسان انھن کي ھڪ الڳ مخزن ۾ الڳ ڪيو، پوءِ انھن کي Nuget پيڪيجز ۾ وجھو، جنھن کي اسان آرٽيفيڪٽري ۾ وجھي ڇڏيو. ڪنهن به تبديلي سان، اسيمبلي ۽ اشاعت خودڪار طريقي سان ٿيندي آهي.
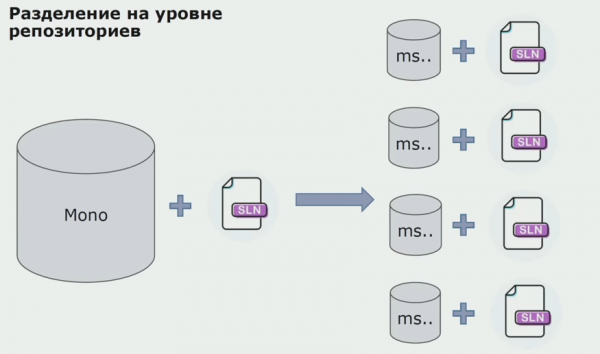
اسان جون خدمتون اندروني انفراسٽرڪچر پيڪيجز جي حوالي ڪرڻ شروع ڪيون ويون آهن ساڳئي طريقي سان ٻاهرئين طور تي. اسان نگيٽ مان خارجي لائبريريون ڊائون لوڊ ڪريون ٿا. آرٽيفيڪٽري سان ڪم ڪرڻ لاء، جتي اسان اهي پيڪيجز رکيا، اسان ٻه پيڪيج مينيجر استعمال ڪيا. ننڍڙن ذخيرن ۾ اسان پڻ استعمال ڪيو Nuget. ڪيترن ئي خدمتن سان گڏ ذخيرو ۾، اسان Paket استعمال ڪيو، جيڪو ماڊلز جي وچ ۾ وڌيڪ نسخو استحڪام مهيا ڪري ٿو.
اهڙيءَ طرح، سورس ڪوڊ تي ڪم ڪرڻ سان، فن تعمير کي ٿورو تبديل ڪري ۽ مخزن کي الڳ ڪري، اسان پنهنجي خدمتن کي وڌيڪ خودمختيار بڻايون ٿا.
انفراسٽرڪچر مسئلا
مائيڪرو سروسز ڏانهن منتقل ٿيڻ جا گهڻا نقصان انفراسٽرڪچر سان لاڳاپيل آهن. توهان کي خودڪار ترتيب جي ضرورت پوندي، توهان کي انفراسٽرڪچر کي هلائڻ لاءِ نئين لائبريرين جي ضرورت پوندي.
ماحول ۾ دستي تنصيب
شروعات ۾، اسان دستي طور تي ماحول لاء حل نصب ڪيو. هن عمل کي خودڪار ڪرڻ لاء، اسان هڪ CI/CD پائپ لائن ٺاهي. اسان مسلسل ترسيل جي عمل کي چونڊيو آهي ڇو ته ڪاروباري عملن جي نقطي نظر کان اسان لاءِ لاڳيتو تعیناتي اڃا تائين قابل قبول ناهي. تنهن ڪري، آپريشن لاء موڪلڻ هڪ بٽڻ استعمال ڪيو ويندو آهي، ۽ جاچ لاء - خودڪار.
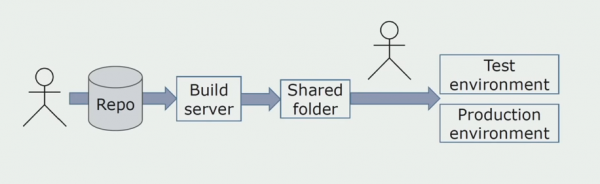
اسان استعمال ڪريون ٿا Atlassian، Bitbucket ماخذ ڪوڊ اسٽوريج لاءِ ۽ بانس تعمير ڪرڻ لاءِ. اسان ڪيڪ ۾ بلڊ اسڪرپٽ لکڻ چاهيون ٿا ڇاڪاڻ ته اهو ساڳيو آهي C#. تيار ٿيل پيڪيجز آرٽيفيڪٽري ۾ ايندا آهن، ۽ جوابي خودڪار طور تي ٽيسٽ سرورز تائين پهچي ويندا آهن، جنهن کان پوء انهن کي فوري طور تي جانچ ڪري سگهجي ٿو.
الڳ لاگنگ
هڪ دفعي، مونولٿ جي خيالن مان هڪ گڏيل لاگنگ مهيا ڪرڻ هو. اسان کي اهو سمجهڻ جي ضرورت آهي ته انفرادي لاگن سان ڇا ڪجي جيڪي ڊسڪ تي آهن. اسان جا لاگ ٽيڪسٽ فائلن تي لکيل آهن. اسان هڪ معياري ELK اسٽيڪ استعمال ڪرڻ جو فيصلو ڪيو. اسان سڌو سنئون مهيا ڪندڙن جي ذريعي ELK ڏانهن نه لکيو، پر فيصلو ڪيو ته اسان ٽيڪسٽ لاگز کي حتمي شڪل ڏينداسين ۽ انهن ۾ هڪ سڃاڻپ ڪندڙ جي طور تي ٽريڪ ID لکنداسين، سروس جو نالو شامل ڪيو، ته جيئن اهي لاگ ان بعد ۾ پارس ٿي سگهن.
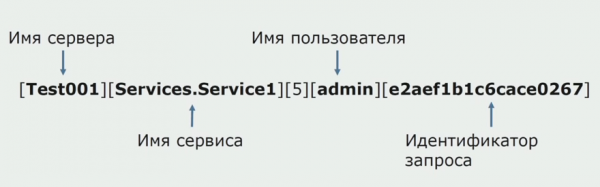
فائل بيٽ سان اسان پنهنجا لاگ گڏ ڪرڻ جي قابل آهيون جتان سرور، پوءِ انهن کي تبديل ڪريو، UI ۾ سوال ٺاهڻ لاءِ ڪِبانا استعمال ڪريو، ۽ ڏسو ته ڪال کي خدمتن جي وچ ۾ ڪيئن روٽ ڪيو ويو. ٽريس آئي ڊيز ان لاءِ تمام مددگار آهن.
جاچ ۽ ڊيبگنگ لاڳاپيل خدمتون
شروعات ۾، اسان مڪمل طور تي نه سمجھندا هئاسين ته ترقي يافته خدمتن کي ڪيئن ڊيب ڪيو وڃي. مونولٿ سان سڀ ڪجهه سادو هو؛ اسان ان کي مقامي مشين تي هلائي ڇڏيو. پهرين ته انهن مائڪرو سروسز سان ساڳيو ڪم ڪرڻ جي ڪوشش ڪئي، پر ڪڏهن ڪڏهن مڪمل طور تي هڪ مائڪرو سروس شروع ڪرڻ لاءِ توهان کي ٻين کي لانچ ڪرڻ جي ضرورت آهي، ۽ اهو مشڪل آهي. اسان محسوس ڪيو ته اسان کي هڪ ماڊل ڏانهن وڃڻ جي ضرورت آهي جتي اسان صرف مقامي مشين تي ڇڏي ڏيون ٿا خدمت يا خدمتون جيڪي اسان ڊيبگ ڪرڻ چاهيون ٿا. باقي خدمتون سرورز مان استعمال ڪيون وينديون آهن جيڪي ترتيب سان ملن ٿيون پروڊ سان. ڊيبگنگ کان پوء، جاچ دوران، هر ڪم لاء، صرف تبديل ٿيل خدمتون ٽيسٽ سرور ڏانهن جاري ڪيا ويا آهن. اهڙيء طرح، حل فارم ۾ آزمائشي آهي جنهن ۾ اهو مستقبل ۾ پيداوار ۾ ظاهر ٿيندو.
اهڙا سرور آهن جيڪي صرف خدمتن جي پيداوار ورزن کي هلائيندا آهن. انهن سرورن جي ضرورت آهي واقعن جي صورت ۾، ترسيل کان اڳ ۽ اندروني تربيت لاءِ چيڪ ڪرڻ لاءِ.
اسان مشهور اسپيڪ فلو لائبريري استعمال ڪندي هڪ خودڪار ٽيسٽنگ عمل شامل ڪيو آهي. ٽيسٽ پاڻمرادو هلن ٿيون NUnit استعمال ڪندي فوري طور تي جواب ڏيڻ کان پوءِ. جيڪڏهن ڪم ڪوريج مڪمل طور تي خودڪار آهي، پوء دستيابي جاچ جي ڪا ضرورت ناهي. جيتوڻيڪ ڪڏهن ڪڏهن اضافي دستي جاچ اڃا به گهربل آهي. اسان جيرا ۾ ٽيگ استعمال ڪندا آهيون اهو طئي ڪرڻ لاءِ ته ڪهڙن ٽيسٽن کي ڪنهن مخصوص مسئلي لاءِ هلائڻو آهي.
اضافي طور تي، لوڊ ٽيسٽ جي ضرورت وڌي وئي آهي؛ اڳي اهو صرف نادر ڪيسن ۾ ڪيو ويندو هو. اسان ٽيسٽ هلائڻ لاءِ JMeter استعمال ڪريون ٿا، ان کي ذخيرو ڪرڻ لاءِ InfluxDB، ۽ Grafana پروسيس گراف ٺاهڻ لاءِ.
اسان ڇا حاصل ڪيو آهي؟
پهرين، اسان کي "ڇڏي" جي تصور کان نجات حاصل ڪئي. گذري ويا ٻه مهينا خوفناڪ رليز جڏهن هي ڪولوسس هڪ پيداوار واري ماحول ۾ مقرر ڪيو ويو، عارضي طور تي ڪاروباري عملن کي روڪيو. ھاڻي اسين خدمتون ترتيب ڏيون ٿا سراسري طور تي ھر 1,5 ڏينھن ۾، انھن کي گروپ ڪريون ڇو ته اھي منظوري کان پوءِ عمل ۾ اچن ٿيون.
اسان جي نظام ۾ ڪا به موتمار ناڪامي ناهي. جيڪڏهن اسان هڪ بگ سان مائڪرو سروس جاري ڪريون ٿا، ته پوءِ ان سان جڙيل ڪارڪردگي ٽوڙي ويندي، ۽ ٻيا سڀ ڪارڪردگي متاثر نه ٿيندا. اهو استعمال ڪندڙ تجربو کي تمام گهڻو بهتر بڻائي ٿو.
اسان ترتيب ڏيڻ واري نموني کي ڪنٽرول ڪري سگهون ٿا. توھان منتخب ڪري سگھوٿا خدمتن جا گروپ الڳ الڳ حل جي باقي کان، جيڪڏھن ضروري ھجي.
ان کان علاوه، اسان سڌارن جي وڏي قطار سان مسئلو گھٽائي ڇڏيو آھي. اسان وٽ ھاڻي الڳ پراڊڪٽ ٽيمون آھن جيڪي ڪجھ خدمتن سان آزاديءَ سان ڪم ڪن ٿيون. Scrum عمل هتي اڳ ۾ ئي هڪ سٺو فٽ آهي. ھڪڙي مخصوص ٽيم وٽ ھڪڙو الڳ پراڊڪٽ مالڪ آھي جيڪو ان کي ڪم تفويض ڪري ٿو.
خلاصو
- مائيڪرو سروسز پيچيده سسٽم کي ختم ڪرڻ لاءِ مناسب آهن. ان عمل ۾، اسان اهو سمجهڻ شروع ڪريون ٿا ته اسان جي سسٽم ۾ ڇا آهي، ڪهڙا محدود حوالا آهن، انهن جون حدون ڪٿي آهن. هي توهان کي ماڊلز جي وچ ۾ سڌارن کي صحيح طور تي ورهائڻ ۽ ڪوڊ جي مونجهاري کي روڪڻ جي اجازت ڏئي ٿو.
- Microservices مهيا ڪن ٿا تنظيمي فائدا. اهي اڪثر ڪري صرف فن تعمير جي باري ۾ ڳالهائي رهيا آهن، پر ڪنهن به فن تعمير کي ڪاروباري ضرورتن کي حل ڪرڻ جي ضرورت آهي، ۽ پنهنجي پاڻ تي نه. تنهن ڪري، اسان اهو چئي سگهون ٿا ته ننڍن ٽيمن ۾ مسئلن کي حل ڪرڻ لاء مائڪرو سروسز مناسب آهن، انهي ڪري ته Scrum هاڻي تمام گهڻو مشهور آهي.
- علحدگيءَ جو هڪ ورجايل عمل آهي. توهان ايپليڪيشن نه وٺي سگهو ٿا ۽ صرف ان کي مائڪرو سروسز ۾ ورهائي سگهو ٿا. نتيجو ڪندڙ پيداوار ممڪن ناهي ته ڪم ڪار. جڏهن microservices کي وقف ڪري، موجوده ورثي کي ٻيهر لکڻ لاءِ فائديمند آهي، يعني، ان کي ڪوڊ ۾ بدلايو جيڪو اسان پسند ڪيو ۽ بهتر ڪارڪردگي ۽ رفتار جي لحاظ کان ڪاروباري ضرورتن کي پورو ڪري.
هڪ ننڍڙو احتياط: مائڪرو سروسز ڏانهن منتقل ٿيڻ جا خرچ ڪافي اهم آهن. اهو صرف بنيادي ڍانچي جي مسئلي کي حل ڪرڻ لاء هڪ ڊگهو وقت ورتو. تنهن ڪري جيڪڏهن توهان وٽ هڪ ننڍڙي ايپليڪيشن آهي جنهن کي مخصوص اسڪيلنگ جي ضرورت نه آهي، جيستائين توهان وٽ گراهڪ جو وڏو تعداد توهان جي ٽيم جي توجه ۽ وقت لاءِ مقابلو ڪري رهيو آهي، ته پوءِ مائڪرو سروسز شايد نه هجن جيڪي توهان کي اڄ جي ضرورت آهي. اهو ڪافي مهانگو آهي. جيڪڏهن توهان مائڪرو سروسز سان عمل شروع ڪريو ٿا، ته پوءِ قيمتون شروعاتي طور تي ان کان وڌيڪ هونديون جيڪڏهن توهان هڪ ئي پروجيڪٽ کي هڪ مونولٿ جي ترقي سان شروع ڪيو.
P.S. هڪ وڌيڪ جذباتي ڪهاڻي (۽ ڄڻ ته توهان لاء ذاتي طور تي) - مطابق .
هتي رپورٽ جو مڪمل نسخو آهي.
جو ذريعو: www.habr.com
