

2019 පෙබරවාරි-මාර්තු මාසවලදී, සමාජ ජාල සංග්රහය ශ්රේණිගත කිරීම සඳහා තරඟයක් පවත්වන ලදී , අපේ කණ්ඩායම පළමු ස්ථානය ලබා ගත්හ. ලිපියෙන් මම තරඟය සංවිධානය කිරීම, අපි උත්සාහ කළ ක්රම සහ විශාල දත්ත පිළිබඳ පුහුණුව සඳහා කැට්බූස්ට් සැකසුම් ගැන කතා කරමි.

SNA Hackathon
මේ නමින් හැකතන් තරගයක් පැවැත්වෙන තුන්වැනි අවස්ථාව මෙයයි. එය පිළිවෙලින් සමාජ ජාලය ok.ru විසින් සංවිධානය කරනු ලැබේ, කාර්යය සහ දත්ත මෙම සමාජ ජාලයට සෘජුවම සම්බන්ධ වේ.
මෙම අවස්ථාවෙහිදී SNA (සමාජ ජාල විශ්ලේෂණය) වඩාත් නිවැරදිව වටහාගෙන ඇත්තේ සමාජ ප්රස්ථාරයක විශ්ලේෂණයක් ලෙස නොව, සමාජ ජාලයක විශ්ලේෂණයක් ලෙස ය.
- 2014 දී, කාර්යය වූයේ පෝස්ට් එකකට ලැබෙන ලයික් ගණන පුරෝකථනය කිරීමයි.
- 2016 දී - VVZ කාර්යය (සමහරවිට ඔබ හුරුපුරුදු විය හැකිය), සමාජ ප්රස්ථාරයේ විශ්ලේෂණයට සමීප වේ.
- 2019 දී, පරිශීලකයා පළ කිරීමට කැමති වීමේ සම්භාවිතාව මත පදනම්ව පරිශීලකයාගේ සංග්රහය ශ්රේණිගත කිරීම.
මට 2014 ගැන කියන්න බැහැ, නමුත් 2016 සහ 2019 දී, දත්ත විශ්ලේෂණ හැකියාවන්ට අමතරව, විශාල දත්ත සමඟ වැඩ කිරීමේ කුසලතා ද අවශ්ය විය. මම හිතන්නේ යන්ත්ර ඉගෙනීමේ සහ විශාල දත්ත සැකසීමේ ගැටළු වල එකතුව මෙම තරඟ සඳහා මා ආකර්ෂණය වූ අතර, මෙම ක්ෂේත්රවල මගේ අත්දැකීම් මට ජයග්රහණය කිරීමට උපකාරී විය.
mlbootcamp
2019 දී තරඟය වේදිකාවේ සංවිධානය කරන ලදී .
තරඟය පෙබරවාරි 7 වන දින අන්තර්ජාලය හරහා ආරම්භ වූ අතර එය කාර්යයන් 3 කින් සමන්විත විය. ඕනෑම කෙනෙකුට වෙබ් අඩවියේ ලියාපදිංචි විය හැකිය, බාගත කරන්න සහ පැය කිහිපයක් සඳහා ඔබේ මෝටර් රථය පටවන්න. මාර්තු 15 වනදා ඔන්ලයින් වේදිකාව අවසානයේ, සෑම ප්රදර්ශන පැනීමේ ඉසව්වකම ඉහළම 15 දෙනාට නොබැඳි වේදිකාව සඳහා Mail.ru කාර්යාලයට ආරාධනා කරන ලද අතර එය මාර්තු 30 සිට අප්රේල් 1 දක්වා සිදු විය.
අරමුණු
මූලාශ්ර දත්ත මඟින් පරිශීලක හැඳුනුම්පත් (පරිශීලක හැඳුනුම්පත්) සහ තැපැල් හැඳුනුම්පත් (වස්තු හැඳුනුම්පත්) සපයයි. පරිශීලකයාට පළ කිරීමක් පෙන්වූයේ නම්, දත්තවල userId, objectId, මෙම පළ කිරීමට පරිශීලක ප්රතිචාර (ප්රතිපෝෂණ) සහ විවිධ විශේෂාංග හෝ පින්තූර සහ පෙළ වෙත සබැඳි අඩංගු පේළියක් අඩංගු වේ.
| පරිශීලක ID | objectId | හිමිකරු Id | ප්රතිචාර | රූප |
|---|---|---|---|---|
| 3555 | 22 | 5677 | [කැමති, ක්ලික්] | [hash1] |
| 12842 | 55 | 32144 | [කැමති නැති] | [hash2,hash3] |
| 13145 | 35 | 5677 | [ක්ලික් කර, බෙදාගත්] | [hash2] |
පරීක්ෂණ දත්ත කට්ටලයේ සමාන ව්යුහයක් අඩංගු වේ, නමුත් ප්රතිපෝෂණ ක්ෂේත්රය අස්ථානගත වී ඇත. කාර්යය වන්නේ ප්රතිපෝෂණ ක්ෂේත්රයේ 'කැමති' ප්රතික්රියාව පවතින බව පුරෝකථනය කිරීමයි.
ඉදිරිපත් කිරීමේ ගොනුවට පහත ව්යුහය ඇත:
| පරිශීලක ID | වර්ග කළ ලැයිස්තුව[objectId] |
|---|---|
| 123 | 78,13,54,22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
මෙට්රික් යනු පරිශීලකයින් සඳහා සාමාන්ය ROC AUC වේ.
දත්ත පිළිබඳ වඩාත් සවිස්තරාත්මක විස්තරයක් සොයාගත හැකිය. ඔබට පරීක්ෂණ සහ පින්තූර ඇතුළුව එහි දත්ත බාගත කළ හැකිය.
මාර්ගගත වේදිකාව
සබැඳි වේදිකාවේදී, කාර්යය කොටස් 3 කට බෙදා ඇත
- - පින්තූර සහ පෙළ හැර අනෙකුත් සියලුම විශේෂාංග ඇතුළත් වේ;
- - පින්තූර පිළිබඳ තොරතුරු පමණක් ඇතුළත් වේ;
- - පෙළ ගැන පමණක් තොරතුරු ඇතුළත් වේ.
නොබැඳි අදියර
නොබැඳි අවධියේදී, දත්තවල සියලුම විශේෂාංග ඇතුළත් වූ අතර, පෙළ සහ පින්තූර විරල විය. දත්ත කට්ටලයේ පේළි 1,5 ගුණයකින් වැඩි වූ අතර, ඒවායින් දැනටමත් විශාල ප්රමාණයක් තිබුණි.
ගැටලුවේ විසඳුම
මම රැකියාවේදී CV කරන නිසා, මම මේ තරඟයේ මගේ ගමන ආරම්භ කළේ "රූප" කාර්යයෙන්. සපයන ලද දත්ත වනුයේ userId, objectId, ownerId (පළ කිරීම ප්රකාශනය කරන ලද කණ්ඩායම), පළ කිරීම නිර්මාණය කිරීම සහ ප්රදර්ශනය කිරීම සඳහා වේලා මුද්රා, සහ, ඇත්ත වශයෙන්ම, මෙම පළ කිරීම සඳහා වන රූපයයි.
වේලා මුද්රා මත පදනම් වූ විශේෂාංග කිහිපයක් ජනනය කිරීමෙන් පසු, මීළඟ අදහස වූයේ ඉමේජ්නෙට් මත පූර්ව-පුහුණු කළ නියුරෝනයේ අවසාන ස්තරය ගෙන මෙම කාවැද්දීම් වැඩි කිරීමට යැවීමයි.
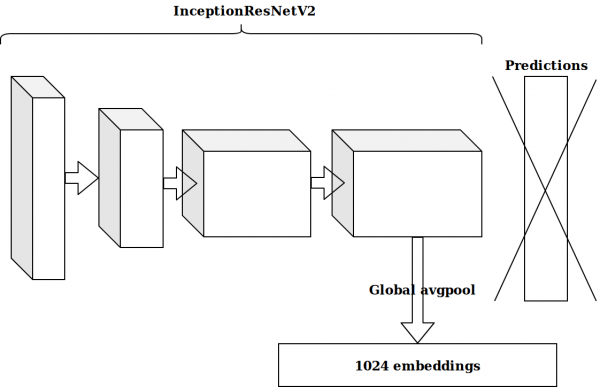
ප්රතිඵල සිත් ඇදගන්නා සුළු නොවීය. ඉමේජ්නෙට් නියුරෝනයෙන් කාවැද්දීම අදාළ නැත, මම සිතුවෙමි, මට මගේම ස්වයංක්රීය කේතකය සෑදිය යුතුය.
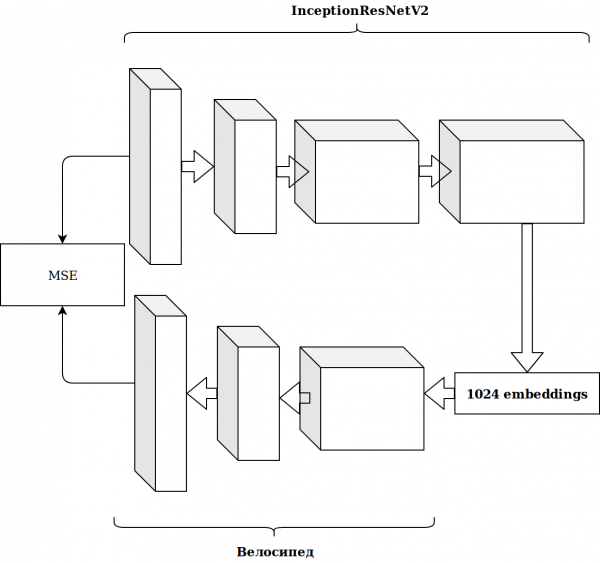
එය බොහෝ කාලයක් ගත වූ අතර ප්රතිඵලය වැඩි දියුණු නොවීය.
විශේෂාංග උත්පාදනය
පින්තූර සමඟ වැඩ කිරීමට බොහෝ කාලයක් ගත වන අතර, ඒ නිසා මම සරල දෙයක් කිරීමට තීරණය කළා.
ඔබට වහාම දැකිය හැකි පරිදි, දත්ත කට්ටලයේ වර්ගීකරණ විශේෂාංග කිහිපයක් ඇති අතර, ඕනෑවට වඩා කරදර නොකිරීමට, මම කැට්බූස්ට් ගත්තා. විසඳුම විශිෂ්ටයි, කිසිදු සැකසුම් නොමැතිව මම වහාම ප්රමුඛ පුවරුවේ පළමු පේළියට පැමිණියෙමි.
සෑහෙන දත්ත ප්රමාණයක් ඇති අතර එය පාකට් ආකෘතියෙන් දක්වා ඇත, එබැවින් දෙවරක් නොසිතා මම ස්කාලා ගෙන සියල්ල ගිනි පුපුරෙන් ලිවීමට පටන් ගතිමි.
රූප කාවැද්දීම්වලට වඩා වැඩි වර්ධනයක් ලබා දුන් සරලම විශේෂාංග:
- objectId, userId සහ ownerId දත්තවල කොපමණ වාර ගණනක් දර්ශනය වී තිබේද (ජනප්රියත්වය සමඟ සහසම්බන්ධ විය යුතුය);
- userId විසින් ownerId වෙතින් පළ කිරීම් කීයක් දැක තිබේද (සමූහය තුළ පරිශීලකයාගේ උනන්දුව සමඟ සහසම්බන්ධ විය යුතුය);
- හිමිකරු අයිඩී වෙතින් අනන්ය පරිශීලක අයිඩී කොපමණ පළ කිරීම් නරඹා ඇත්ද (සමූහයේ ප්රේක්ෂක ප්රමාණය පිළිබිඹු කරයි).
වේලා මුද්දර වලින් පරිශීලකයා සංග්රහය නැරඹූ දවසේ වේලාව (උදෑසන/පස්වරු/සවස/රාත්රිය) ලබා ගැනීමට හැකි විය. මෙම ප්රවර්ග ඒකාබද්ධ කිරීමෙන්, ඔබට විශේෂාංග උත්පාදනය දිගටම කරගෙන යා හැක:
- සවස් වරුවේ userId කී වතාවක් ලොග් වී ඇත්ද;
- මෙම පළ කිරීම බොහෝ විට පෙන්වන්නේ කුමන වේලාවටද (objectId) සහ යනාදිය.
මේ සියල්ල ක්රමයෙන් ප්රමිතික වැඩි දියුණු කළේය. නමුත් පුහුණු දත්ත කට්ටලයේ ප්රමාණය වාර්තා මිලියන 20ක් පමණ වේ, එබැවින් විශේෂාංග එකතු කිරීම පුහුණුව බෙහෙවින් මන්දගාමී විය.
මම දත්ත භාවිතා කිරීමට මගේ ප්රවේශය නැවත සිතා බැලුවෙමි. දත්ත කාලය මත රඳා පැවතුනද, “අනාගතයේදී” පැහැදිලි තොරතුරු කාන්දු වීමක් මා දුටුවේ නැත, කෙසේ වෙතත්, මම එය මේ ආකාරයට බිඳ දැමුවෙමි:
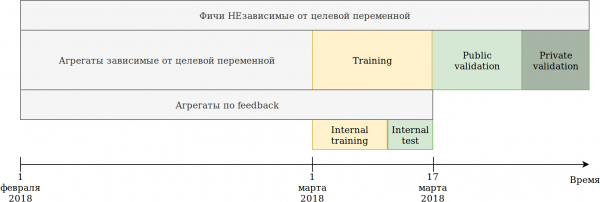
අපට ලබා දුන් පුහුණු කට්ටලය (පෙබරවාරි සහ මාර්තු සති 2) කොටස් 2 කට බෙදා ඇත.
ආකෘතිය පසුගිය N දින සිට දත්ත මත පුහුණු කරන ලදී. ඉහත විස්තර කර ඇති එකතු කිරීම් පරීක්ෂණය ඇතුළුව සියලුම දත්ත මත ගොඩනගා ඇත. ඒ අතරම, ඉලක්ක විචල්යයේ විවිධ කේතීකරණ ගොඩනගා ගත හැකි දත්ත දර්ශනය වී ඇත. සරලම ප්රවේශය නම් දැනටමත් නව විශේෂාංග නිර්මාණය කරමින් පවතින කේතය නැවත භාවිතා කිරීම සහ එය පුහුණු නොකළ දත්ත සහ ඉලක්ක = 1 පෝෂණය කිරීමයි.
මේ අනුව, අපට සමාන ලක්ෂණ ඇත:
- group ownerId හි පළ කිරීමක් userId කී වතාවක් දැක තිබේද;
- සමූහ හිමිකරු අයිඩී හි පළ කිරීමට පරිශීලක අයිඩී කී වතාවක් කැමතිද;
- userId ownerId වෙතින් කැමති පළ කිරීම් ප්රතිශතය.
එනම්, එය හැරී ගියේය ඉලක්ක කේතනය අදහස් කරයි වර්ගීකරණ විශේෂාංගවල විවිධ සංයෝජන සඳහා දත්ත කට්ටලයේ කොටසක් මත. ප්රතිපත්තිමය වශයෙන්, catboost ද ඉලක්ක කේතීකරණය ගොඩනඟන අතර මෙම දෘෂ්ටි කෝණයෙන් කිසිදු ප්රතිලාභයක් නොමැත, නමුත්, උදාහරණයක් ලෙස, මෙම කණ්ඩායමේ පළ කිරීම් වලට කැමති වූ අද්විතීය පරිශීලකයින් සංඛ්යාව ගණනය කිරීමට හැකි විය. ඒ සමගම, ප්රධාන ඉලක්කය සාක්ෂාත් කර ගන්නා ලදී - මගේ දත්ත කට්ටලය කිහිප වතාවක් අඩු කරන ලද අතර, විශේෂාංග උත්පාදනය දිගටම කරගෙන යාමට හැකි විය.
catboost හට කැමති ප්රතික්රියාව මත පමණක් කේතනය ගොඩනගා ගත හැකි අතර, ප්රතිපෝෂණයට වෙනත් ප්රතික්රියා ඇත: නැවත බෙදාගත්, අකමැති වූ, අකමැති වූ, ක්ලික් කළ, නොසලකා හරින ලද, අතින් කළ හැකි කේතන. මම සියලු වර්ගවල එකතු කිරීම් නැවත ගණනය කළ අතර දත්ත කට්ටලය පුම්බා නොදැමීම සඳහා අඩු වැදගත්කමක් ඇති විශේෂාංග ඉවත් කළෙමි.
ඒ වන විට මම විශාල පරතරයකින් පළමු ස්ථානයේ සිටියා. ව්යාකූල වූ එකම දෙය නම් රූප කාවැද්දීම කිසිදු වර්ධනයක් පෙන්නුම් නොකිරීමයි. හැම දෙයක්ම කැට්බූස්ට් කරන්න දෙන්න අදහසක් ආවා. අපි Kmeans පින්තූර පොකුරු කර නව වර්ගීකරණ විශේෂාංග imageCat ලබා ගනිමු.
KMeans වෙතින් ලබාගත් පොකුරු අතින් පෙරීම සහ ඒකාබද්ධ කිරීමෙන් පසු පන්ති කිහිපයක් මෙන්න.
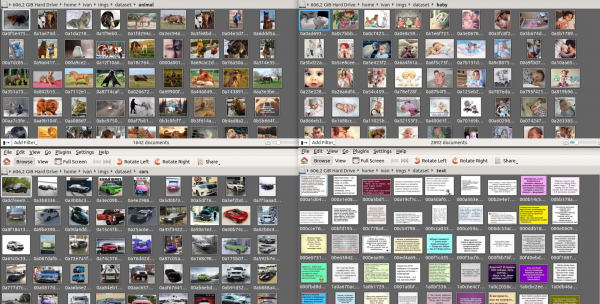
imageCat මත පදනම්ව අපි උත්පාදනය කරන්නේ:
- නව වර්ගීකරණ විශේෂාංග:
- userId විසින් බොහෝ විට නරඹන ලද imageCat කවරේද;
- කුමන imageCat බොහෝ විට හිමිකරු Id පෙන්වයි;
- userId විසින් බොහෝ විට කැමති වූ imageCat කවරේද;
- විවිධ කවුන්ටර:
- අනන්ය imageCat කීයක් userId බැලුවද;
- ඉහත විස්තර කර ඇති පරිදි සමාන විශේෂාංග 15ක් පමණ සහ ඉලක්ක කේතනය.
පෙළ
රූප තරගයේ ප්රතිඵල මට ගැළපුණු අතර මම පෙළ උත්සාහ කිරීමට තීරණය කළෙමි. මම මීට පෙර පෙළ සමඟ වැඩිපුර වැඩ කර නොමැති අතර, මෝඩ ලෙස, මම tf-idf සහ svd මත දවස මරා දැමුවෙමි. ඊට පස්සේ මම දැක්කා මට අවශ්ය දේ හරියටම කරන doc2vec සමඟ බේස්ලයින්. doc2vec පරාමිති තරමක් ගැලපීමෙන් පසුව, මට පෙළ කාවැද්දීම් ලැබුණි.
ඉන්පසු මම පින්තූර සඳහා කේතය නැවත භාවිතා කළෙමි, එහි මම රූප කාවැද්දීම් පෙළ කාවැද්දීම සමඟ ප්රතිස්ථාපනය කළෙමි. ඒ නිසා මට පෙළ තරගයෙන් 2 වැනි ස්ථානය ලැබුණා.
සහයෝගීතා පද්ධතිය
මම තවමත් පොල්ලකින් "පොක්" නොකළ එක් තරඟයක් ඉතිරිව තිබූ අතර, ප්රමුඛ පුවරුවේ AUC විසින් විනිශ්චය කිරීම, මෙම විශේෂිත තරඟයේ ප්රතිඵල නොබැඳි වේදිකාවට විශාලතම බලපෑමක් ඇති කළ යුතුව තිබුණි.
මම මූලාශ්ර දත්තවල තිබූ සියලුම විශේෂාංග ගෙන, වර්ගීකරණය කළ ඒවා තෝරාගෙන, රූප මත පදනම් වූ විශේෂාංග හැර, රූප සඳහා එකම එකතුව ගණනය කළෙමි. මේක කැට්බූස්ට් එකට දැම්මම මාව 2 වෙනි තැනට ගත්තා.
කැට්බූස්ට් ප්රශස්තකරණයේ පළමු පියවර
පළමු හා දෙවන ස්ථාන දෙකක් මා සතුටු කළ නමුත් මම විශේෂ දෙයක් කර නොමැති බවට අවබෝධයක් තිබුණි, එයින් අදහස් කරන්නේ මට තනතුර අහිමි වීමක් අපේක්ෂා කළ හැකි බවයි.
තරඟයේ කර්තව්යය වන්නේ පරිශීලකයා තුළ තනතුරු ශ්රේණිගත කිරීම වන අතර, මේ කාලය පුරාම මම වර්ගීකරණ ගැටළුව විසඳමින් සිටියෙමි, එනම් වැරදි මෙට්රික් ප්රශස්ත කිරීම.
මම ඔබට සරල උදාහරණයක් දෙන්නම්:
| පරිශීලක ID | objectId | අනාවැකිය | බිම් සත්යය |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
අපි කුඩා නැවත සකස් කිරීමක් කරමු
| පරිශීලක ID | objectId | අනාවැකිය | බිම් සත්යය |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
අපි පහත ප්රතිඵල ලබා ගනිමු:
| ආකෘතිය | AUC | පරිශීලක1 AUC | පරිශීලක2 AUC | AUC යන්නෙන් අදහස් කෙරේ |
|---|---|---|---|---|
| විකල්ප 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| විකල්ප 2 | 0,7 | 0,75 | 1,0 | 0,875 |
ඔබට පෙනෙන පරිදි, සමස්ත AUC මෙට්රික් වැඩිදියුණු කිරීම යනු පරිශීලකයෙකු තුළ සාමාන්ය AUC මෙට්රික් වැඩි දියුණු කිරීම නොවේ.
කැට්බූස්ට් පෙට්ටියෙන්. මම ශ්රේණිගත කිරීමේ ප්රමිතික ගැන කියෙව්වා, catboost භාවිතා කරන විට සහ එක රැයකින් පුහුණු වීමට YetiRankPairwise සකසන්න. ප්රතිඵලය ආකර්ෂණීය නොවීය. මම අඩු පුහුණුවක් ලබා ඇති බව තීරණය කරමින්, මම දෝෂ ශ්රිතය QueryRMSE වෙත වෙනස් කළෙමි, එය catboost ලේඛනගත කිරීම අනුව විනිශ්චය කිරීම, වේගයෙන් අභිසාරී වේ. අවසානයේදී, වර්ගීකරණය සඳහා පුහුණුවීම් කරන විට මට සමාන ප්රතිඵල ලැබුණි, නමුත් මෙම ආකෘති දෙකේ ensembles හොඳ වැඩිවීමක් ලබා දුන් අතර, එය තරඟ තුනේම පළමු ස්ථානයට ගෙන ආවේය.
"සහයෝගී පද්ධති" තරඟයේ මාර්ගගත වේදිකාව අවසන් වීමට මිනිත්තු 5 කට පෙර, සර්ජි ෂල්නොව් මාව දෙවන ස්ථානයට ගෙන ගියේය. අපි එකට ඉදිරි මාවතේ ගමන් කළෙමු.
නොබැඳි අදියර සඳහා සූදානම් වෙමින්
RTX 2080 TI වීඩියෝ කාඩ්පතක් සමඟ සබැඳි වේදිකාවේ ජයග්රහණය අපට සහතික විය, නමුත් ප්රධාන ත්යාගය වන රූබල් 300 සහ, බොහෝ දුරට, අවසාන පළමු ස්ථානය පවා මෙම සති 000 සඳහා වැඩ කිරීමට අපට බල කළේය.
පෙනෙන පරිදි, සර්ජි ද කැට්බූස්ට් භාවිතා කළේය. අපි අදහස් සහ විශේෂාංග හුවමාරු කර ගත්තා, මම ඉගෙන ගත්තා මගේ බොහෝ ප්රශ්නවලට පිළිතුරු සහ ඒ වන විට මා සතුව නොතිබූ ඒවාට පවා පිළිතුරු එහි අඩංගු විය.
වාර්තාව බැලීමෙන් අපට සියලු පරාමිතියන් පෙරනිමි අගය වෙත ආපසු ලබා දිය යුතු අතර, සැකසුම් ඉතා ප්රවේශමෙන් සිදු කළ යුතු අතර විශේෂාංග සමූහයක් සවි කිරීමෙන් පසුව පමණක් කළ යුතුය යන අදහස මට ගෙන ආවේය. දැන් එක් පුහුණුවක් සඳහා පැය 15 ක් පමණ ගත විය, නමුත් එක් ආකෘතියක් ශ්රේණිගත කිරීම සමඟ සමූහයේ ලබාගත් වේගයට වඩා හොඳ වේගයක් ලබා ගැනීමට සමත් විය.
විශේෂාංග උත්පාදනය
සහයෝගීතා පද්ධති තරඟයේදී, ආකෘතිය සඳහා වැදගත් අංගයන් විශාල ප්රමාණයක් තක්සේරු කෙරේ. උදාහරණ වශයෙන්, auditweights_spark_svd - වැදගත්ම ලකුණ, නමුත් එයින් අදහස් කරන්නේ කුමක්ද යන්න පිළිබඳ තොරතුරු නොමැත. වැදගත් ලක්ෂණ මත පදනම්ව විවිධ එකතු කිරීම් ගණනය කිරීම වටී යැයි මම සිතුවෙමි. උදාහරණයක් ලෙස, සාමාන්ය auditweights_spark_svd පරිශීලකයා විසින්, කණ්ඩායම අනුව, වස්තුව අනුව. කිසිදු පුහුණුවක් සිදු නොකරන දත්ත භාවිතා කරමින් එයම ගණනය කළ හැකි අතර ඉලක්කය = 1, එනම් සාමාන්යය auditweights_spark_svd පරිශීලකයා විසින් ඔහු කැමති වස්තූන් අනුව. ඊට අමතරව වැදගත් සංඥා auditweights_spark_svd, කිහිපයක් තිබුණා. ඒවායින් කිහිපයක් මෙන්න:
- auditweightsCtrGender
- විගණන බර CtrHigh
- userOwnerCounterCreateLikes
උදාහරණයක් ලෙස, සාමාන්යය auditweightsCtrGender userId ට අනුව එය සාමාන්ය අගය මෙන් වැදගත් අංගයක් බවට පත් විය userOwnerCounterCreateLikes userId+ownerId මගින්. ක්ෂේත්රවල තේරුම ඔබ තේරුම් ගත යුතු බව මෙය දැනටමත් ඔබට සිතිය යුතුය.
එසේම වැදගත් අංගයන් විය auditweightsLikesCount и auditweightsShowsCount. එකින් එක බෙදලා ඊටත් වඩා වැදගත් ලක් ෂණයක් ලැබුණා.
දත්ත කාන්දු වීම
තරඟකාරිත්වය සහ නිෂ්පාදන ආකෘති නිර්මාණය ඉතා වෙනස් කාර්යයන් වේ. දත්ත සකස් කිරීමේදී, සියලු විස්තර සැලකිල්ලට ගැනීම ඉතා අපහසු වන අතර පරීක්ෂණයේ ඉලක්ක විචල්යය පිළිබඳ සුළු නොවන තොරතුරු ලබා නොදීම. අපි නිෂ්පාදන විසඳුමක් නිර්මාණය කරන්නේ නම්, ආකෘතිය පුහුණු කිරීමේදී දත්ත කාන්දුවීම් භාවිතා නොකිරීමට අපි උත්සාහ කරමු. නමුත් අපට තරඟය ජය ගැනීමට අවශ්ය නම්, දත්ත කාන්දු වීම හොඳම විශේෂාංග වේ.
දත්ත අධ්යයනය කිරීමෙන් පසු, objectId අගයන් අනුව ඔබට එය දැක ගත හැකිය auditweightsLikesCount и auditweightsShowsCount වෙනස් කිරීම, එයින් අදහස් කරන්නේ මෙම විශේෂාංගවල උපරිම අගයන්හි අනුපාතය ප්රදර්ශනය වන අවස්ථාවේ අනුපාතයට වඩා පශ්චාත් පරිවර්තනය වඩා හොඳින් පිළිබිඹු වන බවයි.
අපි සොයා ගත් පළමු කාන්දුව auditweightsLikesCountMax/auditweightsShowsCountMax.
නමුත් අපි දත්ත වඩාත් සමීපව බැලුවහොත් කුමක් කළ යුතුද? අපි සංදර්ශන දිනය අනුව වර්ග කර ලබා ගනිමු:
| objectId | පරිශීලක ID | auditweightsShowsCount | auditweightsLikesCount | ඉලක්කය (කැමතියි) |
|---|---|---|---|---|
| 1 | 1 | 12 | 3 | සමහරවිට නැහැ |
| 1 | 2 | 15 | 3 | සමහරවිට ඔව් |
| 1 | 3 | 16 | 4 |
එවැනි පළමු උදාහරණය මා සොයාගත් විට එය පුදුමයට කරුණක් වූ අතර මගේ අනාවැකිය සැබෑ නොවූ බව පෙනී ගියේය. එහෙත්, වස්තුව තුළ මෙම ලක්ෂණවල උපරිම අගයන් වැඩි වීමක් ලබා දුන් බව සැලකිල්ලට ගනිමින්, අපි කම්මැලි නොවී සොයා ගැනීමට තීරණය කළෙමු. auditweightsShowsCountNext и auditweightsLikesCountNext, එනම්, ඊළඟ මොහොතේ අගයන්. විශේෂාංගයක් එකතු කිරීමෙනි
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) අපි ඉක්මනින් තියුණු පැනීමක් කළා.
සඳහා පහත අගයන් සොයා ගැනීමෙන් සමාන කාන්දුවීම් භාවිතා කළ හැක userOwnerCounterCreateLikes userId+ownerId තුළ සහ, උදාහරණයක් ලෙස, auditweightsCtrGender objectId+userGender තුළ. අපි කාන්දුවීම් සහිත සමාන ක්ෂේත්ර 6 ක් සොයාගෙන ඒවායින් හැකි තරම් තොරතුරු උපුටා ගත්තෙමු.
ඒ වන විට, අපි සහයෝගී විශේෂාංග වලින් හැකිතාක් තොරතුරු මිරිකා, නමුත් රූප සහ පෙළ තරඟ සඳහා ආපසු ගියේ නැත. මට පරීක්ෂා කිරීමට හොඳ අදහසක් තිබුණි: අදාළ තරඟ වලදී පින්තූර හෝ පෙළ මත කෙලින්ම පදනම් වූ විශේෂාංග කොපමණ ප්රමාණයක් ලබා දෙයිද?
පින්තූර සහ පෙළ තරඟ වල කාන්දුවීම් සිදු නොවීය, නමුත් ඒ වන විට මම පෙරනිමි කැට්බූස්ට් පරාමිති ආපසු ලබා දී කේතය පිරිසිදු කර විශේෂාංග කිහිපයක් එකතු කර ඇත. එකතුව වූයේ:
| තීරණය | ඉක්මනින් |
|---|---|
| පින්තූර සමඟ උපරිම | 0.6411 |
| උපරිම පින්තූර නැත | 0.6297 |
| දෙවන ස්ථානය ප්රතිඵලය | 0.6295 |
| තීරණය | ඉක්මනින් |
|---|---|
| පෙළ සමඟ උපරිම | 0.666 |
| පෙළ නොමැතිව උපරිම | 0.660 |
| දෙවන ස්ථානය ප්රතිඵලය | 0.656 |
| තීරණය | ඉක්මනින් |
|---|---|
| සහයෝගීතාවයෙන් උපරිම | 0.745 |
| දෙවන ස්ථානය ප්රතිඵලය | 0.723 |
පෙළ සහ රූපවලින් බොහෝ දේ මිරිකා ගැනීමට අපට නොහැකි බව පැහැදිලි වූ අතර, වඩාත් සිත්ගන්නාසුලු අදහස් කිහිපයක් උත්සාහ කිරීමෙන් පසු අපි ඔවුන් සමඟ වැඩ කිරීම නැවැත්වූයෙමු.
සහයෝගීතා පද්ධතිවල විශේෂාංග තවදුරටත් උත්පාදනය වැඩි වීමක් ලබා නොදුන් අතර, අපි ශ්රේණිගත කිරීම ආරම්භ කළෙමු. සබැඳි වේදිකාවේදී, වර්ගීකරණය සහ ශ්රේණිගත කිරීමේ කණ්ඩායම මට කුඩා වැඩිවීමක් ලබා දුන්නේ, එය මා වර්ගීකරණය අඩුවෙන් පුහුණු කර ඇති බැවිනි. YetiRanlPairwise ඇතුළුව කිසිදු දෝෂ ශ්රිතයක්, LogLoss සිදු කළ ප්රතිඵලය ආසන්නයේ කිසිම තැනක නිපදවා නැත (0,745 එදිරිව 0,725). දියත් කළ නොහැකි වූ QueryCrossEntropy සඳහා තවමත් බලාපොරොත්තුවක් තිබුණි.
නොබැඳි අදියර
නොබැඳි අවධියේදී, දත්ත ව්යුහය එලෙසම පැවතුනද, සුළු වෙනස්කම් ඇති විය:
- හඳුනාගැනීම් userId, objectId, ownerId නැවත සසම්භාවී විය;
- සලකුණු කිහිපයක් ඉවත් කරන ලද අතර කිහිපයක් නැවත නම් කරන ලදී;
- දත්ත දළ වශයෙන් 1,5 ගුණයකින් වැඩි වී ඇත.
ලැයිස්තුගත දුෂ්කරතා වලට අමතරව, එක් විශාල ප්ලස් එකක් විය: කණ්ඩායමට RTX 2080TI සමඟ විශාල සේවාදායකයක් වෙන් කරන ලදී. මම කාලයක් තිස්සේ htop එක රස වින්දා.
එකම අදහසක් තිබුනේ - දැනටමත් පවතින දේ සරලව ප්රතිනිෂ්පාදනය කිරීම. සේවාදායකයේ පරිසරය සැකසීමට පැය කිහිපයක් ගත කිරීමෙන් පසු, අපි ක්රමයෙන් ප්රතිඵල නැවත ලබා ගත හැකි බව තහවුරු කර ගැනීමට පටන් ගත්තෙමු. අප මුහුණ දෙන ප්රධාන ගැටලුව වන්නේ දත්ත පරිමාව වැඩිවීමයි. අපි බර ටිකක් අඩු කර catboost පරාමිතිය ctr_complexity=1 සැකසීමට තීරණය කළෙමු. මෙය වේගය ටිකක් අඩු කරයි, නමුත් මගේ ආකෘතිය වැඩ කිරීමට පටන් ගත්තේය, ප්රතිඵලය හොඳයි - 0,733. සර්ජි, මා මෙන් නොව, දත්ත කොටස් 2 කට බෙදා නොගත් අතර සියලුම දත්ත පුහුණු කර ඇත, මෙය මාර්ගගත වේදිකාවේදී හොඳම ප්රති result ලය ලබා දුන්නද, නොබැඳි අවධියේදී බොහෝ දුෂ්කරතා ඇති විය. අප විසින් ජනනය කරන ලද සියලුම විශේෂාංග ගෙන ඒවා කැට්බූස්ට් වෙත තල්ලු කිරීමට උත්සාහ කළහොත්, සබැඳි වේදිකාවේදී කිසිවක් ක්රියා නොකරනු ඇත. සර්ජි විසින් වර්ග ප්රශස්තකරණය සිදු කරන ලදී, උදාහරණයක් ලෙස, float64 වර්ග float32 බවට පරිවර්තනය කිරීම. පැන්ඩා වල මතක ප්රශස්තකරණය පිළිබඳ තොරතුරු ඔබට සොයාගත හැකිය. එහි ප්රතිඵලයක් වශයෙන්, සර්ජි සියළුම දත්ත භාවිතා කරමින් CPU මත පුහුණු කර 0,735 ක් පමණ ලබා ගත්තේය.
මෙම ප්රතිඵල ජයග්රහණය කිරීමට ප්රමාණවත් වූ නමුත් අපි අපගේ සැබෑ වේගය සඟවා ගත් අතර අනෙක් කණ්ඩායම් ද එසේ නොකරන බවට සහතික විය නොහැක.
අන්තිම වෙනකම් සටන් කරන්න
Catboost සුසර කිරීම
අපගේ විසඳුම සම්පූර්ණයෙන්ම ප්රතිනිෂ්පාදනය කරන ලදී, අපි පෙළ දත්ත සහ රූපවල විශේෂාංග එකතු කළෙමු, එබැවින් ඉතිරිව ඇත්තේ කැට්බූස්ට් පරාමිතීන් සුසර කිරීම පමණි. සර්ජි කුඩා පුනරාවර්තන සංඛ්යාවක් සමඟ CPU මත පුහුණු වූ අතර මම ctr_complexity=1 සමඟ පුහුණු කළෙමි. එක් දිනක් ඉතිරිව ඇති අතර, ඔබ පුනරාවර්තන එකතු කළහොත් හෝ ctr_complexity වැඩි කළහොත්, උදෑසන වන විට ඔබට ඊටත් වඩා හොඳ වේගයක් ලබා ගත හැකි අතර දවස පුරා ඇවිදින්න.
නොබැඳි අවධියේදී, වෙබ් අඩවියේ හොඳම විසඳුම තෝරා ගැනීමෙන් වේගය ඉතා පහසුවෙන් සැඟවිය හැක. ඉදිරිපත් කිරීම් අවසන් වීමට පෙර අවසන් මිනිත්තු කිහිපය තුළ අපි ප්රමුඛ පුවරුවේ දැඩි වෙනස්කම් අපේක්ෂා කළ අතර නතර නොකිරීමට තීරණය කළෙමු.
ඇනාගේ වීඩියෝවෙන්, ආකෘතියේ ගුණාත්මකභාවය වැඩි දියුණු කිරීම සඳහා පහත සඳහන් පරාමිතීන් තෝරා ගැනීම වඩාත් සුදුසු බව මම ඉගෙන ගතිමි:
- ඉගෙනීමේ_අනුපාතය — දත්ත කට්ටලයේ විශාලත්වය මත පදනම්ව පෙරනිමි අගය ගණනය කෙරේ. ඉගෙනීමේ_අනුපාතය වැඩි කිරීම සඳහා පුනරාවර්තන ගණන වැඩි කිරීම අවශ්ය වේ.
- l2_leaf_reg — නිත්යකරණ සංගුණකය, පෙරනිමි අගය 3, වඩාත් සුදුසු වන්නේ 2 සිට 30 දක්වා තෝරා ගැනීමයි. අගය අඩු කිරීම අධික ලෙස ගැලපීම වැඩි වීමට හේතු වේ.
- බෑග්_උෂ්ණත්වය - නියැදියේ ඇති වස්තූන්ගේ බරට සසම්භාවීකරණය එකතු කරයි. පෙරනිමි අගය 1 වේ, එහිදී බර ඝාතීය ව්යාප්තියකින් ලබා ගනී. අගය අඩු වීම අධික ලෙස ගැලපීම වැඩි වීමට හේතු වේ.
- අහඹු_ශක්තිය - නිශ්චිත පුනරාවර්තනයකදී බෙදීම් තෝරාගැනීමට බලපායි. අහඹු_ශක්තිය වැඩි වන තරමට, අඩු වැදගත්කමක් ඇති බෙදීමක් තෝරා ගැනීමේ අවස්ථාව වැඩි වේ. එක් එක් පසු පුනරාවර්තනයකදී, අහඹු බව අඩු වේ. අගය අඩු වීම අධික ලෙස ගැලපීම වැඩි වීමට හේතු වේ.
අනෙකුත් පරාමිතීන් අවසාන ප්රති result ලය කෙරෙහි වඩා කුඩා බලපෑමක් ඇති කරයි, එබැවින් මම ඒවා තෝරා ගැනීමට උත්සාහ නොකළෙමි. ctr_complexity=1 සමඟ මගේ GPU දත්ත කට්ටලයේ එක් පුනරාවර්තනයක් සඳහා මිනිත්තු 20ක් ගත වූ අතර, අඩු කරන ලද දත්ත කට්ටලයේ තෝරාගත් පරාමිති සම්පූර්ණ දත්ත කට්ටලයේ ඇති ප්රශස්ත ඒවාට වඩා තරමක් වෙනස් විය. අවසානයේදී, මම දත්ත වලින් 30% ක පුනරාවර්තන 10 ක් පමණ කළෙමි, පසුව සියලු දත්ත මත තවත් පුනරාවර්තන 10 ක් පමණ කළෙමි. එය මේ වගේ දෙයක් බවට පත් විය:
- ඉගෙනීමේ_අනුපාතය මම පෙරනිමියෙන් 40% කින් වැඩි කළෙමි;
- l2_leaf_reg එය එලෙසම අත්හැරිය;
- බෑග්_උෂ්ණත්වය и අහඹු_ශක්තිය 0,8 දක්වා අඩු කර ඇත.
ආකෘතිය පෙරනිමි පරාමිතීන් සමඟ අඩු පුහුණුවක් ලබා ඇති බව අපට නිගමනය කළ හැකිය.
ප්රමුඛ පුවරුවේ ප්රතිඵලය දුටු විට මම ඉතා පුදුමයට පත් විය:
| ආකෘතිය | ආකෘතිය 1 | ආකෘතිය 2 | ආකෘතිය 3 | සමූහ |
|---|---|---|---|---|
| සුසර කිරීමකින් තොරව | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| සුසර කිරීම සමඟ | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
මාදිලියේ ඉක්මන් යෙදුමක් අවශ්ය නොවේ නම්, ප්රශස්ත නොවන පරාමිතීන් භාවිතා කරමින් පරාමිති තේරීම ආකෘති කිහිපයක එකතුවක් සමඟ ප්රතිස්ථාපනය කිරීම වඩා හොඳ බව මම මා විසින්ම නිගමනය කළෙමි.
සර්ජි එය GPU මත ධාවනය කිරීමට දත්ත කට්ටලයේ ප්රමාණය ප්රශස්ත කරමින් සිටියේය. සරලම විකල්පය වන්නේ දත්තවල කොටසක් කපා හැරීමයි, නමුත් මෙය ක්රම කිහිපයකින් කළ හැකිය:
- දත්ත කට්ටලය මතකයට ගැළපීමට පටන් ගන්නා තෙක් පැරණිතම දත්ත (පෙබරවාරි මස ආරම්භය) ක්රමයෙන් ඉවත් කරන්න;
- අඩුම වැදගත්කමක් ඇති විශේෂාංග ඉවත් කරන්න;
- එක් ප්රවේශයක් පමණක් ඇති userId ඉවත් කරන්න;
- පරීක්ෂණයේ ඇති userId පමණක් තබන්න.
අවසාන වශයෙන්, සියලු විකල්ප වලින් සමූහයක් සාදන්න.
අවසාන කණ්ඩායම
අවසාන දිනයේ සවස් වන විට, අපි 0,742 ලබා දුන් අපගේ මාදිලි සමූහයක් සකස් කර ඇත. එක රැයකින් මම මගේ මාදිලිය ctr_complexity=2 සමඟ දියත් කළ අතර මිනිත්තු 30ක් වෙනුවට එය පැය 5ක් පුහුණු කළා. උදේ 4 ට පමණක් එය ගණන් කරන ලද අතර, මම අවසාන කණ්ඩායම සෑදුවෙමි, එය පොදු ප්රමුඛ පුවරුවේ 0,7433 ලබා දුන්නේය.
ගැටළුව විසඳීම සඳහා විවිධ ප්රවේශයන් හේතුවෙන්, අපගේ අනාවැකි දැඩි ලෙස සහසම්බන්ධ නොවූ අතර එය සමූහයේ හොඳ වැඩි වීමක් ලබා දුන්නේය. හොඳ එකතුවක් ලබා ගැනීම සඳහා, raw model අනාවැකි අනාවැකි (Prediction_type='RawFormulaVal') භාවිතා කිරීම සහ scale_pos_weight=neg_count/pos_count සැකසීම වඩා හොඳය.
වෙබ් අඩවියේ ඔබට දැක ගත හැකිය .
වෙනත් විසඳුම්
බොහෝ කණ්ඩායම් නිර්දේශිත පද්ධති ඇල්ගොරිතමවල කැනන අනුගමනය කළහ. මම, මෙම ක්ෂේත්රයේ විශේෂඥයෙකු නොවන නිසා, ඒවා ඇගයීමට නොහැකිය, නමුත් මට රසවත් විසඳුම් 2 ක් මතකයි.
- . Mail.ru හි සේවකයෙකු වූ Nikolay ත්යාග සඳහා අයදුම් නොකළ බැවින් ඔහුගේ ඉලක්කය වූයේ උපරිම වේගයක් ලබා ගැනීම නොව පහසුවෙන් පරිමාණය කළ හැකි විසඳුමක් ලබා ගැනීමයි.
- ජූරි ත්යාගලාභී කණ්ඩායමේ තීරණය පදනම් වී ඇත , අතින් වැඩ කිරීමකින් තොරව ඉතා හොඳ රූප පොකුරු සඳහා ඉඩ ලබා දේ.
නිගමනය
මගේ මතකයේ වැඩිපුරම රැඳුණු දේ:
- දත්තවල වර්ගීකරණ විශේෂාංග තිබේ නම් සහ ඉලක්ක කේතනය නිවැරදිව කරන්නේ කෙසේදැයි ඔබ දන්නේ නම්, තවමත් catboost උත්සාහ කිරීම වඩා හොඳය.
- ඔබ තරඟයකට සහභාගී වන්නේ නම්, learning_rate සහ පුනරාවර්තන හැර වෙනත් පරාමිති තෝරාගැනීමේදී ඔබ කාලය නාස්ති නොකළ යුතුය. වේගවත් විසඳුමක් වන්නේ ආකෘති කිහිපයක එකතුවක් සෑදීමයි.
- GPU මත Boosting ඉගෙන ගත හැක. Catboost GPU මත ඉතා ඉක්මනින් ඉගෙන ගත හැක, නමුත් එය මතකය විශාල ප්රමාණයක් අනුභව කරයි.
- අදහස් සංවර්ධනය කිරීමේදී සහ පරීක්ෂා කිරීමේදී, කුඩා rsm~=0.2 (CPU පමණි) සහ ctr_complexity=1 සැකසීම වඩා හොඳය.
- අනෙකුත් කණ්ඩායම් මෙන් නොව, අපගේ නිරූපිකාවන්ගේ කණ්ඩායම විශාල වැඩිවීමක් ලබා දුන්නේය. අපි අදහස් හුවමාරු කර ගත්තේ විවිධ භාෂාවලින් ලිව්වා පමණයි. දත්ත බෙදීමට අපට වෙනස් ප්රවේශයක් තිබූ අතර, මම සිතන්නේ, ඒ සෑම එකක්ම තමන්ගේම දෝෂ ඇති බවයි.
- ශ්රේණිගත කිරීම් ප්රශස්තකරණය වර්ගීකරණ ප්රශස්තකරණයට වඩා නරක ලෙස ක්රියා කළේ මන්දැයි පැහැදිලි නැත.
- මම පෙළ සමඟ වැඩ කිරීමේ යම් අත්දැකීමක් සහ නිර්දේශිත පද්ධති සෑදෙන්නේ කෙසේද යන්න පිළිබඳ අවබෝධයක් ලබා ගත්තා.

ලැබුණු හැඟීම්, දැනුම සහ ත්යාග සඳහා සංවිධායකයින්ට ස්තූතියි.
මූලාශ්රය: www.habr.com
