

R - data.tableக்கு அட்டவணை தரவு செயலாக்க நூலகத்தைப் பயன்படுத்துபவர்களுக்கு இந்தக் குறிப்பு ஆர்வமாக இருக்கும், மேலும் பல்வேறு எடுத்துக்காட்டுகளில் அதன் பயன்பாட்டின் நெகிழ்வுத்தன்மையைக் கண்டு மகிழ்ச்சியடையலாம்.
ஒரு நல்ல உதாரணத்தால் ஈர்க்கப்பட்டது , மற்றும் அவருடைய கட்டுரையை நீங்கள் ஏற்கனவே படித்திருப்பீர்கள் என்று நம்புகிறேன், குறியீடு தேர்வுமுறை மற்றும் செயல்திறன் அடிப்படையில் ஆழமாக தோண்டி எடுக்க நான் முன்மொழிகிறேன். தரவு. அட்டவணை.
அறிமுகம்: data.table எங்கிருந்து வருகிறது?
தொலைதூரத்திலிருந்து நூலகத்துடன் பழகத் தொடங்குவது சிறந்தது, அதாவது தரவு. அட்டவணைப் பொருளை (இனி DT என குறிப்பிடப்படும்) பெறக்கூடிய தரவு கட்டமைப்புகளுடன்.
வரிசை
குறியீடு
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
அத்தகைய ஒரு அமைப்பு ஒரு வரிசை (?அடிப்படை::வரிசை) மற்ற மொழிகளைப் போலவே, இங்கும் வரிசைகள் பல பரிமாணங்கள் கொண்டவை. இருப்பினும், சுவாரஸ்யமான விஷயம் என்னவென்றால், எடுத்துக்காட்டாக, இரு பரிமாண வரிசை மேட்ரிக்ஸ் வகுப்பிலிருந்து பண்புகளைப் பெறத் தொடங்குகிறது. (?அடிப்படை::மேட்ரிக்ஸ்), மற்றும் ஒரு பரிமாண வரிசை, இதுவும் முக்கியமானது, ஒரு திசையனிலிருந்து மரபுரிமை பெறாது (?அடிப்படை::வெக்டர்).
எந்தவொரு பொருளிலும் உள்ள தரவு வகை செயல்பாட்டைப் பயன்படுத்தி சரிபார்க்கப்பட வேண்டும் என்பதை புரிந்து கொள்ள வேண்டும் அடிப்படை::வகை, இது இன் படி உள் வகை விளக்கத்தை வழங்குகிறது ஆர் இன்டர்னல்ஸ் - மூலத்துடன் தொடர்புடைய மொழியின் பொதுவான நெறிமுறை C.
ஒரு பொருளின் வகுப்பை தீர்மானிக்க மற்றொரு கட்டளை அடிப்படை::வகுப்பு, திசையன்களின் விஷயத்தில், திசையன் வகையை வழங்குகிறது (அது அகத்திலிருந்து பெயரில் வேறுபடுகிறது, ஆனால் தரவு வகையைப் புரிந்துகொள்ள உங்களை அனுமதிக்கிறது).
பட்டியல்
மேட்ரிக்ஸ் என்றும் அழைக்கப்படும் இரு பரிமாண வரிசையில் இருந்து, நீங்கள் பட்டியலுக்கு செல்லலாம் (?அடிப்படை:: பட்டியல்).
குறியீடு
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
ஒரே நேரத்தில் பல விஷயங்கள் நடக்கும்:
- மேட்ரிக்ஸின் இரண்டாவது பரிமாணம் சரிகிறது, அதாவது, ஒரே நேரத்தில் ஒரு பட்டியல் மற்றும் திசையன் இரண்டையும் பெறுகிறோம்.
- பட்டியல் இந்த வகுப்புகளிலிருந்து பெறுகிறது. ஒரு பட்டியல் உறுப்பு அணிவரிசை மேட்ரிக்ஸின் கலத்திலிருந்து ஒரு (ஸ்கேலர்) மதிப்புடன் ஒத்திருக்கும் என்பதை நினைவில் கொள்ள வேண்டும்.
பட்டியல் ஒரு திசையன் என்பதால், சில திசையன் செயல்பாடுகளை அதற்குப் பயன்படுத்தலாம்.
டேட்டாஃப்ரேம்
நீங்கள் பட்டியல், அணி அல்லது வெக்டரில் இருந்து டேட்டாஃப்ரேமிற்கு செல்லலாம் (?base::data.frame).
குறியீடு
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
இதில் சுவாரஸ்யமானது என்ன: டேட்டாஃப்ரேம் பட்டியலிலிருந்து பெறுகிறது! டேட்டாஃப்ரேம் நெடுவரிசைகள் பட்டியல் கலங்கள். பட்டியல்களுக்குப் பயன்படுத்தப்படும் செயல்பாடுகளைப் பயன்படுத்தும்போது இது பின்னர் முக்கியமானதாக இருக்கும்.
தரவு. அட்டவணை
டிடி (?data.table::data.table) இருந்து இருக்கலாம் தரவுச்சட்டம், பட்டியல், திசையன் அல்லது அணி. உதாரணமாக, இது போன்ற (இடத்தில்).
குறியீடு
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
டேட்டாஃப்ரேமைப் போலவே, டிடியும் பட்டியலின் பண்புகளைப் பெறுவது பயனுள்ளது.
டிடி மற்றும் நினைவகம்
R தளத்தில் உள்ள மற்ற எல்லா பொருட்களையும் போலல்லாமல், DTகள் குறிப்பு மூலம் அனுப்பப்படுகின்றன. நீங்கள் ஒரு புதிய நினைவக பகுதிக்கு நகலெடுக்க வேண்டும் என்றால், உங்களுக்கு ஒரு செயல்பாடு தேவை data.table::நகல் அல்லது பழைய பொருளில் இருந்து தேர்வு செய்ய வேண்டும்.
குறியீடு
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
இத்துடன் அறிமுகம் முடிகிறது. DT என்பது R இல் தரவு கட்டமைப்புகளின் வளர்ச்சியின் தொடர்ச்சியாகும், இது முக்கியமாக டேட்டாஃப்ரேம் வகுப்பின் பொருள்களில் செய்யப்படும் செயல்பாடுகளின் விரிவாக்கம் மற்றும் முடுக்கம் காரணமாக நிகழ்கிறது. அதே நேரத்தில், பிற ஆதிகாலங்களிலிருந்து பரம்பரை பாதுகாக்கப்படுகிறது.
data.table பண்புகளைப் பயன்படுத்துவதற்கான சில எடுத்துக்காட்டுகள்
ஒரு பட்டியல் போல...
டேட்டாஃப்ரேம் அல்லது டிடியின் வரிசைகளை மீண்டும் மீண்டும் செய்வது நல்ல யோசனையல்ல, ஏனெனில் மொழியில் உள்ள லூப் குறியீடு R மிகவும் மெதுவாக C, ஆனால் நெடுவரிசைகள் மூலம் லூப் செய்வது மிகவும் சாத்தியம், அவை பொதுவாக மிகவும் சிறியவை. நெடுவரிசைகளின் வழியாகச் செல்லும்போது, ஒவ்வொரு நெடுவரிசையும் பட்டியலின் ஒரு உறுப்பு என்பதை நினைவில் கொள்ளுங்கள், பொதுவாக ஒரு திசையன் உள்ளது. மற்றும் திசையன்களின் செயல்பாடுகள் மொழியின் அடிப்படை செயல்பாடுகளில் நன்கு வெக்டரைஸ் செய்யப்படுகின்றன. பட்டியல்கள் மற்றும் வெக்டர்களுக்கு பொதுவான தேர்வு ஆபரேட்டர்களையும் நீங்கள் பயன்படுத்தலாம்: `[[`, `$`.
குறியீடு
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
வெக்டரைசேஷன்
ஒரு பெரிய டிடியின் வரிகள் வழியாக செல்ல வேண்டிய அவசியம் இருந்தால், திசையன்மயமாக்கலுடன் ஒரு செயல்பாட்டை எழுதுவதே சிறந்த தீர்வாக இருக்கும். ஆனால் இது வேலை செய்யவில்லை என்றால், சுழற்சி என்பதை நீங்கள் நினைவில் கொள்ள வேண்டும் உள்ள DT இன்னும் சுழற்சியை விட வேகமாக உள்ளது R, அன்று நிகழ்த்தப்படுவதால் C.
100K வரிசைகள் கொண்ட பெரிய எடுத்துக்காட்டில் இதை முயற்சிப்போம். திசையன் நெடுவரிசையில் உள்ள சொற்களிலிருந்து முதல் எழுத்தைப் பிரித்தெடுப்போம் w.
புதுப்பிக்கப்பட்ட
குறியீடு
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
முதலில் வரிசைகளில் மீண்டும் இயக்கவும்:
அலகு: மில்லி விநாடிகள்
எக்ஸ்பிர நிமிடம்
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)]} 439.6217
lq சராசரி uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
இரண்டாவது ரன், பட்டியலை மேட்ரிக்ஸாக மாற்றுவதன் மூலம் வெக்டரைசேஷன் நிகழ்கிறது மற்றும் குறியீட்டு 1 உடன் ஸ்லைஸில் உள்ள கூறுகளை எடுத்துக்கொள்வது (பிந்தையது வெக்டரைசேஷன் ஆகும்). திருத்தம்: செயல்பாட்டு மட்டத்தில் வெக்டரைசேஷன் strsplit, இது ஒரு திசையனை உள்ளீடாக ஏற்றுக்கொள்ளும். ஒரு பட்டியலை மேட்ரிக்ஸாக மாற்றுவதற்கான செயல்முறை திசையன்மயமாக்கலை விட மிகவும் கடினம் என்று மாறிவிடும், ஆனால் இந்த விஷயத்தில் இது திசையன் இல்லாத பதிப்பை விட மிக வேகமாக உள்ளது.
அலகு: மில்லி விநாடிகள்
expr min lq சராசரி uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
இடைநிலை இன் மூலம் முடுக்கம் 3 முறை.
மூன்றாவது ரன், மேட்ரிக்ஸாக மாற்றும் திட்டம் மாற்றப்பட்டது.
அலகு: மில்லி விநாடிகள்
expr min lq சராசரி uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
இடைநிலை இன் மூலம் முடுக்கம் 13 முறை.
இந்த விஷயத்தில் நீங்கள் பரிசோதனை செய்ய வேண்டும், மேலும், அது சிறப்பாக இருக்கும்.
திசையன்மயமாக்கலுடன் மற்றொரு எடுத்துக்காட்டு, அங்கு உரையும் உள்ளது, ஆனால் அது உண்மையான நிலைமைகளுக்கு அருகில் உள்ளது: வெவ்வேறு சொற்களின் நீளம், வெவ்வேறு எண்ணிக்கையிலான சொற்கள். நீங்கள் முதல் 3 வார்த்தைகளைப் பெற வேண்டும். இது போல்:
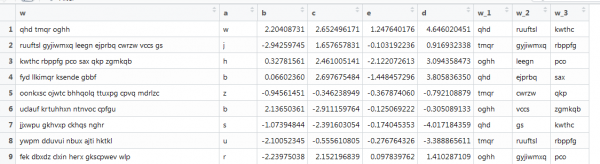
இங்கே முந்தைய செயல்பாடு வேலை செய்யாது, ஏனெனில் திசையன்கள் வெவ்வேறு நீளங்களைக் கொண்டுள்ளன, மேலும் நாங்கள் மேட்ரிக்ஸ் அளவை அமைக்கிறோம். இணையத்தில் தோண்டி இதை மீண்டும் செய்யலாம்.
குறியீடு
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
அலகு: மில்லி விநாடிகள்
expr min lq சராசரி சராசரி
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fixed = T))] 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
ஸ்கிரிப்ட் சராசரியாக 1 வினாடி வேகத்தில் ஓடியது. மோசமாக இல்லை.
ஒரு சங்கிலியால் இணைக்கப்பட்டுள்ளது...
சங்கிலியைப் பயன்படுத்தி டிடி பொருள்களுடன் நீங்கள் வேலை செய்யலாம். இது வலதுபுறத்தில் அடைப்புக்குறி தொடரியல், முக்கியமாக சர்க்கரை இணைப்பது போல் தெரிகிறது.
குறியீடு
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
குழாய்கள் வழியாக பாயும்...
அதே செயல்பாடுகளை குழாய் வழியாக செய்ய முடியும், இது ஒத்ததாக தோன்றுகிறது, ஆனால் செயல்பாட்டு ரீதியாக பணக்காரமானது, ஏனெனில் நீங்கள் டிடி மட்டுமின்றி எந்த முறையையும் பயன்படுத்தலாம். டிடியில் பல வடிப்பான்களுடன் எங்களின் செயற்கைத் தரவுகளுக்கான லாஜிஸ்டிக் ரிக்ரஷன் குணகங்களைப் பெறுவோம்.
குறியீடு
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
புள்ளியியல், இயந்திர கற்றல் மற்றும் DT இன் உள்ளே பல
நீங்கள் லாம்ப்டா செயல்பாடுகளைப் பயன்படுத்தலாம், ஆனால் சில நேரங்களில் அவற்றை தனித்தனியாக உருவாக்கி, முழு தரவு பகுப்பாய்வு பைப்லைனையும் எழுதி, மேலே செல்லவும் - அவை டிடிக்குள் வேலை செய்கின்றன. மேலே உள்ள அனைத்து அம்சங்களுடனும், DT ஆயுதக் களஞ்சியத்திலிருந்து பல பயனுள்ள விஷயங்களுடனும் உதாரணம் செறிவூட்டப்பட்டுள்ளது (ஒரு இணைப்பு வழியாக DT க்குள் DT யை அணுகுவது போன்றவை, சில சமயங்களில் வரிசையாக சேர்க்கப்படாமல், ஆனால் அது இருக்கும்).
குறியீடு
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
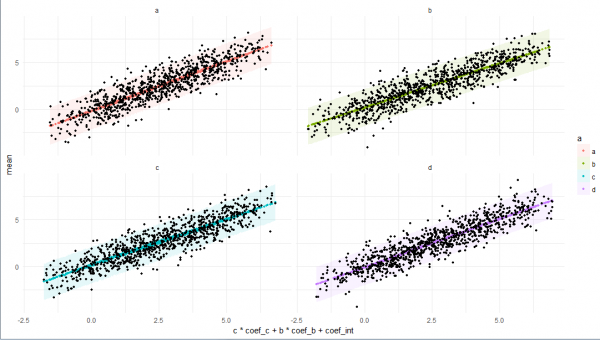
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
முடிவுக்கு
தரவு. அட்டவணை போன்ற ஒரு பொருளின் முழுமையான படத்தை என்னால் உருவாக்க முடிந்தது என்று நம்புகிறேன் . இந்த நூலகத்தை உங்கள் பணிக்காகவும் பயன்படுத்தவும் இது உங்களுக்கு உதவும் என்று நம்புகிறேன் பொழுதுபோக்கு.
நன்றி!
முழு குறியீடு
குறியீடு
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
ஆதாரம்: www.habr.com
