


రెండు సంవత్సరాల క్రితం, కుబెర్నెటెస్ అధికారిక గిట్హబ్ బ్లాగ్లో. అప్పటి నుండి, ఇది సేవలను అమలు చేయడానికి ప్రామాణిక సాంకేతికతగా మారింది. కుబెర్నెటెస్ ఇప్పుడు మా అంతర్గత మరియు పబ్లిక్ సేవల్లో గణనీయమైన భాగానికి శక్తిని అందిస్తోంది. మా క్లస్టర్లు పెరగడం మరియు పనితీరు అవసరాలు మరింత కఠినతరం కావడంతో, అప్లికేషన్ లోడ్ ద్వారా వివరించలేని కొన్ని కుబెర్నెటెస్-ఆధారిత సేవల్లో అడపాదడపా జాప్య సమస్యలను మేము గమనించాము.
ముఖ్యంగా, అప్లికేషన్లు 100 ms లేదా అంతకంటే ఎక్కువ యాదృచ్ఛిక నెట్వర్క్ లేటెన్సీని ఎదుర్కొంటాయి, ఇది టైమ్అవుట్లు లేదా రీట్రైలకు దారితీస్తుంది. సేవలు 100 ms కంటే చాలా వేగంగా అభ్యర్థనలకు ప్రతిస్పందించగలవని ఆశించబడింది. కానీ కనెక్షన్కే అంత సమయం పడితే ఇది అసాధ్యం. ప్రత్యేకంగా, మిల్లీసెకన్లలో పూర్తికావాల్సిన చాలా వేగవంతమైన MySQL క్వెరీలను మేము గమనించాము, మరియు MySQL నిజంగానే మిల్లీసెకన్లలో ప్రతిస్పందించింది, కానీ అభ్యర్థించే అప్లికేషన్ దృక్కోణం నుండి చూస్తే, ఆ ప్రతిస్పందనకు 100 ms లేదా అంతకంటే ఎక్కువ సమయం పట్టింది.
కాల్ కుబెర్నెటెస్ వెలుపల నుండి వచ్చినప్పటికీ, కుబెర్నెటెస్ నోడ్కు కనెక్ట్ చేసేటప్పుడు మాత్రమే ఈ సమస్య తలెత్తుతుందని వెంటనే స్పష్టమైంది. ఈ సమస్యను పునరావృతం చేయడానికి సులభమైన మార్గం ఒక పరీక్ష. ఏదైనా అంతర్గత హోస్ట్ నుండి రన్ అయ్యే ఇది, ఒక నిర్దిష్ట పోర్ట్పై కుబెర్నెటెస్ సేవను పరీక్షిస్తుంది మరియు అడపాదడపా అధిక లేటెన్సీని లాగ్ చేస్తుంది. ఈ ఆర్టికల్లో, ఈ సమస్యకు కారణాన్ని మేము ఎలా కనుగొన్నామో చూద్దాం.
వైఫల్య శ్రేణి నుండి అనవసరమైన సంక్లిష్టతను తొలగించడం
అదే ఉదాహరణను పునరావృతం చేయడం ద్వారా, మేము సమస్యను తగ్గించి, అనవసరమైన సంక్లిష్టత పొరలను తొలగించాలని అనుకున్నాము. ప్రారంభంలో, వెజిటా మరియు కుబెర్నెటెస్ పాడ్ల మధ్య ప్రవాహంలో చాలా అంశాలు ఉన్నాయి. లోతైన నెట్వర్క్ సమస్యను గుర్తించడానికి, మేము వాటిలో కొన్నింటిని తొలగించాల్సి వచ్చింది.
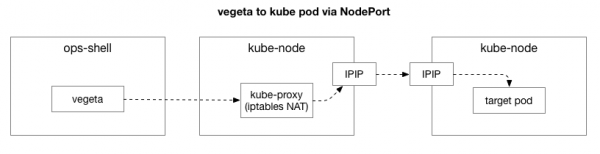
క్లయింట్ (వెజిటా) క్లస్టర్లోని ఏదైనా నోడ్కు TCP కనెక్షన్ను సృష్టిస్తుంది. కుబెర్నెటెస్ ఇప్పటికే ఉన్న డేటా సెంటర్ నెట్వర్క్పై ఒక ఓవర్లే నెట్వర్క్గా పనిచేస్తుంది. అంటే, ఇది ఓవర్లే నెట్వర్క్ యొక్క IP ప్యాకెట్లను డేటా సెంటర్ యొక్క IP ప్యాకెట్లలో పొందుపరుస్తుంది. మొదటి నోడ్కు కనెక్ట్ అయిన తర్వాత, నెట్వర్క్ అడ్రస్ ట్రాన్స్లేషన్ నిర్వహించబడుతుంది. స్టేట్ఫుల్ నెట్వర్క్ అడ్రస్ ట్రాన్స్లేషన్ (NAT) అనేది ఒక కుబెర్నెటెస్ నోడ్ యొక్క IP అడ్రస్ మరియు పోర్ట్ను ఓవర్లే నెట్వర్క్లోని (ప్రత్యేకంగా, అప్లికేషన్ను హోస్ట్ చేసే పాడ్లోని) IP అడ్రస్ మరియు పోర్ట్కు అనువదించే ఒక పద్ధతి. లోపలికి వచ్చే ప్యాకెట్లు దీనికి వ్యతిరేక ప్రక్రియకు లోనవుతాయి. సర్వీసులను డిప్లాయ్ చేసినప్పుడు మరియు తరలించినప్పుడు నిరంతరం అప్డేట్ చేయబడే మరియు సవరించబడే పెద్ద సంఖ్యలో స్టేట్లు మరియు బహుళ ఎలిమెంట్లతో కూడిన ఇది ఒక సంక్లిష్టమైన వ్యవస్థ.
వినియోగ tcpdump వెజిటా పరీక్షలో, TCP హ్యాండ్షేక్ సమయంలో (SYN మరియు SYN-ACK మధ్య) ఆలస్యం ఉంటుంది. ఈ అనవసరమైన సంక్లిష్టతను తొలగించడానికి, మీరు దీనిని ఉపయోగించవచ్చు. hping3 SYN ప్యాకెట్లతో చేసే సాధారణ పింగ్ల కోసం, మేము ప్రతిస్పందన ప్యాకెట్లో ఆలస్యాన్ని తనిఖీ చేసి, ఆపై కనెక్షన్ను రీసెట్ చేస్తాము. 100 ms కంటే ఎక్కువ నిడివి ఉన్న ప్యాకెట్లను మాత్రమే చేర్చడానికి మేము డేటాను ఫిల్టర్ చేయవచ్చు, ఇది వెజిటాలో పూర్తి లేయర్ 7 నెట్వర్కింగ్ పరీక్ష కంటే సమస్యను పునరుత్పత్తి చేయడానికి ఒక సులభమైన మార్గాన్ని అందిస్తుంది. ఇక్కడ, సర్వీస్ యొక్క "నోడ్ పోర్ట్" (30927) పై 10 ms విరామంతో TCP SYN/SYN-ACKని ఉపయోగించి, అత్యంత నెమ్మదైన ప్రతిస్పందనల ద్వారా ఫిల్టర్ చేయబడిన ఒక కుబెర్నెటెస్ నోడ్ యొక్క పింగ్లు ఉన్నాయి:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms
మొదటి పరిశీలనను వెంటనే చేయవచ్చు. క్రమ సంఖ్యలు మరియు సమయాలను బట్టి ఇవి ఒక్కసారి మాత్రమే ఏర్పడే అడ్డంకులు కావని తెలుస్తోంది. ఈ ఆలస్యం తరచుగా పేరుకుపోయి, చివరికి పరిష్కరించబడుతుంది.
తరువాత, ఏ అంశాలు ఈ రద్దీకి కారణమవుతున్నాయో మనం నిర్ధారించుకోవాలి. NAT లోని వందలాది iptables నియమాలలో ఒకటి కారణం కావచ్చునా? లేదా నెట్వర్క్లో IPIP టన్నెలింగ్కు సంబంధించిన ఏవైనా సమస్యలా? దీన్ని తనిఖీ చేయడానికి ఒక మార్గం, సిస్టమ్లోని ప్రతి దశను తొలగించడం. మనం NAT మరియు ఫైర్వాల్ లాజిక్ను తీసివేసి, కేవలం IPIP భాగాన్ని మాత్రమే ఉంచితే ఏమవుతుంది?
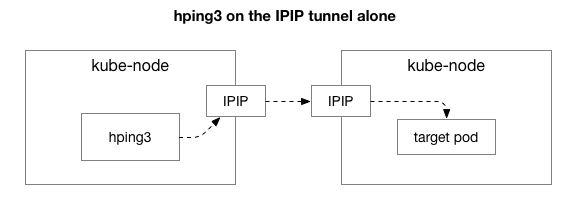
అదృష్టవశాత్తూ, Linux మెషిన్ అదే నెట్వర్క్లో ఉన్నట్లయితే, IP ఓవర్లే లేయర్ను నేరుగా సులభంగా యాక్సెస్ చేయడానికి ఇది మిమ్మల్ని అనుమతిస్తుంది:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms
ఫలితాలను బట్టి చూస్తే, సమస్య ఇంకా కొనసాగుతూనే ఉంది! దీనివల్ల iptables మరియు NAT కారణం కాదని తేలింది. అయితే, సమస్య TCP లో ఉందా? ఒక సాధారణ ICMP పింగ్ ఎలా పనిచేస్తుందో చూద్దాం:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
ఫలితాలు సమస్య ఇంకా కొనసాగుతోందని చూపిస్తున్నాయి. బహుశా అది IPIP టన్నెల్ వల్ల కావచ్చు? పరీక్షను మరింత సులభతరం చేద్దాం:
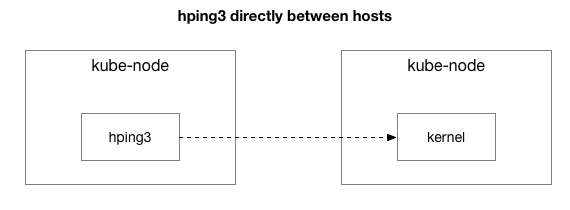
ఈ రెండు హోస్ట్ల మధ్య అన్ని ప్యాకెట్లు పంపబడతాయా?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
మేము ఈ పరిస్థితిని రెండు కుబెర్నెటెస్ నోడ్లు ఒకదానికొకటి ఏ ప్యాకెట్నైనా, ICMP పింగ్ను కూడా పంపుకునేలా సరళీకరించాము. లక్ష్య హోస్ట్ "సరిగ్గా లేకపోతే" (కొన్నింటి కంటే మరికొన్ని అధ్వాన్నంగా ఉంటే) అవి ఇప్పటికీ లేటెన్సీని గమనిస్తాయి.
ఇప్పుడు చివరి ప్రశ్న: ఈ ఆలస్యం కేవలం క్యూబ్-నోడ్ సర్వర్లలో మాత్రమే ఎందుకు జరుగుతుంది? మరియు ఇది క్యూబ్-నోడ్ పంపేటప్పుడు జరుగుతుందా లేక స్వీకరించేటప్పుడు జరుగుతుందా? అదృష్టవశాత్తూ, కుబెర్నెటీస్ వెలుపల ఉన్న ఒక హోస్ట్ నుండి, అదే "తెలిసిన చెడ్డ" రిసీవర్తో ఒక ప్యాకెట్ను పంపడం ద్వారా దీనిని కూడా చాలా సులభంగా కనుక్కోవచ్చు. మనం చూడగలిగినట్లుగా, సమస్య కొనసాగుతూనే ఉంది:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms
ఆ తర్వాత, మునుపటి సోర్స్ క్యూబ్-నోడ్ నుండి బాహ్య హోస్ట్కు అదే అభ్యర్థనలను అమలు చేస్తాము (ఇది సోర్స్ హోస్ట్ను మినహాయిస్తుంది, ఎందుకంటే పింగ్లో RX మరియు TX భాగాలు రెండూ ఉంటాయి):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
ఆలస్యంతో కూడిన ప్యాకెట్ క్యాప్చర్లను పరిశీలించడం ద్వారా, మేము కొంత అదనపు సమాచారాన్ని పొందాము. ప్రత్యేకంగా, పంపేవారు (దిగువన) ఈ టైమ్అవుట్ను చూస్తారని, కానీ స్వీకరించేవారు (పైన) చూడరని మేము తెలుసుకున్నాము—డెల్టా కాలమ్ను (సెకన్లలో) చూడండి:
ఇంకా, స్వీకరించే చివరన TCP మరియు ICMP ప్యాకెట్ల క్రమంలోని వ్యత్యాసాన్ని (సీక్వెన్స్ నంబర్ల ఆధారంగా) మనం పరిశీలిస్తే, ICMP ప్యాకెట్లు ఎల్లప్పుడూ పంపిన క్రమంలోనే, కానీ వేర్వేరు సమయాలతో వస్తాయని మనం గమనిస్తాము. అదే సమయంలో, TCP ప్యాకెట్లు కొన్నిసార్లు ఒకదానితో ఒకటి కలగలిసిపోతాయి, మరియు కొన్ని నిలిచిపోతాయి. ప్రత్యేకించి, మనం SYN ప్యాకెట్ల పోర్టులను పరిశీలిస్తే, అవి పంపే చివరన క్రమంలో ఉన్నాయని, కానీ స్వీకరించే చివరన అలా లేవని మనం గమనిస్తాము.
విధానంలో ఒక సూక్ష్మమైన తేడా ఉంది ఆధునిక సర్వర్లు (మన డేటా సెంటర్లోని వాటిలాంటివి) TCP లేదా ICMP ఉన్న ప్యాకెట్లను ప్రాసెస్ చేస్తాయి. ఒక ప్యాకెట్ వచ్చినప్పుడు, నెట్వర్క్ అడాప్టర్ దానిని "కనెక్షన్ వారీగా హ్యాష్ చేస్తుంది," అంటే అది కనెక్షన్లను క్యూలుగా విభజించి, ప్రతి క్యూను ఒక ప్రత్యేక ప్రాసెసర్ కోర్కు పంపడానికి ప్రయత్నిస్తుంది. TCP విషయంలో, ఈ హ్యాష్లో సోర్స్ మరియు డెస్టినేషన్ IP అడ్రస్లు మరియు పోర్ట్లు రెండూ ఉంటాయి. మరో మాటలో చెప్పాలంటే, ప్రతి కనెక్షన్ (బహుశా) వేర్వేరుగా హ్యాష్ చేయబడుతుంది. ICMP విషయంలో, పోర్ట్లు ఉండవు కాబట్టి, కేవలం IP అడ్రస్లు మాత్రమే హ్యాష్ చేయబడతాయి.
మరొక కొత్త పరిశీలన: ఈ కాలంలో, రెండు హోస్ట్ల మధ్య జరిగే అన్ని కమ్యూనికేషన్లలో ICMP ఆలస్యాలు కనిపిస్తున్నాయి, అయితే TCPలో కనిపించడం లేదు. దీనిని బట్టి, దీనికి కారణం బహుశా RX క్యూ హ్యాషింగ్కు సంబంధించినది అని తెలుస్తోంది: ఈ రద్దీ దాదాపు ఖచ్చితంగా ప్రతిస్పందనలను పంపడంలో కాకుండా, RX ప్యాకెట్ ప్రాసెసింగ్లోనే ఏర్పడుతోంది.
దీంతో, సాధ్యమయ్యే కారణాల జాబితా నుండి ప్యాకెట్ పంపడం తొలగిపోతుంది. ప్యాకెట్ ప్రాసెసింగ్ సమస్య కొన్ని క్యూబ్-నోడ్ సర్వర్ల స్వీకరించే వైపున ఉందని ఇప్పుడు మనకు తెలుసు.
కెర్నల్లో ప్యాకెట్ ప్రాసెసింగ్ను అర్థం చేసుకోవడం Linux
కొన్ని క్యూబ్-నోడ్ సర్వర్లలో రిసీవర్లో ఈ సమస్య ఎందుకు వస్తుందో అర్థం చేసుకోవడానికి, కెర్నల్ ఎలా పనిచేస్తుందో చూద్దాం. Linux ప్యాకెట్లను ప్రాసెస్ చేస్తుంది.
అత్యంత సరళమైన సాంప్రదాయ అమలు పద్ధతికి తిరిగి వెళితే, నెట్వర్క్ కార్డ్ ప్యాకెట్ను స్వీకరించి దానిని పంపుతుంది. ప్రధాన భాగం Linuxప్రాసెస్ చేయాల్సిన ప్యాకెట్ ఒకటి ఉందని తెలియగానే, కెర్నల్ ఇతర పనులను ఆపివేసి, కాంటెక్స్ట్ను ఇంటరప్ట్ హ్యాండ్లర్కు మార్చి, ప్యాకెట్ను ప్రాసెస్ చేసి, ఆపై ప్రస్తుత టాస్క్కు తిరిగి వస్తుంది.
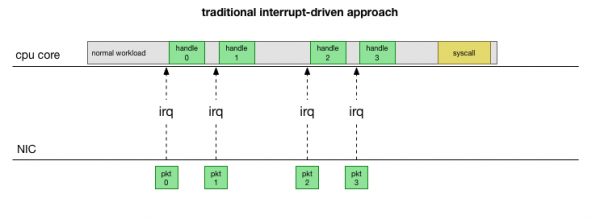
ఈ కాంటెక్స్ట్ స్విచ్చింగ్ నెమ్మదిగా ఉంటుంది: 90లలోని 10Mbps NICలపై ఈ లేటెన్సీ అంతగా గమనించలేకపోయి ఉండవచ్చు, కానీ నేటి 10G కార్డ్లపై, సెకనుకు 15 మిలియన్ ప్యాకెట్ల గరిష్ట థ్రూపుట్తో, ఒక చిన్న ఎనిమిది-కోర్ సర్వర్లోని ప్రతి కోర్ సెకనుకు మిలియన్ల సార్లు అంతరాయానికి గురికావచ్చు.
అంతరాయాలను నిరంతరం నిర్వహించవలసిన అవసరాన్ని నివారించడానికి, చాలా సంవత్సరాల క్రితం Linux జోడించారు అధిక వేగాల వద్ద పనితీరును మెరుగుపరచడానికి అన్ని ఆధునిక డ్రైవర్లు ఉపయోగించే నెట్వర్క్ API. తక్కువ వేగాల వద్ద, కెర్నల్ ఇప్పటికీ పాత పద్ధతిలో నెట్వర్క్ కార్డ్ నుండి ఇంటరప్ట్లను అందుకుంటుంది. థ్రెషోల్డ్ను మించిపోయేంత సంఖ్యలో ప్యాకెట్లు వచ్చిన తర్వాత, కెర్నల్ ఇంటరప్ట్లను నిలిపివేసి, దానికి బదులుగా నెట్వర్క్ అడాప్టర్ను పోల్ చేయడం మరియు ప్యాకెట్లను భాగాలుగా స్వీకరించడం ప్రారంభిస్తుంది. ప్రాసెసింగ్ సాఫ్ట్ఇర్క్లలో, అనగా, నిర్వహించబడుతుంది. సిస్టమ్ కాల్స్ మరియు హార్డ్వేర్ ఇంటరప్ట్ల తర్వాత, యూజర్ స్పేస్కు బదులుగా కెర్నల్ ఇప్పటికే నడుస్తున్నప్పుడు.
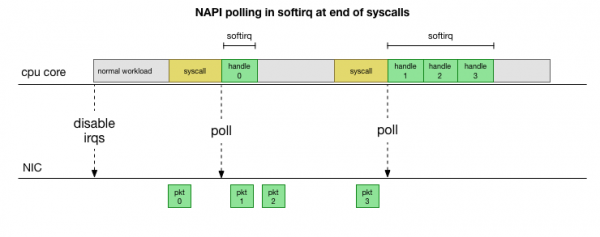
ఇది చాలా వేగవంతమైనది, కానీ ఇది మరొక సమస్యను సృష్టిస్తుంది. ప్యాకెట్లు చాలా ఎక్కువగా ఉంటే, సమయమంతా నెట్వర్క్ కార్డ్ నుండి వచ్చే ప్యాకెట్లను ప్రాసెస్ చేయడానికే సరిపోతుంది, మరియు యూజర్-స్పేస్ ప్రాసెస్లకు ఈ క్యూలను వాస్తవంగా ఖాళీ చేయడానికి (TCP కనెక్షన్ల నుండి చదవడం మొదలైనవి) సమయం ఉండదు. చివరికి, క్యూలు నిండిపోతాయి, మరియు మనం ప్యాకెట్లను వదిలివేయడం ప్రారంభిస్తాము. ఒక సమతుల్యతను కనుగొనే ప్రయత్నంలో, కెర్నల్ సాఫ్ట్ఇర్క్ కాంటెక్స్ట్లో ప్రాసెస్ చేయగల గరిష్ట ప్యాకెట్ల సంఖ్యకు ఒక బడ్జెట్ను నిర్దేశిస్తుంది. ఈ బడ్జెట్ దాటినప్పుడు, ఒక ప్రత్యేక థ్రెడ్ మేల్కొంటుంది. ksoftirqd మీరు వాటిలో ఒకదాన్ని చూస్తారు ps (ప్రతి కోర్కు) ఇది సాధారణ సిస్కాల్/ఇంటరప్ట్ మార్గానికి వెలుపల ఈ సాఫ్ట్ఇర్క్లను నిర్వహిస్తుంది. ఈ థ్రెడ్ ప్రామాణిక ప్రాసెస్ షెడ్యూలర్ను ఉపయోగించి షెడ్యూల్ చేయబడుతుంది, ఇది వనరులను సమానంగా పంపిణీ చేయడానికి ప్రయత్నిస్తుంది.
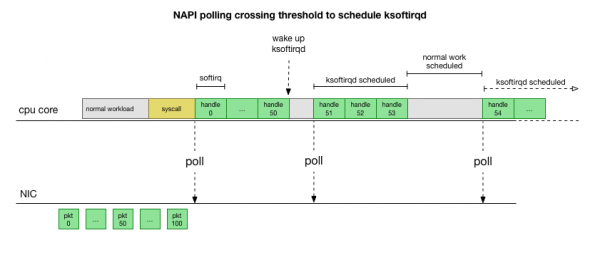
కెర్నల్ ప్యాకెట్లను ఎలా ప్రాసెస్ చేస్తుందో పరిశీలించడం ద్వారా, రద్దీకి కొంత అవకాశం ఉందని మనం చూడవచ్చు. సాఫ్ట్ఇర్క్లు తక్కువ తరచుగా స్వీకరించబడితే, ప్యాకెట్లు ప్రాసెస్ చేయబడటానికి నెట్వర్క్ కార్డ్లోని RX క్యూలో కొంత సమయం వేచి ఉండవలసి ఉంటుంది. ఒక టాస్క్ ప్రాసెసర్ కోర్ను నిరోధించడం వల్ల గానీ, లేదా మరేదైనా కారణం వల్ల కెర్నల్ సాఫ్ట్ఇర్క్లను అమలు చేయలేకపోవడం వల్ల గానీ ఇది జరగవచ్చు.
ప్రాసెసింగ్ను ఒక ప్రధాన అంశానికి లేదా పద్ధతికి పరిమితం చేయడం
సాఫ్ట్ఇర్క్ ఆలస్యాలు ప్రస్తుతానికి కేవలం ఒక ఊహ మాత్రమే. కానీ అది సహేతుకంగానే ఉంది, మరియు మనం కూడా దాదాపు ఇలాంటిదే చూస్తున్నామని మనకు తెలుసు. కాబట్టి తదుపరి దశ ఈ సిద్ధాంతాన్ని నిర్ధారించడం. ఒకవేళ అది నిర్ధారించబడితే, అప్పుడు ఈ ఆలస్యాలకు కారణాన్ని కనుక్కోవాలి.
మన నెమ్మదైన ప్యాకెట్ల విషయానికి తిరిగి వద్దాం:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
ముందుగా చర్చించినట్లుగా, ఈ ICMP ప్యాకెట్లు ఒకే NIC RX క్యూలోకి హ్యాష్ చేయబడి, ఒకే CPU కోర్ ద్వారా ప్రాసెస్ చేయబడతాయి. మనం ఆపరేషన్ను అర్థం చేసుకోవాలనుకుంటే Linuxప్రక్రియను గుర్తించడానికి, ఈ ప్యాకెట్లు ఎక్కడ (ఏ CPU కోర్పై) మరియు ఎలా (softirq, ksoftirqd) ప్రాసెస్ చేయబడుతున్నాయో తెలుసుకోవడం ఉపయోగకరంగా ఉంటుంది.
ఇప్పుడు కెర్నల్ పనితీరును నిజ సమయంలో పర్యవేక్షించడానికి వీలు కల్పించే సాధనాలను ఉపయోగించాల్సిన సమయం వచ్చింది. Linuxఇక్కడ మేము ఉపయోగించాము ఈ టూల్కిట్, ఏకపక్ష కెర్నల్ ఫంక్షన్లను మరియు బఫర్ ఈవెంట్లను ఒక యూజర్-స్పేస్ పైథాన్ ప్రోగ్రామ్కు అనుసంధానించే చిన్న C ప్రోగ్రామ్లను వ్రాయడానికి మిమ్మల్ని అనుమతిస్తుంది, ఆ ప్రోగ్రామ్ వాటిని ప్రాసెస్ చేసి ఫలితాన్ని తిరిగి ఇస్తుంది. ఏకపక్ష కెర్నల్ ఫంక్షన్లను అనుసంధానించడం సంక్లిష్టమైనప్పటికీ, ఈ యుటిలిటీ గరిష్ట భద్రత కోసం రూపొందించబడింది మరియు టెస్టింగ్ లేదా డెవలప్మెంట్ వాతావరణంలో పునరావృతం చేయడం కష్టంగా ఉండే ప్రొడక్షన్ సమస్యలను ట్రాక్ చేయడానికి ఉద్దేశించబడింది.
ఇక్కడ ప్రణాళిక చాలా సులభం: ఈ ICMP పింగ్లను కెర్నల్ నిర్వహిస్తుందని మనకు తెలుసు, కాబట్టి మనం ఒక కెర్నల్ ఫంక్షన్లోకి ప్రవేశిస్తాము. ఇది ఇన్కమింగ్ ICMP "ఎకో రిక్వెస్ట్" ప్యాకెట్ను స్వీకరించి, ICMP "ఎకో రెస్పాన్స్" పంపడాన్ని ప్రారంభిస్తుంది. పెరుగుతున్న icmp_seq సంఖ్య ద్వారా మనం ప్యాకెట్ను గుర్తించవచ్చు, ఇది చూపిస్తుంది hping3 పైన.
కోడ్ ఇది సంక్లిష్టంగా కనిపిస్తుంది, కానీ కనిపించినంత భయానకమైనది కాదు. పనితీరు icmp_echo తెలియచేస్తుంది struct sk_buff *skbఇది ఒక ఎకో రిక్వెస్ట్ ప్యాకెట్. మనం దీనిని ట్రేస్ చేసి సీక్వెన్స్ను సంగ్రహించవచ్చు. echo.sequence (దీనిని పోల్చారు icmp_seq hping3 నుండి выше), మరియు దానిని యూజర్ స్పేస్కు పంపండి. ప్రస్తుత ప్రాసెస్ పేరు/IDని సంగ్రహించడం కూడా సౌకర్యవంతంగా ఉంటుంది. కెర్నల్ ప్యాకెట్ ప్రాసెసింగ్ సమయంలో మనం నేరుగా చూసే ఫలితాలు క్రింద ఉన్నాయి:
TGID PID ప్రాసెస్ పేరు ICMP_SEQ 0 0 swapper/11 770 0 0 swapper/11 771 0 0 swapper/11 772 0 0 swapper/11 773 0 0 swapper/11 774 20041 20086 prometheus 775 0 0 swapper/11 776 0 0 swapper/11 777 0 0 swapper/11 778 4512 4542 spokes-report-s 779
ఇక్కడ సందర్భంలో గమనించవలసిన విషయం ఏమిటంటే softirq సిస్టమ్ కాల్స్ చేసిన ప్రాసెస్లు "ప్రాసెస్లు"గా కనిపిస్తాయి, అయినప్పటికీ వాస్తవానికి కెర్నల్ కాంటెక్స్ట్లో ప్యాకెట్లను సురక్షితంగా నిర్వహించేది కెర్నల్.
ఈ సాధనంతో మనం జాప్యాన్ని చూపించే నిర్దిష్ట ప్యాకెట్లతో నిర్దిష్ట ప్రక్రియలను అనుబంధించవచ్చు. hping3దీన్ని సరళంగా చేద్దాం grep కొన్ని విలువల కోసం ఈ సంగ్రహణపై icmp_seqపైన పేర్కొన్న icmp_seq విలువలతో సరిపోలిన ప్యాకెట్లు, వాటి RTT లతో పాటుగా గుర్తించబడ్డాయి, వీటిని మేము పైన గమనించాము (50 ms కంటే తక్కువ RTT విలువలు ఉన్నందున మేము ఫిల్టర్ చేసిన ప్యాకెట్ల యొక్క ఆశించిన RTT విలువలు బ్రాకెట్లలో ఉన్నాయి):
TGID PID ప్రక్రియ పేరు ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 1953 ** 94/ms 76 76 76 76 ksoftirqd/11 1955 ** 79ms 76 76 ksoftirqd/11 1956 ** 69ms 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 (76 76 ksoftirqd/11 1956 ksoftirqd/11 1959 ** (39ms) 76 76 ksoftirqd/11 1960 ** (29ms) 76 76 ksoftirqd/11 1961 ** (19ms) 76 76 ksoftirqd/11 1962 ** (9ms) -- 10137 10436 cadvisor 2068 10130 cadvisor 796 626 60 ksoftirqd/11 2070 ** 75ms 76 76 ksoftirqd/11 2071 ** 65ms 76 76 ksoftirqd/11 2072 ** 55ms 76 76 ksoftirqd/11 2073 ksoft ** (45ms 2074** (35ms) 76 76 ksoftirqd/11 2075 ** (25ms) 76 76 ksoftirqd/11 2076 ** (15ms) 76 76 ksoftirqd/11 2077 ** (5ms)
ఫలితాలు మనకు అనేక విషయాలు తెలియజేస్తున్నాయి. మొదటిది, ఈ ప్యాకేజీలన్నీ కాంటెక్స్ట్ను నిర్వహిస్తాయి. ksoftirqd/11దీని అర్థం ఏమిటంటే, ఈ నిర్దిష్ట జత మెషీన్ల కోసం, స్వీకరించే చివరన ఉన్న కోర్ 11 వద్ద ICMP ప్యాకెట్లు హ్యాష్ చేయబడ్డాయి. అలాగే, ప్రతి కంజెషన్ పాయింట్ వద్ద, ఒక సిస్టమ్ కాల్ సందర్భంలో ప్యాకెట్లు ప్రాసెస్ చేయబడుతున్నాయని కూడా మనం గమనిస్తాము. cadvisor. అప్పుడు ksoftirqd పనిని చేపట్టి, పేరుకుపోయిన క్యూను ప్రాసెస్ చేస్తుంది: తర్వాత పేరుకుపోయిన ప్యాకెట్ల సంఖ్యకు సరిగ్గా సమానంగా cadvisor.
దీనికి ముందు వెంటనే ఎల్లప్పుడూ పని చేస్తుంది అనే వాస్తవం cadvisor, సమస్యలో అతని ప్రమేయాన్ని సూచిస్తుంది. విడ్డూరంగా, ఉద్దేశ్యం ఈ పనితీరు సమస్యను కలిగించడానికి బదులుగా, "నడుస్తున్న కంటైనర్ల వనరుల వినియోగం మరియు పనితీరు లక్షణాలను విశ్లేషించడం".
కంటైనర్ ఆపరేషన్లోని ఇతర అంశాల మాదిరిగానే, ఇదంతా చాలా అధునాతనమైన టూలింగ్, మరియు కొన్ని ఊహించని పరిస్థితులలో పనితీరు సమస్యలు తలెత్తే అవకాశం పూర్తిగా ఉంది.
ప్యాకెట్ క్యూను నెమ్మదింపజేసేలా క్యాడ్వైజర్ ఏమి చేస్తోంది?
క్రాష్ ఎలా జరుగుతుంది, ఏ ప్రాసెస్ దానికి కారణమవుతోంది మరియు ఏ CPUలో జరుగుతోంది అనే విషయాలపై ఇప్పుడు మనకు చాలా మంచి అవగాహన ఉంది. హార్డ్ లాక్ కారణంగా, కెర్నల్ Linux సమయానికి ప్రణాళిక వేసుకోవడానికి సమయం లేదు ksoftirqdమరియు ప్యాకెట్లు సందర్భానుసారంగా ప్రాసెస్ చేయబడతాయని మనం చూస్తాము. cadvisorఅలా భావించడం తార్కికం cadvisor నెమ్మదిగా ఉండే ఒక సిస్టమ్ కాల్ను ప్రారంభిస్తుంది, ఆ తర్వాత అప్పటికి పోగుపడిన ప్యాకెట్లన్నీ ప్రాసెస్ చేయబడతాయి:
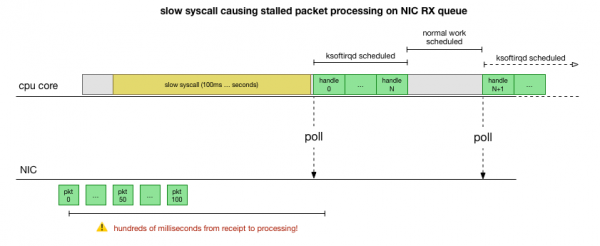
అది సిద్ధాంతం, కానీ మనం దానిని ఎలా పరీక్షించగలం? మనం చేయగలిగేది ఏమిటంటే, ఈ ప్రక్రియ అంతటా CPU కోర్ యొక్క కార్యాచరణను పర్యవేక్షించడం, ప్యాకెట్ బడ్జెట్ ఎక్కడ మించిపోయి ksoftirqd పిలవబడుతుందో ఆ పాయింట్ను కనుగొనడం, ఆపై ఆ క్షణానికి కొంచెం ముందు CPU కోర్లో సరిగ్గా ఏమి నడుస్తోందో చూడటం. ఇది ప్రతి కొన్ని మిల్లీసెకన్లకు CPUకి ఎక్స్-రే తీయడం లాంటిది. అది ఈ విధంగా కనిపిస్తుంది:
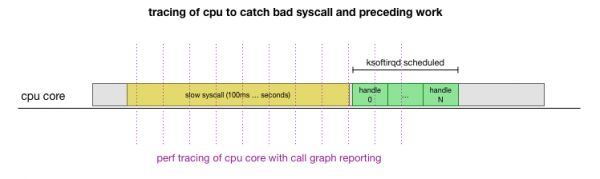
ఇప్పటికే ఉన్న సాధనాలతో ఇదంతా చేయగలగడం సౌకర్యంగా ఉంది. ఉదాహరణకు, నిర్దిష్ట ఫ్రీక్వెన్సీ వద్ద ఇచ్చిన CPU కోర్ను తనిఖీ చేస్తుంది మరియు యూజర్ స్పేస్ మరియు కెర్నల్ రెండింటినీ కలుపుకొని, నడుస్తున్న సిస్టమ్ యొక్క కాల్ గ్రాఫ్ను రూపొందించగలదు. Linuxమీరు ఈ రికార్డును తీసుకొని, ప్రోగ్రామ్ యొక్క చిన్న ఫోర్క్ను ఉపయోగించి దానిని ప్రాసెస్ చేయవచ్చు. స్టాక్ ట్రేస్ క్రమాన్ని కాపాడే బ్రెండన్ గ్రెగ్ పరిష్కారం, ప్రతి 1 మిల్లీసెకనుకు ఒకే-లైన్ స్టాక్ ట్రేస్లను సేవ్ చేయడానికి, ఆపై ట్రేస్ ముగియడానికి 100 మిల్లీసెకన్ల ముందు ఒక నమూనాను సంగ్రహించి సేవ్ చేయడానికి మనకు వీలు కల్పిస్తుంది. ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
ఫలితాలు ఇక్కడ ఉన్నాయి:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
ఇక్కడ చాలా విషయాలు జరుగుతున్నాయి, కానీ ముఖ్యమైన విషయం ఏమిటంటే, మనం ఇంతకు ముందు ICMP ట్రేసర్లో చూసిన "cadvisor before ksoftirqd" నమూనా మనకు కనిపిస్తుంది. దీని అర్థం ఏమిటి?
ప్రతి లైన్ ఒక నిర్దిష్ట సమయంలోని CPU ట్రేస్. ఒక లైన్లోని స్టాక్లో ప్రతి కాల్ సెమికోలన్తో వేరు చేయబడింది. లైన్ల మధ్యలో, సిస్టమ్ కాల్ (syscall) పిలవబడటాన్ని మనం చూడవచ్చు: read(): .... ;do_syscall_64;sys_read; ...అందువల్ల, క్యాడ్వైజర్ సిస్టమ్ కాల్పై చాలా సమయం వెచ్చిస్తుంది. read(), విధులకు సంబంధించినది mem_cgroup_* (కాల్ స్టాక్ పైభాగం/లైన్ చివర).
కాల్ ట్రేస్లో సరిగ్గా ఏమి చదవబడుతుందో చూడటం సౌకర్యవంతంగా లేదు, కాబట్టి మనం రన్ చేద్దాం strace మరియు క్యాడ్వైజర్ ఏమి చేస్తుందో చూద్దాం మరియు 100 ms కంటే ఎక్కువ నిడివి ఉన్న సిస్టమ్ కాల్స్ను కనుగొందాం:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
ఊహించినట్లుగానే, ఇక్కడ కాల్స్ నెమ్మదిగా జరగడాన్ని మనం చూస్తాము. read()రీడ్ ఆపరేషన్లు మరియు కాంటెక్స్ట్ యొక్క కంటెంట్ల నుండి mem_cgroup ఈ సవాళ్లు స్పష్టంగా ఉన్నాయి read() ఫైల్కు సంబంధించి memory.statఇది మెమరీ వినియోగం మరియు cgroup పరిమితులను (డాకర్లోని ఒక రిసోర్స్ ఐసోలేషన్ టెక్నాలజీ) చూపిస్తుంది. కంటైనర్ల కోసం రిసోర్స్ వినియోగ సమాచారాన్ని పొందడానికి క్యాడ్వైజర్ టూల్ ఈ ఫైల్ను క్వెరీ చేస్తుంది. కెర్నల్ లేదా క్యాడ్వైజర్ ఏదైనా ఊహించని విధంగా చేస్తోందా అని తనిఖీ చేద్దాం:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
నిజమైన 0మీ0.153సె
వినియోగదారు 0మీ0.000సె
సిస్ 0మీ0.152సె
theojulienne@kube-node-bad ~ $
ఇప్పుడు మనం బగ్ను పునరుత్పత్తి చేసి, కెర్నల్ను అర్థం చేసుకోగలం. Linux వ్యాధిని ఎదుర్కొంటుంది.
రీడ్ ఆపరేషన్ ఎందుకు ఇంత నెమ్మదిగా ఉంది?
ఈ దశలో, ఇలాంటి సమస్యలనే నివేదిస్తున్న ఇతర వినియోగదారులను కనుగొనడం చాలా సులభం. ఈ బగ్ క్యాడ్వైజర్ ఇష్యూ ట్రాకర్లో ఈ విధంగా నివేదించబడినట్లు తేలింది. నెట్వర్క్ స్టాక్లో కూడా ఆ జాప్యం యాదృచ్ఛికంగా ప్రతిబింబిస్తోందని ఎవరూ గమనించలేదు. క్యాడ్వైజర్ ఊహించిన దానికంటే ఎక్కువ CPU సమయాన్ని వినియోగిస్తోందన్నది నిజమే, కానీ మా సర్వర్లకు చాలా CPU వనరులు ఉన్నందున దాని గురించి పెద్దగా ఆలోచించలేదు, కాబట్టి ఆ సమస్యను క్షుణ్ణంగా పరిశోధించలేదు.
సమస్య ఏమిటంటే, కంట్రోల్ గ్రూపులు (cgroups) ఒక నేమ్స్పేస్ (కంటైనర్) లోపల మెమరీ వినియోగాన్ని నిర్దేశిస్తాయి. ఒక cgroup లోని అన్ని ప్రాసెస్లు ముగిసినప్పుడు, డాకర్ ఆ మెమరీ cgroup ను ఖాళీ చేస్తుంది. అయితే, ఈ "మెమరీ" కేవలం ప్రాసెస్ మెమరీ మాత్రమే కాదు. ప్రాసెస్ మెమరీ స్వయంగా ఇకపై వాడుకలో లేనప్పటికీ, కెర్నల్ డెంట్రీలు మరియు ఐనోడ్ల (డైరెక్టరీ మరియు ఫైల్ మెటాడేటా) వంటి కాష్ చేయబడిన కంటెంట్ను కూడా కేటాయిస్తుంది, ఇవి ఆ మెమరీ cgroup లో కాష్ చేయబడతాయి. సమస్య వివరణ నుండి:
జోంబీ cgroups: వీటిలో ఎటువంటి ప్రాసెస్లు లేకుండా తొలగించబడిన కంట్రోల్ గ్రూపులు, కానీ వీటికి ఇంకా మెమరీ కేటాయించబడి ఉంటుంది (నా విషయంలో, డెంట్రీ కాష్ నుండి, కానీ ఇది పేజ్ కాష్ లేదా tmpfs నుండి కూడా కేటాయించబడవచ్చు).
cgroupను విడుదల చేసేటప్పుడు కెర్నల్ కాష్ చేయబడిన అన్ని పేజీలను తిరిగి తనిఖీ చేయడం చాలా నెమ్మదిగా ఉంటుంది, కాబట్టి ఒక నిదానమైన ప్రక్రియ ఎంచుకోబడుతుంది: ఈ పేజీలు మళ్లీ అభ్యర్థించబడే వరకు వేచి ఉండి, ఆపై, మెమరీ నిజంగా అవసరమైనప్పుడు, చివరకు cgroupను విడుదల చేస్తుంది. ఈ సమయం వరకు, cgroup ఇప్పటికీ గణాంకాల సేకరణలో చేర్చబడి ఉంటుంది.
పనితీరు పరంగా, వారు పనితీరు కోసం మెమరీని త్యాగం చేశారు: కొంత కాష్డ్ మెమరీని వదిలివేయడం ద్వారా ప్రారంభ క్లీనప్ను వేగవంతం చేశారు. ఇది సాధారణం. కెర్నల్ కాష్డ్ మెమరీని చివరిగా ఉపయోగించినప్పుడు, cgroup చివరికి శుభ్రపరచబడుతుంది, కాబట్టి దీనిని "లీక్" అని పిలవలేము. దురదృష్టవశాత్తు, సెర్చ్ మెకానిజం యొక్క నిర్దిష్ట అమలు memory.stat ఈ కెర్నల్ వెర్షన్ (4.9)లో, మా సర్వర్లలో ఉన్న భారీ మెమరీ కారణంగా, తాజా కాష్ డేటాను పునరుద్ధరించడానికి మరియు జాంబీ cgroupsను శుభ్రపరచడానికి చాలా ఎక్కువ సమయం పడుతుంది.
మా కొన్ని నోడ్లలో cgroup జాంబీలు చాలా ఎక్కువగా ఉండటం వల్ల, రీడ్ మరియు లేటెన్సీ ఒక సెకనుకు మించిపోతున్నాయని తేలింది.
క్యాడ్వైజర్ సమస్యకు ఒక తాత్కాలిక పరిష్కారం ఏమిటంటే, సిస్టమ్ వ్యాప్తంగా డెంట్రీస్/ఐనోడ్స్ కాష్లను వెంటనే విడుదల చేయడం. కాష్ను క్లియర్ చేయడంలో కాష్ చేయబడిన జాంబీ సిగ్రూప్ పేజీలు కూడా ఉంటాయి కాబట్టి, ఇది హోస్ట్పై రీడ్ లేటెన్సీతో పాటు నెట్వర్క్ లేటెన్సీని కూడా తక్షణమే తొలగిస్తుంది. ఇది ఒక పరిష్కారం కాదు, కానీ ఇది సమస్య యొక్క కారణాన్ని నిర్ధారిస్తుంది.
కొత్త కెర్నల్ వెర్షన్లలో (4.19+) కాల్ పనితీరు మెరుగుపరచబడిందని తేలింది. memory.statకాబట్టి, ఈ కెర్నల్కు మారడంతో సమస్య పరిష్కారమైంది. అదే సమయంలో, కుబెర్నెటెస్ క్లస్టర్లలో సమస్యాత్మక నోడ్లను గుర్తించడానికి, వాటిని సజావుగా ఖాళీ చేయడానికి మరియు రీబూట్ చేయడానికి మా వద్ద సాధనాలు ఉన్నాయి. మేము అన్ని క్లస్టర్లను క్షుణ్ణంగా పరిశీలించి, తగినంత అధిక లేటెన్సీ ఉన్న నోడ్లను కనుగొని, వాటిని రీబూట్ చేశాము. దీనివల్ల మిగిలిన సర్వర్లలో OSను అప్గ్రేడ్ చేయడానికి మాకు సమయం దొరికింది.
సంగ్రహించేందుకు
ఈ బగ్ NIC RX క్యూ ప్రాసెసింగ్ను వందల మిల్లీసెకన్ల పాటు నిలిపివేయడం వల్ల, ఇది చిన్న కనెక్షన్లపై అధిక లేటెన్సీకి మరియు MySQL క్వెరీలు మరియు రెస్పాన్స్ ప్యాకెట్ల మధ్య వంటి కనెక్షన్ మధ్యలో లేటెన్సీకి కారణమైంది.
కుబెర్నెటెస్ వంటి ప్రాథమిక వ్యవస్థల పనితీరును అర్థం చేసుకోవడం మరియు నిర్వహించడం అనేది, వాటిపై నడిచే అన్ని సేవల విశ్వసనీయతకు మరియు వేగానికి కీలకం. కుబెర్నెటెస్ పనితీరులో చేసే మెరుగుదలలు దానిపై నడిచే అన్ని వ్యవస్థలకు ప్రయోజనం చేకూరుస్తాయి.
మూలం: www.habr.com
