

అనే పరిస్థితులు ఉన్నాయి ప్రాథమిక కీ లేని పట్టికకు లేదా కొన్ని ఇతర ప్రత్యేక సూచిక, పర్యవేక్షణ కారణంగా, ఇప్పటికే ఉన్న రికార్డుల పూర్తి క్లోన్లు చేర్చబడ్డాయి.

ఉదాహరణకు, కాలక్రమ మెట్రిక్ యొక్క విలువలు కాపీ స్ట్రీమ్ని ఉపయోగించి PostgreSQLలో వ్రాయబడతాయి, ఆపై ఆకస్మిక వైఫల్యం ఉంది మరియు పూర్తిగా ఒకే రకమైన డేటాలో కొంత భాగం మళ్లీ వస్తుంది.
అనవసరమైన క్లోన్ల డేటాబేస్ను ఎలా తొలగించాలి?
పికె సహాయకుడు కానప్పుడు
అటువంటి పరిస్థితిని మొదటి స్థానంలో జరగకుండా నిరోధించడం సులభమయిన మార్గం. ఉదాహరణకు, రోల్ ప్రైమరీ కీ. కానీ నిల్వ చేయబడిన డేటా వాల్యూమ్ను పెంచకుండా ఇది ఎల్లప్పుడూ సాధ్యం కాదు.
ఉదాహరణకు, డేటాబేస్లోని ఫీల్డ్ యొక్క ఖచ్చితత్వం కంటే సోర్స్ సిస్టమ్ యొక్క ఖచ్చితత్వం ఎక్కువగా ఉంటే:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
నీవు గమనించావా? 00:00:02కి బదులుగా కౌంట్డౌన్ డేటాబేస్లో ఒక సెకను ముందు ts తో రికార్డ్ చేయబడింది, కానీ అప్లికేషన్ కోణం నుండి చాలా చెల్లుబాటు అయ్యేది (అన్ని తరువాత, డేటా విలువలు భిన్నంగా ఉంటాయి!).
వాస్తవానికి మీరు దీన్ని చేయగలరు PK(మెట్రిక్, ts) - అయితే చెల్లుబాటు అయ్యే డేటా కోసం మేము చొప్పించే వైరుధ్యాలను పొందుతాము.
చేయవచ్చు PK(మెట్రిక్, ts, డేటా) - కానీ ఇది దాని వాల్యూమ్ను బాగా పెంచుతుంది, దానిని మేము ఉపయోగించము.
అందువల్ల, సాధారణ నాన్-యూనిక్ ఇండెక్స్ తయారు చేయడం చాలా సరైన ఎంపిక (మెట్రిక్, ts) మరియు సమస్యలు తలెత్తితే వాస్తవం తర్వాత వాటిని పరిష్కరించండి.
"క్లోనిక్ యుద్ధం ప్రారంభమైంది"
ఒక రకమైన ప్రమాదం జరిగింది, మరియు ఇప్పుడు మేము టేబుల్ నుండి క్లోన్ రికార్డులను నాశనం చేయాలి.

అసలు డేటాను మోడల్ చేద్దాం:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;ఇక్కడ మా చేయి మూడుసార్లు వణికింది, Ctrl+V ఇరుక్కుపోయింది, ఇప్పుడు...
మొదట, మన పట్టిక చాలా పెద్దదిగా ఉంటుందని అర్థం చేసుకుందాం, కాబట్టి మేము అన్ని క్లోన్లను కనుగొన్న తర్వాత, తొలగించడానికి అక్షరాలా “మన వేలిని పొడుచుకోవడం” మంచిది. నిర్దిష్ట రికార్డులను తిరిగి శోధించకుండా.
మరియు అటువంటి మార్గం ఉంది - ఇది , నిర్దిష్ట రికార్డు యొక్క భౌతిక ఐడెంటిఫైయర్.
అంటే, ముందుగా, మేము పట్టిక వరుస యొక్క పూర్తి కంటెంట్ సందర్భంలో రికార్డుల ctidని సేకరించాలి. సరళమైన ఎంపిక మొత్తం పంక్తిని వచనంలోకి ప్రసారం చేయడం:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
వేయకుండా ఉండవచ్చా?సూత్రప్రాయంగా, ఇది చాలా సందర్భాలలో సాధ్యమే. మీరు ఈ పట్టికలోని ఫీల్డ్లను ఉపయోగించడం ప్రారంభించే వరకు సమానత్వ ఆపరేటర్ లేని రకాలు:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
అవును, శ్రేణిలో ఒకటి కంటే ఎక్కువ ఎంట్రీలు ఉంటే, ఇవన్నీ క్లోన్లు అని మేము వెంటనే చూస్తాము. వాటిని వదిలేద్దాం:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)పొట్టిగా రాయాలనుకునే వారికిమీరు దీన్ని ఇలా కూడా వ్రాయవచ్చు:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;సీరియలైజ్ చేయబడిన స్ట్రింగ్ యొక్క విలువ మాకు ఆసక్తికరంగా లేనందున, మేము దానిని సబ్క్వెరీ యొక్క తిరిగి వచ్చిన నిలువు వరుసల నుండి విసిరివేసాము.
చేయడానికి ఇంకా కొంచెం మిగిలి ఉంది - మేము అందుకున్న సెట్ని ఉపయోగించి తొలగించండి:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);మనల్ని మనం తనిఖీ చేసుకుందాం:
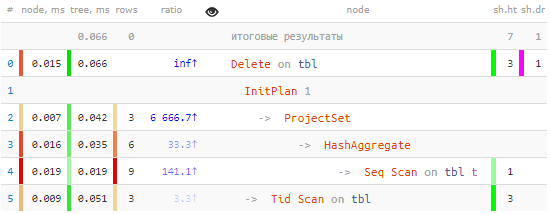
అవును, ప్రతిదీ సరైనది: మొత్తం పట్టికలోని ఏకైక Seq స్కాన్ కోసం మా 3 రికార్డ్లు ఎంపిక చేయబడ్డాయి మరియు డేటా కోసం శోధించడానికి తొలగించు నోడ్ ఉపయోగించబడింది టిడ్ స్కాన్తో సింగిల్ పాస్:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))మీరు చాలా రికార్డులను క్లియర్ చేసినట్లయితే, .
పెద్ద పట్టిక మరియు ఎక్కువ సంఖ్యలో నకిలీలతో తనిఖీ చేద్దాం:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
కాబట్టి, పద్ధతి విజయవంతంగా పనిచేస్తుంది, అయితే ఇది కొన్ని జాగ్రత్తలతో ఉపయోగించాలి. ఎందుకంటే తొలగించబడిన ప్రతి రికార్డ్కు, టిడ్ స్కాన్లో చదవబడిన డేటా పేజీ ఒకటి మరియు డిలీట్లో ఒకటి ఉంటుంది.
మూలం: www.habr.com
