

في هذه المقالة ، سنتحدث عن التبعيات الوظيفية في قواعد البيانات - ما هي ، وأين يتم استخدامها ، وما هي الخوارزميات الموجودة للعثور عليها.
سننظر في التبعيات الوظيفية في سياق قواعد البيانات العلائقية. يتحدث بشكل تقريبي ، في قواعد البيانات هذه ، يتم تخزين المعلومات في شكل جداول. بعد ذلك ، نستخدم مفاهيم تقريبية غير قابلة للتبديل في النظرية العلائقية الصارمة: الجدول نفسه سيطلق عليه علاقة ، الأعمدة ستسمى سمات (مجموعتها عبارة عن مخطط علاقة) ، ومجموعة قيم الصف في مجموعة فرعية من السمات سيطلق عليها tuple.
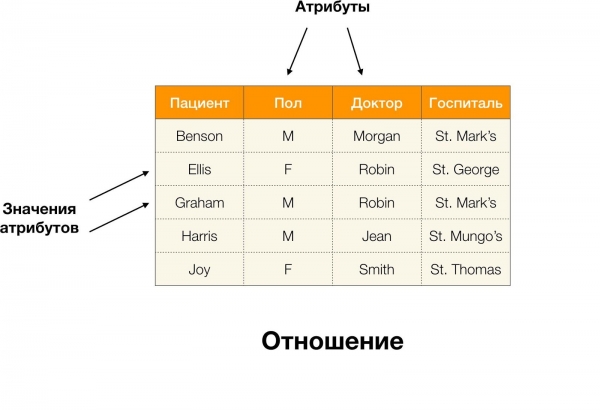
على سبيل المثال ، في الجدول أعلاه ، (بنسون ، إم ، مورغان) عبارة عن مجموعة حسب السمات (المريض ، بول ، دكتور).
بشكل أكثر رسمية ، هذا مكتوب على النحو التالي:  [المريض ، بول ، دكتور] = (بنسون ، إم ، مورغان).
[المريض ، بول ، دكتور] = (بنسون ، إم ، مورغان).
الآن يمكننا تقديم مفهوم الاعتماد الوظيفي (FC):
التعريف 1. العلاقة R تفي بـ FD X → Y (حيث X ، Y R) إذا وفقط إذا كانت لأي مجموعات  ,
,  ∈ R مقتنع: إذا
∈ R مقتنع: إذا  [x] =
[x] =  [X] ، إذن
[X] ، إذن  [ص] =
[ص] =  [ص]. في مثل هذه الحالة ، يُقال إن X (المجموعة المحددة أو المحددة للسمات) تحدد وظيفيًا Y (المجموعة التابعة).
[ص]. في مثل هذه الحالة ، يُقال إن X (المجموعة المحددة أو المحددة للسمات) تحدد وظيفيًا Y (المجموعة التابعة).
بعبارة أخرى ، وجود قانون اتحادي X → ص يعني أنه إذا كان لدينا مجموعتان في R وتتطابق في السمات X، ثم سيتطابقون أيضًا حسب السمات Y.
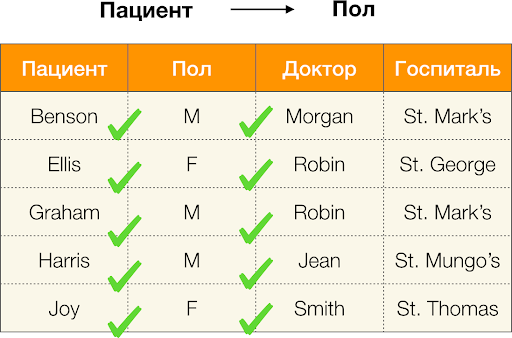
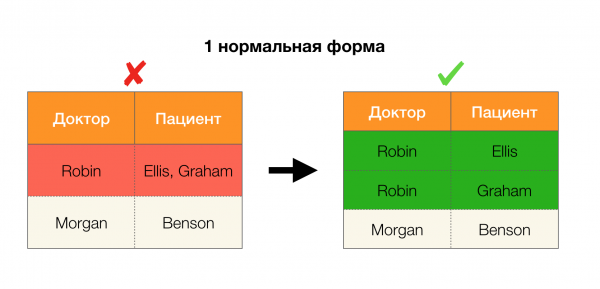
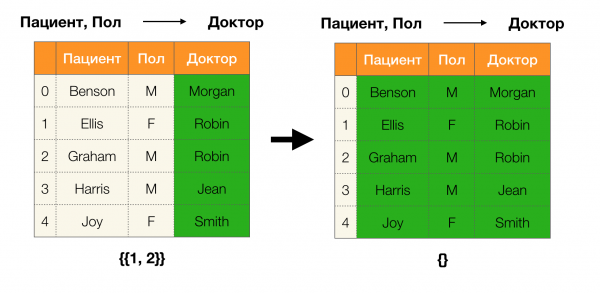
والآن بالترتيب. ضع في اعتبارك السمات المريض и بول التي نريد أن نعرف ما إذا كانت هناك تبعيات بينهما أم لا. لهذه المجموعة من السمات ، قد توجد التبعيات التالية:
- المريض → الجنس
- الجنس → المريض
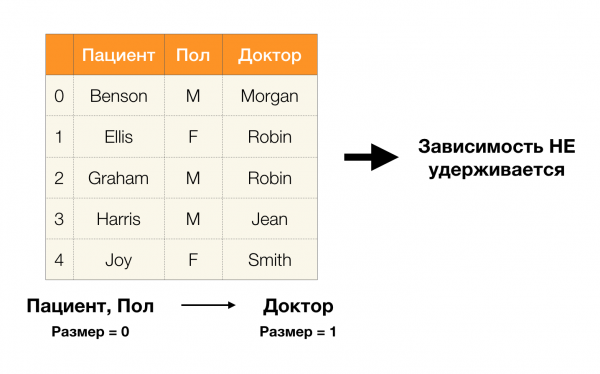
وفقًا للتعريف أعلاه ، من أجل الاحتفاظ بالاعتماد الأول ، كل قيمة فريدة للعمود المريض يجب أن تتطابق قيمة عمود واحدة فقط بول. وهذا صحيح بالنسبة لجدول المثال. ومع ذلك ، هذا لا يعمل في الاتجاه المعاكس ، أي أن التبعية الثانية لم تتحقق ، والسمة بول ليس محددًا ل مريض. وبالمثل ، إذا أخذنا الاعتماد طبيب → مريض، يمكنك أن ترى أنه انتهك ، منذ القيمة روبن لهذه السمة عدة قيم مختلفة - إليس وجراهام.
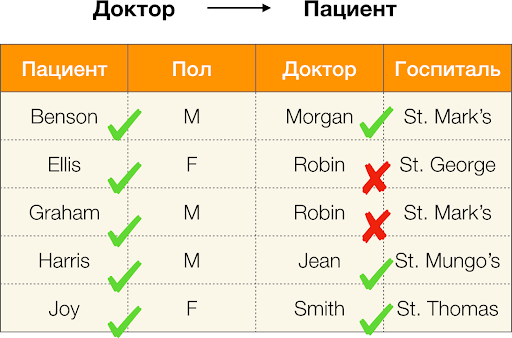
وبالتالي ، تسمح لك التبعيات الوظيفية بتحديد العلاقات الحالية بين مجموعات سمات الجدول. من هنا فصاعدًا ، سننظر في الروابط الأكثر إثارة للاهتمام ، أو بالأحرى ، مثل X → صما هم:
- غير تافهة ، أي أن الجانب الأيمن من الاعتماد ليس مجموعة فرعية من اليسار (ص ⊆ X);
- الحد الأدنى ، أي أنه لا يوجد مثل هذا الاعتماد ض → صأن ض ⊂ س.
كانت التبعيات التي تم النظر فيها حتى هذه النقطة صارمة ، أي أنها لم توفر أي انتهاكات على الجدول ، ولكن بالإضافة إلى ذلك ، هناك أيضًا تلك التي تسمح ببعض التناقض بين قيم المجموعات. يتم أخذ هذه التبعيات في فئة منفصلة ، تسمى التقريبية ، ويسمح بانتهاكها على عدد معين من المجموعات. يتم تعديل هذا الرقم من خلال emax مؤشر الخطأ الأقصى. على سبيل المثال ، معدل الخطأ  = 0.01 قد تعني أنه قد يتم انتهاك التبعية بنسبة 1٪ من المجموعات المتاحة على مجموعة السمات المعتبرة. وهذا يعني أنه بالنسبة لـ 1000 سجل ، يمكن لعدد 10 مجموعات كحد أقصى انتهاك القانون الفيدرالي. سننظر في مقياس مختلف قليلاً بناءً على القيم الزوجية المختلفة للمجموعات المقارنة. للإدمان X → ص فيما يتعلق r تحسب مثل هذا:
= 0.01 قد تعني أنه قد يتم انتهاك التبعية بنسبة 1٪ من المجموعات المتاحة على مجموعة السمات المعتبرة. وهذا يعني أنه بالنسبة لـ 1000 سجل ، يمكن لعدد 10 مجموعات كحد أقصى انتهاك القانون الفيدرالي. سننظر في مقياس مختلف قليلاً بناءً على القيم الزوجية المختلفة للمجموعات المقارنة. للإدمان X → ص فيما يتعلق r تحسب مثل هذا:

دعنا نحسب الخطأ ل طبيب → مريض من المثال أعلاه. لدينا مجموعتان تختلف قيمهما في السمة المريض، ولكن تتزامن مع طبيب:  [دكتور ، مريض] = (روبن ، إليس) و
[دكتور ، مريض] = (روبن ، إليس) و  [دكتور ، مريض] = (روبن ، جراهام). بعد تعريف الخطأ ، يجب أن نأخذ في الاعتبار جميع الأزواج المتضاربة ، مما يعني أنه سيكون هناك اثنان منهم:
[دكتور ، مريض] = (روبن ، جراهام). بعد تعريف الخطأ ، يجب أن نأخذ في الاعتبار جميع الأزواج المتضاربة ، مما يعني أنه سيكون هناك اثنان منهم: ,
,  ) ومعكوسه (
) ومعكوسه ( ,
,  ). استبدل الصيغة واحصل على:
). استبدل الصيغة واحصل على:

والآن دعونا نحاول الإجابة على السؤال: "لماذا كل هذا؟". في الواقع ، المنطقة الحرة مختلفة. النوع الأول هو تلك التبعيات التي حددها المسؤول في مرحلة تصميم قاعدة البيانات. عادة ما تكون قليلة ، فهي صارمة ، والتطبيق الرئيسي هو تسوية البيانات وتصميم مخطط العلاقة.
النوع الثاني هو التبعيات التي تمثل البيانات "المخفية" والعلاقات غير المعروفة سابقًا بين السمات. أي أنه لم يتم التفكير في مثل هذه التبعيات في وقت التصميم وتم العثور عليها بالفعل لمجموعة البيانات الحالية ، بحيث يمكن استخلاص أي استنتاجات حول المعلومات المخزنة لاحقًا بناءً على مجموعة FDs المحددة. مع هذه التبعيات نعمل. إنهم يشاركون في مجال كامل من التنقيب عن البيانات باستخدام تقنيات وخوارزميات بحث متنوعة مبنية على أساسهم. لنكتشف كيف يمكن أن تكون التبعيات الوظيفية الموجودة (الدقيقة أو التقريبية) في أي بيانات مفيدة.

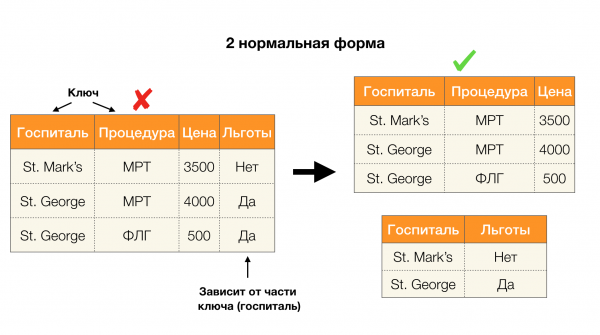
اليوم ، من بين المجالات الرئيسية لتطبيق التبعيات ، يتم تمييز تنظيف البيانات. وهو ينطوي على تطوير عمليات لتحديد "البيانات القذرة" ومن ثم تصحيحها. ممثلو "البيانات القذرة" المتميزون هم التكرارات وأخطاء البيانات أو الأخطاء المطبعية والقيم المفقودة والبيانات القديمة والمسافات الزائدة وما شابه.
مثال على خطأ البيانات:
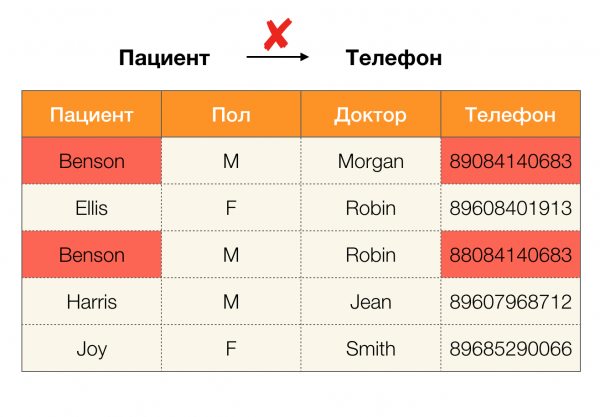
مثال على التكرارات في البيانات:
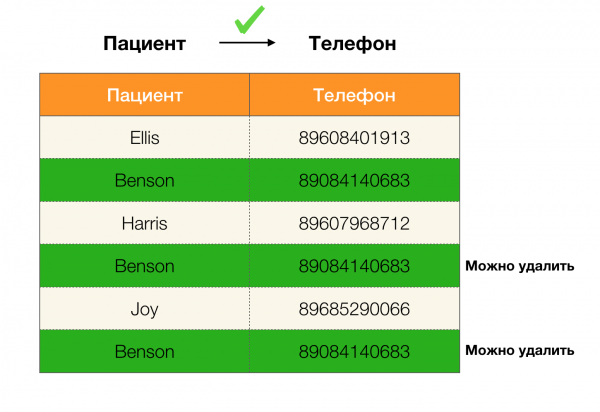
على سبيل المثال ، لدينا جدول ومجموعة من القوانين الفيدرالية التي يجب الوفاء بها. يتضمن تنظيف البيانات في هذه الحالة تغيير البيانات بطريقة تجعل القوانين الفيدرالية صحيحة. في الوقت نفسه ، يجب أن يكون عدد التعديلات ضئيلاً (هناك خوارزميات لهذا الإجراء ، والتي لن نركز عليها في هذه المقالة). يوجد أدناه مثال على تحويل البيانات هذا. على اليسار توجد العلاقة الأولية ، والتي من الواضح أنها لم تتحقق FLs الضرورية (مثال على انتهاك أحد FLs تم تمييزه باللون الأحمر). على اليمين العلاقة المحدثة ، مع إظهار الخلايا الخضراء القيم المتغيرة. بعد تنفيذ مثل هذا الإجراء ، بدأ الحفاظ على التبعيات اللازمة.
مجال التطبيق الشائع الآخر هو تصميم قاعدة البيانات. هنا يجدر التذكير بالأشكال العادية والتطبيع. التطبيع هو عملية جعل العلاقة متوافقة مع مجموعة معينة من المتطلبات ، كل منها محدد بالشكل العادي بطريقته الخاصة. لن نصف متطلبات الأشكال العادية المختلفة (يتم ذلك في أي كتاب عن دورة قاعدة البيانات للمبتدئين) ، لكن نلاحظ فقط أن كل منها يستخدم مفهوم التبعيات الوظيفية بطريقته الخاصة. بعد كل شيء ، فإن FDs هي قيود تكامل بطبيعتها تؤخذ في الاعتبار عند تصميم قاعدة بيانات (في سياق هذه المهمة ، تسمى FDs أحيانًا بالمفاتيح الفائقة).
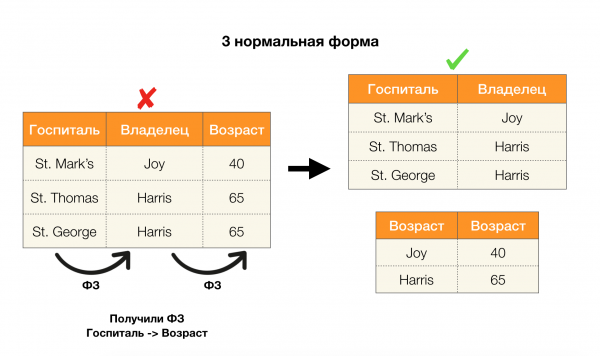
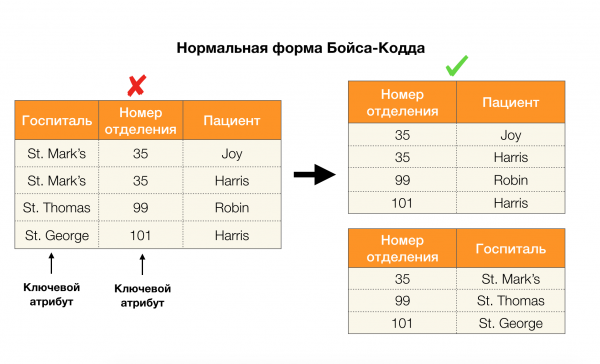
ضع في اعتبارك طلبهم للأشكال الأربعة العادية الموضحة في الصورة أدناه. تذكر أن نموذج Boyce-Codd العادي أكثر صرامة من النموذج الثالث ، ولكنه أقل صرامة من النموذج الرابع. نحن لا نعتبر الأخير حتى الآن ، لأن صياغته تتطلب فهم التبعيات متعددة القيم ، والتي لا تهمنا في هذه المقالة.
هناك مجال آخر وجدت فيه التبعيات طريقها وهو تقليل أبعاد مساحة الميزة في مشاكل مثل بناء مصنف بايز ساذج ، واستخراج ميزات مهمة ، وإعادة ضبط نموذج الانحدار. في المقالات الأصلية ، تسمى هذه المشكلة تحديد الميزات الزائدة (التكرار في الميزات) وذات الصلة (ملاءمة الميزة) [5 ، 6] ، ويتم حلها بالاستخدام النشط لمفاهيم قواعد البيانات. مع ظهور مثل هذه الأعمال ، يمكننا القول أن هناك طلبًا اليوم على الحلول التي تسمح بدمج قاعدة البيانات والتحليلات وتنفيذ مشاكل التحسين المذكورة أعلاه في أداة واحدة [7 ، 8 ، 9].
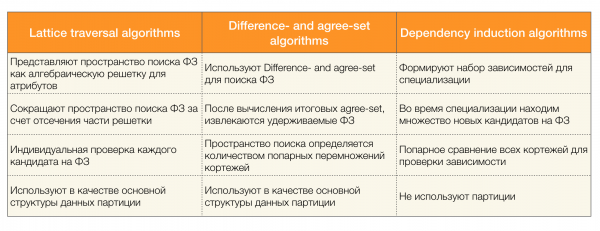
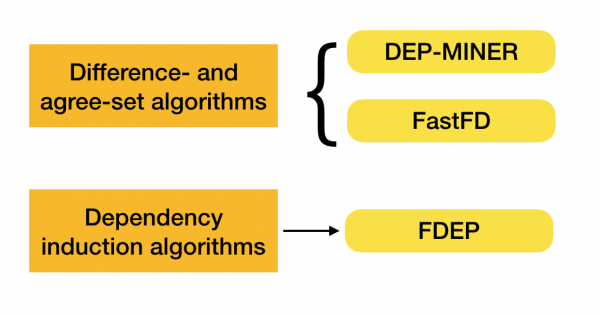
يوجد العديد من الخوارزميات (حديثة وغير حديثة جدًا) للبحث عن FD في مجموعة بيانات ويمكن تقسيم هذه الخوارزميات إلى ثلاث مجموعات:
- خوارزميات اجتياز شعرية
- الخوارزميات القائمة على البحث عن قيم متسقة (خوارزميات الاختلاف والموافقة)
- خوارزميات مبنية على مقارنات زوجية (خوارزميات تحريض التبعية)
ويرد وصف موجز لكل نوع من أنواع الخوارزمية في الجدول أدناه:
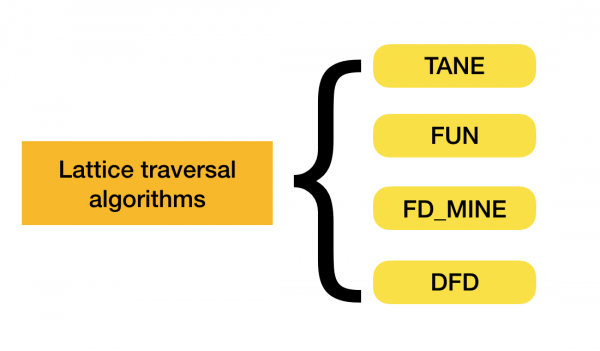
يمكن العثور على مزيد من التفاصيل حول هذا التصنيف في [4]. فيما يلي أمثلة على الخوارزميات لكل نوع:
حاليًا ، تظهر خوارزميات جديدة تجمع بين عدة طرق لإيجاد التبعيات الوظيفية في وقت واحد. ومن أمثلة هذه الخوارزميات Pyro [2] و HyFD [3]. من المتوقع تحليل عملهم في المقالات التالية من هذه السلسلة. في هذه المقالة ، سنقوم فقط بتحليل المفاهيم الأساسية و lemma الضرورية لفهم تقنيات تحديد التبعيات.
لنبدأ بمجموعة بسيطة - مجموعة الاختلاف والاتفاق ، المستخدمة في النوع الثاني من الخوارزميات. مجموعة الاختلافات هي مجموعة من المجموعات التي لا تتطابق في القيمة ، والمجموعة المتفق عليها ، على العكس من ذلك ، هي مجموعات تتطابق في القيمة. وتجدر الإشارة إلى أننا في هذه الحالة ننظر فقط إلى الجانب الأيسر من الاعتماد.
أيضا من المفاهيم الهامة التي تمت مواجهتها أعلاه هي الشبكة الجبرية. نظرًا لأن العديد من الخوارزميات الحديثة تعمل على هذا المفهوم ، نحتاج إلى تكوين فكرة عن ماهيته.
من أجل تقديم مفهوم الشبكة ، من الضروري تحديد مجموعة مرتبة جزئيًا (أو مجموعة مرتبة جزئيًا ، أو مجموعة موجزة للاختصار).
التعريف 2. يُقال إن المجموعة S مرتبة جزئيًا بواسطة علاقة ثنائية ⩽ إذا كانت الخصائص التالية تنطبق على أي أ ، ب ، ج ∈ S:
- الانعكاسية ، أي أ أ
- عدم التناظر ، أي إذا أ ب و ب أ ، أ = ب
- الانتقال ، أي بالنسبة لـ a b و b c ، يتبع ذلك a ⩽ c
تسمى هذه العلاقة علاقة الترتيب الجزئي (غير الصارم) ، وتسمى المجموعة نفسها مجموعة مرتبة جزئيًا. تدوين رسمي: ⟨S، ⩽⟩.
كأبسط مثال على مجموعة مرتبة جزئيًا ، يمكننا أن نأخذ مجموعة جميع الأعداد الطبيعية N مع علاقة الترتيب المعتادة ⩽. من السهل التحقق من استيفاء جميع البديهيات الضرورية.
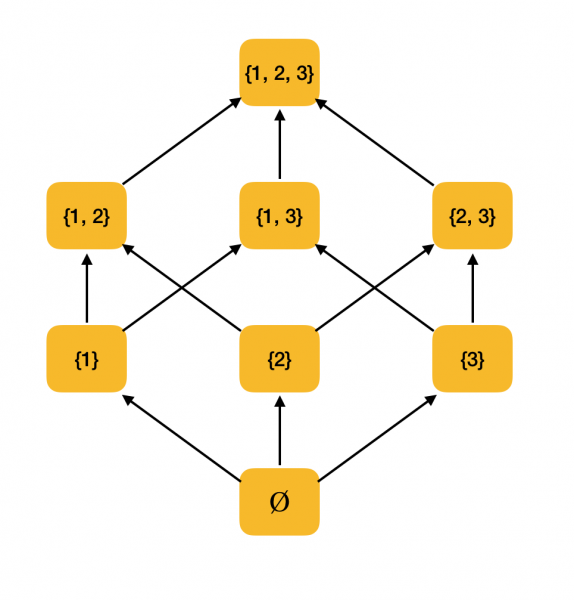
مثال أكثر وضوحا. ضع في اعتبارك مجموعة كل المجموعات الفرعية {1، 2، 3} مرتبة حسب علاقة التضمين ⊆. في الواقع ، تفي هذه العلاقة بجميع شروط الترتيب الجزئي ، لذا فإن ⟨P ({1، 2، 3})، هي مجموعة مرتبة جزئيًا. يوضح الشكل أدناه بنية هذه المجموعة: إذا كان من الممكن السير على طول الأسهم إلى عنصر آخر من عنصر ، فعندئذ تكون في علاقة ترتيب.
نحتاج إلى تعريفين أكثر بساطة من مجال الرياضيات - supremum (supremum) و infimum (infimum).
التعريف 3. لنفترض أن ⟨S، يكون موجبًا ، A ⊆ S. الحد الأعلى لـ A هو عنصر u ∈ S بحيث يكون ∀x ∈ S: x ⩽ u. لنفترض أن U هي مجموعة جميع الحدود العليا لـ S. إذا كانت U تحتوي على أصغر عنصر ، فيُطلق عليها اسم supremum ويُشار إليها باسم sup A.
يتم تقديم فكرة الحد الأدنى الدقيق بالمثل.
التعريف 4. لنفترض أن ⟨S، يكون موجبًا ، A ⊆ S. الحد الأدنى من A هو عنصر l ∈ S بحيث يكون ∀x ∈ S: l ⩽ x. لنفترض أن L هي مجموعة جميع الحدود السفلية لـ S. إذا كان هناك أكبر عنصر في L ، فيُطلق عليه اسم infimum ويُشار إليه على أنه inf A.
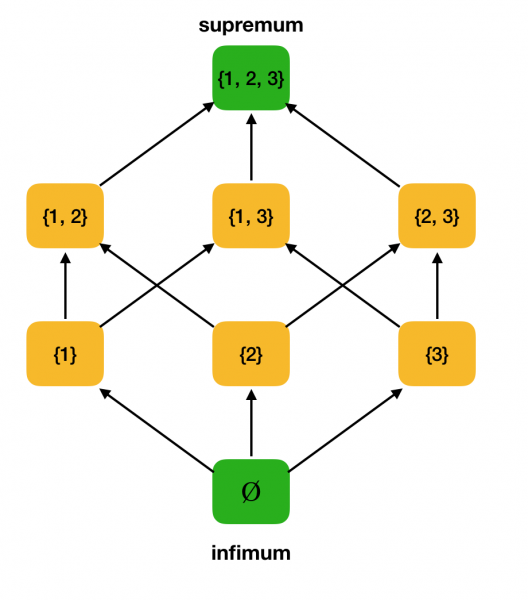
كمثال ، ضع في اعتبارك المجموعة المذكورة أعلاه مرتبة جزئيًا ⟨P ({1، 2، 3}) ، ⊆⟩ وابحث عن supremum و infimum فيها:
يمكننا الآن صياغة تعريف الشبكة الجبرية.
التعريف 5. لنفترض أن P ، يكون وضعًا بحيث يكون لكل مجموعة جزئية مكونة من عنصرين حدود علوية وسفلية حادة. ثم يسمى P بالشبكة الجبرية. في هذه الحالة ، تتم كتابة sup {x، y} بالصيغة x ∨ y و inf {x، y} بالشكل x ∧ y.
دعنا نتحقق من أن مثالنا العملي ⟨P ({1، 2، 3}) ⊆⟩ عبارة عن شبكة. في الواقع ، بالنسبة لأي a ، b ∈ P ({1، 2، 3}) ، a∨b = a∪b و a∧b = a∩b. على سبيل المثال ، ضع في اعتبارك المجموعات {1، 2} و {1، 3} وابحث عن infimum و supremum الخاص بهم. إذا تقاطعنا معهم ، نحصل على المجموعة {1} ، والتي ستكون الحد الأدنى. يتم الحصول على السيادة من قبل اتحادهم - {1، 2، 3}.
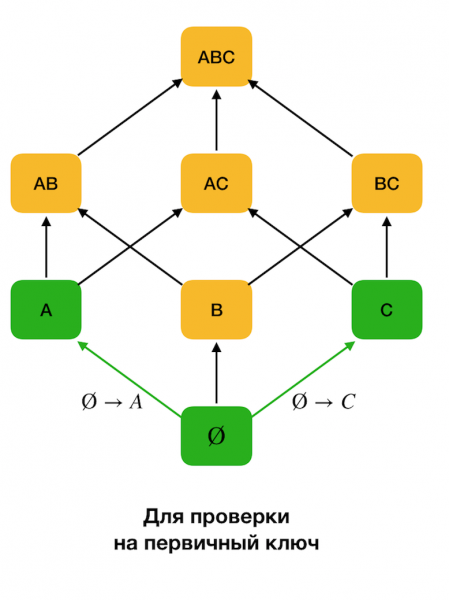
في خوارزميات اكتشاف FD ، غالبًا ما يتم تمثيل مساحة البحث في شكل شبكة ، حيث تمثل مجموعات من عنصر واحد (اقرأ المستوى الأول من شبكة البحث ، حيث يتكون الجانب الأيسر من التبعيات من سمة واحدة) كل سمة من سمات العلاقة الأصلية.
في البداية ، تبعيات النموذج ∅ → سمة واحدة. تتيح لك هذه الخطوة تحديد السمات التي تعتبر مفاتيح أساسية (لا توجد محددات لهذه السمات ، وبالتالي يكون الجانب الأيسر فارغًا). علاوة على ذلك ، تتحرك هذه الخوارزميات لأعلى في الشبكة. في الوقت نفسه ، تجدر الإشارة إلى أنه لا يمكن تجاوز الشبكة بالكامل ، أي إذا تم تمرير الحجم الأقصى المطلوب للجانب الأيسر إلى الإدخال ، فلن تتجاوز الخوارزمية المستوى بهذا الحجم.
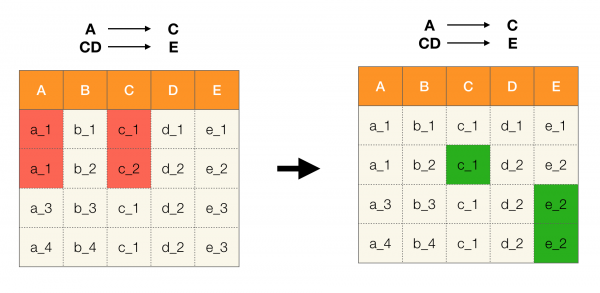
يوضح الشكل أدناه كيف يمكنك استخدام الشبكة الجبرية في مشكلة البحث عن FD. هنا كل حافة (X ، XY) يمثل التبعية X → ص. على سبيل المثال ، لقد اجتزنا المستوى الأول ونعلم أن التبعية محتفظ بها أ → ب (سنعرض هذا بوصلة خضراء بين الرؤوس A и B). علاوة على ذلك ، عندما نتحرك لأعلى في الشبكة ، لا يمكننا التحقق من التبعية أ ، ج → ب، لأنه لم يعد بالحد الأدنى. وبالمثل ، لن نتحقق من ذلك إذا تم الاحتفاظ بالتبعية ج → ب.
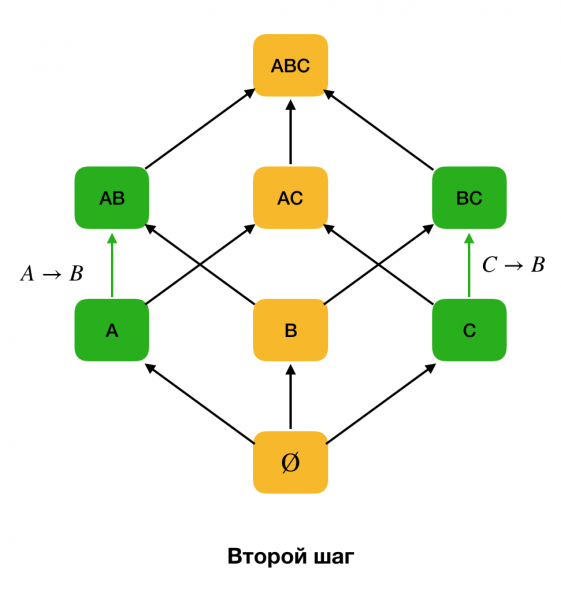
بالإضافة إلى ذلك ، وكقاعدة عامة ، تستخدم جميع الخوارزميات الحديثة للبحث عن FDs بنية بيانات كقسم (في القسم الأصلي - القسم المجرد [1]). التعريف الرسمي للقسم هو كما يلي:
التعريف 6. دع X ⊆ R مجموعة من السمات للعلاقة r. العنقود هو مجموعة من مؤشرات الصفوف من r التي لها نفس القيمة لـ X ، أي c (t) = {i | ti [X] = t [X]}. القسم عبارة عن مجموعة من الكتل ، باستثناء مجموعات من طول الوحدة:

بعبارات بسيطة ، قسم للسمة X هي مجموعة من القوائم ، حيث تحتوي كل قائمة على أرقام أسطر بنفس قيم X. في الأدب الحديث ، يُطلق على الهيكل الذي يمثل الأقسام اسم فهرس قائمة الموضع (PLI). يتم استبعاد المجموعات ذات الطول الفردي لأغراض ضغط PLI لأنها مجموعات تحتوي فقط على رقم سجل ذي قيمة فريدة سيكون من السهل دائمًا تعيينها.
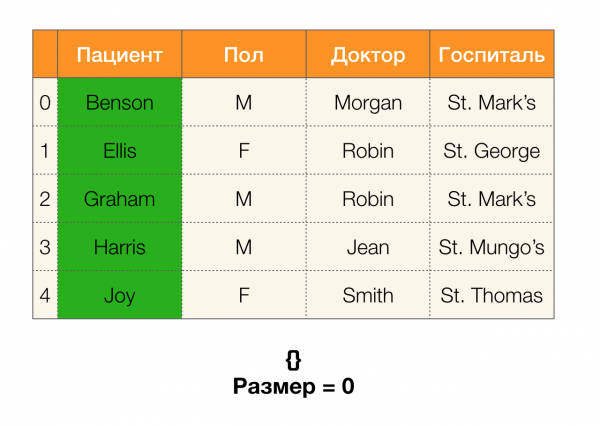
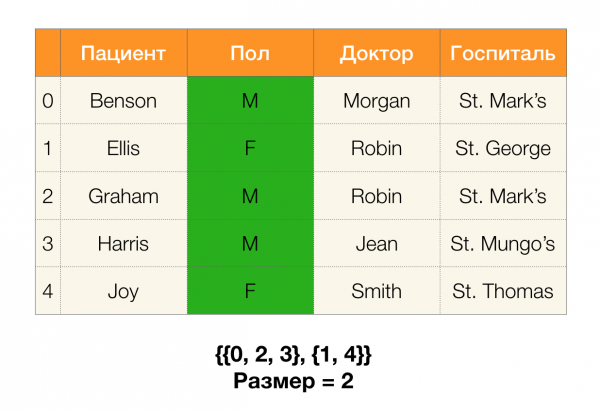
تأمل في مثال. دعنا نعود إلى نفس الجدول مع المرضى ونبني أقسامًا للأعمدة المريض и بول (ظهر عمود جديد على اليسار ، حيث تم وضع علامة على أرقام صفوف الجدول):
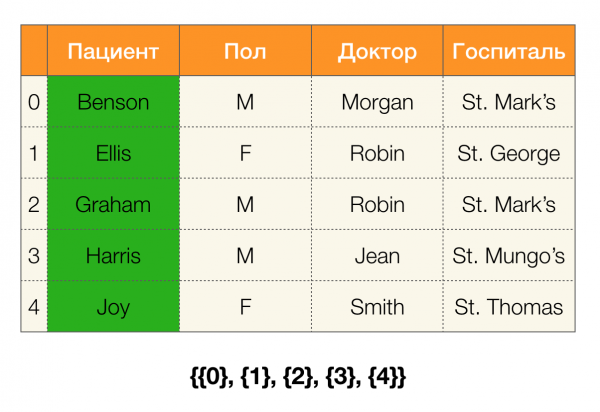
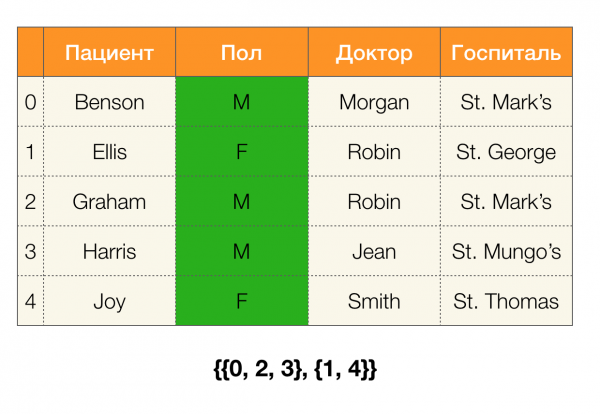
في هذه الحالة ، وفقًا للتعريف ، قسم العمود المريض سيكون فارغًا بالفعل ، حيث يتم استبعاد المجموعات الفردية من القسم.
يمكن الحصول على الأقسام بعدة سمات. ولهذا ، هناك طريقتان: من خلال السير في الجدول ، قم ببناء قسم دفعة واحدة بكل السمات الضرورية ، أو قم ببنائه باستخدام عملية عبور الأقسام بواسطة مجموعة فرعية من السمات. تستخدم خوارزميات البحث FD الخيار الثاني.
بكلمات بسيطة ، على سبيل المثال ، للحصول على قسم حسب الأعمدة ايه بي سي، يمكنك أن تأخذ أقسامًا لـ AC и B (أو أي مجموعة أخرى من المجموعات الفرعية المنفصلة) وتقاطعها مع بعضها البعض. عملية عبور قسمين تحدد المجموعات ذات الطول الأكبر المشتركة لكلا القسمين.
لنلقي نظرة على مثال:
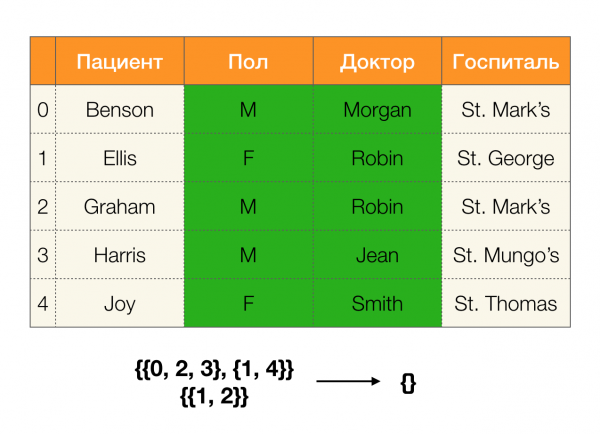

في الحالة الأولى ، حصلنا على قسم فارغ. إذا نظرت عن كثب إلى الجدول ، فعندئذٍ لا توجد قيم متطابقة لسمتين. إذا قمنا بتعديل الجدول قليلاً (الحالة على اليمين) ، فسنحصل بالفعل على تقاطع غير فارغ. في الوقت نفسه ، يحتوي السطران 1 و 2 بالفعل على نفس قيم السمات بول и الطبيب.
بعد ذلك ، نحتاج إلى مفهوم مثل حجم القسم. رسميا:

ببساطة ، حجم القسم هو عدد الكتل المضمنة في القسم (تذكر أن المجموعات الفردية غير مضمنة في القسم!):
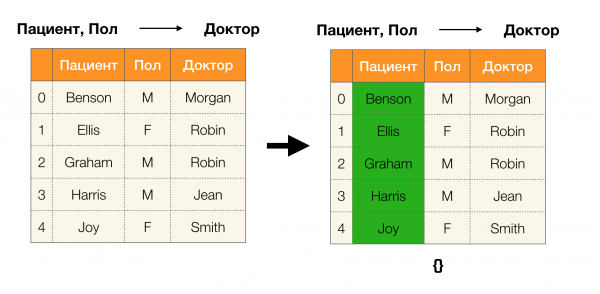
يمكننا الآن تحديد أحد المفاتيح الرئيسية ، والتي ، بالنسبة لأقسام معينة ، تسمح لنا بتحديد ما إذا كانت التبعية محتفظ بها أم لا:
ليما 1. يتم الاحتفاظ بالتبعية A ، B → C إذا وفقط إذا

وفقًا لـ lemma ، هناك أربع خطوات لتحديد ما إذا كانت التبعية محتجزة:
- حساب التقسيم للجانب الأيسر من التبعية
- احسب قسم الجانب الأيمن من التبعية
- احسب حاصل ضرب الخطوتين الأولى والثانية
- قارن أحجام الأقسام التي تم الحصول عليها في الخطوتين الأولى والثالثة
يوجد أدناه مثال للتحقق مما إذا كانت التبعية محتجزة بواسطة هذا اللمة:
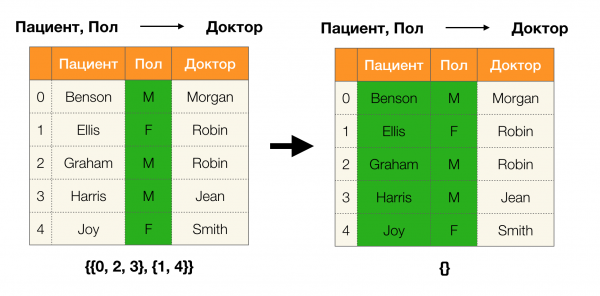
في هذه المقالة ، قمنا بتحليل مفاهيم مثل الاعتماد الوظيفي ، والاعتماد الوظيفي التقريبي ، وفحصنا مكان استخدامها ، وأيضًا ما هي خوارزميات البحث عن FD الموجودة. حللنا أيضًا بالتفصيل المفاهيم الأساسية ولكن المهمة التي يتم استخدامها بنشاط في الخوارزميات الحديثة للبحث عن FDs.
روابط الأدب:
- Huhtala Y. et al. TANE: خوارزمية فعالة لاكتشاف التبعيات الوظيفية والتقريبية // مجلة الكمبيوتر. - 1999. - ت 42. - لا. 2. - س 100-111.
- Kruse S. ، Naumann F. الاكتشاف الفعال للتبعيات التقريبية // وقائع VLDB Endowment. - 2018. - T. 11. - لا. 7. - ص 759-772.
- Papenbrock T. ، Naumann F. نهج هجين لاكتشاف التبعية الوظيفية // وقائع المؤتمر الدولي لعام 2016 حول إدارة البيانات. - ACM ، 2016. - ص 821-833.
- Papenbrock T. وآخرون. اكتشاف التبعية الوظيفية: تقييم تجريبي لسبع خوارزميات // وقائع VLDB Endowment. - 2015. - T. 8. - لا. 10. - س 1082-1093.
- كومار أ وآخرون. للانضمام أم لا للانضمام ؟: التفكير مرتين في الانضمام قبل اختيار الميزة // وقائع المؤتمر الدولي لعام 2016 حول إدارة البيانات. - ACM ، 2016. - S. 19-34.
- Abo Khamis M. et al. التعلم في قاعدة البيانات باستخدام الموترات المتفرقة // وقائع الندوة السابعة والثلاثين من ACM SIGMOD-SIGACT-SIGAI حول مبادئ أنظمة قواعد البيانات. - ACM، 37. - ص 2018-325.
- هيلرشتاين جم وآخرون. مكتبة تحليلات MADlib: أو MAD Skills ، SQL // Proceedings of the VLDB Endowment. - 2012. - V. 5. - لا. 12. - س 1700-1711.
- Qin C.، Rusu F. تقديرات تقريبية لتحسين نزول التدرج الموزع من تيراسكيل // وقائع ورشة العمل الرابعة حول تحليلات البيانات في السحابة. - ACM ، 2015. - ص 1.
- منغ إكس وآخرون. مليب: التعلم الآلي في اباتشي سبارك // مجلة أبحاث التعلم الآلي. - 2016. - T. 17. - لا. 1. - س 1235-1241.
مؤلفو المقالات: ، باحث في , и ، باحث في
المصدر: www.habr.com
