

Yn aml, mae gan bobl sy'n dechrau ym maes gwyddor data ddisgwyliadau afrealistig o'r hyn sy'n eu disgwyl. Mae llawer yn meddwl y byddant yn gallu codio rhwydweithiau niwral gwych, creu cynorthwyydd llais yn seiliedig ar Iron Man, neu guro pawb arall yn y marchnadoedd ariannol.
Ond gwaith Dyddiad Mae gwyddonydd yn cael ei yrru gan ddata, ac un o'r agweddau pwysicaf a mwyaf amser-gymerol yw prosesu'r data cyn ei fwydo i'r rhwydwaith niwral neu ei ddadansoddi mewn ffordd benodol.
Yn yr erthygl hon, bydd ein tîm yn disgrifio sut i brosesu data yn gyflym ac yn hawdd, gan ddefnyddio cyfarwyddiadau cam wrth gam a chod. Rydym wedi ymdrechu i wneud y cod yn ddigon hyblyg i fod yn berthnasol i amrywiaeth o setiau data.
Efallai na fydd llawer o weithwyr proffesiynol yn dod o hyd i unrhyw beth rhyfeddol yn yr erthygl hon, ond bydd dechreuwyr yn gallu dysgu rhywbeth newydd, a gall unrhyw un sydd wedi breuddwydio ers amser maith am wneud llyfr nodiadau ar wahân ar gyfer prosesu data cyflym a strwythuredig gopïo'r cod a'i fformatio drostynt eu hunain, neu
Mae'r set ddata gennym ni. Beth nesaf?
Felly, y safon: mae angen i ni ddeall beth rydyn ni'n delio ag ef, y darlun mawr. I wneud hyn, byddwn ni'n defnyddio pandas i ddiffinio'r gwahanol fathau o ddata yn syml.
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения

df.info() #Демонстрируем информацию о колонках
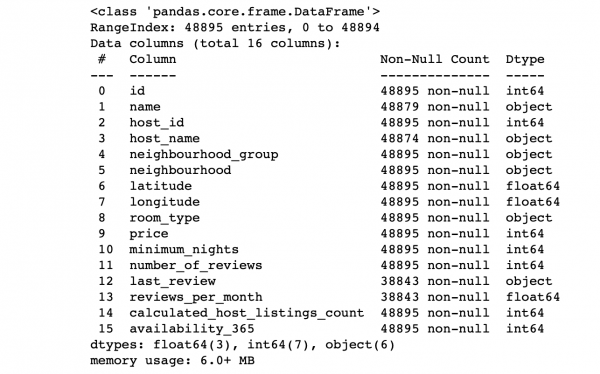
Beth am edrych ar werthoedd y golofn:
- A yw nifer y rhesi ym mhob colofn yn cyfateb i gyfanswm nifer y rhesi?
- Beth yw hanfod y data ym mhob colofn?
- Pa golofn yr ydym am ei thargedu i wneud rhagfynegiadau ar ei chyfer?
Bydd atebion i'r cwestiynau hyn yn caniatáu inni ddadansoddi'r set ddata ac amlinellu cynllun bras ar gyfer gweithredu ar unwaith.
Gallwn hefyd ddefnyddio'r ffwythiant pandas describe() i gael golwg fanylach ar y gwerthoedd ym mhob colofn. Fodd bynnag, anfantais y ffwythiant hwn yw nad yw'n darparu gwybodaeth am golofnau gyda gwerthoedd llinynnol. Byddwn yn trafod y rheini yn nes ymlaen.
df.describe()
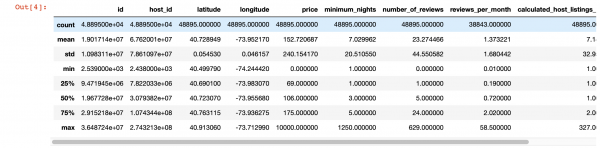
Delweddu hudolus
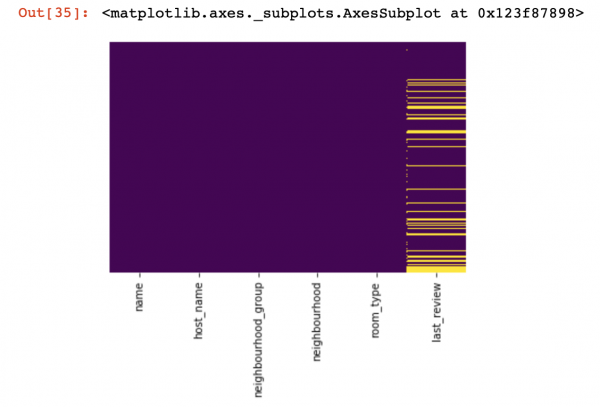
Gadewch i ni edrych ar ble nad oes gennym unrhyw werthoedd o gwbl:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')
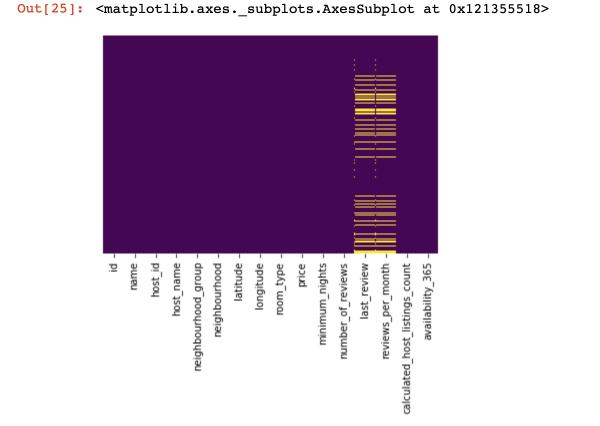
Dyma gipolwg bach o'r uchod, nawr byddwn yn symud ymlaen at bethau mwy diddorol
Gadewch i ni geisio dod o hyd i golofnau sy'n cynnwys un gwerth yn unig ym mhob rhes, ac os yn bosibl, eu tynnu (ni fyddant yn effeithio ar y canlyniad mewn unrhyw ffordd):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значенияNawr rydym yn ein hamddiffyn ein hunain a llwyddiant ein prosiect rhag llinellau dyblyg (llinellau sy'n cynnwys yr un wybodaeth yn yr un drefn â llinell sy'n bodoli eisoes):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.Rhannon ni'r set ddata yn ddau: un gyda gwerthoedd ansoddol a'r llall gyda rhai meintiol.
Mae angen eglurhad bach yma: os nad yw'r rhesi gyda data coll yn y data ansoddol a meintiol yn gysylltiedig yn sylweddol, yna bydd angen i ni benderfynu beth i'w aberthu—pob rhes gyda data coll, dim ond rhai ohonynt, neu golofnau penodol. Os yw'r rhesi'n gysylltiedig, yna mae gennym gyfiawnhad llwyr dros rannu'r set ddata yn ddau. Fel arall, bydd angen i ni fynd i'r afael â'r rhesi gyda data coll nad ydynt yn gysylltiedig rhwng y data ansoddol a meintiol yn gyntaf, a dim ond wedyn rhannu'r set ddata yn ddau.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Rydyn ni'n gwneud hyn i'w gwneud hi'n haws i ni brosesu'r ddau fath gwahanol hyn o ddata - byddwn ni'n deall yn ddiweddarach faint yn haws mae hyn yn gwneud ein bywydau.
Gweithio gyda data meintiol
Y peth cyntaf sydd angen i ni ei wneud yw pennu a oes unrhyw "golofnau ysbïo" yn y data meintiol. Rydym yn galw'r colofnau hyn yn hyn oherwydd eu bod yn ymddangos fel data meintiol, ond mewn gwirionedd maent yn gweithredu fel data ansoddol.
Sut ydyn ni'n eu hadnabod? Wrth gwrs, mae'r cyfan yn dibynnu ar natur y data rydych chi'n ei ddadansoddi, ond yn gyffredinol, bydd gan golofnau o'r fath ychydig o werthoedd unigryw (tua 3-10).
print(df_numerical.nunique())Unwaith y byddwn wedi penderfynu ar y colofnau ysbïo, byddwn yn eu symud o ddata meintiol i ddata ansoddol:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данныеRydym o'r diwedd wedi gwahanu'r data meintiol o'r data ansoddol yn llwyr, a nawr gallwn weithio gyda nhw'n iawn. Yn gyntaf, mae angen i ni ddeall ble mae gennym werthoedd gwag (bydd NaN, ac mewn rhai achosion, hyd yn oed 0, yn cael eu hystyried yn wag).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())Ar y cam hwn, mae'n bwysig deall pa golofnau a all gynnwys seroau sy'n dynodi gwerthoedd coll: a yw hyn oherwydd sut y casglwyd y data? Neu a allai fod oherwydd y gwerthoedd data? Mae angen ateb y cwestiynau hyn fesul achos.
Felly, os penderfynwn y gallem fod data ar goll lle mae seroau, dylem ddisodli'r seroau gyda NaN i'w gwneud hi'n haws gweithio gyda'r data coll hwn yn ddiweddarach:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)Nawr, gadewch i ni weld ble mae data ar goll:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info()
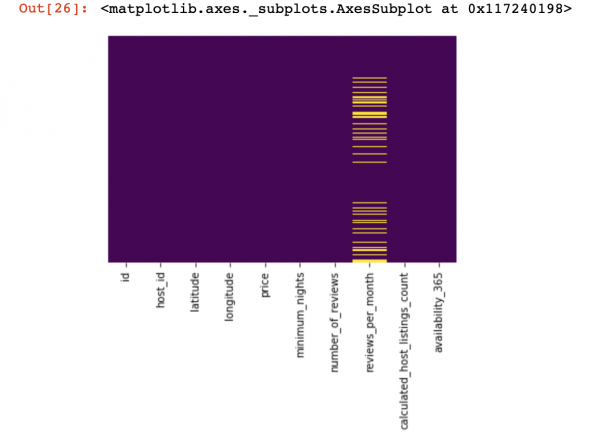
Yma, dylid amlygu'r gwerthoedd coll o fewn y colofnau mewn melyn. Nawr daw'r rhan hwyl: beth i'w wneud â'r gwerthoedd hyn? Dileu'r rhesi neu'r colofnau gyda'r gwerthoedd hyn? Neu lenwi'r gwerthoedd gwag hyn gyda rhai eraill?
Dyma ddiagram bras a allai eich helpu i ddarganfod beth allwch chi ei wneud gyda gwerthoedd gwag:
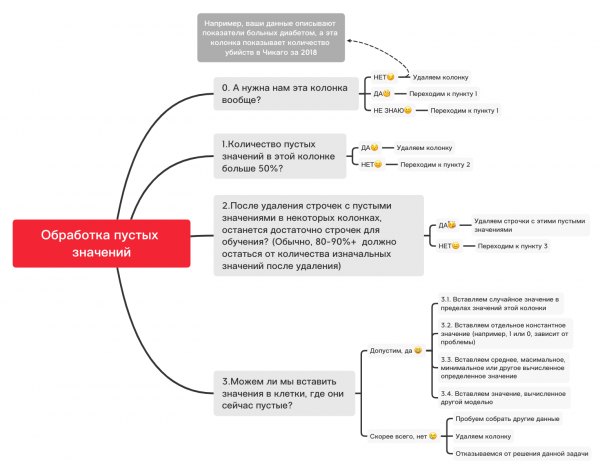
0. Tynnwch golofnau diangen
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. A yw nifer y gwerthoedd gwag yn y golofn hon yn fwy na 50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2. Dileu llinellau gyda gwerthoedd gwag
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1 Mewnosod gwerth ar hap
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. Mewnosod gwerth cyson
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. Mewnosodwch y gwerth cyfartalog neu uchafswm aml
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4 Mewnosod gwerth a gyfrifwyd gan fodel arall
Weithiau, gellir cyfrifo gwerthoedd gan ddefnyddio modelau atchweliad, gan ddefnyddio modelau o lyfrgell sklearn neu lyfrgelloedd tebyg eraill. Bydd ein tîm yn neilltuo erthygl ar wahân i'r dull hwn yn y dyfodol agos.
Felly, am y tro, bydd y drafodaeth am ddata meintiol yn oedi, gan fod llawer o naws eraill i'w hystyried ynghylch y ffordd orau o baratoi a rhagbrosesu data ar gyfer gwahanol dasgau. Mae hanfodion data meintiol wedi'u trafod yn yr erthygl hon, a nawr yw'r amser i ddychwelyd at ddata ansoddol, yr ydym wedi'i wahanu ychydig gamau yn ôl oddi wrth ddata meintiol. Gallwch addasu'r llyfr nodiadau hwn fel y dymunwch, gan ei addasu i wahanol dasgau i wneud rhagbrosesu data yn hynod gyflym!
Data ansoddol
Defnyddir amgodio un-poeth yn bennaf ar gyfer data o ansawdd uchel i'w fformatio o linyn (neu wrthrych) i rif. Cyn i ni symud ymlaen i'r adran hon, gadewch i ni ddefnyddio'r diagram a'r cod uchod i ddelio â gwerthoedd gwag.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')
0. Tynnwch golofnau diangen
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. A yw nifer y gwerthoedd gwag yn y golofn hon yn fwy na 50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2. Dileu llinellau gyda gwerthoedd gwag
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1 Mewnosod gwerth ar hap
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. Mewnosod gwerth cyson
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)Felly, rydym o'r diwedd wedi delio â gwerthoedd gwag mewn data ansoddol. Nawr mae'n bryd amgodio'r gwerthoedd yn eich cronfa ddata unwaith ac am byth. Defnyddir y dull hwn yn aml iawn i alluogi eich algorithm i ddysgu o ddata ansoddol.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Felly, rydym o'r diwedd wedi gorffen prosesu'r data ansoddol a meintiol ar wahân – mae'n bryd eu cyfuno'n ôl at ei gilydd.
new_df = pd.concat([df_numerical,df_categorical], axis=1)Ar ôl i ni uno'r setiau data yn un, gallwn o'r diwedd drawsnewid y data gan ddefnyddio MinMaxScaler o lyfrgell sklearn. Bydd hyn yn sicrhau bod ein gwerthoedd o fewn yr ystod o 0 i 1, a fydd o gymorth gyda hyfforddiant modelu yn y dyfodol.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Mae'r data hwn bellach yn barod ar gyfer popeth – rhwydweithiau niwral, algorithmau ML safonol, ac ati!
Yn yr erthygl hon, nid ydym wedi trafod gweithio gyda data cyfres amser, gan fod data o'r fath angen technegau prosesu ychydig yn wahanol, yn dibynnu ar eich anghenion penodol. Bydd ein tîm yn neilltuo erthygl ar wahân i'r pwnc hwn yn y dyfodol, a gobeithiwn y bydd yn dod â rhywbeth diddorol, newydd a defnyddiol i chi, yn union fel yr un hon.
Ffynhonnell: hab.com
