

Hej Habr! Ni invitas Datumajn Inĝenierojn kaj Maŝinlernadajn specialistojn al senpaga Demo-leciono . Ni ankaŭ publikigas artikolon de Luca Monno - Estro de Financa Analizo ĉe CDP SpA.
Unu el la plej utilaj kaj simplaj maŝinlernadaj metodoj estas Ensembla Lernado. Ensemble Learning estas la subesta tekniko por XGBoost, Bagging, Random Forest, kaj multaj aliaj algoritmoj.
Estas multaj bonegaj artikoloj pri Towards Data Science, sed mi elektis du rakontojn ( и ) kiun mi plej ŝatis. Kial do verki alian artikolon pri EL? Ĉar mi volas montri al vi kiel ĝi funkcias sur simpla ekzemplo, kio komprenigis al mi, ke ĉi tie ne ekzistas magio.
Kiam mi unue vidis EL en agado (laborante kun kelkaj tre simplaj regresaj modeloj) mi ne povis kredi miajn okulojn, kaj mi ankoraŭ memoras la profesoron, kiu instruis al mi ĉi tiun metodon.
Mi havis du malsamajn modelojn (du malfortajn lernalgoritmojn) kun eksponentoj ekstere de specimeno R² egalas al 0,90 kaj 0,93 respektive. Antaŭ ol rigardi la rezulton, mi pensis, ke mi ricevos R² ie inter la du komencaj valoroj. Alivorte, mi pensis, ke EL povus esti uzata por ke la modelo ne rezultu tiel malbone kiel la plej malbona modelo, sed ne tiel bone kiel povus la plej bona modelo.
Je mia granda surprizo, la rezultoj de simpla averaĝado de la antaŭdiroj donis R² de 0,95.
Komence mi komencis serĉi eraron, sed poste mi pensis, ke eble estas ia magio kaŝita ĉi tie!
Kio estas Ensembla Lernado
Kun EL, vi povas kombini la antaŭdirojn de du aŭ pli da modeloj por akiri pli fidindan kaj efikan modelon. Estas multaj metodaroj por labori kun ensembloj de modeloj. Ĉi tie mi tuŝos la du plej utilajn por doni al vi ideon.
Kun la helpo de regreso vi povas averaĝi la rendimenton de la disponeblaj modeloj.
Kun la helpo de klasifiko vi povas lasi modelojn elekti etikedojn. La etikedo plej ofte elektita estas tiu, kiu estos elektita de la nova modelo.
Kial EL Funkcias Pli bone
La ĉefa kialo kial EL funkcias pli bone estas ĉar ĉiu antaŭdiro havas eraron (ni scias tion el probabla teorio), kombini du antaŭdirojn povas helpi redukti la eraron, kaj tiel plibonigi rendimentajn indikilojn (RMSE, R², ktp.). d.).
La sekva diagramo montras kiel du malfortaj algoritmoj funkcias sur datumaro. La unua algoritmo havas pli grandan deklivon ol necesa, dum la dua havas preskaŭ nulon (eble pro troa reguligo). Sed ensemblo montras pli bonajn rezultojn.
Se vi rigardas la R², tiam la unua kaj dua trejnado-algoritmo havos ĝin egala al -0.01¹, 0.22, respektive, dum por la ensemblo ĝi estos egala al 0.73.
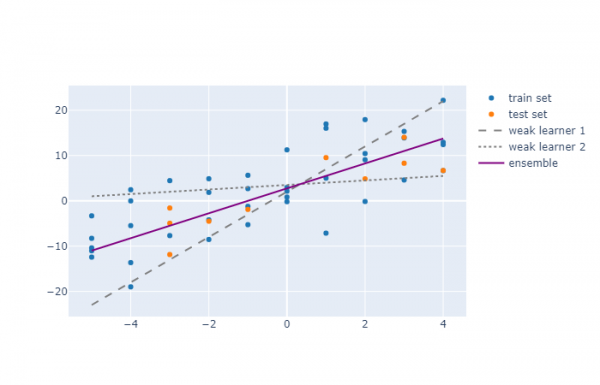
Estas multaj kialoj, kial algoritmo povas esti malbona modelo eĉ por baza ekzemplo kiel ĉi tiu: eble vi decidis uzi reguligon por eviti troagordon, aŭ vi decidis ne forigi iujn anomaliojn, aŭ eble vi uzis polinoman regreson kaj elektis malĝustan gradon. (ekzemple , uzis polinomon de la dua grado, kaj la testaj datumoj montras klaran malsimetrion, por kiu la tria grado pli taŭgas).
Kiam EL Funkcias Plejbone
Ni rigardu du lernajn algoritmojn, kiuj funkcias sur la samaj datumoj.
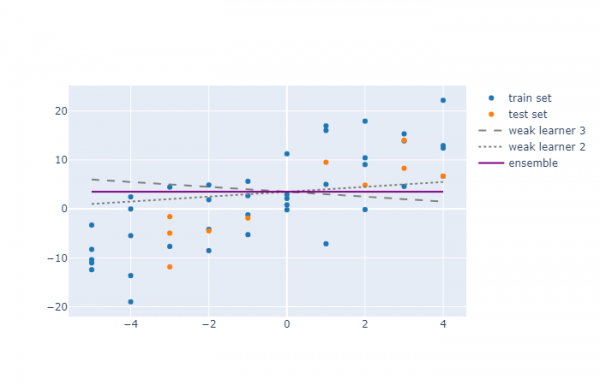
Ĉi tie vi povas vidi, ke kombini la du modelojn ne multe plibonigis rendimenton. Komence, por la du trejnaj algoritmoj, la R²-valoroj estis -0,37 kaj 0,22, respektive, kaj por la ensemblo ĝi rezultis esti -0,04. Tio estas, la EL-modelo ricevis la averaĝan valoron de la indikiloj.
Tamen, estas granda diferenco inter ĉi tiuj du ekzemploj: en la unua ekzemplo, la eraroj de la modeloj estis negative korelaciitaj, kaj en la dua - pozitive (la koeficientoj de la tri modeloj ne estis taksitaj, sed simple elektitaj de la aŭtoro. kiel ekzemplo.)
Tial, Ensemblo-Lernado povas esti uzata por plibonigi la biasan/dispersan ekvilibron en ĉiuj kazoj, sed kiam modeleraroj ne estas pozitive korelaciitaj, uzi EL povas konduki al pli bona efikeco.
Homogenaj kaj heterogenaj modeloj
Tre ofte EL estas uzata sur homogenaj modeloj (kiel en ĉi tiu ekzemplo aŭ hazarda arbaro), sed fakte oni povas kombini malsamajn modelojn (linia regreso + neŭrala reto + XGBoost) kun malsamaj aroj de klarigaj variabloj. Ĉi tio verŝajne kondukos al nekorelaciaj eraroj kaj plibonigos rendimenton.
Komparo kun biletujo diversigo
EL funkcias simile al diversigo en teorio de biletujo, sed des pli bone por ni.
Kiam vi diversigas, vi provas redukti la variancon en via agado investante en nerilatigitaj akcioj. Bone diversigita biletujo de akcioj funkcios pli bone ol la plej malbonaj unuopaj akcioj, sed neniam pli bone ol la plej bonaj.
Citante Warren Buffett:
"Diversiĝo estas defendo kontraŭ nescio, por iu, kiu ne scias, kion li faras, ĝi [diversiĝo] havas tre malmulte da senco."
En maŝinlernado, EL helpas redukti la variancon de via modelo, sed tio povas rezultigi modelon kun pli bona ĝenerala rendimento ol la plej bona komenca modelo.
Ni sumigu la rezultojn
Kombini plurajn modelojn en unu estas relative simpla tekniko kiu povas konduki al solvo al la varianbiasproblemo kaj plibonigita efikeco.
Se vi havas du aŭ pli da modeloj kiuj bone funkcias, ne elektu inter ili: uzu ilin ĉiujn (sed singarde)!
Ĉu vi interesiĝas disvolvi ĉi tiun direkton? Registriĝi por senpaga demo-leciono kaj partopreni — Inĝeniero pri Maŝinlernado ĉe Mail.ru Group.
fonto: www.habr.com
