


Doloras nur la unuan fojon!
Saluton al ĉiuj! Karaj amikoj, en ĉi tiu artikolo mi volas kunhavigi mian sperton pri uzado de TensorRT, RetinaNet bazita sur la deponejo. (ĉi tio estas forko de la oficiala rapo de , kiu permesos al vi komenci uzi optimumigitajn modelojn en produktado kiel eble plej baldaŭ). Rulumado tra mesaĝoj en komunumaj kanaloj , mi renkontas demandojn pri uzado de TensorRT kaj la demandoj plejparte ripetas, do mi decidis skribi kiel eble plej kompleta Gvidilo pri uzado de rapida inferenco bazita sur TensorRT, RetinaNet, Unet kaj docker.
Priskribo de la tasko
Mi proponas formuli la taskon tiel: ni bezonas etikedi la datumbazon, trejni la RetinaNet/Unet-reton per Pytorch 1.3+, konverti la akiritajn pezojn al ONNX, poste konverti ilin al la TensorRT-motoro kaj funkciigi la tutan aferon en Docker, prefereble per Ubuntu 18 kaj tre dezirinda sur la arkitekturo ARM (Jetson)*, tiel minimumigante manan deplojon de la medio. La fina rezulto estos ujo preta ne nur por eksportado kaj trejnado de RetinaNet/Unet, sed ankaŭ por plenkreska disvolviĝo kaj trejnado de klasifikaj kaj segmentaj sistemoj, kun la tuta necesa aparataro.
Etapo 1. Preparado de la medio
Estas grave rimarki ĉi tie, ke lastatempe mi tute forlasis la uzadon kaj disfaldiĝon de almenaŭ kelkaj bibliotekoj sur labortabla maŝino, same kiel sur devbox. La nura afero, kiun vi devas krei kaj instali, estas python virtuala medio kaj cuda 10.2 (vi povas limigi vin al unu nvidia ŝoforo) de deb.
Ni supozu, ke vi havas ĵus instalitan Ubuntu 18. Ni instalu cuda 10.2 (deb). Mi ne detale priskribos la instalan procezon, la oficiala dokumentado estas sufiĉe sufiĉa.
Nun ni instalu docker, la gvidilo pri instalado de docker facile troveblas, jen ekzemplo , versio 19+ jam disponeblas - instalu ĝin. Nu, ne forgesu ebligi uzi docker sen sudo, ĝi estos pli oportuna. Post kiam ĉio funkciis, ni faras ĉi tion:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
Kaj vi eĉ ne devas rigardi la oficialan deponejon .
Nun ni faru git-klonon .
Restas nur iomete, por komenci uzi docker kun nvidia bildo, ni devos registriĝi ĉe NGC Cloud kaj ensaluti. Ni iru ĉi tien , registriĝu kaj post kiam ni eniras NGC Cloud, alklaku AJRO en la supra maldekstra angulo de la ekrano aŭ sekvu ĉi tiun ligon . Alklaku "generi ŝlosilon". Mi rekomendas konservi ĝin, alie la venontan fojon kiam vi vizitos ĝin, vi devos generi ĝin denove kaj, sekve, deploji ĝin sur nova aŭto kaj ripeti ĉi tiun operacion.
Ni faru:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
Uzantnomo estas simple kopiita. Nu, konsideru la medion deplojitan!
Etapo 2: Konstruado de la docker-ujo
En la dua etapo de nia laboro, ni konstruos docker kaj konatiĝos kun ĝiaj internoj.
Ni iru al la radika dosierujo rilate al la projekto de retino-ekzemploj kaj ekzekutu
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Ni konstruas docker pasante la nunan uzanton en ĝin - ĉi tio estas tre utila se vi skribas ion al muntita VOLUME kun la rajtoj de la nuna uzanto, alie ĝi estos radiko kaj doloro.
Dum docker konstruas, ni ekzamenu la Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
Kiel vi povas vidi el la teksto, ni prenas ĉiujn niajn plej ŝatatajn bibliotekojn, kompilas retinanet, kaj aldonas kelkajn bazajn ilojn por faciligi la uzadon. Ubuntu kaj agordu la OpenSSH-servilon. La unua linio heredas la NVIDIA-bildon, por kiu ni kreis la ensaluton al NGC Cloud kaj kiu enhavas Pytorch1.3, TensorRT6.xxx, kaj multajn aliajn bibliotekojn, kiuj permesas al ni kompili la fontkodon de CPP por nia detektilo.
Etapo 3: Lanĉo kaj Sencimigado de la Docker-Ujo
Ni iru al la ĉefa kazo de uzado de la ujo kaj evolumedio; unue, ni lanĉu nvidia docker. Ni faru:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestLa ujo nun estas alirebla per ssh @localhost. Post sukcesa lanĉo, malfermu la projekton en PyCharm. Poste ni malfermas
Settings->Project Interpreter->Add->Ssh Interpreter paŝi 1
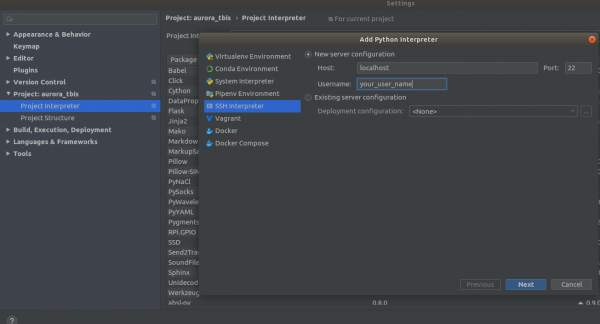
paŝi 2
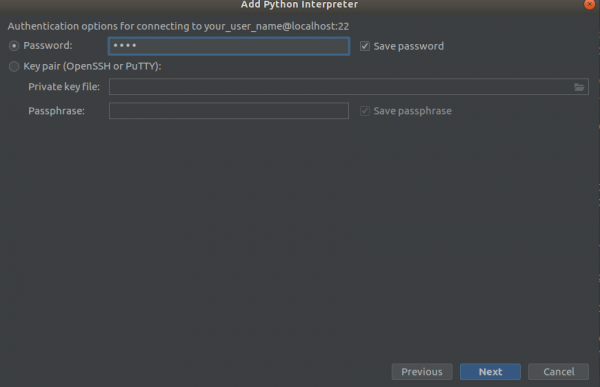
paŝi 3
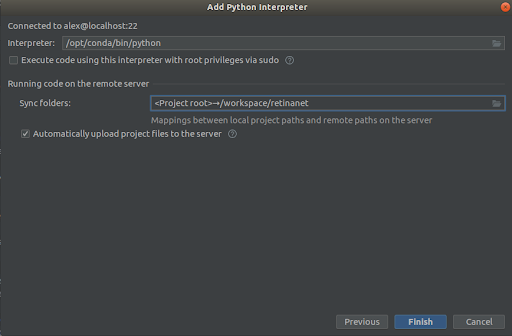
Ni elektas ĉion kiel en la ekrankopioj,
Interpreter -> /opt/conda/bin/python- ĉi tio estos ln en Python3.6 kaj
Sync folder -> /workspace/retinanetNi premas fini, atendas indekson, kaj jen, la medio estas preta por uzo!
GRAVA!!! Tuj post indeksado, tiru la kompilitajn dosierojn por Retinanet el docker. En la kunteksta menuo en la projekta radiko, elektu la eron
Deployment->DownloadUnu dosiero kaj du dosierujoj aperos: build, retinanet.egg-info kaj _С.so
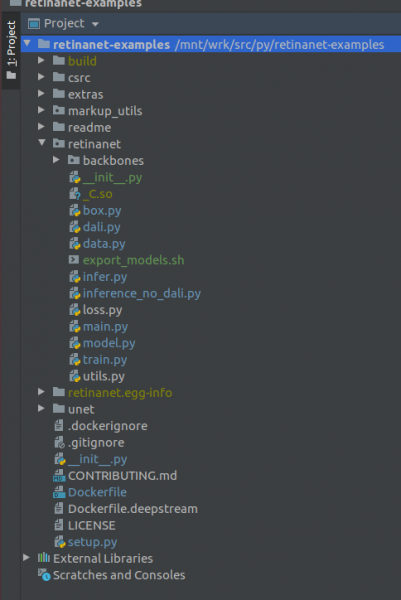
Se via projekto aspektas tiel, tiam la medio vidas ĉiujn necesajn dosierojn kaj ni pretas trejni RetinaNet.
Etapo 4. Etikedu la datumojn kaj trejnu la detektilon
Por markado mi ĉefe uzas — agrabla kaj oportuna ilo, lastatempe amaso da cimoj estis riparita kaj ĝi fariĝis signife pli bone konduta.
Ni supozu, ke vi markis la datumaron kaj elŝutis ĝin, sed vi ne povos tuj enmeti ĝin en nian RetinaReton, ĉar ĝi estas en sia propra formato kaj por tio ni devas konverti ĝin al COCO. La konverta ilo troviĝas en:
markup_utils/supervisly_to_coco.pyBonvolu noti, ke Kategorio en la skripto estas ekzemplo kaj vi devas enmeti vian propran (ne necesas aldoni la fonan kategorion)
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] Ial, la aŭtoroj de la originala deponejo decidis, ke vi trejnos nenion krom COCO/VOC por detekto, do ili devis iomete redakti la fontdosieron.
retinanet/dataset.pyAldonante viajn plej ŝatatajn pliigojn ĉi tie kaj eltranĉu malmolajn kategoriojn de COCO. Eblas ankaŭ tondi grandajn detektajn areojn, se vi serĉas malgrandajn objektojn en grandaj bildoj, vi havas malgrandan datumaron =), kaj nenio funkcias, sed pli pri tio alian fojon.
Ĝenerale, la trajnbuklo ankaŭ estas malforta, komence ĝi ne ŝparis kontrolpunktojn, ĝi uzis ian teruran planilon, ktp. Sed nun ĉio, kion vi devas fari, estas elekti la spinon kaj ekzekuti
/opt/conda/bin/python retinanet/main.pykun parametroj:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
En la konzolo vi vidos:
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148Por esplori la tutan aron de parametroj, rigardu
retinanet/main.pyĜenerale, ili estas normaj por detekto, kaj ili havas priskribon. Komencu la trejnadon kaj atendu la rezultojn. Ekzemplo de inferenco povas esti vidita en:
retinanet/infer_example.pyaŭ rulu la komandon:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
La deponejo jam havas Focal Loss kaj plurajn spinojn enkonstruitajn, kaj ankaŭ estas facile enigi vian propran
retinanet/backbones/*.pyEn la tabelo la aŭtoroj donas kelkajn karakterizaĵojn:
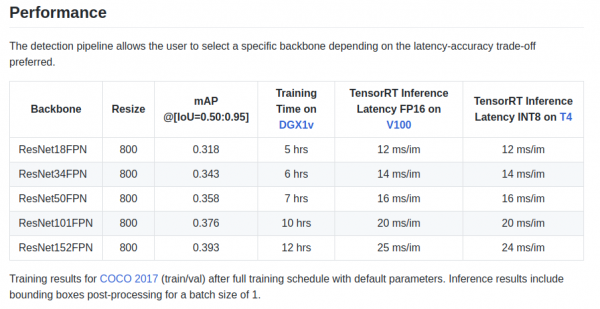
Ekzistas ankaŭ spino ResNeXt50_32x4dFPN kaj ResNeXt101_32x8dFPN, prenitaj de torchvision.
Mi esperas, ke vi iom eltrovis la detekton, sed vi certe devus legi la oficialan dokumentaron tiel kompreni eksportajn kaj registrajn reĝimojn.
Etapo 5. Eksporto kaj inferenco de Unet-modeloj kun Resnet-kodilo
Kiel vi verŝajne rimarkis, bibliotekoj por segmentado estis instalitaj en la Dockerfile, kaj precipe la mirinda lib . En la unitet-pakaĵo vi povas trovi ekzemplojn de inferenco kaj eksportado de pytorch-transirejoj al la motoro TensorRT.
La ĉefa problemo dum eksportado de Unet-similaj modeloj de ONNX al TensoRT estas la bezono agordi fiksan Supran specimenon aŭ uzi ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
Uzante ĉi tiun transformon, vi povas fari tion aŭtomate kiam vi eksportas al ONNX, sed jam en la versio 7 de TensorRT ĉi tiu problemo estis solvita, kaj ni devas atendi sufiĉe.
konkludo
Kiam mi komencis uzi docker, mi dubis pri ĝia agado por miaj taskoj. Unu el miaj unuoj nuntempe havas sufiĉe multe da rettrafiko generita de pluraj fotiloj.
Diversaj testoj en la Interreto indikis relative grandan superkoston por reto interagado kaj registrado sur VOLUME, krom la nekonata kaj terura GIL, kaj ekde la kaptado de kadro, funkciigado de la ŝoforo kaj transdoni la kadron tra la reto estas atoma operacio en la reĝimo. malfacila reala tempo, retaj prokrastoj estas tre kritikaj por mi.
Sed ĉio fariĝis en ordo =)
PS Restas nur aldoni vian preferatan trajnobuklon por segmentado kaj produktado!
Dankon
Dankon al la komunumo , sen ĝi estas neeble disvolviĝi! Multaj dankoj , kiu instigis min fari DL, pro siaj valoregaj konsiloj kaj ekstrema profesieco!
Uzu optimumigitajn modelojn en produktado!
 Aurorai, llc
Aurorai, llc
fonto: www.habr.com
