


Apache Cassandra datu-basea eta Kubernetes-en oinarritutako azpiegitura baten barruan funtzionatzeko beharrarekin topo egiten dugu aldizka. Material honetan, Cassandra K8ra migratzeko beharrezkoak diren urratsen, irizpideen eta dauden soluzioen ikuspegia (operadoreen ikuspegi orokorra barne) partekatuko dugu.
"Emakume bat gobernatzen duenak estatua ere goberna dezake"
Nor da Cassandra? Banatutako biltegiratze sistema bat da, datu-bolumen handiak kudeatzeko diseinatua, erabilgarritasun handia bermatuz huts-puntu bakar bat ere izan gabe. Proiektuak ez du sarrera luzerik behar, beraz, artikulu zehatz baten testuinguruan garrantzitsuak izango diren Cassandraren ezaugarri nagusiak soilik emango ditut:
- Cassandra Javan idatzita dago.
- Cassandra topologiak hainbat maila ditu:
- Nodoa - inplementatutako Cassandra instantzia bat;
- Rack Cassandra instantzia-multzo bat da, ezaugarri batzuk elkartuta, datu-zentro berean kokatua;
- Datacenter - datu-zentro batean kokatutako Cassandra instantzia talde guztien bilduma;
- Cluster datu-zentro guztien bilduma da.
- Cassandra-k IP helbide bat erabiltzen du nodo bat identifikatzeko.
- Idazketa eta irakurketa eragiketak bizkortzeko, Cassandra-k datu batzuk RAMan gordetzen ditu.
Orain - Kubernetesera benetako mugimendu potentziala.
Transferentziarako kontrol-zerrenda
Cassandra Kuberneteserako migrazioari buruz hitz egitean, espero dugu mugimenduarekin kudeatzeko erosoagoa izango dela. Zer eskatuko da horretarako, zer lagunduko du honetan?
1. Datuak biltegiratzea
Dagoeneko argitu den bezala, Cassandak datuen zati bat RAM-n gordetzen du Memtable. Baina bada diskoan gordetzen den datuen beste zati bat, formularioan SSTable. Datu horiei entitate bat gehitzen zaie Konpromisoen erregistroa — transakzio guztien erregistroak, diskoan gordetzen direnak ere.
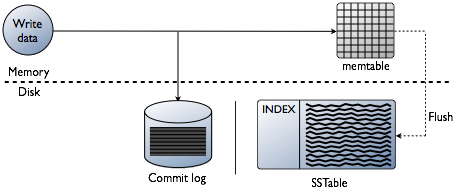
Idatzi transakzio-diagrama Cassandra-n
Kubernetesen, PersistentVolume erabil dezakegu datuak gordetzeko. Frogatutako mekanismoei esker, Kubernetesen datuekin lan egitea urtero errazagoa da.
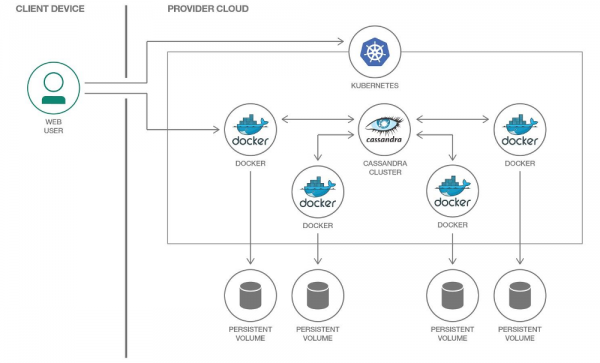
Pod bakoitza Cassandrarekin bere Bolumen iraunkorra esleituko dugu
Garrantzitsua da Cassandrak berak datuen erreplikazioa inplikatzen duela, horretarako mekanismo integratuak eskainiz. Hori dela eta, Cassandra kluster bat nodo kopuru handitik eraikitzen ari bazara, ez dago zertan Ceph edo GlusterFS bezalako sistema banatuak erabili datuak biltegiratzeko. Kasu honetan, logikoa izango litzateke datuak ostalariaren diskoan gordetzea erabiliz edo muntatzea hostPath.
Beste galdera bat da ezaugarrien adar bakoitzerako garatzaileentzako ingurune bereizi bat sortu nahi duzun. Kasu honetan, ikuspegi zuzena Cassandra nodo bat igotzea eta datuak biltegiratze banatu batean biltegiratzea litzateke, hau da. aipatutako Ceph eta GlusterFS izango dira zure aukerak. Orduan garatzaileak ziurtatuko du ez dituela probako datuak galduko Kuberntes klusterreko nodoetako bat galdu arren.
2. Jarraipena
Kubernetesen monitorizazioa ezartzeko ia eztabaidaezina den aukera Prometheus da (Hori buruz zehatz-mehatz hitz egin dugu ). Nola ari da Cassandra Prometheus-eko metrika-esportatzaileekin? Eta, zer da are garrantzitsuagoa, Grafanaren aginte-panelekin?
Cassandrarentzat Grafana-n grafikoen agerpenaren adibidea
Bi esportatzaile baino ez daude: и .
Lehenengoa guretzat aukeratu dugu zeren eta:
- JMX Exporter hazten eta garatzen ari da, Cassandra Exporter-ek ezin izan du komunitatearen laguntza nahikoa lortu. Cassandra Exporter-ek oraindik ez ditu Cassandraren bertsio gehienak onartzen.
- javaagent gisa exekutatu dezakezu bandera bat gehituz
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Berarentzat badago bat , Cassandra Exporter-ekin bateraezina dena.
3. Kubernetes primitiboak hautatzea
Cassandra klusterraren goiko egituraren arabera, saia gaitezen bertan deskribatzen den guztia Kubernetesen terminologiara itzultzen:
- Cassandra Nodoa → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → StatefulSets-en igerilekua
- Cassandra Cluster → ???
Bihurtzen da Cassandra kluster osoa aldi berean kudeatzeko entitate gehigarriren bat falta dela. Baina zerbait existitzen ez bada, guk sortu dezakegu! Kubernetes-ek bere baliabideak definitzeko mekanismo bat dauka horretarako - .
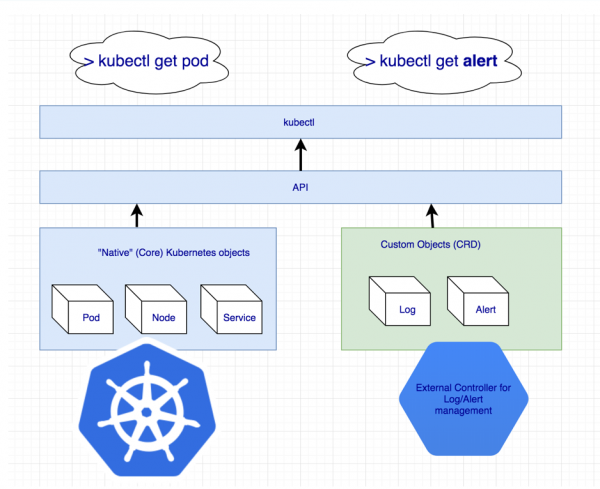
Erregistroetarako eta alertetarako baliabide osagarriak deklaratzea
Baina Custom Resource berak ez du ezer esan nahi: azken finean, eskatzen du kontroladore. Baliteke laguntza bilatu behar izatea ...
4. Lekak identifikatzea
Goiko paragrafoan, Cassandra nodo bat Kubernetes-en pod bat berdina izango dela adostu genuen. Baina poden IP helbideak desberdinak izango dira bakoitzean. Eta Cassandra-n nodo baten identifikazioa IP helbidean oinarritzen da... Gertatzen da pod bat kendu ondoren, Cassandra klusterrak nodo berri bat gehituko duela.
Irteera bat dago, eta ez bakarra:
- Erregistroak ostalari-identifikatzaileen arabera gorde ditzakegu (Casandra instantziak esklusiboki identifikatzen dituzten UUIDak) edo IP helbideen arabera eta dena egitura/taula batzuetan gorde dezakegu. Metodoak bi desabantaila nagusi ditu:
- Lasterketa-egoera bat gertatzeko arriskua bi nodo aldi berean erortzen badira. Igoeraren ondoren, Cassandra nodoek aldi berean IP helbide bat eskatuko dute mahaitik eta baliabide berberaren alde lehiatuko dira.
- Cassandra nodo batek datuak galdu baditu, ezingo dugu identifikatu.
- Bigarren irtenbideak hack txiki bat dirudi, baina hala ere: ClusterIP-arekin Zerbitzu bat sor dezakegu Cassandra nodo bakoitzeko. Inplementazio honen arazoak:
- Cassandra kluster batean nodo asko baldin badaude, Zerbitzu asko sortu beharko ditugu.
- ClusterIP funtzioa iptables bidez inplementatzen da. Hau arazo bihur daiteke Cassandra klusterrak nodo asko (1000... edo 100?) baditu. Nahiz eta arazo hau konpondu dezake.
- Hirugarren irtenbidea Cassandra nodoetarako nodoen sarea erabiltzea da, ezarpena gaituz, pods sare dedikatu baten ordez.
hostNetwork: true. Metodo honek zenbait murrizketa ezartzen ditu:- Unitateak ordezkatzeko. Beharrezkoa da nodo berriak aurrekoaren IP helbide bera izatea (AWS bezalako hodeietan, GCP hori ia ezinezkoa da);
- Kluster-nodoen sarea erabiliz, sareko baliabideetarako lehiatzen hasiko gara. Hori dela eta, Cassandrarekin pod bat baino gehiago kluster-nodo batean jartzea arazotsua izango da.
5. Backups
Cassandra nodo bakar baten datuen bertsio osoa gorde nahi dugu programazio batean. Kubernetes-ek funtzio erosoa eskaintzen du , baina hemen Kasandrak berak errabo bat jartzen digu gurpiletan.
Gogora dezadan Cassandra-k datu batzuk memorian gordetzen dituela. Babeskopia osoa egiteko, memoriako datuak behar dituzu (Memtables) diskora eraman (SSTables). Une honetan, Cassandra nodoak konexioak onartzeari uzten dio, klusteretik erabat itzali.
Horren ondoren, babeskopia kentzen da (argazkia) eta eskema gordetzen da (tekla-espazioa). Eta gero, konturatzen da babeskopia batek ez digula ezer ematen: Cassandra nodoaren ardura izan zen datu-identifikatzaileak gorde behar ditugu - token bereziak dira.
Tokenen banaketa Cassandra nodoek zer daturen ardura duten identifikatzeko
Kubernetes-en Google-tik Cassandra babeskopia bat hartzeko script adibide bat aurki daiteke hemen . Gidoiak kontuan hartzen ez duen puntu bakarra nodoan datuak berrezartzea da argazkia atera aurretik. Hau da, babeskopia ez da uneko egoerarako egiten, apur bat lehenagoko egoera baterako baizik. Baina honek nodoa funtzionamendutik ez kentzen laguntzen du, eta horrek oso logikoa dirudi.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Cassandra nodo batetik babeskopia hartzeko bash script baten adibidea
Cassandrarentzat prest dauden irtenbideak Kubernetes-en
Zer erabiltzen da gaur egun Cassandra Kubernetes-en zabaltzeko eta hauetako zein egokitzen da emandako eskakizunetara?
1. StatefulSet edo Helm diagrametan oinarritutako soluzioak
Cassandra kluster bat exekutatzeko StatefulSets oinarrizko funtzioak erabiltzea aukera ona da. Helm diagrama eta Go txantiloiak erabiliz, erabiltzaileari interfaze malgu bat eskain diezaiokezu Cassandra zabaltzeko.
Normalean ondo funtzionatzen du... ustekabeko zerbait gertatu arte, adibidez, nodoen hutsegite bat. Kubernetes tresna estandarrek ezin dituzte kontuan hartu goian deskribatutako ezaugarri guztiak. Gainera, ikuspegi hau oso mugatua da zenbateraino heda daitekeen erabilera konplexuagoetarako: nodoen ordezkapena, babeskopia, berreskuratzea, monitorizazioa, etab.
Ordezkariak:
- ;
- .
Bi grafikoak berdin onak dira, baina goian azaldutako arazoen menpe daude.
2. Kubernetes Operator-ean oinarritutako soluzioak
Horrelako aukerak interesgarriagoak dira, klusterrak kudeatzeko aukera zabalak ematen dituztelako. Cassandra operadore bat diseinatzeko, beste edozein datu-base bezala, eredu on batek Sidecar Controller CRD bezalakoa da:
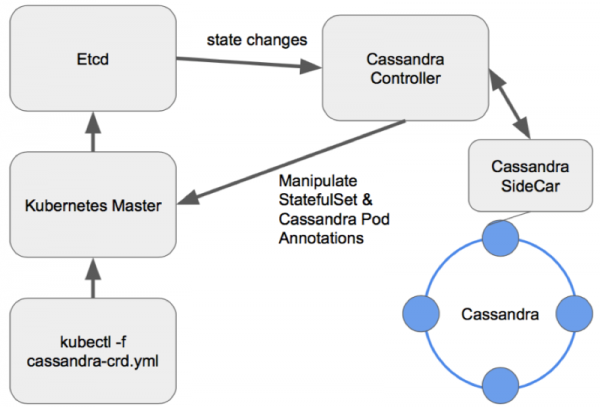
Nodoen kudeaketa eskema ondo diseinatutako Cassandra operadore batean
Ikus ditzagun lehendik dauden operadoreak.
1. Cassandra-operatzailea instaclustr-etik
- Presttasuna: Alfa
- Lizentzia: Apache 2.0
- Inplementatua: Java
Cassandra inplementazioak eskaintzen dituen enpresa baten proiektu itxaropentsua eta aktiboki garatzen duen proiektua da. Goian azaldu bezala, HTTP bidez komandoak onartzen dituen sidecar edukiontzi bat erabiltzen du. Javan idatzita, batzuetan client-go liburutegiaren funtzionalitate aurreratuagoa falta du. Gainera, operadoreak ez ditu Rack desberdinak onartzen Datu-zentro baterako.
Baina operadoreak abantailak ditu monitorizaziorako euskarria, CRD erabiliz goi mailako kluster kudeaketa eta baita babeskopiak egiteko dokumentazioa ere.
2. Jetstack-eko nabigatzailea
- Presttasuna: Alfa
- Lizentzia: Apache 2.0
- Inplementatua: Golang
DB-as-a-Service inplementatzeko diseinatutako adierazpena. Gaur egun bi datu-base onartzen ditu: Elasticsearch eta Cassandra. RBAC bidez datu basearen sarbidea kontrolatzeko irtenbide interesgarriak ditu (horretarako bere nabigatzaile-apiserver bereizia du). Gehiago aztertzea mereziko lukeen proiektu interesgarria, baina azken konpromisoa duela urte eta erdi egin zen, eta horrek argi eta garbi murrizten du bere potentziala.
3. Cassandra-operatzailea vgkowski-k
- Presttasuna: Alfa
- Lizentzia: Apache 2.0
- Inplementatua: Golang
Ez zuten “serio” hartu, biltegirako azken konpromisoa duela urtebete baino gehiago izan zelako. Operadorearen garapena bertan behera utzi da: onartzen dela jakinarazitako Kubernetes-en azken bertsioa 1.9 da.
4. Rook-en Cassandra-operatzailea
- Presttasuna: Alfa
- Lizentzia: Apache 2.0
- Inplementatua: Golang
Garapena guk nahi bezain azkar aurrera egiten ez duen operadorea. Klusterren kudeaketarako CRD egitura ondo pentsatua du, ClusterIP-arekin Zerbitzua erabiliz nodoak identifikatzeko arazoa konpontzen du («hack» bera)... baina hori da oraingoz. Une honetan ez dago monitorizaziorik edo babeskopiarik gabe (bide batez, monitorizaziorako gaude ). Puntu interesgarri bat da ScyllaDB ere inplementa dezakezula operadore hau erabiliz.
OHARRA: Operadore hau aldaketa txikiekin erabili dugu gure proiektuetako batean. Operadorearen lanean ez zen arazorik nabaritu funtzionamendu-aldi osoan (~4 hilabeteko funtzionamenduan).
5. Orange-ko CassKop
- Presttasuna: Alfa
- Lizentzia: Apache 2.0
- Inplementatua: Golang
Zerrendako operadore gazteena: lehen konpromisoa 23ko maiatzaren 2019an egin zen. Dagoeneko bere armategian gure zerrendako ezaugarri ugari ditu, eta horien xehetasun gehiago proiektuaren biltegian aurki daitezke. Operadore-sdk ezagunaren arabera eraikitzen da. Kutxaz kanpoko monitorizazioa onartzen du. Beste operadoreekiko desberdintasun nagusia erabilera da , Python-en inplementatu eta Cassandra nodoen arteko komunikaziorako erabiltzen da.
Findings
Cassandra Kubernetesera eramateko planteamendu eta aukera posibleak berez hitz egiten du: gaia eskatzen da.
Fase honetan, goiko edozein proba dezakezu zure arriskuan eta arriskuan: garatzaileetako inork ez du bermatzen bere soluzioaren % 100eko funtzionamendua ekoizpen ingurune batean. Baina dagoeneko produktu askok garapen-bankuetan erabiltzen saiatzeko itxaropentsu dirudi.
Uste dut etorkizunean ontziko emakume hau ondo etorriko dela!
PS
Irakurri ere gure blogean:
- «»;
- «»;
- «»;
- «'.
Iturria: www.habr.com
