

Usein tietotieteen alalle tulevilla ihmisillä on vähemmän realistisia odotuksia siitä, mikä heitä odottaa. Monet ihmiset ajattelevat, että nyt he kirjoittavat hienoja hermoverkkoja, luovat ääniavustajan Iron Manista tai lyövät kaikki rahoitusmarkkinoilla.
Mutta työtä Päiväys Tiedemies on datavetoinen, ja yksi tärkeimmistä ja aikaa vievistä näkökohdista on tietojen käsittely ennen sen syöttämistä neuroverkkoon tai analysointia tietyllä tavalla.
Tässä artikkelissa tiimimme kuvaa, kuinka voit käsitellä tietoja nopeasti ja helposti vaiheittaisten ohjeiden ja koodin avulla. Yritimme tehdä koodista melko joustavaa ja sitä voitaisiin käyttää erilaisiin tietokokonaisuuksiin.
Monet ammattilaiset eivät ehkä löydä tästä artikkelista mitään erikoista, mutta aloittelijat voivat oppia jotain uutta, ja jokainen, joka on pitkään haaveillut erillisen muistikirjan tekemisestä nopeaa ja jäsenneltyä tietojenkäsittelyä varten, voi kopioida koodin ja muotoilla sen itse, tai
Saimme tietojoukon. Mitä tehdä seuraavaksi?
Joten, standardi: meidän on ymmärrettävä, mitä olemme tekemisissä, kokonaiskuva. Tätä varten käytämme pandoja yksinkertaisesti määrittämään eri tietotyypit.
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения 
df.info() #Демонстрируем информацию о колонках 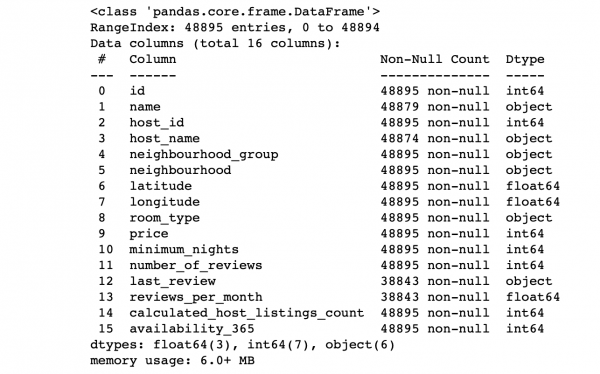
Katsotaanpa sarakkeiden arvoja:
- Vastaako kunkin sarakkeen rivien lukumäärä rivien kokonaismäärää?
- Mikä on kunkin sarakkeen tietojen ydin?
- Mihin sarakkeeseen haluamme kohdistaa ennusteita varten?
Vastaukset näihin kysymyksiin antavat sinun analysoida tietojoukon ja tehdä karkeasti suunnitelman tuleville toimillesi.
Voit myös tarkastella kunkin sarakkeen arvoja tarkemmin käyttämällä pandat description() -funktiota. Tämän toiminnon haittana on kuitenkin se, että se ei anna tietoa sarakkeista, joissa on merkkijonoarvoja. Käsittelemme niitä myöhemmin.
df.describe() 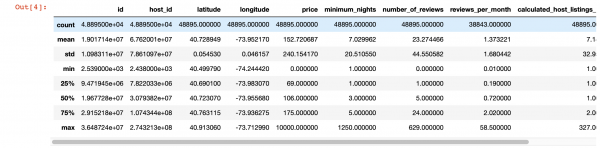
Maaginen visualisointi
Katsotaanpa, missä meillä ei ole arvoja ollenkaan:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis') 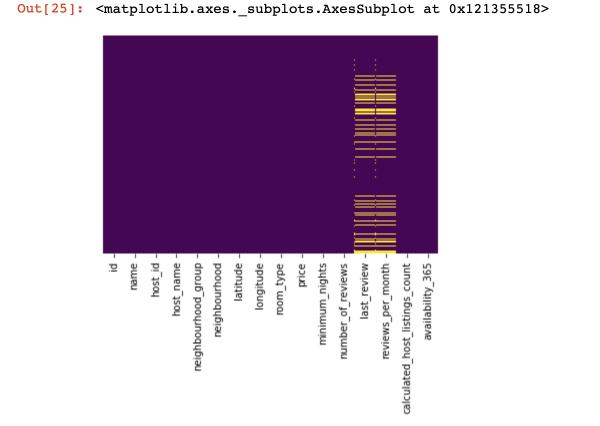
Tämä oli lyhyt katsaus ylhäältä, nyt siirrytään kiinnostavampiin asioihin
Yritetään etsiä ja, jos mahdollista, poistaa sarakkeita, joilla on vain yksi arvo kaikilla riveillä (ne eivät vaikuta tulokseen millään tavalla):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значенияNyt suojaamme itseämme ja projektimme menestystä päällekkäisiltä riveiltä (rivit, jotka sisältävät samat tiedot samassa järjestyksessä kuin yksi olemassa olevista riveistä):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.Jaamme tietojoukon kahteen: toiseen kvalitatiivisiin arvoihin ja toiseen kvantitatiivisiin arvoihin
Tässä meidän on tehtävä pieni selvennys: jos laadullisten ja kvantitatiivisten tietojen rivit, joilla on puuttuvia tietoja, eivät korreloi kovinkaan hyvin keskenään, meidän on päätettävä, mitä uhraamme - kaikki rivit, joista puuttuu tietoja, vain osa niistä, tai tietyt sarakkeet. Jos rivit korreloivat, meillä on täysi oikeus jakaa tietojoukko kahteen osaan. Muussa tapauksessa sinun on ensin käsiteltävä rivejä, jotka eivät korreloi puuttuvia tietoja laadullisesti ja määrällisesti, ja vasta sitten jakaa tietojoukko kahteen osaan.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Teemme tämän helpottaaksemme näiden kahden erityyppisen datan käsittelyä – myöhemmin ymmärrämme, kuinka paljon se helpottaa elämäämme.
Työskentelemme kvantitatiivisten tietojen kanssa
Ensimmäinen asia, joka meidän pitäisi tehdä, on määrittää, onko kvantitatiivisissa tiedoissa "vakoilusarakkeita". Kutsumme näitä sarakkeita sellaisiksi, koska ne esittävät itsensä kvantitatiivisena datana, mutta toimivat kvalitatiivisena datana.
Miten määrittelemme ne? Tietysti kaikki riippuu analysoimiesi tietojen luonteesta, mutta yleensä tällaisissa sarakkeissa voi olla vähän ainutlaatuista tietoa (noin 3–10 yksilöllistä arvoa).
print(df_numerical.nunique())Kun olemme tunnistaneet vakoilusarakkeet, siirrämme ne kvantitatiivisista tiedoista laadullisiin tietoihin:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данныеLopuksi olemme erottaneet kvantitatiiviset tiedot laadullisista tiedoista, ja nyt voimme työskennellä sen kanssa kunnolla. Ensimmäinen asia on ymmärtää, missä meillä on tyhjiä arvoja (NaN, ja joissakin tapauksissa 0 hyväksytään tyhjiksi arvoiksi).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())Tässä vaiheessa on tärkeää ymmärtää, missä sarakkeissa nollat voivat merkitä puuttuvia arvoja: johtuuko tämä siitä, miten tiedot kerättiin? Vai voisiko se liittyä tietoarvoihin? Näihin kysymyksiin on vastattava tapauskohtaisesti.
Joten jos päätämme edelleen, että meiltä saattaa puuttua tietoja, joissa on nollia, meidän tulee korvata nollat NaN:lla, jotta kadonneiden tietojen käsittely on myöhemmin helpompaa:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)Katsotaan nyt, mistä tiedot puuttuvat:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info() 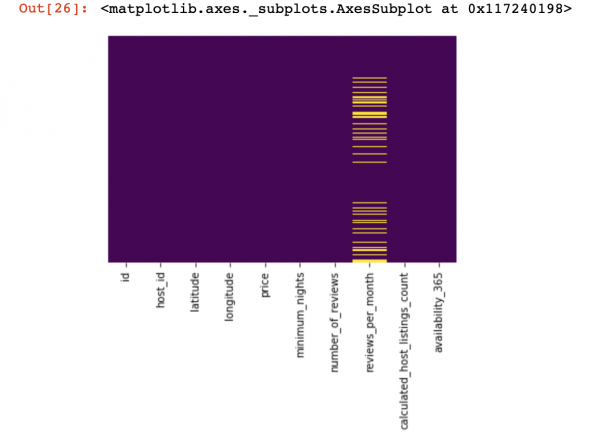
Tässä sarakkeiden sisältä puuttuvat arvot tulee merkitä keltaisella. Ja nyt alkaa hauskuus – kuinka käsitellä näitä arvoja? Pitäisikö minun poistaa näitä arvoja sisältävät rivit vai sarakkeet? Vai täyttääkö nämä tyhjät arvot muilla?
Tässä on likimääräinen kaavio, joka voi auttaa sinua päättämään, mitä voidaan periaatteessa tehdä tyhjillä arvoilla:
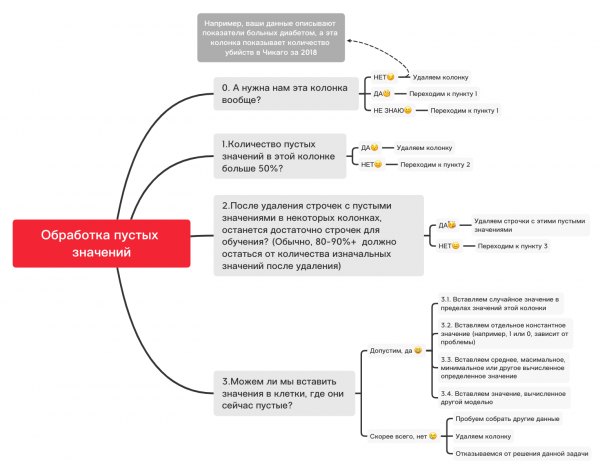
0. Poista tarpeettomat sarakkeet
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Onko tässä sarakkeessa olevien tyhjien arvojen määrä suurempi kuin 50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2. Poista tyhjät arvot sisältävät rivit
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1. Satunnaisen arvon lisääminen
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. Vakioarvon lisääminen
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. Lisää keskiarvo tai yleisin arvo
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4. Lisää toisen mallin laskema arvo
Joskus arvot voidaan laskea käyttämällä regressiomalleja käyttämällä malleja sklearn-kirjastosta tai muista vastaavista kirjastoista. Tiimimme omistaa erillisen artikkelin siitä, miten tämä voidaan tehdä lähitulevaisuudessa.
Joten toistaiseksi kvantitatiivisen tiedon kerronta keskeytyy, koska siinä on monia muita vivahteita, kuinka tiedon valmistelu ja esikäsittely eri tehtäviin voidaan tehdä paremmin, ja kvantitatiivisen tiedon perusasiat on tässä artikkelissa otettu huomioon, ja nyt on aika palata laadullisiin tietoihin, jotka erosimme määrällisistä tiedoista. Voit muuttaa tätä muistikirjaa haluamallasi tavalla mukauttamalla sitä erilaisiin tehtäviin, jotta tietojen esikäsittely sujuu erittäin nopeasti!
Laadulliset tiedot
Pohjimmiltaan kvalitatiivisille tiedoille käytetään One-hot-koodausmenetelmää sen muotoilemiseksi merkkijonosta (tai objektista) numeroksi. Ennen kuin siirrymme tähän kohtaan, käytetään yllä olevaa kaaviota ja koodia tyhjien arvojen käsittelyyn.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis') 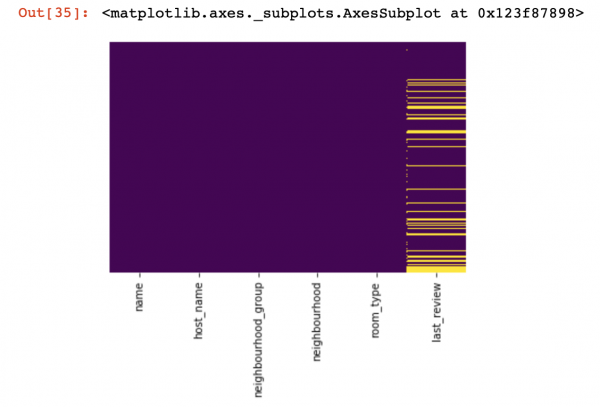
0. Poista tarpeettomat sarakkeet
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Onko tässä sarakkeessa olevien tyhjien arvojen määrä suurempi kuin 50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2. Poista tyhjät arvot sisältävät rivit
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1. Satunnaisen arvon lisääminen
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. Vakioarvon lisääminen
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)Joten, olemme vihdoin saaneet käsityksen laadullisten tietojen nollapisteistä. Nyt on aika suorittaa yhden kuuman koodaus tietokannassasi oleville arvoille. Tätä menetelmää käytetään hyvin usein varmistamaan, että algoritmisi voi oppia korkealaatuisista tiedoista.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Olemme siis vihdoin saaneet valmiiksi erillisten laadullisten ja määrällisten tietojen käsittelyn – on aika yhdistää ne takaisin
new_df = pd.concat([df_numerical,df_categorical], axis=1)Kun olemme yhdistäneet tietojoukot yhteen, voimme vihdoin käyttää tietojen muuntamista sklearn-kirjaston MinMaxScalerilla. Tämä tekee arvomme väliltä 0 ja 1, mikä auttaa mallin kouluttamisessa tulevaisuudessa.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Nämä tiedot ovat nyt valmiita kaikkeen - hermoverkkoihin, standardeihin ML-algoritmeihin jne.!
Tässä artikkelissa emme ottaneet huomioon työskentelyä aikasarjatietojen kanssa, koska tällaisille tiedoille tulisi käyttää hieman erilaisia käsittelytekniikoita tehtävästäsi riippuen. Jatkossa tiimimme omistaa tälle aiheelle erillisen artikkelin, ja toivomme, että se pystyy tuomaan jotain mielenkiintoista, uutta ja hyödyllistä elämääsi, kuten tämä.
Lähde: will.com
