


Tietokonenäön hermoverkot kehittyvät aktiivisesti, monet ongelmat ovat vielä kaukana ratkaisusta. Jos haluat olla alasi trendissä, seuraa vain vaikuttajia Twitterissä ja lue aiheeseen liittyviä artikkeleita arXiv.orgista. Mutta meillä oli mahdollisuus käydä International Conference on Computer Vision (ICCV) 2019. Tänä vuonna se järjestetään Etelä-Koreassa. Nyt haluamme jakaa Habr-lukijoiden kanssa, mitä näimme ja opimme.
Meitä oli paikalla paljon Yandexistä: paikalle tuli itseajavien autojen kehittäjiä, tutkijoita ja palveluissa CV-tehtävien parissa työskenteleviä. Mutta nyt haluamme esittää hieman subjektiivisen näkemyksen tiimistämme - Machine Intelligence Laboratorysta (Yandex MILAB). Muut kaverit luultavasti katsoivat konferenssia omasta näkökulmastaan.
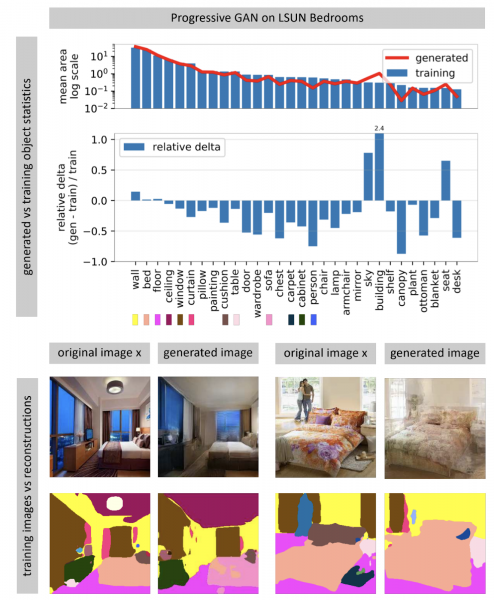
Mitä laboratorio tekee?Teemme kokeellisia projekteja, jotka liittyvät kuvien ja musiikin luomiseen viihdetarkoituksiin. Olemme erityisen kiinnostuneita hermoverkoista, joiden avulla voit muuttaa käyttäjän sisältöä (valokuvien kohdalla tätä tehtävää kutsutaan kuvankäsittelyksi). työmme tulos YaC 2019 -konferenssista.
Tieteellisiä konferensseja on paljon, mutta niistä nousevat esiin huippukokoukset, niin sanotut A*-konferenssit, joissa yleensä julkaistaan artikkeleita mielenkiintoisimmista ja tärkeimmistä teknologioista. Tarkkaa luetteloa A*-konferensseista ei ole, tässä on likimääräinen ja epätäydellinen luettelo: NeurIPS (entinen NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Kolme viimeistä ovat erikoistuneet CV-aiheeseen.
ICCV yhdellä silmäyksellä: julisteita, opetusohjelmia, työpajoja, osastot
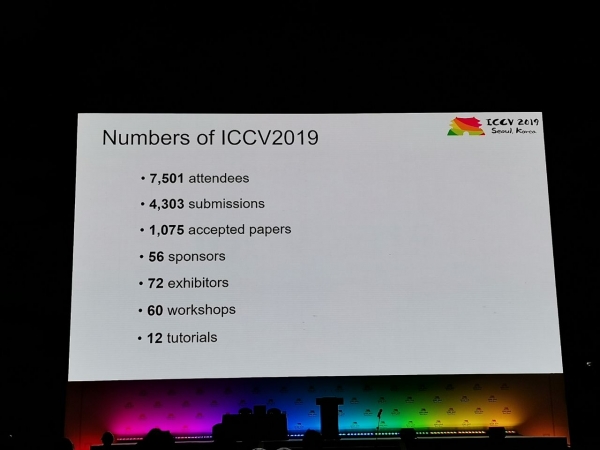
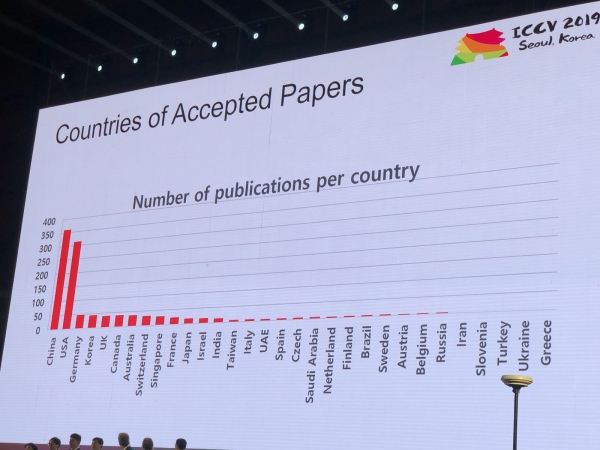
Konferenssiin saapui 1075 esitelmää, osallistujia oli 7500 Venäjältä, artikkeleita oli Yandexin, Skoltechin, Samsung AI Centerin ja Samaran yliopiston työntekijöiltä. Tänä vuonna ICCV:ssä ei vieraili paljon huippututkijoita, mutta esimerkiksi Aleksei (Alyosha) Efros, joka houkuttelee aina paljon ihmisiä:

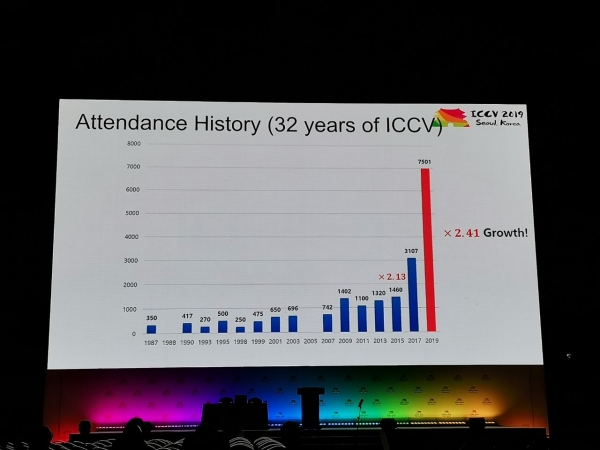
Tilastot 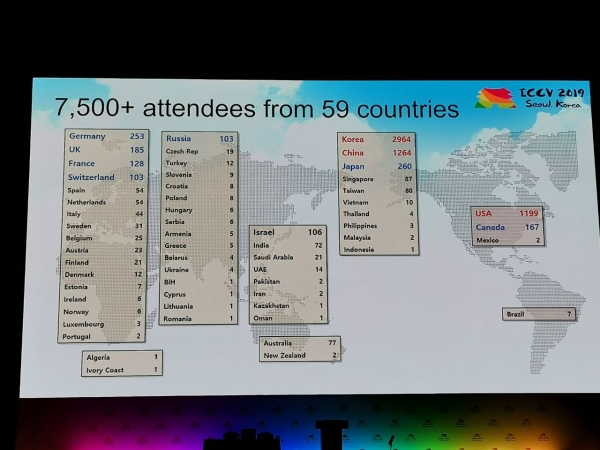

Kaikissa tällaisissa konferensseissa artikkelit esitetään julisteina ( formaatista), ja parhaat esitellään myös lyhyiden raporttien muodossa.
Tässä muutamia teoksia Venäjältä 


Opetusohjelmien avulla voit sukeltaa tiettyyn aihealueeseen, se muistuttaa luentoa yliopistossa. Sen lukee yksi henkilö, yleensä puhumatta yksittäisistä teoksista. Esimerkki hienosta opetusohjelmasta ():

Työpajoissa päinvastoin puhutaan artikkeleista. Yleensä nämä ovat teoksia jostain kapeasta aiheesta, laboratorioiden johtajien tarinoita kaikista opiskelijoiden uusimmista töistä tai artikkeleita, joita ei hyväksytty pääkonferenssiin.
Sponsoroivat yritykset tulevat ICCV:hen osastoilla. Tänä vuonna paikalle saapuivat Google, Facebook, Amazon ja monet muut kansainväliset yritykset sekä suuri määrä startuppeja - korealaisia ja kiinalaisia. Erityisen paljon startupeja oli datakoodaukseen erikoistuneita. Osastolla on esityksiä, voit ottaa kauppatavaraa ja kysyä. Metsästystarkoituksiin sponsoriyritykset järjestävät juhlia. Voit päästä niihin, jos vakuutat rekrytoijat kiinnostuksestasi ja siitä, että voit mahdollisesti läpäistä haastattelut. Jos olet julkaissut artikkelin (tai lisäksi esitellyt sen), aloittanut tai viimeistelemässä tohtorintutkintoa, tämä on plussaa, mutta joskus voit neuvotella osastolla esittämällä mielenkiintoisia kysymyksiä yrityksen insinööreille.
suuntaukset
Konferenssissa pääset tutustumaan koko CV-kenttään. Tiettyä aihetta koskevien julisteiden lukumäärän perusteella voit arvioida, kuinka kuuma aihe on. Jotkut johtopäätökset ehdottavat itseään avainsanojen perusteella:

Nolla-, kerta-, muutaman otoksen, itseohjattu ja puolivalvottu: uusia lähestymistapoja pitkään opittuihin tehtäviin
Ihmiset oppivat käyttämään dataa tehokkaammin. Esimerkiksi sisään on mahdollista luoda ilmeitä eläimistä, jotka eivät olleet koulutussarjassa (sovelluksessa tarjoamalla useita vertailukuvia). Deep Image Priorin ideoita on kehitetty, ja nyt GAN-verkkoja voidaan kouluttaa yhdelle kuvalle - puhumme tästä alla . Voit käyttää itsevalvontaa esiharjoitteluun (ratkaisemaan ongelma, jota varten voit syntetisoida kohdistettuja tietoja, kuten ennustaa kuvan kiertokulmaa) tai oppia samanaikaisesti merkityistä ja merkitsemättömistä tiedoista. Tässä mielessä artikkelia voidaan pitää luomisen kruununa . Ja tässä on esikoulutus ImageNetissä Se auttaa.

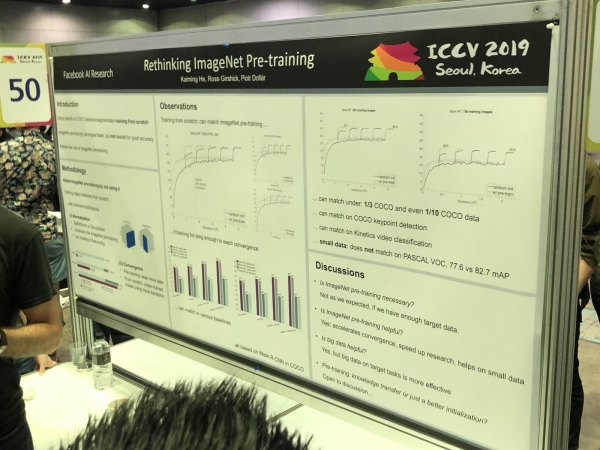
3D ja 360°
Enimmäkseen valokuvien osalta ratkaistut ongelmat (segmentointi, tunnistus) vaativat lisätutkimusta 3D-malleja ja panoraamavideoita varten. Olemme nähneet monia artikkeleita RGB:n ja RGB-D:n muuntamisesta 3D:ksi. Jotkut ongelmat, kuten ihmisen asennon estimointi, voidaan ratkaista luonnollisemmin siirtymällä 3D-malleihin. Mutta vielä ei ole yksimielisyyttä siitä, miten XNUMXD-malleja tarkalleen esitetään - verkon, pistepilven, vokseleiden tai SDF:n muodossa. Tässä on toinen vaihtoehto:
Panoraamoissa pallon mutaatiot kehittyvät aktiivisesti (katso. ) ja etsi kehyksen avainobjekteja.
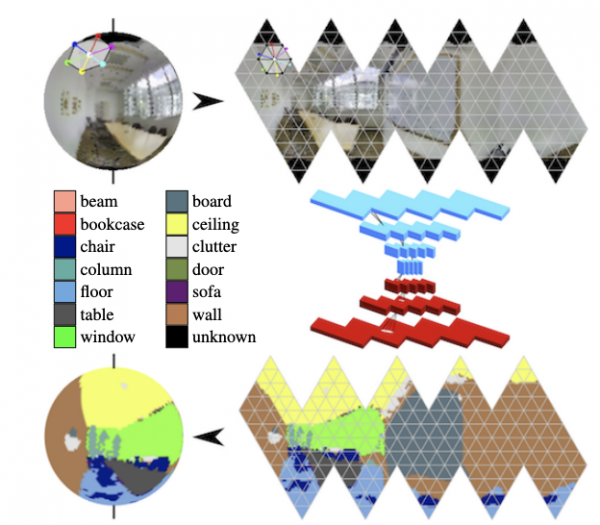
Asennontunnistus ja ihmisen liikkeen ennustaminen
Asennontunnistuksessa on jo edistytty 2D:ssä – nyt painopiste on siirtynyt useiden kameroiden kanssa työskentelemiseen ja 3D:hen. On myös mahdollista esimerkiksi havaita luuranko seinän läpi seuraamalla muutoksia Wi-Fi-signaalissa sen kulkiessa ihmiskehon läpi.
Käsin avainpisteiden tunnistuksen alalla on tehty paljon työtä. Uusia tietojoukkoja on ilmestynyt, mukaan lukien ne, jotka perustuvat kahden ihmisen dialogien videoihin – nyt voit ennustaa käden eleitä keskustelun äänen tai tekstin perusteella! Samaa edistystä on tapahtunut katseenseurantatehtävissä (katsomisen estimointi).

Voidaan myös tunnistaa suuri joukko ihmisen liikkeen ennustamiseen liittyviä teoksia (esim. tai ). Tehtävä on tärkeä ja sitä käytetään tekijöiden kanssa käytyjen keskustelujen perusteella useimmiten jalankulkijoiden käyttäytymisen analysointiin autonomisessa ajossa.
Manipulaatioita ihmisten kanssa valokuvissa ja videoissa, virtuaaliset sovitushuoneet
Päätrendi on muuttaa kasvokuvaa tulkittavissa olevien parametrien mukaan. Ideat: Deepfake yhden kuvan perusteella, ilmeen muuttaminen kasvojen renderöinnin perusteella (), eteenpäin - muuta parametreja (esim. ). Tyylin siirrot ovat siirtyneet aiheen otsikosta työn sovellukseen. Virtuaaliset sovitushuoneet ovat eri juttu, ne toimivat lähes aina huonosti, demot.


Sukupolvi luonnoksista/kaavioista
Idean "Anna ruudukon synnyttää jotain aikaisemman kokemuksen perusteella" kehitystyöstä tuli toinen: "Näytetään ruudukolle, mikä vaihtoehto kiinnostaa meitä."
mahdollistaa ohjatun maalauksen: käyttäjä voi maalata osan kasvoista kuvan poistetulle alueelle ja saada palautetun kuvan valmistumisesta riippuen.
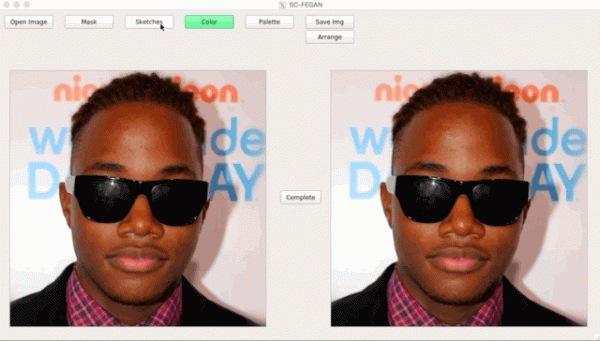
Yksi 25 Adoben ICCV-artikkelista yhdistää kaksi GAN:ia: toinen viimeistelee luonnoksen käyttäjälle, toinen luo luonnoksesta fotorealistisen kuvan ().
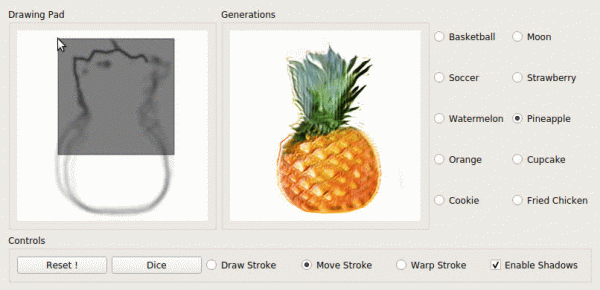
Aikaisemmin kuvaajia ei tarvittu kuvanluonnissa, mutta nyt niistä on tehty kohtauksen tiedon säiliö. Artikkeli voitti myös ICCV:n tuloksiin perustuvan Best Paper Honorable Mentions -palkinnon . Yleensä voit käyttää niitä eri tavoilla: luoda kaavioita kuvista tai kuvia ja tekstejä kaavioista.
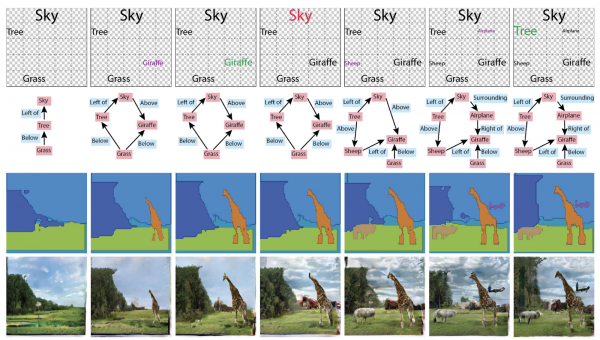
Ihmisten ja autojen tunnistaminen uudelleen, väkijoukon koon laskeminen (!)
Monet artikkelit on omistettu ihmisten jäljittämiseen ja ihmisten ja koneiden tunnistamiseen uudelleen. Mutta se, mikä yllätti meidät, oli joukko joukon laskemista koskevia artikkeleita, kaikki Kiinasta.
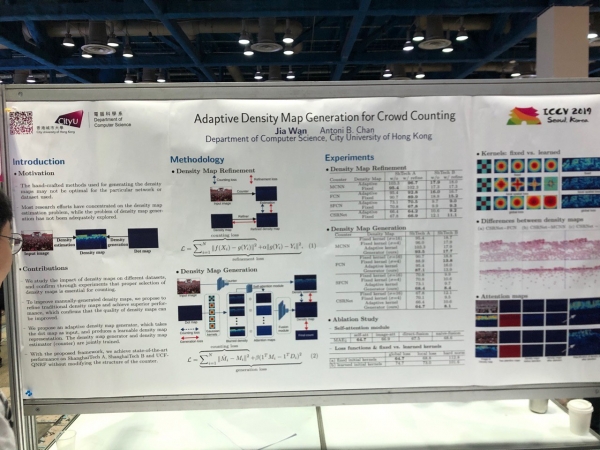
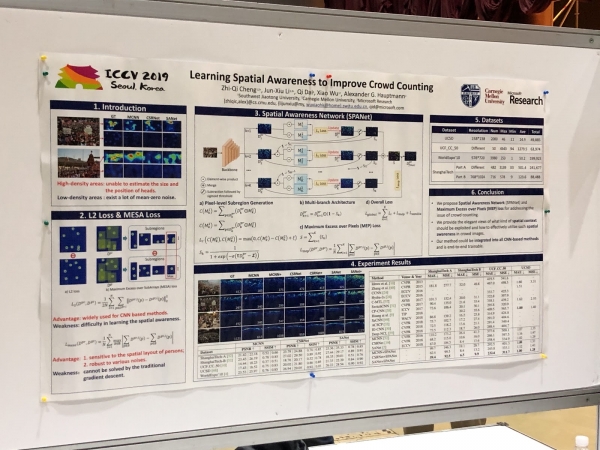
Julisteet 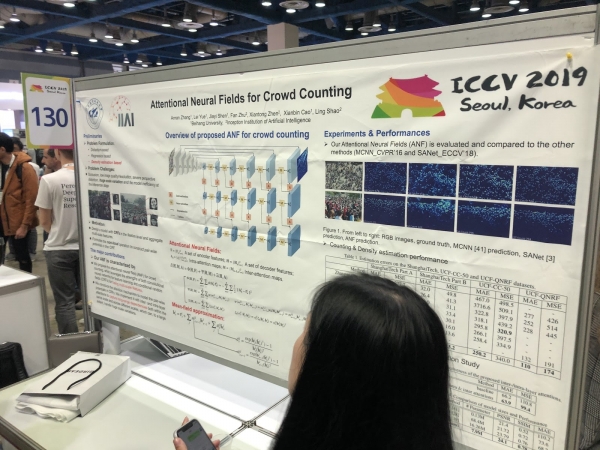


Mutta Facebook päinvastoin anonymisoi valokuvan. Ja se tekee tämän mielenkiintoisella tavalla: se kouluttaa hermoverkkoa luomaan kasvot ilman ainutlaatuisia yksityiskohtia - samanlaisia, mutta ei niin samanlaisia, että ne voidaan tunnistaa oikein kasvojentunnistusjärjestelmillä.

Suojaus vihollisia hyökkäyksiä vastaan
Kun tietokonenäkösovellukset kehittyvät todellisessa maailmassa (itseajavissa autoissa, kasvojentunnistuksessa), kysymys tällaisten järjestelmien luotettavuudesta nousee yhä enemmän esille. CV:n täysimääräinen käyttö edellyttää, että järjestelmä on vastustuskykyinen vastakkaisille hyökkäyksille – siksi niitä vastaan suojautumisesta ei ollut vähemmän artikkeleita kuin itse hyökkäyksistä. Verkoston ennusteiden (saliency map) selittämisessä ja tuloksen luottamuksen mittaamisessa on tehty paljon työtä.
Yhdistetyt tehtävät
Useimmissa yhden kohteen tehtävissä mahdollisuudet laadun parantamiseen ovat käytännössä loppuneet, yksi uusista suunnasta laadun edelleen nostamiseen on opettaa neuroverkkoja ratkaisemaan useita samanlaisia ongelmia samanaikaisesti. Esimerkkejä:
— toiminnan ennustaminen + optisen virtauksen ennustaminen,
- videoesitys + kieliesitys (),
- .
Siellä on myös artikkeleita segmentoinnista, asennon määrittämisestä ja eläinten uudelleentunnistamisesta!

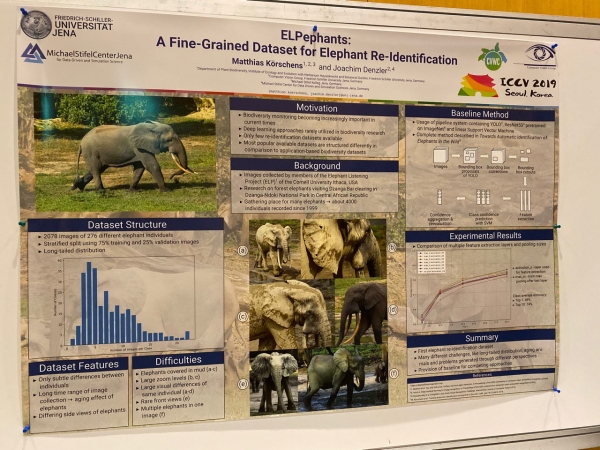
Kohokohdat
Lähes kaikki artikkelit olivat tiedossa etukäteen, teksti oli saatavilla osoitteessa arXiv.org. Siksi tällaisten teosten, kuten Everybody Dance Now, FUNIT, Image2StyleGAN, esittely vaikuttaa melko oudolta - nämä ovat erittäin hyödyllisiä teoksia, mutta eivät uusia. Näyttää siltä, että klassinen tieteellisten julkaisujen prosessi on täällä murtumassa - tiede etenee liian nopeasti.
Parhaita teoksia on erittäin vaikea määrittää - niitä on monia, aiheet ovat erilaisia. Useita artikkeleita vastaanotettu .
Haluamme tuoda esille teoksia, jotka ovat mielenkiintoisia kuvankäsittelyn näkökulmasta, koska tämä on aiheemme. Ne osoittautuivat meille melko tuoreiksi ja mielenkiintoisiksi (emme teeskentele objektiivisuutta).
SinGAN (paras paperipalkinto) ja InGAN
SinGAN: , , .
InGAN: , , .
Deep Imagen kehittäminen Dmitry Uljanovin, Andrea Vedaldin ja Victor Lempitskyn aiempi idea. Sen sijaan, että verkostot kouluttaisivat GANeja tietojoukossa, ne oppivat saman kuvan fragmenteista muistaakseen sen sisältämät tilastot. Koulutetun verkon avulla voit muokata ja animoida valokuvia (SinGAN) tai luoda minkä tahansa kokoisia uusia kuvia alkuperäisen kuvan tekstuurista säilyttäen paikallisen rakenteen (InGAN).
SinGAN:

InGAN:

Katso, mitä GAN ei voi luoda
.
Kuvia luovat hermoverkot ottavat usein syötteenä satunnaisen kohinan vektorin. Koulutetussa verkossa monet syöttövektorit muodostavat tilan, jota pitkin pienet liikkeet johtavat pieniin muutoksiin kuvassa. Optimoinnin avulla voit ratkaista käänteisen ongelman: löytää sopiva syöttövektori kuvalle todellisesta maailmasta. Kirjoittaja osoittaa, että hermoverkosta ei ole lähes koskaan mahdollista löytää täysin vastaavaa kuvaa. Joitakin kuvan objekteja ei luoda (ilmeisesti näiden objektien suuren vaihtelun vuoksi).
Kirjoittaja olettaa, että GAN ei kata koko kuvatilaa, vaan vain jotkin osajoukot, jotka ovat täynnä reikiä, kuten juustoa. Kun yritämme löytää siitä kuvia todellisesta maailmasta, epäonnistumme aina, koska GAN ei silti luo täysin aitoja valokuvia. Erot todellisten ja luotujen kuvien välillä voidaan voittaa vain muuttamalla verkon painoja, eli kouluttamalla se uudelleen tiettyä valokuvaa varten.

Kun verkko on lisäksi koulutettu tiettyä valokuvaa varten, voit kokeilla erilaisia käsittelyjä tällä kuvalla. Alla olevassa esimerkissä kuvaan lisättiin ikkuna ja verkko loi lisäksi heijastuksia keittiökalusteeseen. Tämä tarkoittaa, että verkko ei myöskään valokuvauksen lisäkoulutuksen jälkeen menettänyt kykyään nähdä yhteys kohtauksen kohteiden välillä.

GANalyze: Kohti kognitiivisen kuvan ominaisuuksien visuaalisia määritelmiä
, .
Tämän työn lähestymistapaa käyttämällä voit visualisoida ja analysoida, mitä hermoverkko on oppinut. Kirjoittajat ehdottavat, että GAN koulutetaan luomaan kuvia, joille verkko luo tietyt ennusteet. Artikkelissa käytettiin esimerkkeinä useita verkkoja, mukaan lukien MemNet, joka ennustaa valokuvien muistettavuutta. Kävi ilmi, että paremman muiston vuoksi valokuvan kohteen tulisi:
- olla lähempänä keskustaa
- on pyöreämpi tai neliömäisempi ja rakenteeltaan yksinkertainen,
- olla yhtenäisellä taustalla,
- sisältää ilmeikkäät silmät (ainakin koiravalokuvissa),
- olla kirkkaampi, kylläisempi, joissain tapauksissa punaisempi.

Liquid Warping GAN: yhtenäinen kehys ihmisen liikkeen jäljittelylle, ulkonäön siirrolle ja uudenlaisen näkymän synteesille
, , .
Kanava valokuvien luomiseen ihmisistä yksi kuva kerrallaan. Kirjoittajat näyttävät onnistuneita esimerkkejä ihmisen liikkeen siirtämisestä toiselle, vaatteiden siirtämisestä ihmisten välillä ja uusien näkökulmien luomisesta ihmisestä - kaikki yhdestä valokuvasta. Toisin kuin aikaisemmissa teoksissa, tässä emme käytä 2D:n avainpisteitä (ase), vaan kehon 3D-verkkoa (asento + muoto) olosuhteiden luomiseen. Tekijät keksivät myös kuinka siirtää tietoa alkuperäisestä kuvasta luotuun (Liquid Warping Block). Tulokset näyttävät hyviltä, mutta tuloksena olevan kuvan resoluutio on vain 256x256. Vertailun vuoksi todettakoon, että vuosi sitten ilmestynyt vid2vid pystyy generoimaan 2048x1024-resoluutiolla, mutta se vaatii aineistona jopa 10 minuuttia videotallennusta.

FSGAN: Subject Agnosttic Face Swapping and Reenactment
, .
Aluksi näyttää siltä, että ei ole mitään epätavallista: deepfake, jonka laatu on enemmän tai vähemmän normaali. Mutta työn tärkein saavutus on kasvojen korvaaminen yhdestä kuvasta. Toisin kuin aikaisemmissa töissä, koulutusta vaadittiin useisiin tietyn henkilön valokuviin. Liukulinja osoittautui hankalaksi (uudelleenesitys ja segmentointi, näkymäinterpolointi, maalaus, sekoitus) ja paljon teknisiä hakkereita, mutta tulos on sen arvoinen.

Odottamattoman havaitseminen kuvan uudelleensynteesin avulla
.
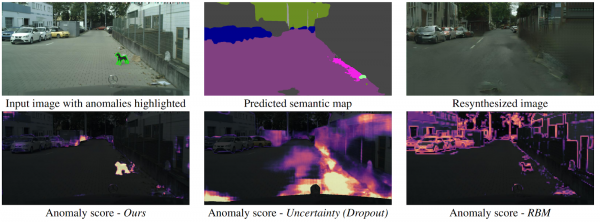
Kuinka drone voi ymmärtää, että sen eteen on yhtäkkiä ilmestynyt esine, joka ei kuulu mihinkään semanttiseen segmentointiluokkaan? On olemassa useita menetelmiä, mutta kirjoittajat ehdottavat uutta, intuitiivista algoritmia, joka toimii paremmin kuin edeltäjänsä. Semanttinen segmentointi ennustetaan tulotiekuvasta. Se syötetään tulona GAN:iin (pix2pixHD), joka yrittää palauttaa alkuperäisen kuvan vain semanttisesta kartasta. Poikkeamat, jotka eivät kuulu mihinkään segmenttiin, eroavat merkittävästi lähdöstä ja luodusta kuvasta. Kolme kuvaa (alkuperäinen, segmentoitu ja rekonstruoitu) syötetään sitten toiseen verkkoon, joka ennustaa poikkeavuuksia. Tietojoukko tätä varten luotiin tunnetusta Cityscapes-tietojoukosta, muuttamalla semanttisen segmentoinnin luokat satunnaisesti. Mielenkiintoista on, että tässä tilanteessa keskellä tietä seisova, mutta oikein segmentoitu koira (mikä tarkoittaa, että sille on luokka), ei ole poikkeama, koska järjestelmä pystyi tunnistamaan sen.
Johtopäätös
Ennen konferenssia on tärkeää tietää, mitkä ovat tieteelliset kiinnostuksen kohteesi, mihin esityksiin haluat osallistua ja kenelle puhua. Silloin kaikki on paljon tuottavampaa.
ICCV on ennen kaikkea verkostoitumista. Ymmärrät, että on olemassa huippuinstituutteja ja huipputieteellisiä osastoja, alat ymmärtää tämän, opit tuntemaan ihmisiä. Ja voit lukea artikkeleita arXivista - ja muuten, on erittäin siistiä, että sinun ei tarvitse mennä minnekään saadaksesi tietoa.
Lisäksi konferenssissa voit sukeltaa syvälle aiheisiin, jotka eivät ole sinua lähellä ja nähdä trendejä. No, kirjoita luettelo artikkeleista luettavaksi. Jos olet opiskelija, tämä on sinulle mahdollisuus tavata potentiaalinen opettaja, jos olet alalta, niin uuden työnantajan kanssa, ja jos olet yritys, niin esitellä itsesi.
Tilaa ! Tämä on henkilökohtainen projekti: johdamme sitä yhdessä . Julkaisimme täällä kaikki teokset, joista pidimme konferenssin aikana: .
Lähde: will.com
