

L'article se compose de deux parties :
- Une brève description de certaines architectures de réseau pour la détection d'objets dans les images et la segmentation d'images avec les liens les plus compréhensibles vers les ressources pour moi. J'ai essayé de choisir des explications vidéo et de préférence en russe.
- La deuxième partie est une tentative de comprendre la direction du développement des architectures de réseaux neuronaux. Et les technologies basées sur eux.

Figure 1 – Comprendre les architectures de réseaux de neurones n'est pas facile
Tout a commencé lorsque j'ai créé deux applications de démonstration pour la classification et la détection d'objets sur mon téléphone. Android:
- , lorsque les données sont traitées sur le serveur et transmises au téléphone. Classification d'images de trois types d'ours : brun, noir et peluche.
- lorsque les données sont traitées sur le téléphone lui-même. Détection d'objets (détection d'objets) de trois types : noisettes, figues et dattes.
Il existe une différence entre les tâches de classification d'images, de détection d'objets dans une image et . Il était donc nécessaire de découvrir quelles architectures de réseaux neuronaux détectent les objets dans les images et lesquelles peuvent les segmenter. J'ai trouvé les exemples d'architectures suivants avec les liens vers des ressources les plus compréhensibles pour moi :
- Une série d'architectures basées sur R-CNN (Rrégions avec Convolution Neuro Nfonctionnalités réseaux) : R-CNN, Fast R-CNN, , . Pour détecter un objet dans une image, des cadres de délimitation sont alloués à l'aide du mécanisme RPN (Region Proposal Network). Initialement, le mécanisme de recherche sélective, plus lent, était utilisé à la place du RPN. Ensuite, les régions limitées sélectionnées sont transmises à l'entrée d'un réseau neuronal conventionnel pour classification. L'architecture R-CNN comporte des boucles « pour » explicites sur des régions limitées, totalisant jusqu'à 2000 XNUMX exécutions via le réseau interne d'AlexNet. Les boucles « for » explicites ralentissent la vitesse de traitement des images. Le nombre de boucles explicites traversant le réseau neuronal interne diminue à chaque nouvelle version de l'architecture, et des dizaines d'autres modifications sont apportées pour augmenter la vitesse et remplacer la tâche de détection d'objets par la segmentation d'objets dans Mask R-CNN.
- (You Orien Look Once) est le premier réseau neuronal capable de reconnaître des objets en temps réel sur des appareils mobiles. Particularité : distinguer les objets en un seul passage (il suffit de regarder une fois). Autrement dit, dans l'architecture YOLO, il n'y a pas de boucles « pour » explicites, c'est pourquoi le réseau fonctionne rapidement. Par exemple, cette analogie : dans NumPy, lors de l'exécution d'opérations avec des matrices, il n'y a pas non plus de boucles « for » explicites, qui dans NumPy sont implémentées aux niveaux inférieurs de l'architecture via le langage de programmation C. YOLO utilise une grille de fenêtres prédéfinies. Pour éviter que le même objet soit défini plusieurs fois, le coefficient de chevauchement de fenêtre (IoU) est utilisé. Inintersection ovoir Union). Cette architecture fonctionne sur une large plage et présente des caractéristiques élevées : Un modèle peut être formé sur des photographies tout en restant performant sur des peintures dessinées à la main.
- (SIngle SMultiBox chaude Detector) – les « hacks » les plus réussis de l’architecture YOLO sont utilisés (par exemple, suppression non maximale) et de nouveaux sont ajoutés pour rendre le réseau neuronal plus rapide et plus précis. Particularité : distinguer les objets en une seule fois à l'aide d'une grille de fenêtres donnée (case par défaut) sur la pyramide d'images. La pyramide d'images est codée en tenseurs de convolution par des opérations successives de convolution et de pooling (avec l'opération max-pooling, la dimension spatiale diminue). De cette manière, les objets grands et petits sont déterminés en une seule fois sur le réseau.
- SSD mobile (MobileNetV2+ SSD) est une combinaison de deux architectures de réseaux neuronaux. Premier réseau fonctionne rapidement et augmente la précision de la reconnaissance. MobileNetV2 est utilisé à la place de VGG-16, qui était initialement utilisé dans . Le deuxième réseau SSD détermine l'emplacement des objets dans l'image.
- – un réseau neuronal très petit mais précis. En soi, cela ne résout pas le problème de la détection d’objets. Cependant, il peut être utilisé dans une combinaison de différentes architectures. Et utilisé dans les appareils mobiles. La particularité est que les données sont d'abord compressées dans quatre filtres convolutifs 1 × 1, puis développées en quatre filtres convolutifs 1 × 1 et quatre filtres convolutifs 3 × 3. Une telle itération de compression-expansion de données est appelée « module Fire ».
- (Semantic Image Segmentation with Deep Convolutional Nets) – segmentation des objets dans l’image. Une caractéristique distinctive de l'architecture est la convolution dilatée, qui préserve la résolution spatiale. Vient ensuite une étape de post-traitement des résultats utilisant un modèle graphique probabiliste (champ aléatoire conditionnel), qui permet de supprimer les petits bruits dans la segmentation et d'améliorer la qualité de l'image segmentée. Derrière le formidable nom de « modèle probabiliste graphique » se cache un filtre gaussien classique, approximé par cinq points.
- J'ai essayé de comprendre l'appareil (Coup unique Affinerment réseau neuronal pour objet Detection), mais je n’ai pas compris grand chose.
- J'ai également regardé comment fonctionne la technologie « attention » : , , . Une particularité de l'architecture « attention » est la sélection automatique des régions d'attention accrue dans l'image (RoI, Rles égions of Ininterest) à l’aide d’un réseau neuronal appelé Attention Unit. Les régions d'attention accrue sont similaires aux cadres de délimitation, mais contrairement à elles, elles ne sont pas fixes dans l'image et peuvent avoir des limites floues. Ensuite, à partir des régions d'attention accrue, des signes (caractéristiques) sont isolés, qui sont « nourris » vers des réseaux de neurones récurrents avec des architectures. . Les réseaux de neurones récurrents sont capables d'analyser la relation entre les caractéristiques d'une séquence. Les réseaux de neurones récurrents étaient initialement utilisés pour traduire du texte dans d'autres langues, et maintenant pour la traduction и .
En explorant ces architectures J'ai réalisé que je ne comprenais rien. Et ce n’est pas que mon réseau neuronal ait des problèmes avec le mécanisme d’attention. La création de toutes ces architectures s’apparente à une sorte de gigantesque hackathon, où les auteurs s’affrontent dans des hacks. Hack est une solution rapide à un problème logiciel difficile. Autrement dit, il n’existe aucun lien logique visible et compréhensible entre toutes ces architectures. Tout ce qui les unit, c'est un ensemble de hacks les plus réussis qu'ils empruntent les uns aux autres, plus un commun à tous. (erreur de rétropropagation, rétropropagation). Non ! On ne sait pas exactement quoi changer ni comment optimiser les réalisations existantes.
En raison du manque de connexion logique entre les hacks, ils sont extrêmement difficiles à mémoriser et à appliquer dans la pratique. Il s’agit d’une connaissance fragmentée. Au mieux, on se souvient de quelques moments intéressants et inattendus, mais la plupart de ce qui est compris et incompréhensible disparaît de la mémoire en quelques jours. Ce serait bien si dans une semaine vous vous souveniez au moins du nom de l'architecture. Mais plusieurs heures, voire jours de travail, ont été consacrés à lire des articles et à regarder des vidéos de critiques !
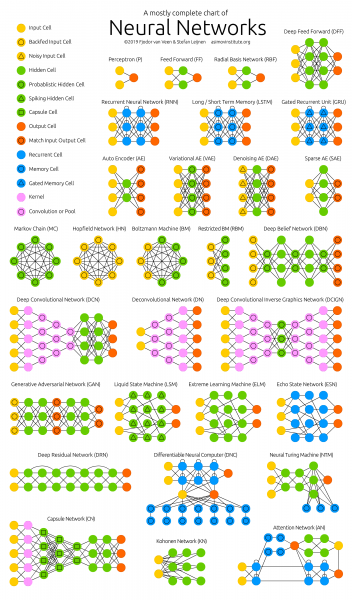
Figure 2 -
La plupart des auteurs d'articles scientifiques, à mon avis, font tout leur possible pour que même ces connaissances fragmentées ne soient pas comprises par le lecteur. Mais les phrases participatives dans des phrases de dix lignes avec des formules prises « de nulle part » font l'objet d'un article séparé (problème ).
Pour cette raison, il est nécessaire de systématiser l'information à l'aide de réseaux de neurones et ainsi d'augmenter la qualité de la compréhension et de la mémorisation. Par conséquent, le sujet principal de l'analyse des technologies individuelles et des architectures des réseaux de neurones artificiels était la tâche suivante : découvre où tout va, et non le périphérique d'un réseau neuronal spécifique séparément.
Où va tout cela ? Principaux résultats:
- Nombre de startups de machine learning au cours des deux dernières années . Raison possible : « les réseaux de neurones ne sont plus quelque chose de nouveau ».
- N’importe qui peut créer un réseau neuronal fonctionnel pour résoudre un problème simple. Pour ce faire, prenez un modèle prêt à l'emploi du « zoo modèle » et entraînez la dernière couche du réseau neuronal () sur des données prêtes à l'emploi de ou de En libre .
- Les grands fabricants de réseaux de neurones ont commencé à créer "zoos modèles" (zoo modèle). En les utilisant, vous pouvez créer rapidement une application commerciale : pour TensorFlow, pour PyTorch, pour Café2, pour Chainer et .
- Les réseaux de neurones travaillant dans temps réel (en temps réel) sur les appareils mobiles. De 10 à 50 images par seconde.
- L'utilisation des réseaux de neurones dans les téléphones (TF Lite), dans les navigateurs (TF.js) et dans (IdO, Internet of Tcharnières). Surtout dans les téléphones qui prennent déjà en charge les réseaux de neurones au niveau matériel (accélérateurs de neurones).
- « Chaque appareil, vêtement et peut-être même nourriture aura Adresse IP-v6 et communiquer les uns avec les autres" - .
- Le nombre de publications sur l’apprentissage automatique a commencé à augmenter (doublement tous les deux ans) depuis 2015. Évidemment, nous avons besoin de réseaux de neurones pour analyser les articles.
- Les technologies suivantes gagnent en popularité :
- PyTorch – la popularité augmente rapidement et semble dépasser TensorFlow.
- Sélection automatique des hyperparamètres AutoML – la popularité augmente doucement.
- Diminution progressive de la précision et augmentation de la vitesse de calcul : , algorithmes , calculs inexacts (approximatifs), quantification (lorsque les poids du réseau neuronal sont convertis en nombres entiers et quantifiés), accélérateurs neuronaux.
- La traduction и .
- création , maintenant en temps réel.
- L'essentiel à propos de DL est qu'il y a beaucoup de données, mais les collecter et les étiqueter n'est pas facile. Par conséquent, l'automatisation du balisage se développe () pour les réseaux de neurones utilisant des réseaux de neurones.
- Avec les réseaux de neurones, l'informatique est soudainement devenue science expérimentale et est apparu .
- L’argent des technologies de l’information et la popularité des réseaux neuronaux sont apparus simultanément lorsque l’informatique est devenue une valeur marchande. L’économie est en train de passer d’une économie d’or et de devises à informatique-monnaie-or. Voir mon article sur et la raison de l'apparition de l'argent informatique.
Petit à petit, un nouveau apparaît (Machine Learning & Deep Learning), qui repose sur la représentation du programme comme un ensemble de modèles de réseaux neuronaux entraînés.
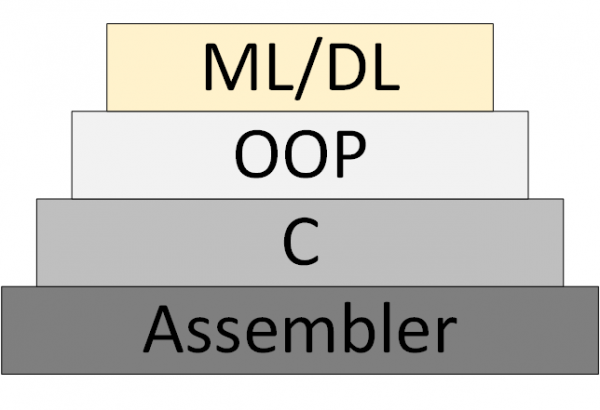
Figure 3 – ML/DL comme nouvelle méthodologie de programmation
Cependant, il n'est jamais apparu "théorie des réseaux neuronaux", au sein duquel vous pouvez réfléchir et travailler de manière systématique. Ce que l’on appelle aujourd’hui « théorie » est en réalité des algorithmes expérimentaux et heuristiques.
Liens vers mes ressources et d'autres :
- Newsletter sur la science des données. Principalement du traitement d'images. Toute personne souhaitant le recevoir doit envoyer un e-mail (foobar167<gaf-gaf>gmail<dot>com). J'envoie des liens vers des articles et des vidéos au fur et à mesure que le matériel s'accumule.
- Général que j'ai réussi et que j'aimerais réussir.
- , où vous devriez commencer à étudier les réseaux de neurones. Brochure Plus .
- , où chacun trouvera quelque chose d'intéressant pour lui-même.
- Nous les avons trouvés extrêmement utiles. chaînes vidéo pour l'analyse d'articles scientifiques par la science des données. Retrouvez-les, abonnez-vous et transmettez les liens à vos collègues et à moi aussi. Exemples:
- aka avec des instructions étape par étape et open source.
Je vous remercie!
Source: habr.com
