

Beidh an nóta seo ina ábhar spéise dóibh siúd a bhaineann úsáid as an leabharlann tháblach próiseála sonraí le haghaidh R - data.table, agus b’fhéidir go mbeadh siad sásta solúbthacht a úsáide a fheiceáil i samplaí éagsúla.
Spreagtha ag dea-shampla , agus ag súil go bhfuil a chuid alt léite agat cheana féin, molann mé tochailt níos doimhne i dtreo leas iomlán a bhaint cód agus feidhmíocht bunaithe ar sonraí.tábla.
Réamhrá: Cad as a dtagann data.table?
Is fearr dul i dtaithí ar an leabharlann beagán ó i bhfad, eadhon, leis na struchtúir sonraí ónar féidir an réad data.table (dá ngairfear DT anseo feasta).
Массив
Cód
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Struchtúr amháin den sórt sin is ea eagar (?bun::eagar). Mar atá i dteangacha eile, is eagair iltoiseacha iad seo. Mar sin féin, is é an rud suimiúil, mar shampla, go dtosaíonn eagar déthoiseach ar airíonna oidhreachta ón rang maitrís. (?bun::maitrís), agus eagar aontoiseach, atá tábhachtach freisin, nach bhfaigheann sé oidhreacht ó veicteoir (?bun::veicteoir).
Ba cheart a thuiscint gur cheart an cineál sonraí atá in aon réad a sheiceáil ag baint úsáide as an bhfeidhm bonn::typeof, a thugann tuairisc ar an gcineál inmheánach ar ais de réir R Inmheánach - prótacal ginearálta na teanga a bhaineann leis an mbunleagan C.
Ordú eile chun aicme ruda a chinneadh ná bonn::rang, i gcás veicteoirí, cuireann sé an cineál veicteora ar ais (tá sé difriúil ó thaobh ainm ón gceann inmheánach, ach ligeann sé duit an cineál sonraí a thuiscint freisin).
Liosta
Ó eagar déthoiseach, ar a dtugtar maitrís freisin, is féidir leat dul chuig an liosta (?bun::liosta).
Cód
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Tarlaíonn roinnt rudaí ag an am céanna:
- Titeann an dara toise den mhaitrís, is é sin, faigheann muid liosta agus veicteoir araon ag an am céanna.
- Mar sin tagann an liosta le hoidhreacht ó na haicmí seo. Ní mór a choinneáil i gcuimhne go gcomhfhreagróidh eilimint liosta do luach amháin (scalach) ó chill den mhaitrís eagair.
Toisc gur veicteoir é liosta freisin, is féidir roinnt feidhmeanna veicteora a chur i bhfeidhm air.
Fráma sonraí
Is féidir leat dul ó liosta, maitrís nó veicteoir go fráma sonraí (?Bunáit::data.frame).
Cód
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Cad atá suimiúil faoi: oidhreacht an fráma sonraí ón liosta! Is cealla liosta iad colúin dataframe. Beidh sé seo tábhachtach níos déanaí nuair a úsáidimid feidhmeanna a chuirtear i bhfeidhm ar liostaí.
sonraí.tábla
Faigh DT (?tábla.sonraí::tábla.sonraí) is féidir ó fráma sonraí, liosta, veicteoir nó maitrís. Mar shampla, mar seo (i bhfeidhm).
Cód
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Tá sé úsáideach, cosúil le fráma sonraí, go bhfaighidh DT airíonna liosta le hoidhreacht.
DT agus cuimhne
Murab ionann agus gach réad eile i mbonn R, seoltar DTanna trí thagairt. Más gá duit cóip a dhéanamh chuig limistéar cuimhne nua, beidh feidhm uait data.table::cóip nó caithfidh tú rogha a dhéanamh ón seanréad.
Cód
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Críochnaíonn sé seo an réamhrá. Leanann DT le forbairt struchtúir sonraí i R, a tharlaíonn go príomha mar gheall ar leathnú agus luasghéarú na n-oibríochtaí a dhéantar ar rudaí den rang fráma sonraí. Ag an am céanna, caomhnaítear oidhreacht ó phrimitives eile.
Roinnt samplaí de úsáid a bhaint as airíonna data.table
Cosúil le liosta...
Ní smaoineamh maith é atriallú thar na sraitheanna de fhráma sonraí nó DT, ós rud é go bhfuil an cód lúb sa teanga R i bhfad níos moille C, ach is féidir go leor lúbadh trí na colúin, a bhíonn i bhfad níos lú de ghnáth. Ag dul tríd na colúin, cuimhnigh gur eilimint de liosta é gach colún, ina bhfuil veicteoir de ghnáth. Agus tá oibríochtaí ar veicteoirí veicteoirithe go maith i bhfeidhmeanna bunúsacha na teanga. Is féidir leat oibreoirí roghnúcháin a bhaineann le liostaí agus veicteoirí a úsáid freisin: `[[`, `$`.
Cód
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Veicteoiriú
Más gá dul trí línte DT mór, is é an réiteach is fearr ná feidhm a scríobh le veicteoiriú. Ach más rud é nach bhfuil sé seo ag obair, ansin ba chóir duit cuimhneamh go bhfuil an timthriall laistigh Tá DT fós níos tapúla ná an timthriall R, ós rud é go ndéantar é ar C.
Déanaimis iarracht é ar shampla níos mó le sraitheanna 100K. Bainfimid an chéad litir as na focail atá sa cholún veicteora w.
Nuashonraithe
Cód
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
An chéad rith ag atriall thar sraitheanna:
Aonad: milleasoicindí
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", seasta = T))[1]), le = 1:nrow(dt)] } 439.6217
lq meán airmheán uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
An dara rith, áit a dtarlaíonn veicteoiriú tríd an liosta a iompú ina mhaitrís agus gnéithe a ghlacadh ar an tslis le hinnéacs 1 (is é an veicteoiriú féin an dara ceann). Ceartú: veicteoiriú ag an leibhéal feidhme strscoilt, atá in ann glacadh le veicteoir mar ionchur. Tharlaíonn sé go raibh an nós imeachta chun liosta a iompú isteach i maitrís i bhfad níos deacra ná an veicteoiriú féin, ach sa chás seo tá sé i bhfad níos tapúla ná an leagan neamh-veicteoraithe.
Aonad: milleasoicindí
expr min lq meán airmheán uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Luasghéarú de réir airmheán i Amanna 3.
An tríú rith, áit ar athraíodh an scéim claochlaithe isteach sa mhaitrís.
Aonad: milleasoicindí
expr min lq meán airmheán uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))) } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Luasghéarú de réir airmheán i Amanna 13.
Ní mór duit triail a bhaint as an ábhar seo, is amhlaidh is mó, is amhlaidh is fearr a bheidh sé.
Sampla eile le veicteoiriú, áit a bhfuil téacs freisin, ach tá sé gar do choinníollacha fíor: faid éagsúla focal, líon difriúil focal. Caithfidh tú an chéad 3 fhocal a fháil. Mar seo:
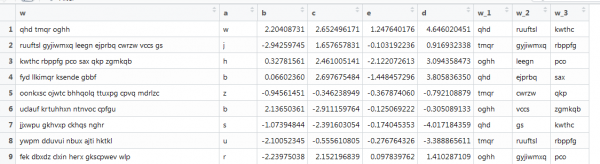
Anseo ní oibríonn an fheidhm roimhe seo, ós rud é go bhfuil na veicteoirí faid éagsúla, agus socróimid an méid maitrís. Déanaimis é seo arís trí thochailt a dhéanamh ar an Idirlíon.
Cód
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Aonad: milleasoicindí
expr min lq mean airmheán
{ dt[, `:=`((greamaigh0("w_", 1:3)), strsplit(w, scoilt = " ", seasta = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Rith an script ar mheánluas 1 soicind. Ní dona.
Ceangailte le slabhra amháin...
Is féidir leat oibriú le rudaí DT ag baint úsáide as slabhraithe. Breathnaíonn sé cosúil le comhréir lúibíní a cheangal ar dheis, go bunúsach siúcra.
Cód
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Ag sileadh tríd na píopaí...
Is féidir na hoibríochtaí céanna a dhéanamh trí phíobáin, tá cuma an-chosúil air, ach tá sé níos saibhre ó thaobh feidhme, toisc gur féidir leat aon mhodhanna a úsáid, ní hamháin DT. Déanaimis comhéifeachtaí aischéimniúcháin lóistíochta a dhíorthú dár sonraí sintéiseacha le roinnt scagairí ar DT.
Cód
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Staitisticí, meaisínfhoghlaim agus níos mó taobh istigh de DT
Is féidir leat feidhmeanna lambda a úsáid, ach uaireanta tá sé níos fearr iad a chruthú ar leithligh, an píblíne anailíse sonraí iomlán a scríobh, agus dul ar aghaidh - oibríonn siad taobh istigh den DT. Saibhrítear an sampla leis na gnéithe thuas go léir, chomh maith le roinnt rudaí úsáideacha ón Arsenal DT (amhail rochtain a fháil ar an DT féin taobh istigh den DT trí nasc, uaireanta a chuirtear isteach ní go seicheamhach, ach ionas go mbeidh sé).
Cód
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
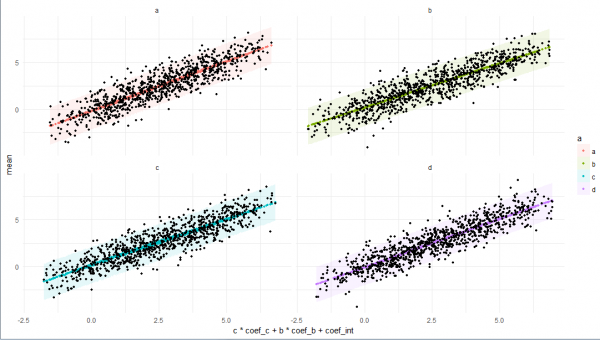
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Conclúid
Tá súil agam go raibh mé in ann pictiúr iomlán, ach, ar ndóigh, nach bhfuil iomlán, a chruthú de rud den sórt sin mar data.table, ag tosú óna airíonna a bhaineann le hoidhreacht ó ranganna R agus ag críochnú lena ghnéithe agus a thimpeallacht féin ó eilimintí slachtmhara. . Tá súil agam go gcabhróidh sé seo leat an leabharlann seo a fhoghlaim agus a úsáid níos fearr le haghaidh oibre agus siamsaíochta.
Go raibh maith agat!
Cód iomlán
Cód
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Foinse: will.com
