

Se ao comezo da obra dis que hai código C++ colgado na parede, ao final está obrigado a dispararche no pé.
Bjarne Stroustrup
Do 31 de outubro ao 1 de novembro, celebrouse en San Petersburgo a conferencia C++ Russia Piter, unha das conferencias de programación a gran escala en Rusia, organizadas polo Grupo JUG Ru. Entre os relatores convidados figuran membros do Comité de Estándares de C++, relatores de CppCon, autores de libros de O'Reilly e mantedores de proxectos como LLVM, libc++ e Boost. A conferencia está dirixida a desenvolvedores C++ experimentados que queiran afondar na súa experiencia e intercambiar experiencias en comunicación en directo. Os estudantes, estudantes de posgrao e profesores universitarios teñen descontos moi agradables.
A edición de Moscova da conferencia poderá visitarse xa en abril do próximo ano, pero mentres tanto os nosos alumnos contarán que cousas interesantes aprenderon no último evento.

Foto de
Quen somos
Dous estudantes da National Research University Higher School of Economics - San Petersburgo traballaron nesta publicación:
- Liza Vasilenko é unha estudante de 4º curso que estuda Linguaxes de Programación como parte do programa de Matemáticas Aplicadas e Informática. Despois de familiarizarme coa linguaxe C++ no meu primeiro ano na universidade, posteriormente gañei experiencia traballando con el a través de prácticas na industria. A paixón polas linguaxes de programación en xeral e a programación funcional en particular deixou pegada na elección dos relatorios da conferencia.
- Danya Smirnov é estudante de 1º curso do máster "Programación e Análise de Datos". Mentres aínda estaba na escola, escribín os problemas das Olimpiadas en C++, e entón ocorreu que a lingua apareceu constantemente nas actividades educativas e, finalmente, converteuse na principal lingua de traballo. Decidín participar nas xornadas para mellorar os meus coñecementos e tamén coñecer novas oportunidades.
No boletín, a dirección da facultade adoita compartir información sobre eventos educativos relacionados coa nosa especialidade. En setembro vimos información sobre C++ Rusia e decidimos rexistrarnos como oíntes. Esta é a nosa primeira experiencia de participar neste tipo de conferencias.
Estrutura da conferencia
Informes
Ao longo de dous días, os expertos leron 30 informes, que abarcaban moitos temas candentes: usos enxeñosos de funcións lingüísticas para resolver problemas aplicados, próximas actualizacións lingüísticas en relación co novo estándar, compromisos no deseño de C++ e precaucións ao traballar coas súas consecuencias, exemplos. de arquitectura de proxecto interesante, así como algúns detalles subterráneos da infraestrutura lingüística. Realizáronse tres actuacións simultáneamente, a maioría das veces dúas en ruso e unha en inglés.
Zonas de debate
Despois do discurso, todas as preguntas non formuladas e as discusións sen rematar foron trasladadas a áreas especialmente designadas para a comunicación cos relatores, equipadas con cadros marcadores. Unha boa forma de pasar o descanso entre discursos cunha conversa agradable.
Charlas Lightning e discusións informais
Se queres facer un breve informe, podes rexistrarte no encerado para a charla Lightning Talk da noite e ter cinco minutos de tempo para falar sobre calquera cousa sobre o tema da conferencia. Por exemplo, unha rápida introdución aos desinfectantes para C++ (para algúns era novo) ou unha historia sobre un erro na xeración de onda sinusoidal que só se pode escoitar, pero non ver.
Outro formato é a mesa de debate "Con un comité de corazón a corazón". No escenario hai algúns membros do comité de normalización, no proxector hai unha lareira (oficialmente - para crear unha atmosfera sincera, pero a razón "porque TODO ESTÁ A LUME" parece máis divertida), preguntas sobre o estándar e a visión xeral de C++ , sen acaloradas discusións técnicas e holiwars. Resultou que o comité tamén contén persoas vivas que poden non estar completamente seguras de algo ou non saben algo.
Para os fanáticos dos holivars, o terceiro evento permaneceu no caso: a sesión BOF "Go vs. C++". Levamos un amante de Go, un amante de C++, antes de comezar a sesión preparan xuntos 100500 diapositivas sobre un tema (como problemas cos paquetes en C++ ou a falta de xenéricos en Go), e despois teñen unha animada discusión entre eles e co público, e o público trata de comprender dous puntos de vista á vez. Se un holivar comeza fóra de contexto, o moderador intervén e concilia as partes. Este formato é adictivo: varias horas despois do inicio, só se completaron a metade das diapositivas. Había que acelerar moito o final.
Stands de socios
Os socios das xornadas estiveron representados nos salóns -nos stands falaron de proxectos actuais, ofreceron prácticas e emprego, realizaron concursos e pequenos concursos e tamén sortearon bonitos premios. Ao mesmo tempo, algunhas empresas incluso ofreceron pasar polas fases iniciais das entrevistas, o que podería ser útil para quen acudía non só para escoitar reportaxes.
Detalles técnicos dos informes
Escoitamos informes os dous días. Ás veces era difícil escoller un informe entre os paralelos: acordamos dividirnos e intercambiar os coñecementos adquiridos nos recreos. E aínda así, parece que queda moito fóra. Aquí queremos falar dos contidos dalgunhas das reportaxes que nos pareceron máis interesantes
Excepcións en C++ a través do prisma das optimizacións do compilador, Roman Rusyaev
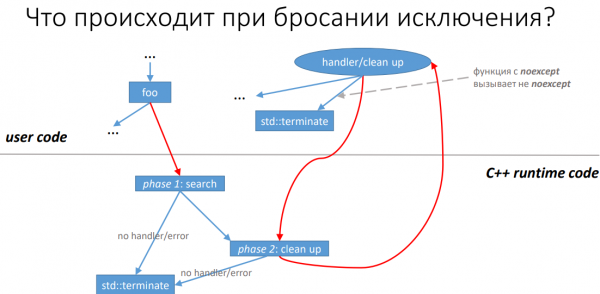
Desliza desde
Como suxire o título, Roman considerou traballar con excepcións usando LLVM como exemplo. Ao mesmo tempo, para aqueles que non usan Clang no seu traballo, o informe aínda pode dar algunha idea de como se podería optimizar o código. Isto é así porque os desenvolvedores de compiladores e as correspondentes bibliotecas estándar comunícanse entre si e moitas solucións exitosas poden coincidir.
Entón, para xestionar unha excepción, cómpre facer moitas cousas: chamar ao código de manexo (se o hai) ou aos recursos gratuítos no nivel actual e subir a pila máis arriba. Todo isto leva ao feito de que o compilador engade instrucións adicionais para chamadas que potencialmente xeran excepcións. Polo tanto, se a excepción non se levanta realmente, o programa seguirá realizando accións innecesarias. Para reducir dalgún xeito a sobrecarga, LLVM ten varias heurísticas para determinar situacións nas que non é necesario engadir código de manexo de excepcións ou se pode reducir o número de instrucións "extra".
O relator examina preto dunha ducia deles e mostra tanto situacións nas que axudan a acelerar a execución do programa, como aquelas nas que estes métodos non son aplicables.
Así, Roman Rusyaev leva aos estudantes á conclusión de que o código que contén o manexo de excepcións non sempre se pode executar sen sobrecarga cero e dá os seguintes consellos:
- á hora de desenvolver bibliotecas, paga a pena abandonar as excepcións en principio;
- se aínda son necesarias excepcións, sempre que sexa posible paga a pena engadir modificadores noexcept (e const) en todas partes para que o compilador poida optimizar o máximo posible.
En xeral, o relator confirmou a opinión de que as excepcións son mellor empregadas ao mínimo ou abandonadas por completo.
As diapositivas do informe están dispoñibles na seguinte ligazón:
Xeradores, corrutinas e outras dozuras para desenrolar o cerebro, Adi Shavit

Desliza desde
Un dos moitos relatorios desta conferencia dedicada ás innovacións en C++20 foi memorable non só pola súa colorida presentación, senón tamén pola súa clara identificación dos problemas existentes coa lóxica de procesamento da colección (for loop, callbacks).
Adi Shavit destaca o seguinte: os métodos actualmente dispoñibles pasan por toda a colección e non proporcionan acceso a algún estado intermedio interno (ou si o fan no caso das devolucións de chamada, pero cunha gran cantidade de efectos secundarios desagradables, como Callback Hell) . Parece que hai iteradores, pero aínda con eles non todo é tan suave: non hai puntos comúns de entrada e saída (begin → end versus rbegin → rend etc), non está claro canto tempo iteraremos? A partir de C++20, estes problemas están resoltos!
Primeira opción: rangos. Ao envolver os iteradores, obtemos unha interface común para o inicio e o final dunha iteración e tamén temos a capacidade de compoñer. Todo isto facilita a creación de pipelines de procesamento de datos completos. Pero non todo é tan suave: parte da lóxica de cálculo sitúase dentro da implementación dun iterador específico, o que pode complicar a comprensión e depuración do código.

Desliza desde
Ben, para este caso, C++20 engadiu corrutinas (funcións cuxo comportamento é semellante aos xeradores en Python): a execución pódese aprazar devolvendo algún valor actual mantendo un estado intermedio. Así, conseguimos non só traballar cos datos tal e como aparecen, senón tamén encapsular toda a lóxica dentro dunha corrutina específica.
Pero hai unha mosca no ungüento: polo momento só están parcialmente compatibles cos compiladores existentes e tampouco están implementados tan ben como nos gustaría: por exemplo, aínda non paga a pena usar referencias e obxectos temporais en corrutinas. Ademais, hai algunhas restricións sobre o que poden ser corrutinas, e as funcións constexpr, os construtores/destrutores e os main non están incluídos nesta lista.
Así, as corrutinas resolven unha parte importante dos problemas coa sinxeleza da lóxica de procesamento de datos, pero as súas implementacións actuais requiren melloras.
Materiais:
- Diapositivas de C++ Rusia -
Trucos C++ de Yandex.Taxi, Anton Polukhin
Nas miñas actividades profesionais, ás veces teño que implementar cousas puramente auxiliares: un envoltorio entre a interface interna e a API dalgunha biblioteca, rexistro ou análise. Neste caso, normalmente non hai necesidade de optimización adicional. Pero e se estes compoñentes se usan nalgúns dos servizos máis populares de RuNet? En tal situación, terás que procesar só terabytes por hora de rexistros. Entón cada milisegundo conta e, polo tanto, tes que recorrer a varios trucos - Anton Polukhin falou sobre eles.
Quizais o exemplo máis interesante foi a implementación do patrón pointer-to-implementation (pimpl).
#include <third_party/json.hpp> //PROBLEMS!
struct Value {
Value() = default;
Value(Value&& other) = default;
Value& operator=(Value&& other) = default;
~Value() = default;
std::size_t Size() const { return data_.size(); }
private:
third_party::Json data_;
};Neste exemplo, primeiro quero desfacerme dos ficheiros de cabeceira das bibliotecas externas; isto compilarase máis rápido e pode protexerse de posibles conflitos de nomes e outros erros similares.
Está ben, movemos #include ao ficheiro .cpp: necesitamos unha declaración de avance da API integrada, así como std::unique_ptr. Agora temos asignacións dinámicas e outras cousas desagradables, como datos espallados por unha morea de datos e garantías reducidas. std::aligned_storage pode axudar con todo isto.
struct Value {
// ...
private:
using JsonNative = third_party::Json;
const JsonNative* Ptr() const noexcept;
JsonNative* Ptr() noexcept;
constexpr std::size_t kImplSize = 32;
constexpr std::size_t kImplAlign = 8;
std::aligned_storage_t<kImplSize, kImplAlign> data_;
};O único problema: necesitamos especificar o tamaño e o aliñamento para cada envoltorio: fagamos o noso modelo de pimpl cos parámetros , usemos algúns valores arbitrarios e engadamos unha comprobación ao destrutor de que adiviñamos todo ben. :
~FastPimpl() noexcept {
validate<sizeof(T), alignof(T)>();
Ptr()->~T();
}
template <std::size_t ActualSize, std::size_t ActualAlignment>
static void validate() noexcept {
static_assert(
Size == ActualSize,
"Size and sizeof(T) mismatch"
);
static_assert(
Alignment == ActualAlignment,
"Alignment and alignof(T) mismatch"
);
}Dado que T xa está definido ao procesar o destrutor, este código analizarase correctamente e na fase de compilación sairá o tamaño necesario e os valores de aliñamento que deben introducirse como erros. Así, ao custo dunha execución de compilación adicional, deshacémonos da asignación dinámica das clases envolventes, ocultamos a API nun ficheiro .cpp coa implementación e tamén obtemos un deseño máis axeitado para o almacenamento na caché do procesador.
O rexistro e a análise parecían menos impresionantes e, polo tanto, non se mencionarán nesta revisión.
As diapositivas do informe están dispoñibles na seguinte ligazón:
Técnicas modernas para manter o teu código SECO, Björn Fahller
Nesta charla, Björn Fahller mostra varias formas diferentes de combater a falla estilística das comprobacións repetidas de condicións:
assert(a == IDLE || a == CONNECTED || a == DISCONNECTED);Soa familiar? Usando varias técnicas C++ potentes introducidas nos estándares recentes, pode implementar elegantemente a mesma funcionalidade sen ningunha penalización de rendemento. Comparar:
assert(a == any_of(IDLE, CONNECTED, DISCONNECTED));Para xestionar un número non fixado de comprobacións, cómpre usar inmediatamente modelos variadic e expresións dobradas. Supoñamos que queremos comprobar a igualdade de varias variables co elemento state_type da enumeración. O primeiro que se me ocorre é escribir unha función auxiliar is_any_of:
enum state_type { IDLE, CONNECTED, DISCONNECTED };
template <typename ... Ts>
bool is_any_of(state_type s, const Ts& ... ts) {
return ((s == ts) || ...);
}
Este resultado intermedio é decepcionante. Ata agora o código non se está facendo máis lexible:
assert(is_any_of(state, IDLE, DISCONNECTING, DISCONNECTED)); Os parámetros do modelo non tipo axudarán a mellorar un pouco a situación. Coa súa axuda, transferiremos os elementos enumerables da enumeración á lista de parámetros do modelo:
template <state_type ... states>
bool is_any_of(state_type t) {
return ((t == states) | ...);
}
assert(is_any_of<IDLE, DISCONNECTING, DISCONNECTED>(state)); Ao usar auto nun parámetro de modelo non tipo (C++17), o enfoque simplemente xeneraliza a comparacións non só con elementos state_type, senón tamén con tipos primitivos que se poden usar como parámetros de modelo non tipo:
template <auto ... alternatives, typename T>
bool is_any_of(const T& t) {
return ((t == alternatives) | ...);
}A través destas sucesivas melloras, conséguese a sintaxe fluída desexada para as comprobacións:
template <class ... Ts>
struct any_of : private std::tuple<Ts ...> {
// поленимся и унаследуем конструкторы от tuple
using std::tuple<Ts ...>::tuple;
template <typename T>
bool operator ==(const T& t) const {
return std::apply(
[&t](const auto& ... ts) {
return ((ts == t) || ...);
},
static_cast<const std::tuple<Ts ...>&>(*this));
}
};
template <class ... Ts>
any_of(Ts ...) -> any_of<Ts ... >;
assert(any_of(IDLE, DISCONNECTING, DISCONNECTED) == state);
Neste exemplo, a guía de dedución serve para suxerir os parámetros de modelo de estrutura desexados ao compilador, que coñece os tipos de argumentos do construtor.
Ademais - máis interesante. Bjorn ensina a xeneralizar o código resultante para operadores de comparación máis aló de ==, e despois para operacións arbitrarias. Ao longo do camiño, explícanse características como o atributo no_unique_address (C++20) e os parámetros de modelo en funcións lambda (C++20) mediante exemplos de uso. (Si, agora a sintaxe lambda é aínda máis fácil de lembrar: son catro pares consecutivos de parénteses de todo tipo.) A solución final que usa funcións como detalles do construtor realmente quenta a miña alma, sen esquecer a expresión tupla nas mellores tradicións de lambda. cálculo.
Ao final, non esquezas pulilo:
- Lembra que as lambdas son constexpr gratis;
- Engademos o reenvío perfecto e vexamos a súa sintaxe fea en relación co paquete de parámetros no peche lambda;
- Imos darlle ao compilador máis oportunidades para optimizacións con noexcept condicional;
- Coidemos a saída de erros máis comprensibles nos modelos grazas aos valores de retorno explícitos das lambdas. Isto obrigará ao compilador a facer máis comprobacións antes de que se chame realmente a función do modelo, na fase de verificación de tipo.
Para obter máis información, consulte os materiais da charla:
- Informe de diapositivas:
As nosas impresións
A nosa primeira participación en C++ Rusia foi memorable pola súa intensidade. Tiven a impresión de C++ Rusia como un evento sincero, onde a liña entre a formación e a comunicación en directo é case imperceptible. Todo, dende o estado de ánimo dos relatores ata as competicións dos socios do evento, é propicio para acaloradas discusións. O contido da conferencia, consistente en relatorios, abrangue un abano bastante amplo de temas, incluíndo innovacións en C++, estudos de casos de grandes proxectos e consideracións arquitectónicas ideolóxicas. Pero sería inxusto ignorar o compoñente social do evento, que axuda a superar as barreiras lingüísticas en relación non só co C++.
Agradecemos aos organizadores da conferencia a oportunidade de participar neste evento!
Podes ver a publicación dos organizadores sobre o pasado, presente e futuro de C++ Rusia .
Grazas por ler, e esperamos que a nosa narración de eventos fose útil!
Fonte: www.habr.com
