

Nedavno objavljeno , što lijepo ilustrira trend u strojnom učenju posljednjih godina. Ukratko, broj startupa za strojno učenje naglo je pao u posljednje dvije godine.
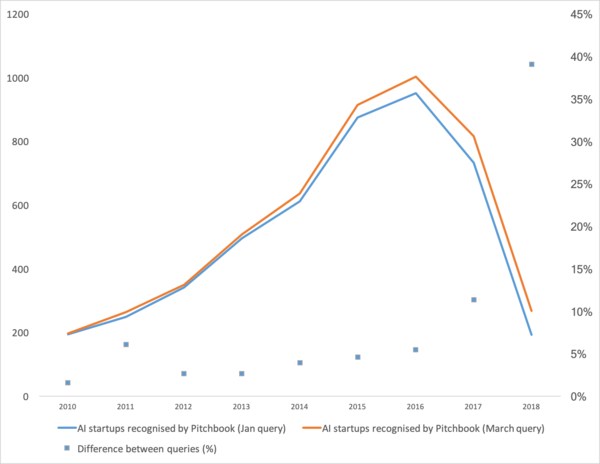
Pa dobro onda. Hajde da shvatimo je li balon pukao, kako živjeti dalje i raspravimo odakle je došla sva ova buka.
Prvo, razgovarajmo o tome što je bio poticaj za ovu krivulju. Odakle je došao. Vjerojatno će se svi sjetiti. Strojno učenje 2012. na natjecanju ImageNet. Uostalom, to je bio prvi globalni događaj! Ali u stvarnosti to nije slučaj. A krivulja rasta počinje nešto ranije. Podijelio bih je na nekoliko točaka.
- 2008. je bila godina pojave termina „veliki podaci“. Počeli su se stvarati pravi proizvodi. Od 2010. godine. Veliki podaci izravno su povezani sa strojnim učenjem. Bez velikih podataka, stabilan rad algoritama koji su tada postojali bio bi nemoguć. A to nisu bile neuronske mreže. Prije 2012. godine neuronske mreže bile su rezervirane za marginalnu manjinu. Ali tada su počeli raditi potpuno drugačiji algoritmi, koji su postojali godinama, ako ne i desetljećima: (1963., 1993. godine), (1995), (2003.),… Startupi tih godina bili su prvenstveno povezani s automatskom obradom strukturiranih podataka: blagajne, korisnici, oglašavanje i još mnogo toga.
Derivat ovog prvog vala je skup okvira kao što su XGBoost, CatBoost, LightGBM itd.
- U razdoblju 2011.-2012. Osvojili smo niz natjecanja u prepoznavanju slika. Njihova stvarna upotreba donekle je kasnila. Rekao bih da su se značajni startupi i rješenja počeli pojavljivati u velikim razmjerima 2014. godine. Trebale su dvije godine da se shvati da neuronske mreže zapravo funkcioniraju, da se stvore korisnički prilagođeni okviri koji se mogu instalirati i pokrenuti u razumnom roku te da se razviju metode koje bi stabilizirale i ubrzale vrijeme konvergencije.
Konvolucijske mreže omogućile su rješavanje problema računalnog vida: klasifikacija slika i objekata, detekcija objekata, prepoznavanje objekata i osoba, poboljšanje slike itd., itd.
- 2015.-2017. Procvat algoritama i projekata temeljenih na rekurentnim mrežama ili njihovim analozima (LSTM, GRU, TransformerNet itd.). Pojavili su se dobro učinkoviti algoritmi za pretvaranje govora u tekst i sustavi strojnog prevođenja. Djelomično su se temeljili na konvolucijskim mrežama za izdvajanje osnovnih značajki. Djelomično su se temeljili na razvoju velikih, visokokvalitetnih skupova podataka.
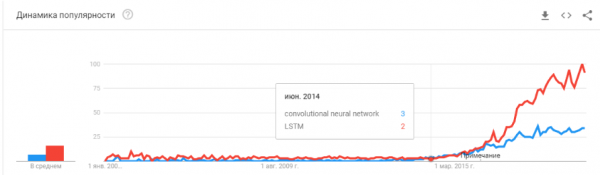
"Je li balon puknuo? Je li pompa pregrijana? Jesu li mrtvi poput blockchaina?"
Pa, naravno! Sutra Siri neće raditi na vašem telefonu, a prekosutra vaš Tesla neće moći razlikovati skretanje od klokana.
Neuronske mreže već rade. Nalaze se u desecima uređaja. One zapravo zarađuju novac, mijenjaju tržište i svijet oko nas. Pomama je malo drugačija:
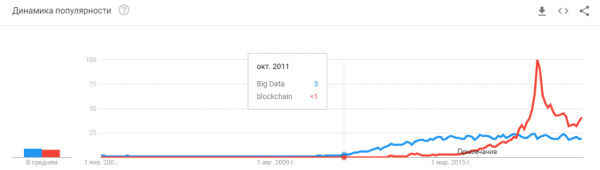
Neuronske mreže jednostavno više nisu novost. Da, mnogi ljudi imaju nerealna očekivanja. Ali veliki broj tvrtki naučio je koristiti neuronske mreže i razvijati proizvode temeljene na njima. Neuronske mreže nude nove funkcionalnosti, pomažu u uklanjanju radnih mjesta i smanjuju troškove usluga:
- Proizvodne tvrtke integriraju algoritme za analizu nedostataka na montažnoj traci.
- Stočarske farme kupuju sustave za praćenje krava.
- Automatski kombajni.
- Automatizirani pozivni centri.
- SnapChat filteri (barem nešto korisno!)
Ali glavna, i ne tako očita, poanta je: "Nema više novih ideja ili neće generirati trenutni kapital." Neuronske mreže riješile su desetke problema. I riješit će ih još više. Sve očite ideje koje su postojale iznjedrile su bezbroj startupa. Ali sve što je bilo na površini već je prikupljeno. Tijekom protekle dvije godine nisam naišao ni na jednu novu ideju za korištenje neuronskih mreža. Niti na jedan novi pristup (pa, u redu, postoji nekoliko neobičnosti s GAN-ovima).
I svaki novi startup postaje sve složeniji. Više ne zahtijeva dva tipa koji treniraju neuronsku mrežu na otvorenim podacima. Potrebni su programeri, poslužitelji, tim komentatora, složena podrška i tako dalje.
Kao rezultat toga, startupova je sve manje. Ali proizvodni sustavi rastu. Trebate li dodati prepoznavanje registarskih oznaka? Na tržištu postoje stotine stručnjaka s relevantnim iskustvom. Možete zaposliti nekoga i imati izgrađen sustav za par mjeseci. Ili kupiti gotov. Ali pokrenuti novi startup? Ludost!
Moramo stvoriti sustav za praćenje posjetitelja - zašto plaćati hrpu licenci kada možete stvoriti vlastiti za 3-4 mjeseca i prilagoditi ga svom poslovanju?
Neuronske mreže sada prolaze istim putem kojim su krenule deseci drugih tehnologija.
Sjećate li se kako se pojam "web developer" promijenio od 1995.? Tržište još nije zasićeno stručnjacima. Vrlo je malo profesionalaca. Ali kladio bih se da za 5-10 godina neće biti velike razlike između Java programera i programera neuronskih mreža. Na tržištu će biti mnogo stručnjaka za obje vrste.
Jednostavno će postojati klasa problema koji se mogu riješiti pomoću neuronskih mreža. Nastaje problem - zapošljavate stručnjaka.
"Što je sljedeće? Gdje je obećana umjetna inteligencija?"
Ali ovdje postoji jedna mala, ali zanimljiva specifičnost :)
Trenutni tehnološki stog, sudeći po svemu, neće nas dovesti do umjetne inteligencije. Ideje i njihova novost su se uglavnom iscrpile. Razgovarajmo o tome što nas drži na trenutnoj razini razvoja.
Ograničenja
Krenimo s autonomnim automobilima. Čini se jasnim da su potpuno autonomni automobili mogući s današnjom tehnologijom. Ali koliko će vremena za to trebati, nije jasno. Tesla vjeruje da će se to dogoditi za nekoliko godina.

Postoje mnogi drugi , koji to procjenjuju na 5-10 godina.
Najvjerojatnije će se, po mom mišljenju, za 15 godina infrastruktura gradova toliko promijeniti da će pojava autonomnih automobila postati neizbježna, postajući njezin nastavak. Ali to se ne može smatrati inteligencijom. Moderna Tesla je vrlo složena transportna traka za filtriranje podataka, njihovo pretraživanje i prekvalifikaciju. To su pravila-pravila-pravila, prikupljanje podataka i filtriranje preko njih (to je to). O tome sam pisao malo detaljnije, ili pogledajte od oznake).
Prvi problem
I ovdje vidimo prvi temeljni problemVeliki podaci. To je ono što je potaknulo trenutni val neuronskih mreža i strojnog učenja. Danas, za bilo što složeno i automatizirano, potrebno je puno podataka. Ne samo puno, nego jako puno. Trebaju nam automatizirani algoritmi za njihovo prikupljanje, označavanje i korištenje. Ako želimo da automobil detektira kamione nasuprot suncu, prvo ih moramo prikupiti dovoljan broj. Ako želimo da automobil ne poludi kada se bicikl pričvrsti na prtljažnik, trebamo više uzoraka.
I jedan primjer nije dovoljan. Stotine? Tisuće?

Drugi problem
Drugi problem — vizualizacija onoga što je naša neuronska mreža naučila. Ovo je vrlo izazovan zadatak. Malo ljudi još uvijek razumije kako to vizualizirati. Ovi članci su prilično noviji; to su samo neki primjeri, iako daleki:
Fiksacija teksture. Jasno pokazuje na što se neuronska mreža obično usredotočuje i što doživljava kao ulaz.

pozornost na Zapravo, pažnja se često može koristiti upravo kako bi se pokazalo što je uzrokovalo određenu reakciju mreže. Susreo sam se s takvim stvarima i za otklanjanje pogrešaka i za odluke o proizvodu. Postoji mnogo članaka na ovu temu. Ali što su podaci složeniji, to je teže razumjeti kako postići stabilnu vizualizaciju.

Pa, da, onaj dobri stari set "pogledaj što je u mreži" "Ove su slike bile popularne prije 3-4 godine, ali svi su brzo shvatili da su lijepe, ali da u njima nema puno značenja."
Nisam spomenuo desetke drugih naprava, metoda, trikova i studija o tome kako mapirati unutarnje dijelove mreže. Rade li ovi alati? Pomažu li u brzom identificiranju problema i otklanjanju pogrešaka u mreži? Pomažu li u izdvajanju posljednjih nekoliko postotaka? Pa, nešto poput ovoga:

Možete pogledati bilo koje Kaggle natjecanje. I tamo je opisano kako ljudi dolaze do svojih konačnih rješenja. Složili smo 100, 500, 800 milijuna modela i uspjelo je!
Pretjerujem, naravno. Ali ovi pristupi ne daju brze i izravne odgovore.
S dovoljnim iskustvom i testiranjem različitih opcija, možete doći do zaključka zašto je vaš sustav donio ovu odluku. Ali ispravljanje ponašanja sustava bit će teško. Možete instalirati zaobilazno rješenje, pomaknuti prag, dodati skup podataka ili koristiti drugu pozadinsku mrežu.
Treći problem
Treći temeljni problem — mreže podučavaju statistiku, a ne logiku. Statistički gledano, ovo je :

Logično, ne čini se tako. Neuronske mreže ne uče ništa složeno osim ako nisu prisiljene. Uvijek uče najjednostavnije moguće značajke. Ima li oči, nos, glavu? To znači da je to lice! Ili navedite primjer gdje oči ne označavaju lice. I opet, postoje milijuni primjera.
Ima puno mjesta na dnu
Rekao bih da ova tri globalna problema trenutno ograničavaju razvoj neuronskih mreža i strojnog učenja. Tamo gdje ovi problemi prije nisu ograničavali područje, već se aktivno koriste.
Je li ovo kraj? Jesu li neuronske mreže u zastoju?
Nepoznato je. Ali, naravno, svi se nadaju da neće.
Postoji mnogo pristupa i smjerova za rješavanje temeljnih problema koje sam gore naveo. Ali do sada nam nijedan od tih pristupa nije omogućio da učinimo nešto fundamentalno novo, da riješimo nešto što prije nije riješeno. Zasad su svi temeljni projekti temeljeni na utvrđenim pristupima (Tesla) ili ostaju testni projekti za institute ili korporacije (Google Brain, OpenAI).
Grubo govoreći, glavni fokus je stvaranje neke reprezentacije ulaznih podataka na visokoj razini - "memorije", u određenom smislu. Najjednostavniji primjer memorije su razne "ugrađivane" reprezentacije slika. Na primjer, svi sustavi za prepoznavanje lica. Mreža uči izdvojiti neku stabilnu reprezentaciju iz lica koja je neovisna o rotaciji, osvjetljenju ili rezoluciji. U biti, mreža minimizira metrike "različita lica su daleko" i "identična lica su blizu".
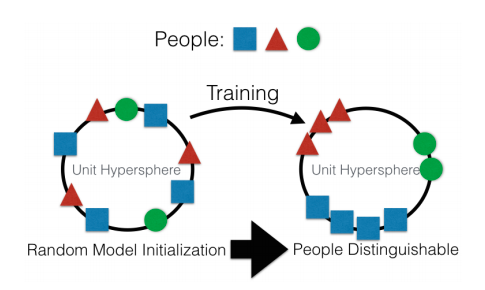
Ova vrsta učenja zahtijeva desetke i stotine tisuća primjera. Ali rezultat nosi neke od osnova "učenja iz jednog pokušaja". Sada nam ne trebaju stotine lica da bismo zapamtili osobu. Samo jedno lice i to je to - mi !
Postoji samo jedan problem... Mreža može učiti samo prilično jednostavne objekte. Kada pokušava razlikovati ne lica, već, na primjer, "ljude po odjeći" (zadatak ) — kvaliteta pada za redove veličine. I mreža više ne može učiti dovoljno očite promjene u perspektivi.
A učenje iz milijuna primjera također nekako nije toliko zabavno.
Postoje studije o značajnom smanjenju broja izbora. Na primjer, odmah se možemo sjetiti jedne od prvih studija o Učenje jednim udarcem :
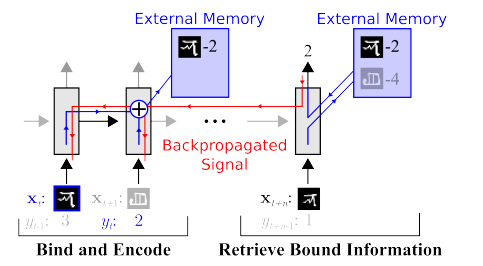
Postoji mnogo takvih djela, npr. ili ili .
Postoji jedna mana: trening obično dobro funkcionira na jednostavnim, "MNIST-sličnim" primjerima. Ali kada se prelazi na složenije probleme, potrebna vam je veća baza podataka, objektni model ili neka vrsta magije.
Općenito, rad na učenju iz jednog pokušaja je vrlo zanimljiva tema. Pronalazi se mnogo ideja. Ali uglavnom, dva problema koja sam naveo (predtrening na ogromnom skupu podataka i nestabilnost na složenim podacima) stvarno ometaju učenje.
S druge strane, GAN-ovi - generativne adversarijalne mreže - dobar su pristup ugradnji. Vjerojatno ste pročitali hrpu članaka o ovoj temi na Habru., ,)
Posebnost GAN-a je formiranje nekog unutarnjeg prostora stanja (u biti isto što i Embedding), koji omogućuje crtanje slike. To mogu biti , možda .
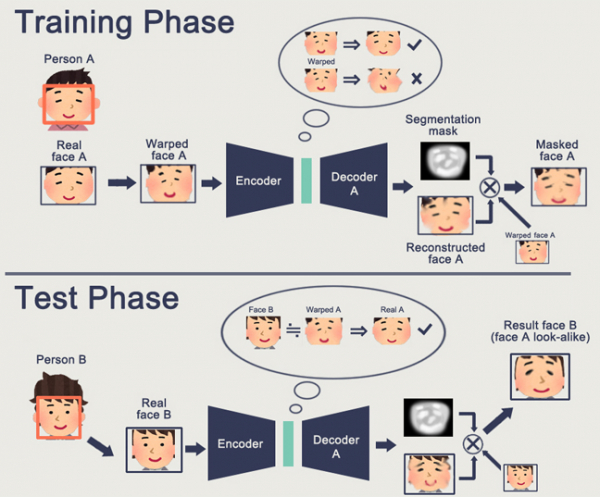
Problem s GAN-ovima je taj što što je generirani objekt složeniji, to ga je teže opisati pomoću logike generatora i diskriminatora. Kao rezultat toga, jedina primjena GAN-ova u stvarnom svijetu o kojoj se široko raspravlja je DeepFake, koji, opet, manipulira prikazima lica (za koje postoji ogromna baza podataka).
Naišao sam na vrlo malo drugih korisnih aplikacija. Obično neke vrste zvona i zviždaljki sa slikama koje se dovršavaju.
I opet. Nitko ne razumije kako će nam ovo omogućiti da krenemo prema svijetloj budućnosti. Predstavljanje logike/prostora u neuronskoj mreži je dobro. Ali potreban nam je ogroman broj primjera; ne razumijemo kako neuronska mreža to predstavlja i ne razumijemo kako natjerati neuronsku mrežu da zapamti bilo koju doista složenu reprezentaciju.
Ojačavanje učenja — ovo je pristup iz potpuno drugačijeg kuta. Vjerojatno se sjećate kako je Google pobijedio sve u Gou. I nedavnih pobjeda u Starcraftu i Doti. Ali stvari ovdje nisu baš tako ružičaste i obećavajuće. Najbolji način da se govori o RL-u i njegovim složenostima je putem .
Da ukratko sažmemo što je autor napisao:
- Modeli odmah po instalaciji u većini slučajeva ne odgovaraju/rade loše
- Praktične probleme je lakše riješiti drugim metodama. Boston Dynamics ne koristi RL zbog njegove složenosti/nepredvidljivosti/računske složenosti.
- Da bi RL radio, potrebna je složena funkcija. Često ju je teško stvoriti/napisati.
- Teško je trenirati modele. Potrebno je puno vremena da se osposobe i pokrenu izvan lokalnih optimuma.
- Kao rezultat toga, teško je ponoviti model, a model postaje nestabilan pri najmanjim promjenama.
- Često se previše prilagođava nekoj vrsti ljevičarskih obrazaca, sve do generatora slučajnih brojeva.
Ključna stvar je da RL još ne radi u produkciji. Google provodi neke eksperimente ( , ). Ali nisam vidio niti jedan sustav proizvoda.
memorijaNedostatak svega gore opisanog je nedostatak strukture. Jedan od pristupa rješavanju ovog problema je dati neuronskoj mreži pristup zasebnoj memoriji kako bi tamo mogla snimati i prepisivati rezultate svojih koraka. Tada se neuronska mreža može definirati trenutnim stanjem memorije. To je vrlo slično klasičnim procesorima i računalima.
Najpoznatiji i najpopularniji — iz DeepMinda:
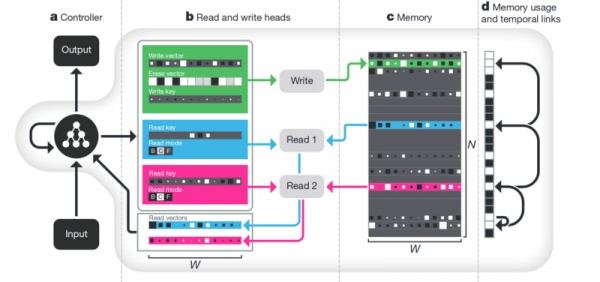
Čini li se ovo kao ključ za razumijevanje inteligencije? Ali vjerojatno ne. Sustav i dalje zahtijeva ogromnu količinu podataka za obuku. I radi prvenstveno sa strukturiranim tabličnim podacima. U međuvremenu, kada Facebook Ako su imali sličan problem, išli su putem "zbrinite pamćenje, samo učinite neuronsku mrežu složenijom, dajte joj više primjera i ona će sama učiti".
Prevazilaženje teškoćaDrugi način stvaranja smislene memorije je korištenje istih ugrađivanja, ali uvođenje dodatnih kriterija tijekom treniranja koji bi nam omogućili da iz njih izvučemo "značenje". Na primjer, želimo trenirati neuronsku mrežu da prepoznaje ljudsko ponašanje u trgovini. Ako bismo slijedili standardni pristup, morali bismo stvoriti dvanaest mreža. Jedna bi tražila osobu, druga bi određivala što radi, treća bi određivala njezinu dob, četvrta bi određivala njezin spol. Zasebna logika bi promatrala dio trgovine gdje to rade/uče to raditi. Treća bi određivala njezinu putanju i tako dalje.
Ili, ako bi postojala beskonačna količina podataka, tada bi bilo moguće trenirati jednu mrežu na svim mogućim ishodima (očito je da se takav niz podataka ne može prikupiti).
Pristup raspetljavanja nam govori: trenirajmo mrežu tako da sama može razlikovati koncepte. Tako da može formirati ugradnju na temelju videa, gdje jedna regija definira radnju, jedna položaj na podu tijekom vremena, jedna visinu osobe, a treća njezin spol. Istovremeno, tijekom treniranja, željeli bismo izbjeći poticanje mreže takvim ključnim konceptima, već da sama identificira i grupira regije. Vrlo je malo takvih članaka (neki od njih , , ) i općenito su prilično teorijski.
Ali ovaj smjer, barem teoretski, trebao bi zatvoriti probleme navedene na početku.
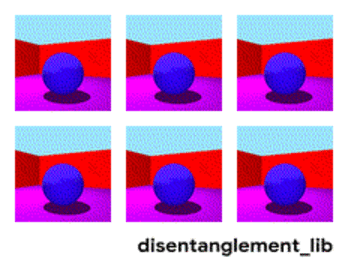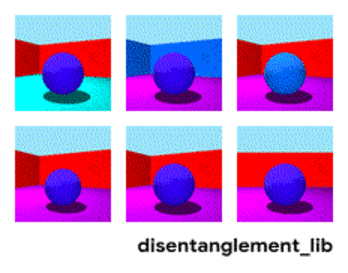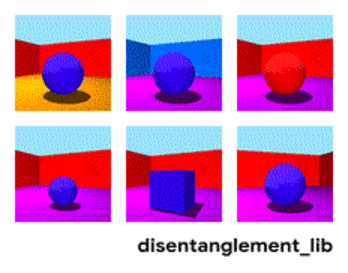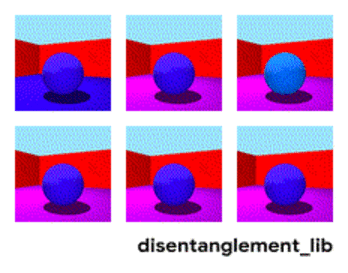
Dekompozicija slike prema parametrima „boja zida/boja poda/oblik objekta/boja objekta/itd.“

Dekompozicija lica prema parametrima kao što su „veličina, obrve, orijentacija, boja kože itd.“
Drugi
Postoje mnoga druga, manje globalna područja koja nam omogućuju da na neki način smanjimo baze podataka, radimo s heterogenijim podacima itd.
PažnjaVjerojatno nema smisla izdvajati ovo kao zasebnu metodu. To je jednostavno pristup koji pojačava druge. Mnogi su članci posvećeni tome (,,). Cilj Pažnje je ojačati odgovor mreže na relevantne objekte tijekom treninga. To se često postiže nekim vanjskim ciljanjem ili malom vanjskom mrežom.
3D simulacijaAko stvorite dobar 3D engine, često ga možete koristiti za pokrivanje 90% podataka za obuku (čak sam vidio primjer gdje je dobar engine pokrio gotovo 99% podataka). Postoje mnoge ideje i trikovi za korištenje mreže obučene na 3D engineu sa stvarnim podacima (fino podešavanje, prijenos stilova itd.). Ali često je stvaranje dobrog enginea za redove veličine teže od prikupljanja podataka. Primjeri enginea koji se razvijaju:
Obuka robota (, )
Nastava roba u trgovini (ali u dva projekta koja smo radili, lako smo se snašli i bez toga).
Trening u Tesli (opet, isti video kao gore).
Zaključci
Cijeli članak je, u određenom smislu, zaključak. Pretpostavljam da je glavna poanta koju sam htio istaknuti bila: "Besplatna vožnja je završena; neuronske mreže više ne pružaju jednostavna rješenja." Sada moramo naporno raditi na izgradnji složenih rješenja. Ili naporno raditi na provođenju složenih znanstvenih istraživanja.
Ovo je tema za raspravu. Možda čitatelji imaju zanimljivije primjere?
Izvor: www.habr.com
