

A cikk két részből áll:
- Néhány hálózati architektúra rövid leírása a képekben történő objektumészleléshez és a képszegmentáláshoz, a számomra legérthetőbb hivatkozásokkal a forrásokhoz. Igyekeztem videós magyarázatokat választani és lehetőleg oroszul.
- A második rész egy kísérlet a neurális hálózati architektúrák fejlődési irányának megértésére. És az ezeken alapuló technológiák.

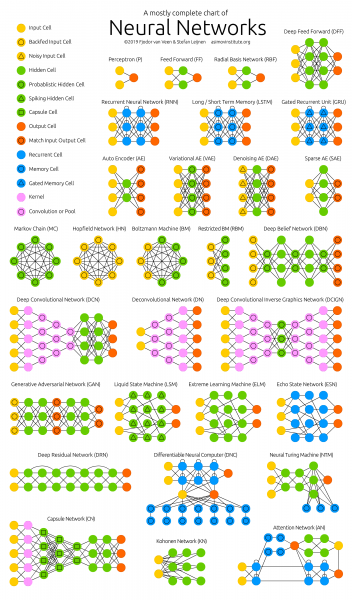
1. ábra – A neurális hálózati architektúrák megértése nem könnyű
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- , amikor az adatokat a szerveren dolgozzák fel és továbbítják a telefonra. Három típusú medvék képbesorolása: barna, fekete és mackó.
- amikor magán a telefonon dolgozzák fel az adatokat. Háromféle tárgyak észlelése (tárgyfelismerés): mogyoró, füge és datolya.
Különbség van a képosztályozás, a képen a tárgyfelismerés és a . Ezért felmerült az igény annak kiderítésére, hogy mely neurális hálózati architektúrák észlelik a képeken lévő objektumokat, és melyek képesek szegmentálni. Az alábbi architektúra-példákat találtam, amelyek a számomra legérthetőbb hivatkozásokat tartalmazzák az erőforrásokhoz:
- R-CNN-en alapuló architektúrák sorozata (Rrégiók Convolúció Neural Nhálózat jellemzői): R-CNN, Fast R-CNN, , . A képen lévő objektumok észleléséhez a határolókereteket a Region Proposal Network (RPN) mechanizmus segítségével osztják ki. Kezdetben a lassabb szelektív keresési mechanizmust használták az RPN helyett. Ezután a kiválasztott korlátozott régiókat egy hagyományos neurális hálózat bemenetére táplálják osztályozás céljából. Az R-CNN architektúra explicit „for” hurokkal rendelkezik korlátozott régiókban, összesen akár 2000 futással az AlexNet belső hálózatán. Az explicit „for” hurkok lelassítják a képfeldolgozási sebességet. A belső neurális hálózaton áthaladó explicit hurkok száma az architektúra minden új verziójával csökken, és tucatnyi egyéb változtatást hajtanak végre a sebesség növelése és az objektumészlelés feladatának az objektumszegmentáció helyett a Mask R-CNN-ben.
- (You Only Look Once) az első neurális hálózat, amely valós időben felismerte az objektumokat a mobileszközökön. Megkülönböztető jellemző: objektumok megkülönböztetése egy futásban (csak egyszer nézd meg). Vagyis a YOLO architektúrában nincsenek kifejezett „for” hurkok, ezért a hálózat gyorsan működik. Például ezt a hasonlatot: a NumPy-ban a mátrixokkal végzett műveletek során szintén nincsenek kifejezett „for” ciklusok, amelyek a NumPy-ben az architektúra alacsonyabb szintjein valósulnak meg a C programozási nyelven keresztül. A YOLO előre definiált ablakokból álló rácsot használ. Annak megakadályozására, hogy ugyanazt az objektumot többször meghatározzák, az ablak átfedési együtthatóját (IoU) használják. Iútkereszteződés over Union). Ez az architektúra széles tartományban működik, és magas : A modellt meg lehet tanítani a fényképekre, de még mindig jól teljesít a kézzel rajzolt festményeken.
- (Stűz Sforró MultiBox Detector) – a YOLO architektúra legsikeresebb „hackjeit” használják (például a nem maximális elnyomást), és újakat adnak hozzá, hogy a neurális hálózat gyorsabban és pontosabban működjön. Megkülönböztető jellemző: objektumok megkülönböztetése egy futásban a képpiramis adott ablakrácsának (alapértelmezett doboz) segítségével. A képpiramis konvolúciós tenzorokba van kódolva az egymást követő konvolúciós és összevonási műveleteken keresztül (a max-pooling művelettel a térbeli dimenzió csökken). Ily módon a nagy és a kis objektumok is meghatározásra kerülnek egy hálózati futásban.
- MobileSSD (MobilNetV2+ SSD) két neurális hálózati architektúra kombinációja. Első hálózat gyorsan működik és növeli a felismerés pontosságát. A MobileNetV2-t használják az eredetileg használt VGG-16 helyett . A második SSD-hálózat határozza meg az objektumok helyét a képen.
- – egy nagyon kicsi, de pontos neurális hálózat. Önmagában nem oldja meg az objektumészlelés problémáját. Használható azonban különböző architektúrák kombinációjában. És mobil eszközökben használják. A megkülönböztető jellemzője, hogy az adatokat először négy 1 × 1-es konvolúciós szűrőbe tömörítik, majd négy 1 × 1-es és négy 3 × 3-as konvolúciós szűrőre bővítik. Az adattömörítés-bővítés egyik ilyen iterációját „Fire Module”-nak nevezik.
- (Semantic Image Segmentation with Deep Convolutional Nets) – a képen lévő objektumok szegmentálása. Az architektúra jellegzetessége a dilatált konvolúció, amely megőrzi a térbeli felbontást. Ezt követi az eredmények utófeldolgozása egy grafikus valószínűségi modell segítségével (feltételes véletlenszerű mező), amely lehetővé teszi a kis zaj eltávolítását a szegmentálásban és a szegmentált kép minőségének javítását. A félelmetes „grafikus valószínűségi modell” elnevezés mögött egy hagyományos Gauss-szűrő bújik meg, amelyet öt ponttal közelítenek.
- Megpróbálta kitalálni a készüléket (Egyetlen lövés Finomítsaneurális hálózat az objektum számára aztakció), de nem sokat értettem.
- Megnéztem azt is, hogyan működik a „figyelem” technológia: , , . A „figyelem” architektúra megkülönböztető jellemzője a fokozott figyelem területeinek automatikus kiválasztása a képen (RoI, Regions of Interest) az Attention Unit nevű neurális hálózat segítségével. A fokozott figyelem területei hasonlóak a határolókeretekhez, de velük ellentétben nem rögzülnek a képen, és elmosódott határaik lehetnek. Ezután a fokozott figyelmet igénylő területekről jeleket (jellemzőket) izolálnak, amelyeket „táplálnak” a visszatérő architektúrájú neurális hálózatokba. . Az ismétlődő neurális hálózatok képesek elemezni egy sorozat jellemzőinek kapcsolatát. A visszatérő neurális hálózatokat kezdetben szövegek más nyelvekre való lefordítására használták, most pedig fordításra и .
Ahogy feltárjuk ezeket az architektúrákat Rájöttem, hogy nem értek semmit. És nem arról van szó, hogy a neurális hálózatomnak problémái vannak a figyelemmechanizmussal. Mindezen architektúrák létrehozása olyan, mint valami hatalmas hackathon, ahol a szerzők hackelésben versenyeznek. A hack egy gyors megoldás egy bonyolult szoftverproblémára. Azaz nincs látható és érthető logikai kapcsolat ezen architektúrák között. Csak a legsikeresebb hackek készlete köti össze őket, amelyeket egymástól kölcsönöznek, valamint egy mindenki számára közös (hiba visszaszaporítás, visszaszaporítás). Nem ! Nem világos, hogy min változtassunk és hogyan optimalizáljuk a meglévő eredményeket.
A hackek közötti logikai kapcsolat hiánya miatt rendkívül nehéz megjegyezni és a gyakorlatban alkalmazni. Ez töredezett tudás. Legjobb esetben néhány érdekes és váratlan pillanat emlékezik meg, de a legtöbb megértett és felfoghatatlan néhány napon belül eltűnik az emlékezetből. Jó lesz, ha egy hét múlva emlékszel legalább az építészet nevére. De több óra, sőt nap munkaidő telt el cikkek olvasásával és ismertető videók nézésével!
2. ábra -
A tudományos cikkek szerzőinek többsége személyes véleményem szerint mindent megtesz annak érdekében, hogy még ezt a töredezett tudást se értse meg az olvasó. De a tízsoros mondatokban szereplő, „levegőből” vett képletekkel rendelkező részes kifejezések egy külön cikk témája (probléma ).
Emiatt szükség van az információk neurális hálózatok segítségével történő rendszerezésére, és ezáltal a megértés és a memorizálás minőségének javítására. Ezért a mesterséges neurális hálózatok egyes technológiáinak és architektúráinak elemzésének fő témája a következő feladat volt: megtudja, hová megy ez az egész, és nem egy adott neurális hálózat eszközét külön-külön.
Hová megy ez az egész? Főbb eredmények:
- A gépi tanulással induló vállalkozások száma az elmúlt két évben . Lehetséges ok: „A neurális hálózatok már nem újdonságok.”
- Bárki létrehozhat működő neurális hálózatot egy egyszerű probléma megoldására. Ehhez vegyünk egy kész modellt a „modell állatkertből”, és képezzük ki a neurális hálózat utolsó rétegét () származó kész adatokon vagy a ingyenesen .
- A neurális hálózatok nagy gyártói elkezdtek létrehozni "mintaállatkertek" (minta állatkert). Segítségükkel gyorsan létrehozhat egy kereskedelmi alkalmazást: a TensorFlow számára, a PyTorch számára, a Caffe2 számára, a Chainer és .
- Működő neurális hálózatok valós idő (valós idejű) mobileszközökön. 10-50 képkocka másodpercenként.
- Neurális hálózatok használata telefonokban (TF Lite), böngészőkben (TF.js) és innen (IoT, Internet of Tzsanérok). Főleg azokban a telefonokban, amelyek már hardver szinten támogatják a neurális hálózatokat (neurális gyorsítók).
- „Minden eszköznek, ruhadarabnak és talán még ételnek is meglesz IP-v6 cím és kommunikálj egymással" - .
- A gépi tanulással kapcsolatos publikációk száma növekedni kezdett (kétévente megduplázódik) 2015 óta. Nyilvánvalóan szükségünk van neurális hálózatokra a cikkek elemzéséhez.
- A következő technológiák egyre népszerűbbek:
- PyTorch – a népszerűség gyorsan növekszik, és úgy tűnik, hogy megelőzi a TensorFlow-t.
- A hiperparaméterek automatikus kiválasztása AutoML – zökkenőmentesen nő a népszerűség.
- A pontosság fokozatos csökkenése és a számítási sebesség növekedése: , algoritmusok , pontatlan (közelítő) számítások, kvantálás (amikor a neurális hálózat súlyait egész számokká alakítjuk és kvantáljuk), neurális gyorsítók.
- fordítás и .
- teremtés , most valós időben.
- A DL-ben az a lényeg, hogy rengeteg adat van, de ezek összegyűjtése és címkézése nem egyszerű. Ezért fejlődik a jelölés automatizálása () neurális hálózatokat használó neurális hálózatokhoz.
- A neurális hálózatokkal hirtelen a számítástechnika lett kísérleti tudomány és felkelt .
- Az informatikai pénz és a neurális hálózatok népszerűsége egyszerre jelent meg, amikor a számítástechnika piaci értékké vált. A gazdaság arany- és valutagazdaságból átalakul arany-valuta-számítástechnika. Lásd a cikkemet és az informatikai pénzek megjelenésének oka.
Fokozatosan megjelenik egy új (Machine Learning & Deep Learning), amely a program képzett neurális hálózati modellek halmazaként való megjelenítésén alapul.
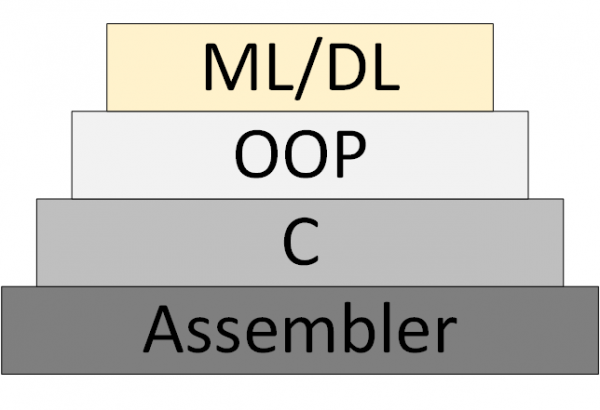
3. ábra – Az ML/DL mint új programozási módszertan
Azonban soha nem jelent meg "neurális hálózat elmélet", amelyen belül lehet szisztematikusan gondolkodni és dolgozni. Amit ma „elméletnek” neveznek, az valójában kísérleti, heurisztikus algoritmusok.
Linkek az én és más forrásaimhoz:
- Adattudományi Hírlevél. Főleg képfeldolgozás. Aki meg akarja kapni, küldjön egy e-mailt (foobar167<gaf-gaf>gmail<dot>com). Cikkekre és videókra mutató linkeket küldök ki, ahogy gyűlnek az anyagok.
- Általános amin átmentem és amin szeretnék átmenni.
- , ahol érdemes elkezdeni a neurális hálózatok tanulmányozását. Plusz prospektus .
- , ahol mindenki talál valami érdekeset a maga számára.
- Rendkívül hasznosnak találtuk őket. videocsatornák tudományos cikkek elemzéséhez a Data Science által. Keresse meg, iratkozzon fel rájuk, és adja tovább a linkeket kollégáinak és nekem is. Példák:
- más néven lépésenkénti utasításokkal és nyílt forráskóddal.
Спасибо за внимание!
Forrás: will.com
