


こんにちは。最近、多数のブロック デバイスをバックアップするためのストレージをセットアップするという興味深いタスクに遭遇しました。
当社では毎週クラウド内のすべての仮想マシンをバックアップしているため、何千ものバックアップを維持し、できるだけ迅速かつ効率的に実行できる必要があります。
残念ながら、標準構成では RAID5, RAID6 この場合、彼らはそうしたくないでしょう。なぜなら、私たちのディスクのような大容量ディスクのリカバリプロセスは非常に長く、おそらく決して終わらないでしょう。
どのような代替案があるか考えてみましょう。
— RAID5、RAID6に類似していますが、パリティレベルを設定できます。この場合、バックアップはブロック単位ではなく、オブジェクトごとに個別に実行されます。消失訂正符号を試す最も簡単な方法は、 .
— は現在リリースされていないZFSの機能です。RAIDZとは異なり、DRAIDは分散パリティブロックを備え、リカバリ時にアレイ内のすべてのディスクを一度に使用するため、ディスク障害への対応力が向上し、クラッシュからのリカバリが迅速化されます。


利用可能なサーバーがあります 富士通Primergy RX300 S7 プロセッサ搭載 インテル Xeon CPU E5-2650L 0 @ 1.80GHz、9つのRAMモジュール Samsung DDR3-1333 8Gb PC3L-10600R ECC レジスタード (M393B1K70DH0-YH9)、ディスクシェルフ Supermicro スーパーシャーシ 847E26-RJBOD1、接続経由 デュアル LSI SAS2X36 エクスパンダー 45枚のディスク シーゲージ ST6000NM0115-1YZ110 上の 6TB それぞれ。
何かを決定する前に、まずすべてを適切にテストする必要があります。
そのため、様々な構成を準備し、テストを行いました。S3バックエンドとして機能するminioを使用し、ターゲット数が異なる様々なモードで実行しました。
minio ケースは主に、同じ数のディスクとパリティ ディスクを使用した消去コーディングとソフトウェア RAID (つまり、RAID6、RAIDZ2、DRAID2) の比較でテストされました。
参考までに、minio をターゲットが3つのみの場合、S3 ゲートウェイモードで動作し、ローカルファイルシステムが SXNUMX ストレージとして使用されます。minio を複数のターゲットで実行する場合、Erasure Coding モードが自動的に有効になり、データがターゲット間で分散されるため、フォールトトレランスが実現されます。
デフォルトでは、minio はターゲットを 16 個のディスクのグループに分割し、各グループには 2 つのパリティが設定されます。つまり、XNUMX 個のディスクが同時に故障しても、データが失われることはありません。
パフォーマンス テストでは、16 TB のディスクを 6 枚使用し、そこに 1 MB の小さなオブジェクトを書き込みました。これは、すべての最新のバックアップ ツールがデータを数メガバイトのブロックに分割して書き込むため、将来のワークロードを可能な限り正確に表したものです。
ベンチマークには、リモートサーバー上で実行されるs3benchユーティリティを使用し、数万個のオブジェクトを数百のストリームでminioに送信しました。その後、minioは同じ方法でそれらのオブジェクトをリクエストし返しました。
ベンチマークの結果は次の表に示されています。
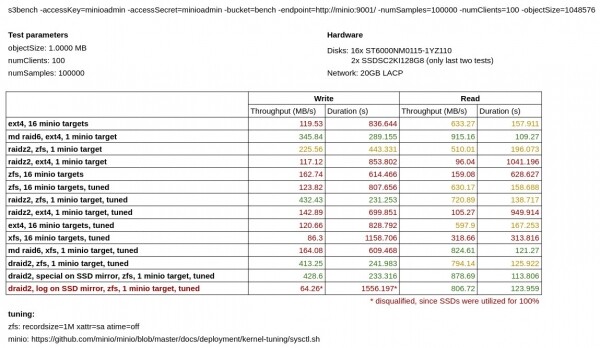
ご覧のとおり、ネイティブ消去コーディング モードの minio は、同じ構成でソフトウェア RAID6、RAIDZ2、および DRAID2 上で実行されている minio よりも書き込みのパフォーマンスが大幅に低下します。
別に私 ext4とXFSでminioをテストしました。驚いたことに、私のワークロードでは、XFSはext4よりも大幅に遅かったです。
最初の一連のテストではMdadmがZFSよりも優れていることが示されましたが、その後 次のオプションを設定することで、ZFS のパフォーマンスを向上できます。
xattr=sa atime=off recordsize=1Mそれ以来、ZFS のテストは大幅に改善されました。
また、DRAID は RAIDZ に比べてパフォーマンスが大幅に向上するわけではないことにも気づくでしょうが、理論的にははるかに安全であるはずです。
最後の2つのテストでは、メタデータ(特殊)とZIL(ログ)をSSDからミラーに移動してみました。しかし、メタデータを移動しても書き込み速度はあまり向上せず、ZILを移動した際には 使用率が100%で限界に達したため、このテストは失敗とみなします。より高速なSSDドライブがあれば、結果が大幅に改善された可能性もあると思いますが、残念ながら手元にありませんでした。
最終的に私は DRAID を選択することにしました。ベータ版であるにもかかわらず、DRAID は私たちのユースケースにとって最も高速かつ最も効率的なストレージ ソリューションです。
2 つのグループと XNUMX つの分散スペアを含む構成で、シンプルな DRAIDXNUMX を作成しました。
# zpool status data
pool: data
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
draid2:3g:2s-0 ONLINE 0 0 0
sdy ONLINE 0 0 0
sdam ONLINE 0 0 0
sdf ONLINE 0 0 0
sdau ONLINE 0 0 0
sdab ONLINE 0 0 0
sdo ONLINE 0 0 0
sdw ONLINE 0 0 0
sdak ONLINE 0 0 0
sdd ONLINE 0 0 0
sdas ONLINE 0 0 0
sdm ONLINE 0 0 0
sdu ONLINE 0 0 0
sdai ONLINE 0 0 0
sdaq ONLINE 0 0 0
sdk ONLINE 0 0 0
sds ONLINE 0 0 0
sdag ONLINE 0 0 0
sdi ONLINE 0 0 0
sdq ONLINE 0 0 0
sdae ONLINE 0 0 0
sdz ONLINE 0 0 0
sdan ONLINE 0 0 0
sdg ONLINE 0 0 0
sdac ONLINE 0 0 0
sdx ONLINE 0 0 0
sdal ONLINE 0 0 0
sde ONLINE 0 0 0
sdat ONLINE 0 0 0
sdaa ONLINE 0 0 0
sdn ONLINE 0 0 0
sdv ONLINE 0 0 0
sdaj ONLINE 0 0 0
sdc ONLINE 0 0 0
sdar ONLINE 0 0 0
sdl ONLINE 0 0 0
sdt ONLINE 0 0 0
sdah ONLINE 0 0 0
sdap ONLINE 0 0 0
sdj ONLINE 0 0 0
sdr ONLINE 0 0 0
sdaf ONLINE 0 0 0
sdao ONLINE 0 0 0
sdh ONLINE 0 0 0
sdp ONLINE 0 0 0
sdad ONLINE 0 0 0
spares
s0-draid2:3g:2s-0 AVAIL
s1-draid2:3g:2s-0 AVAIL
errors: No known data errorsさて、ストレージの整理は完了しました。次は、バックアップ方法についてお話しましょう。ここで、私が試してみた3つの解決策について早速ご紹介したいと思います。
- フォーク ブロックデバイスバックアップに特化したソリューションであるは、Cephと緊密に統合されています。スナップショット間の差分を取得し、そこから増分バックアップを作成できます。ローカルとS3の両方を含む、多数のストレージバックエンドをサポートしています。重複排除ハッシュテーブルを保存するために別のデータベースが必要です。欠点:Pythonで記述されており、CLIの応答性がやや低い。
- フォーク は長年実績のあるバックアップツールで、データのバックアップと重複排除を効果的に行うことができます。バックアップはローカルとscp経由でリモートサーバーの両方に保存できます。フラグ付きで起動すれば、ブロックデバイスもバックアップできます。 --specialマイナス面としては、バックアップを作成するときにリポジトリが完全にブロックされるため、仮想マシンごとに個別のリポジトリを作成することをお勧めします。原則としてこれは問題ではなく、幸いなことに非常に簡単に作成できます。
— は活発に開発が進められているプロジェクトで、Go言語で書かれており、十分な速度があり、ローカルストレージ、scp、S3など、多数のストレージバックエンドをサポートしています。また、特別に作成された restic用。これは、ストレージをリモートでの使用のためにエクスポートするのに最も高速です。上記のものの中で、私が一番気に入ったのはresticです。標準入力からバックアップできます。目立った欠点はほとんどありませんが、いくつかの機能があります。
-
まず、すべての仮想マシン(Benjiなど)に対して汎用リポジトリモードで使用してみましたが、問題なく動作しました。しかし、リストア操作にはかなり時間がかかりました。これは、リストア前に毎回resticがすべてのバックアップのメタデータを読み取ろうとするためです。この問題は、borgと同様に、仮想マシンごとに個別のリポジトリを作成することで簡単に解決できました。このアプローチは、バックアップ管理にも非常に効果的であることがわかりました。個別のリポジトリにはデータにアクセスするための個別のパスワードを設定でき、グローバルリポジトリが何らかの理由で破損する心配もありません。borgバックアップと同様に、新しいリポジトリを簡単に作成できます。
いずれの場合も、重複排除はバックアップの以前のバージョンに対してのみ実行されます。以前のバックアップは指定されたバックアップのパスによって決定されます。したがって、stdinから共通のリポジトリに異なるオブジェクトをバックアップする場合は、オプションを指定することを忘れないでください。
--stdin-filenameまたは、毎回オプションを明示的に指定する--parent.
-
第二に、stdoutへのリストアは並列処理のため、ファイルシステムへのリストアよりも大幅に時間がかかります。今後、ブロックデバイスのバックアップのサポートを強化する予定です。
-
第三に、現時点では バージョン 0.9.6 には、大きなファイルの復元に時間がかかるバグがあるためです。
バックアップの効率とバックアップ/リストア速度をテストするために、別のリポジトリを作成し、小さな仮想マシンイメージ(21GB)のバックアップを試みました。元のイメージに変更を加えずにXNUMX回のバックアップを実行し、リストされている各ソリューションを用いて、重複排除されたデータのコピー速度の違いを確認しました。
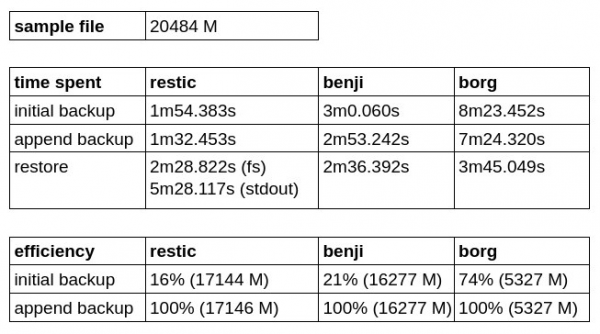
ご覧のとおり、Borg Backup は初期バックアップ効率比が最も優れていますが、書き込み速度と復元速度の両方で劣っています。
Restic は Benji Backup よりも高速であることが判明しましたが、stdout への復元に時間がかかり、残念ながらまだブロック デバイスに直接書き込むことはできません。
あらゆる長所と短所を検討した結果、私は レスティック с RESTサーバー 最も便利で有望なバックアップ ソリューションとして。
このスクリーンキャストでは、複数のバックアップ操作を同時に実行しながら、10ギガビットチャネルを最大限に活用する様子をご覧いただけます。ディスク使用率は30%を超えないことにご注目ください。
受け取った解決策には非常に満足しました!
出所: habr.com
