

Python コードの型チェック システムを実装する際に Dropbox がたどった道に関する資料の翻訳の XNUMX 番目の部分を紹介します。
→ 前編: и
入力されたコードが 4 万行に達する
もう XNUMX つの大きな課題 (社内調査対象者の間で XNUMX 番目に多かった懸念事項) は、Dropbox で型チェックの対象となるコードの量が増加することでした。 私たちは、型付きコードベースのサイズを自然に大きくすることから、静的および動的な自動型推論に mypy チームの取り組みを集中させることまで、この問題を解決するためにいくつかのアプローチを試してきました。 最終的には、単純な勝利戦略は存在しないように見えましたが、多くのアプローチを組み合わせることで、アノテーション付きコードの量を急速に増やすことができました。
その結果、当社の最大の Python リポジトリ (バックエンド コードを含む) には、約 4 万行の注釈付きコードが含まれています。 静的コード型付けの作業は約 XNUMX 年かけて完了しました。 Mypy は、入力の進行状況を監視しやすくするさまざまなタイプのコード カバレッジ レポートをサポートするようになりました。 特に、型の明示的な使用など、型に曖昧さがあるコードに関するレポートを生成できます。 Any 検証できない注釈、または型注釈のないサードパーティ ライブラリのインポートなどで。 Dropbox の型チェックの精度を向上させるプロジェクトの一環として、私たちは集中型 Python リポジトリ内のいくつかの人気のあるオープン ソース ライブラリの型定義 (いわゆるスタブ ファイル) の改善に貢献しました。 .
一部の特定の Python パターンに対してより正確な型を可能にする型システムの新機能を実装 (および後続の PEP で標準化) しました。 この顕著な例は次のとおりです TypeDict、それぞれが独自の型の値を持つ文字列キーの固定セットを持つ JSON のような辞書の型を提供します。 今後も型システムを拡張していきます。 次のステップは、Python の数値機能のサポートを改善することになるでしょう。
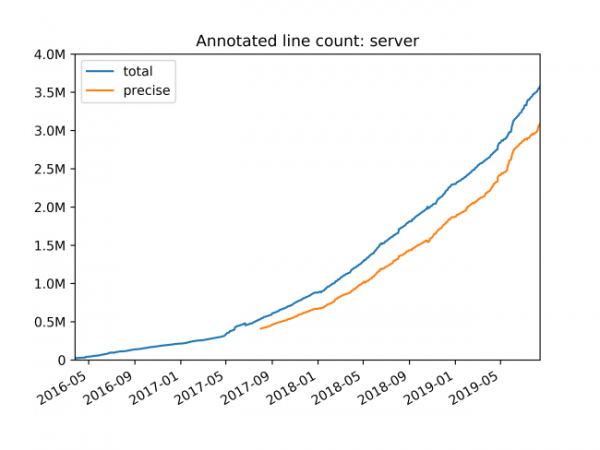
注釈付きコードの行数: サーバー
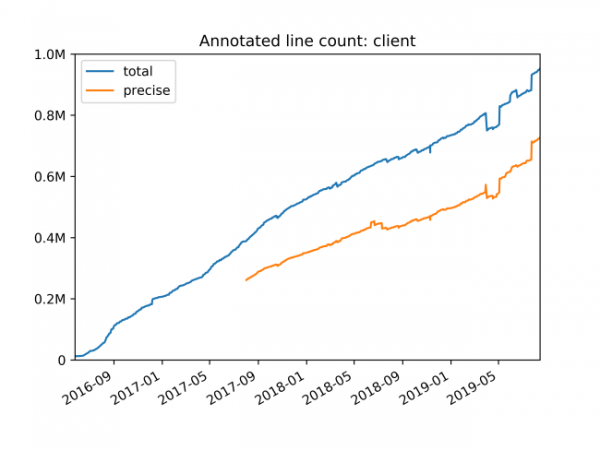
注釈付きコードの行数: クライアント
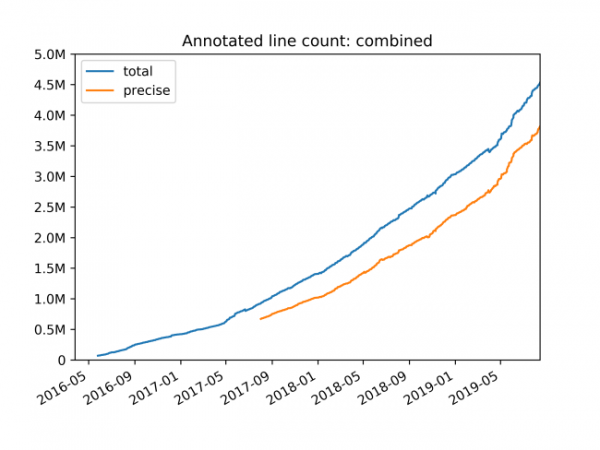
注釈付きコードの総行数
Dropbox 内の注釈付きコードの量を増やすために行った主な機能の概要は次のとおりです。
注釈の厳密さ。 新しいコードに注釈を付ける厳密さの要件を徐々に増やしていきました。 私たちは、すでに注釈が付けられているファイルに注釈を追加することを提案するリンター ヒントから始めました。 新しい Python ファイルとほとんどの既存のファイルで型アノテーションが必要になりました。
レポートを入力しています。 私たちはチームにコードの入力レベルに関するレポートを週次で送信し、最初に何に注釈を付ける必要があるかについてアドバイスを提供します。
マイピーの普及。 私たちはイベントで mypy について話し、チームが型アノテーションを使い始めるのを支援するように話し合います。
世論調査。 重大な問題を特定するために、定期的にユーザー調査を実施します。 私たちはこれらの問題を解決するためにかなりの努力をする準備ができています (mypy を高速化するための新しい言語を作成することさえあります!)。
パフォーマンス。 デーモンと mypyc を使用することで、mypy のパフォーマンスが大幅に向上しました。 これは、注釈プロセス中に発生する不便を軽減し、大量のコードを処理できるようにするために行われました。
エディターとの統合。 Dropbox で人気のあるエディタでの mypy の実行をサポートするツールを構築しました。 これには、PyCharm、Vim、VS Code が含まれます。 これにより、コードに注釈を付けてその機能をチェックするプロセスが大幅に簡素化されました。 これらのタイプのアクションは、既存のコードに注釈を付ける場合に一般的です。
静的解析。 静的解析ツールを使用して関数シグネチャを推測するツールを作成しました。 このツールは比較的単純な状況でのみ機能しますが、それほど苦労せずにコード タイプの範囲を増やすのに役立ちました。
サードパーティライブラリのサポート。 私たちのプロジェクトの多くは SQLAlchemy ツールキットを使用しています。 これは、PEP 484 型では直接モデル化できない Python の動的機能を利用します。 PEP 561 に従って、対応するスタブ ファイルを作成し、mypy 用のプラグインを作成しました ()、SQLAlchemy のサポートが向上します。
私たちが遭遇した困難
4 万行の型付きコードへの道は、私たちにとって必ずしも簡単なものではありませんでした。 この道で私たちはたくさんの穴に遭遇し、いくつかの間違いを犯しました。 これらは私たちが遭遇した問題の一部です。 それらについて伝えることで、他の人が同様の問題を回避するのに役立つことを願っています。
ファイルがありません。 私たちは少量のファイルのみをチェックすることから作業を開始しました。 これらのファイルに含まれていないものはチェックされませんでした。 ファイルは、最初の注釈がファイルに表示されたときにスキャン リストに追加されました。 検証の範囲外にあるモジュールから何かがインポートされた場合、次のような値を扱うことについて話していました。 Any、まったくテストされていませんでした。 これにより、特に移行の初期段階で入力精度が大幅に低下しました。 このアプローチはこれまでのところ驚くほどうまく機能していますが、レビューの範囲にファイルを追加すると、コードベースの他の部分の問題が明らかになるのが一般的な状況です。 最悪の場合、コードの XNUMX つの分離された領域がマージされ、互いに独立して型がチェックされていた場合、これらの領域の型が互いに互換性がないことが判明しました。 そのため、注釈に多くの変更を加える必要がありました。 今振り返ってみると、mypy の型チェック領域にコア ライブラリ モジュールをもっと早く追加すべきだったと気づきました。 これにより、私たちの仕事はより予測可能になります。
古いコードに注釈を付けます。 私たちが始めたとき、既存の Python コードは約 4 万行ありました。 このコードすべてに注釈を付けるのが簡単な作業ではないことは明らかでした。 私たちは、テストの実行時に型情報を収集し、収集した情報に基づいてコードに型注釈を追加できる PyAnnotate というツールを作成しました。 ただし、このツールが特に広く採用されているということはありません。 型情報の収集には時間がかかり、自動生成された注釈には多くの手動編集が必要になることがよくありました。 コードをレビューするたびにこのツールを自動的に実行することや、実際の少量のネットワーク リクエストの分析に基づいて型情報を収集することも考えましたが、どちらのアプローチもリスクが高すぎるため、実行しないことにしました。
その結果、コードの大部分は所有者によって手動で注釈が付けられたことがわかります。 このプロセスを正しい方向に導くために、注釈を付ける必要がある特に重要なモジュールと機能に関するレポートを作成します。 たとえば、何百もの場所で使用されるライブラリ モジュールに型アノテーションを提供することが重要です。 しかし、新しいサービスに置き換えられる古いサービスには、アノテーションを付けることはそれほど重要ではなくなりました。 また、静的解析を使用してレガシー コードの型アノテーションを生成する実験も行っています。
循環インポート。 上で、循環インポート (「依存関係のもつれ」) について説明しました。このインポートの存在により、mypy の高速化が困難になりました。 また、これらの循環インポートによって生じるあらゆる種類のイディオムを mypy でサポートできるようにするために、懸命に取り組む必要がありました。 私たちは最近、循環インポートに関する mypy の問題のほとんどを修正する大規模なシステム再設計プロジェクトを完了しました。 これらの問題は、実際には、mypy プロジェクトが当初焦点を当てていた教育言語である Alore に遡る、プロジェクトの非常に初期の段階に発生しました。 Alore 構文を使用すると、循環インポート コマンドの問題を簡単に解決できます。 最新の mypy は、以前の単純な実装 (Alore に最適でした) からいくつかの制限を継承しています。 Python では、式があいまいなことが主な理由で、循環インポートの操作が困難になります。 たとえば、代入操作では実際に型の別名を定義する場合があります。 Mypy は、インポート ループの大部分が処理されるまで、このようなものを常に検出できるとは限りません。 アローレにはそのような曖昧さはありませんでした。 システム開発の初期段階で不適切な決定を下すと、何年も後にプログラマに不快な驚きをもたらす可能性があります。
結果: 5 万行のコードと新たな地平への道
mypy プロジェクトは、初期のプロトタイプから 4 万行の製品コード タイプを制御するシステムまで、長い道のりを歩んできました。 mypy が進化するにつれて、Python の型ヒントは標準化されました。 最近では、Python コードの入力を中心に強力なエコシステムが発展しています。 ライブラリをサポートする場所があり、IDE とエディタ用の補助ツールが含まれており、いくつかの型制御システムがあり、それぞれに長所と短所があります。
Dropbox では型チェックはすでに当たり前になっていますが、Python コードの入力に関してはまだ初期段階にあると思います。 型チェック技術は今後も進化し、改善されると思います。
大規模な Python プロジェクトで型チェックをまだ使用したことがない場合は、静的型付けへの移行を開始するのに今が非常に良い時期であることを知ってください。 同じような変化を遂げた人たちと話をしました。 彼らの誰もそれを後悔していませんでした。 型チェックにより、Python は「通常の Python」よりも大規模プロジェクトの開発にはるかに適した言語になります。
親愛なる読者! Python プロジェクトで型チェックを使用していますか?
出所: habr.com
