


痛いのは最初だけ!
こんにちは、みんな!親愛なる皆さん、この記事では、リポジトリに基づいて TensorRT、RetinaNet を使用した私の経験を共有したいと思います。 (これは公式のカブのフォークです これにより、最適化されたモデルを実稼働環境でできるだけ早く使用し始めることができます)。コミュニティチャンネルのメッセージをスクロールする 、TensorRT の使用に関する質問に遭遇しており、その質問はほとんど繰り返されているため、書くことにしました。 可能な限り完全な TensorRT、RetinaNet、Unet、docker に基づく高速推論を使用するためのガイド。
タスクの説明
タスクを次のように定式化することを提案します。データセットにラベルを付け、Pytorch 1.3+ で RetinaNet/Unet ネットワークをトレーニングし、取得した重みを ONNX に変換し、次にそれらを TensorRT エンジンに変換して、できれば Docker で全体を実行する必要があります。 Ubuntu 18 ARM (Jetson)* アーキテクチャでは非常に望ましく、環境の手動展開を最小限に抑えます。最終的な成果は、RetinaNet/Unet のエクスポートとトレーニングだけでなく、必要なすべてのハードウェアを備えた、分類およびセグメンテーションシステムの本格的な開発とトレーニングにも対応できるコンテナになります。
ステージ 1. 環境の準備
ここで注意しなければならないのは、最近私はデスクトップ マシンや devbox 上で少なくとも一部のライブラリの使用と展開を完全に放棄したということです。作成してインストールする必要があるのは、deb からの Python 仮想環境と cuda 10.2 (nvidia ドライバーを XNUMX つに制限できます) だけです。
新しくインストールしたと仮定しましょう Ubuntu 18. CUDA 10.2 (deb) をインストールしましょう。インストール手順については、公式ドキュメントで十分説明されているので、ここでは詳しく説明しません。
それでは、docker をインストールしましょう。docker インストール ガイドは簡単に見つかります。ここに例を示します。 、バージョン 19 以降はすでに利用可能です - インストールしてください。まあ、sudo なしで docker を使用できるようにすることを忘れないでください。そうすることでより便利になります。すべてがうまくいった後、次のことを行います。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
公式リポジトリを見る必要さえありません .
それでは git clone を実行しましょう .
残りわずかです。nvidia イメージで docker を使用し始めるには、NGC Cloud に登録してログインする必要があります。ここに行きましょう 、登録し、NGC Cloud に入ったら、画面の左上隅にある [セットアップ] をクリックするか、このリンクをクリックします。 。 「キーの生成」をクリックします。保存することをお勧めします。保存しないと、次回アクセスしたときに再度生成し、新しい車に展開してこの操作を繰り返す必要があります。
やろう:
docker login nvcr.io
Username: $oauthtoken
Password: <Your Key> - сгенерированный ключ
ユーザー名は単純にコピーされます。さて、デプロイされた環境を検討してください。
ステージ 2: Docker コンテナの構築
作業の第 2 段階では、docker を構築し、その内部を理解します。
retina-examples プロジェクトに関連するルート フォルダーに移動して実行しましょう。
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
現在のユーザーを Docker に渡すことによって Docker を構築します。これは、現在のユーザーの権限でマウントされた VOLUME に何かを書き込む場合に非常に便利です。そうでない場合は、root になり面倒になります。
docker の構築中に、Dockerfile を調べてみましょう。
FROM nvcr.io/nvidia/pytorch:19.10-py3
ARG USER=alex
ARG UID=1000
ARG GID=1000
ARG PW=alex
RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd
RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo
RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master
COPY . retinanet/
RUN pip install --no-cache-dir -e retinanet/
RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
RUN pip install tensorboardx
RUN pip install albumentations
RUN pip install setproctitle
RUN pip install paramiko
RUN pip install flask
RUN pip install mem_top
RUN pip install arrow
RUN pip install pycuda
RUN pip install torchvision
RUN pip install pretrainedmodels
RUN pip install efficientnet-pytorch
RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch
RUN pip install pytorch_toolbelt
RUN chown -R ${USER}:${USER} retinanet/
RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace
RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap
RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping
RUN mkdir /var/run/sshd
RUN echo 'root:pass' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@sessions*requireds*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
CMD ["/usr/sbin/sshd", "-D"]
本文から分かるように、私たちはお気に入りのライブラリをすべて使用し、retinanet をコンパイルし、作業を容易にするための基本的なツールをいくつか追加しました。 Ubuntu そして、OpenSSHサーバーを設定します。最初の行は、NGC Cloudログインを作成したNVIDIAイメージを継承しており、このイメージにはPytorch1.3、TensorRT6.xxx、および検出器のCPPソースコードをコンパイルするために必要なその他のライブラリが多数含まれています。
ステージ 3: Docker コンテナの起動とデバッグ
コンテナーと開発環境を使用する主なケースに移りましょう。まず、nvidia docker を起動しましょう。やろう:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latestコンテナに ssh 経由でアクセスできるようになりました@ローカルホスト。起動に成功したら、PyCharm でプロジェクトを開きます。次に開けます
Settings->Project Interpreter->Add->Ssh Interpreter ステップ1
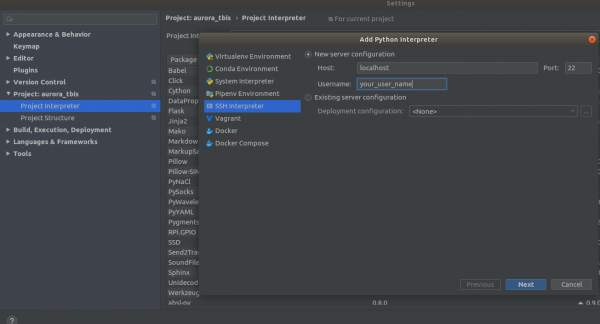
ステップ2
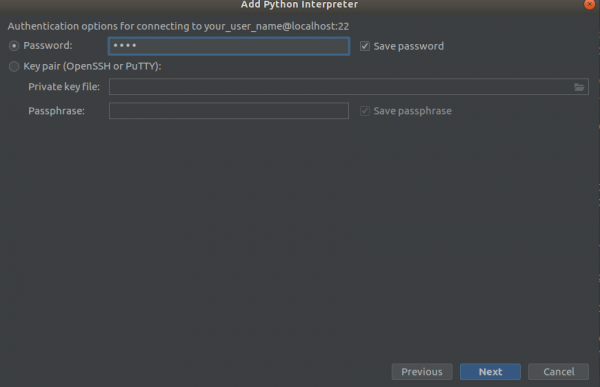
ステップ3
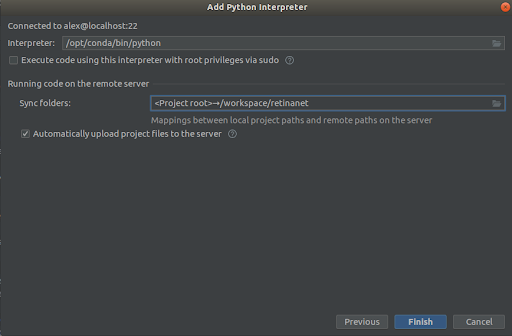
スクリーンショットのようにすべてを選択します。
Interpreter -> /opt/conda/bin/python- これは Python3.6 では ln になります。
Sync folder -> /workspace/retinanet終了を押してインデックス作成を待つだけで、環境が使用できるようになります。
重要! インデックス作成の直後に、Retinanet 用にコンパイルされたファイルを Docker からプルします。プロジェクト ルートのコンテキスト メニューで、項目を選択します
Deployment->Download1 つのファイルと 2 つのフォルダー (build、retinanet.egg-info、および _С.so) が表示されます。
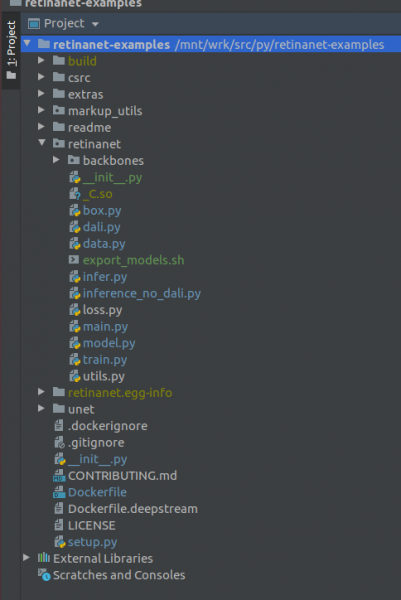
プロジェクトが次のようであれば、環境は必要なファイルをすべて認識しており、RetinaNet をトレーニングする準備が整っています。
ステージ 4. データにラベルを付け、検出器をトレーニングする
私が主に使用するマークアップには — 快適で便利なツールですが、最近多くのバグが修正され、動作が大幅に改善されました。
データセットをマークアップしてダウンロードしたと仮定しますが、データセットは独自の形式であり、そのためには COCO に変換する必要があるため、すぐに RetinaNet に入れることはできません。変換ツールは次の場所にあります。
markup_utils/supervisly_to_coco.pyスクリプト内のカテゴリは一例であり、独自のカテゴリを挿入する必要があることに注意してください (背景のカテゴリを追加する必要はありません)。
categories = [{'id': 1, 'name': '1'},
{'id': 2, 'name': '2'},
{'id': 3, 'name': '3'},
{'id': 4, 'name': '4'}] 何らかの理由で、元のリポジトリの作成者は、検出のために COCO/VOC 以外のものはトレーニングしないと決定したため、ソース ファイルを少し編集する必要がありました。
retinanet/dataset.pyここにお気に入りの拡張機能を追加すると、 そして、COCO から固定的なカテゴリーを削除します。大きな検出エリアをトリミングすることもできます。大きな写真の中で小さなオブジェクトを探している場合、データセットが小さい =) と何も機能しませんが、これについてはまた別の機会に説明します。
一般に、電車のループも弱く、最初はチェックポイントを保存しなかったり、ある種のひどいスケジューラーを使用したりしていました。ただし、あとはバックボーンを選択して実行するだけです。
/opt/conda/bin/python retinanet/main.pyパラメータ付き:
train retinanet_rn34fpn.pth
--backbone ResNet34FPN
--classes 12
--val-iters 10
--images /workspace/mounted_vol/dataset/train/images
--annotations /workspace/mounted_vol/dataset/train_12_class.json
--val-images /workspace/mounted_vol/dataset/test/images_small
--val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json
--jitter 256 512
--max-size 512
--batch 32
コンソールには次の内容が表示されます。
Initializing model...
model: RetinaNet
backbone: ResNet18FPN
classes: 2, anchors: 9
Selected optimization level O0: Pure FP32 training.
Defaults for this optimization level are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 1.0
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O0
cast_model_type : torch.float32
patch_torch_functions : False
keep_batchnorm_fp32 : None
master_weights : False
loss_scale : 128.0
Preparing dataset...
loader: pytorch
resize: [1024, 1280], max: 1280
device: 4 gpus
batch: 4, precision: mixed
Training model for 20000 iterations...
[ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001
[ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001
[ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001
[ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001
[ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001
[ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001
[ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001
[ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001
[ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001
[ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001
[ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001
[ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001
[ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001
[ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000
Saving model: 148パラメータのセット全体を調べるには、次を参照してください。
retinanet/main.py一般に、これらは検出の標準であり、説明が付いています。トレーニングを開始して結果を待ちます。推論の例は次のとおりです。
retinanet/infer_example.pyまたは次のコマンドを実行します。
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth
--images /workspace/mounted_vol/dataset/test/images
--annotations /workspace/mounted_vol/dataset/val.json
--output result.json
--resize 256
--max-size 512
--batch 32
リポジトリにはすでに Focal Loss といくつかのバックボーンが組み込まれており、独自のバックボーンを組み込むことも簡単です
retinanet/backbones/*.py著者らは表の中でいくつかの特徴を示しています。
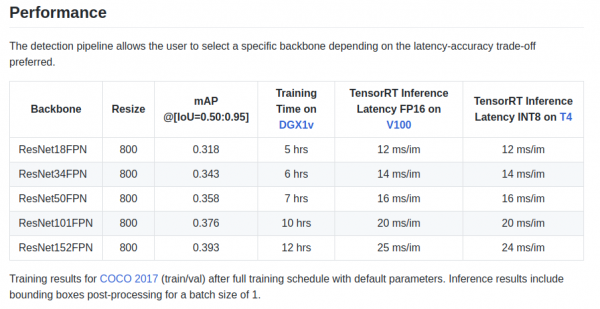
torchvision から取得したバックボーン ResNeXt50_32x4dFPN および ResNeXt101_32x8dFPN もあります。
検出について少しは理解できたと思いますが、公式ドキュメントを必ず読んでください。 エクスポートモードとロギングモードを理解する.
ステージ 5. Resnet エンコーダーを使用した Unet モデルのエクスポートと推論
お気づきかと思いますが、セグメンテーション用のライブラリは Dockerfile にインストールされており、特に素晴らしい lib 。 Unitet パッケージには、推論の例と pytorch チェックポイントの TensorRT エンジンへのエクスポートの例があります。
Unet のようなモデルを ONNX から TensoRT にエクスポートするときの主な問題は、固定のアップサンプル サイズを設定するか、ConvTranspose2D を使用する必要があることです。
import torch.onnx.symbolic_opset9 as onnx_symbolic
def upsample_nearest2d(g, input, output_size):
# Currently, TRT 5.1/6.0 ONNX Parser does not support all ONNX ops
# needed to support dynamic upsampling ONNX forumlation
# Here we hardcode scale=2 as a temporary workaround
scales = g.op("Constant", value_t=torch.tensor([1., 1., 2., 2.]))
return g.op("Upsample", input, scales, mode_s="nearest")
onnx_symbolic.upsample_nearest2d = upsample_nearest2d
この変換を使用すると、ONNX にエクスポートするときにこれを自動的に行うことができますが、TensorRT のバージョン 7 ではすでにこの問題は解決されており、かなり待たなければなりません。
まとめ
docker を使い始めたとき、自分のタスクに対する docker のパフォーマンスに疑問を感じていました。現在、私のユニットの 1 つでは、複数のカメラによって大量のネットワーク トラフィックが生成されています。
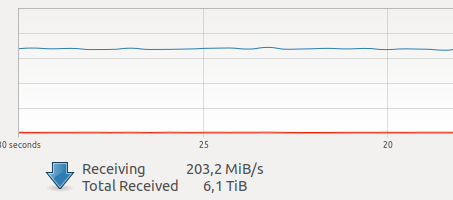
インターネット上のさまざまなテストでは、ネットワーク インタラクションと VOLUME での記録に比較的大きなオーバーヘッドがあり、未知の恐ろしい GIL が存在することが報告されています。また、フレームのキャプチャ、ドライバーの操作、およびネットワーク経由でのフレームの送信は、このモードではアトミックな操作であるため、 ハードリアルタイム, ネットワークの遅延は私にとって非常に重要です。
しかし、すべてがうまくいきました =)
PS 残っているのは、セグメンテーションと制作用にお気に入りの列車ループを追加することだけです。
ありがとう
コミュニティのおかげで 、それなしでは開発は不可能です。どうもありがとう 、彼の貴重なアドバイスと非常に高いプロ意識のおかげで、DLすることを私に勧めてくれました。
本番環境では最適化されたモデルを使用してください。
 オーロライ株式会社
オーロライ株式会社
出所: habr.com
