

ចូរយើងរំលឹកថា Elastic Stack គឺផ្អែកលើមូលដ្ឋានទិន្នន័យ Elasticsearch ដែលមិនទាក់ទងគ្នា ចំណុចប្រទាក់បណ្ដាញ Kibana និងអ្នកប្រមូលទិន្នន័យ និងដំណើរការ (Logstash ដ៏ល្បីល្បាញបំផុត Beats ផ្សេងៗ APM និងផ្សេងៗទៀត)។ ការបន្ថែមដ៏ល្អមួយទៅជង់ផលិតផលដែលបានរាយបញ្ជីទាំងមូលគឺការវិភាគទិន្នន័យដោយប្រើក្បួនដោះស្រាយការរៀនម៉ាស៊ីន។ នៅក្នុងអត្ថបទយើងយល់ពីអ្វីដែលជាក្បួនដោះស្រាយទាំងនេះ។ សូមនៅក្រោមឆ្មា។
ការរៀនម៉ាស៊ីនគឺជាលក្ខណៈពិសេសដែលបានបង់នៃ shareware Elastic Stack ហើយត្រូវបានរួមបញ្ចូលនៅក្នុង X-Pack ។ ដើម្បីចាប់ផ្តើមប្រើវា គ្រាន់តែបើកដំណើរការសាកល្បងរយៈពេល 30 ថ្ងៃបន្ទាប់ពីដំឡើងរួច។ បន្ទាប់ពីរយៈពេលសាកល្បងផុតកំណត់ អ្នកអាចស្នើសុំជំនួយដើម្បីបន្តវា ឬទិញការជាវ។ តម្លៃនៃការជាវមួយត្រូវបានគណនាមិនផ្អែកលើបរិមាណនៃទិន្នន័យនោះទេ ប៉ុន្តែអាស្រ័យលើចំនួនថ្នាំងដែលបានប្រើ។ ទេ បរិមាណនៃទិន្នន័យពិតជាប៉ះពាល់ដល់ចំនួនថ្នាំងដែលត្រូវការ ប៉ុន្តែនៅតែវិធីសាស្រ្តនៃការផ្តល់អាជ្ញាប័ណ្ណនេះគឺមានភាពមនុស្សធម៌ជាងទាក់ទងនឹងថវិការបស់ក្រុមហ៊ុន។ ប្រសិនបើមិនត្រូវការផលិតភាពខ្ពស់ទេ អ្នកអាចសន្សំប្រាក់បាន។
ML នៅក្នុង Elastic Stack ត្រូវបានសរសេរក្នុង C++ ហើយដំណើរការនៅខាងក្រៅ JVM ដែល Elasticsearch ខ្លួនវាដំណើរការ។ នោះគឺជាដំណើរការ (ដោយវិធីនេះវាត្រូវបានគេហៅថា autodetect) ប្រើប្រាស់អ្វីគ្រប់យ៉ាងដែល JVM មិនលេប។ នៅលើការបង្ហាញសាកល្បង នេះមិនមែនជារឿងសំខាន់នោះទេ ប៉ុន្តែនៅក្នុងបរិយាកាសផលិតកម្ម វាមានសារៈសំខាន់ក្នុងការបែងចែកថ្នាំងដាច់ដោយឡែកសម្រាប់កិច្ចការ ML ។
ក្បួនដោះស្រាយការរៀនម៉ាស៊ីនធ្លាក់ជាពីរប្រភេទ − и . នៅក្នុង Elastic Stack ក្បួនដោះស្រាយគឺស្ថិតនៅក្នុងប្រភេទ "មិនមានការត្រួតពិនិត្យ"។ ដោយ អ្នកអាចមើលឃើញឧបករណ៍គណិតវិទ្យានៃក្បួនដោះស្រាយការរៀនម៉ាស៊ីន។
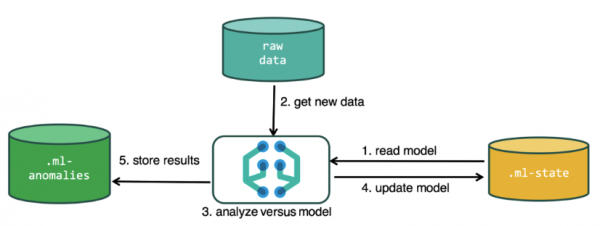
ដើម្បីអនុវត្តការវិភាគ ក្បួនដោះស្រាយការរៀនម៉ាស៊ីនប្រើទិន្នន័យដែលរក្សាទុកក្នុងសន្ទស្សន៍ Elasticsearch ។ អ្នកអាចបង្កើតភារកិច្ចសម្រាប់ការវិភាគទាំងពីចំណុចប្រទាក់ Kibana និងតាមរយៈ API ។ ប្រសិនបើអ្នកធ្វើបែបនេះតាមរយៈ Kibana នោះអ្នកមិនចាំបាច់ដឹងរឿងខ្លះទេ។ ឧទាហរណ៍ លិបិក្រមបន្ថែមដែលក្បួនដោះស្រាយប្រើកំឡុងប្រតិបត្តិការរបស់វា។
សន្ទស្សន៍បន្ថែមដែលប្រើក្នុងដំណើរការវិភាគ.ml-state — ព័ត៌មានអំពីគំរូស្ថិតិ (ការកំណត់ការវិភាគ);
.ml-anomalies-* — លទ្ធផលនៃ ML algorithms;
.ml-notifications — ការកំណត់សម្រាប់ការជូនដំណឹងដោយផ្អែកលើលទ្ធផលវិភាគ។
រចនាសម្ព័ន្ធទិន្នន័យនៅក្នុងមូលដ្ឋានទិន្នន័យ Elasticsearch មានលិបិក្រម និងឯកសារដែលរក្សាទុកក្នុងពួកវា។ នៅពេលប្រៀបធៀបទៅនឹងមូលដ្ឋានទិន្នន័យទំនាក់ទំនង លិបិក្រមអាចប្រៀបធៀបទៅនឹងគ្រោងការណ៍មូលដ្ឋានទិន្នន័យ និងឯកសារទៅកំណត់ត្រាក្នុងតារាងមួយ។ ការប្រៀបធៀបនេះមានលក្ខខណ្ឌ និងត្រូវបានផ្តល់ជូនដើម្បីសម្រួលការយល់ដឹងអំពីសម្ភារៈបន្ថែមទៀតសម្រាប់អ្នកដែលបានឮតែអំពី Elasticsearch ប៉ុណ្ណោះ។
មុខងារដូចគ្នាគឺអាចរកបានតាមរយៈ API ដូចតាមរយៈចំណុចប្រទាក់គេហទំព័រ ដូច្នេះសម្រាប់ភាពច្បាស់លាស់ និងការយល់ដឹងអំពីគោលគំនិត យើងនឹងបង្ហាញពីរបៀបកំណត់វាតាមរយៈ Kibana។ នៅក្នុងម៉ឺនុយនៅខាងឆ្វេងមានផ្នែក Machine Learning ដែលអ្នកអាចបង្កើតការងារថ្មី។ នៅក្នុងចំណុចប្រទាក់ Kibana វាមើលទៅដូចជារូបភាពខាងក្រោម។ ឥឡូវនេះយើងនឹងវិភាគប្រភេទនៃភារកិច្ចនីមួយៗនិងបង្ហាញប្រភេទនៃការវិភាគដែលអាចសាងសង់នៅទីនេះ។
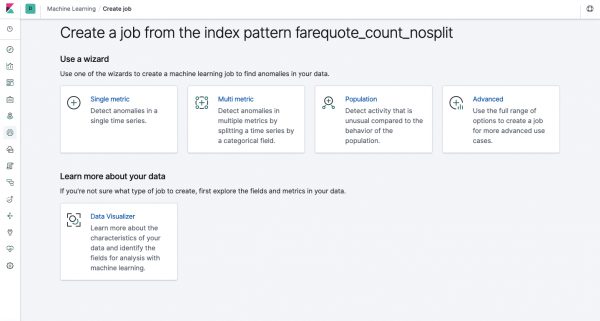
Single Metric - ការវិភាគនៃម៉ែត្រមួយ Multi Metric - ការវិភាគនៃម៉ែត្រពីរឬច្រើន។ ក្នុងករណីទាំងពីរនេះម៉ែត្រនីមួយៗត្រូវបានវិភាគក្នុងបរិយាកាសដាច់ដោយឡែកមួយពោលគឺ។ ក្បួនដោះស្រាយមិនគិតពីឥរិយាបទនៃម៉ែត្រដែលបានវិភាគស្របគ្នានោះទេ ព្រោះវាអាចហាក់ដូចជាក្នុងករណី Multi Metric។ ដើម្បីអនុវត្តការគណនាដោយគិតគូរពីការជាប់ទាក់ទងគ្នានៃម៉ែត្រផ្សេងៗ អ្នកអាចប្រើការវិភាគចំនួនប្រជាជន។ ហើយ Advanced កំពុងធ្វើការកែសំរួលក្បួនដោះស្រាយជាមួយនឹងជម្រើសបន្ថែមសម្រាប់កិច្ចការជាក់លាក់។
ម៉ែត្រតែមួយ
ការវិភាគការផ្លាស់ប្តូរនៅក្នុងម៉ែត្រតែមួយគឺជារឿងសាមញ្ញបំផុតដែលអាចធ្វើបាននៅទីនេះ។ បន្ទាប់ពីចុចលើ បង្កើតការងារ ក្បួនដោះស្រាយនឹងរកមើលភាពមិនប្រក្រតី។
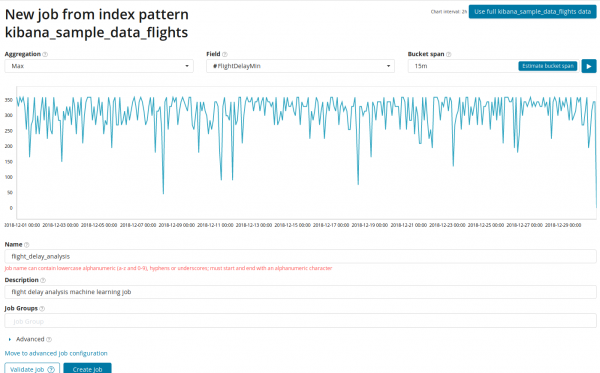
នៅក្នុងវាល ការប្រមូលផ្ដុំ អ្នកអាចជ្រើសរើសវិធីសាស្រ្តក្នុងការស្វែងរកភាពមិនប្រក្រតី។ ឧទាហរណ៍នៅពេល នាទី តម្លៃខាងក្រោមតម្លៃធម្មតានឹងត្រូវបានចាត់ទុកថាមិនប្រក្រតី។ បរិភោគ អតិបរមា, មធ្យមខ្ពស់, ទាប, មធ្យម, ខុសគ្នា ហើយផ្សេងទៀត។ ការពិពណ៌នាអំពីមុខងារទាំងអស់អាចរកបាន .
នៅក្នុងវាល វាល ចង្អុលបង្ហាញវាលលេខនៅក្នុងឯកសារដែលយើងនឹងធ្វើការវិភាគ។
នៅក្នុងវាល - ភាពលម្អិតនៃចន្លោះពេលនៅលើបន្ទាត់ពេលវេលាដែលការវិភាគនឹងត្រូវបានអនុវត្ត។ អ្នកអាចជឿជាក់លើស្វ័យប្រវត្តិកម្ម ឬជ្រើសរើសដោយដៃ។ រូបភាពខាងក្រោមគឺជាឧទាហរណ៍នៃទំហំតូចពេក - អ្នកអាចនឹកភាពមិនប្រក្រតី។ ដោយប្រើការកំណត់នេះ អ្នកអាចផ្លាស់ប្តូរភាពប្រែប្រួលនៃក្បួនដោះស្រាយទៅជាភាពមិនប្រក្រតី។
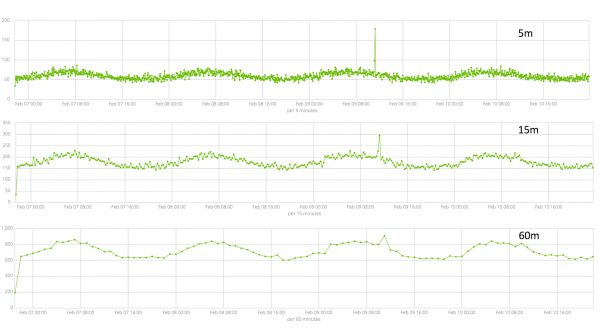
រយៈពេលនៃទិន្នន័យដែលប្រមូលបានគឺជារឿងសំខាន់ដែលប៉ះពាល់ដល់ប្រសិទ្ធភាពនៃការវិភាគ។ កំឡុងពេលវិភាគ ក្បួនដោះស្រាយកំណត់ចន្លោះពេលធ្វើម្តងទៀត គណនាចន្លោះពេលទំនុកចិត្ត (បន្ទាត់មូលដ្ឋាន) និងកំណត់ភាពមិនប្រក្រតី - គម្លាត atypical ពីឥរិយាបថធម្មតារបស់ម៉ែត្រ។ គ្រាន់តែឧទាហរណ៍៖
មូលដ្ឋានទិន្នន័យតូចមួយ៖
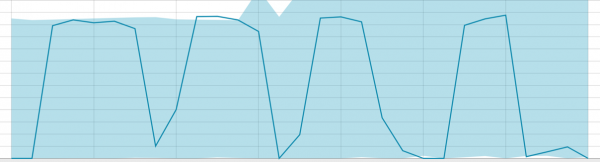
នៅពេលដែល algorithm មានអ្វីដែលត្រូវរៀន បន្ទាត់គោលមើលទៅដូចនេះ៖
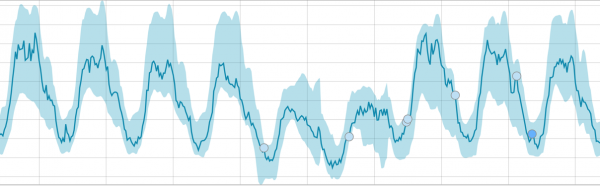
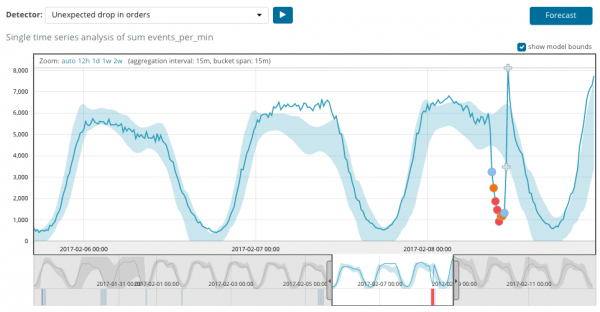
បន្ទាប់ពីចាប់ផ្តើមកិច្ចការ ក្បួនដោះស្រាយកំណត់គម្លាតខុសប្រក្រតីពីបទដ្ឋាន ហើយចាត់ចំណាត់ថ្នាក់ពួកវាតាមប្រូបាប៊ីលីតេនៃភាពមិនប្រក្រតី (ពណ៌នៃស្លាកដែលត្រូវគ្នាត្រូវបានចង្អុលបង្ហាញនៅក្នុងវង់ក្រចក)៖
ការព្រមាន (ពណ៌ខៀវ): តិចជាង 25
អនីតិជន (ពណ៌លឿង): 25-50
សំខាន់ (ពណ៌ទឹកក្រូច): 50-75
សំខាន់ (ក្រហម): 75-100
ក្រាហ្វខាងក្រោមបង្ហាញឧទាហរណ៍នៃភាពមិនប្រក្រតីដែលបានរកឃើញ។
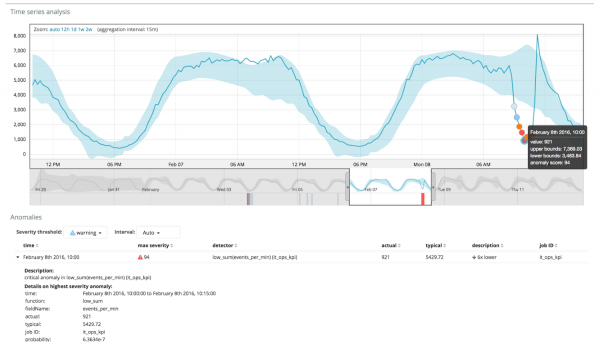
នៅទីនេះអ្នកអាចឃើញលេខ 94 ដែលបង្ហាញពីប្រូបាប៊ីលីតេនៃភាពមិនប្រក្រតី។ វាច្បាស់ណាស់ថាចាប់តាំងពីតម្លៃគឺជិត 100 វាមានន័យថាយើងមានភាពមិនប្រក្រតី។ ជួរឈរខាងក្រោមក្រាហ្វបង្ហាញពីប្រូបាប៊ីលីតេតិចតួចដែលគួរឱ្យស្អប់ខ្ពើមនៃ 0.000063634% នៃតម្លៃម៉ែត្រដែលលេចឡើងនៅទីនោះ។
បន្ថែមពីលើការស្វែងរកភាពមិនប្រក្រតី អ្នកអាចដំណើរការការព្យាករណ៍នៅក្នុង Kibana ។ នេះត្រូវបានធ្វើដោយសាមញ្ញនិងពីទិដ្ឋភាពដូចគ្នាជាមួយនឹងភាពមិនប្រក្រតី - ប៊ូតុង ការទស្សទាយ នៅជ្រុងខាងស្តាំខាងលើ។
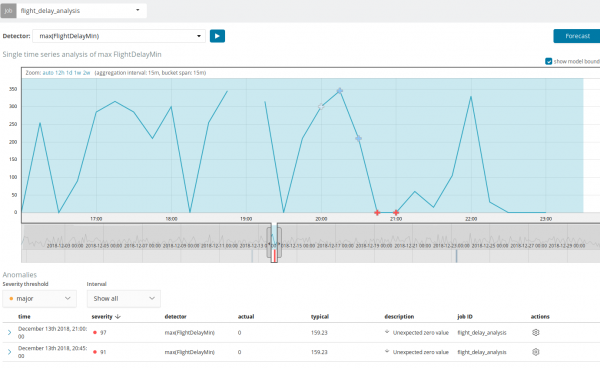
ការព្យាករណ៍ត្រូវបានធ្វើឡើងសម្រាប់រយៈពេលអតិបរមា 8 សប្តាហ៍ជាមុន។ ទោះបីជាអ្នកពិតជាចង់ក៏ដោយ វាមិនអាចទៅរួចនោះទេដោយការរចនា។
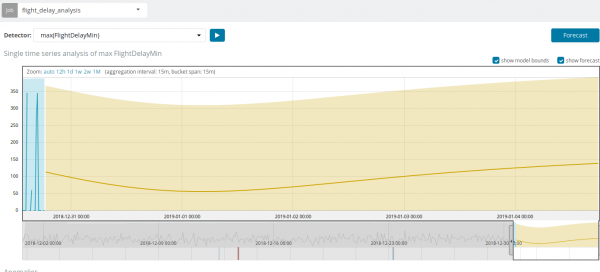
នៅក្នុងស្ថានភាពខ្លះ ការព្យាករណ៍នឹងមានប្រយោជន៍ខ្លាំងណាស់ ឧទាហរណ៍នៅពេលត្រួតពិនិត្យការផ្ទុកអ្នកប្រើប្រាស់លើហេដ្ឋារចនាសម្ព័ន្ធ។
ពហុម៉ែត្រ
ចូរបន្តទៅមុខងារ ML បន្ទាប់នៅក្នុង Elastic Stack - ការវិភាគម៉ែត្រជាច្រើនក្នុងមួយបាច់។ ប៉ុន្តែនេះមិនមានន័យថាការពឹងផ្អែកនៃម៉ែត្រមួយទៅម៉ែត្រមួយផ្សេងទៀតនឹងត្រូវបានវិភាគនោះទេ។ នេះគឺដូចគ្នានឹង Single Metric ដែរ ប៉ុន្តែមានម៉ែត្រច្រើននៅលើអេក្រង់មួយ ដើម្បីងាយស្រួលក្នុងការប្រៀបធៀបផលប៉ះពាល់នៃឥទ្ធិពលមួយទៅមួយទៀត។ យើងនឹងនិយាយអំពីការវិភាគការអាស្រ័យនៃម៉ែត្រមួយលើម៉ែត្រមួយទៀតនៅក្នុងផ្នែកចំនួនប្រជាជន។
បន្ទាប់ពីចុចលើការេជាមួយ Multi Metric បង្អួចដែលមានការកំណត់នឹងលេចឡើង។ សូមក្រឡេកមើលពួកវាឱ្យបានលំអិត។
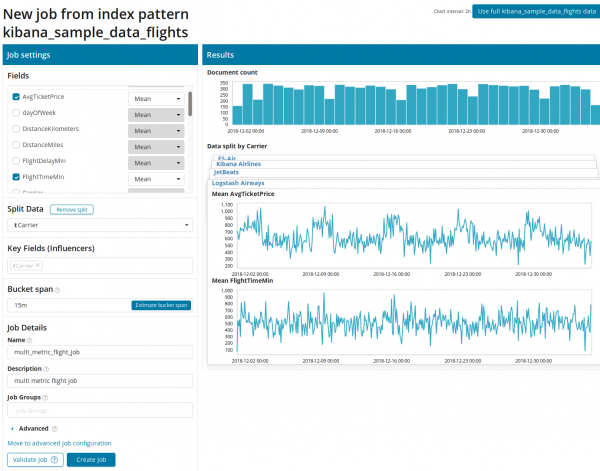
ដំបូងអ្នកត្រូវជ្រើសរើសវាលសម្រាប់ការវិភាគ និងការប្រមូលផ្តុំទិន្នន័យនៅលើពួកវា។ ជម្រើសនៃការប្រមូលផ្តុំនៅទីនេះគឺដូចគ្នាទៅនឹង Single Metric (អតិបរមា, មធ្យមខ្ពស់, ទាប, មធ្យម, ខុសគ្នា ហើយផ្សេងទៀត)។ លើសពីនេះ ប្រសិនបើចង់បាន ទិន្នន័យត្រូវបានបែងចែកទៅជាវាលមួយ (វាល បំបែកទិន្នន័យ) ក្នុងឧទាហរណ៍ យើងបានធ្វើវាតាមវាល លេខសម្គាល់ព្រលានយន្តហោះប្រភពដើម. សូមកត់សម្គាល់ថា ក្រាហ្វម៉ែត្រខាងស្ដាំឥឡូវត្រូវបានបង្ហាញជាក្រាហ្វច្រើន។
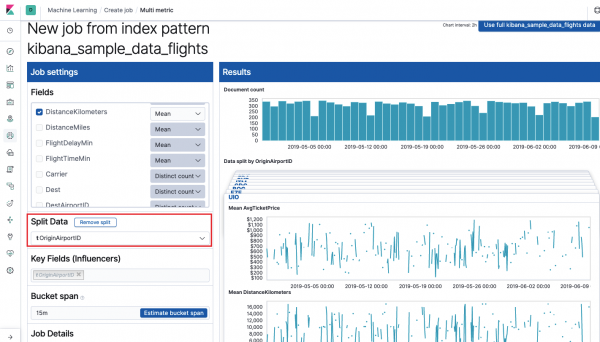
វាល វាលសំខាន់ៗ (អ្នកមានឥទ្ធិពល) ប៉ះពាល់ដោយផ្ទាល់ទៅលើភាពមិនប្រក្រតីដែលបានរកឃើញ។ តាមលំនាំដើម វាតែងតែមានតម្លៃយ៉ាងហោចណាស់មួយនៅទីនេះ ហើយអ្នកអាចបន្ថែមតម្លៃបន្ថែមបាន។ ក្បួនដោះស្រាយនឹងគិតគូរពីឥទ្ធិពលនៃវាលទាំងនេះ នៅពេលវិភាគ និងបង្ហាញតម្លៃ "ឥទ្ធិពល" បំផុត។
បន្ទាប់ពីបើកដំណើរការ អ្វីមួយដូចនេះនឹងបង្ហាញនៅក្នុងចំណុចប្រទាក់ Kibana។
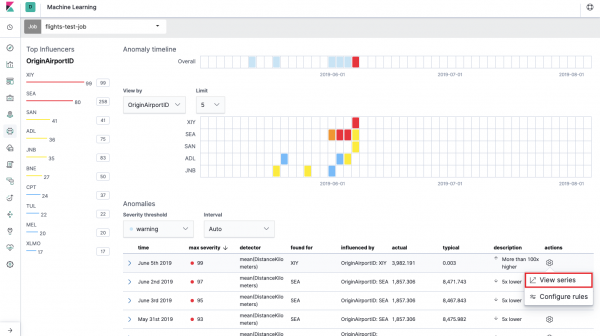
នេះគឺជាអ្វីដែលគេហៅថា ផែនទីកំដៅនៃភាពមិនប្រក្រតីសម្រាប់តម្លៃវាលនីមួយៗ លេខសម្គាល់ព្រលានយន្តហោះប្រភពដើមដែលយើងបានបង្ហាញនៅក្នុង បំបែកទិន្នន័យ. ដូចទៅនឹង Single Metric ពណ៌បង្ហាញពីកម្រិតនៃគម្លាតមិនប្រក្រតី។ វាងាយស្រួលធ្វើការវិភាគស្រដៀងគ្នា ឧទាហរណ៍នៅលើស្ថានីយការងារ ដើម្បីតាមដានអ្នកដែលមានការអនុញ្ញាតច្រើនគួរឱ្យសង្ស័យ។ល។ យើងបានសរសេររួចហើយ ដែលអាចត្រូវបានប្រមូល និងវិភាគនៅទីនេះផងដែរ។
ខាងក្រោមផែនទីកំដៅគឺជាបញ្ជីនៃភាពមិនប្រក្រតី ពីនីមួយៗអ្នកអាចប្តូរទៅទិដ្ឋភាពម៉ែត្រតែមួយសម្រាប់ការវិភាគលម្អិត។
ចំនួនប្រជាជន
ដើម្បីរកមើលភាពមិនប្រក្រតីក្នុងចំណោមទំនាក់ទំនងរវាងម៉ែត្រផ្សេងគ្នា Elastic Stack មានការវិភាគចំនួនប្រជាជនពិសេស។ វាគឺដោយមានជំនួយរបស់វាដែលអ្នកអាចរកមើលតម្លៃមិនធម្មតានៅក្នុងដំណើរការនៃម៉ាស៊ីនមេបើប្រៀបធៀបទៅនឹងអ្នកផ្សេងទៀតនៅពេលដែលឧទាហរណ៍ចំនួននៃសំណើទៅកាន់ប្រព័ន្ធគោលដៅកើនឡើង។
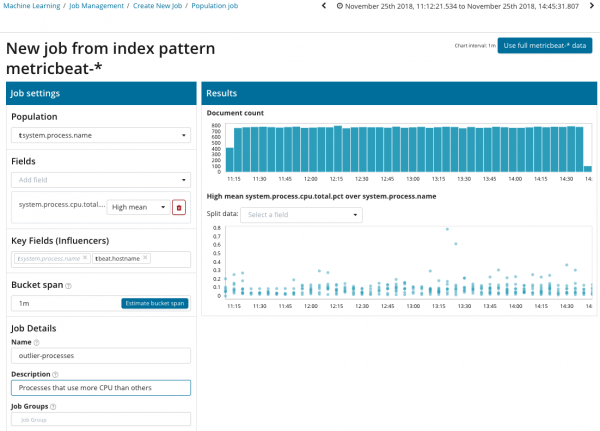
នៅក្នុងរូបភាពនេះ វាលចំនួនប្រជាជនបង្ហាញពីតម្លៃដែលម៉ែត្រដែលបានវិភាគនឹងទាក់ទង។ ក្នុងករណីនេះវាគឺជាឈ្មោះនៃដំណើរការ។ ជាលទ្ធផល យើងនឹងឃើញពីរបៀបដែលបន្ទុកដំណើរការនៃដំណើរការនីមួយៗមានឥទ្ធិពលលើគ្នាទៅវិញទៅមក។
សូមចំណាំថាក្រាហ្វនៃទិន្នន័យដែលបានវិភាគខុសពីករណីដែលមាន Single Metric និង Multi Metric។ នេះត្រូវបានធ្វើនៅក្នុង Kibana ដោយការរចនាសម្រាប់ការយល់ឃើញប្រសើរឡើងនៃការចែកចាយតម្លៃនៃទិន្នន័យដែលបានវិភាគ។
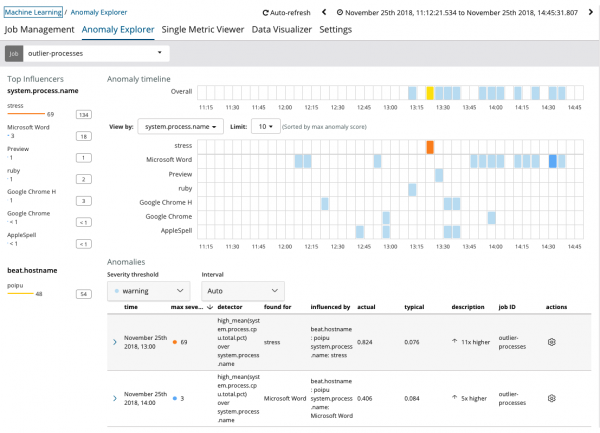
ក្រាហ្វបង្ហាញថាដំណើរការមានដំណើរការខុសប្រក្រតី ភាពតានតឹង (ដោយវិធីនេះ បង្កើតដោយឧបករណ៍ប្រើប្រាស់ពិសេស) នៅលើម៉ាស៊ីនមេ ប៉ោយពូដែលមានឥទ្ធិពល (ឬប្រែទៅជាអ្នកមានឥទ្ធិពល) ការកើតឡើងនៃភាពមិនធម្មតានេះ។
Advanced
ការវិភាគជាមួយការកែតម្រូវ។ ជាមួយនឹងការវិភាគកម្រិតខ្ពស់ ការកំណត់បន្ថែមបង្ហាញនៅក្នុង Kibana។ បន្ទាប់ពីចុចលើផ្ទាំងកម្រិតខ្ពស់នៅក្នុងម៉ឺនុយបង្កើត បង្អួចដែលមានផ្ទាំងនេះលេចឡើង។ ផ្ទាំង ព័ត៌មានលំអិតការងារ។ យើងបានរំលងវាដោយគោលបំណង មានការកំណត់មូលដ្ឋានដែលមិនទាក់ទងដោយផ្ទាល់ទៅនឹងការដំឡើងការវិភាគ។
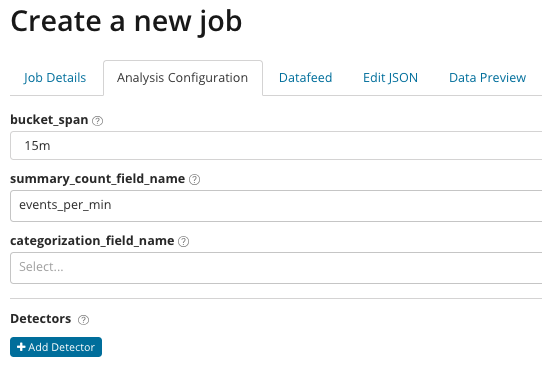
В summary_count_field_name ជាជម្រើស អ្នកអាចបញ្ជាក់ឈ្មោះវាលពីឯកសារដែលមានតម្លៃសរុប។ ក្នុងឧទាហរណ៍នេះ ចំនួនព្រឹត្តិការណ៍ក្នុងមួយនាទី។ IN បង្ហាញឈ្មោះ និងតម្លៃនៃវាលពីឯកសារដែលមានតម្លៃអថេរមួយចំនួន។ ដោយប្រើរបាំងនៅលើវាលនេះ អ្នកអាចបំបែកទិន្នន័យដែលបានវិភាគទៅជាសំណុំរង។ យកចិត្តទុកដាក់លើប៊ូតុង បន្ថែមឧបករណ៍ចាប់សញ្ញា នៅក្នុងរូបភាពមុន។ ខាងក្រោមនេះជាលទ្ធផលនៃការចុចប៊ូតុងនេះ។
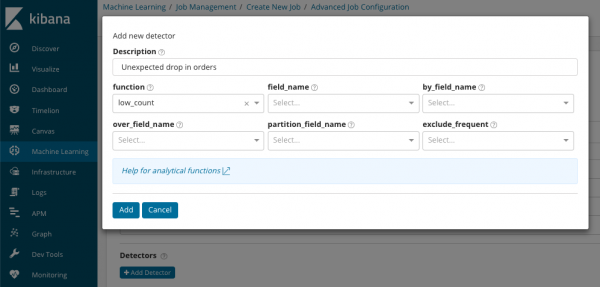
នេះគឺជាប្លុកបន្ថែមនៃការកំណត់សម្រាប់កំណត់រចនាសម្ព័ន្ធឧបករណ៍ចាប់ភាពមិនប្រក្រតីសម្រាប់កិច្ចការជាក់លាក់មួយ។ យើងមានគម្រោងពិភាក្សាអំពីករណីប្រើប្រាស់ជាក់លាក់ (ជាពិសេសសុវត្ថិភាព) នៅក្នុងអត្ថបទខាងក្រោម។ ឧទាហរណ៍, ករណីមួយក្នុងចំណោមករណីដែលត្រូវបានរុះរើ។ វាត្រូវបានផ្សារភ្ជាប់ជាមួយនឹងការស្វែងរកតម្លៃដែលកម្រនឹងលេចឡើងហើយត្រូវបានអនុវត្ត .
នៅក្នុងវាល មុខងារ អ្នកអាចជ្រើសរើសមុខងារជាក់លាក់មួយដើម្បីស្វែងរកភាពមិនប្រក្រតី។ លើកលែងតែ កម្រមានមុខងារគួរឱ្យចាប់អារម្មណ៍ពីរបីទៀត - . ពួកគេកំណត់អត្តសញ្ញាណភាពមិនប្រក្រតីនៅក្នុងឥរិយាបទនៃម៉ែត្រពេញមួយថ្ងៃ ឬសប្តាហ៍រៀងៗខ្លួន។ មុខងារវិភាគផ្សេងៗ .
В ឈ្មោះវាល ចង្អុលបង្ហាញវាលនៃឯកសារដែលការវិភាគនឹងត្រូវបានអនុវត្ត។ By_field_name អាចត្រូវបានប្រើដើម្បីបំបែកលទ្ធផលវិភាគសម្រាប់តម្លៃនីមួយៗនៃវាលឯកសារដែលបានបញ្ជាក់នៅទីនេះ។ ប្រសិនបើអ្នកបំពេញ over_field_name អ្នកទទួលបានការវិភាគចំនួនប្រជាជនដែលយើងបានពិភាក្សាខាងលើ។ ប្រសិនបើអ្នកបញ្ជាក់តម្លៃនៅក្នុង partition_field_nameបន្ទាប់មកសម្រាប់វាលនៃឯកសារនេះ បន្ទាត់មូលដ្ឋានដាច់ដោយឡែកនឹងត្រូវបានគណនាសម្រាប់តម្លៃនីមួយៗ (តម្លៃអាចជាឧទាហរណ៍ ឈ្មោះរបស់ម៉ាស៊ីនមេ ឬដំណើរការនៅលើម៉ាស៊ីនមេ)។ IN មិនរាប់បញ្ចូល_ញឹកញាប់ អាចជ្រើសរើសបាន ទាំងអស់ ឬ គ្មានដែលនឹងមានន័យថាមិនរាប់បញ្ចូល (ឬរួមបញ្ចូល) តម្លៃវាលឯកសារដែលកើតឡើងញឹកញាប់។
នៅក្នុងអត្ថបទនេះ យើងបានព្យាយាមផ្តល់គំនិតឱ្យខ្លីតាមដែលអាចធ្វើទៅបានអំពីសមត្ថភាពនៃការរៀនម៉ាស៊ីននៅក្នុង Elastic Stack វានៅតែមានព័ត៌មានលម្អិតជាច្រើនដែលបន្សល់ទុកនៅខាងក្រោយឆាក។ ប្រាប់យើងនៅក្នុងមតិយោបល់អំពីករណីដែលអ្នកបានដោះស្រាយដោយប្រើ Elastic Stack និងកិច្ចការអ្វីដែលអ្នកប្រើវាសម្រាប់។ ដើម្បីទាក់ទងមកយើងខ្ញុំ អ្នកអាចប្រើសារផ្ទាល់ខ្លួននៅលើ Habre ឬ .
ប្រភព: www.habr.com
