

ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಪೂರ್ಣ ಕ್ರಿಯಾತ್ಮಕತೆಗೆ ಮರುಸ್ಥಾಪಿಸುವ ನನ್ನ ಮೊದಲ ಯಶಸ್ವಿ ಅನುಭವವನ್ನು ನಿಮ್ಮೊಂದಿಗೆ ಹಂಚಿಕೊಳ್ಳಲು ನಾನು ಬಯಸುತ್ತೇನೆ. ನಾನು ಅರ್ಧ ವರ್ಷದ ಹಿಂದೆ ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಡಿಬಿಎಂಎಸ್ನೊಂದಿಗೆ ಪರಿಚಯವಾಯಿತು, ಅದಕ್ಕೂ ಮೊದಲು ನನಗೆ ಡೇಟಾಬೇಸ್ ಆಡಳಿತದಲ್ಲಿ ಯಾವುದೇ ಅನುಭವವಿರಲಿಲ್ಲ.

ನಾನು ದೊಡ್ಡ IT ಕಂಪನಿಯಲ್ಲಿ ಅರೆ-DevOps ಇಂಜಿನಿಯರ್ ಆಗಿ ಕೆಲಸ ಮಾಡುತ್ತಿದ್ದೇನೆ. ನಮ್ಮ ಕಂಪನಿಯು ಹೆಚ್ಚಿನ ಲೋಡ್ ಸೇವೆಗಳಿಗಾಗಿ ಸಾಫ್ಟ್ವೇರ್ ಅನ್ನು ಅಭಿವೃದ್ಧಿಪಡಿಸುತ್ತದೆ ಮತ್ತು ಕಾರ್ಯಕ್ಷಮತೆ, ನಿರ್ವಹಣೆ ಮತ್ತು ನಿಯೋಜನೆಗೆ ನಾನು ಜವಾಬ್ದಾರನಾಗಿರುತ್ತೇನೆ. ನನಗೆ ಪ್ರಮಾಣಿತ ಕಾರ್ಯವನ್ನು ನೀಡಲಾಗಿದೆ: ಒಂದು ಸರ್ವರ್ನಲ್ಲಿ ಅಪ್ಲಿಕೇಶನ್ ಅನ್ನು ನವೀಕರಿಸಲು. ಅಪ್ಲಿಕೇಶನ್ ಅನ್ನು ಜಾಂಗೊದಲ್ಲಿ ಬರೆಯಲಾಗಿದೆ, ನವೀಕರಣದ ಸಮಯದಲ್ಲಿ ವಲಸೆಗಳನ್ನು ನಡೆಸಲಾಗುತ್ತದೆ (ಡೇಟಾಬೇಸ್ ರಚನೆಯಲ್ಲಿ ಬದಲಾವಣೆಗಳು), ಮತ್ತು ಈ ಪ್ರಕ್ರಿಯೆಯ ಮೊದಲು ನಾವು ಪ್ರಮಾಣಿತ pg_dump ಪ್ರೋಗ್ರಾಂ ಮೂಲಕ ಪೂರ್ಣ ಡೇಟಾಬೇಸ್ ಡಂಪ್ ಅನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ.
ಡಂಪ್ ತೆಗೆದುಕೊಳ್ಳುವಾಗ ಅನಿರೀಕ್ಷಿತ ದೋಷ ಸಂಭವಿಸಿದೆ (ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಆವೃತ್ತಿ 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly ದೋಷ "ಬ್ಲಾಕ್ನಲ್ಲಿ ಅಮಾನ್ಯ ಪುಟ" ಫೈಲ್ ಸಿಸ್ಟಮ್ ಮಟ್ಟದಲ್ಲಿ ಸಮಸ್ಯೆಗಳ ಬಗ್ಗೆ ಮಾತನಾಡುತ್ತಾರೆ, ಅದು ತುಂಬಾ ಕೆಟ್ಟದಾಗಿದೆ. ವಿವಿಧ ವೇದಿಕೆಗಳಲ್ಲಿ ಇದನ್ನು ಮಾಡಲು ಸೂಚಿಸಲಾಗಿದೆ ಪೂರ್ಣ ನಿರ್ವಾತ ಆಯ್ಕೆಯೊಂದಿಗೆ ಶೂನ್ಯ_ಹಾನಿಗೊಳಗಾದ_ಪುಟಗಳು ಈ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸಲು. ಸರಿ, ಪ್ರಯತ್ನಿಸೋಣ ...
ಚೇತರಿಕೆಗೆ ತಯಾರಿ
ಗಮನ! ನಿಮ್ಮ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಮರುಸ್ಥಾಪಿಸುವ ಯಾವುದೇ ಪ್ರಯತ್ನದ ಮೊದಲು ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಬ್ಯಾಕಪ್ ತೆಗೆದುಕೊಳ್ಳಲು ಮರೆಯದಿರಿ. ನೀವು ವರ್ಚುವಲ್ ಯಂತ್ರವನ್ನು ಹೊಂದಿದ್ದರೆ, ಡೇಟಾಬೇಸ್ ಅನ್ನು ನಿಲ್ಲಿಸಿ ಮತ್ತು ಸ್ನ್ಯಾಪ್ಶಾಟ್ ತೆಗೆದುಕೊಳ್ಳಿ. ಸ್ನ್ಯಾಪ್ಶಾಟ್ ತೆಗೆದುಕೊಳ್ಳಲು ಸಾಧ್ಯವಾಗದಿದ್ದರೆ, ಡೇಟಾಬೇಸ್ ಅನ್ನು ನಿಲ್ಲಿಸಿ ಮತ್ತು ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಡೈರೆಕ್ಟರಿಯ ವಿಷಯಗಳನ್ನು (ವಾಲ್ ಫೈಲ್ಗಳನ್ನು ಒಳಗೊಂಡಂತೆ) ಸುರಕ್ಷಿತ ಸ್ಥಳಕ್ಕೆ ನಕಲಿಸಿ. ನಮ್ಮ ವ್ಯವಹಾರದಲ್ಲಿ ಮುಖ್ಯ ವಿಷಯವೆಂದರೆ ವಿಷಯಗಳನ್ನು ಕೆಟ್ಟದಾಗಿ ಮಾಡುವುದು ಅಲ್ಲ. ಓದು .
ಡೇಟಾಬೇಸ್ ಸಾಮಾನ್ಯವಾಗಿ ನನಗೆ ಕೆಲಸ ಮಾಡುವುದರಿಂದ, ನಾನು ಸಾಮಾನ್ಯ ಡೇಟಾಬೇಸ್ ಡಂಪ್ಗೆ ನನ್ನನ್ನು ಸೀಮಿತಗೊಳಿಸಿದ್ದೇನೆ, ಆದರೆ ಹಾನಿಗೊಳಗಾದ ಡೇಟಾದೊಂದಿಗೆ ಟೇಬಲ್ ಅನ್ನು ಹೊರತುಪಡಿಸಿದೆ (ಆಯ್ಕೆ -T, --exclude-table=TABLE pg_dump ನಲ್ಲಿ).
ಸರ್ವರ್ ಭೌತಿಕವಾಗಿದೆ, ಸ್ನ್ಯಾಪ್ಶಾಟ್ ತೆಗೆದುಕೊಳ್ಳಲು ಅಸಾಧ್ಯವಾಗಿತ್ತು. ಬ್ಯಾಕಪ್ ಅನ್ನು ತೆಗೆದುಹಾಕಲಾಗಿದೆ, ನಾವು ಮುಂದುವರಿಯೋಣ.
ಪ್ರೋವರ್ಕಾ ಫೈಲ್ ಸಿಸ್ಟಮ್
ಡೇಟಾಬೇಸ್ ಅನ್ನು ಮರುಸ್ಥಾಪಿಸಲು ಪ್ರಯತ್ನಿಸುವ ಮೊದಲು, ಫೈಲ್ ಸಿಸ್ಟಮ್ನೊಂದಿಗೆ ಎಲ್ಲವೂ ಕ್ರಮದಲ್ಲಿದೆ ಎಂದು ನಾವು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಬೇಕು. ಮತ್ತು ತಪ್ಪುಗಳ ಸಂದರ್ಭದಲ್ಲಿ, ಅವುಗಳನ್ನು ಸರಿಪಡಿಸಿ, ಇಲ್ಲದಿದ್ದರೆ ನೀವು ವಿಷಯಗಳನ್ನು ಕೆಟ್ಟದಾಗಿ ಮಾಡಬಹುದು.
ನನ್ನ ಸಂದರ್ಭದಲ್ಲಿ, ಡೇಟಾಬೇಸ್ನೊಂದಿಗೆ ಫೈಲ್ ಸಿಸ್ಟಮ್ ಅನ್ನು ಅಳವಡಿಸಲಾಗಿದೆ "/srv" ಮತ್ತು ಪ್ರಕಾರವು ext4 ಆಗಿತ್ತು.
ಡೇಟಾಬೇಸ್ ಅನ್ನು ನಿಲ್ಲಿಸುವುದು: systemctl ಸ್ಟಾಪ್ postgresql@9.5-main.service ಮತ್ತು ಕಡತ ವ್ಯವಸ್ಥೆಯು ಯಾರಿಂದಲೂ ಬಳಕೆಯಲ್ಲಿಲ್ಲ ಎಂಬುದನ್ನು ಪರಿಶೀಲಿಸಿ ಮತ್ತು ಆಜ್ಞೆಯನ್ನು ಬಳಸಿಕೊಂಡು ಅನ್ಮೌಂಟ್ ಮಾಡಬಹುದು lsof:
lsof +D / srv
ನಾನು ರೆಡಿಸ್ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಸಹ ನಿಲ್ಲಿಸಬೇಕಾಗಿತ್ತು, ಏಕೆಂದರೆ ಅದು ಸಹ ಬಳಸುತ್ತಿದೆ "/srv". ಮುಂದೆ ನಾನು ಅನ್ಮೌಂಟ್ ಮಾಡಿದೆ / srv (ಉಮೌಂಟ್).
ಉಪಯುಕ್ತತೆಯನ್ನು ಬಳಸಿಕೊಂಡು ಫೈಲ್ ಸಿಸ್ಟಮ್ ಅನ್ನು ಪರಿಶೀಲಿಸಲಾಗಿದೆ e2fsck ಸ್ವಿಚ್ -f ಜೊತೆಗೆ (ಫೈಲ್ಸಿಸ್ಟಮ್ ಅನ್ನು ಕ್ಲೀನ್ ಎಂದು ಗುರುತಿಸಿದ್ದರೂ ಸಹ ಬಲವಂತವಾಗಿ ಪರಿಶೀಲಿಸಲಾಗುತ್ತಿದೆ):
ಮುಂದೆ, ಉಪಯುಕ್ತತೆಯನ್ನು ಬಳಸುವುದು dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep ಪರಿಶೀಲಿಸಲಾಗಿದೆ) ಚೆಕ್ ಅನ್ನು ನಿಜವಾಗಿಯೂ ನಿರ್ವಹಿಸಲಾಗಿದೆ ಎಂದು ನೀವು ಪರಿಶೀಲಿಸಬಹುದು:

e2fsck ext4 ಫೈಲ್ ಸಿಸ್ಟಮ್ ಮಟ್ಟದಲ್ಲಿ ಯಾವುದೇ ಸಮಸ್ಯೆಗಳು ಕಂಡುಬಂದಿಲ್ಲ ಎಂದು ಹೇಳುತ್ತದೆ, ಇದರರ್ಥ ನೀವು ಡೇಟಾಬೇಸ್ ಅನ್ನು ಮರುಸ್ಥಾಪಿಸಲು ಪ್ರಯತ್ನಿಸುವುದನ್ನು ಮುಂದುವರಿಸಬಹುದು ಅಥವಾ ಇದಕ್ಕೆ ಹಿಂತಿರುಗಬಹುದು ನಿರ್ವಾತ ಪೂರ್ಣ (ಸಹಜವಾಗಿ, ನೀವು ಫೈಲ್ ಸಿಸ್ಟಮ್ ಅನ್ನು ಮತ್ತೆ ಆರೋಹಿಸಬೇಕು ಮತ್ತು ಡೇಟಾಬೇಸ್ ಅನ್ನು ಪ್ರಾರಂಭಿಸಬೇಕು).
ನೀವು ಭೌತಿಕ ಸರ್ವರ್ ಹೊಂದಿದ್ದರೆ, ಡಿಸ್ಕ್ಗಳ ಸ್ಥಿತಿಯನ್ನು ಪರೀಕ್ಷಿಸಲು ಮರೆಯದಿರಿ (ಮೂಲಕ smartctl -a /dev/XXX) ಅಥವಾ ಸಮಸ್ಯೆಯು ಹಾರ್ಡ್ವೇರ್ ಮಟ್ಟದಲ್ಲಿಲ್ಲ ಎಂದು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು RAID ನಿಯಂತ್ರಕ. ನನ್ನ ಸಂದರ್ಭದಲ್ಲಿ, RAID "ಹಾರ್ಡ್ವೇರ್" ಆಗಿ ಹೊರಹೊಮ್ಮಿತು, ಆದ್ದರಿಂದ ನಾನು RAID ನ ಸ್ಥಿತಿಯನ್ನು ಪರಿಶೀಲಿಸಲು ಸ್ಥಳೀಯ ನಿರ್ವಾಹಕರನ್ನು ಕೇಳಿದೆ (ಸರ್ವರ್ ನನ್ನಿಂದ ನೂರಾರು ಕಿಲೋಮೀಟರ್ ದೂರದಲ್ಲಿದೆ). ಯಾವುದೇ ದೋಷಗಳಿಲ್ಲ ಎಂದು ಅವರು ಹೇಳಿದರು, ಅಂದರೆ ನಾವು ಖಂಡಿತವಾಗಿಯೂ ಪುನಃಸ್ಥಾಪನೆಯನ್ನು ಪ್ರಾರಂಭಿಸಬಹುದು.
ಪ್ರಯತ್ನ 1: zero_damaged_pages
ಸೂಪರ್ಯೂಸರ್ ಹಕ್ಕುಗಳನ್ನು ಹೊಂದಿರುವ ಖಾತೆಯೊಂದಿಗೆ ನಾವು psql ಮೂಲಕ ಡೇಟಾಬೇಸ್ಗೆ ಸಂಪರ್ಕಿಸುತ್ತೇವೆ. ನಮಗೆ ಸೂಪರ್ಯೂಸರ್ ಅಗತ್ಯವಿದೆ, ಏಕೆಂದರೆ... ಆಯ್ಕೆಯನ್ನು ಶೂನ್ಯ_ಹಾನಿಗೊಳಗಾದ_ಪುಟಗಳು ಅವನು ಮಾತ್ರ ಬದಲಾಗಬಹುದು. ನನ್ನ ವಿಷಯದಲ್ಲಿ ಇದು ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಆಗಿದೆ:
psql -h 127.0.0.1 -U postgres -s [ಡೇಟಾಬೇಸ್_ಹೆಸರು]
ಆಯ್ಕೆ ಶೂನ್ಯ_ಹಾನಿಗೊಳಗಾದ_ಪುಟಗಳು ಓದುವ ದೋಷಗಳನ್ನು ನಿರ್ಲಕ್ಷಿಸಲು ಅಗತ್ಯವಿದೆ (postgrespro ವೆಬ್ಸೈಟ್ನಿಂದ):
PostgreSQL ದೋಷಪೂರಿತ ಪುಟದ ಹೆಡರ್ ಅನ್ನು ಪತ್ತೆ ಮಾಡಿದಾಗ, ಅದು ಸಾಮಾನ್ಯವಾಗಿ ದೋಷವನ್ನು ವರದಿ ಮಾಡುತ್ತದೆ ಮತ್ತು ಪ್ರಸ್ತುತ ವಹಿವಾಟನ್ನು ಸ್ಥಗಿತಗೊಳಿಸುತ್ತದೆ. zero_damaged_pages ಅನ್ನು ಸಕ್ರಿಯಗೊಳಿಸಿದರೆ, ಸಿಸ್ಟಮ್ ಎಚ್ಚರಿಕೆಯನ್ನು ನೀಡುತ್ತದೆ, ಮೆಮೊರಿಯಲ್ಲಿ ಹಾನಿಗೊಳಗಾದ ಪುಟವನ್ನು ಶೂನ್ಯಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುವುದನ್ನು ಮುಂದುವರಿಸುತ್ತದೆ. ಈ ನಡವಳಿಕೆಯು ಡೇಟಾವನ್ನು ನಾಶಪಡಿಸುತ್ತದೆ, ಅವುಗಳೆಂದರೆ ಹಾನಿಗೊಳಗಾದ ಪುಟದಲ್ಲಿನ ಎಲ್ಲಾ ಸಾಲುಗಳು.
ನಾವು ಆಯ್ಕೆಯನ್ನು ಸಕ್ರಿಯಗೊಳಿಸುತ್ತೇವೆ ಮತ್ತು ಕೋಷ್ಟಕಗಳ ಸಂಪೂರ್ಣ ನಿರ್ವಾತವನ್ನು ಮಾಡಲು ಪ್ರಯತ್ನಿಸುತ್ತೇವೆ:
VACUUM FULL VERBOSE 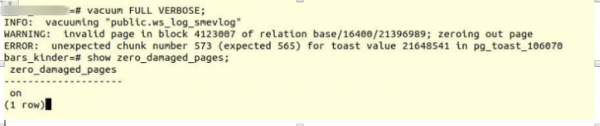
ದುರದೃಷ್ಟವಶಾತ್, ದುರದೃಷ್ಟ.
ನಾವು ಇದೇ ರೀತಿಯ ದೋಷವನ್ನು ಎದುರಿಸಿದ್ದೇವೆ:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070- ಒಂದು ಪುಟದಲ್ಲಿ (8kb ಪೂರ್ವನಿಯೋಜಿತವಾಗಿ) ಹೊಂದಿಕೆಯಾಗದಿದ್ದರೆ Poetgres ನಲ್ಲಿ "ದೀರ್ಘ ಡೇಟಾ" ಅನ್ನು ಸಂಗ್ರಹಿಸುವ ಕಾರ್ಯವಿಧಾನ
ಪ್ರಯತ್ನ 2: ರೀಇಂಡೆಕ್ಸ್
Google ನಿಂದ ಮೊದಲ ಸಲಹೆ ಸಹಾಯ ಮಾಡಲಿಲ್ಲ. ಕೆಲವು ನಿಮಿಷಗಳ ಹುಡುಕಾಟದ ನಂತರ, ನಾನು ಎರಡನೇ ಸಲಹೆಯನ್ನು ಕಂಡುಕೊಂಡೆ - ಮಾಡಲು ರೀಇಂಡೆಕ್ಸ್ ಹಾನಿಗೊಳಗಾದ ಟೇಬಲ್. ನಾನು ಅನೇಕ ಸ್ಥಳಗಳಲ್ಲಿ ಈ ಸಲಹೆಯನ್ನು ನೋಡಿದೆ, ಆದರೆ ಇದು ಆತ್ಮವಿಶ್ವಾಸವನ್ನು ಉಂಟುಮಾಡಲಿಲ್ಲ. ರೀಇಂಡೆಕ್ಸ್ ಮಾಡೋಣ:
reindex table ws_log_smevlog 
ರೀಇಂಡೆಕ್ಸ್ ಸಮಸ್ಯೆಗಳಿಲ್ಲದೆ ಪೂರ್ಣಗೊಂಡಿದೆ.
ಆದಾಗ್ಯೂ, ಇದು ಸಹಾಯ ಮಾಡಲಿಲ್ಲ, ನಿರ್ವಾತ ಪೂರ್ಣ ಇದೇ ದೋಷದೊಂದಿಗೆ ಕ್ರ್ಯಾಶ್ ಆಗಿದೆ. ನಾನು ವೈಫಲ್ಯಗಳಿಗೆ ಒಗ್ಗಿಕೊಂಡಿರುವ ಕಾರಣ, ನಾನು ಇಂಟರ್ನೆಟ್ನಲ್ಲಿ ಸಲಹೆಗಾಗಿ ಮತ್ತಷ್ಟು ನೋಡಲು ಪ್ರಾರಂಭಿಸಿದೆ ಮತ್ತು ಹೆಚ್ಚು ಆಸಕ್ತಿದಾಯಕವಾಗಿದೆ .
ಪ್ರಯತ್ನ 3: ಆಯ್ಕೆ, ಮಿತಿ, ಆಫ್ಸೆಟ್
ಮೇಲಿನ ಲೇಖನವು ಸಾಲಿನಿಂದ ಟೇಬಲ್ ಸಾಲನ್ನು ನೋಡಲು ಮತ್ತು ಸಮಸ್ಯಾತ್ಮಕ ಡೇಟಾವನ್ನು ತೆಗೆದುಹಾಕಲು ಸಲಹೆ ನೀಡಿದೆ. ಮೊದಲು ನಾವು ಎಲ್ಲಾ ಸಾಲುಗಳನ್ನು ನೋಡಬೇಕಾಗಿದೆ:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneನನ್ನ ಸಂದರ್ಭದಲ್ಲಿ, ಟೇಬಲ್ ಒಳಗೊಂಡಿದೆ 1 628 991 ಸಾಲುಗಳು! ಚೆನ್ನಾಗಿ ನೋಡಿಕೊಳ್ಳುವುದು ಅಗತ್ಯವಾಗಿತ್ತು , ಆದರೆ ಇದು ಪ್ರತ್ಯೇಕ ಚರ್ಚೆಗೆ ವಿಷಯವಾಗಿದೆ. ಇದು ಶನಿವಾರ, ನಾನು ಈ ಆಜ್ಞೆಯನ್ನು tmux ನಲ್ಲಿ ಚಲಾಯಿಸಿದೆ ಮತ್ತು ಮಲಗಲು ಹೋದೆ:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneಬೆಳಿಗ್ಗೆ ನಾನು ವಿಷಯಗಳು ಹೇಗೆ ನಡೆಯುತ್ತಿವೆ ಎಂಬುದನ್ನು ಪರಿಶೀಲಿಸಲು ನಿರ್ಧರಿಸಿದೆ. ನನ್ನ ಆಶ್ಚರ್ಯಕ್ಕೆ, 20 ಗಂಟೆಗಳ ನಂತರ, ಕೇವಲ 2% ಡೇಟಾವನ್ನು ಮಾತ್ರ ಸ್ಕ್ಯಾನ್ ಮಾಡಲಾಗಿದೆ ಎಂದು ನಾನು ಕಂಡುಹಿಡಿದಿದ್ದೇನೆ! ನಾನು 50 ದಿನ ಕಾಯಲು ಬಯಸಲಿಲ್ಲ. ಮತ್ತೊಂದು ಸಂಪೂರ್ಣ ವೈಫಲ್ಯ.
ಆದರೆ ನಾನು ಬಿಡಲಿಲ್ಲ. ಸ್ಕ್ಯಾನಿಂಗ್ ಏಕೆ ಇಷ್ಟು ಸಮಯ ತೆಗೆದುಕೊಂಡಿತು ಎಂದು ನಾನು ಆಶ್ಚರ್ಯ ಪಡುತ್ತೇನೆ. ದಸ್ತಾವೇಜನ್ನು (ಮತ್ತೆ postgrespro ನಲ್ಲಿ) ನಾನು ಕಂಡುಕೊಂಡೆ:
OFFSET ಸಾಲುಗಳನ್ನು ಔಟ್ಪುಟ್ ಮಾಡಲು ಪ್ರಾರಂಭಿಸುವ ಮೊದಲು ನಿರ್ದಿಷ್ಟ ಸಂಖ್ಯೆಯ ಸಾಲುಗಳನ್ನು ಬಿಟ್ಟುಬಿಡಲು ಸೂಚಿಸುತ್ತದೆ.
OFFSET ಮತ್ತು LIMIT ಎರಡನ್ನೂ ನಿರ್ದಿಷ್ಟಪಡಿಸಿದರೆ, ಸಿಸ್ಟಮ್ ಮೊದಲು OFFSET ಸಾಲುಗಳನ್ನು ಬಿಟ್ಟುಬಿಡುತ್ತದೆ ಮತ್ತು ನಂತರ LIMIT ನಿರ್ಬಂಧಕ್ಕಾಗಿ ಸಾಲುಗಳನ್ನು ಎಣಿಸಲು ಪ್ರಾರಂಭಿಸುತ್ತದೆ.LIMIT ಅನ್ನು ಬಳಸುವಾಗ, ಆರ್ಡರ್ ಬೈ ಷರತ್ತನ್ನು ಬಳಸುವುದು ಸಹ ಮುಖ್ಯವಾಗಿದೆ ಆದ್ದರಿಂದ ಫಲಿತಾಂಶದ ಸಾಲುಗಳನ್ನು ನಿರ್ದಿಷ್ಟ ಕ್ರಮದಲ್ಲಿ ಹಿಂತಿರುಗಿಸಲಾಗುತ್ತದೆ. ಇಲ್ಲದಿದ್ದರೆ, ಸಾಲುಗಳ ಅನಿರೀಕ್ಷಿತ ಉಪವಿಭಾಗಗಳನ್ನು ಹಿಂತಿರುಗಿಸಲಾಗುತ್ತದೆ.
ನಿಸ್ಸಂಶಯವಾಗಿ, ಮೇಲಿನ ಆಜ್ಞೆಯು ತಪ್ಪಾಗಿದೆ: ಮೊದಲನೆಯದಾಗಿ, ಇಲ್ಲ ಮೂಲಕ ಆದೇಶ, ಫಲಿತಾಂಶವು ತಪ್ಪಾಗಿರಬಹುದು. ಎರಡನೆಯದಾಗಿ, ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಮೊದಲು OFFSET ಸಾಲುಗಳನ್ನು ಸ್ಕ್ಯಾನ್ ಮಾಡಬೇಕಾಗಿತ್ತು ಮತ್ತು ಬಿಟ್ಟುಬಿಡಬೇಕಾಗಿತ್ತು ಮತ್ತು ಹೆಚ್ಚುತ್ತಿರುವಾಗ ಆಫ್ಸೆಟ್ ಉತ್ಪಾದಕತೆ ಇನ್ನೂ ಕುಸಿಯುತ್ತದೆ.
ಪ್ರಯತ್ನ 4: ಪಠ್ಯ ರೂಪದಲ್ಲಿ ಡಂಪ್ ತೆಗೆದುಕೊಳ್ಳಿ
ನಂತರ ತೋರಿಕೆಯಲ್ಲಿ ಅದ್ಭುತವಾದ ಕಲ್ಪನೆಯು ನನ್ನ ಮನಸ್ಸಿಗೆ ಬಂದಿತು: ಪಠ್ಯ ರೂಪದಲ್ಲಿ ಡಂಪ್ ಅನ್ನು ತೆಗೆದುಕೊಂಡು ಕೊನೆಯ ರೆಕಾರ್ಡ್ ಮಾಡಿದ ಸಾಲನ್ನು ವಿಶ್ಲೇಷಿಸಿ.
ಆದರೆ ಮೊದಲು, ಮೇಜಿನ ರಚನೆಯನ್ನು ನೋಡೋಣ. ws_log_smevlog:
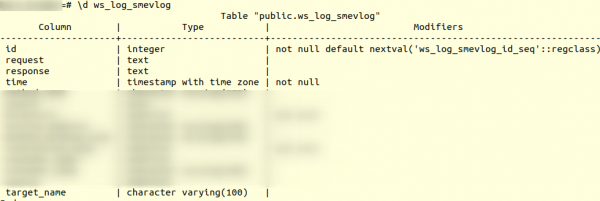
ನಮ್ಮ ಸಂದರ್ಭದಲ್ಲಿ ನಾವು ಕಾಲಮ್ ಅನ್ನು ಹೊಂದಿದ್ದೇವೆ "ಐಡಿ", ಇದು ಸಾಲಿನ ಅನನ್ಯ ಗುರುತಿಸುವಿಕೆಯನ್ನು (ಕೌಂಟರ್) ಒಳಗೊಂಡಿದೆ. ಯೋಜನೆ ಹೀಗಿತ್ತು:
- ನಾವು ಪಠ್ಯ ರೂಪದಲ್ಲಿ ಡಂಪ್ ತೆಗೆದುಕೊಳ್ಳಲು ಪ್ರಾರಂಭಿಸುತ್ತೇವೆ (sql ಆಜ್ಞೆಗಳ ರೂಪದಲ್ಲಿ)
- ಒಂದು ನಿರ್ದಿಷ್ಟ ಸಮಯದಲ್ಲಿ, ದೋಷದಿಂದಾಗಿ ಡಂಪ್ ಅಡಚಣೆಯಾಗುತ್ತದೆ, ಆದರೆ ಪಠ್ಯ ಫೈಲ್ ಅನ್ನು ಇನ್ನೂ ಡಿಸ್ಕ್ನಲ್ಲಿ ಉಳಿಸಲಾಗುತ್ತದೆ
- ನಾವು ಪಠ್ಯ ಫೈಲ್ನ ಅಂತ್ಯವನ್ನು ನೋಡುತ್ತೇವೆ, ಆ ಮೂಲಕ ಯಶಸ್ವಿಯಾಗಿ ತೆಗೆದುಹಾಕಲಾದ ಕೊನೆಯ ಸಾಲಿನ ಗುರುತಿಸುವಿಕೆ (ಐಡಿ) ಅನ್ನು ನಾವು ಕಂಡುಕೊಳ್ಳುತ್ತೇವೆ
ನಾನು ಪಠ್ಯ ರೂಪದಲ್ಲಿ ಡಂಪ್ ತೆಗೆದುಕೊಳ್ಳಲು ಪ್ರಾರಂಭಿಸಿದೆ:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpನಿರೀಕ್ಷೆಯಂತೆ, ಅದೇ ದೋಷದೊಂದಿಗೆ ಡಂಪ್ಗೆ ಅಡ್ಡಿಪಡಿಸಲಾಗಿದೆ:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 ಮತ್ತಷ್ಟು ಮೂಲಕ ಬಾಲ ನಾನು ಡಂಪ್ನ ಕೊನೆಯಲ್ಲಿ ನೋಡಿದೆ (ಬಾಲ -5 ./my_dump.dump) ಐಡಿಯೊಂದಿಗೆ ಸಾಲಿನಲ್ಲಿ ಡಂಪ್ ಅಡಚಣೆಯಾಗಿದೆ ಎಂದು ಕಂಡುಹಿಡಿದಿದೆ 186 525. "ಆದ್ದರಿಂದ ಸಮಸ್ಯೆಯು ಐಡಿ 186 526 ರ ಸಾಲಿನಲ್ಲಿದೆ, ಅದು ಮುರಿದುಹೋಗಿದೆ ಮತ್ತು ಅಳಿಸಬೇಕಾಗಿದೆ!" - ನಾನು ಯೋಚಿಸಿದೆ. ಆದರೆ, ಡೇಟಾಬೇಸ್ಗೆ ಪ್ರಶ್ನೆಯನ್ನು ಮಾಡುವುದು:
«id=186529 ಅಲ್ಲಿ ws_log_smevlog ನಿಂದ * ಅನ್ನು ಆಯ್ಕೆ ಮಾಡಿ"ಈ ಸಾಲಿನಲ್ಲಿ ಎಲ್ಲವೂ ಉತ್ತಮವಾಗಿದೆ ಎಂದು ಬದಲಾಯಿತು ... 186 - 530 ಸೂಚ್ಯಂಕಗಳೊಂದಿಗಿನ ಸಾಲುಗಳು ಸಹ ಸಮಸ್ಯೆಗಳಿಲ್ಲದೆ ಕೆಲಸ ಮಾಡುತ್ತವೆ. ಮತ್ತೊಂದು "ಅದ್ಭುತ ಕಲ್ಪನೆ" ವಿಫಲವಾಗಿದೆ. ಇದು ಏಕೆ ಸಂಭವಿಸಿತು ಎಂದು ನಂತರ ನಾನು ಅರ್ಥಮಾಡಿಕೊಂಡಿದ್ದೇನೆ: ಟೇಬಲ್ನಿಂದ ಡೇಟಾವನ್ನು ಅಳಿಸುವಾಗ ಮತ್ತು ಬದಲಾಯಿಸುವಾಗ, ಅವುಗಳನ್ನು ಭೌತಿಕವಾಗಿ ಅಳಿಸಲಾಗುವುದಿಲ್ಲ, ಆದರೆ "ಡೆಡ್ ಟುಪಲ್ಸ್" ಎಂದು ಗುರುತಿಸಲಾಗುತ್ತದೆ, ನಂತರ ಬರುತ್ತದೆ ಸ್ವಯಂ ನಿರ್ವಾತ ಮತ್ತು ಈ ಸಾಲುಗಳನ್ನು ಅಳಿಸಲಾಗಿದೆ ಎಂದು ಗುರುತಿಸುತ್ತದೆ ಮತ್ತು ಈ ಸಾಲುಗಳನ್ನು ಮರುಬಳಕೆ ಮಾಡಲು ಅನುಮತಿಸುತ್ತದೆ. ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು, ಕೋಷ್ಟಕದಲ್ಲಿನ ಡೇಟಾವನ್ನು ಬದಲಾಯಿಸಿದರೆ ಮತ್ತು ಆಟೋವಾಕ್ಯೂಮ್ ಅನ್ನು ಸಕ್ರಿಯಗೊಳಿಸಿದರೆ, ಅದನ್ನು ಅನುಕ್ರಮವಾಗಿ ಸಂಗ್ರಹಿಸಲಾಗುವುದಿಲ್ಲ.
ಪ್ರಯತ್ನ 5: ಆಯ್ಕೆ, ಇಂದ, ಎಲ್ಲಿ ಐಡಿ=
ವೈಫಲ್ಯಗಳು ನಮ್ಮನ್ನು ಬಲಪಡಿಸುತ್ತವೆ. ನೀವು ಎಂದಿಗೂ ಬಿಟ್ಟುಕೊಡಬಾರದು, ನೀವು ಕೊನೆಯವರೆಗೂ ಹೋಗಬೇಕು ಮತ್ತು ನಿಮ್ಮನ್ನು ಮತ್ತು ನಿಮ್ಮ ಸಾಮರ್ಥ್ಯಗಳನ್ನು ನಂಬಬೇಕು. ಹಾಗಾಗಿ ನಾನು ಇನ್ನೊಂದು ಆಯ್ಕೆಯನ್ನು ಪ್ರಯತ್ನಿಸಲು ನಿರ್ಧರಿಸಿದೆ: ಡೇಟಾಬೇಸ್ನಲ್ಲಿರುವ ಎಲ್ಲಾ ದಾಖಲೆಗಳನ್ನು ಒಂದೊಂದಾಗಿ ನೋಡಿ. ನನ್ನ ಕೋಷ್ಟಕದ ರಚನೆಯನ್ನು ತಿಳಿದುಕೊಳ್ಳುವುದರಿಂದ (ಮೇಲೆ ನೋಡಿ), ನಾವು ಅನನ್ಯವಾಗಿರುವ ಐಡಿ ಕ್ಷೇತ್ರವನ್ನು ಹೊಂದಿದ್ದೇವೆ (ಪ್ರಾಥಮಿಕ ಕೀ). ನಾವು ಕೋಷ್ಟಕದಲ್ಲಿ 1 ಸಾಲುಗಳನ್ನು ಹೊಂದಿದ್ದೇವೆ ಮತ್ತು id ಕ್ರಮದಲ್ಲಿದೆ, ಅಂದರೆ ನಾವು ಅವುಗಳನ್ನು ಒಂದೊಂದಾಗಿ ಹೋಗಬಹುದು:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneಯಾರಿಗಾದರೂ ಅರ್ಥವಾಗದಿದ್ದರೆ, ಆಜ್ಞೆಯು ಈ ಕೆಳಗಿನಂತೆ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ: ಇದು ಟೇಬಲ್ ಸಾಲನ್ನು ಸಾಲಿನಿಂದ ಸ್ಕ್ಯಾನ್ ಮಾಡುತ್ತದೆ ಮತ್ತು stdout ಅನ್ನು ಕಳುಹಿಸುತ್ತದೆ / dev / ಶೂನ್ಯ, ಆದರೆ SELECT ಆಜ್ಞೆಯು ವಿಫಲವಾದಲ್ಲಿ, ದೋಷ ಪಠ್ಯವನ್ನು ಮುದ್ರಿಸಲಾಗುತ್ತದೆ (stderr ಅನ್ನು ಕನ್ಸೋಲ್ಗೆ ಕಳುಹಿಸಲಾಗುತ್ತದೆ) ಮತ್ತು ದೋಷವನ್ನು ಹೊಂದಿರುವ ಸಾಲನ್ನು ಮುದ್ರಿಸಲಾಗುತ್ತದೆ (ಧನ್ಯವಾದಗಳು || ಗೆ ಧನ್ಯವಾದಗಳು, ಅಂದರೆ ಆಯ್ಕೆಯು ಸಮಸ್ಯೆಗಳನ್ನು ಹೊಂದಿದೆ (ಆಜ್ಞೆಯ ರಿಟರ್ನ್ ಕೋಡ್ 0 ಅಲ್ಲ)).
ನಾನು ಅದೃಷ್ಟಶಾಲಿಯಾಗಿದ್ದೆ, ನಾನು ಮೈದಾನದಲ್ಲಿ ಸೂಚ್ಯಂಕಗಳನ್ನು ರಚಿಸಿದ್ದೇನೆ id:

ಇದರರ್ಥ ಅಪೇಕ್ಷಿತ ಐಡಿಯೊಂದಿಗೆ ಸಾಲನ್ನು ಹುಡುಕಲು ಹೆಚ್ಚು ಸಮಯ ತೆಗೆದುಕೊಳ್ಳಬಾರದು. ತಾತ್ವಿಕವಾಗಿ ಅದು ಕೆಲಸ ಮಾಡಬೇಕು. ಸರಿ, ಆಜ್ಞೆಯನ್ನು ಚಲಾಯಿಸೋಣ tmux ಮತ್ತು ಮಲಗಲು ಹೋಗೋಣ.
ಬೆಳಗಿನ ಹೊತ್ತಿಗೆ ಸುಮಾರು 90 ನಮೂದುಗಳನ್ನು ವೀಕ್ಷಿಸಲಾಗಿದೆ ಎಂದು ನಾನು ಕಂಡುಕೊಂಡಿದ್ದೇನೆ, ಅದು ಕೇವಲ 000% ಕ್ಕಿಂತ ಹೆಚ್ಚು. ಹಿಂದಿನ ವಿಧಾನಕ್ಕೆ (5%) ಹೋಲಿಸಿದರೆ ಅತ್ಯುತ್ತಮ ಫಲಿತಾಂಶ! ಆದರೆ ನಾನು 2 ದಿನ ಕಾಯಲು ಬಯಸಲಿಲ್ಲ ...
ಪ್ರಯತ್ನ 6: ಆಯ್ಕೆ, ಇಂದ, ಎಲ್ಲಿ ಐಡಿ >= ಮತ್ತು ಐಡಿ
ಗ್ರಾಹಕರು ಡೇಟಾಬೇಸ್ಗೆ ಮೀಸಲಾಗಿರುವ ಅತ್ಯುತ್ತಮ ಸರ್ವರ್ ಅನ್ನು ಹೊಂದಿದ್ದರು: ಡ್ಯುಯಲ್-ಪ್ರೊಸೆಸರ್ ಇಂಟೆಲ್ ಕ್ಸಿಯಾನ್ E5-2697 v2, ನಮ್ಮ ಸ್ಥಳದಲ್ಲಿ 48 ಥ್ರೆಡ್ಗಳು ಇದ್ದವು! ಸರ್ವರ್ನಲ್ಲಿನ ಲೋಡ್ ಸರಾಸರಿಯಾಗಿದೆ; ನಾವು ಯಾವುದೇ ಸಮಸ್ಯೆಗಳಿಲ್ಲದೆ ಸುಮಾರು 20 ಥ್ರೆಡ್ಗಳನ್ನು ಡೌನ್ಲೋಡ್ ಮಾಡಬಹುದು. ಸಾಕಷ್ಟು RAM ಸಹ ಇತ್ತು: 384 ಗಿಗಾಬೈಟ್ಗಳಷ್ಟು!
ಆದ್ದರಿಂದ, ಆಜ್ಞೆಯನ್ನು ಸಮಾನಾಂತರಗೊಳಿಸಬೇಕಾಗಿದೆ:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneಇಲ್ಲಿ ಸುಂದರವಾದ ಮತ್ತು ಸೊಗಸಾದ ಸ್ಕ್ರಿಪ್ಟ್ ಅನ್ನು ಬರೆಯಲು ಸಾಧ್ಯವಾಯಿತು, ಆದರೆ ನಾನು ವೇಗವಾಗಿ ಸಮಾನಾಂತರಗೊಳಿಸುವ ವಿಧಾನವನ್ನು ಆರಿಸಿದೆ: 0-1628991 ಶ್ರೇಣಿಯನ್ನು 100 ದಾಖಲೆಗಳ ಮಧ್ಯಂತರಗಳಾಗಿ ಹಸ್ತಚಾಲಿತವಾಗಿ ವಿಭಜಿಸಿ ಮತ್ತು ಫಾರ್ಮ್ನ 000 ಆಜ್ಞೆಗಳನ್ನು ಪ್ರತ್ಯೇಕವಾಗಿ ಚಲಾಯಿಸಿ:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneಆದರೆ ಇಷ್ಟೇ ಅಲ್ಲ. ಸಿದ್ಧಾಂತದಲ್ಲಿ, ಡೇಟಾಬೇಸ್ಗೆ ಸಂಪರ್ಕಿಸಲು ಸ್ವಲ್ಪ ಸಮಯ ಮತ್ತು ಸಿಸ್ಟಮ್ ಸಂಪನ್ಮೂಲಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ. 1 ಅನ್ನು ಸಂಪರ್ಕಿಸುವುದು ತುಂಬಾ ಸ್ಮಾರ್ಟ್ ಆಗಿರಲಿಲ್ಲ, ನೀವು ಒಪ್ಪುತ್ತೀರಿ. ಆದ್ದರಿಂದ, ಒಂದು ಸಂಪರ್ಕದಲ್ಲಿ ಒಂದರ ಬದಲಿಗೆ 628 ಸಾಲುಗಳನ್ನು ಹಿಂಪಡೆಯೋಣ. ಪರಿಣಾಮವಾಗಿ, ತಂಡವು ಹೀಗೆ ರೂಪಾಂತರಗೊಂಡಿದೆ:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; donetmux ಸೆಷನ್ನಲ್ಲಿ 16 ವಿಂಡೋಗಳನ್ನು ತೆರೆಯಿರಿ ಮತ್ತು ಆಜ್ಞೆಗಳನ್ನು ಚಲಾಯಿಸಿ:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
ಒಂದು ದಿನದ ನಂತರ ನಾನು ಮೊದಲ ಫಲಿತಾಂಶಗಳನ್ನು ಸ್ವೀಕರಿಸಿದ್ದೇನೆ! ಅವುಗಳೆಂದರೆ (XXX ಮತ್ತು ZZZ ಮೌಲ್ಯಗಳನ್ನು ಇನ್ನು ಮುಂದೆ ಸಂರಕ್ಷಿಸಲಾಗುವುದಿಲ್ಲ):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000ಇದರರ್ಥ ಮೂರು ಸಾಲುಗಳು ದೋಷವನ್ನು ಹೊಂದಿರುತ್ತವೆ. ಮೊದಲ ಮತ್ತು ಎರಡನೇ ಸಮಸ್ಯೆಯ ದಾಖಲೆಗಳ ಐಡಿಗಳು 829 ಮತ್ತು 000 ರ ನಡುವೆ ಇದ್ದವು, ಮೂರನೇ ಐಡಿಗಳು 830 ಮತ್ತು 000 ರ ನಡುವೆ ಇದ್ದವು, ನಾವು ಸಮಸ್ಯೆಯ ದಾಖಲೆಗಳ ನಿಖರವಾದ ಐಡಿ ಮೌಲ್ಯವನ್ನು ಕಂಡುಹಿಡಿಯಬೇಕಾಗಿತ್ತು. ಇದನ್ನು ಮಾಡಲು, ನಾವು 146 ರ ಹಂತದೊಂದಿಗೆ ಸಮಸ್ಯಾತ್ಮಕ ದಾಖಲೆಗಳೊಂದಿಗೆ ನಮ್ಮ ಶ್ರೇಣಿಯನ್ನು ನೋಡುತ್ತೇವೆ ಮತ್ತು ಐಡಿಯನ್ನು ಗುರುತಿಸುತ್ತೇವೆ:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
ಸುಖಾಂತ್ಯ
ನಾವು ಸಮಸ್ಯಾತ್ಮಕ ಸಾಲುಗಳನ್ನು ಕಂಡುಕೊಂಡಿದ್ದೇವೆ. ನಾವು psql ಮೂಲಕ ಡೇಟಾಬೇಸ್ಗೆ ಹೋಗುತ್ತೇವೆ ಮತ್ತು ಅವುಗಳನ್ನು ಅಳಿಸಲು ಪ್ರಯತ್ನಿಸುತ್ತೇವೆ:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1ನನ್ನ ಆಶ್ಚರ್ಯಕ್ಕೆ, ಯಾವುದೇ ಸಮಸ್ಯೆಗಳಿಲ್ಲದೆ ನಮೂದುಗಳನ್ನು ಆಯ್ಕೆಯಿಲ್ಲದೆ ಅಳಿಸಲಾಗಿದೆ ಶೂನ್ಯ_ಹಾನಿಗೊಳಗಾದ_ಪುಟಗಳು.
ನಂತರ ನಾನು ಡೇಟಾಬೇಸ್ಗೆ ಸಂಪರ್ಕಿಸಿದೆ, ಮಾಡಿದೆ ನಿರ್ವಾತ ಪೂರ್ಣ (ಇದನ್ನು ಮಾಡುವುದು ಅನಿವಾರ್ಯವಲ್ಲ ಎಂದು ನಾನು ಭಾವಿಸುತ್ತೇನೆ), ಮತ್ತು ಅಂತಿಮವಾಗಿ ನಾನು ಬ್ಯಾಕಪ್ ಅನ್ನು ಬಳಸಿಕೊಂಡು ಯಶಸ್ವಿಯಾಗಿ ತೆಗೆದುಹಾಕಿದೆ pg_dump. ಯಾವುದೇ ದೋಷಗಳಿಲ್ಲದೆ ಡಂಪ್ ಅನ್ನು ತೆಗೆದುಕೊಳ್ಳಲಾಗಿದೆ! ಸಮಸ್ಯೆಯನ್ನು ಅಂತಹ ಮೂರ್ಖ ರೀತಿಯಲ್ಲಿ ಪರಿಹರಿಸಲಾಗಿದೆ. ಸಂತೋಷಕ್ಕೆ ಯಾವುದೇ ಮಿತಿಯಿಲ್ಲ, ಹಲವಾರು ವೈಫಲ್ಯಗಳ ನಂತರ ನಾವು ಪರಿಹಾರವನ್ನು ಕಂಡುಕೊಳ್ಳುವಲ್ಲಿ ಯಶಸ್ವಿಯಾಗಿದ್ದೇವೆ!
ಸ್ವೀಕೃತಿಗಳು ಮತ್ತು ತೀರ್ಮಾನ
ನಿಜವಾದ ಪೋಸ್ಟ್ಗ್ರೆಸ್ ಡೇಟಾಬೇಸ್ ಅನ್ನು ಮರುಸ್ಥಾಪಿಸುವ ನನ್ನ ಮೊದಲ ಅನುಭವವು ಹೇಗೆ ಹೊರಹೊಮ್ಮಿತು. ನಾನು ಈ ಅನುಭವವನ್ನು ದೀರ್ಘಕಾಲ ನೆನಪಿಸಿಕೊಳ್ಳುತ್ತೇನೆ.
ಮತ್ತು ಅಂತಿಮವಾಗಿ, ದಸ್ತಾವೇಜನ್ನು ರಷ್ಯನ್ ಭಾಷೆಗೆ ಭಾಷಾಂತರಿಸಿದ್ದಕ್ಕಾಗಿ ಪೋಸ್ಟ್ಗ್ರೆಸ್ಪ್ರೊಗೆ ನಾನು ಧನ್ಯವಾದ ಹೇಳಲು ಬಯಸುತ್ತೇನೆ ಮತ್ತು , ಇದು ಸಮಸ್ಯೆಯ ವಿಶ್ಲೇಷಣೆಯ ಸಮಯದಲ್ಲಿ ಬಹಳಷ್ಟು ಸಹಾಯ ಮಾಡಿತು.
ಮೂಲ: www.habr.com
