

ဤပို့စ်သည် R table data processing library data.table ကို အသုံးပြုသူများအတွက် စိတ်ဝင်စားဖွယ်ဖြစ်ပြီး ဥပမာအမျိုးမျိုးဖြင့် ၎င်း၏အသုံးချပလီကေးရှင်း၏ ပြောင်းလွယ်ပြင်လွယ်ကို မြင်တွေ့ရသည့်အတွက် ကျေနပ်မိပေမည်။
စံနမူနာကောင်းတစ်ခုက စိတ်အားထက်သန်တယ်။ သူ့ဆောင်းပါးကို သင်ဖတ်ပြီးပြီဟု မျှော်လင့်လျက်၊ code optimization နှင့် performance ကိုအခြေခံ၍ ပိုမိုနက်ရှိုင်းစွာ တူးဖော်ရန် အကြံပြုပါသည်။ ဒေတာ.
နိဒါန်း- data.table ဘယ်ကလာတာလဲ။
ပြောရရင် data.table object (နောင်နောင်၊ DT) ကို ရယူနိုင်တဲ့ data structures တွေနဲ့ နည်းနည်းဝေးဝေးက စာကြည့်တိုက်နဲ့ စတင်ရင်းနှီးတာ အကောင်းဆုံးပါပဲ။
Array
ကုဒ်
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
ထိုကဲ့သို့သောဖွဲ့စည်းပုံများထဲမှတစ်ခုသည် array တစ်ခုဖြစ်သည် (?base::array) အခြားဘာသာစကားများကဲ့သို့ပင်၊ ဤနေရာတွင် array များသည် ဘက်ပေါင်းစုံရှိသည်။ သို့သော် စိတ်ဝင်စားစရာကောင်းသည်မှာ ဥပမာအားဖြင့်၊ နှစ်ဘက်မြင် array သည် matrix class မှ ဂုဏ်သတ္တိများကို အမွေဆက်ခံလာပါသည်။ (?base::matrix) နှင့် အရေးကြီးသောအချက်မှာ တစ်ဖက်မြင် array သည် vector တစ်ခုမှ အမွေဆက်ခံခြင်း မရှိပါ (?base::vector).
မည်သည့်အရာဝတ္တုတွင်ပါရှိသောဒေတာအမျိုးအစားကို function မှစစ်ဆေးသင့်သည်ကိုနားလည်ရန်အရေးကြီးပါသည်။ အခြေခံ::အမျိုးအစားအမျိုးအစားအလိုက် အတွင်းပိုင်းဖော်ပြချက်ကို ပြန်ပေးသည်။ R အတွင်းပိုင်း — မူရင်းနှင့် ဆက်စပ်နေသော ဘုံဘာသာစကား ပရိုတိုကော C.
အခြားအရာဝတ္ထုတစ်ခု၏ class ကိုဆုံးဖြတ်ရန် command ၊ အခြေခံ::အတန်းVector များတွင်၊ vector အမျိုးအစားကို ပြန်ပေးသည် (၎င်းတွင် အတွင်းပိုင်းအမည်နှင့် ကွဲပြားသော်လည်း ဒေတာအမျိုးအစားကို နားလည်နိုင်သည်)။
စာရင်း
မက်ထရစ်ဟုလည်း ခေါ်သော နှစ်ဘက်မြင် ခင်းကျင်းမှ၊ စာရင်းတစ်ခုသို့ သင်သွားနိုင်သည်။?base::စာရင်း).
ကုဒ်
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
တစ်ချိန်တည်းတွင် အရာများစွာ ဖြစ်ပေါ်လာသည်-
- မက်ထရစ်၏ ဒုတိယအတိုင်းအတာ ပြိုကျသည်၊ ဆိုလိုသည်မှာ၊ ကျွန်ုပ်တို့သည် စာရင်းတစ်ခုနှင့် vector တစ်ခုတို့ကို တစ်ပြိုင်နက်တည်း ရရှိသည်။
- ထို့ကြောင့် ဤအတန်းများမှ အမွေဆက်ခံသောစာရင်း။ စာရင်းဒြပ်စင်တစ်ခုစီသည် matrix array ၏ဆဲလ်တစ်ခုမှ (scalar) တန်ဖိုးတစ်ခုနှင့် သက်ဆိုင်ကြောင်း မှတ်သားထားပါ။
စာရင်းတစ်ခုသည် vector တစ်ခုဖြစ်သောကြောင့်၊ အချို့သော vector functions များကို ၎င်းတွင်အသုံးချနိုင်သည်။
ဒေတာဘောင်
စာရင်းတစ်ခု၊ matrix သို့မဟုတ် vector မှ data frame သို့သင်သွားနိုင်သည်။?base::data.frame).
ကုဒ်
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
စိတ်ဝင်စားစရာကောင်းတာက dataframe ဟာ စာရင်းတစ်ခုကနေ အမွေဆက်ခံရတာဘဲ။ ဒေတာဘောင်၏ ကော်လံများသည် စာရင်း၏ဆဲလ်များဖြစ်သည်။ စာရင်းများနှင့် သက်ဆိုင်သော လုပ်ဆောင်ချက်များကို အသုံးပြုသည့်အခါ ၎င်းသည် နောက်ပိုင်းတွင် အရေးကြီးပါသည်။
ဒေတာ
DT ရယူပါ (?data.table::data.table) မှ ဖြစ်နိုင်ပါသည်။ ဒေတာဘောင်၊ စာရင်း ၊ vector ၊ သို့မဟုတ် matrix ။ ဥပမာ- ဤကဲ့သို့သော (အရပ်)။
ကုဒ်
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
အသုံးဝင်တာကတော့ dataframe ကဲ့သို့၊ DT သည် list တစ်ခု၏ ဂုဏ်သတ္တိများကို အမွေဆက်ခံပါသည်။
DT နှင့် memory
R အခြေစိုက်စခန်းရှိ အခြားအရာဝတ္တုများနှင့်မတူဘဲ DTs များကို အကိုးအကားဖြင့် ဖြတ်သန်းပါသည်။ ၎င်းတို့ကို မမ်မိုရီတည်နေရာအသစ်သို့ ကူးယူရန် လိုအပ်ပါက၊ လုပ်ဆောင်ချက်တစ်ခု လိုအပ်ပါသည်။ data.table::ကော်ပီ သို့မဟုတ် သင်သည် အရာဝတ္ထုဟောင်းမှ ရွေးချယ်မှုပြုလုပ်ရန် လိုအပ်သည်။
ကုဒ်
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
ဒါက နိဒါန်းကို နိဂုံးချုပ်ပါတယ်။ DT သည် အဓိကအားဖြင့် dataframe objects များပေါ်တွင် လုပ်ဆောင်ခဲ့သော ချဲ့ထွင်ခြင်းနှင့် အရှိန်မြှင့်ခြင်းများအားဖြင့် R တွင် ဒေတာဖွဲ့စည်းပုံများ ဖွံ့ဖြိုးတိုးတက်မှု၏ အဆက်အဆက်တစ်ခုဖြစ်သည်။ အခြားအဓီကများထံမှ အမွေကို ထိန်းသိမ်းထားစဉ်။
data.table ဂုဏ်သတ္တိများကို အသုံးပြုခြင်း၏ ဥပမာအချို့
စာရင်းအနေဖြင့်…
ဒေတာဘောင်တစ်ခု သို့မဟုတ် DT ၏အတန်းများကို ထပ်ခါထပ်ခါပြုလုပ်ခြင်းသည် အကောင်းဆုံးစိတ်ကူးမဟုတ်ပါ၊ ကွင်းကုဒ်သည် ဘာသာစကားဖြင့်ဖြစ်သောကြောင့်၊ R အများကြီးနှေးတယ်။ Cသို့သော် အများအားဖြင့် ပိုနည်းသော ကော်လံများကို လှည့်ပတ်ခြင်းသည် လုံးဝ ဖြစ်နိုင်သည်။ ကော်လံများကို လှည့်ပတ်သည့်အခါ ကော်လံတစ်ခုစီသည် ပုံမှန်အားဖြင့် vector တစ်ခုပါရှိသော စာရင်းဒြပ်စင်တစ်ခုဖြစ်ကြောင်း သတိရပါ။ နှင့် vector များပေါ်တွင် လုပ်ဆောင်ချက်များကို အခြေခံဘာသာစကားလုပ်ဆောင်ချက်များတွင် ကောင်းမွန်စွာ ပုံဖော်ထားပါသည်။ စာရင်းများနှင့် vectors များအတွက် မွေးရာပါ ရွေးချယ်မှု အော်ပရေတာများကို သင်လည်း အသုံးပြုနိုင်ပါသည်။ `[[`၊ `$`.
ကုဒ်
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
ပိုးသတ်ခြင်း
အကယ်၍ သင်သည် ကြီးမားသော DT အတန်းများကို ထပ်ဆင့်ပြန်ဆိုလိုပါက၊ အကောင်းဆုံးဖြေရှင်းချက်မှာ vectorized function ကိုရေးရန်ဖြစ်သည်။ ဒါပေမယ့် အဲဒါက အလုပ်မဖြစ်ဘူးဆိုရင်တော့ ကြိုးဝိုင်းကို သတိရလိုက်ပါ။ အတွင်း DT သည် လည်ပတ်မှုထက် ပိုမြန်နေသေးသည်။ Rကစလို့ ကပြဖျော်ဖြေတယ်။ C.
100K အတန်းများပါရှိသော ပိုကြီးသောဥပမာတစ်ခုတွင် ၎င်းကိုစမ်းကြည့်ကြပါစို့။ ကော်လံ vector တွင်ပါဝင်သော စကားလုံးများမှ ပထမစာလုံးကို ထုတ်ယူပါမည်။ w.
နောက်ဆုံးရေးသားချိန်
ကုဒ်
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
ပထမဦးစွာ အတန်းများပေါ်တွင် ထပ်ခါထပ်ခါ လုပ်ဆောင်ပါ-
ယူနစ်- မီလီစက္ကန့်
expr မိနစ်
{ dt[၊ `:=`(first_l၊ unlist(strsplit(w၊ split=""၊ fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq ဆိုသည်မှာ ပျမ်းမျှ uq max neval ဖြစ်သည်။
451.9998 460.1593 456.2505 460.9147 621.4042 100
စာရင်းကို မက်ထရစ်အဖြစ်ပြောင်းပြီး အညွှန်း 1 ဖြင့် အချပ်၏ဒြပ်စင်များကို ယူခြင်းဖြင့် vectorization ဖြစ်ပေါ်လာသည့် ဒုတိယအပြေးဖြစ်သည်။ အမှားပြင်ဆင်ခြင်း- လုပ်ဆောင်ချက်အဆင့်တွင် vectorization။ strsplitVector ကို input အဖြစ် လက်ခံနိုင်သော၊ စာရင်းတစ်ခုအား matrix အဖြစ်သို့ပြောင်းလဲခြင်းလုပ်ထုံးလုပ်နည်းသည် vectorization ကိုယ်တိုင်လုပ်ဆောင်ခြင်းထက် များစွာပိုမိုရှုပ်ထွေးသော်လည်း ဤအခြေအနေတွင်ပင်၊ ၎င်းသည် non-vectorized version ထက်ပိုမိုမြန်ဆန်ပါသည်။
ယူနစ်- မီလီစက္ကန့်
expr min lq ဆိုသည်မှာ median uq max neval ဖြစ်သည်။
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
ပျမ်းမျှအားဖြင့် အရှိန် 3 ကြိမ်.
တတိယအပြေး၊ မက်ထရစ်ကူးပြောင်းမှုအစီအစဉ်ကို ပြောင်းလဲခဲ့သည်။
ယူနစ်- မီလီစက္ကန့်
expr min lq ဆိုသည်မှာ median uq max neval ဖြစ်သည်။
{ dt[၊ `:=`(first_l၊ .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
ပျမ်းမျှအားဖြင့် အရှိန် 13 ကြိမ်.
ဒီကိစ္စကို စမ်းသပ်ဖို့ လိုလေလေ၊ ပိုကောင်းလေပါပဲ။
ဒါက စာသားနဲ့လည်း ပိုနီးစပ်တဲ့ အခြား vectorization ဥပမာ ဥပမာ- မတူညီတဲ့ စကားလုံးအရှည်တွေနဲ့ မတူညီတဲ့ စကားလုံးအရေအတွက်။ ရည်ရွယ်ချက်မှာ ပထမစကားလုံးသုံးလုံးကို ထုတ်ယူရန်ဖြစ်သည်။ ဒီလိုမျိုး:
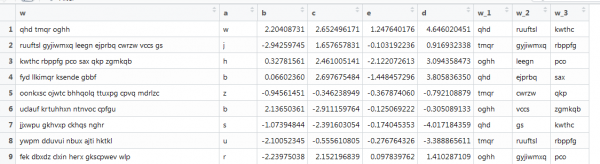
vector များသည် ကွဲပြားသော အလျားများနှင့် matrix အရွယ်အစားကို သတ်မှတ်ပေးသောကြောင့် ယခင်လုပ်ဆောင်ချက်သည် ဤနေရာတွင် အလုပ်မလုပ်ပါ။ ဒါကို အွန်လိုင်းမှာ ရှာဖွေပြီး ပြန်လုပ်ကြည့်ရအောင်။
ကုဒ်
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
ယူနစ်- မီလီစက္ကန့်
expr min lq ဆိုသည်မှာ အလယ်အလတ်ဖြစ်သည်။
{ dt[, `:=`((paste0(“w_”၊ 1:3)), strsplit(w, split="", fixed = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
ဇာတ်ညွှန်းသည် ပျမ်းမျှအမြန်နှုန်း 1 စက္ကန့်ဖြင့် လည်ပတ်သည်။ မဆိုးပါဘူး။
ကွင်းဆက်တစ်ခုဖြင့် ချိတ်ဆက်ထားသော...
chaining သုံးပြီး DT objects တွေနဲ့ အလုပ်လုပ်နိုင်ပါတယ်။ ၎င်းသည် ညာဘက်ရှိ ကွင်းစည်းအထားအသိုများကို ကွင်းဆက်ထားပုံရသည်၊ အခြေခံအားဖြင့် သကြားအလွှာတစ်ခုဖြစ်သည်။
ကုဒ်
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
ပိုက်တွေက ပေါက်နေတယ်...
piping ကို အသုံးပြု၍ တူညီသော လုပ်ဆောင်ချက်များကို လုပ်ဆောင်နိုင်သည်။ ပုံသဏ္ဍာန်တူသော်လည်း DT တစ်ခုတည်းတင်မဟုတ်ဘဲ မည်သည့်နည်းလမ်းများကိုမဆို သုံးနိုင်သောကြောင့် ပိုမိုလုပ်ဆောင်နိုင်သည် ။ DT filters အများအပြားဖြင့် ကျွန်ုပ်တို့၏ပေါင်းစပ်ဒေတာအတွက် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုကိန်းဂဏန်းများကို ရယူကြပါစို့။
ကုဒ်
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
စာရင်းအင်းများ၊ စက်သင်ယူမှုနှင့် DT အတွင်း အခြားအရာများ
Lambda လုပ်ဆောင်ချက်များကို အသုံးပြုနိုင်သော်လည်း တစ်ခါတစ်ရံတွင် ၎င်းတို့ကို သီးခြားဖန်တီးခြင်း၊ ဒေတာခွဲခြမ်းစိတ်ဖြာမှု ပိုက်လိုင်းတစ်ခုလုံးကို ရေးပြီး DT တွင် လုပ်ဆောင်ပါက ပိုမိုကောင်းမွန်ပါသည်။ ဥပမာတွင် အထက်ဖော်ပြပါ အင်္ဂါရပ်များအပြင် DT arsenal မှ အသုံးဝင်သောအရာများစွာဖြင့် ပြည့်စုံသည် (ဥပမာ DT အတွင်းမှ DT ကို လင့်ခ်တစ်ခုမှတစ်ဆင့် DT အတွင်းဝင်ရောက်ခြင်း၊ တစ်ခါတစ်ရံ အစီအစဥ်အတိုင်းထည့်သွင်းထားသော်လည်း သေချာစေရန်)။
ကုဒ်
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
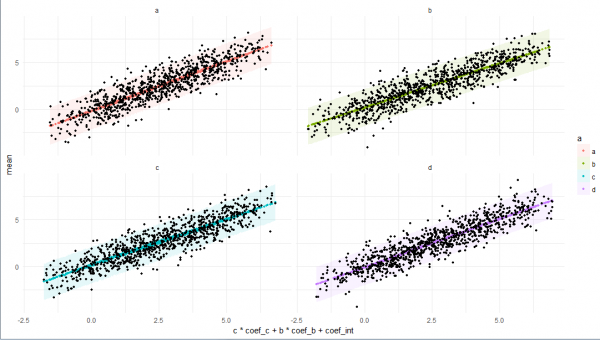
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
ကောက်ချက်
data.table object ၏ ရုပ်ပုံ၊ အလုံးစုံ မပြည့်စုံသော်လည်း၊ R အတန်းများမှ အမွေဆက်ခံခြင်းဆိုင်ရာ ဂုဏ်သတ္တိများမှ ၎င်း၏ ကိုယ်ပိုင်အင်္ဂါရပ်များနှင့် သပ်ရပ်သော ဒြပ်စင်များ၏ ပတ်ဝန်းကျင်အထိ ကျယ်ကျယ်ပြန့်ပြန့် ဖန်တီးနိုင်မည်ဟု မျှော်လင့်ပါသည်။ ၎င်းသည် သင့်အား ဤစာကြည့်တိုက်ကို ပိုမိုနားလည်ပြီး သင့်အလုပ်တွင် အသုံးချနိုင်လိမ့်မည်ဟု မျှော်လင့်ပါသည်။ ဖျော်ဖြေရေး.
Thank you!
ကုဒ်အပြည့်အစုံ
ကုဒ်
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
source: www.habr.com
