

Jean-Baptiste Lallement, directeur engineering bij Canonical, presenteerde het Myna-project, dat een spraakherkenningsapplicatie ontwikkelt die bedoeld is om spraakinvoer te organiseren en commando's in natuurlijke taal te herkennen. Ubuntu Desktop. Het project wordt gedistribueerd onder de GPLv3-licentie, maar de repository bevat momenteel alleen schetsen die de modulaire architectuur van het project en de integratie ervan beschrijven. Ubuntu.
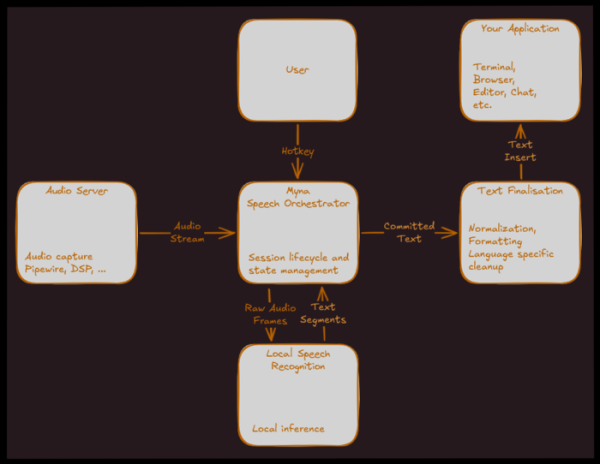
Voor publicatie Ubuntu Op 26.10 oktober zal de app compatibel zijn met spraakinvoer. Een gebruikerssessie bestaat uit het activeren van de app via een sneltoets, hardop dicteren en het plakken van de herkende tekst in de app via gesimuleerde toetsenbordinvoer terwijl u spreekt. Er verschijnt een speciale indicator in het paneel wanneer de microfoon is geactiveerd.
De basis testomgeving is naar verluidt GNOME op basis van Wayland, maar de applicatie is vanaf het begin ontworpen om aanpasbaar te zijn aan diverse desktopomgevingen.
Myna maakt gebruik van een lokaal draaiend AI-model voor spraakherkenning. De app moet aan de volgende eisen voldoen: offline kunnen werken; de microfoon moet alleen worden ingeschakeld na het expliciet activeren van de dicteermodus met een sneltoets; audio moet in het geheugen worden verwerkt, dat na elk gebruik wordt gewist; en het is niet mogelijk om audio-opnames naar externe services te verzenden.
Componenten voor spraakherkenning, gebruikersinteractie, dicteerbeheer en tekstvervanging worden ontwikkeld in de vorm van modules.
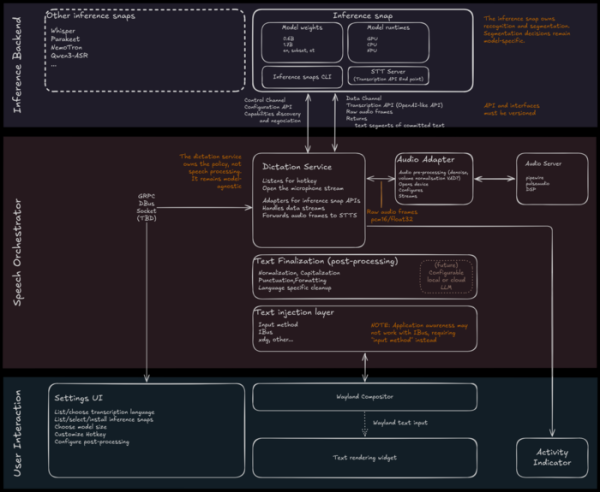
De uitvoeringsomgeving van het AI-model wordt als een snapshot verpakt. Whisper, Parakeet, NemoTron en Qwen3-ASR worden genoemd als mogelijke herkenningsmodellen.
De dicteerservice controleert toetsaanslagen, activeert de microfoon, benadert het AI-model in het snap-pakket via een API, stuurt de audiostream van de audioservice ernaartoe en coördineert de gegevensstromen.
De audioservice benadert het audioapparaat, direct of via de PulseAudio- of PipeWire-audioservers, onderdrukt ruis en egaliseert het volume. De door het model gegenereerde tekst wordt doorgegeven aan de nabewerkingsmodule voor opschoning, normalisatie, opmaak en interpunctie. De uiteindelijke tekst wordt in de applicatie ingevoegd via inputsubstitutie, bijvoorbeeld via het Wayland-inputmethodeprotocol of IBus.
Zodra de initiële functionaliteit stabiel is, is de implementatie van mogelijkheden zoals functioneren als spraakassistent, het uitvoeren van spraakopdrachten, spraakbesturing van het bureaublad en het vertalen van gedicteerde tekst met automatische taalherkenning niet uit te sluiten.
Bron: opennet.ru
