

In dit artikel zal ik vertellen hoe het project waaraan ik werk, is getransformeerd van een grote monoliet naar een reeks microservices.
Het project begon zijn geschiedenis lang geleden, begin 2000. De eerste versies werden geschreven in Visual Basic 6. Na verloop van tijd werd het duidelijk dat de ontwikkeling in deze taal in de toekomst moeilijk te ondersteunen zou zijn, aangezien de IDE en de taal zelf zijn slecht ontwikkeld. Eind jaren 2000 werd besloten om over te stappen op het veelbelovende C#. De nieuwe versie werd parallel geschreven met de herziening van de oude, geleidelijk werd er steeds meer code in .NET geschreven. Backend in C# was aanvankelijk gericht op een servicearchitectuur, maar tijdens de ontwikkeling werd gebruik gemaakt van gemeenschappelijke bibliotheken met logica en werden services in één proces gelanceerd. Het resultaat was een applicatie die we een ‘servicemonoliet’ noemden.
Een van de weinige voordelen van deze combinatie was de mogelijkheid dat services elkaar kunnen aanroepen via een externe API. Er waren duidelijke voorwaarden voor de transitie naar een correctere dienstverlening en in de toekomst naar een microservice-architectuur.
We zijn rond 2015 begonnen met ons werk op het gebied van decompositie. We hebben nog geen ideale staat bereikt - er zijn nog steeds delen van een groot project die nauwelijks monolieten kunnen worden genoemd, maar ze zien er ook niet uit als microservices. Niettemin is de vooruitgang aanzienlijk.
Ik zal erover praten in het artikel.
Inhoud
Architectuur en problemen van de bestaande oplossing
Aanvankelijk zag de architectuur er als volgt uit: de gebruikersinterface is een afzonderlijke applicatie, het monolithische deel is geschreven in Visual Basic 6, de .NET-applicatie is een reeks gerelateerde services die met een vrij grote database werken.
Nadelen van de vorige oplossing
Eén punt van mislukking
Er was één single point of fail: de .NET-applicatie draaide in één proces. Als een module faalde, faalde de hele applicatie en moest deze opnieuw worden opgestart. Omdat we voor verschillende gebruikers een groot aantal processen automatiseren, kon door een storing in één daarvan iedereen een tijdje niet werken. En in het geval van een softwarefout hielp zelfs een back-up niet.
Wachtrij van verbeteringen
Dit nadeel is nogal organisatorisch. Onze applicatie heeft veel klanten en ze willen deze allemaal zo snel mogelijk verbeteren. Voorheen was het onmogelijk om dit parallel te doen en stonden alle klanten in de rij. Voor bedrijven was dit proces negatief omdat zij moesten bewijzen dat hun taak waardevol was. En het ontwikkelingsteam heeft tijd besteed aan het organiseren van deze wachtrij. Dit kostte veel tijd en moeite en het product kon uiteindelijk niet zo snel veranderen als ze hadden gewild.
Suboptimaal gebruik van hulpbronnen
Bij het hosten van diensten in één proces kopieerden we de configuratie altijd volledig van server naar server. We wilden de zwaarst belaste services afzonderlijk plaatsen om geen middelen te verspillen en een flexibelere controle te krijgen over ons inzetschema.
Moeilijk om moderne technologieën te implementeren
Een probleem dat alle ontwikkelaars kent: er is een wens om moderne technologieën in het project te introduceren, maar er is geen mogelijkheid. Met een grote monolithische oplossing wordt elke update van de huidige bibliotheek, om nog maar te zwijgen van de overgang naar een nieuwe, een nogal niet-triviale taak. Het duurt lang voordat je aan de teamleider kunt bewijzen dat dit meer bonussen oplevert dan verspilde zenuwen.
Moeilijkheden om wijzigingen door te geven
Dit was het ernstigste probleem: we brachten elke twee maanden releases uit.
Elke release werd een echte ramp voor de bank, ondanks de tests en inspanningen van de ontwikkelaars. Het bedrijf begreep dat begin deze week een deel van de functionaliteit niet zou werken. En de ontwikkelaars begrepen dat hen een week vol ernstige incidenten te wachten stond.
Iedereen had de wens om de situatie te veranderen.
Verwachtingen van microservices
Uitgifte van componenten wanneer gereed. Levering van componenten wanneer deze gereed zijn door de oplossing te ontleden en verschillende processen te scheiden.
Kleine productteams. Dit is belangrijk omdat een groot team dat aan de oude monoliet werkte moeilijk te managen was. Zo’n team moest noodgedwongen volgens een strikt proces werken, maar wilde meer creativiteit en onafhankelijkheid. Alleen kleine teams konden dit betalen.
Isolatie van services in afzonderlijke processen. Idealiter zou ik het in containers willen isoleren, maar een groot aantal services die in het .NET Framework zijn geschreven, draaien alleen onder WindowsEr verschijnen nu weliswaar diensten gebaseerd op .NET Core, maar het zijn er nog maar weinig.
Flexibiliteit bij implementatie. We willen services graag combineren zoals wij die nodig hebben, en niet zoals de code dit afdwingt.
Gebruik van nieuwe technologieën. Dit is interessant voor elke programmeur.
Overgangsproblemen
Als het gemakkelijk zou zijn om een monoliet in microservices op te splitsen, zou het natuurlijk niet nodig zijn om er op conferenties over te praten en artikelen te schrijven. Er zijn veel valkuilen in dit proces; ik zal de belangrijkste beschrijven die ons hinderden.
Het eerste probleem: typisch voor de meeste monolieten: samenhang van bedrijfslogica. Wanneer we een monoliet schrijven, willen we onze klassen hergebruiken om geen onnodige code te schrijven. En bij de overstap naar microservices wordt dit een probleem: alle code is behoorlijk nauw met elkaar verbonden en het is moeilijk om de services te scheiden.
Toen de werkzaamheden begonnen, had de repository meer dan 500 projecten en meer dan 700 regels code. Dit is een behoorlijk grote beslissing en tweede probleem. Het was niet mogelijk om het simpelweg in microservices te verdelen.
Derde probleem — gebrek aan noodzakelijke infrastructuur. In feite kopieerden we de broncode handmatig naar de servers.
Hoe u van monoliet naar microservices kunt gaan
Microservices inrichten
Ten eerste hebben we voor onszelf meteen vastgesteld dat het scheiden van microservices een iteratief proces is. Er werd altijd van ons verwacht dat we bedrijfsproblemen parallel ontwikkelden. Hoe we dit technisch gaan implementeren is al ons probleem. Daarom hebben we ons voorbereid op een iteratief proces. Anders werkt het niet als je een grote applicatie hebt en deze in eerste instantie nog niet klaar is om herschreven te worden.
Welke methoden gebruiken we om microservices te isoleren?
De eerste methode — bestaande modules als services verplaatsen. In dit opzicht hadden we geluk: er waren al geregistreerde services die werkten met het WCF-protocol. Ze werden gescheiden in afzonderlijke vergaderingen. We hebben ze afzonderlijk geporteerd en aan elke build een kleine launcher toegevoegd. Het is geschreven met behulp van de prachtige Topshelf-bibliotheek, waarmee je de applicatie zowel als service als als console kunt gebruiken. Dit is handig bij het debuggen, omdat er geen extra projecten nodig zijn in de oplossing.
De diensten waren verbonden volgens bedrijfslogica, omdat ze gebruik maakten van gemeenschappelijke assemblages en werkten met een gemeenschappelijke database. In hun pure vorm kunnen ze nauwelijks microservices worden genoemd. We kunnen deze diensten echter afzonderlijk, in verschillende processen, aanbieden. Dit alleen al maakte het mogelijk om hun invloed op elkaar te verminderen, waardoor het probleem met parallelle ontwikkeling en een enkel punt van mislukking werd verminderd.
Assembly met de host is slechts één regel code in de Program-klasse. We hebben het werk met Topshelf verborgen in een hulpklas.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
De tweede manier om microservices toe te wijzen is: creëer ze om nieuwe problemen op te lossen. Als de monoliet tegelijkertijd niet groeit, is dit al uitstekend, wat betekent dat we in de goede richting gaan. Om nieuwe problemen op te lossen, probeerden we aparte diensten te creëren. Als er zo'n mogelijkheid was, dan hebben we meer 'canonieke' services gecreëerd die hun eigen datamodel, een aparte database, volledig beheren.
Wij zijn, zoals velen, begonnen met authenticatie- en autorisatiediensten. Ze zijn hier perfect voor. Ze zijn onafhankelijk, in de regel hebben ze een apart datamodel. Ze hebben zelf geen interactie met de monoliet, maar hij wendt zich tot hen om enkele problemen op te lossen. Met behulp van deze services kunt u de overgang naar een nieuwe architectuur beginnen, de infrastructuur erop debuggen, een aantal benaderingen uitproberen die verband houden met netwerkbibliotheken, enz. We hebben geen teams in onze organisatie die geen authenticatieservice kunnen creëren.
De derde manier om microservices toe te wijzenDegene die we gebruiken is een beetje specifiek voor ons. Dit is het verwijderen van bedrijfslogica uit de UI-laag. Onze belangrijkste UI-applicatie is desktop; deze is, net als de backend, geschreven in C#. De ontwikkelaars maakten regelmatig fouten en brachten delen van de logica over naar de gebruikersinterface die in de backend hadden moeten bestaan en hergebruikt zouden moeten worden.
Als je naar een echt voorbeeld uit de code van het UI-gedeelte kijkt, kun je zien dat het grootste deel van deze oplossing echte bedrijfslogica bevat die nuttig is in andere processen, niet alleen voor het bouwen van het UI-formulier.
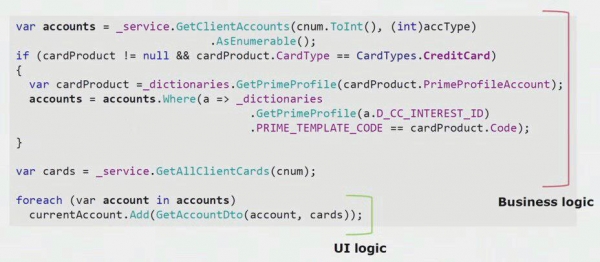
De echte UI-logica is alleen aanwezig in de laatste paar regels. We hebben het naar de server overgebracht zodat het opnieuw kon worden gebruikt, waardoor de gebruikersinterface werd verkleind en de juiste architectuur werd bereikt.
De vierde en belangrijkste manier om microservices te isoleren, wat het mogelijk maakt om de monoliet te verkleinen, is het verwijderen van bestaande diensten met verwerking. Wanneer we bestaande modules eruit halen zoals ze zijn, is het resultaat niet altijd naar de zin van de ontwikkelaars en is het bedrijfsproces mogelijk verouderd sinds de functionaliteit is gecreëerd. Met refactoring kunnen we een nieuw bedrijfsproces ondersteunen, omdat de bedrijfsvereisten voortdurend veranderen. We kunnen de broncode verbeteren, bekende defecten verwijderen en een beter datamodel creëren. Er zijn veel voordelen te behalen.
Het scheiden van diensten en verwerking is onlosmakelijk verbonden met het concept van begrensde context. Dit is een concept van Domain Driven Design. Het betekent een deel van het domeinmodel waarin alle termen van een enkele taal uniek zijn gedefinieerd. Laten we als voorbeeld eens kijken naar de context van verzekeringen en rekeningen. We hebben een monolithische toepassing en we moeten werken met de verzekeringsrekening. We verwachten dat de ontwikkelaar een bestaande Account-klasse in een andere assembly vindt, ernaar verwijst vanuit de Insurance-klasse, en we hebben werkende code. Het DRY-principe zal worden gerespecteerd, de taak zal sneller worden uitgevoerd door bestaande code te gebruiken.
Hierdoor blijkt dat de contexten van rekeningen en verzekeringen met elkaar verbonden zijn. Naarmate er nieuwe eisen ontstaan, zal deze koppeling de ontwikkeling belemmeren, waardoor de complexiteit van de toch al complexe bedrijfslogica toeneemt. Om dit probleem op te lossen, moet u grenzen tussen contexten in de code vinden en hun overtredingen verwijderen. In de context van verzekeringen is het bijvoorbeeld heel goed mogelijk dat een 20-cijferig rekeningnummer van de Centrale Bank en de datum van opening van de rekening voldoende zijn.
Om deze begrensde contexten van elkaar te scheiden en het proces van het scheiden van microservices van een monolithische oplossing te starten, hebben we een aanpak gebruikt zoals het creëren van externe API's binnen de applicatie. Als we wisten dat een bepaalde module een microservice zou moeten worden, op de een of andere manier aangepast binnen het proces, dan hebben we onmiddellijk via externe oproepen de logica aangeroepen die tot een andere beperkte context behoort. Bijvoorbeeld via REST of WCF.
We hebben resoluut besloten dat we code die gedistribueerde transacties vereist, niet zouden vermijden. In ons geval bleek het vrij eenvoudig om deze regel te volgen. We zijn nog geen situaties tegengekomen waarin strikt gedistribueerde transacties echt nodig zijn - de uiteindelijke consistentie tussen modules is ruim voldoende.
Laten we eens naar een specifiek voorbeeld kijken. We hebben het concept van een orkestrator: een pijplijn die de entiteit van de “applicatie” verwerkt. Hij maakt achtereenvolgens een klant, een rekening en een bankpas aan. Als de klant en het account succesvol zijn aangemaakt, maar het aanmaken van de kaart mislukt, gaat de applicatie niet naar de status “succesvol” en blijft in de status “kaart niet aangemaakt”. In de toekomst zal achtergrondactiviteit het oppakken en afmaken. Het systeem verkeert al enige tijd in een staat van inconsistentie, maar daar zijn we over het algemeen tevreden mee.
Mocht er zich een situatie voordoen waarin het nodig is om een deel van de gegevens consequent op te slaan, dan zullen wij hoogstwaarschijnlijk voor consolidatie van de dienstverlening gaan om deze in één proces te kunnen verwerken.
Laten we eens kijken naar een voorbeeld van het toewijzen van een microservice. Hoe kun je het relatief veilig naar productie brengen? In dit voorbeeld hebben we een apart deel van het systeem: een salarisservicemodule, een van de codesecties waarvan we graag een microservice willen maken.
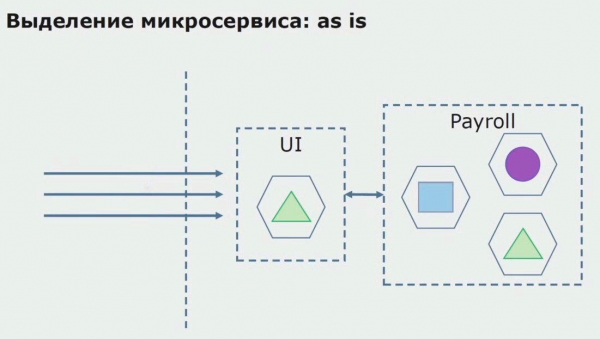
Allereerst creëren we een microservice door de code te herschrijven. We zijn bezig met het verbeteren van een aantal aspecten waar we niet blij mee waren. Wij implementeren nieuwe bedrijfseisen van de klant. We voegen een API Gateway toe aan de verbinding tussen de UI en de backend, die zorgt voor het doorsturen van oproepen.
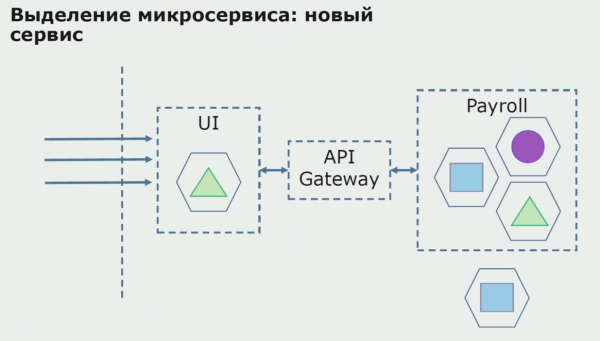
Vervolgens brengen we deze configuratie in gebruik, maar dan in een pilotstatus. De meeste van onze gebruikers werken nog met oude bedrijfsprocessen. Voor nieuwe gebruikers ontwikkelen we een nieuwe versie van de monolithische applicatie die dit proces niet langer bevat. In wezen hebben we een combinatie van een monoliet en een microservice die als pilot werkt.
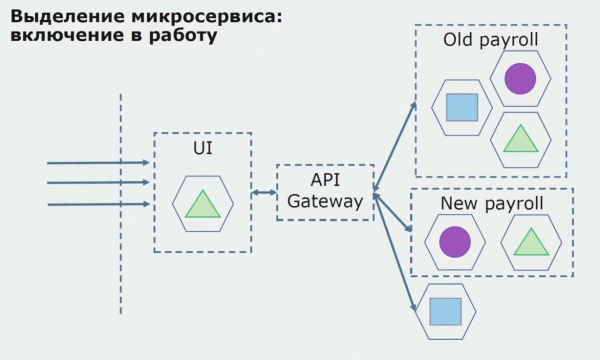
Met een succesvolle pilot begrijpen we dat de nieuwe configuratie inderdaad werkbaar is, we kunnen de oude monoliet uit de vergelijking verwijderen en de nieuwe configuratie in plaats van de oude oplossing laten.
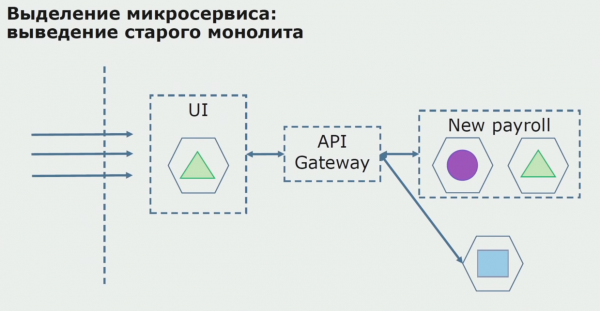
In totaal gebruiken we vrijwel alle bestaande methoden voor het splitsen van de broncode van een monoliet. Ze stellen ons allemaal in staat de omvang van delen van de applicatie te verkleinen en deze naar nieuwe bibliotheken te vertalen, waardoor een betere broncode ontstaat.
Werken met de databank
De database kan slechter worden verdeeld dan de broncode, omdat deze niet alleen het huidige schema bevat, maar ook verzamelde historische gegevens.
Onze database had, net als vele andere, nog een belangrijk nadeel: de enorme omvang ervan. Deze database is ontworpen volgens de ingewikkelde bedrijfslogica van een monoliet, en de relaties zijn opgebouwd tussen de tabellen van verschillende begrensde contexten.
In ons geval deed zich naast alle problemen (grote database, veel verbindingen, soms onduidelijke grenzen tussen tabellen) een probleem voor dat bij veel grote projecten voorkomt: het gebruik van de gedeelde databasesjabloon. Gegevens werden via weergave en replicatie uit tabellen gehaald en naar andere systemen verzonden waar deze replicatie nodig was. Als gevolg hiervan konden we de tabellen niet naar een apart schema verplaatsen omdat ze actief werden gebruikt.
Dezelfde indeling in beperkte contexten in de code helpt ons bij de indeling. Het geeft ons meestal een redelijk goed beeld van hoe we de gegevens op databaseniveau opsplitsen. We begrijpen welke tabellen tot de ene begrensde context behoren en welke tot de andere.
We gebruikten twee globale methoden voor het partitioneren van databases: het partitioneren van bestaande tabellen en het partitioneren met verwerking.
Het afsplitsen van bestaande tabellen is een goede methode als de datastructuur goed is, voldoet aan de zakelijke vereisten en iedereen er blij mee is. In dit geval kunnen we bestaande tabellen in een afzonderlijk schema scheiden.
Er is een afdeling met verwerking nodig als het bedrijfsmodel sterk is veranderd en de tabellen ons helemaal niet meer tevreden stellen.
Bestaande tabellen splitsen. We moeten bepalen wat we gaan scheiden. Zonder deze kennis zal niets werken, en hier zal de scheiding van begrensde contexten in de code ons helpen. Als u de grenzen van contexten in de broncode begrijpt, wordt het in de regel duidelijk welke tabellen in de lijst voor de afdeling moeten worden opgenomen.
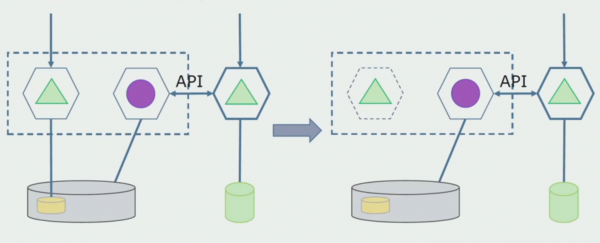
Laten we ons voorstellen dat we een oplossing hebben waarin twee monolietmodules samenwerken met één database. We moeten ervoor zorgen dat slechts één module communiceert met de sectie met gescheiden tabellen, en dat de andere ermee begint te communiceren via de API. Om te beginnen is het voldoende dat alleen de opname via de API plaatsvindt. Dit is een noodzakelijke voorwaarde voor ons om over de onafhankelijkheid van microservices te praten. Leesverbindingen kunnen blijven bestaan zolang er geen groot probleem is.
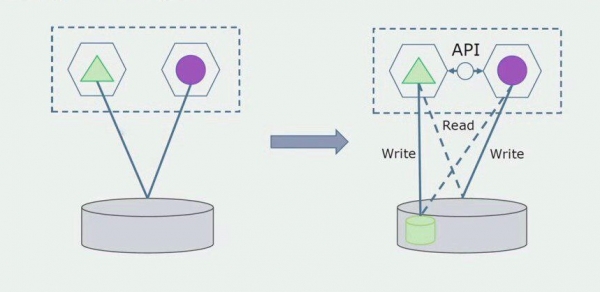
De volgende stap is dat we het codegedeelte dat met afzonderlijke tabellen werkt, met of zonder verwerking, kunnen scheiden in een afzonderlijke microservice en deze in een afzonderlijk proces, een container, kunnen uitvoeren. Dit wordt een aparte dienst met een verbinding met de monolith-database en de tabellen die daar niet direct verband mee houden. De monoliet werkt bij het lezen nog steeds samen met het afneembare deel.
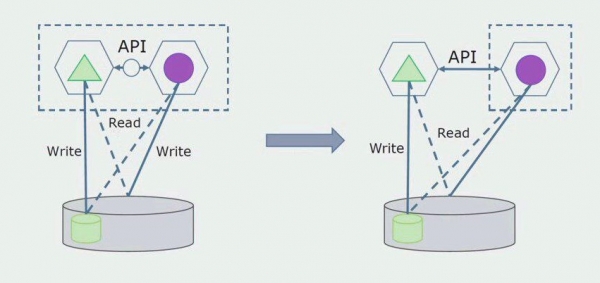
Later zullen we deze verbinding verwijderen, dat wil zeggen dat het lezen van gegevens uit een monolithische applicatie uit gescheiden tabellen ook naar de API zal worden overgebracht.
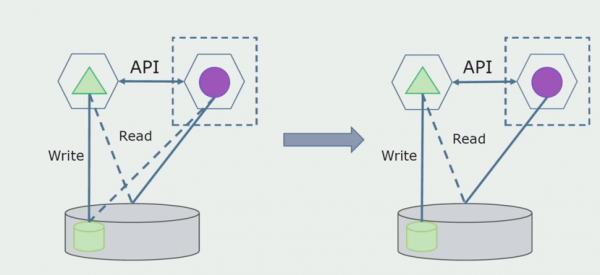
Vervolgens selecteren we uit de algemene database de tabellen waarmee alleen de nieuwe microservice werkt. We kunnen de tabellen naar een apart schema of zelfs naar een aparte fysieke database verplaatsen. Er is nog steeds een leesverbinding tussen de microservice en de monolith-database, maar u hoeft zich nergens zorgen over te maken, in deze configuratie kan deze behoorlijk lang meegaan.
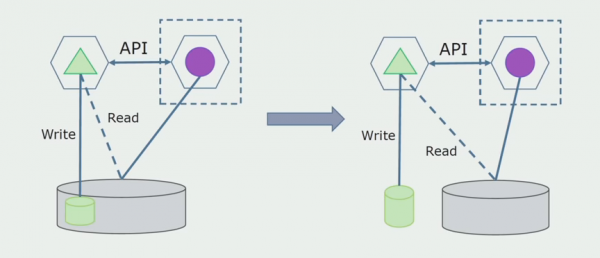
De laatste stap is het volledig verwijderen van alle verbindingen. In dit geval moeten we mogelijk gegevens uit de hoofddatabase migreren. Soms willen we bepaalde gegevens of mappen die zijn gerepliceerd vanuit externe systemen in verschillende databases hergebruiken. Dit overkomt ons periodiek.
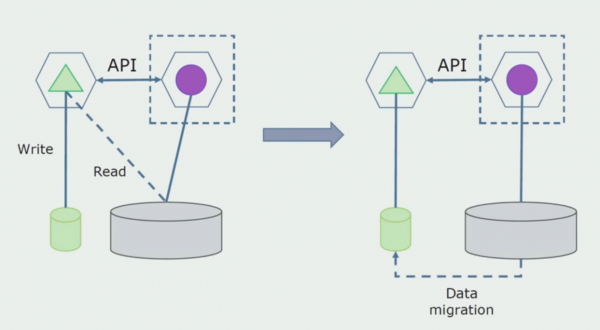
Afdeling Verwerking. Deze methode lijkt sterk op de eerste, alleen in omgekeerde volgorde. We wijzen onmiddellijk een nieuwe database toe en een nieuwe microservice die via een API met de monoliet communiceert. Maar tegelijkertijd blijft er een reeks databasetabellen over die we in de toekomst willen verwijderen. We hebben hem niet meer nodig; we hebben hem vervangen in het nieuwe model.
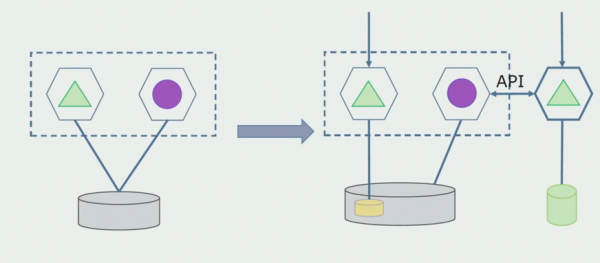
Om dit plan te laten werken, hebben we waarschijnlijk een overgangsperiode nodig.
Er zijn dan twee mogelijke benaderingen.
Eerste: we dupliceren alle gegevens in de nieuwe en oude databases. In dit geval is er sprake van gegevensredundantie en kunnen er synchronisatieproblemen optreden. Maar we kunnen twee verschillende klanten aannemen. De één werkt met de nieuwe versie, de ander met de oude.
Tweede: we verdelen de gegevens volgens enkele zakelijke criteria. We hadden bijvoorbeeld 5 producten in het systeem die in de oude database waren opgeslagen. De zesde binnen de nieuwe bedrijfstaak plaatsen we in een nieuwe database. Maar we hebben een API Gateway nodig die deze gegevens synchroniseert en de klant laat zien waar en wat hij vandaan moet halen.
Beide benaderingen werken, kies afhankelijk van de situatie.
Nadat we er zeker van zijn dat alles werkt, kan het deel van de monoliet dat met oude databasestructuren werkt, worden uitgeschakeld.
De laatste stap is het verwijderen van de oude datastructuren.
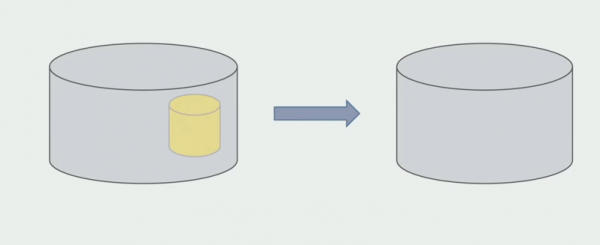
Samenvattend kunnen we zeggen dat we problemen hebben met de database: het is moeilijk om ermee te werken in vergelijking met de broncode, het is moeilijker om te delen, maar het kan en moet gedaan worden. We hebben een aantal manieren gevonden waarmee we dit redelijk veilig kunnen doen, maar het is nog steeds gemakkelijker om fouten te maken met data dan met broncode.
Werken met broncode
Zo zag het broncodediagram eruit toen we begonnen met het analyseren van het monolithische project.
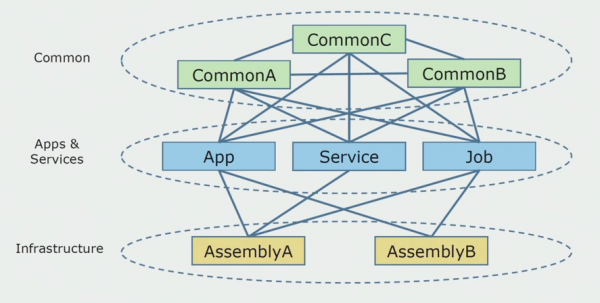
Het kan grofweg in drie lagen worden verdeeld. Dit is een laag van gelanceerde modules, plug-ins, services en individuele activiteiten. In feite waren dit toegangspunten binnen een monolithische oplossing. Ze waren allemaal goed afgesloten met een gemeenschappelijke laag. Het had bedrijfslogica die de services deelden en veel verbindingen. Elke service en plug-in gebruikte maximaal 10 of meer gebruikelijke samenstellingen, afhankelijk van hun grootte en het geweten van de ontwikkelaars.
We hadden het geluk dat we infrastructuurbibliotheken hadden die afzonderlijk konden worden gebruikt.
Soms deed zich een situatie voor waarin sommige gemeenschappelijke objecten eigenlijk niet tot deze laag behoorden, maar infrastructuurbibliotheken waren. Dit is opgelost door de naam te wijzigen.
De grootste zorg betrof de begrensde contexten. Het gebeurde dat 3-4 contexten gemengd waren in één gemeenschappelijke vergadering en elkaar gebruikten binnen dezelfde bedrijfsfuncties. Het was noodzakelijk om te begrijpen waar dit verdeeld kon worden en langs welke grenzen, en wat we vervolgens moesten doen door deze verdeling in broncodesamenstellen in kaart te brengen.
We hebben verschillende regels geformuleerd voor het codesplitsingsproces.
Het eerste: We wilden niet langer bedrijfslogica delen tussen services, activiteiten en plug-ins. We wilden bedrijfslogica onafhankelijk maken binnen microservices. Microservices worden daarentegen idealiter gezien als diensten die volledig onafhankelijk bestaan. Ik ben van mening dat deze aanpak enigszins verkwistend is en moeilijk te realiseren, omdat services in C# bijvoorbeeld sowieso met elkaar verbonden zullen zijn door een standaardbibliotheek. Ons systeem is geschreven in C#; andere technologieën hebben we nog niet gebruikt. Daarom besloten we dat we het ons konden veroorloven om gemeenschappelijke technische assemblages te gebruiken. Het belangrijkste is dat ze geen fragmenten van bedrijfslogica bevatten. Als u een handige verpakking hebt over de ORM die u gebruikt, is het kopiëren ervan van service naar service erg duur.
Ons team is fan van domeingedreven design, dus uienarchitectuur paste uitstekend bij ons. De basis van onze dienstverlening is niet de datatoegangslaag, maar een samenstel met domeinlogica, die alleen bedrijfslogica bevat en geen verbindingen heeft met de infrastructuur. Tegelijkertijd kunnen we de domeinassemblage onafhankelijk aanpassen om problemen met raamwerken op te lossen.
In dit stadium kwamen we ons eerste serieuze probleem tegen. De service moest verwijzen naar één domeinassemblage, we wilden de logica onafhankelijk maken, en het DRY-principe hinderde ons hier enorm. De ontwikkelaars wilden klassen van aangrenzende assemblages hergebruiken om duplicatie te voorkomen, en als gevolg daarvan begonnen domeinen weer aan elkaar te worden gekoppeld. We analyseerden de resultaten en kwamen tot de conclusie dat het probleem misschien ook op het gebied van het broncode-opslagapparaat ligt. We hadden een grote repository met daarin alle broncode. De oplossing voor het gehele project was zeer lastig te monteren op een lokale machine. Daarom werden voor delen van het project afzonderlijke kleine oplossingen gecreëerd, en niemand verbood het om er een gemeenschappelijke of domeinassemblage aan toe te voegen en deze opnieuw te gebruiken. De enige tool waarmee we dit niet konden doen, was code review. Maar soms mislukte het ook.
Vervolgens zijn we overgestapt op een model met afzonderlijke repositories. Bedrijfslogica stroomt niet langer van dienst naar dienst, domeinen zijn werkelijk onafhankelijk geworden. Begrensde contexten worden duidelijker ondersteund. Hoe hergebruiken we infrastructuurbibliotheken? We hebben ze gescheiden in een aparte repository en vervolgens in Nuget-pakketten geplaatst, die we in Artifactory hebben geplaatst. Bij elke wijziging vindt de montage en publicatie automatisch plaats.
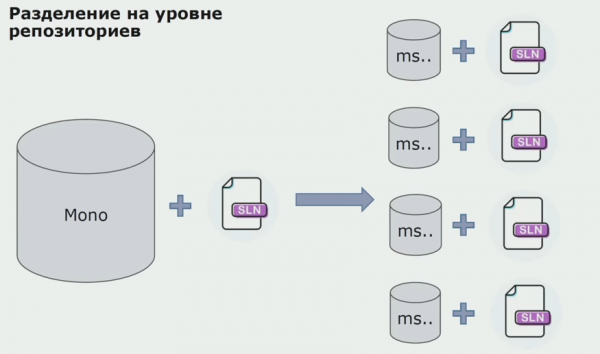
Onze services begonnen op dezelfde manier te verwijzen naar interne infrastructuurpakketten als externe pakketten. We downloaden externe bibliotheken van Nuget. Om met Artifactory te werken, waar we deze pakketten hebben geplaatst, hebben we twee pakketbeheerders gebruikt. In kleine repositories gebruikten we ook Nuget. In repository's met meerdere services hebben we Paket gebruikt, wat voor meer versieconsistentie tussen modules zorgt.
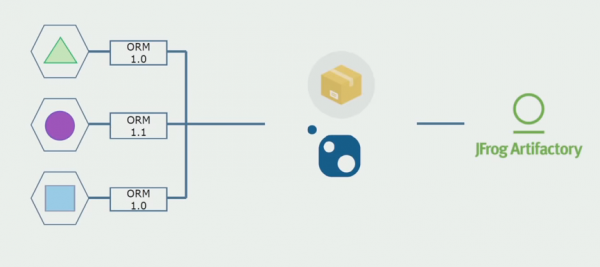
Door aan de broncode te werken, de architectuur enigszins te veranderen en de repositories te scheiden, maken we onze diensten onafhankelijker.
Problemen met de infrastructuur
De meeste nadelen van de overstap naar microservices hebben te maken met de infrastructuur. Je hebt geautomatiseerde implementatie nodig, je hebt nieuwe bibliotheken nodig om de infrastructuur te laten draaien.
Handmatige installatie in omgevingen
In eerste instantie hebben we de oplossing voor omgevingen handmatig geïnstalleerd. Om dit proces te automatiseren, hebben we een CI/CD-pijplijn gemaakt. Wij hebben gekozen voor het proces van continue levering, omdat continue inzet voor ons vanuit het oogpunt van bedrijfsprocessen nog niet acceptabel is. Daarom wordt het verzenden voor gebruik uitgevoerd met een knop en voor testen - automatisch.
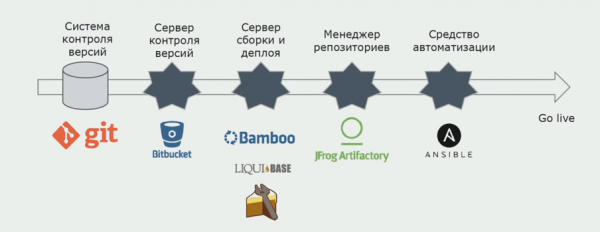
We gebruiken Atlassian, Bitbucket voor opslag van broncode en Bamboo voor bouwen. We schrijven graag build-scripts in Cake omdat het hetzelfde is als C#. Kant-en-klare pakketten komen naar Artifactory en Ansible komt automatisch op de testservers terecht, waarna ze direct getest kunnen worden.
Aparte logboekregistratie
Ooit was een van de ideeën van de monoliet het bieden van gedeelde houtkap. We moesten ook begrijpen wat we moesten doen met de afzonderlijke logboeken die op de schijven staan. Onze logs worden naar tekstbestanden geschreven. We hebben besloten om een standaard ELK-stack te gebruiken. We hebben niet rechtstreeks via de providers naar ELK geschreven, maar besloten dat we de tekstlogboeken zouden finaliseren en de trace-ID daarin zouden schrijven als identificatiemiddel, met toevoeging van de servicenaam, zodat deze logs later konden worden geparseerd.
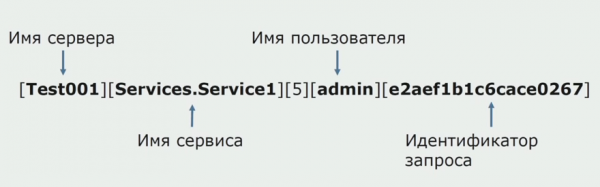
Met Filebeat kunnen we onze logbestanden verzamelen van serversTransformeer ze vervolgens, gebruik Kibana om query's in de gebruikersinterface te bouwen en zie hoe de aanroep tussen services is gerouteerd. Trace-ID's zijn hierbij erg nuttig.
Gerelateerde services testen en debuggen
Aanvankelijk begrepen we niet volledig hoe we fouten moesten opsporen in de services die werden ontwikkeld. Alles was eenvoudig met de monoliet; we draaiden het op een lokale machine. In eerste instantie probeerden ze hetzelfde te doen met microservices, maar soms moet je om één microservice volledig te lanceren meerdere andere lanceren, en dit is lastig. We realiseerden ons dat we naar een model moesten overstappen waarbij we alleen de service of services die we willen debuggen op de lokale machine achterlaten. De overige services worden gebruikt vanaf servers die overeenkomen met de configuratie met prod. Na het debuggen worden tijdens het testen voor elke taak alleen de gewijzigde services aan de testserver doorgegeven. Zo wordt de oplossing getest in de vorm waarin deze in de toekomst in productie zal verschijnen.
Er zijn servers die alleen productieversies van services uitvoeren. Deze servers zijn nodig bij incidenten, om de oplevering te controleren vóór inzet en voor interne trainingen.
We hebben een geautomatiseerd testproces toegevoegd met behulp van de populaire Specflow-bibliotheek. Tests worden automatisch uitgevoerd met NUnit onmiddellijk na implementatie vanuit Ansible. Als de taakdekking volledig automatisch verloopt, is handmatig testen niet nodig. Hoewel soms nog steeds aanvullende handmatige tests nodig zijn. We gebruiken tags in Jira om te bepalen welke tests er voor een specifiek probleem moeten worden uitgevoerd.
Bovendien is de behoefte aan belastingtests toegenomen; voorheen werden deze alleen in zeldzame gevallen uitgevoerd. We gebruiken JMeter om tests uit te voeren, InfluxDB om ze op te slaan en Grafana om procesgrafieken te bouwen.
Wat hebben we bereikt?
Ten eerste hebben we het concept ‘vrijgave’ afgeschaft. Voorbij zijn de twee maanden durende monsterlijke releases waarbij dit gevaarte in een productieomgeving werd ingezet, waardoor bedrijfsprocessen tijdelijk werden verstoord. Nu zetten we diensten gemiddeld elke 1,5 dag in en groeperen we ze omdat ze na goedkeuring in gebruik worden genomen.
Er zijn geen fatale storingen in ons systeem. Als we een microservice met een bug vrijgeven, wordt de bijbehorende functionaliteit verbroken en worden alle andere functionaliteiten niet beïnvloed. Dit verbetert de gebruikerservaring aanzienlijk.
We kunnen het implementatiepatroon beheersen. Indien nodig kunt u groepen services afzonderlijk van de rest van de oplossing selecteren.
Bovendien hebben we het probleem aanzienlijk verminderd met een grote reeks verbeteringen. We hebben nu aparte productteams die zelfstandig met een deel van de diensten werken. Het Scrum-proces past hier al goed bij. Een specifiek team kan een aparte Product Owner hebben die er taken aan toewijst.
Beknopt
- Microservices zijn zeer geschikt voor het ontleden van complexe systemen. Gaandeweg beginnen we te begrijpen wat er in ons systeem zit, welke beperkte contexten er zijn, waar hun grenzen liggen. Hierdoor kunt u verbeteringen correct over modules verdelen en codeverwarring voorkomen.
- Microservices bieden organisatorische voordelen. Er wordt vaak alleen over architectuur gesproken, maar elke architectuur is nodig om zakelijke behoeften op te lossen, en niet op zichzelf. Daarom kunnen we zeggen dat microservices zeer geschikt zijn voor het oplossen van problemen in kleine teams, aangezien Scrum nu erg populair is.
- Scheiding is een iteratief proces. Je kunt een applicatie niet eenvoudigweg opdelen in microservices. Het is onwaarschijnlijk dat het resulterende product functioneel zal zijn. Bij het inzetten van microservices is het nuttig om de bestaande erfenis te herschrijven, dat wil zeggen deze om te zetten in code die we leuk vinden en die beter voldoet aan de zakelijke behoeften op het gebied van functionaliteit en snelheid.
Een klein voorbehoud: De kosten voor de overstap naar microservices zijn behoorlijk aanzienlijk. Het duurde lang om het infrastructuurprobleem alleen op te lossen. Dus als u een kleine applicatie heeft waarvoor geen specifieke schaalvergroting nodig is, tenzij u een groot aantal klanten heeft die strijden om de aandacht en tijd van uw team, dan zijn microservices misschien niet wat u vandaag nodig heeft. Het is vrij duur. Start je het traject met microservices, dan zullen de kosten in eerste instantie hoger uitvallen dan wanneer je hetzelfde project start met de ontwikkeling van een monoliet.
PS Een emotioneler verhaal (en alsof het voor jou persoonlijk is) - volgens .
Hier vindt u de volledige versie van het rapport.
Bron: www.habr.com
