

Det første trinnet når du begynner å jobbe med et nytt datasett er å forstå det. For å gjøre dette, må du for eksempel finne ut verdiområdene akseptert av variablene, deres typer, og også finne ut om antall manglende verdier.
Panda-biblioteket gir oss mange nyttige verktøy for å utføre utforskende dataanalyse (EDA). Men før du bruker dem, må du vanligvis begynne med mer generelle funksjoner som df.describe(). Det bør imidlertid bemerkes at mulighetene som tilbys av slike funksjoner er begrenset, og de innledende stadiene av å jobbe med ethvert datasett når du utfører EDA er veldig ofte veldig like hverandre.
Forfatteren av materialet vi publiserer i dag sier at han ikke er en fan av å utføre repeterende handlinger. Som et resultat, på jakt etter verktøy for raskt og effektivt å utføre utforskende dataanalyse, fant han biblioteket . Resultatene av arbeidet uttrykkes ikke i form av enkelte individuelle indikatorer, men i form av en ganske detaljert HTML-rapport som inneholder mesteparten av informasjonen om de analyserte dataene som du kanskje trenger å vite før du begynner å jobbe tettere med dem.
Her vil vi se på funksjonene ved bruk av pandas-profileringsbiblioteket ved å bruke Titanic-datasettet som eksempel.
Utforskende dataanalyse ved hjelp av pandaer
Jeg bestemte meg for å eksperimentere med panda-profilering på Titanic-datasettet på grunn av de forskjellige typene data det inneholder og tilstedeværelsen av manglende verdier i det. Jeg tror at pandas-profileringsbiblioteket er spesielt interessant i tilfeller der dataene ennå ikke er renset og krever ytterligere behandling avhengig av egenskapene. For å kunne utføre en slik behandling, må du vite hvor du skal begynne og hva du skal være oppmerksom på. Det er her panda-profileringsevner kommer godt med.
Først importerer vi dataene og bruker pandaer for å få beskrivende statistikk:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()Etter å ha utført denne kodebiten, får du det som er vist i følgende figur.
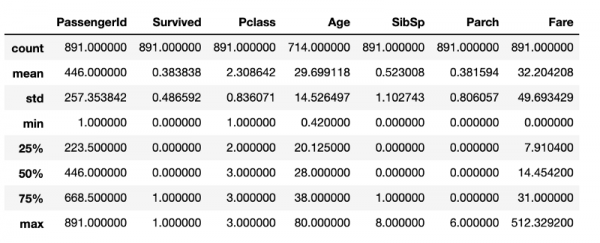
Beskrivende statistikk innhentet ved bruk av standard pandaverktøy
Selv om det er mye nyttig informasjon her, inneholder den ikke alt som kunne vært interessant å vite om dataene som studeres. For eksempel kan man anta at i en dataramme, i en struktur DataFrame, det er 891 linjer. Hvis dette må kontrolleres, kreves det en annen kodelinje for å bestemme størrelsen på rammen. Selv om disse beregningene ikke er spesielt ressurskrevende, er det å gjenta dem hele tiden sløsing med tid som sannsynligvis kan brukes bedre på å rense dataene.
Utforskende dataanalyse ved bruk av panda-profilering
La oss nå gjøre det samme ved å bruke pandas-profilering:
pandas_profiling.ProfileReport(df)Utførelse av kodelinjen ovenfor vil generere en rapport med utforskende dataanalyseindikatorer. Koden vist ovenfor vil sende ut dataene som er funnet, men du kan få den til å sende ut en HTML-fil som du for eksempel kan vise til noen.
Den første delen av rapporten vil inneholde en oversiktsdel, som gir grunnleggende informasjon om dataene (antall observasjoner, antall variabler osv.). Den vil også inneholde en liste over varsler, som varsler analytikeren om ting å være spesielt oppmerksom på. Disse varslene kan gi ledetråder om hvor du kan fokusere arbeidet med dataopprydding.
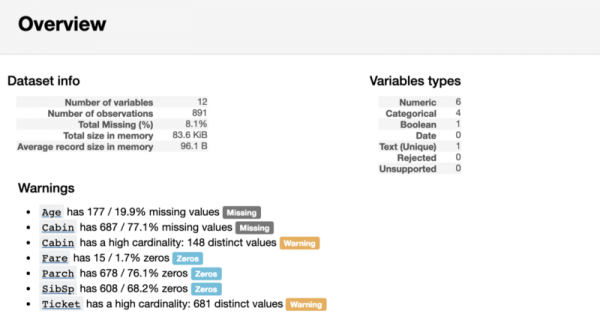
Oversiktsrapportseksjon
Utforskende variabelanalyse
Under Oversikt-delen av rapporten kan du finne nyttig informasjon om hver variabel. De inkluderer blant annet små diagrammer som beskriver fordelingen av hver variabel.

Om den numeriske aldersvariabelen
Som du kan se fra forrige eksempel, gir pandas-profilering oss flere nyttige indikatorer, for eksempel prosentandelen og antall manglende verdier, samt de beskrivende statistikkmålene som vi allerede har sett. Fordi Age er en numerisk variabel, visualisering av distribusjonen i form av et histogram lar oss konkludere med at vi har en fordeling skjevt til høyre.
Når man vurderer en kategorisk variabel, er utdataresultatene litt forskjellige fra de som er funnet for en numerisk variabel.

Om den kategoriske kjønnsvariabelen
Nemlig, i stedet for å finne gjennomsnitt, minimum og maksimum, fant pandas-profileringsbiblioteket antall klasser. Fordi Sex - en binær variabel, dens verdier er representert av to klasser.
Hvis du liker å undersøke kode som jeg gjør, kan du være interessert i hvordan pandas-profileringsbiblioteket beregner disse beregningene. Å finne ut om dette, gitt at bibliotekkoden er åpen og tilgjengelig på GitHub, er ikke så vanskelig. Siden jeg ikke er noen stor fan av å bruke svarte bokser i prosjektene mine, tok jeg en titt på bibliotekets kildekode. Dette er for eksempel hvordan mekanismen for å behandle numeriske variabler ser ut, representert ved funksjonen :
def describe_numeric_1d(series, **kwargs):
"""Compute summary statistics of a numerical (`TYPE_NUM`) variable (a Series).
Also create histograms (mini an full) of its distribution.
Parameters
----------
series : Series
The variable to describe.
Returns
-------
Series
The description of the variable as a Series with index being stats keys.
"""
# Format a number as a percentage. For example 0.25 will be turned to 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# To avoid to compute it several times
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# The dropna() is a workaround for https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] if stats['mean'] else np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Histograms
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name) Selv om denne kodebiten kan virke ganske stor og kompleks, er den faktisk veldig enkel å forstå. Poenget er at i kildekoden til biblioteket er det en funksjon som bestemmer typene variabler. Hvis det viser seg at biblioteket har støtt på en numerisk variabel, vil funksjonen ovenfor finne beregningene vi så på. Denne funksjonen bruker standard pandaoperasjoner for å arbeide med objekter av typen Series, som series.mean(). Beregningsresultater lagres i en ordbok stats. Histogrammer genereres ved hjelp av en tilpasset versjon av funksjonen matplotlib.pyplot.hist. Tilpasning er rettet mot å sikre at funksjonen kan arbeide med ulike typer datasett.
Korrelasjonsindikatorer og utvalgsdata studert
Etter resultatene av analysen av variablene, vil panda-profilering, i Korrelasjoner-delen, vise Pearson- og Spearman-korrelasjonsmatrisene.
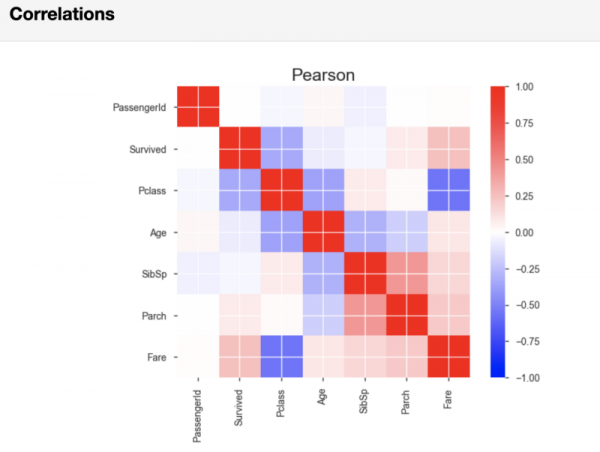
Pearson korrelasjonsmatrise
Om nødvendig kan du, i kodelinjen som utløser genereringen av rapporten, angi indikatorene for terskelverdiene som brukes ved beregning av korrelasjonen. Ved å gjøre dette kan du spesifisere hvilken korrelasjonsstyrke som anses som viktig for analysen din.
Til slutt, i panda-profileringsrapporten, i prøvedelen, vises et fragment av data tatt fra begynnelsen av datasettet som et eksempel. Denne tilnærmingen kan føre til ubehagelige overraskelser, siden de første observasjonene kan representere et utvalg som ikke gjenspeiler egenskapene til hele datasettet.
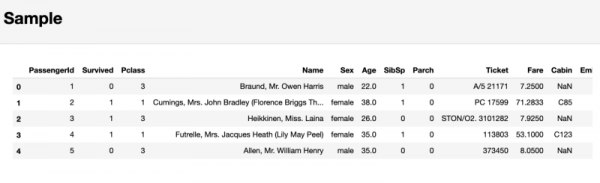
Seksjon som inneholder prøvedata som studeres
Som et resultat anbefaler jeg ikke å ta hensyn til denne siste delen. I stedet er det bedre å bruke kommandoen df.sample(5), som vil tilfeldig velge 5 observasjoner fra datasettet.
Resultater av
For å oppsummere, gir pandas-profileringsbiblioteket analytikeren noen nyttige funksjoner som vil komme til nytte i tilfeller der du raskt trenger å få en grov ide om dataene eller gi videre en etterretningsanalyserapport til noen. Samtidig utføres ekte arbeid med data, tatt i betraktning funksjonene,, som uten bruk av panda-profilering, manuelt.
Hvis du vil ta en titt på hvordan all etterretningsdataanalyse ser ut i én Jupyter-notisbok, ta en titt på prosjektet mitt opprettet ved hjelp av nbviewer. Og i Du kan finne den tilsvarende koden i GitHub-repositories.
Kjære lesere! Hvor begynner du å analysere nye datasett?
Kilde: www.habr.com
