


SRE (Site Reliability Engineering) er en tilnærming for å sikre tilgjengeligheten av nettprosjekter. Det regnes som et rammeverk for DevOps og snakker om hvordan man kan oppnå suksess med å bruke DevOps-praksis. Oversettelse i denne artikkelen bøker fra Google. Jeg utarbeidet denne oversettelsen selv og stolte på min egen erfaring med å forstå overvåkingsprosesser. I telegramkanalen и Jeg publiserte også en oversettelse av kapittel 6 i samme bok om servicenivåmål.
Oversettelse av katt. Liker å lese!
Det er umulig å administrere en tjeneste hvis det ikke er forståelse for hvilke indikatorer som faktisk betyr noe og hvordan man kan måle og evaluere dem. For dette formål definerer og tilbyr vi et visst servicenivå til våre brukere, uavhengig av om de bruker en av våre interne APIer eller et offentlig produkt.
Vi bruker vår intuisjon, erfaring og forståelse av brukernes ønske om å forstå Service Level Indicators (SLIs), Service Level Objectives (SLOs) og Service Level Agreements (SLAs). Disse dimensjonene beskriver de viktigste beregningene som vi ønsker å overvåke og som vi vil reagere på hvis vi ikke kan levere den forventede kvaliteten på tjenesten. Til syvende og sist hjelper det å velge riktige beregninger med å veilede de riktige handlingene hvis noe går galt, og gir også SRE-teamet tillit til helsen til tjenesten.
Dette kapittelet beskriver tilnærmingen vi bruker for å bekjempe problemene med metrisk modellering, metrisk utvalg og metrisk analyse. Det meste av forklaringen vil være uten eksempler, så vi vil bruke Shakespeare-tjenesten beskrevet i implementeringseksemplet (søk etter Shakespeares verk) for å illustrere hovedpoengene.
Terminologi på tjenestenivå
Mange lesere er sannsynligvis kjent med konseptet SLA, men begrepene SLI og SLO fortjener en nøye definisjon fordi begrepet SLA generelt er overbelastet og har en rekke betydninger avhengig av konteksten. For klarhetens skyld ønsker vi å skille disse verdiene.
indikatorer
SLI er en servicenivåindikator – et nøye definert kvantitativt mål på ett aspekt av tjenestenivået som tilbys.
For de fleste tjenester anses nøkkel-SLI å være forespørselsforsinkelse - hvor lang tid det tar å returnere et svar på en forespørsel. Andre vanlige SLI-er inkluderer feilfrekvens, ofte uttrykt som en brøkdel av alle mottatte forespørsler, og systemgjennomstrømning, vanligvis målt i forespørsler per sekund. Målinger er ofte aggregerte: rådata samles først inn og konverteres deretter til en endringshastighet, gjennomsnitt eller persentil.
Ideelt sett måler SLI direkte tjenestenivået av interesse, men noen ganger er bare en relatert beregning tilgjengelig for måling fordi den opprinnelige er vanskelig å få tak i eller tolke. For eksempel er ventetid på klientsiden ofte en mer passende beregning, men det er tider når latens kun kan måles på serveren.
En annen type SLI som er viktig for SREer er tilgjengelighet, eller den delen av tiden en tjeneste kan brukes i. Ofte definert som frekvensen av vellykkede forespørsler, noen ganger kalt avkastning. (Livstid – sannsynligheten for at data vil bli oppbevart i en lengre periode – er også viktig for datalagringssystemer.) Selv om 100 % tilgjengelighet ikke er mulig, er tilgjengelighet nær 100 % ofte oppnåelig; tilgjengelighetsverdier uttrykkes som antall "ni" » prosentandel av tilgjengelighet. For eksempel kan 99 % og 99,999 % tilgjengelighet merkes som "2 niere" og "5 niere". Google Compute Engines nåværende oppgitte tilgjengelighetsmål er «tre og en halv ni» eller 99,95 %.
mål
En SLO er et servicenivåmål: en målverdi eller verdiområde for et servicenivå som måles av SLI. En normal verdi for SLO er “SLI ≤ Target” eller “Lower Limit ≤ SLI ≤ Upper Limit”. For eksempel kan vi bestemme at vi skal returnere Shakespeare-søkeresultater «raske» ved å sette SLO til en gjennomsnittlig søkeforsinkelse på mindre enn 100 millisekunder.
Å velge riktig SLO er en kompleks prosess. For det første kan du ikke alltid velge en bestemt verdi. For eksterne innkommende HTTP-forespørsler til tjenesten din, bestemmes Query Per Second (QPS)-beregningen først og fremst av brukernes ønske om å besøke tjenesten din, og du kan ikke angi en SLO for det.
På den annen side kan du si at du vil at den gjennomsnittlige ventetiden for hver forespørsel skal være mindre enn 100 millisekunder. Å sette et slikt mål kan tvinge deg til å skrive grensesnittet med lav latens eller kjøpe utstyr som gir slik latency. (100 millisekunder er åpenbart et vilkårlig tall, men det er bedre å ha enda lavere latenstidstall. Det er bevis som tyder på at høye hastigheter er bedre enn lave hastigheter, og at latens i behandling av brukerforespørsler over visse verdier faktisk tvinger folk til å holde seg unna fra tjenesten din.)
Igjen, dette er mer tvetydig enn det kan virke ved første øyekast: du bør ikke helt utelukke QPS fra beregningen. Faktum er at QPS og latency er sterkt relatert til hverandre: høyere QPS fører ofte til høyere latenser, og tjenester opplever vanligvis en kraftig nedgang i ytelsen når de når en viss belastningsterskel.
Å velge og publisere en SLO setter brukernes forventninger til hvordan tjenesten vil fungere. Denne strategien kan redusere ubegrunnede klager mot tjenesteeieren, for eksempel langsom ytelse. Uten en eksplisitt SLO, skaper brukere ofte sine egne forventninger om ønsket ytelse, som kanskje ikke har noe å gjøre med meningene til personene som designer og administrerer tjenesten. Denne situasjonen kan føre til oppblåste forventninger fra tjenesten, når brukere feilaktig tror at tjenesten vil være mer tilgjengelig enn den faktisk er, og forårsake mistillit når brukere tror at systemet er mindre pålitelig enn det faktisk er.
Avtaler
En tjenestenivåavtale er en eksplisitt eller implisitt kontrakt med brukerne dine som inkluderer konsekvensene av å møte (eller ikke oppfylle) SLO-ene de inneholder. Konsekvenser gjenkjennes lettest når de er økonomiske – en rabatt eller en bot – men de kan ha andre former. En enkel måte å snakke om forskjellen mellom SLO-er og SLA-er på er å spørre "hva skjer hvis SLO-ene ikke oppfylles?" Hvis det ikke er klare konsekvenser, ser du nesten helt sikkert på en SLO.
SRE er vanligvis ikke involvert i å lage SLAer fordi SLAer er nært knyttet til forretnings- og produktbeslutninger. SRE er imidlertid involvert i å bidra til å dempe konsekvensene av mislykkede SLOer. De kan også bidra til å bestemme SLI: Det må selvsagt være en objektiv måte å måle SLO i avtalen, ellers vil det være uenighet.
Google Søk er et eksempel på en viktig tjeneste som ikke har en offentlig SLA: vi vil at alle skal bruke Søk så effektivt som mulig, men vi har ikke signert en kontrakt med verden. Det er imidlertid fortsatt konsekvenser hvis søk ikke er tilgjengelig - utilgjengelighet resulterer i et fall i omdømmet vårt samt reduserte annonseinntekter. Mange andre Google-tjenester, for eksempel Google for Work, har eksplisitte servicenivåavtaler med brukere. Uavhengig av om en bestemt tjeneste har en SLA, er det viktig å definere SLI og SLO og bruke dem til å administrere tjenesten.
Så mye teori - nå å oppleve.
Indikatorer i praksis
Gitt at vi har konkludert med at det er viktig å velge passende beregninger for å måle tjenestenivå, hvordan vet du nå hvilke beregninger som betyr noe for en tjeneste eller et system?
Hva bryr du deg og brukerne dine om?
Du trenger ikke å bruke hver beregning som en SLI som du kan spore i et overvåkingssystem; Å forstå hva brukerne ønsker fra et system vil hjelpe deg å velge flere beregninger. Å velge for mange indikatorer gjør det vanskelig å fokusere på viktige indikatorer, mens å velge et lite antall kan etterlate store deler av systemet ditt uten tilsyn. Vi bruker vanligvis flere nøkkelindikatorer for å evaluere og forstå helsen til et system.
Tjenester kan generelt deles inn i flere deler når det gjelder SLI som er relevante for dem:
- Egendefinerte front-end-systemer, for eksempel søkegrensesnittene for Shakespeare-tjenesten fra vårt eksempel. De må være tilgjengelige, ha ingen forsinkelser og ha tilstrekkelig båndbredde. Følgelig kan spørsmål stilles: kan vi svare på forespørselen? Hvor lang tid tok det å svare på forespørselen? Hvor mange forespørsler kan behandles?
- Lagringssystemer. De verdsetter lav responsforsinkelse, tilgjengelighet og holdbarhet. Relaterte spørsmål: Hvor lang tid tar det å lese eller skrive data? Kan vi få tilgang til dataene på forespørsel? Er dataene tilgjengelige når vi trenger dem? Se kapittel 26 Dataintegritet: Det du leser er det du skriver for en detaljert diskusjon av disse problemene.
- Big data-systemer som databehandlingsrørledninger er avhengige av gjennomstrømning og ventetid for spørringsbehandling. Relaterte spørsmål: Hvor mye data behandles? Hvor lang tid tar det for data å reise fra du mottar en forespørsel til du gir et svar? (Noen deler av systemet kan også ha forsinkelser på visse stadier.)
Samling av indikatorer
Mange servicenivåindikatorer samles mest naturlig på serversiden ved å bruke et overvåkingssystem som Borgmon (se nedenfor). ) eller Prometheus, eller ganske enkelt periodisk analysere loggene, identifisere HTTP-svar med status 500. Noen systemer bør imidlertid utstyres med innsamling av beregninger på klientsiden, siden mangelen på overvåking på klientsiden kan føre til at man mangler en rekke problemer som påvirker brukere, men påvirker ikke beregninger på serversiden. For eksempel kan fokus på backend-svarforsinkelsen til Shakespeare-søketestapplikasjonen resultere i ventetid på brukersiden på grunn av JavaScript-problemer: i dette tilfellet er det å måle hvor lang tid det tar for nettleseren å behandle siden en bedre beregning.
Aggregasjon
For enkelhets skyld og brukervennlighet samler vi ofte råmål. Dette må gjøres nøye.
Noen beregninger virker enkle, som forespørsler per sekund, men selv denne tilsynelatende enkle målingen samler implisitt data over tid. Mottas målingen spesifikt én gang per sekund, eller er målingen gjennomsnittlig over antall forespørsler per minutt? Det siste alternativet kan skjule et mye høyere øyeblikkelig antall forespørsler som bare varer noen få sekunder. Tenk på et system som betjener 200 forespørsler per sekund med partall og 0 resten av tiden. En konstant i form av en gjennomsnittsverdi på 100 forespørsler per sekund og to ganger den øyeblikkelige belastningen er ikke det samme. På samme måte kan gjennomsnittsberegning av spørringsforsinkelser virke attraktivt, men det skjuler en viktig detalj: det er mulig at de fleste spørringene vil være raske, men det vil være mange spørringer som er trege.
De fleste indikatorer er bedre sett på som fordelinger i stedet for gjennomsnitt. For eksempel, for SLI-latens, vil noen forespørsler bli behandlet raskt, mens noen alltid vil ta lengre tid, noen ganger mye lengre tid. Et enkelt gjennomsnitt kan skjule disse lange forsinkelsene. Figuren viser et eksempel: selv om en typisk forespørsel tar omtrent 50 ms å betjene, er 5 % av forespørslene 20 ganger tregere! Overvåking og varsling basert kun på gjennomsnittlig ventetid viser ikke endringer i atferd gjennom dagen, når det faktisk er merkbare endringer i behandlingstiden for enkelte forespørsler (øverste linje).
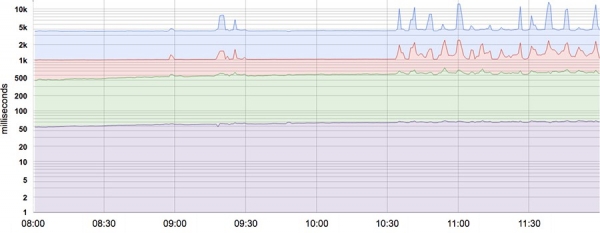
50, 85, 95 og 99 persentil systemforsinkelse. Y-aksen er i logaritmisk format.
Ved å bruke persentiler for indikatorer kan du se formen på fordelingen og dens egenskaper: et høyt persentilnivå, for eksempel 99 eller 99,9, viser den dårligste verdien, mens 50 persentilen (også kjent som medianen) viser den hyppigste tilstanden til metrikken. Jo større spredning i responstid, jo mer langvarige forespørsler påvirker brukeropplevelsen. Effekten forsterkes under høy belastning og i nærvær av køer. Brukererfaringsundersøkelser har vist at folk generelt foretrekker et langsommere system med høy responstidsvarians, så noen SRE-team fokuserer kun på høye persentilpoeng, på grunnlag av at hvis en metrikks oppførsel ved 99,9 persentilen er god, vil de fleste brukere ikke oppleve problemer .
Merknad om statistiske feil
Vi foretrekker generelt å jobbe med persentiler i stedet for gjennomsnittet (aritmetisk gjennomsnitt) av et sett med verdier. Dette lar oss vurdere mer spredte verdier, som ofte har vesentlig andre (og mer interessante) egenskaper enn gjennomsnittet. På grunn av den kunstige naturen til datasystemer, er metriske verdier ofte skjeve, slik at ingen forespørsel kan motta et svar på mindre enn 0 ms, og et tidsavbrudd på 1000 ms betyr at det ikke kan være vellykkede svar med verdier større enn tidsavbruddet. Som et resultat kan vi ikke akseptere at gjennomsnitt og median kan være det samme eller nær hverandre!
Uten forutgående testing, og med mindre visse standardantakelser og tilnærminger holder, er vi forsiktige med å konkludere med at dataene våre er normalt distribuert. Hvis distribusjonen ikke er som forventet, kan automatiseringsprosessen som løser problemet (for eksempel når den ser uteliggere, starter serveren på nytt med høye forespørselsbehandlingsforsinkelser) gjøre det for ofte eller ikke ofte nok (begge ikke er det veldig bra).
Standardiser indikatorer
Vi anbefaler å standardisere de generelle egenskapene for SLI slik at du ikke trenger å spekulere i dem hver gang. Enhver funksjon som tilfredsstiller standardmønstre kan ekskluderes fra spesifikasjonen til en individuell SLI, for eksempel:
- Aggregeringsintervaller: «gjennomsnittlig over 1 minutt»
- Aggregasjonsområder: «Alle oppgaver i klyngen»
- Hvor ofte måles det: «Hvert 10. sekund»
- Hvilke forespørsler er inkludert: "HTTP GET fra svarte boks-overvåkingsjobber"
- Hvordan dataene innhentes: "Takket være vår overvåking målt på serveren"
- Datatilgangsforsinkelse: «Tid til siste byte»
For å spare innsats, lag et sett med gjenbrukbare SLI-maler for hver felles metrikk; de gjør det også lettere for alle å forstå hva en bestemt SLI betyr.
Mål i praksis
Start med å tenke på (eller finne ut!) hva brukerne dine bryr seg om, ikke hva du kan måle. Ofte er det vanskelig eller umulig å måle hva brukerne dine bryr seg om, så du ender opp med å komme nærmere deres behov. Men hvis du bare starter med det som er enkelt å måle, vil du ende opp med mindre nyttige SLOer. Som et resultat har vi noen ganger funnet ut at det å identifisere ønskede mål i utgangspunktet og deretter jobbe med spesifikke indikatorer fungerer bedre enn å velge indikatorer og deretter oppnå målene.
Definer målene dine
For maksimal klarhet bør det defineres hvordan SLOer måles og betingelsene de er gyldige under. For eksempel kan vi si følgende (den andre linjen er den samme som den første, men bruker SLI-standardene):
- 99 % (gjennomsnittlig over 1 minutt) av Get RPC-anrop vil fullføres på mindre enn 100 ms (målt på tvers av alle backend-servere).
- 99 % av Get RPC-anrop vil fullføres på mindre enn 100 ms.
Hvis formen på ytelseskurvene er viktig, kan du spesifisere flere SLOer:
- 90 % av Få RPC-anrop fullført på mindre enn 1 ms.
- 99 % av Få RPC-anrop fullført på mindre enn 10 ms.
- 99.9% Få RPC-kall fullført på under 100 ms.
Hvis brukerne dine genererer heterogene arbeidsbelastninger: massebehandling (som gjennomstrømming er viktig for) og interaktiv behandling (som ventetid er viktig for), kan det være verdt å definere separate mål for hver belastningsklasse:
- 95 % av kundeforespørslene krever gjennomstrømning. Still inn antall utførte RPC-anrop <1 s.
- 99 % av klientene bryr seg om ventetiden. Angi antall RPC-anrop med trafikk <1 KB og kjører <10 ms.
Det er urealistisk og uønsket å insistere på at SLOer skal oppfylles 100 % av tiden: Dette kan redusere tempoet for introduksjon av ny funksjonalitet og utrulling, og kreve dyre løsninger. I stedet er det bedre å tillate et feilbudsjett – prosentandelen av systemnedetid som er tillatt – og overvåke denne verdien daglig eller ukentlig. Toppledelsen vil kanskje ha månedlige eller kvartalsvise evalueringer. (Feilbudsjettet er ganske enkelt en SLO for sammenligning med en annen SLO.)
Prosentandelen av SLO-brudd kan sammenlignes med feilbudsjettet (se kapittel 3 og pkt ), med differanseverdien brukt som input til prosessen som bestemmer når nye utgivelser skal distribueres.
Velge målverdier
Å velge planleggingsverdier (SLOer) er ikke en rent teknisk aktivitet på grunn av produkt- og forretningsinteressene som må reflekteres i de valgte SLIene, SLOene (og muligens SLAene). På samme måte kan det være nødvendig å utveksle informasjon om spørsmål knyttet til bemanning, time to market, utstyrs tilgjengelighet og finansiering. SRE bør være en del av denne samtalen og bidra til å forstå risikoen og levedyktigheten til ulike alternativer. Vi har kommet med noen spørsmål som kan bidra til å sikre en mer produktiv diskusjon:
Ikke velg et mål basert på nåværende ytelse.
Selv om det er viktig å forstå styrken og begrensningene til et system, kan tilpasning av beregninger uten resonnement blokkere deg fra å vedlikeholde systemet: det vil kreve heroisk innsats for å oppnå mål som ikke kan oppnås uten betydelig redesign.
Hold det enkelt
Komplekse SLI-beregninger kan skjule endringer i systemytelsen og gjøre det vanskeligere å finne årsaken til problemet.
Unngå absolutter
Selv om det er fristende å ha et system som kan håndtere en uendelig voksende belastning uten å øke ventetiden, er dette kravet urealistisk. Et system som nærmer seg slike idealer vil sannsynligvis kreve mye tid å designe og bygge, vil være dyrt å drifte, og vil være for godt for forventningene til brukere som ville gjøre med noe mindre.
Bruk så få SLOer som mulig
Velg et tilstrekkelig antall SLOer for å sikre god dekning av systemattributter. Beskytt SLO-ene du velger: Hvis du aldri kan vinne en krangel om prioriteringer ved å spesifisere en spesifikk SLO, er det sannsynligvis ikke verdt å vurdere den SLO-en. Imidlertid er ikke alle systemattributter tilgjengelige for SLOer: det er vanskelig å beregne nivået av brukerglede ved å bruke SLOer.
Ikke jag etter perfeksjon
Du kan alltid avgrense definisjonene og målene til SLOer over tid ettersom du lærer mer om systemets oppførsel under belastning. Det er bedre å starte med et flytende mål som du vil avgrense over tid enn å velge et altfor strengt mål som må slappes av når du finner ut at det er uoppnåelig.
SLO-er kan og bør være en nøkkeldriver i å prioritere arbeid for SRE-er og produktutviklere fordi de reflekterer en bekymring for brukerne. En god SLO er et nyttig håndhevingsverktøy for et utviklingsteam. Men en dårlig utformet SLO kan føre til bortkastet arbeid hvis teamet gjør en heroisk innsats for å oppnå en altfor aggressiv SLO, eller et dårlig produkt hvis SLO er for lav. SLO er en kraftig spak, bruk den med omhu.
Kontroller målingene dine
SLI og SLO er nøkkelelementer som brukes til å administrere systemer:
- Overvåke og måle SLI-systemer.
- Sammenlign SLI med SLO og avgjør om handling er nødvendig.
- Hvis handling er nødvendig, finn ut hva som må skje for å nå målet.
- Fullfør denne handlingen.
For eksempel, hvis trinn 2 viser at forespørselen tar slutt og vil bryte SLO i løpet av noen timer hvis ingenting gjøres, kan trinn 3 innebære å teste hypotesen om at serverne er CPU-bundet og å legge til flere servere vil fordele belastningen. Uten en SLO ville du ikke vite om (eller når) du skulle iverksette tiltak.
Sett SLO - så vil brukerens forventninger bli satt
Å publisere en SLO setter brukerens forventninger til systematferd. Brukere (og potensielle brukere) ønsker ofte å vite hva de kan forvente av en tjeneste for å forstå om den er egnet for bruk. For eksempel kan folk som ønsker å bruke et bildedelingsnettsted være lurt å unngå å bruke en tjeneste som lover lang levetid og lave kostnader i bytte mot litt mindre tilgjengelighet, selv om den samme tjenesten kan være ideell for et arkivoppføringssystem.
For å sette realistiske forventninger til brukerne dine, bruk én eller begge av følgende taktikker:
- Oppretthold en sikkerhetsmargin. Bruk en strengere intern SLO enn det som annonseres til brukere. Dette vil gi deg muligheten til å reagere på problemer før de blir eksternt synlige. SLO-bufferen lar deg også ha en sikkerhetsmargin når du installerer utgivelser som påvirker systemytelsen og sikrer at systemet er enkelt å vedlikeholde uten å måtte frustrere brukere med nedetid.
- Ikke overgå brukernes forventninger. Brukere er basert på hva du tilbyr, ikke hva du sier. Hvis den faktiske ytelsen til tjenesten din er mye bedre enn den angitte SLO-en, vil brukerne stole på den nåværende ytelsen. Du kan unngå overavhengighet ved å med vilje slå av systemet eller begrense ytelsen under lett belastning.
Å forstå hvor godt et system oppfyller forventningene hjelper til med å bestemme om det skal investeres i å få fart på systemet og gjøre det mer tilgjengelig og robust. Alternativt, hvis en tjeneste yter for godt, bør noe av personalet brukes på andre prioriteringer, som å betale ned teknisk gjeld, legge til nye funksjoner eller introdusere nye produkter.
Avtaler i praksis
Å opprette en SLA krever at forretnings- og juridiske team definerer konsekvensene og straffer for brudd på den. SREs rolle er å hjelpe dem å forstå de sannsynlige utfordringene ved å møte SLOene i SLAen. De fleste av anbefalingene for å opprette SLOer gjelder også SLAer. Det er lurt å være konservativ i det du lover brukere fordi jo mer du har, jo vanskeligere er det å endre eller fjerne SLAer som virker urimelige eller vanskelige å oppfylle.
Takk for at du leste oversettelsen til slutten. Abonner på min telegramkanal om overvåking и .
Kilde: www.habr.com
