

O artigo consiste em duas partes:
- Uma breve descrição de algumas arquiteturas de redes de detecção e segmentação de objetos em imagens, com links para recursos que considero mais compreensíveis. Procurei escolher explicações em vídeo, preferencialmente em russo.
- A segunda parte procura compreender a direção do desenvolvimento das arquiteturas de redes neurais e das tecnologias baseadas nelas.

Figura 1 – Compreender as arquiteturas de redes neurais não é fácil
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- , quando os dados são processados no servidor e transmitidos para o telefone. Classificação de imagens de três tipos de ursos: marrom, preto e de pelúcia.
- , quando os dados são processados no próprio telefone. Detecção de objetos de três tipos: avelã, figo e tâmara.
Existe uma diferença entre tarefas de classificação de imagens, detecção de objetos em uma imagem e Portanto, tornou-se necessário aprender quais arquiteturas de redes neurais detectam objetos em imagens e quais conseguem segmentá-los. Encontrei os seguintes exemplos de arquiteturas com os links mais fáceis de entender para recursos:
- Uma série de arquiteturas baseadas em R-CNN (Rregiões com Crevolução Neural NRecursos de rede): R-CNN, Fast R-CNN, , Para detectar objetos em uma imagem, caixas delimitadoras são extraídas usando o mecanismo de Rede de Proposta de Regiões (RPN). Inicialmente, um mecanismo de Busca Seletiva mais lento era usado em vez do RPN. As caixas delimitadoras extraídas são então enviadas para uma rede neural convencional para classificação. A arquitetura R-CNN usa laços "for" explícitos para iterar sobre as caixas delimitadoras, com até 2000 execuções na rede AlexNet interna. Esses laços "for" explícitos tornam o processamento de imagem mais lento. O número de laços explícitos e execuções na rede neural interna é reduzido a cada nova versão da arquitetura, e dezenas de outras mudanças estão sendo feitas para aumentar a velocidade e substituir a tarefa de detecção de objetos pela segmentação de objetos no Mask R-CNN.
- (You Only Look OYOLO (New York Network) é a primeira rede neural a reconhecer objetos em tempo real em dispositivos móveis. Sua característica distintiva é a capacidade de distinguir objetos em uma única execução (apenas um olhar). Ou seja, a arquitetura YOLO não utiliza laços "for" explícitos, o que permite que a rede opere rapidamente. Por exemplo, aqui está uma analogia: o NumPy também não utiliza laços "for" explícitos ao realizar operações matriciais; estas são implementadas no NumPy em níveis mais baixos da arquitetura por meio da linguagem de programação C. O YOLO utiliza uma grade de janelas predefinidas. Para evitar que o mesmo objeto seja detectado várias vezes, utiliza-se uma taxa de sobreposição de janelas (IoU). Iinterseção over Union). Essa arquitetura opera em uma ampla faixa e possui alta O modelo pode ser treinado com fotografias, mas também funciona bem com pinturas feitas à mão.
- (Single SHot MultiBox DA rede neural YOLO utiliza os "truques" mais bem-sucedidos da arquitetura YOLO (por exemplo, supressão não máxima) e adiciona novos para torná-la mais rápida e precisa. Sua característica distintiva é a capacidade de distinguir objetos em uma única execução, utilizando uma grade específica de janelas (por padrão, caixas) em uma pirâmide de imagens. A pirâmide de imagens é codificada em tensores convolucionais por meio de operações sucessivas de convolução e pooling (com max-pooling, a dimensionalidade espacial diminui). Isso permite a detecção de objetos grandes e pequenos em uma única execução da rede.
- MobileSSD (MobileNetV2 + SSD) é uma combinação de duas arquiteturas de redes neurais. A primeira rede Ele funciona rapidamente e aumenta a precisão do reconhecimento. O MobileNetV2 é usado em vez do VGG-16, que era usado originalmente em A segunda rede SSD determina a localização dos objetos na imagem.
- – uma rede neural muito pequena, porém precisa. Ela não resolve o problema de detecção de objetos sozinha. No entanto, pode ser usada em combinação com diversas arquiteturas e é adequada para uso em dispositivos móveis. Sua característica distintiva é que os dados são primeiro comprimidos em quatro filtros convolucionais 1×1 e, em seguida, expandidos em quatro filtros convolucionais 1×1 e quatro filtros convolucionais 3×3. Uma dessas iterações de compressão e expansão de dados é chamada de "Módulo de Disparo".
- (Segmentação Semântica de Imagens com Redes Convolucionais Profundas) – segmentação de objetos em uma imagem. Uma característica distintiva da arquitetura é a convolução dilatada, que preserva a resolução espacial. Isso é seguido por uma etapa de pós-processamento usando um modelo de probabilidade gráfica (um campo aleatório condicional), que remove pequenos ruídos na segmentação e melhora a qualidade da imagem segmentada. Por trás do nome complexo "modelo de probabilidade gráfica" reside um filtro gaussiano simples aproximado por cinco pontos.
- Tentei descobrir como funcionava o dispositivo. (Tiro único) RefinarRede Neural de mento para Objeto Detseção), mas entendia pouco.
- Analisei também como funciona a tecnologia de "atenção": , , Uma característica distintiva da arquitetura de "atenção" é a seleção automática de regiões de maior atenção na imagem (RoI, Regiões of Iinteresse) usando uma rede neural chamada Unidade de Atenção. As regiões de atenção são semelhantes às caixas delimitadoras, mas, ao contrário destas, não são fixas na imagem e podem ter limites desfocados. As características são então extraídas das regiões de atenção e inseridas em redes neurais recorrentes com arquiteturas Redes neurais recorrentes podem analisar as relações entre características em uma sequência. Inicialmente, elas eram usadas para traduzir textos para outros idiomas, e agora também para tradução. и .
Ao estudarmos essas arquiteturas, Percebi que não entendo nada.E não é que minha rede neural tenha problemas com seu mecanismo de atenção. Criar todas essas arquiteturas é como uma espécie de enorme hackathon, onde os autores competem em soluções improvisadas. Uma solução improvisada é uma solução rápida para um problema de programação difícil. Ou seja, não há nenhuma conexão lógica visível ou compreensível entre todas essas arquiteturas. Tudo o que as une é um conjunto das soluções improvisadas mais bem-sucedidas que elas copiam umas das outras, além de um objetivo comum a todas elas. (retropropagação de erros). Não. Não está claro o que precisa ser mudado ou como otimizar as conquistas existentes.
Como os hacks carecem de uma conexão lógica, são extremamente difíceis de memorizar e aplicar. O conhecimento é fragmentado. Na melhor das hipóteses, alguns pontos interessantes e inesperados são lembrados, mas a maior parte do que foi compreendido e do que não foi se perde em poucos dias. Seria ótimo se você conseguisse ao menos se lembrar do nome da arquitetura depois de uma semana. E, no entanto, horas e até dias de trabalho foram desperdiçados lendo artigos e assistindo a vídeos explicativos!
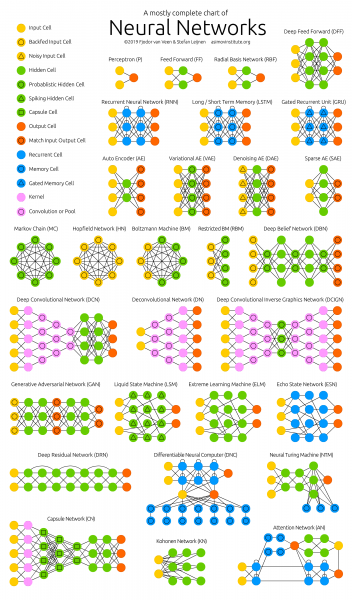
Figura 2 –
Na minha opinião, a maioria dos autores de artigos científicos faz tudo o que pode para garantir que nem mesmo esse conhecimento fragmentado seja compreendido pelo leitor. Mas frases adverbiais participiais em frases de dez linhas com fórmulas tiradas do nada são um tema para um artigo à parte (problema). ).
Por essa razão, surgiu a necessidade de sistematizar as informações sobre redes neurais e, assim, melhorar a qualidade da compreensão e da memorização. Portanto, o principal tema da análise das tecnologias e arquiteturas individuais das redes neurais artificiais tornou-se a seguinte tarefa: Descubra para onde tudo isso está caminhando., e não a estrutura de qualquer rede neural específica isoladamente.
Para onde tudo isso está caminhando? Principais conclusões:
- O número de startups de aprendizado de máquina nos últimos dois anos Possível motivo: "redes neurais já não são uma novidade."
- Qualquer pessoa pode criar uma rede neural funcional para resolver um problema simples. Para isso, basta pegar um modelo pronto do "repositório de modelos" e treinar a camada final da rede neural () em dados prontos de ou de em liberdade .
- Grandes fabricantes de redes neurais começaram a criar "zoológicos modelo" (zoológico modelo). Com a ajuda deles, você pode criar rapidamente um aplicativo comercial: para TensorFlow, para PyTorch, para Caffe2, para Chainer e .
- Redes neurais operando em tempo real (Em tempo real) em dispositivos móveis. De 10 a 50 quadros por segundo.
- Aplicação de redes neurais em telefones (TF Lite), em navegadores (TF.js) e em (IoT, Internet of Tcoisas). Especialmente em telefones que já suportam redes neurais em nível de hardware (aceleradores neurais).
- “Todos os dispositivos, peças de roupa e talvez até mesmo alimentos terão Endereço IPv6 e se comunicar uns com os outros" – .
- O número de publicações sobre aprendizado de máquina começou a crescer. (dobrando a cada dois anos) desde 2015. Obviamente, são necessárias redes neurais para análise de artigos.
- As seguintes tecnologias estão ganhando popularidade:
- PyTorch – Sua popularidade está crescendo rapidamente e parece estar ultrapassando o TensorFlow.
- Seleção automática de hiperparâmetros AutoML – A popularidade está crescendo de forma constante.
- Diminuição gradual da precisão e aumento da velocidade de cálculo: , algoritmos , cálculos imprecisos (aproximados), quantização (quando os pesos da rede neural são convertidos em números inteiros e quantizados), neuroaceleradores.
- Tradução и .
- criação , agora em tempo real.
- A chave para o aprendizado profundo é a grande quantidade de dados, mas coletá-los e rotulá-los não é fácil. Portanto, a automação da rotulagem está em desenvolvimento.) para redes neurais usando redes neurais.
- Com as redes neurais, a Ciência da Computação de repente se transformou em algo completamente diferente. ciência experimental e surgiu .
- O dinheiro da TI e a popularidade das redes neurais surgiram simultaneamente, quando a computação se tornou um valor de mercado. A economia se transformou de uma economia baseada em moeda-ouro. computação-moeda-ouroVeja meu artigo sobre e a razão para o surgimento do dinheiro da TI.
Uma nova está gradualmente surgindo. (Aprendizado de Máquina e Aprendizado Profundo), que se baseia em representar um programa como um conjunto de modelos de redes neurais treinados.
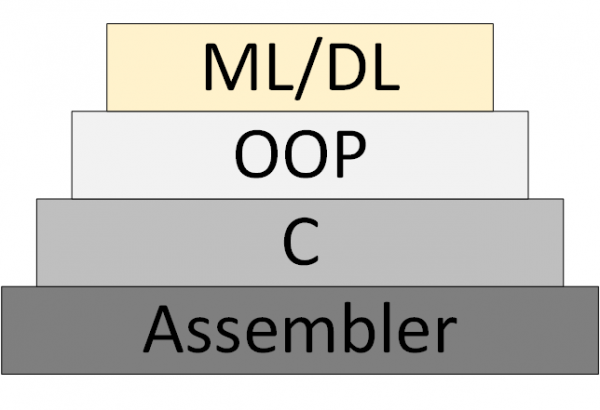
Figura 3 – ML/DL como uma nova metodologia de programação
No entanto, nunca apareceu. teorias de redes neurais, dentro da qual se pode pensar e trabalhar sistematicamente. O que hoje chamamos de "teoria" são, na verdade, algoritmos heurísticos experimentais.
Links para meus recursos e outros:
- Boletim informativo sobre Ciência de Dados. Principalmente sobre processamento de imagens. Quem tiver interesse em recebê-lo pode me enviar um e-mail (foobar167<gaf-gaf>gmail<dot>com). Enviarei links para artigos e vídeos à medida que reunir novos materiais.
- Geral que eu já passei e que eu gostaria de passar.
- , que valem a pena começar a estudar redes neurais. Mais um folheto. .
- , onde todos encontrarão algo interessante para si.
- Eles se revelaram extremamente úteis. Canais de vídeo para análise de artigos científicos Ciência de Dados. Encontre-os, siga-os e compartilhe os links com seus colegas e comigo. Exemplos:
- aka Com instruções passo a passo e código aberto.
Obrigado!
Fonte: habr.com
